 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Self-move and Other-move: Quantum Categorical Foundations of Japanese
Oct 10, 2022


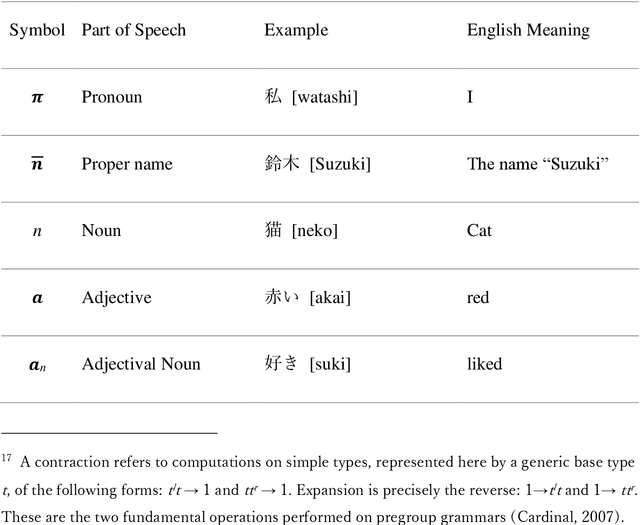

The purpose of this work is to contribute toward the larger goal of creating a Quantum Natural Language Processing (QNLP) translator program. This work contributes original diagrammatic representations of the Japanese language based on prior work that accomplished on the English language based on category theory. The germane differences between the English and Japanese languages are emphasized to help address English language bias in the current body of research. Additionally, topological principles of these diagrams and many potential avenues for further research are proposed. Why is this endeavor important? Hundreds of languages have developed over the course of millennia coinciding with the evolution of human interaction across time and geographic location. These languages are foundational to human survival, experience, flourishing, and living the good life. They are also, however, the strongest barrier between people groups. Over the last several decades, advancements in Natural Language Processing (NLP) have made it easier to bridge the gap between individuals who do not share a common language or culture. Tools like Google Translate and DeepL make it easier than ever before to share our experiences with people globally. Nevertheless, these tools are still inadequate as they fail to convey our ideas across the language barrier fluently, leaving people feeling anxious and embarrassed. This is particularly true of languages born out of substantially different cultures, such as English and Japanese. Quantum computers offer the best chance to achieve translation fluency in that they are better suited to simulating the natural world and natural phenomenon such as natural speech. Keywords: category theory, DisCoCat, DisCoCirc, Japanese grammar, English grammar, translation, topology, Quantum Natural Language Processing, Natural Language Processing
Estimating the confidence of speech spoofing countermeasure
Oct 10, 2021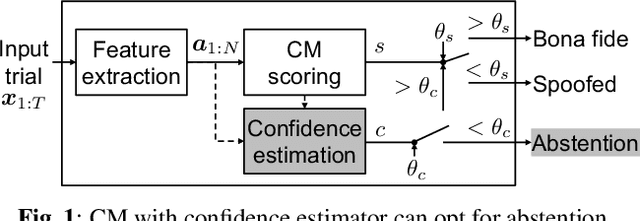

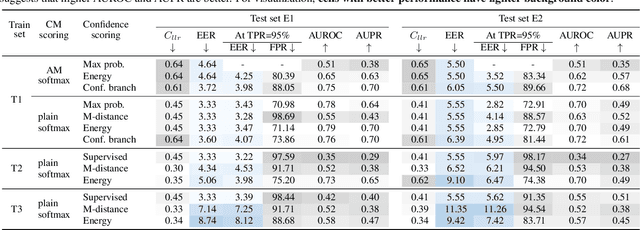
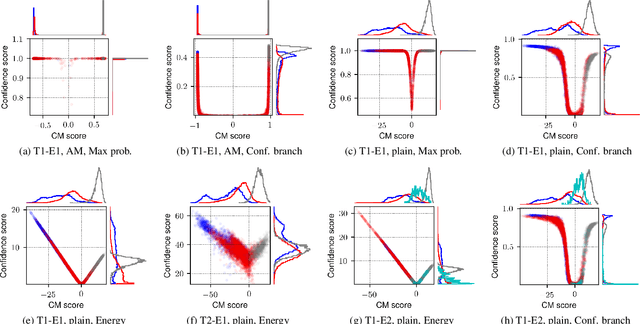
Conventional speech spoofing countermeasures (CMs) are designed to make a binary decision on an input trial. However, a CM trained on a closed-set database is theoretically not guaranteed to perform well on unknown spoofing attacks. In some scenarios, an alternative strategy is to let the CM defer a decision when it is not confident. The question is then how to estimate a CM's confidence regarding an input trial. We investigated a few confidence estimators that can be easily plugged into a CM. On the ASVspoof2019 logical access database, the results demonstrate that an energy-based estimator and a neural-network-based one achieved acceptable performance in identifying unknown attacks in the test set. On a test set with additional unknown attacks and bona fide trials from other databases, the confidence estimators performed moderately well, and the CMs better discriminated bona fide and spoofed trials that had a high confidence score. Additional results also revealed the difficulty in enhancing a confidence estimator by adding unknown attacks to the training set.
Model architectures to extrapolate emotional expressions in DNN-based text-to-speech
Feb 20, 2021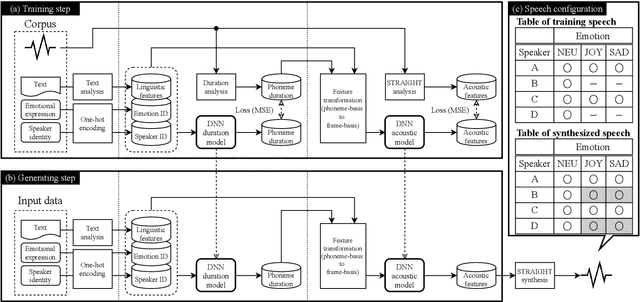
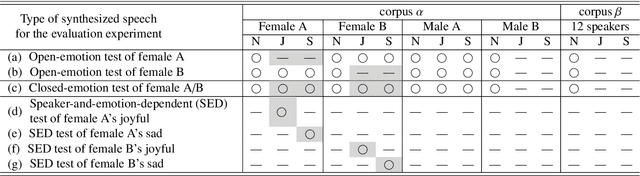
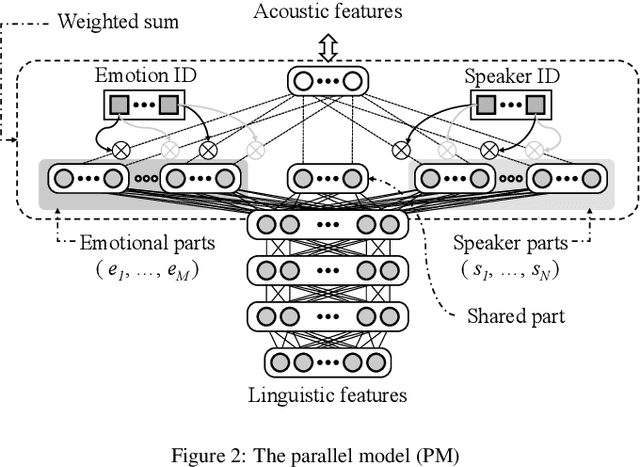

This paper proposes architectures that facilitate the extrapolation of emotional expressions in deep neural network (DNN)-based text-to-speech (TTS). In this study, the meaning of "extrapolate emotional expressions" is to borrow emotional expressions from others, and the collection of emotional speech uttered by target speakers is unnecessary. Although a DNN has potential power to construct DNN-based TTS with emotional expressions and some DNN-based TTS systems have demonstrated satisfactory performances in the expression of the diversity of human speech, it is necessary and troublesome to collect emotional speech uttered by target speakers. To solve this issue, we propose architectures to separately train the speaker feature and the emotional feature and to synthesize speech with any combined quality of speakers and emotions. The architectures are parallel model (PM), serial model (SM), auxiliary input model (AIM), and hybrid models (PM&AIM and SM&AIM). These models are trained through emotional speech uttered by few speakers and neutral speech uttered by many speakers. Objective evaluations demonstrate that the performances in the open-emotion test provide insufficient information. They make a comparison with those in the closed-emotion test, but each speaker has their own manner of expressing emotion. However, subjective evaluation results indicate that the proposed models could convey emotional information to some extent. Notably, the PM can correctly convey sad and joyful emotions at a rate of >60%.
A Neural Acoustic Echo Canceller Optimized Using An Automatic Speech Recognizer And Large Scale Synthetic Data
Jun 01, 2021
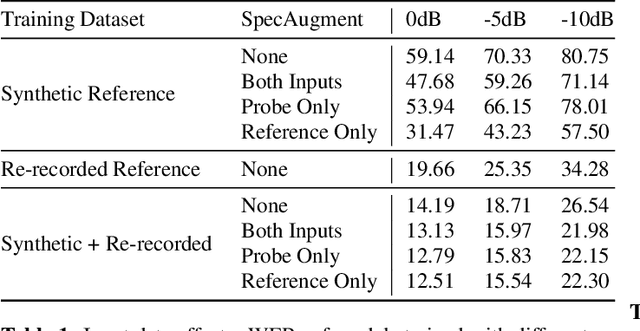
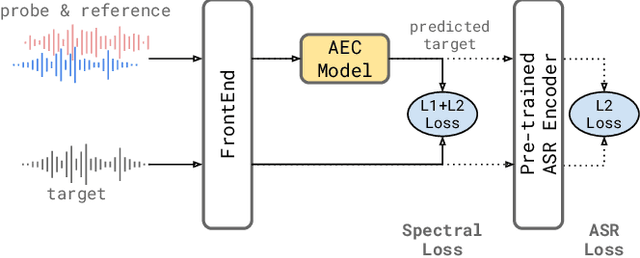
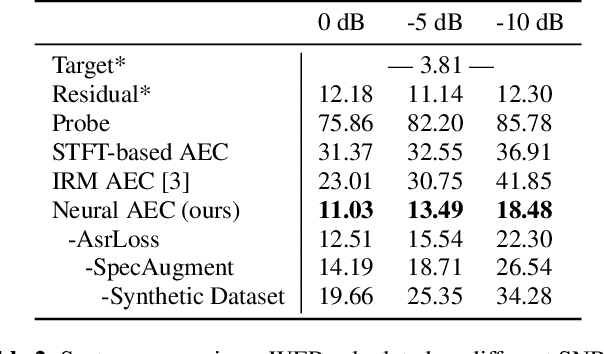
We consider the problem of recognizing speech utterances spoken to a device which is generating a known sound waveform; for example, recognizing queries issued to a digital assistant which is generating responses to previous user inputs. Previous work has proposed building acoustic echo cancellation (AEC) models for this task that optimize speech enhancement metrics using both neural network as well as signal processing approaches. Since our goal is to recognize the input speech, we consider enhancements which improve word error rates (WERs) when the predicted speech signal is passed to an automatic speech recognition (ASR) model. First, we augment the loss function with a term that produces outputs useful to a pre-trained ASR model and show that this augmented loss function improves WER metrics. Second, we demonstrate that augmenting our training dataset of real world examples with a large synthetic dataset improves performance. Crucially, applying SpecAugment style masks to the reference channel during training aids the model in adapting from synthetic to real domains. In experimental evaluations, we find the proposed approaches improve performance, on average, by 57% over a signal processing baseline and 45% over the neural AEC model without the proposed changes.
On the Relevance of Bandwidth Extension for Speaker Verification
Apr 05, 2022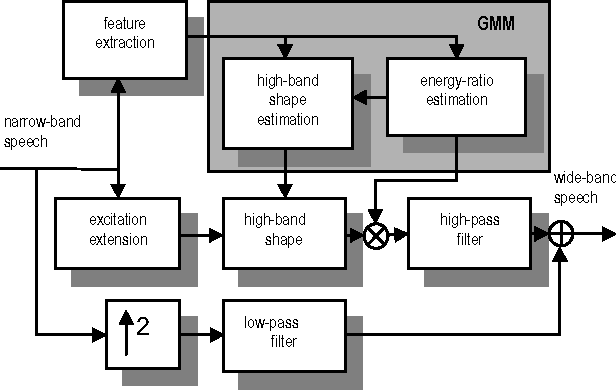

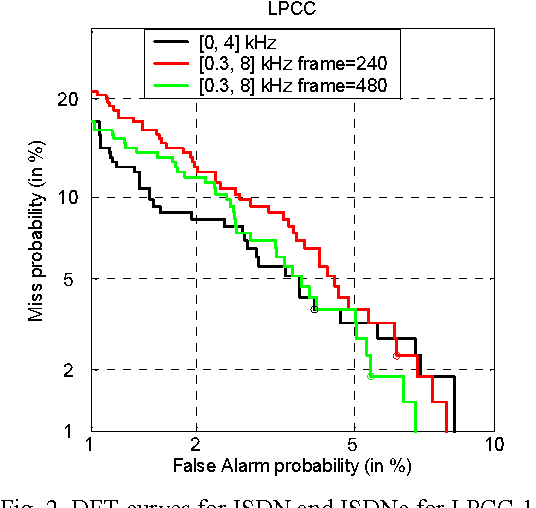
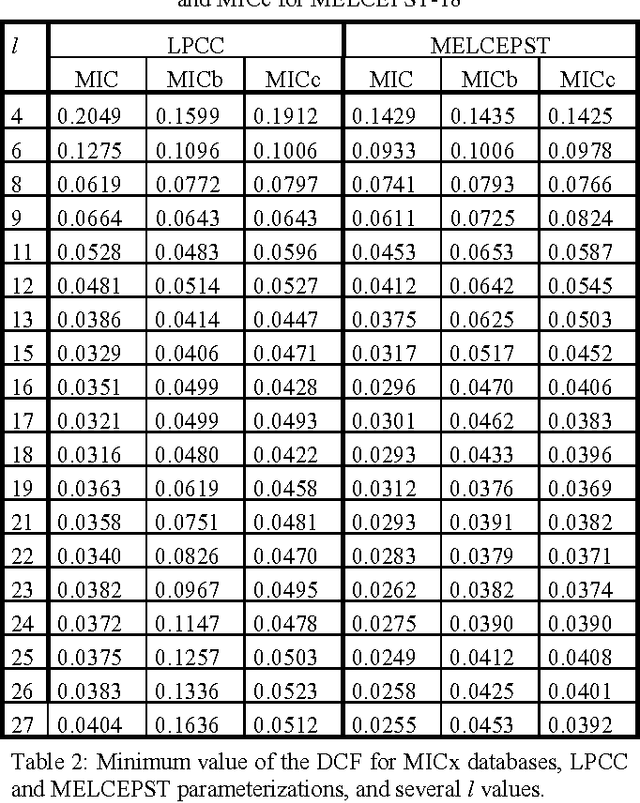
In this paper, we consider the effect of a bandwidth extension of narrow-band speech signals (0.3-3.4 kHz) to 0.3-8 kHz on speaker verification. Using covariance matrix based verification systems together with detection error trade-off curves, we compare the performance between systems operating on narrow-band, wide-band (0-8 kHz), and bandwidth-extended speech. The experiments were conducted using different short-time spectral parameterizations derived from microphone and ISDN speech databases. The studied bandwidth-extension algorithm did not introduce artifacts that affected the speaker verification task, and we achieved improvements between 1 and 10 percent (depending on the model order) over the verification system designed for narrow-band speech when mel-frequency cepstral coefficients for the short-time spectral parameterization were used.
* 4 pages published in 7th International Conference on Spoken Language Processing, September 16-20, 2002, Denver, Colorado, USA. arXiv admin note: text overlap with arXiv:2202.13865
A Syntax Aware BERT for Identifying Well-Formed Queries in a Curriculum Framework
Aug 21, 2022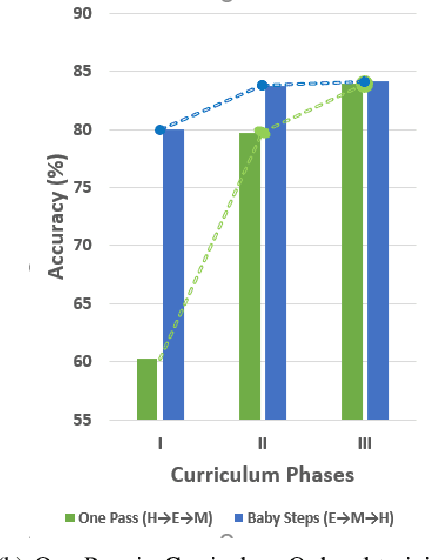
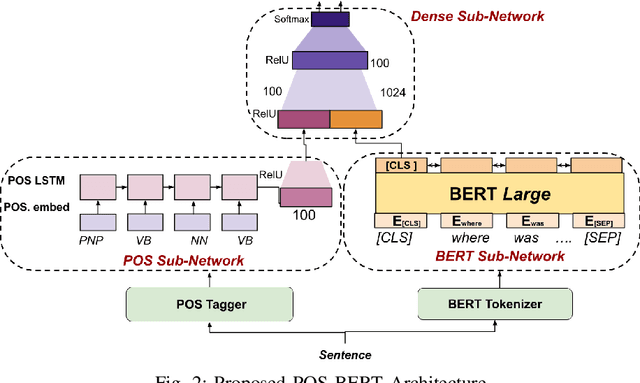
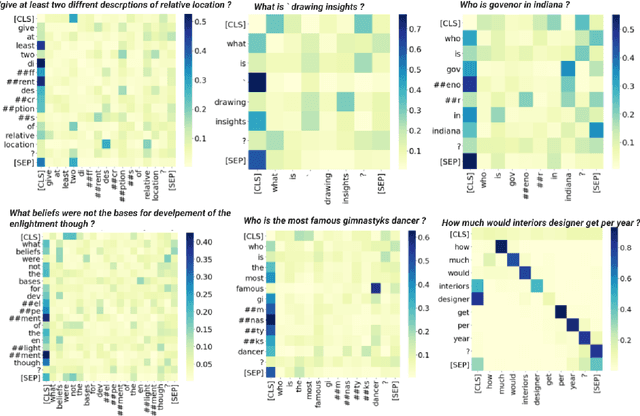

A well formed query is defined as a query which is formulated in the manner of an inquiry, and with correct interrogatives, spelling and grammar. While identifying well formed queries is an important task, few works have attempted to address it. In this paper we propose transformer based language model - Bidirectional Encoder Representations from Transformers (BERT) to this task. We further imbibe BERT with parts-of-speech information inspired from earlier works. Furthermore, we also train the model in multiple curriculum settings for improvement in performance. Curriculum Learning over the task is experimented with Baby Steps and One Pass techniques. Proposed architecture performs exceedingly well on the task. The best approach achieves accuracy of 83.93%, outperforming previous state-of-the-art at 75.0% and reaching close to the approximate human upper bound of 88.4%.
Non-autoregressive Error Correction for CTC-based ASR with Phone-conditioned Masked LM
Sep 08, 2022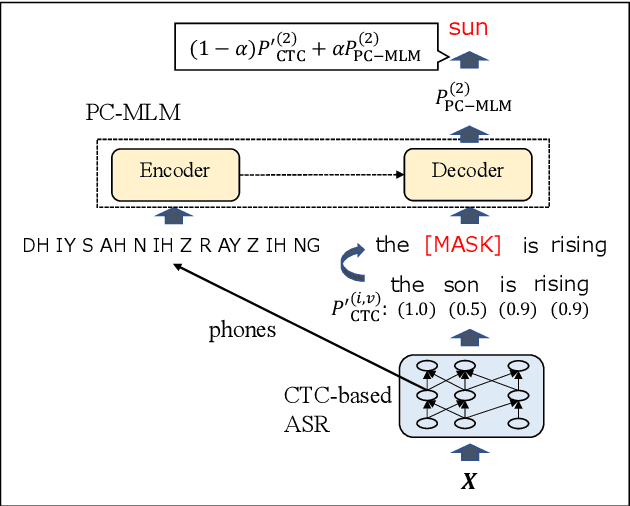
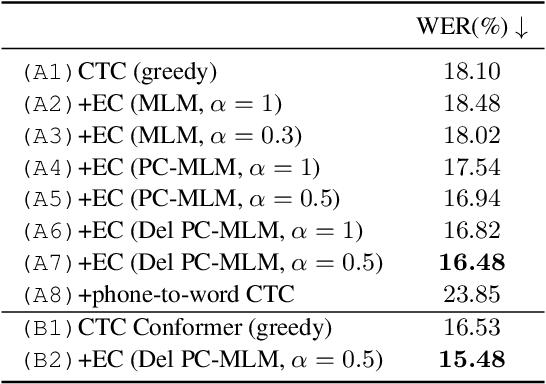
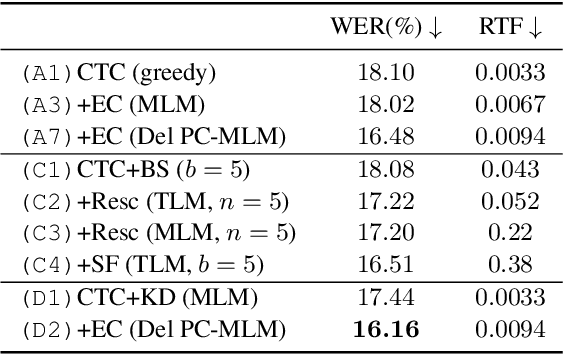
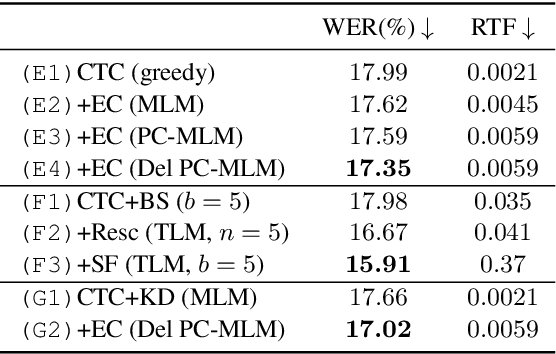
Connectionist temporal classification (CTC) -based models are attractive in automatic speech recognition (ASR) because of their non-autoregressive nature. To take advantage of text-only data, language model (LM) integration approaches such as rescoring and shallow fusion have been widely used for CTC. However, they lose CTC's non-autoregressive nature because of the need for beam search, which slows down the inference speed. In this study, we propose an error correction method with phone-conditioned masked LM (PC-MLM). In the proposed method, less confident word tokens in a greedy decoded output from CTC are masked. PC-MLM then predicts these masked word tokens given unmasked words and phones supplementally predicted from CTC. We further extend it to Deletable PC-MLM in order to address insertion errors. Since both CTC and PC-MLM are non-autoregressive models, the method enables fast LM integration. Experimental evaluations on the Corpus of Spontaneous Japanese (CSJ) and TED-LIUM2 in domain adaptation setting shows that our proposed method outperformed rescoring and shallow fusion in terms of inference speed, and also in terms of recognition accuracy on CSJ.
Teacher-Student MixIT for Unsupervised and Semi-supervised Speech Separation
Jun 16, 2021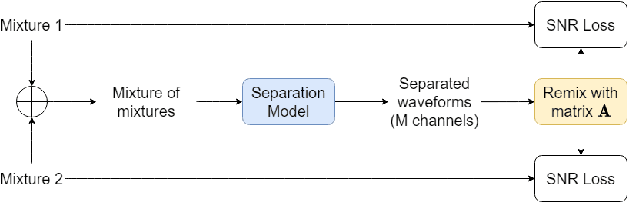
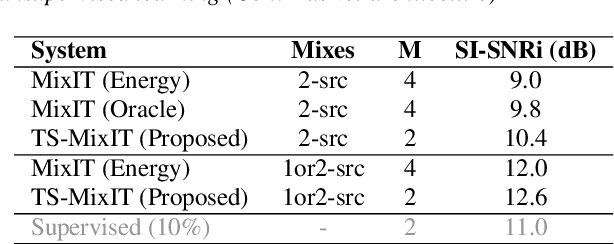
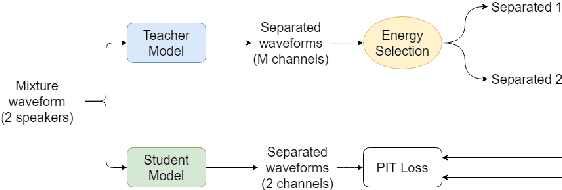
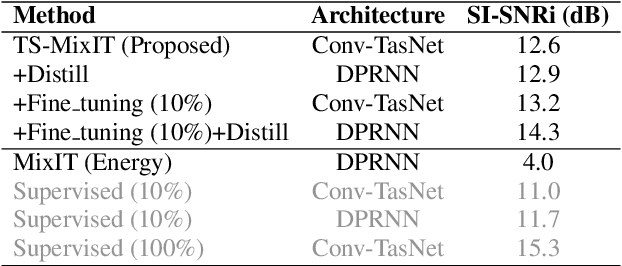
In this paper, we introduce a novel semi-supervised learning framework for end-to-end speech separation. The proposed method first uses mixtures of unseparated sources and the mixture invariant training (MixIT) criterion to train a teacher model. The teacher model then estimates separated sources that are used to train a student model with standard permutation invariant training (PIT). The student model can be fine-tuned with supervised data, i.e., paired artificial mixtures and clean speech sources, and further improved via model distillation. Experiments with single and multi channel mixtures show that the teacher-student training resolves the over-separation problem observed in the original MixIT method. Further, the semisupervised performance is comparable to a fully-supervised separation system trained using ten times the amount of supervised data.
Streaming end-to-end speech recognition with jointly trained neural feature enhancement
May 04, 2021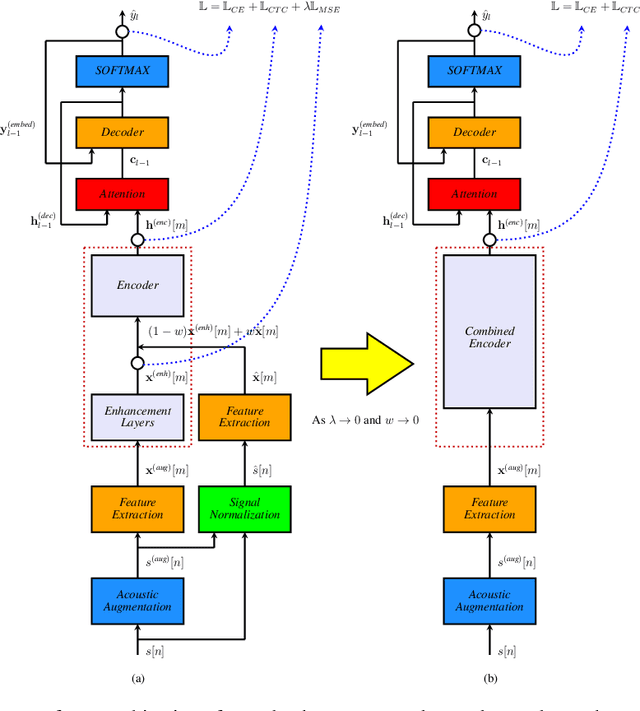
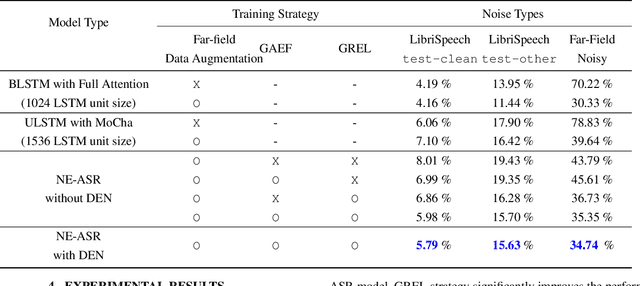
In this paper, we present a streaming end-to-end speech recognition model based on Monotonic Chunkwise Attention (MoCha) jointly trained with enhancement layers. Even though the MoCha attention enables streaming speech recognition with recognition accuracy comparable to a full attention-based approach, training this model is sensitive to various factors such as the difficulty of training examples, hyper-parameters, and so on. Because of these issues, speech recognition accuracy of a MoCha-based model for clean speech drops significantly when a multi-style training approach is applied. Inspired by Curriculum Learning [1], we introduce two training strategies: Gradual Application of Enhanced Features (GAEF) and Gradual Reduction of Enhanced Loss (GREL). With GAEF, the model is initially trained using clean features. Subsequently, the portion of outputs from the enhancement layers gradually increases. With GREL, the portion of the Mean Squared Error (MSE) loss for the enhanced output gradually reduces as training proceeds. In experimental results on the LibriSpeech corpus and noisy far-field test sets, the proposed model with GAEF-GREL training strategies shows significantly better results than the conventional multi-style training approach.
Universal Fourier Attack for Time Series
Sep 02, 2022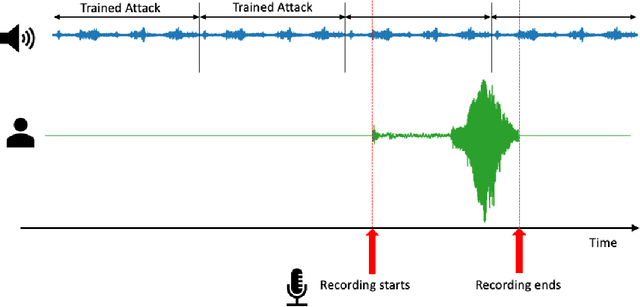
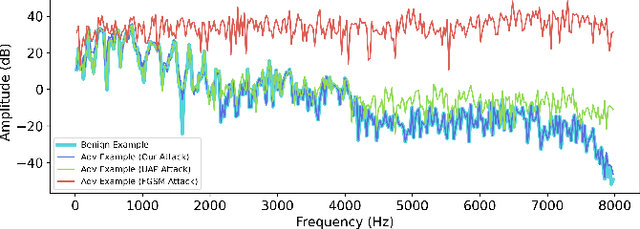
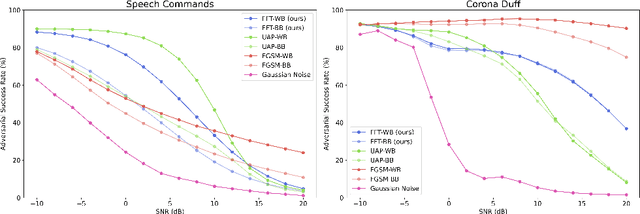
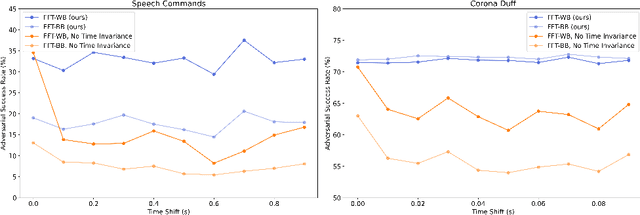
A wide variety of adversarial attacks have been proposed and explored using image and audio data. These attacks are notoriously easy to generate digitally when the attacker can directly manipulate the input to a model, but are much more difficult to implement in the real-world. In this paper we present a universal, time invariant attack for general time series data such that the attack has a frequency spectrum primarily composed of the frequencies present in the original data. The universality of the attack makes it fast and easy to implement as no computation is required to add it to an input, while time invariance is useful for real-world deployment. Additionally, the frequency constraint ensures the attack can withstand filtering. We demonstrate the effectiveness of the attack in two different domains, speech recognition and unintended radiated emission, and show that the attack is robust against common transform-and-compare defense pipelines.