 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Advancing an Interdisciplinary Science of Conversation: Insights from a Large Multimodal Corpus of Human Speech
Mar 01, 2022
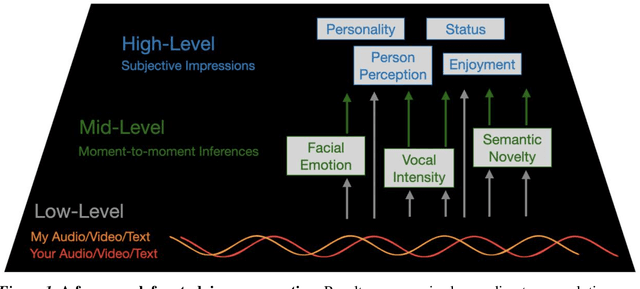
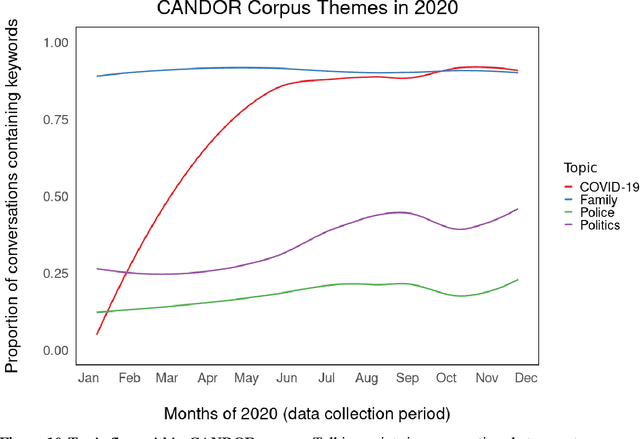

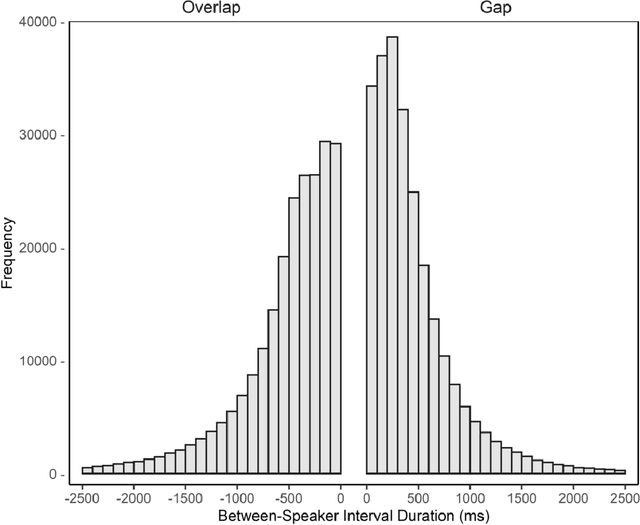
People spend a substantial portion of their lives engaged in conversation, and yet our scientific understanding of conversation is still in its infancy. In this report we advance an interdisciplinary science of conversation, with findings from a large, novel, multimodal corpus of 1,656 recorded conversations in spoken English. This 7+ million word, 850 hour corpus totals over 1TB of audio, video, and transcripts, with moment-to-moment measures of vocal, facial, and semantic expression, along with an extensive survey of speaker post conversation reflections. We leverage the considerable scope of the corpus to (1) extend key findings from the literature, such as the cooperativeness of human turn-taking; (2) define novel algorithmic procedures for the segmentation of speech into conversational turns; (3) apply machine learning insights across various textual, auditory, and visual features to analyze what makes conversations succeed or fail; and (4) explore how conversations are related to well-being across the lifespan. We also report (5) a comprehensive mixed-method report, based on quantitative analysis and qualitative review of each recording, that showcases how individuals from diverse backgrounds alter their communication patterns and find ways to connect. We conclude with a discussion of how this large-scale public dataset may offer new directions for future research, especially across disciplinary boundaries, as scholars from a variety of fields appear increasingly interested in the study of conversation.
Effective and Differentiated Use of Control Information for Multi-speaker Speech Synthesis
Jul 08, 2021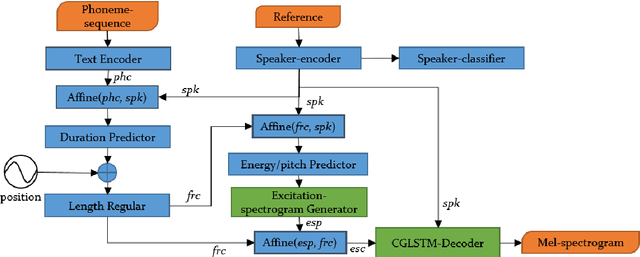

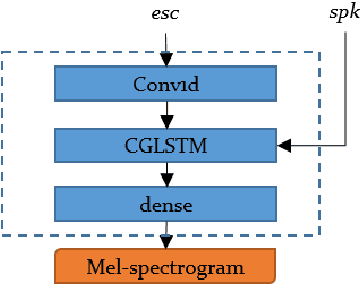
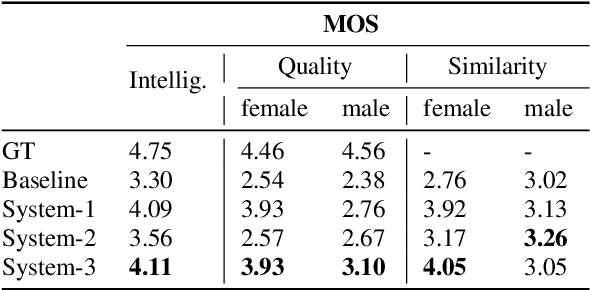
In multi-speaker speech synthesis, data from a number of speakers usually tends to have great diversity due to the fact that the speakers may differ largely in their ages, speaking styles, speeds, emotions, and so on. The diversity of data will lead to the one-to-many mapping problem \cite{Ren2020FastSpeech2F, Kumar2020FewSA}. It is important but challenging to improve the modeling capabilities for multi-speaker speech synthesis. To address the issue, this paper researches into the effective use of control information such as speaker and pitch which are differentiated from text-content information in our encoder-decoder framework: 1) Design a representation of harmonic structure of speech, called excitation spectrogram, from pitch and energy. The excitation spectrogrom is, along with the text-content, fed to the decoder to guide the learning of harmonics of mel-spectrogram. 2) Propose conditional gated LSTM (CGLSTM) whose input/output/forget gates are re-weighted by speaker embedding to control the flow of text-content information in the network. The experiments show significant reduction in reconstruction errors of mel-spectrogram in the training of multi-speaker generative model, and a great improvement is observed in the subjective evaluation of speaker adapted model, e.g, the Mean Opinion Score (MOS) of intelligibility increases by 0.81 points.
Learning to Collocate Visual-Linguistic Neural Modules for Image Captioning
Oct 04, 2022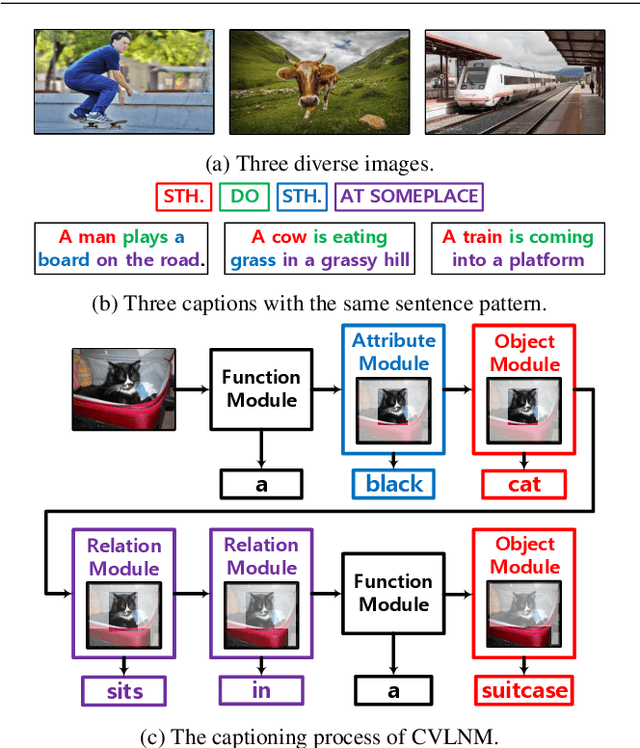


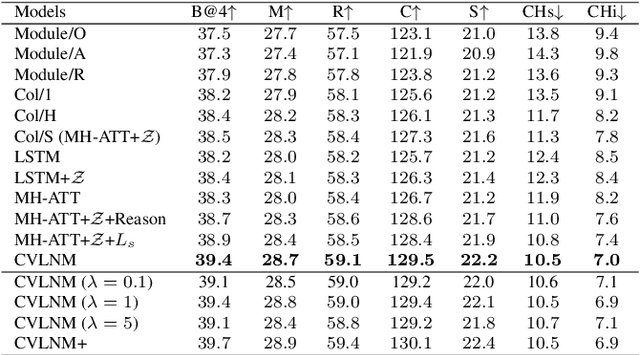
Humans tend to decompose a sentence into different parts like \textsc{sth do sth at someplace} and then fill each part with certain content. Inspired by this, we follow the \textit{principle of modular design} to propose a novel image captioner: learning to Collocate Visual-Linguistic Neural Modules (CVLNM). Unlike the \re{widely used} neural module networks in VQA, where the language (\ie, question) is fully observable, \re{the task of collocating visual-linguistic modules is more challenging.} This is because the language is only partially observable, for which we need to dynamically collocate the modules during the process of image captioning. To sum up, we make the following technical contributions to design and train our CVLNM: 1) \textit{distinguishable module design} -- \re{four modules in the encoder} including one linguistic module for function words and three visual modules for different content words (\ie, noun, adjective, and verb) and another linguistic one in the decoder for commonsense reasoning, 2) a self-attention based \textit{module controller} for robustifying the visual reasoning, 3) a part-of-speech based \textit{syntax loss} imposed on the module controller for further regularizing the training of our CVLNM. Extensive experiments on the MS-COCO dataset show that our CVLNM is more effective, \eg, achieving a new state-of-the-art 129.5 CIDEr-D, and more robust, \eg, being less likely to overfit to dataset bias and suffering less when fewer training samples are available. Codes are available at \url{https://github.com/GCYZSL/CVLMN}
KSoF: The Kassel State of Fluency Dataset -- A Therapy Centered Dataset of Stuttering
Mar 10, 2022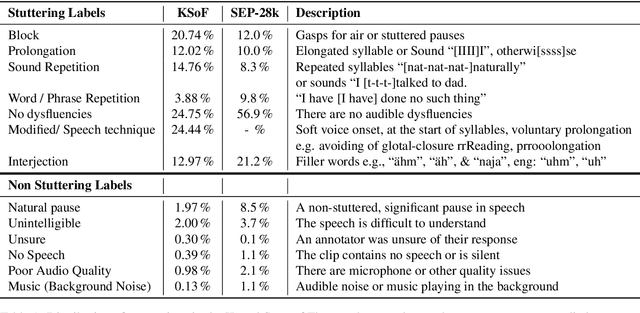
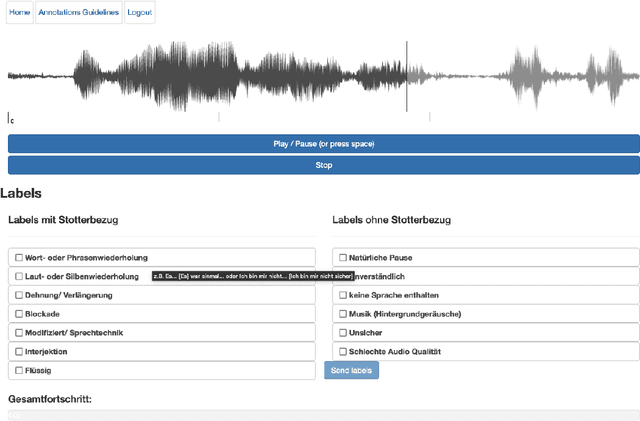
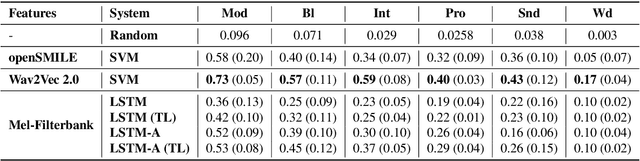
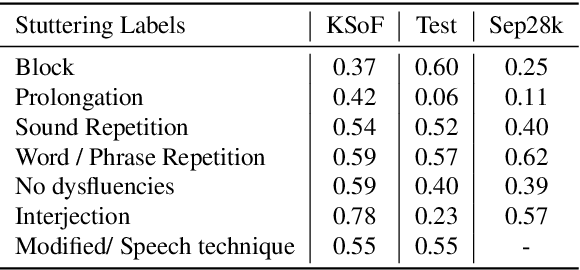
Stuttering is a complex speech disorder that negatively affects an individual's ability to communicate effectively. Persons who stutter (PWS) often suffer considerably under the condition and seek help through therapy. Fluency shaping is a therapy approach where PWSs learn to modify their speech to help them to overcome their stutter. Mastering such speech techniques takes time and practice, even after therapy. Shortly after therapy, success is evaluated highly, but relapse rates are high. To be able to monitor speech behavior over a long time, the ability to detect stuttering events and modifications in speech could help PWSs and speech pathologists to track the level of fluency. Monitoring could create the ability to intervene early by detecting lapses in fluency. To the best of our knowledge, no public dataset is available that contains speech from people who underwent stuttering therapy that changed the style of speaking. This work introduces the Kassel State of Fluency (KSoF), a therapy-based dataset containing over 5500 clips of PWSs. The clips were labeled with six stuttering-related event types: blocks, prolongations, sound repetitions, word repetitions, interjections, and - specific to therapy - speech modifications. The audio was recorded during therapy sessions at the Institut der Kasseler Stottertherapie. The data will be made available for research purposes upon request.
Cross-stitched Multi-modal Encoders
Apr 20, 2022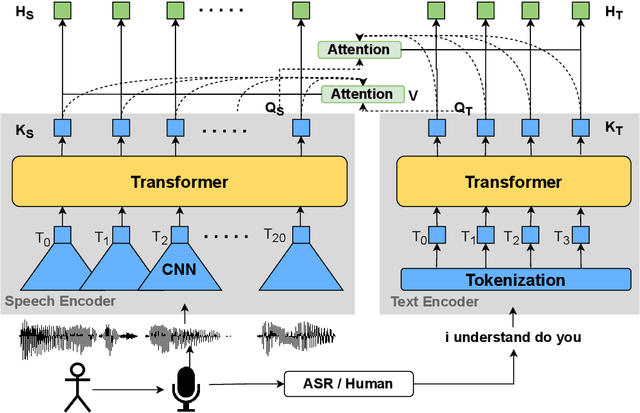
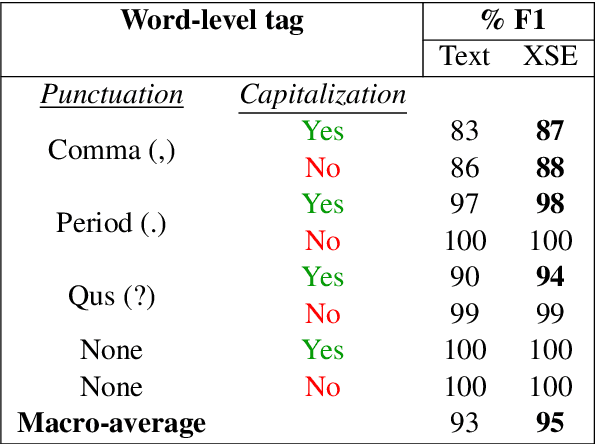
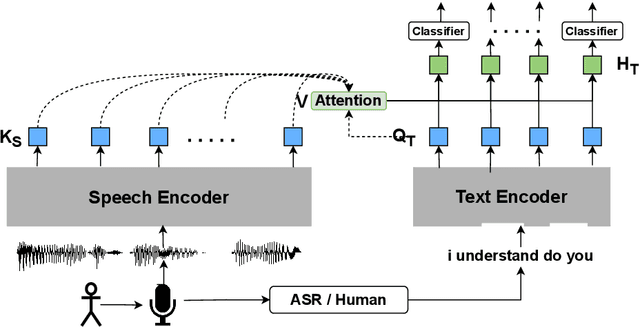
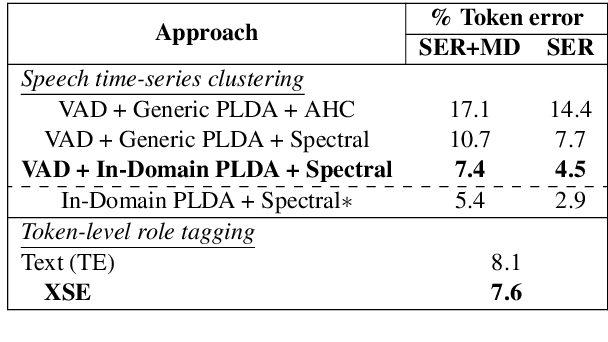
In this paper, we propose a novel architecture for multi-modal speech and text input. We combine pretrained speech and text encoders using multi-headed cross-modal attention and jointly fine-tune on the target problem. The resultant architecture can be used for continuous token-level classification or utterance-level prediction acting on simultaneous text and speech. The resultant encoder efficiently captures both acoustic-prosodic and lexical information. We compare the benefits of multi-headed attention-based fusion for multi-modal utterance-level classification against a simple concatenation of pre-pooled, modality-specific representations. Our model architecture is compact, resource efficient, and can be trained on a single consumer GPU card.
Using Radio Archives for Low-Resource Speech Recognition: Towards an Intelligent Virtual Assistant for Illiterate Users
Apr 27, 2021

For many of the 700 million illiterate people around the world, speech recognition technology could provide a bridge to valuable information and services. Yet, those most in need of this technology are often the most underserved by it. In many countries, illiterate people tend to speak only low-resource languages, for which the datasets necessary for speech technology development are scarce. In this paper, we investigate the effectiveness of unsupervised speech representation learning on noisy radio broadcasting archives, which are abundant even in low-resource languages. We make three core contributions. First, we release two datasets to the research community. The first, West African Radio Corpus, contains 142 hours of audio in more than 10 languages with a labeled validation subset. The second, West African Virtual Assistant Speech Recognition Corpus, consists of 10K labeled audio clips in four languages. Next, we share West African wav2vec, a speech encoder trained on the noisy radio corpus, and compare it with the baseline Facebook speech encoder trained on six times more data of higher quality. We show that West African wav2vec performs similarly to the baseline on a multilingual speech recognition task, and significantly outperforms the baseline on a West African language identification task. Finally, we share the first-ever speech recognition models for Maninka, Pular and Susu, languages spoken by a combined 10 million people in over seven countries, including six where the majority of the adult population is illiterate. Our contributions offer a path forward for ethical AI research to serve the needs of those most disadvantaged by the digital divide.
Domain-aware Self-supervised Pre-training for Label-Efficient Meme Analysis
Sep 29, 2022

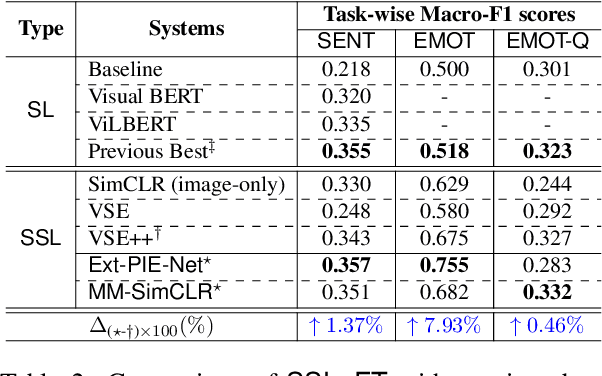
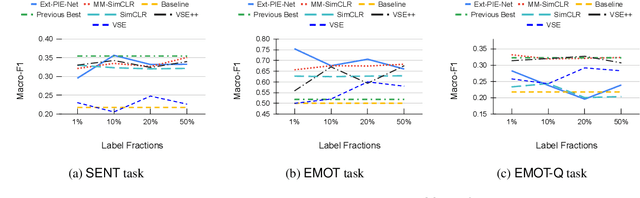
Existing self-supervised learning strategies are constrained to either a limited set of objectives or generic downstream tasks that predominantly target uni-modal applications. This has isolated progress for imperative multi-modal applications that are diverse in terms of complexity and domain-affinity, such as meme analysis. Here, we introduce two self-supervised pre-training methods, namely Ext-PIE-Net and MM-SimCLR that (i) employ off-the-shelf multi-modal hate-speech data during pre-training and (ii) perform self-supervised learning by incorporating multiple specialized pretext tasks, effectively catering to the required complex multi-modal representation learning for meme analysis. We experiment with different self-supervision strategies, including potential variants that could help learn rich cross-modality representations and evaluate using popular linear probing on the Hateful Memes task. The proposed solutions strongly compete with the fully supervised baseline via label-efficient training while distinctly outperforming them on all three tasks of the Memotion challenge with 0.18%, 23.64%, and 0.93% performance gain, respectively. Further, we demonstrate the generalizability of the proposed solutions by reporting competitive performance on the HarMeme task. Finally, we empirically establish the quality of the learned representations by analyzing task-specific learning, using fewer labeled training samples, and arguing that the complexity of the self-supervision strategy and downstream task at hand are correlated. Our efforts highlight the requirement of better multi-modal self-supervision methods involving specialized pretext tasks for efficient fine-tuning and generalizable performance.
Acoustic-Linguistic Features for Modeling Neurological Task Score in Alzheimer's
Sep 13, 2022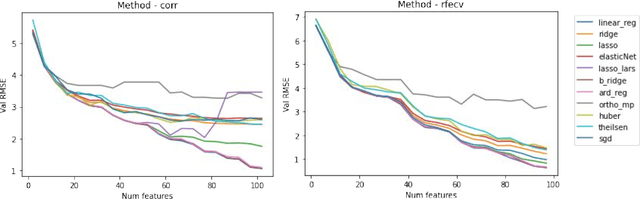
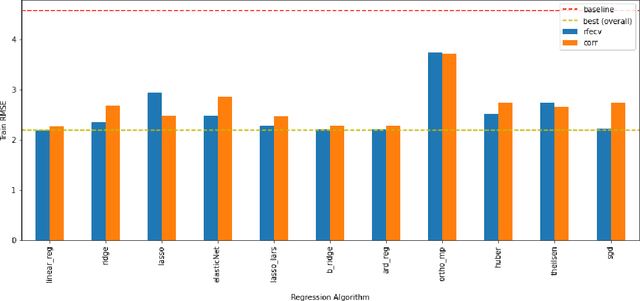
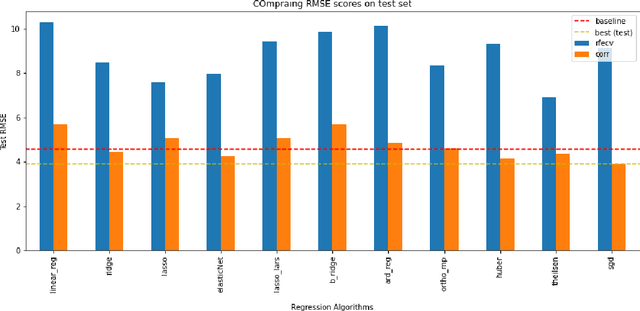
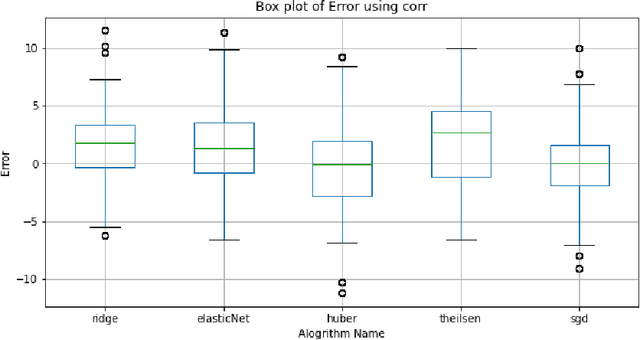
The average life expectancy is increasing globally due to advancements in medical technology, preventive health care, and a growing emphasis on gerontological health. Therefore, developing technologies that detect and track aging-associated disease in cognitive function among older adult populations is imperative. In particular, research related to automatic detection and evaluation of Alzheimer's disease (AD) is critical given the disease's prevalence and the cost of current methods. As AD impacts the acoustics of speech and vocabulary, natural language processing and machine learning provide promising techniques for reliably detecting AD. We compare and contrast the performance of ten linear regression models for predicting Mini-Mental Status Exam scores on the ADReSS challenge dataset. We extracted 13000+ handcrafted and learned features that capture linguistic and acoustic phenomena. Using a subset of 54 top features selected by two methods: (1) recursive elimination and (2) correlation scores, we outperform a state-of-the-art baseline for the same task. Upon scoring and evaluating the statistical significance of each of the selected subset of features for each model, we find that, for the given task, handcrafted linguistic features are more significant than acoustic and learned features.
Speech Recognition with no speech or with noisy speech
Mar 02, 2019
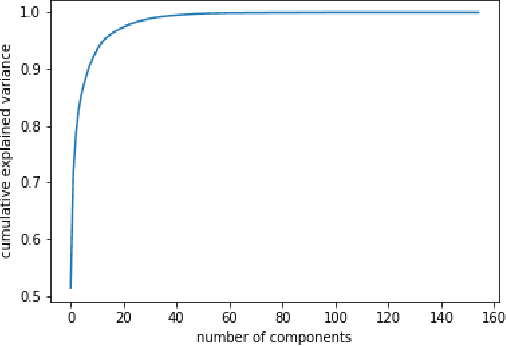
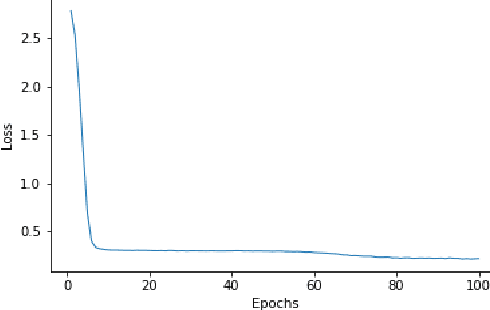
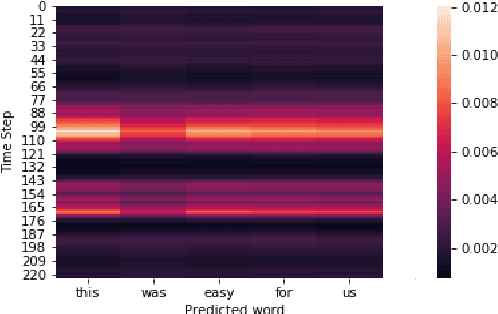
The performance of automatic speech recognition systems(ASR) degrades in the presence of noisy speech. This paper demonstrates that using electroencephalography (EEG) can help automatic speech recognition systems overcome performance loss in the presence of noise. The paper also shows that distillation training of automatic speech recognition systems using EEG features will increase their performance. Finally, we demonstrate the ability to recognize words from EEG with no speech signal on a limited English vocabulary with high accuracy.
Two-Pass Low Latency End-to-End Spoken Language Understanding
Jul 14, 2022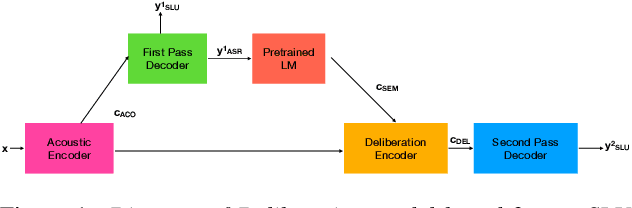
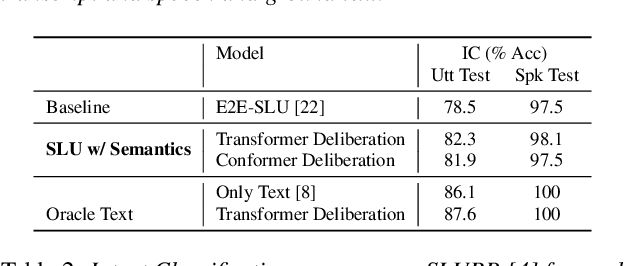

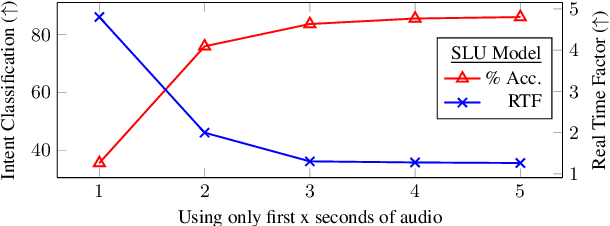
End-to-end (E2E) models are becoming increasingly popular for spoken language understanding (SLU) systems and are beginning to achieve competitive performance to pipeline-based approaches. However, recent work has shown that these models struggle to generalize to new phrasings for the same intent indicating that models cannot understand the semantic content of the given utterance. In this work, we incorporated language models pre-trained on unlabeled text data inside E2E-SLU frameworks to build strong semantic representations. Incorporating both semantic and acoustic information can increase the inference time, leading to high latency when deployed for applications like voice assistants. We developed a 2-pass SLU system that makes low latency prediction using acoustic information from the few seconds of the audio in the first pass and makes higher quality prediction in the second pass by combining semantic and acoustic representations. We take inspiration from prior work on 2-pass end-to-end speech recognition systems that attends on both audio and first-pass hypothesis using a deliberation network. The proposed 2-pass SLU system outperforms the acoustic-based SLU model on the Fluent Speech Commands Challenge Set and SLURP dataset and reduces latency, thus improving user experience. Our code and models are publicly available as part of the ESPnet-SLU toolkit.