 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Synthetic Dataset Generation for Privacy-Preserving Machine Learning
Oct 10, 2022
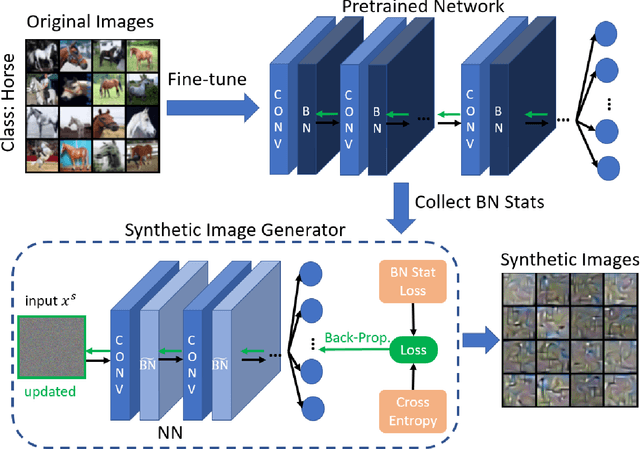



Machine Learning (ML) has achieved enormous success in solving a variety of problems in computer vision, speech recognition, object detection, to name a few. The principal reason for this success is the availability of huge datasets for training deep neural networks (DNNs). However, datasets cannot be publicly released if they contain sensitive information such as medical records, and data privacy becomes a major concern. Encryption methods could be a possible solution, however their deployment on ML applications seriously impacts classification accuracy and results in substantial computational overhead. Alternatively, obfuscation techniques could be used, but maintaining a good trade-off between visual privacy and accuracy is challenging. In this paper, we propose a method to generate secure synthetic datasets from the original private datasets. Given a network with Batch Normalization (BN) layers pretrained on the original dataset, we first record the class-wise BN layer statistics. Next, we generate the synthetic dataset by optimizing random noise such that the synthetic data match the layer-wise statistical distribution of original images. We evaluate our method on image classification datasets (CIFAR10, ImageNet) and show that synthetic data can be used in place of the original CIFAR10/ImageNet data for training networks from scratch, producing comparable classification performance. Further, to analyze visual privacy provided by our method, we use Image Quality Metrics and show high degree of visual dissimilarity between the original and synthetic images. Moreover, we show that our proposed method preserves data-privacy under various privacy-leakage attacks including Gradient Matching Attack, Model Memorization Attack, and GAN-based Attack.
A Neural Acoustic Echo Canceller Optimized Using An Automatic Speech Recognizer And Large Scale Synthetic Data
Jun 01, 2021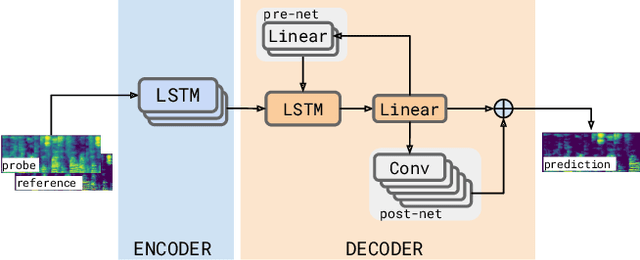
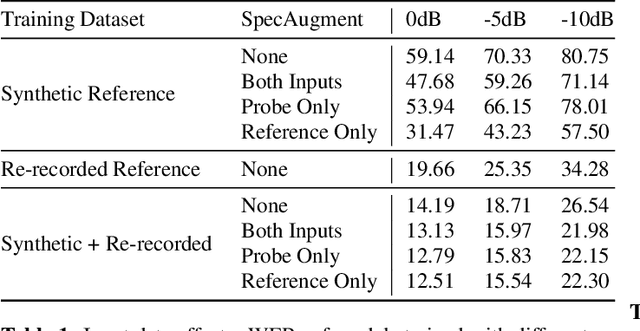
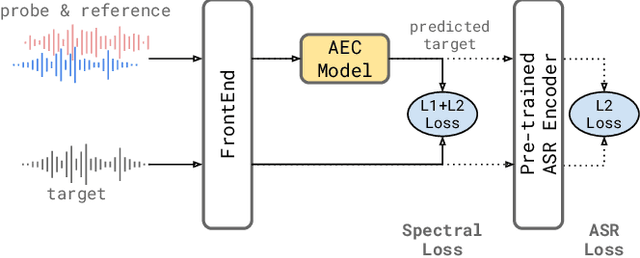
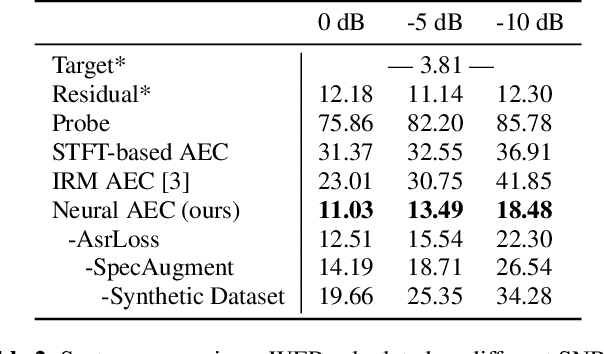
We consider the problem of recognizing speech utterances spoken to a device which is generating a known sound waveform; for example, recognizing queries issued to a digital assistant which is generating responses to previous user inputs. Previous work has proposed building acoustic echo cancellation (AEC) models for this task that optimize speech enhancement metrics using both neural network as well as signal processing approaches. Since our goal is to recognize the input speech, we consider enhancements which improve word error rates (WERs) when the predicted speech signal is passed to an automatic speech recognition (ASR) model. First, we augment the loss function with a term that produces outputs useful to a pre-trained ASR model and show that this augmented loss function improves WER metrics. Second, we demonstrate that augmenting our training dataset of real world examples with a large synthetic dataset improves performance. Crucially, applying SpecAugment style masks to the reference channel during training aids the model in adapting from synthetic to real domains. In experimental evaluations, we find the proposed approaches improve performance, on average, by 57% over a signal processing baseline and 45% over the neural AEC model without the proposed changes.
Phonetic Feedback for Speech Enhancement With and Without Parallel Speech Data
Mar 03, 2020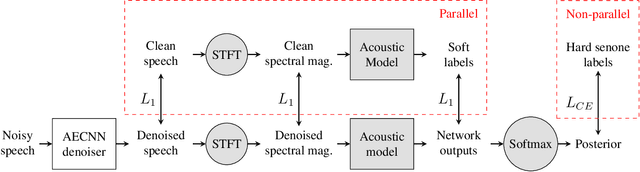
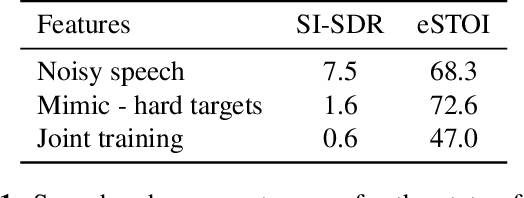
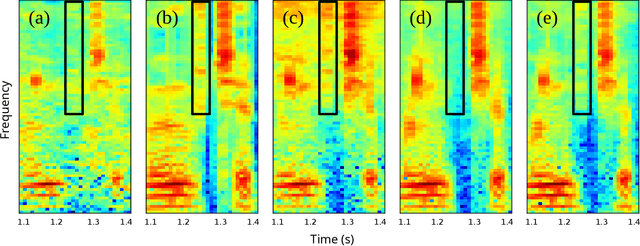
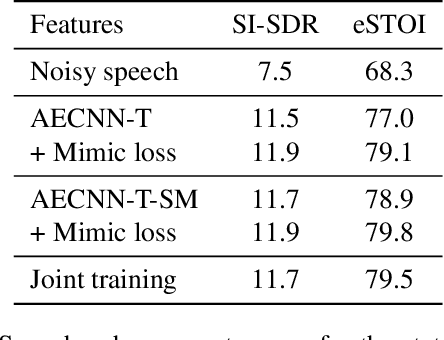
While deep learning systems have gained significant ground in speech enhancement research, these systems have yet to make use of the full potential of deep learning systems to provide high-level feedback. In particular, phonetic feedback is rare in speech enhancement research even though it includes valuable top-down information. We use the technique of mimic loss to provide phonetic feedback to an off-the-shelf enhancement system, and find gains in objective intelligibility scores on CHiME-4 data. This technique takes a frozen acoustic model trained on clean speech to provide valuable feedback to the enhancement model, even in the case where no parallel speech data is available. Our work is one of the first to show intelligibility improvement for neural enhancement systems without parallel speech data, and we show phonetic feedback can improve a state-of-the-art neural enhancement system trained with parallel speech data.
Streaming end-to-end speech recognition with jointly trained neural feature enhancement
May 04, 2021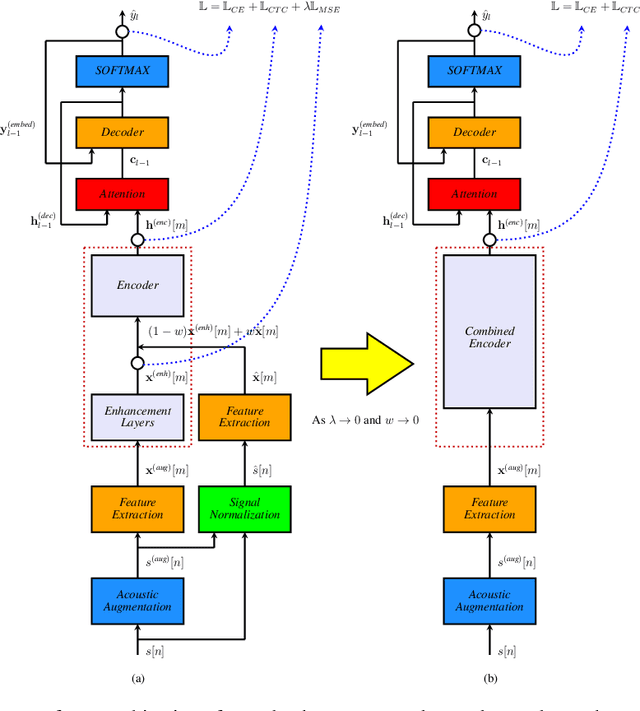
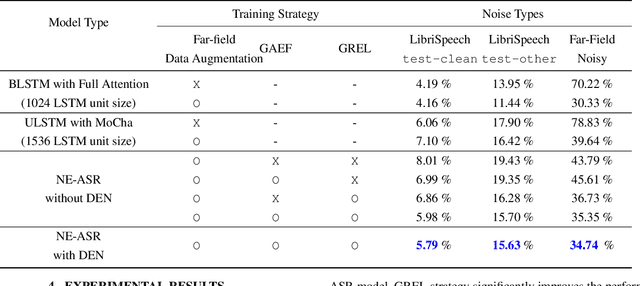
In this paper, we present a streaming end-to-end speech recognition model based on Monotonic Chunkwise Attention (MoCha) jointly trained with enhancement layers. Even though the MoCha attention enables streaming speech recognition with recognition accuracy comparable to a full attention-based approach, training this model is sensitive to various factors such as the difficulty of training examples, hyper-parameters, and so on. Because of these issues, speech recognition accuracy of a MoCha-based model for clean speech drops significantly when a multi-style training approach is applied. Inspired by Curriculum Learning [1], we introduce two training strategies: Gradual Application of Enhanced Features (GAEF) and Gradual Reduction of Enhanced Loss (GREL). With GAEF, the model is initially trained using clean features. Subsequently, the portion of outputs from the enhancement layers gradually increases. With GREL, the portion of the Mean Squared Error (MSE) loss for the enhanced output gradually reduces as training proceeds. In experimental results on the LibriSpeech corpus and noisy far-field test sets, the proposed model with GAEF-GREL training strategies shows significantly better results than the conventional multi-style training approach.
A Study on the Manifestation of Trust in Speech
Feb 09, 2021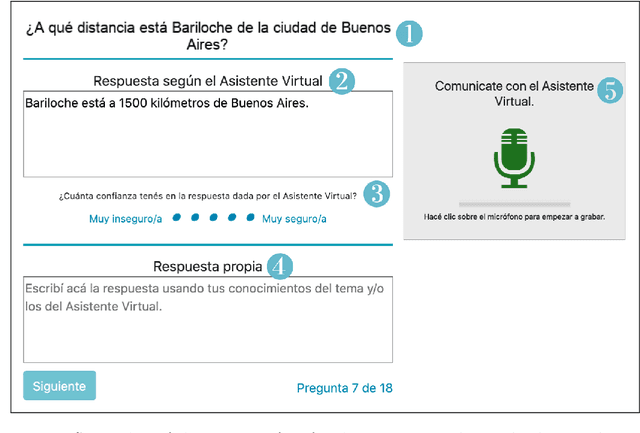
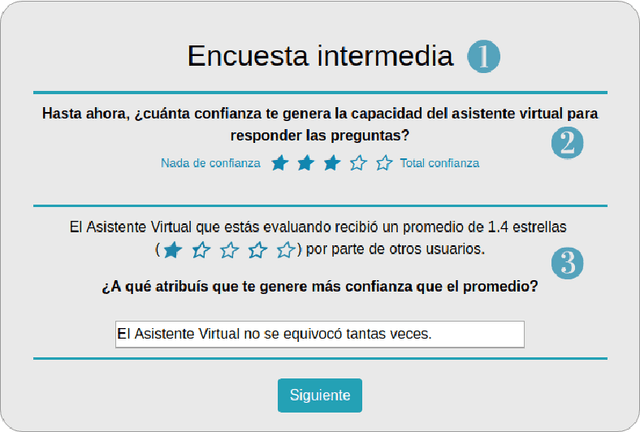
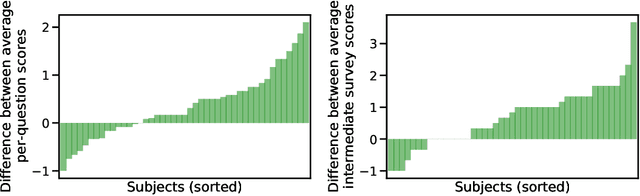
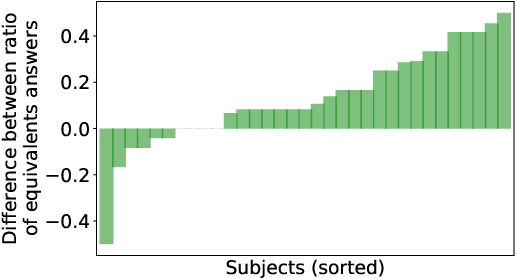
Research has shown that trust is an essential aspect of human-computer interaction directly determining the degree to which the person is willing to use a system. An automatic prediction of the level of trust that a user has on a certain system could be used to attempt to correct potential distrust by having the system take relevant actions like, for example, apologizing or explaining its decisions. In this work, we explore the feasibility of automatically detecting the level of trust that a user has on a virtual assistant (VA) based on their speech. We developed a novel protocol for collecting speech data from subjects induced to have different degrees of trust in the skills of a VA. The protocol consists of an interactive session where the subject is asked to respond to a series of factual questions with the help of a virtual assistant. In order to induce subjects to either trust or distrust the VA's skills, they are first informed that the VA was previously rated by other users as being either good or bad; subsequently, the VA answers the subjects' questions consistently to its alleged abilities. All interactions are speech-based, with subjects and VAs communicating verbally, which allows the recording of speech produced under different trust conditions. Using this protocol, we collected a speech corpus in Argentine Spanish. We show clear evidence that the protocol effectively succeeded in influencing subjects into the desired mental state of either trusting or distrusting the agent's skills, and present results of a perceptual study of the degree of trust performed by expert listeners. Finally, we found that the subject's speech can be used to detect which type of VA they were using, which could be considered a proxy for the user's trust toward the VA's abilities, with an accuracy up to 76%, compared to a random baseline of 50%.
Teacher-Student MixIT for Unsupervised and Semi-supervised Speech Separation
Jun 16, 2021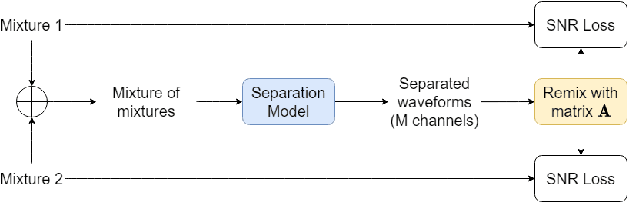
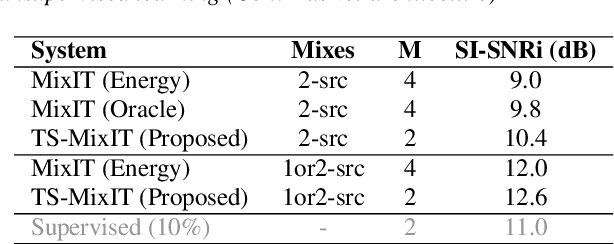
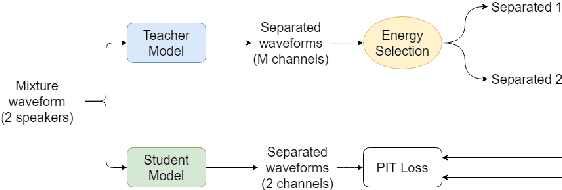
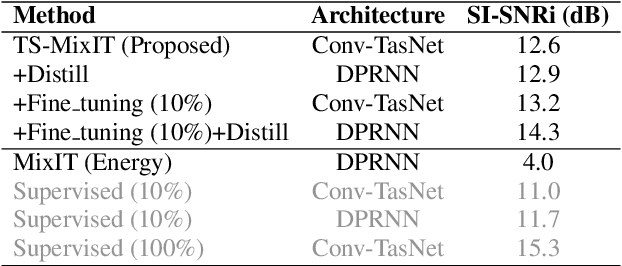
In this paper, we introduce a novel semi-supervised learning framework for end-to-end speech separation. The proposed method first uses mixtures of unseparated sources and the mixture invariant training (MixIT) criterion to train a teacher model. The teacher model then estimates separated sources that are used to train a student model with standard permutation invariant training (PIT). The student model can be fine-tuned with supervised data, i.e., paired artificial mixtures and clean speech sources, and further improved via model distillation. Experiments with single and multi channel mixtures show that the teacher-student training resolves the over-separation problem observed in the original MixIT method. Further, the semisupervised performance is comparable to a fully-supervised separation system trained using ten times the amount of supervised data.
Using Radio Archives for Low-Resource Speech Recognition: Towards an Intelligent Virtual Assistant for Illiterate Users
Apr 27, 2021

For many of the 700 million illiterate people around the world, speech recognition technology could provide a bridge to valuable information and services. Yet, those most in need of this technology are often the most underserved by it. In many countries, illiterate people tend to speak only low-resource languages, for which the datasets necessary for speech technology development are scarce. In this paper, we investigate the effectiveness of unsupervised speech representation learning on noisy radio broadcasting archives, which are abundant even in low-resource languages. We make three core contributions. First, we release two datasets to the research community. The first, West African Radio Corpus, contains 142 hours of audio in more than 10 languages with a labeled validation subset. The second, West African Virtual Assistant Speech Recognition Corpus, consists of 10K labeled audio clips in four languages. Next, we share West African wav2vec, a speech encoder trained on the noisy radio corpus, and compare it with the baseline Facebook speech encoder trained on six times more data of higher quality. We show that West African wav2vec performs similarly to the baseline on a multilingual speech recognition task, and significantly outperforms the baseline on a West African language identification task. Finally, we share the first-ever speech recognition models for Maninka, Pular and Susu, languages spoken by a combined 10 million people in over seven countries, including six where the majority of the adult population is illiterate. Our contributions offer a path forward for ethical AI research to serve the needs of those most disadvantaged by the digital divide.
Listening to Sounds of Silence for Speech Denoising
Oct 22, 2020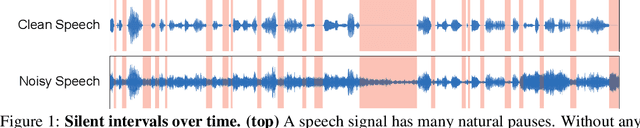
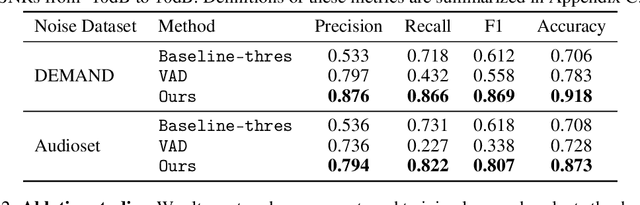
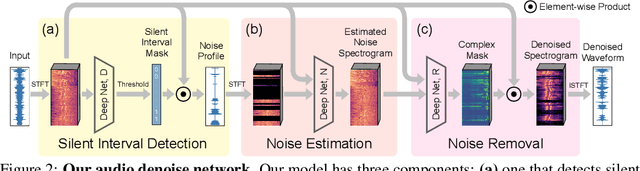
We introduce a deep learning model for speech denoising, a long-standing challenge in audio analysis arising in numerous applications. Our approach is based on a key observation about human speech: there is often a short pause between each sentence or word. In a recorded speech signal, those pauses introduce a series of time periods during which only noise is present. We leverage these incidental silent intervals to learn a model for automatic speech denoising given only mono-channel audio. Detected silent intervals over time expose not just pure noise but its time-varying features, allowing the model to learn noise dynamics and suppress it from the speech signal. Experiments on multiple datasets confirm the pivotal role of silent interval detection for speech denoising, and our method outperforms several state-of-the-art denoising methods, including those that accept only audio input (like ours) and those that denoise based on audiovisual input (and hence require more information). We also show that our method enjoys excellent generalization properties, such as denoising spoken languages not seen during training.
Estimating the confidence of speech spoofing countermeasure
Oct 10, 2021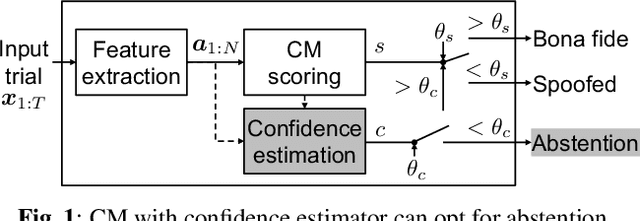

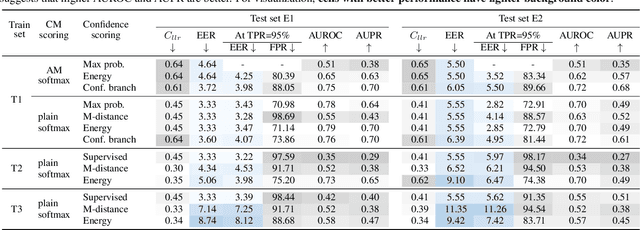
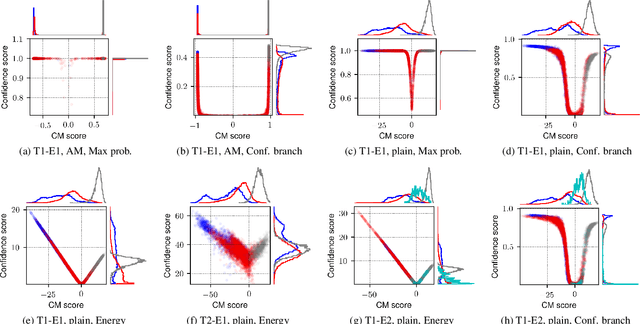
Conventional speech spoofing countermeasures (CMs) are designed to make a binary decision on an input trial. However, a CM trained on a closed-set database is theoretically not guaranteed to perform well on unknown spoofing attacks. In some scenarios, an alternative strategy is to let the CM defer a decision when it is not confident. The question is then how to estimate a CM's confidence regarding an input trial. We investigated a few confidence estimators that can be easily plugged into a CM. On the ASVspoof2019 logical access database, the results demonstrate that an energy-based estimator and a neural-network-based one achieved acceptable performance in identifying unknown attacks in the test set. On a test set with additional unknown attacks and bona fide trials from other databases, the confidence estimators performed moderately well, and the CMs better discriminated bona fide and spoofed trials that had a high confidence score. Additional results also revealed the difficulty in enhancing a confidence estimator by adding unknown attacks to the training set.
Measurement uncertainty and unicity of single number quantities describing the spatial decay of speech level in open-plan offices
Apr 25, 2022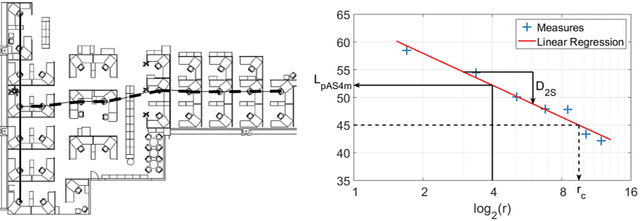
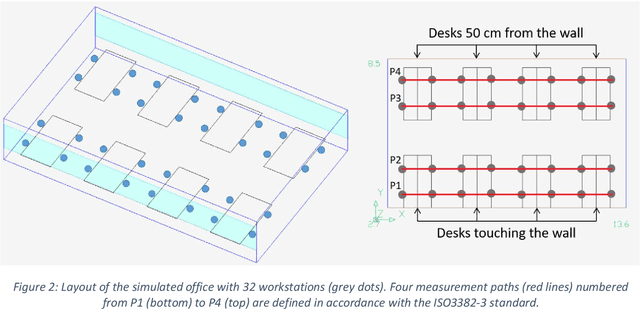
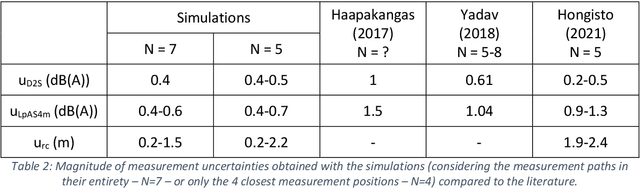
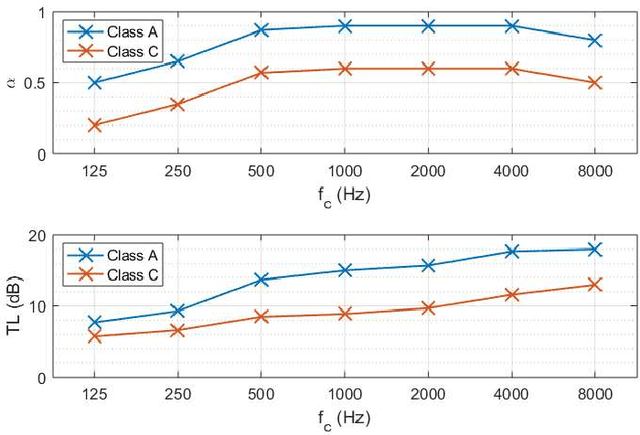
The ISO 3382-3 standard (2012) defines single number quantities (SNQs) which evaluate the acoustic quality of open-plan offices, but does not address the issue of measurement uncertainties. This study focusses on the SNQs present in this standard related to spatial decay of speech, i.e. D 2S , L pAS4m and r c. The aim is to provide additional information to the limited literature on the measurement uncertainties of these SNQs by use of both analytical developments and a stochastic approach based on simulations. The accuracy of the analytical developments was studied thanks to simulations of the sound propagation within a series of offices (1 layout, 16 acoustic configurations with different screen heights and different acoustic qualities of screens and ceiling). The SNQs obtained in the simulations cover a wide range: D 2S between 3.4 and 7.5 dB(A), L pAS4m between 40.6 and 51.9 dB(A) and r c between 2.5 and 14.7 m. Therefore, the simulations are representative of a broad set of acoustic qualities. Estimated uncertainties have a magnitude of 0.4 dB(A) for D 2S and vary between 0.4 and 0.7 dB(A) for L pAS4m and between 0.2 and 1.5 m for r c over a measurement path comprising 7 measurement positions. The simulations also raise the question of describing the acoustic quality of an office using a single value for the indicators. The results of the simulations show that in some cases, D 2S values significantly depend on the measurement path, leading to a strong increase of its measurement uncertainty if a unique value is to be considered.