 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Training Strategies for Own Voice Reconstruction in Hearing Protection Devices using an In-ear Microphone
May 12, 2022
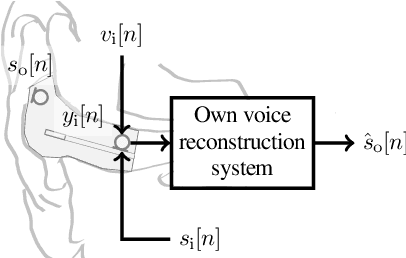
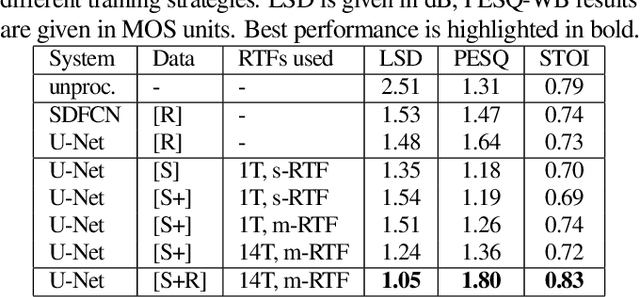
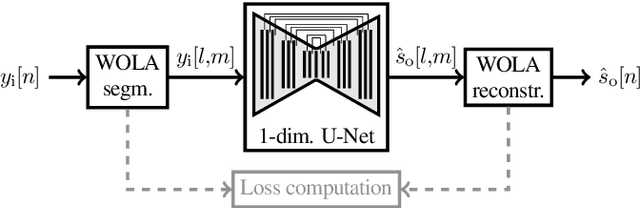
In-ear microphones in hearing protection devices can be utilized to capture the own voice speech of the person wearing the devices in noisy environments. Since in-ear recordings of the own voice are typically band-limited, an own voice reconstruction system is required to recover clean broadband speech from the in-ear signals. However, the availability of speech data for this scenario is typically limited due to device-specific transfer characteristics and the need to collect data from in-situ measurements. In this paper, we apply a deep learning-based bandwidth-extension system to the own voice reconstruction task and investigate different training strategies in order to overcome the limited availability of training data. Experimental results indicate that the use of simulated training data based on recordings of several talkers in combination with a fine-tuning approach using real data is advantageous compared to directly training on a small real dataset.
INTERSPEECH 2021 ConferencingSpeech Challenge: Towards Far-field Multi-Channel Speech Enhancement for Video Conferencing
Apr 02, 2021
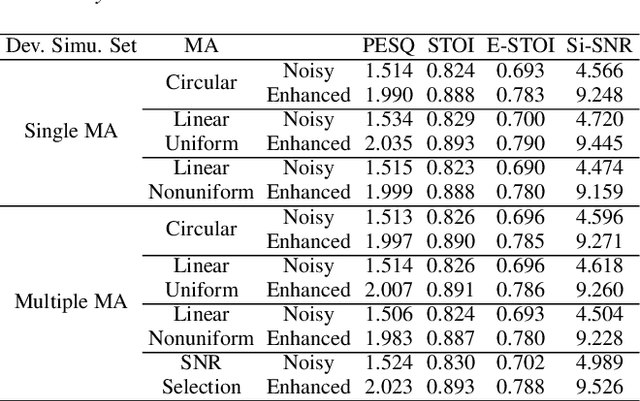

The ConferencingSpeech 2021 challenge is proposed to stimulate research on far-field multi-channel speech enhancement for video conferencing. The challenge consists of two separate tasks: 1) Task 1 is multi-channel speech enhancement with single microphone array and focusing on practical application with real-time requirement and 2) Task 2 is multi-channel speech enhancement with multiple distributed microphone arrays, which is a non-real-time track and does not have any constraints so that participants could explore any algorithms to obtain high speech quality. Targeting the real video conferencing room application, the challenge database was recorded from real speakers and all recording facilities were located by following the real setup of conferencing room. In this challenge, we open-sourced the list of open source clean speech and noise datasets, simulation scripts, and a baseline system for participants to develop their own system. The final ranking of the challenge will be decided by the subjective evaluation which is performed using Absolute Category Ratings (ACR) to estimate Mean Opinion Score (MOS), speech MOS (S-MOS), and noise MOS (N-MOS). This paper describes the challenge, tasks, datasets, and subjective evaluation. The baseline system which is a complex ratio mask based neural network and its experimental results are also presented.
Learning Transferable Spatiotemporal Representations from Natural Script Knowledge
Sep 30, 2022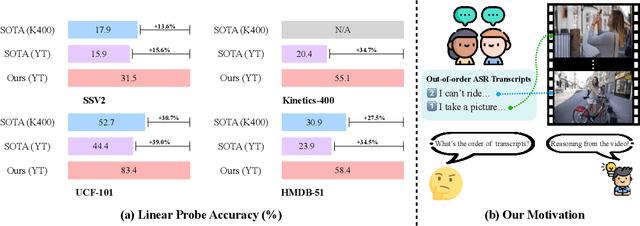
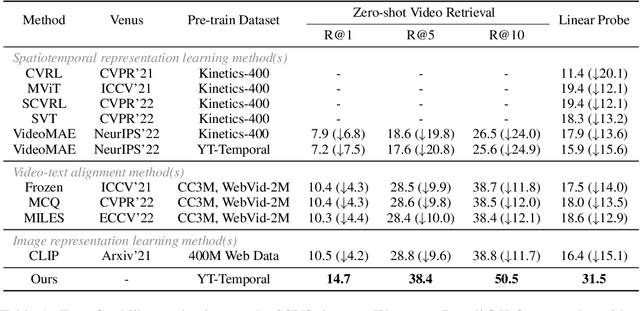
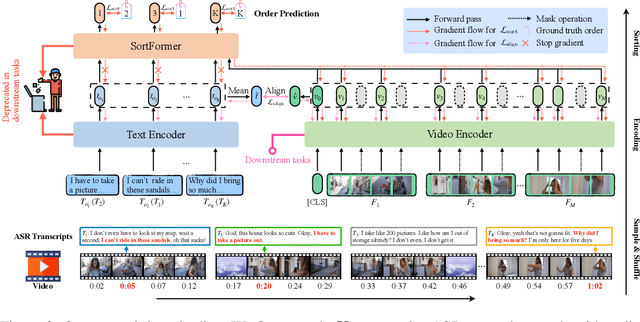
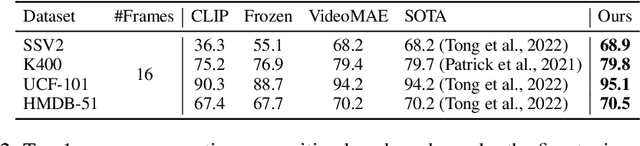
Pre-training on large-scale video data has become a common recipe for learning transferable spatiotemporal representations in recent years. Despite some progress, existing methods are mostly limited to highly curated datasets (e.g., K400) and exhibit unsatisfactory out-of-the-box representations. We argue that it is due to the fact that they only capture pixel-level knowledge rather than spatiotemporal commonsense, which is far away from cognition-level video understanding. Inspired by the great success of image-text pre-training (e.g., CLIP), we take the first step to exploit language semantics to boost transferable spatiotemporal representation learning. We introduce a new pretext task, Turning to Video for Transcript Sorting (TVTS), which sorts shuffled ASR scripts by attending to learned video representations. We do not rely on descriptive captions and learn purely from video, i.e., leveraging the natural transcribed speech knowledge to provide noisy but useful semantics over time. Furthermore, rather than the simple concept learning in vision-caption contrast, we encourage cognition-level temporal commonsense reasoning via narrative reorganization. The advantages enable our model to contextualize what is happening like human beings and seamlessly apply to large-scale uncurated video data in the real world. Note that our method differs from ones designed for video-text alignment (e.g., Frozen) and multimodal representation learning (e.g., Merlot). Our method demonstrates strong out-of-the-box spatiotemporal representations on diverse video benchmarks, e.g., +13.6% gains over VideoMAE on SSV2 via linear probing.
Building a great multi-lingual teacher with sparsely-gated mixture of experts for speech recognition
Jan 04, 2022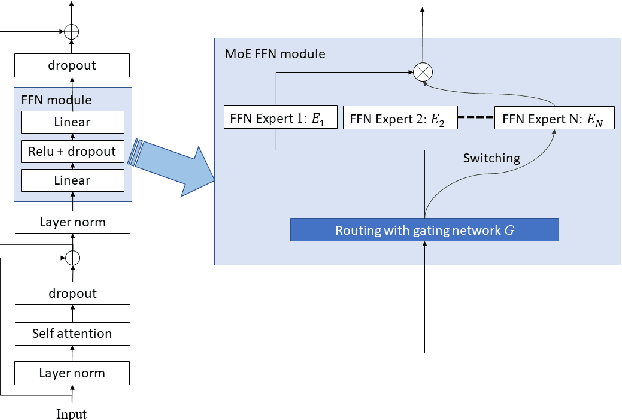
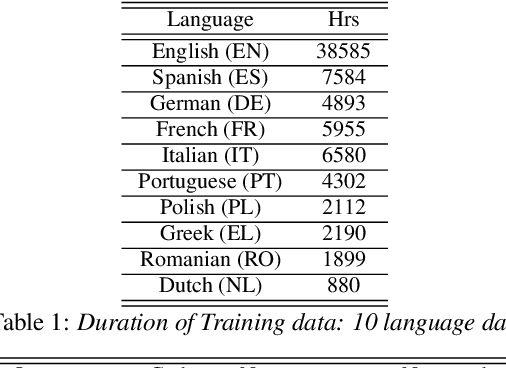
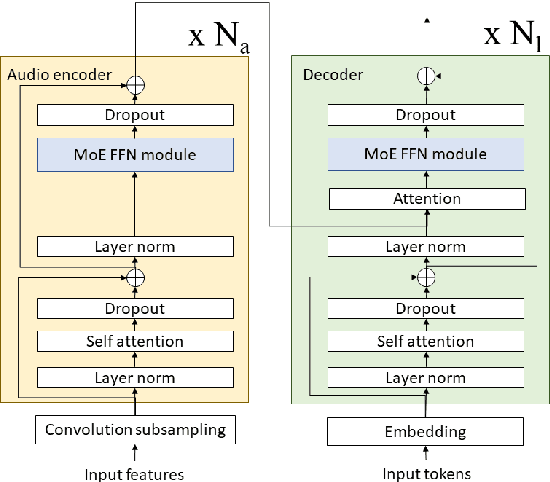
The sparsely-gated Mixture of Experts (MoE) can magnify a network capacity with a little computational complexity. In this work, we investigate how multi-lingual Automatic Speech Recognition (ASR) networks can be scaled up with a simple routing algorithm in order to achieve better accuracy. More specifically, we apply the sparsely-gated MoE technique to two types of networks: Sequence-to-Sequence Transformer (S2S-T) and Transformer Transducer (T-T). We demonstrate through a set of ASR experiments on multiple language data that the MoE networks can reduce the relative word error rates by 16.3% and 4.6% with the S2S-T and T-T, respectively. Moreover, we thoroughly investigate the effect of the MoE on the T-T architecture in various conditions: streaming mode, non-streaming mode, the use of language ID and the label decoder with the MoE.
MixSpeech: Data Augmentation for Low-resource Automatic Speech Recognition
Feb 25, 2021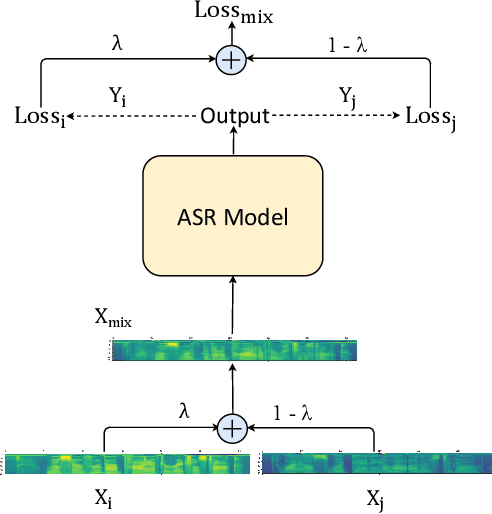

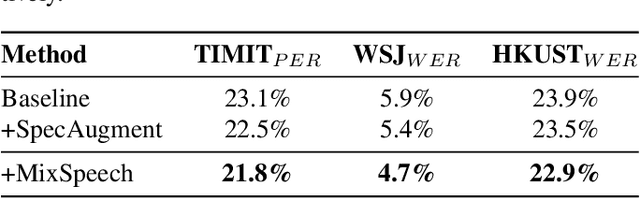
In this paper, we propose MixSpeech, a simple yet effective data augmentation method based on mixup for automatic speech recognition (ASR). MixSpeech trains an ASR model by taking a weighted combination of two different speech features (e.g., mel-spectrograms or MFCC) as the input, and recognizing both text sequences, where the two recognition losses use the same combination weight. We apply MixSpeech on two popular end-to-end speech recognition models including LAS (Listen, Attend and Spell) and Transformer, and conduct experiments on several low-resource datasets including TIMIT, WSJ, and HKUST. Experimental results show that MixSpeech achieves better accuracy than the baseline models without data augmentation, and outperforms a strong data augmentation method SpecAugment on these recognition tasks. Specifically, MixSpeech outperforms SpecAugment with a relative PER improvement of 10.6$\%$ on TIMIT dataset, and achieves a strong WER of 4.7$\%$ on WSJ dataset.
Leveraging cross-platform data to improve automated hate speech detection
Feb 09, 2021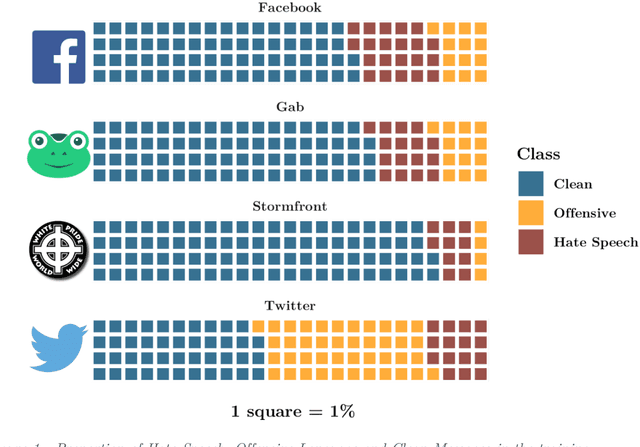

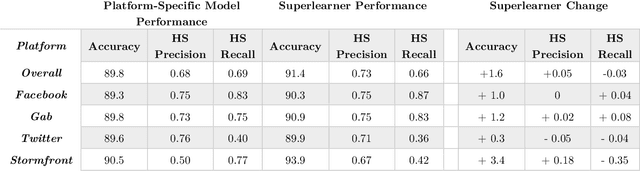
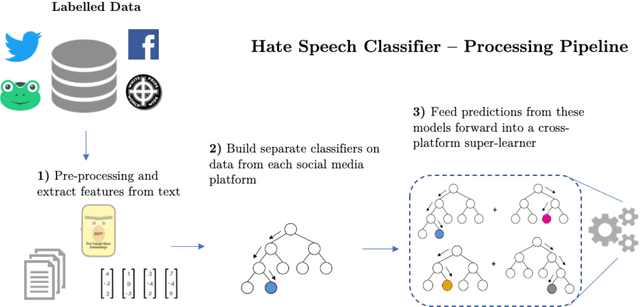
Hate speech is increasingly prevalent online, and its negative outcomes include increased prejudice, extremism, and even offline hate crime. Automatic detection of online hate speech can help us to better understand these impacts. However, while the field has recently progressed through advances in natural language processing, challenges still remain. In particular, most existing approaches for hate speech detection focus on a single social media platform in isolation. This limits both the use of these models and their validity, as the nature of language varies from platform to platform. Here we propose a new cross-platform approach to detect hate speech which leverages multiple datasets and classification models from different platforms and trains a superlearner that can combine existing and novel training data to improve detection and increase model applicability. We demonstrate how this approach outperforms existing models, and achieves good performance when tested on messages from novel social media platforms not included in the original training data.
Acoustic-Linguistic Features for Modeling Neurological Task Score in Alzheimer's
Sep 13, 2022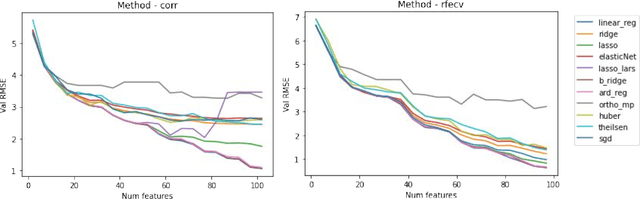
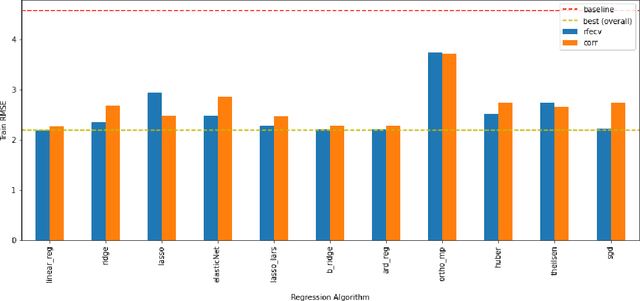
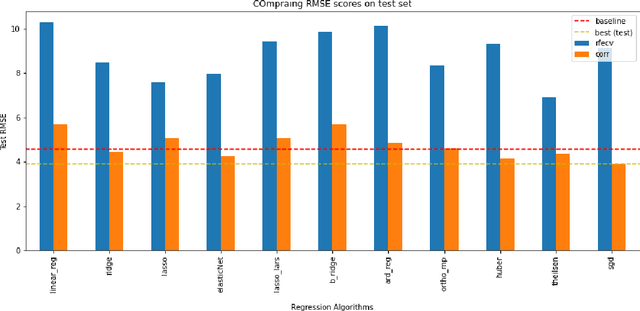
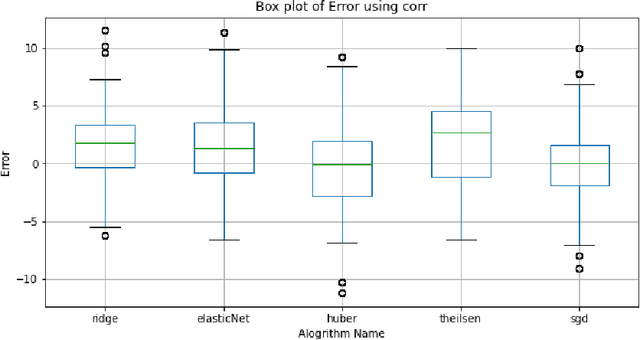
The average life expectancy is increasing globally due to advancements in medical technology, preventive health care, and a growing emphasis on gerontological health. Therefore, developing technologies that detect and track aging-associated disease in cognitive function among older adult populations is imperative. In particular, research related to automatic detection and evaluation of Alzheimer's disease (AD) is critical given the disease's prevalence and the cost of current methods. As AD impacts the acoustics of speech and vocabulary, natural language processing and machine learning provide promising techniques for reliably detecting AD. We compare and contrast the performance of ten linear regression models for predicting Mini-Mental Status Exam scores on the ADReSS challenge dataset. We extracted 13000+ handcrafted and learned features that capture linguistic and acoustic phenomena. Using a subset of 54 top features selected by two methods: (1) recursive elimination and (2) correlation scores, we outperform a state-of-the-art baseline for the same task. Upon scoring and evaluating the statistical significance of each of the selected subset of features for each model, we find that, for the given task, handcrafted linguistic features are more significant than acoustic and learned features.
Controllable Image Captioning
May 03, 2022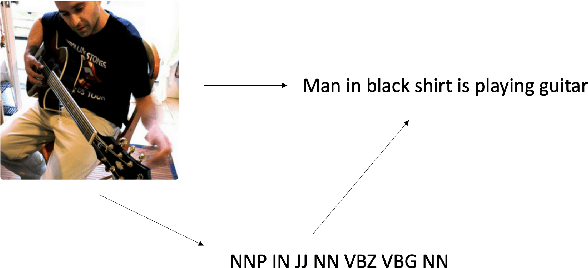
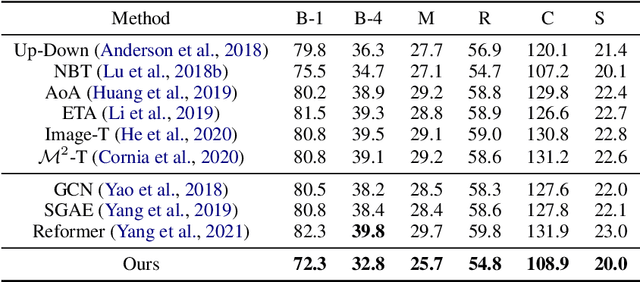
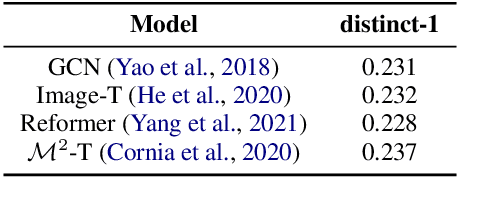
State-of-the-art image captioners can generate accurate sentences to describe images in a sequence to sequence manner without considering the controllability and interpretability. This, however, is far from making image captioning widely used as an image can be interpreted in infinite ways depending on the target and the context at hand. Achieving controllability is important especially when the image captioner is used by different people with different way of interpreting the images. In this paper, we introduce a novel framework for image captioning which can generate diverse descriptions by capturing the co-dependence between Part-Of-Speech tags and semantics. Our model decouples direct dependence between successive variables. In this way, it allows the decoder to exhaustively search through the latent Part-Of-Speech choices, while keeping decoding speed proportional to the size of the POS vocabulary. Given a control signal in the form of a sequence of Part-Of-Speech tags, we propose a method to generate captions through a Transformer network, which predicts words based on the input Part-Of-Speech tag sequences. Experiments on publicly available datasets show that our model significantly outperforms state-of-the-art methods on generating diverse image captions with high qualities.
Scaling sparsemax based channel selection for speech recognition with ad-hoc microphone arrays
Apr 01, 2021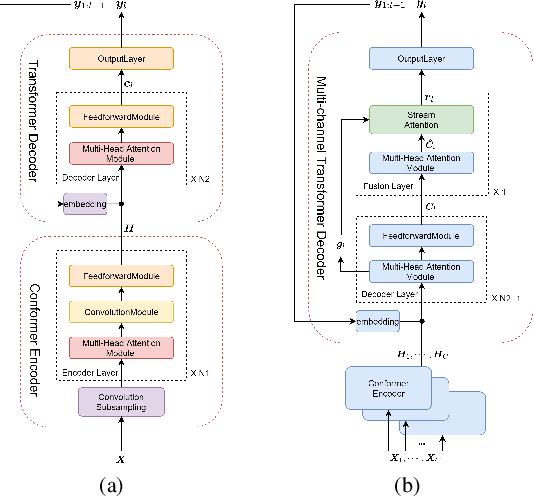
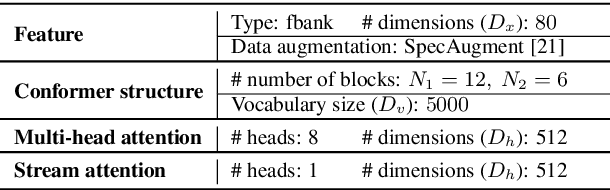
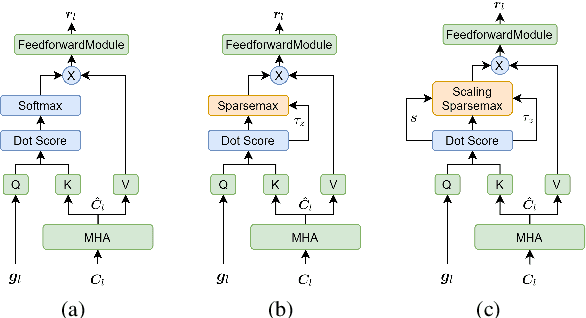
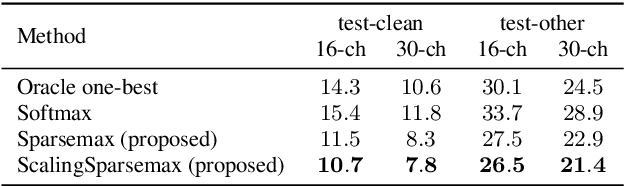
Recently, speech recognition with ad-hoc microphone arrays has received much attention. It is known that channel selection is an important problem of ad-hoc microphone arrays, however, this topic seems far from explored in speech recognition yet, particularly with a large-scale ad-hoc microphone array. To address this problem, we propose a Scaling Sparsemax algorithm for the channel selection problem of the speech recognition with large-scale ad-hoc microphone arrays. Specifically, we first replace the conventional Softmax operator in the stream attention mechanism of a multichannel end-to-end speech recognition system with Sparsemax, which conducts channel selection by forcing the channel weights of noisy channels to zero. Because Sparsemax punishes the weights of many channels to zero harshly, we propose Scaling Sparsemax which punishes the channels mildly by setting the weights of very noisy channels to zero only. Experimental results with ad-hoc microphone arrays of over 30 channels under the conformer speech recognition architecture show that the proposed Scaling Sparsemax yields a word error rate of over 30% lower than Softmax on simulation data sets, and over 20% lower on semi-real data sets, in test scenarios with both matched and mismatched channel numbers.
Learning to Collocate Visual-Linguistic Neural Modules for Image Captioning
Oct 04, 2022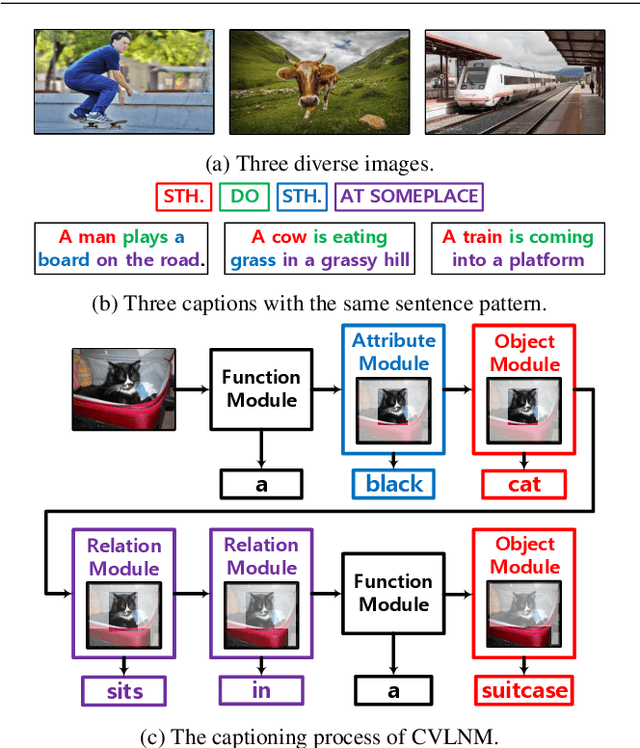


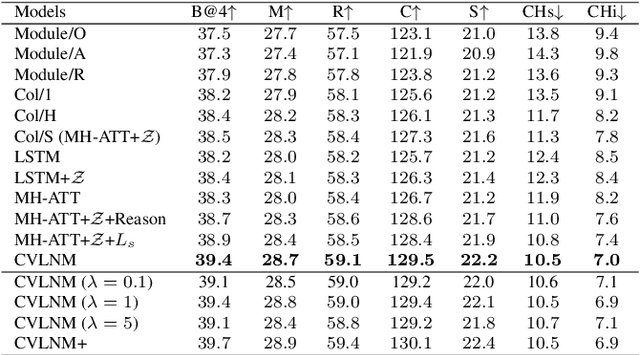
Humans tend to decompose a sentence into different parts like \textsc{sth do sth at someplace} and then fill each part with certain content. Inspired by this, we follow the \textit{principle of modular design} to propose a novel image captioner: learning to Collocate Visual-Linguistic Neural Modules (CVLNM). Unlike the \re{widely used} neural module networks in VQA, where the language (\ie, question) is fully observable, \re{the task of collocating visual-linguistic modules is more challenging.} This is because the language is only partially observable, for which we need to dynamically collocate the modules during the process of image captioning. To sum up, we make the following technical contributions to design and train our CVLNM: 1) \textit{distinguishable module design} -- \re{four modules in the encoder} including one linguistic module for function words and three visual modules for different content words (\ie, noun, adjective, and verb) and another linguistic one in the decoder for commonsense reasoning, 2) a self-attention based \textit{module controller} for robustifying the visual reasoning, 3) a part-of-speech based \textit{syntax loss} imposed on the module controller for further regularizing the training of our CVLNM. Extensive experiments on the MS-COCO dataset show that our CVLNM is more effective, \eg, achieving a new state-of-the-art 129.5 CIDEr-D, and more robust, \eg, being less likely to overfit to dataset bias and suffering less when fewer training samples are available. Codes are available at \url{https://github.com/GCYZSL/CVLMN}