 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Data-driven grapheme-to-phoneme representations for a lexicon-free text-to-speech
Jan 19, 2024
Grapheme-to-Phoneme (G2P) is an essential first step in any modern, high-quality Text-to-Speech (TTS) system. Most of the current G2P systems rely on carefully hand-crafted lexicons developed by experts. This poses a two-fold problem. Firstly, the lexicons are generated using a fixed phoneme set, usually, ARPABET or IPA, which might not be the most optimal way to represent phonemes for all languages. Secondly, the man-hours required to produce such an expert lexicon are very high. In this paper, we eliminate both of these issues by using recent advances in self-supervised learning to obtain data-driven phoneme representations instead of fixed representations. We compare our lexicon-free approach against strong baselines that utilize a well-crafted lexicon. Furthermore, we show that our data-driven lexicon-free method performs as good or even marginally better than the conventional rule-based or lexicon-based neural G2Ps in terms of Mean Opinion Score (MOS) while using no prior language lexicon or phoneme set, i.e. no linguistic expertise.
The Sound of Healthcare: Improving Medical Transcription ASR Accuracy with Large Language Models
Feb 12, 2024In the rapidly evolving landscape of medical documentation, transcribing clinical dialogues accurately is increasingly paramount. This study explores the potential of Large Language Models (LLMs) to enhance the accuracy of Automatic Speech Recognition (ASR) systems in medical transcription. Utilizing the PriMock57 dataset, which encompasses a diverse range of primary care consultations, we apply advanced LLMs to refine ASR-generated transcripts. Our research is multifaceted, focusing on improvements in general Word Error Rate (WER), Medical Concept WER (MC-WER) for the accurate transcription of essential medical terms, and speaker diarization accuracy. Additionally, we assess the role of LLM post-processing in improving semantic textual similarity, thereby preserving the contextual integrity of clinical dialogues. Through a series of experiments, we compare the efficacy of zero-shot and Chain-of-Thought (CoT) prompting techniques in enhancing diarization and correction accuracy. Our findings demonstrate that LLMs, particularly through CoT prompting, not only improve the diarization accuracy of existing ASR systems but also achieve state-of-the-art performance in this domain. This improvement extends to more accurately capturing medical concepts and enhancing the overall semantic coherence of the transcribed dialogues. These findings illustrate the dual role of LLMs in augmenting ASR outputs and independently excelling in transcription tasks, holding significant promise for transforming medical ASR systems and leading to more accurate and reliable patient records in healthcare settings.
Learning to Generate Context-Sensitive Backchannel Smiles for Embodied AI Agents with Applications in Mental Health Dialogues
Feb 13, 2024Addressing the critical shortage of mental health resources for effective screening, diagnosis, and treatment remains a significant challenge. This scarcity underscores the need for innovative solutions, particularly in enhancing the accessibility and efficacy of therapeutic support. Embodied agents with advanced interactive capabilities emerge as a promising and cost-effective supplement to traditional caregiving methods. Crucial to these agents' effectiveness is their ability to simulate non-verbal behaviors, like backchannels, that are pivotal in establishing rapport and understanding in therapeutic contexts but remain under-explored. To improve the rapport-building capabilities of embodied agents we annotated backchannel smiles in videos of intimate face-to-face conversations over topics such as mental health, illness, and relationships. We hypothesized that both speaker and listener behaviors affect the duration and intensity of backchannel smiles. Using cues from speech prosody and language along with the demographics of the speaker and listener, we found them to contain significant predictors of the intensity of backchannel smiles. Based on our findings, we introduce backchannel smile production in embodied agents as a generation problem. Our attention-based generative model suggests that listener information offers performance improvements over the baseline speaker-centric generation approach. Conditioned generation using the significant predictors of smile intensity provides statistically significant improvements in empirical measures of generation quality. Our user study by transferring generated smiles to an embodied agent suggests that agent with backchannel smiles is perceived to be more human-like and is an attractive alternative for non-personal conversations over agent without backchannel smiles.
A Refining Underlying Information Framework for Monaural Speech Enhancement
Dec 24, 2023Supervised speech enhancement has gained significantly from recent advancements in neural networks, especially due to their ability to non-linearly fit the diverse representations of target speech, such as waveform or spectrum. However, these direct-fitting solutions continue to face challenges with degraded speech and residual noise in hearing evaluations. By bridging the speech enhancement and the Information Bottleneck principle in this letter, we rethink a universal plug-and-play strategy and propose a Refining Underlying Information framework called RUI to rise to the challenges both in theory and practice. Specifically, we first transform the objective of speech enhancement into an incremental convergence problem of mutual information between comprehensive speech characteristics and individual speech characteristics, e.g., spectral and acoustic characteristics. By doing so, compared with the existing direct-fitting solutions, the underlying information stems from the conditional entropy of acoustic characteristic given spectral characteristics. Therefore, we design a dual-path multiple refinement iterator based on the chain rule of entropy to refine this underlying information for further approximating target speech. Experimental results on DNS-Challenge dataset show that our solution consistently improves 0.3+ PESQ score over baselines, with only additional 1.18 M parameters. The source code is available at https://github.com/caoruitju/RUI_SE.
A unified multichannel far-field speech recognition system: combining neural beamforming with attention based end-to-end model
Jan 05, 2024Far-field speech recognition is a challenging task that conventionally uses signal processing beamforming to attack noise and interference problem. But the performance has been found usually limited due to heavy reliance on environmental assumption. In this paper, we propose a unified multichannel far-field speech recognition system that combines the neural beamforming and transformer-based Listen, Spell, Attend (LAS) speech recognition system, which extends the end-to-end speech recognition system further to include speech enhancement. Such framework is then jointly trained to optimize the final objective of interest. Specifically, factored complex linear projection (fCLP) has been adopted to form the neural beamforming. Several pooling strategies to combine look directions are then compared in order to find the optimal approach. Moreover, information of the source direction is also integrated in the beamforming to explore the usefulness of source direction as a prior, which is usually available especially in multi-modality scenario. Experiments on different microphone array geometry are conducted to evaluate the robustness against spacing variance of microphone array. Large in-house databases are used to evaluate the effectiveness of the proposed framework and the proposed method achieve 19.26\% improvement when compared with a strong baseline.
Neural Speech Embeddings for Speech Synthesis Based on Deep Generative Networks
Dec 10, 2023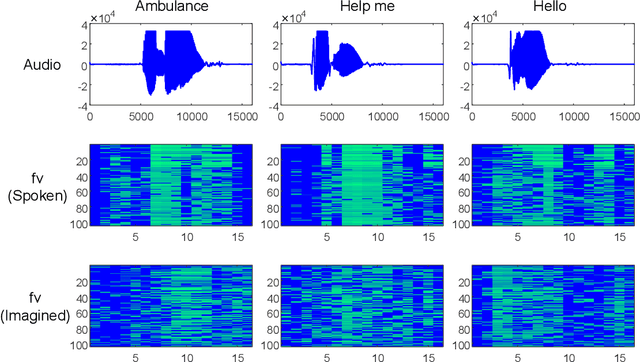
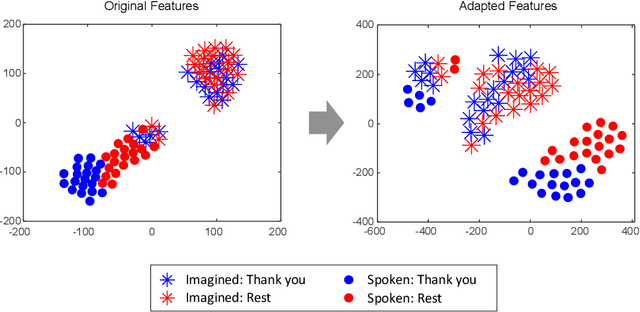
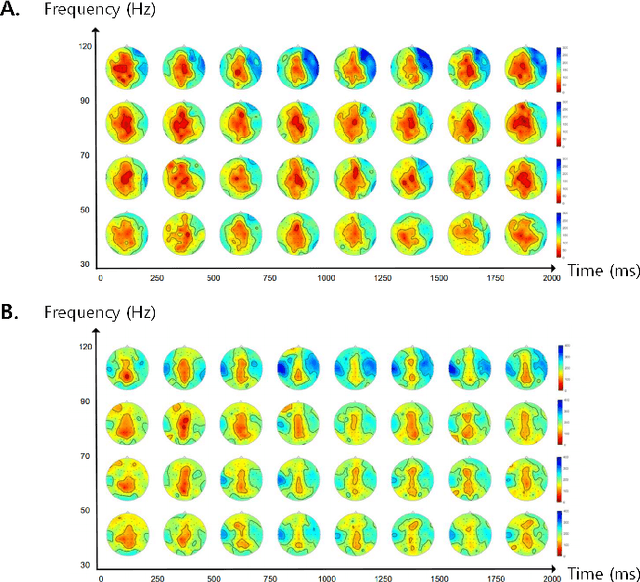
Brain-to-speech technology represents a fusion of interdisciplinary applications encompassing fields of artificial intelligence, brain-computer interfaces, and speech synthesis. Neural representation learning based intention decoding and speech synthesis directly connects the neural activity to the means of human linguistic communication, which may greatly enhance the naturalness of communication. With the current discoveries on representation learning and the development of the speech synthesis technologies, direct translation of brain signals into speech has shown great promise. Especially, the processed input features and neural speech embeddings which are given to the neural network play a significant role in the overall performance when using deep generative models for speech generation from brain signals. In this paper, we introduce the current brain-to-speech technology with the possibility of speech synthesis from brain signals, which may ultimately facilitate innovation in non-verbal communication. Also, we perform comprehensive analysis on the neural features and neural speech embeddings underlying the neurophysiological activation while performing speech, which may play a significant role in the speech synthesis works.
Joint Unsupervised and Supervised Training for Automatic Speech Recognition via Bilevel Optimization
Jan 13, 2024In this paper, we present a novel bilevel optimization-based training approach to training acoustic models for automatic speech recognition (ASR) tasks that we term {bi-level joint unsupervised and supervised training (BL-JUST)}. {BL-JUST employs a lower and upper level optimization with an unsupervised loss and a supervised loss respectively, leveraging recent advances in penalty-based bilevel optimization to solve this challenging ASR problem with affordable complexity and rigorous convergence guarantees.} To evaluate BL-JUST, extensive experiments on the LibriSpeech and TED-LIUM v2 datasets have been conducted. BL-JUST achieves superior performance over the commonly used pre-training followed by fine-tuning strategy.
AugSumm: towards generalizable speech summarization using synthetic labels from large language model
Jan 10, 2024Abstractive speech summarization (SSUM) aims to generate human-like summaries from speech. Given variations in information captured and phrasing, recordings can be summarized in multiple ways. Therefore, it is more reasonable to consider a probabilistic distribution of all potential summaries rather than a single summary. However, conventional SSUM models are mostly trained and evaluated with a single ground-truth (GT) human-annotated deterministic summary for every recording. Generating multiple human references would be ideal to better represent the distribution statistically, but is impractical because annotation is expensive. We tackle this challenge by proposing AugSumm, a method to leverage large language models (LLMs) as a proxy for human annotators to generate augmented summaries for training and evaluation. First, we explore prompting strategies to generate synthetic summaries from ChatGPT. We validate the quality of synthetic summaries using multiple metrics including human evaluation, where we find that summaries generated using AugSumm are perceived as more valid to humans. Second, we develop methods to utilize synthetic summaries in training and evaluation. Experiments on How2 demonstrate that pre-training on synthetic summaries and fine-tuning on GT summaries improves ROUGE-L by 1 point on both GT and AugSumm-based test sets. AugSumm summaries are available at https://github.com/Jungjee/AugSumm.
Enhancing Pre-trained ASR System Fine-tuning for Dysarthric Speech Recognition using Adversarial Data Augmentation
Jan 01, 2024Automatic recognition of dysarthric speech remains a highly challenging task to date. Neuro-motor conditions and co-occurring physical disabilities create difficulty in large-scale data collection for ASR system development. Adapting SSL pre-trained ASR models to limited dysarthric speech via data-intensive parameter fine-tuning leads to poor generalization. To this end, this paper presents an extensive comparative study of various data augmentation approaches to improve the robustness of pre-trained ASR model fine-tuning to dysarthric speech. These include: a) conventional speaker-independent perturbation of impaired speech; b) speaker-dependent speed perturbation, or GAN-based adversarial perturbation of normal, control speech based on their time alignment against parallel dysarthric speech; c) novel Spectral basis GAN-based adversarial data augmentation operating on non-parallel data. Experiments conducted on the UASpeech corpus suggest GAN-based data augmentation consistently outperforms fine-tuned Wav2vec2.0 and HuBERT models using no data augmentation and speed perturbation across different data expansion operating points by statistically significant word error rate (WER) reductions up to 2.01% and 0.96% absolute (9.03% and 4.63% relative) respectively on the UASpeech test set of 16 dysarthric speakers. After cross-system outputs rescoring, the best system produced the lowest published WER of 16.53% (46.47% on very low intelligibility) on UASpeech.
R-BI: Regularized Batched Inputs enhance Incremental Decoding Framework for Low-Latency Simultaneous Speech Translation
Jan 11, 2024Incremental Decoding is an effective framework that enables the use of an offline model in a simultaneous setting without modifying the original model, making it suitable for Low-Latency Simultaneous Speech Translation. However, this framework may introduce errors when the system outputs from incomplete input. To reduce these output errors, several strategies such as Hold-$n$, LA-$n$, and SP-$n$ can be employed, but the hyper-parameter $n$ needs to be carefully selected for optimal performance. Moreover, these strategies are more suitable for end-to-end systems than cascade systems. In our paper, we propose a new adaptable and efficient policy named "Regularized Batched Inputs". Our method stands out by enhancing input diversity to mitigate output errors. We suggest particular regularization techniques for both end-to-end and cascade systems. We conducted experiments on IWSLT Simultaneous Speech Translation (SimulST) tasks, which demonstrate that our approach achieves low latency while maintaining no more than 2 BLEU points loss compared to offline systems. Furthermore, our SimulST systems attained several new state-of-the-art results in various language directions.