 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
INTERSPEECH 2021 ConferencingSpeech Challenge: Towards Far-field Multi-Channel Speech Enhancement for Video Conferencing
Apr 02, 2021
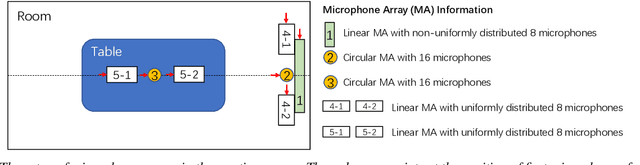
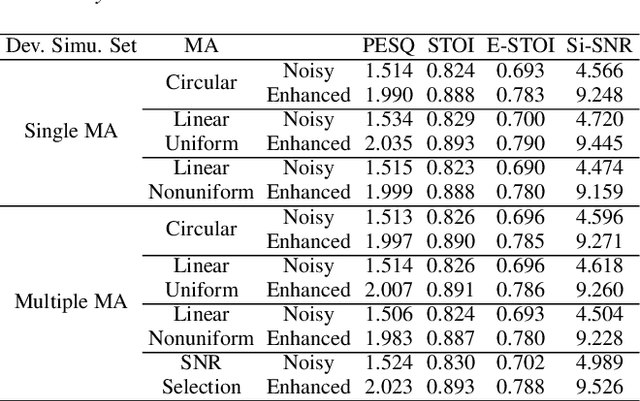

The ConferencingSpeech 2021 challenge is proposed to stimulate research on far-field multi-channel speech enhancement for video conferencing. The challenge consists of two separate tasks: 1) Task 1 is multi-channel speech enhancement with single microphone array and focusing on practical application with real-time requirement and 2) Task 2 is multi-channel speech enhancement with multiple distributed microphone arrays, which is a non-real-time track and does not have any constraints so that participants could explore any algorithms to obtain high speech quality. Targeting the real video conferencing room application, the challenge database was recorded from real speakers and all recording facilities were located by following the real setup of conferencing room. In this challenge, we open-sourced the list of open source clean speech and noise datasets, simulation scripts, and a baseline system for participants to develop their own system. The final ranking of the challenge will be decided by the subjective evaluation which is performed using Absolute Category Ratings (ACR) to estimate Mean Opinion Score (MOS), speech MOS (S-MOS), and noise MOS (N-MOS). This paper describes the challenge, tasks, datasets, and subjective evaluation. The baseline system which is a complex ratio mask based neural network and its experimental results are also presented.
Data Augmentation based Consistency Contrastive Pre-training for Automatic Speech Recognition
Dec 23, 2021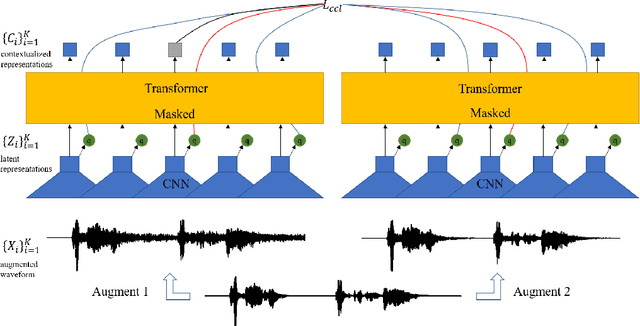
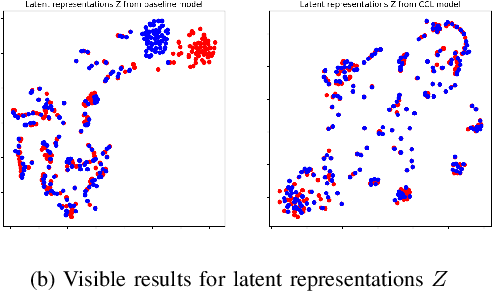
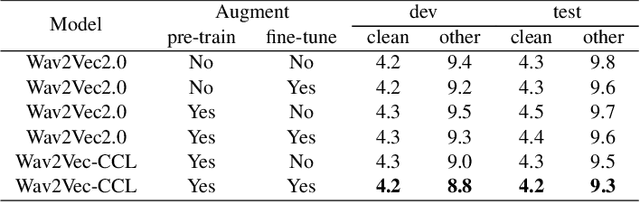
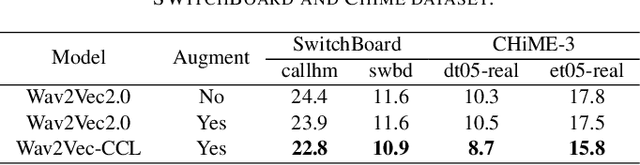
Self-supervised acoustic pre-training has achieved amazing results on the automatic speech recognition (ASR) task. Most of the successful acoustic pre-training methods use contrastive learning to learn the acoustic representations by distinguish the representations from different time steps, ignoring the speaker and environment robustness. As a result, the pre-trained model could show poor performance when meeting out-of-domain data during fine-tuning. In this letter, we design a novel consistency contrastive learning (CCL) method by utilizing data augmentation for acoustic pre-training. Different kinds of augmentation are applied on the original audios and then the augmented audios are fed into an encoder. The encoder should not only contrast the representations within one audio but also maximize the measurement of the representations across different augmented audios. By this way, the pre-trained model can learn a text-related representation method which is more robust with the change of the speaker or the environment.Experiments show that by applying the CCL method on the Wav2Vec2.0, better results can be realized both on the in-domain data and the out-of-domain data. Especially for noisy out-of-domain data, more than 15% relative improvement can be obtained.
Distilling the Knowledge of BERT for CTC-based ASR
Sep 05, 2022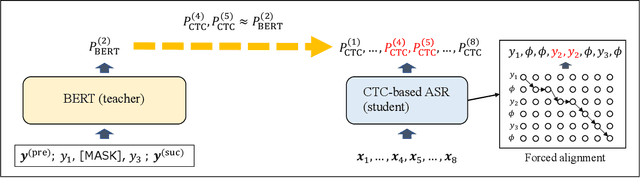
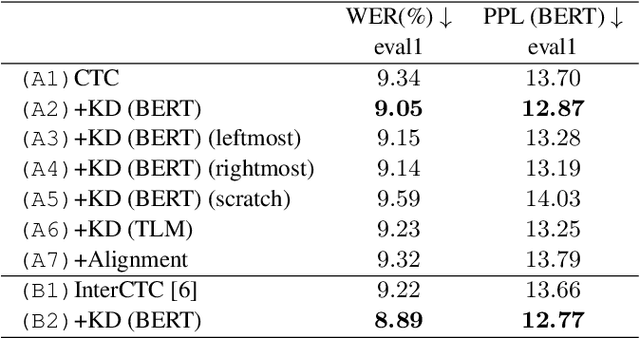
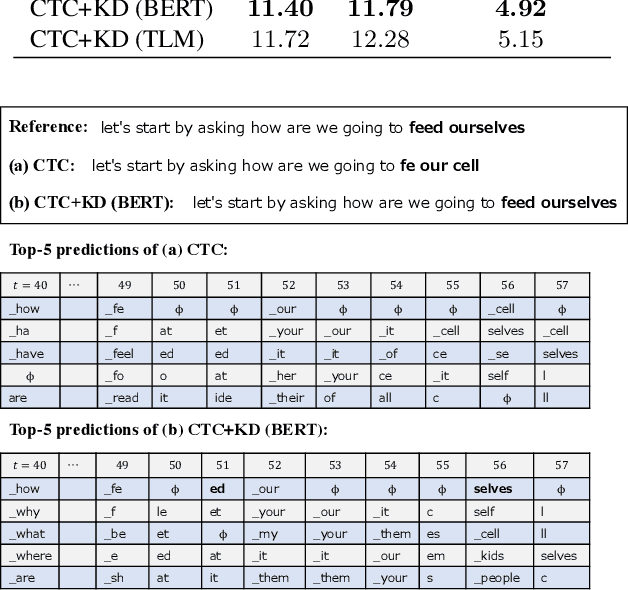
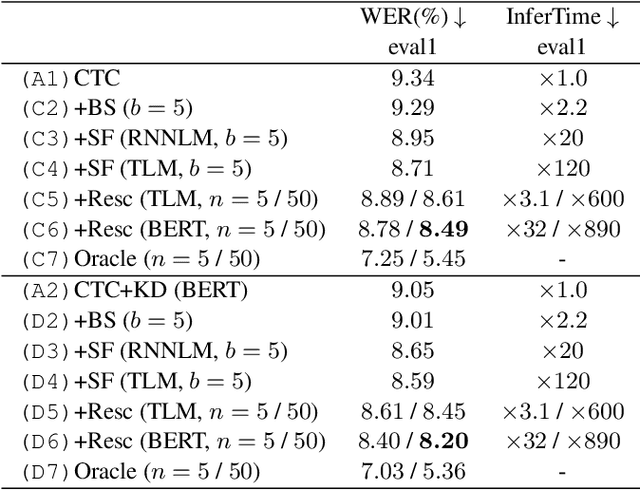
Connectionist temporal classification (CTC) -based models are attractive because of their fast inference in automatic speech recognition (ASR). Language model (LM) integration approaches such as shallow fusion and rescoring can improve the recognition accuracy of CTC-based ASR by taking advantage of the knowledge in text corpora. However, they significantly slow down the inference of CTC. In this study, we propose to distill the knowledge of BERT for CTC-based ASR, extending our previous study for attention-based ASR. CTC-based ASR learns the knowledge of BERT during training and does not use BERT during testing, which maintains the fast inference of CTC. Different from attention-based models, CTC-based models make frame-level predictions, so they need to be aligned with token-level predictions of BERT for distillation. We propose to obtain alignments by calculating the most plausible CTC paths. Experimental evaluations on the Corpus of Spontaneous Japanese (CSJ) and TED-LIUM2 show that our method improves the performance of CTC-based ASR without the cost of inference speed.
The Analysis of Synonymy and Antonymy in Discourse Relations: An interpretable Modeling Approach
Aug 09, 2022
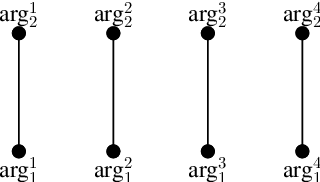

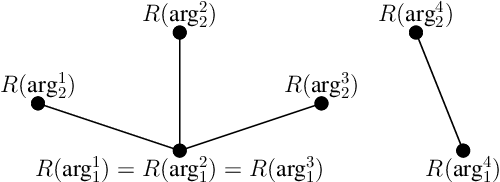
The idea that discourse relations are construed through explicit content and shared, or implicit, knowledge between producer and interpreter is ubiquitous in discourse research and linguistics. However, the actual contribution of the lexical semantics of arguments is unclear. We propose a computational approach to the analysis of contrast and concession relations in the PDTB corpus. Our work sheds light on the extent to which lexical semantics contributes to signaling explicit and implicit discourse relations and clarifies the contribution of different parts of speech in both. This study contributes to bridging the gap between corpus linguistics and computational linguistics by proposing transparent and explainable models of discourse relations based on the synonymy and antonymy of their arguments.
Bridging the prosody GAP: Genetic Algorithm with People to efficiently sample emotional prosody
May 10, 2022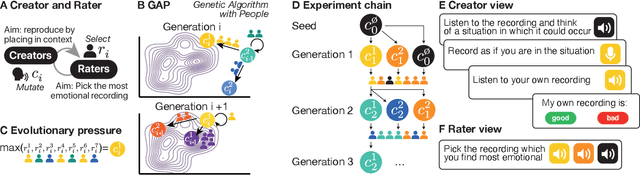
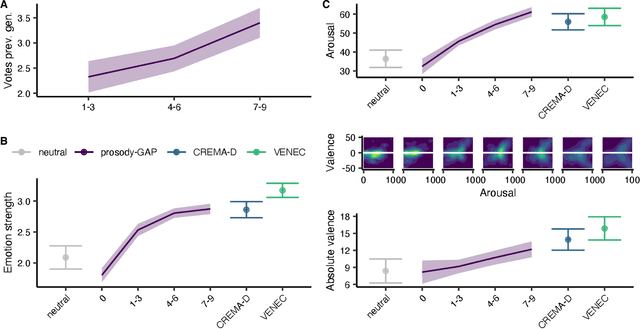
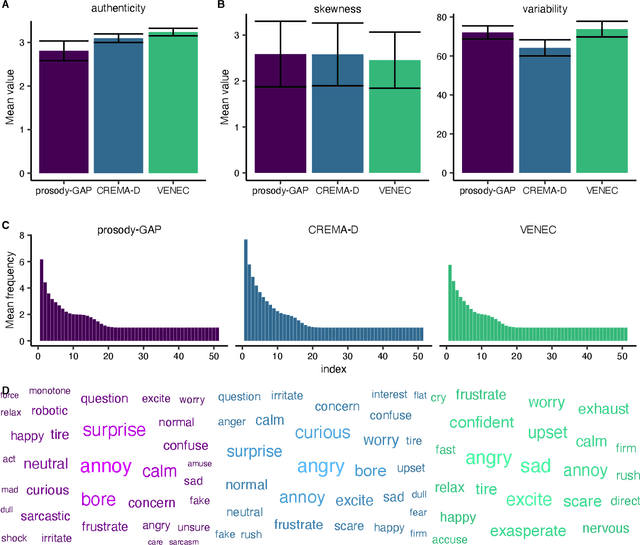
The human voice effectively communicates a range of emotions with nuanced variations in acoustics. Existing emotional speech corpora are limited in that they are either (a) highly curated to induce specific emotions with predefined categories that may not capture the full extent of emotional experiences, or (b) entangled in their semantic and prosodic cues, limiting the ability to study these cues separately. To overcome this challenge, we propose a new approach called 'Genetic Algorithm with People' (GAP), which integrates human decision and production into a genetic algorithm. In our design, we allow creators and raters to jointly optimize the emotional prosody over generations. We demonstrate that GAP can efficiently sample from the emotional speech space and capture a broad range of emotions, and show comparable results to state-of-the-art emotional speech corpora. GAP is language-independent and supports large crowd-sourcing, thus can support future large-scale cross-cultural research.
Consistent Training and Decoding For End-to-end Speech Recognition Using Lattice-free MMI
Dec 30, 2021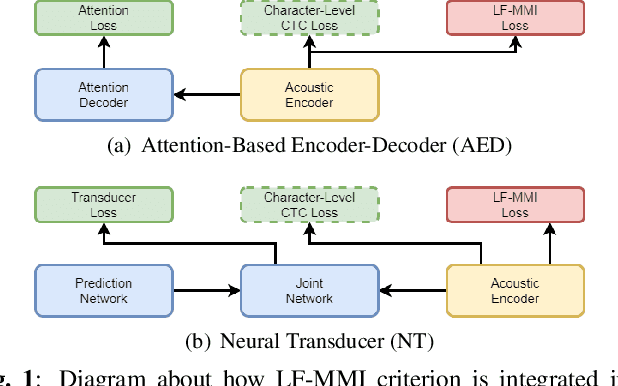
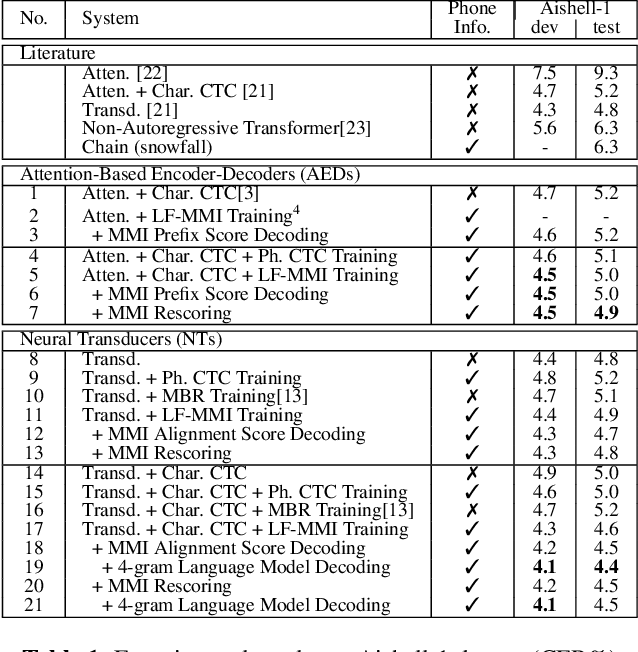
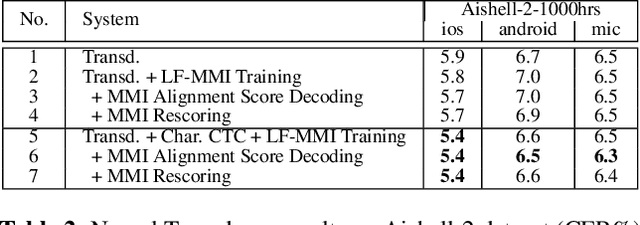
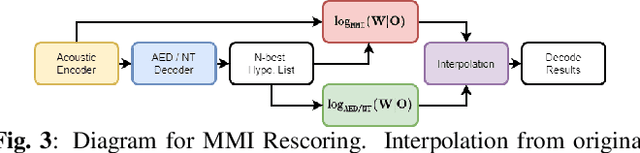
Recently, End-to-End (E2E) frameworks have achieved remarkable results on various Automatic Speech Recognition (ASR) tasks. However, Lattice-Free Maximum Mutual Information (LF-MMI), as one of the discriminative training criteria that show superior performance in hybrid ASR systems, is rarely adopted in E2E ASR frameworks. In this work, we propose a novel approach to integrate LF-MMI criterion into E2E ASR frameworks in both training and decoding stages. The proposed approach shows its effectiveness on two of the most widely used E2E frameworks including Attention-Based Encoder-Decoders (AEDs) and Neural Transducers (NTs). Experiments suggest that the introduction of the LF-MMI criterion consistently leads to significant performance improvements on various datasets and different E2E ASR frameworks. The best of our models achieves competitive CER of 4.1\% / 4.4\% on Aishell-1 dev/test set; we also achieve significant error reduction on Aishell-2 and Librispeech datasets over strong baselines.
Direct Noisy Speech Modeling for Noisy-to-Noisy Voice Conversion
Nov 13, 2021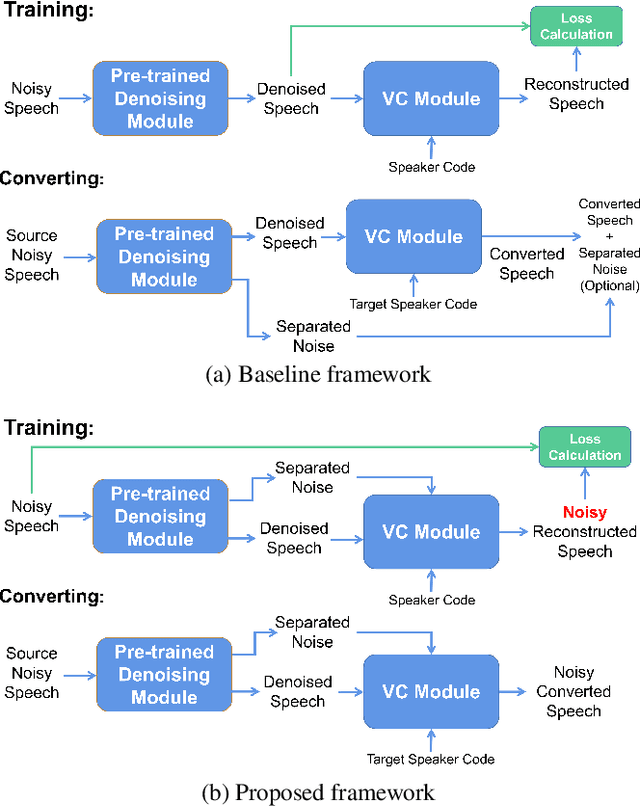
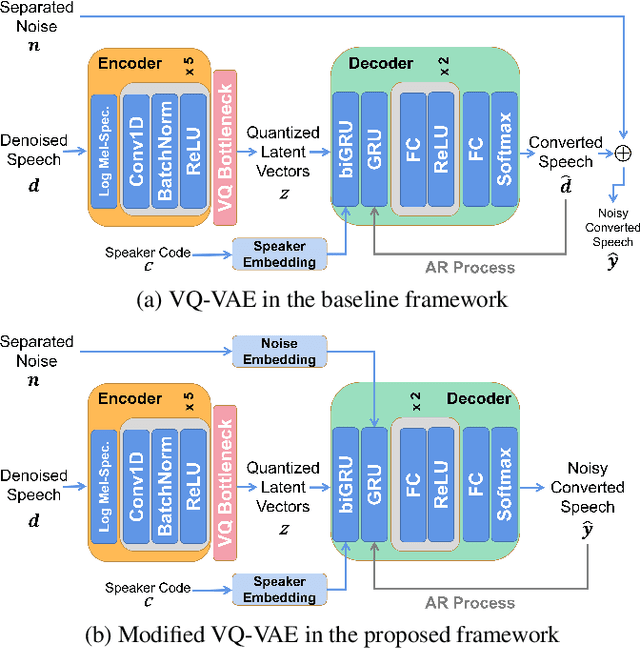
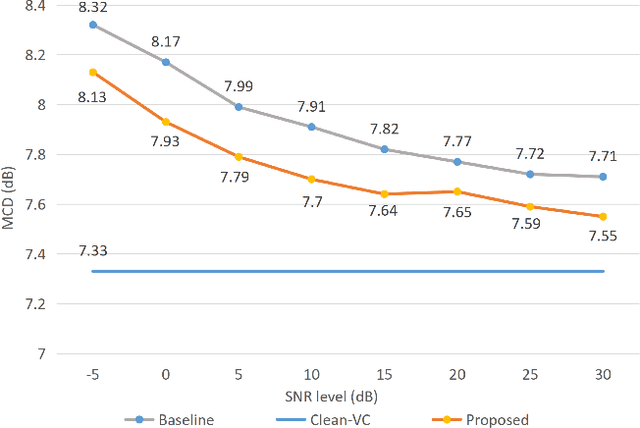
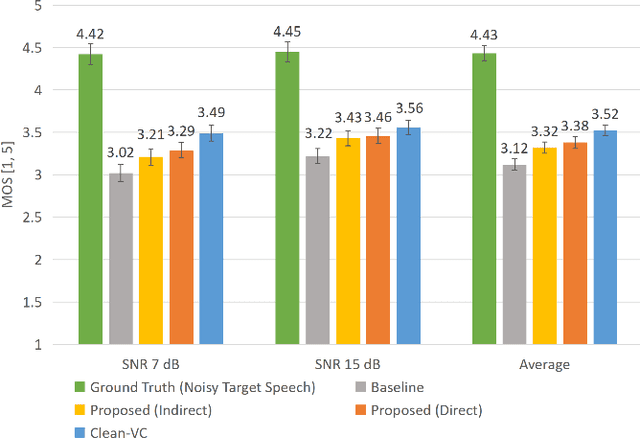
Beyond the conventional voice conversion (VC) where the speaker information is converted without altering the linguistic content, the background sounds are informative and need to be retained in some real-world scenarios, such as VC in movie/video and VC in music where the voice is entangled with background sounds. As a new VC framework, we have developed a noisy-to-noisy (N2N) VC framework to convert the speaker's identity while preserving the background sounds. Although our framework consisting of a denoising module and a VC module well handles the background sounds, the VC module is sensitive to the distortion caused by the denoising module. To address this distortion issue, in this paper we propose the improved VC module to directly model the noisy speech waveform while controlling the background sounds. The experimental results have demonstrated that our improved framework significantly outperforms the previous one and achieves an acceptable score in terms of naturalness, while reaching comparable similarity performance to the upper bound of our framework.
MixSpeech: Data Augmentation for Low-resource Automatic Speech Recognition
Feb 25, 2021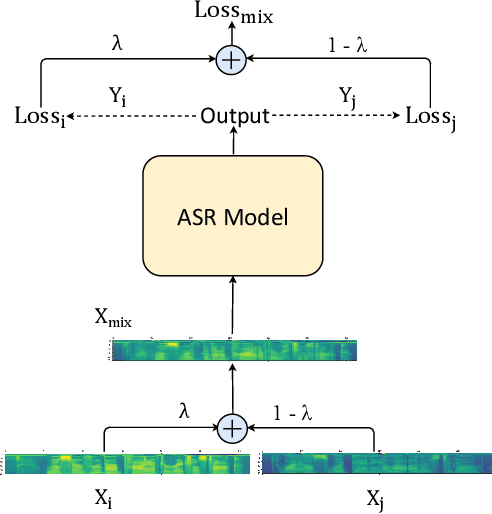

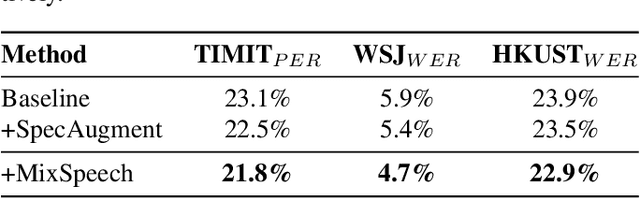
In this paper, we propose MixSpeech, a simple yet effective data augmentation method based on mixup for automatic speech recognition (ASR). MixSpeech trains an ASR model by taking a weighted combination of two different speech features (e.g., mel-spectrograms or MFCC) as the input, and recognizing both text sequences, where the two recognition losses use the same combination weight. We apply MixSpeech on two popular end-to-end speech recognition models including LAS (Listen, Attend and Spell) and Transformer, and conduct experiments on several low-resource datasets including TIMIT, WSJ, and HKUST. Experimental results show that MixSpeech achieves better accuracy than the baseline models without data augmentation, and outperforms a strong data augmentation method SpecAugment on these recognition tasks. Specifically, MixSpeech outperforms SpecAugment with a relative PER improvement of 10.6$\%$ on TIMIT dataset, and achieves a strong WER of 4.7$\%$ on WSJ dataset.
Voice Spoofing Countermeasures: Taxonomy, State-of-the-art, experimental analysis of generalizability, open challenges, and the way forward
Oct 02, 2022
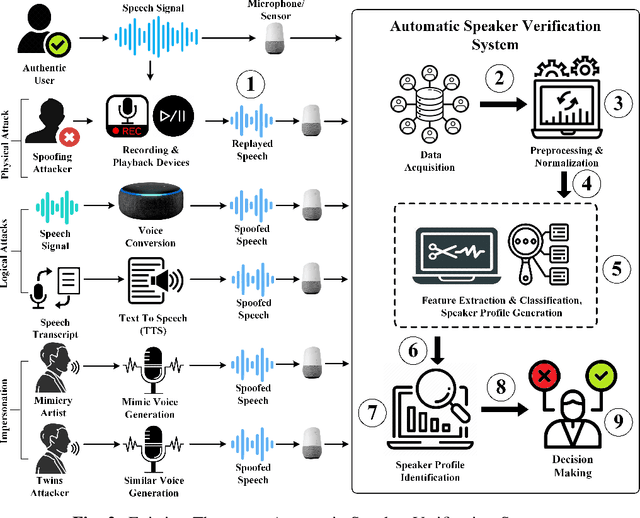
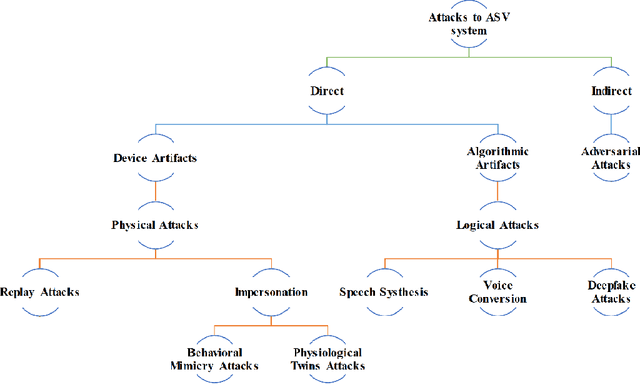
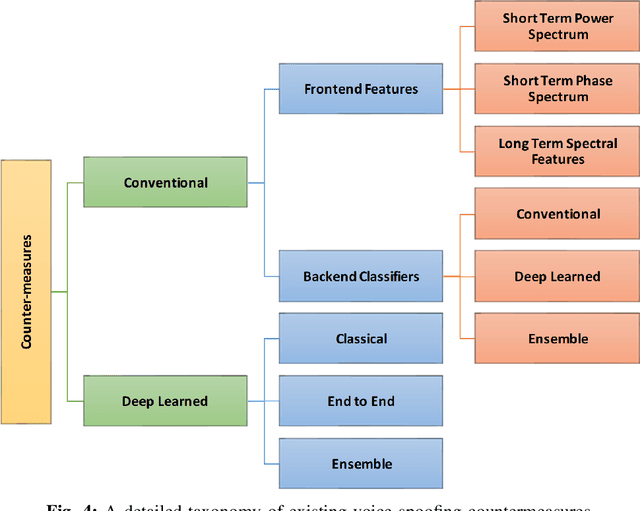
Malicious actors may seek to use different voice-spoofing attacks to fool ASV systems and even use them for spreading misinformation. Various countermeasures have been proposed to detect these spoofing attacks. Due to the extensive work done on spoofing detection in automated speaker verification (ASV) systems in the last 6-7 years, there is a need to classify the research and perform qualitative and quantitative comparisons on state-of-the-art countermeasures. Additionally, no existing survey paper has reviewed integrated solutions to voice spoofing evaluation and speaker verification, adversarial/antiforensics attacks on spoofing countermeasures, and ASV itself, or unified solutions to detect multiple attacks using a single model. Further, no work has been done to provide an apples-to-apples comparison of published countermeasures in order to assess their generalizability by evaluating them across corpora. In this work, we conduct a review of the literature on spoofing detection using hand-crafted features, deep learning, end-to-end, and universal spoofing countermeasure solutions to detect speech synthesis (SS), voice conversion (VC), and replay attacks. Additionally, we also review integrated solutions to voice spoofing evaluation and speaker verification, adversarial and anti-forensics attacks on voice countermeasures, and ASV. The limitations and challenges of the existing spoofing countermeasures are also presented. We report the performance of these countermeasures on several datasets and evaluate them across corpora. For the experiments, we employ the ASVspoof2019 and VSDC datasets along with GMM, SVM, CNN, and CNN-GRU classifiers. (For reproduceability of the results, the code of the test bed can be found in our GitHub Repository.
Unsupervised Voice Activity Detection by Modeling Source and System Information using Zero Frequency Filtering
Jun 27, 2022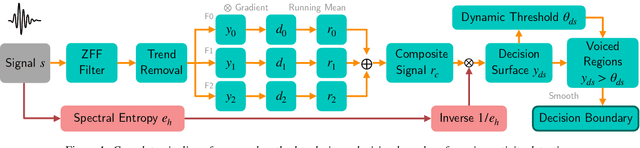
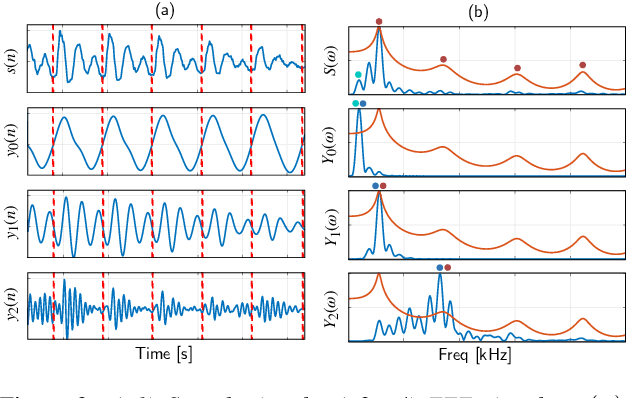
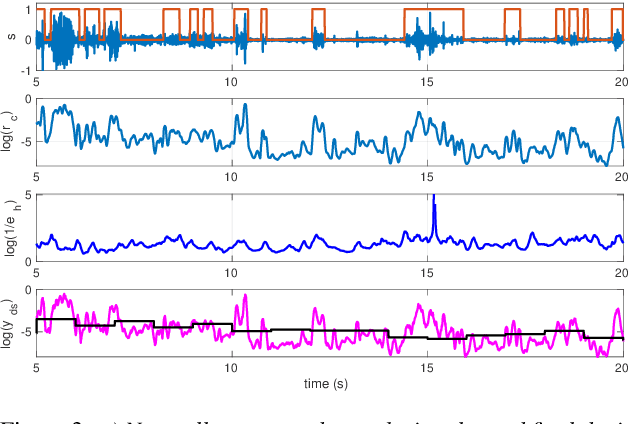
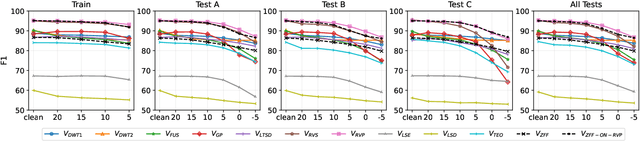
Voice activity detection (VAD) is an important pre-processing step for speech technology applications. The task consists of deriving segment boundaries of audio signals which contain voicing information. In recent years, it has been shown that voice source and vocal tract system information can be extracted using zero-frequency filtering (ZFF) without making any explicit model assumptions about the speech signal. This paper investigates the potential of zero-frequency filtering for jointly modeling voice source and vocal tract system information, and proposes two approaches for VAD. The first approach demarcates voiced regions using a composite signal composed of different zero-frequency filtered signals. The second approach feeds the composite signal as input to the rVAD algorithm. These approaches are compared with other supervised and unsupervised VAD methods in the literature, and are evaluated on the Aurora-2 database, across a range of SNRs (20 to -5 dB). Our studies show that the proposed ZFF-based methods perform comparable to state-of-art VAD methods and are more invariant to added degradation and different channel characteristics.