 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Combining Frame-Synchronous and Label-Synchronous Systems for Speech Recognition
Jul 01, 2021
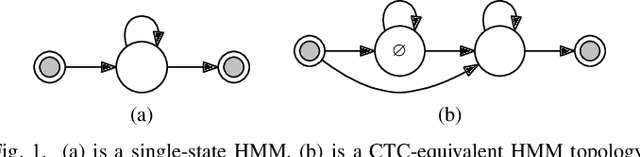
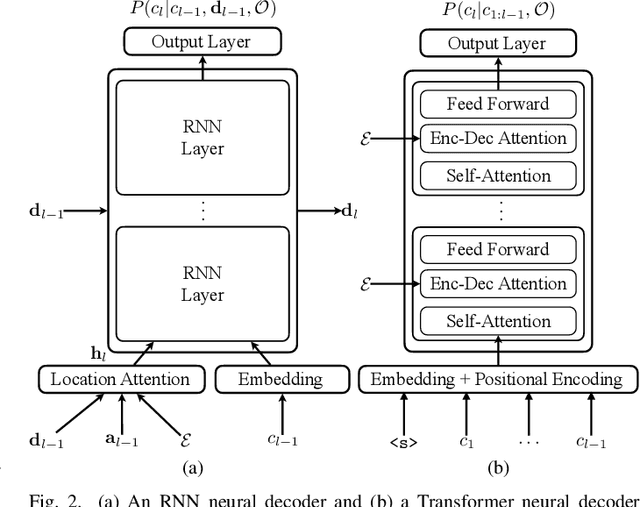
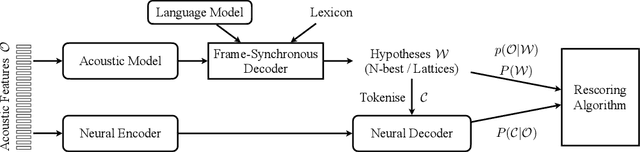
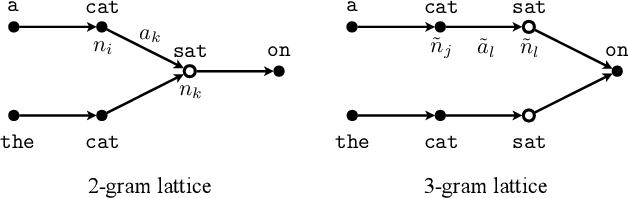
Commonly used automatic speech recognition (ASR) systems can be classified into frame-synchronous and label-synchronous categories, based on whether the speech is decoded on a per-frame or per-label basis. Frame-synchronous systems, such as traditional hidden Markov model systems, can easily incorporate existing knowledge and can support streaming ASR applications. Label-synchronous systems, based on attention-based encoder-decoder models, can jointly learn the acoustic and language information with a single model, which can be regarded as audio-grounded language models. In this paper, we propose rescoring the N-best hypotheses or lattices produced by a first-pass frame-synchronous system with a label-synchronous system in a second-pass. By exploiting the complementary modelling of the different approaches, the combined two-pass systems achieve competitive performance without using any extra speech or text data on two standard ASR tasks. For the 80-hour AMI IHM dataset, the combined system has a 13.7% word error rate (WER) on the evaluation set, which is up to a 29% relative WER reduction over the individual systems. For the 300-hour Switchboard dataset, the WERs of the combined system are 5.7% and 12.1% on Switchboard and CallHome subsets of Hub5'00, and 13.2% and 7.6% on Switchboard Cellular and Fisher subsets of RT03, up to a 33% relative reduction in WER over the individual systems.
Computing with Hypervectors for Efficient Speaker Identification
Aug 28, 2022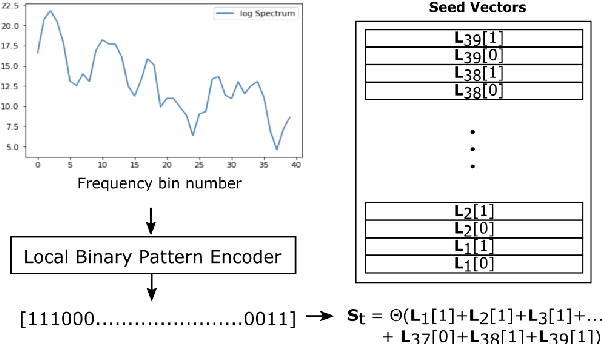

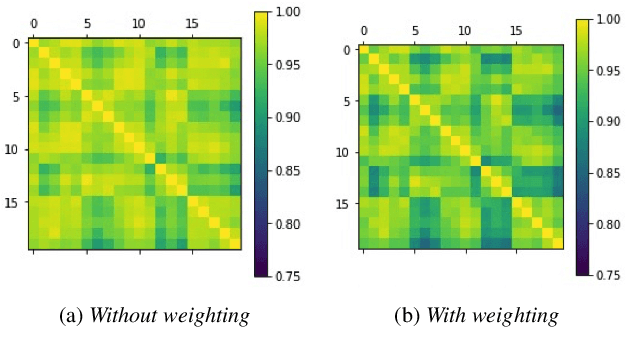
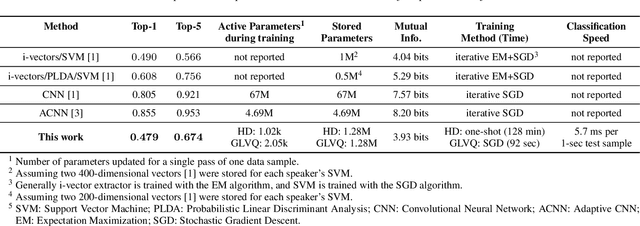
We introduce a method to identify speakers by computing with high-dimensional random vectors. Its strengths are simplicity and speed. With only 1.02k active parameters and a 128-minute pass through the training data we achieve Top-1 and Top-5 scores of 31% and 52% on the VoxCeleb1 dataset of 1,251 speakers. This is in contrast to CNN models requiring several million parameters and orders of magnitude higher computational complexity for only a 2$\times$ gain in discriminative power as measured in mutual information. An additional 92 seconds of training with Generalized Learning Vector Quantization (GLVQ) raises the scores to 48% and 67%. A trained classifier classifies 1 second of speech in 5.7 ms. All processing was done on standard CPU-based machines.
Revisiting IPA-based Cross-lingual Text-to-speech
Oct 18, 2021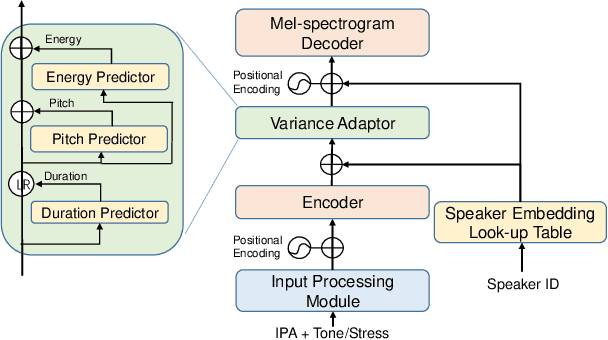
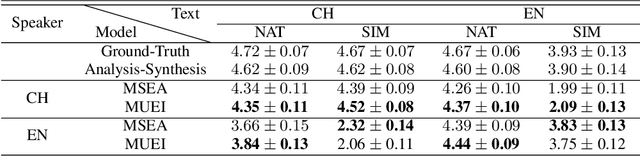
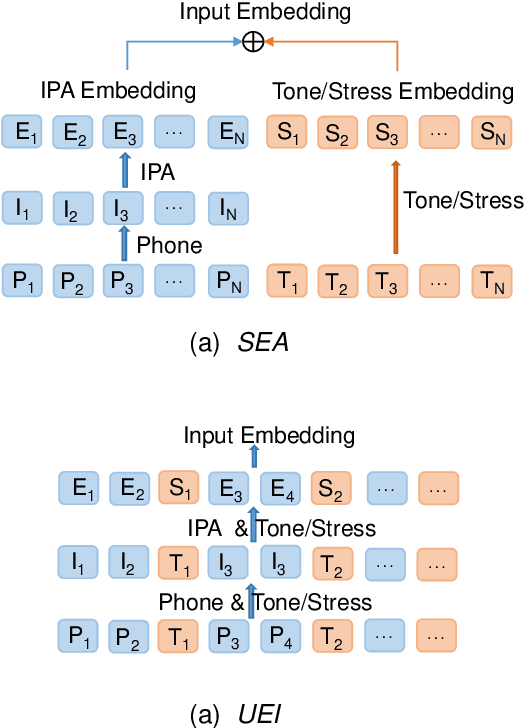
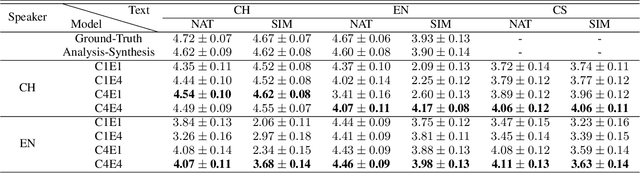
International Phonetic Alphabet (IPA) has been widely used in cross-lingual text-to-speech (TTS) to achieve cross-lingual voice cloning (CL VC). However, IPA itself has been understudied in cross-lingual TTS. In this paper, we report some empirical findings of building a cross-lingual TTS model using IPA as inputs. Experiments show that the way to process the IPA and suprasegmental sequence has a negligible impact on the CL VC performance. Furthermore, we find that using a dataset including one speaker per language to build an IPA-based TTS system would fail CL VC since the language-unique IPA and tone/stress symbols could leak the speaker information. In addition, we experiment with different combinations of speakers in the training dataset to further investigate the effect of the number of speakers on the CL VC performance.
Data Augmentation for Low-Resource Quechua ASR Improvement
Jul 14, 2022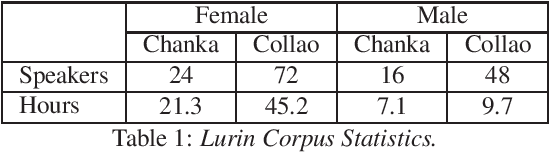
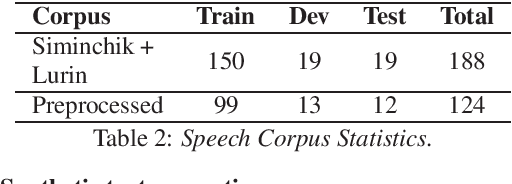
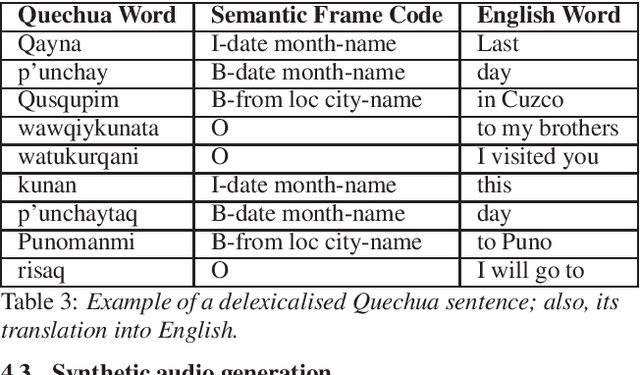
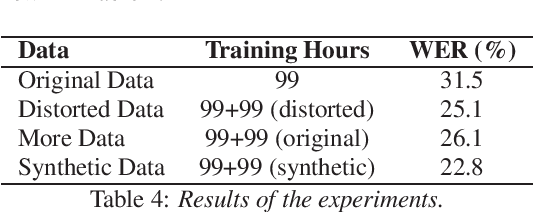
Automatic Speech Recognition (ASR) is a key element in new services that helps users to interact with an automated system. Deep learning methods have made it possible to deploy systems with word error rates below 5% for ASR of English. However, the use of these methods is only available for languages with hundreds or thousands of hours of audio and their corresponding transcriptions. For the so-called low-resource languages to speed up the availability of resources that can improve the performance of their ASR systems, methods of creating new resources on the basis of existing ones are being investigated. In this paper we describe our data augmentation approach to improve the results of ASR models for low-resource and agglutinative languages. We carry out experiments developing an ASR for Quechua using the wav2letter++ model. We reduced WER by 8.73% through our approach to the base model. The resulting ASR model obtained 22.75% WER and was trained with 99 hours of original resources and 99 hours of synthetic data obtained with a combination of text augmentation and synthetic speech generati
Task-specific Optimization of Virtual Channel Linear Prediction-based Speech Dereverberation Front-End for Far-Field Speaker Verification
Dec 27, 2021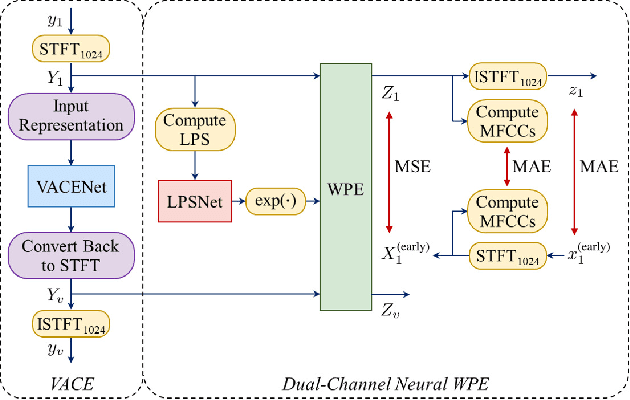
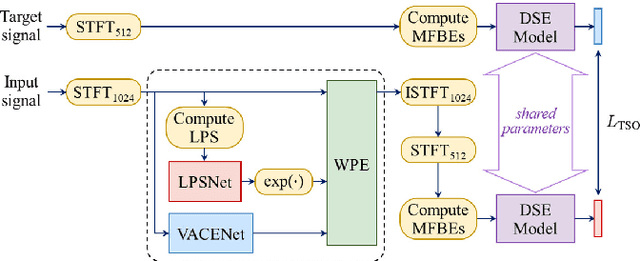
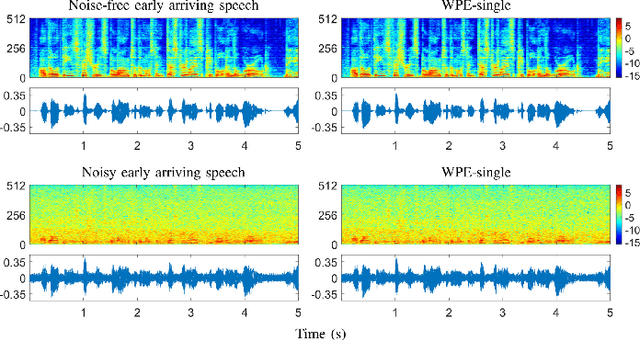
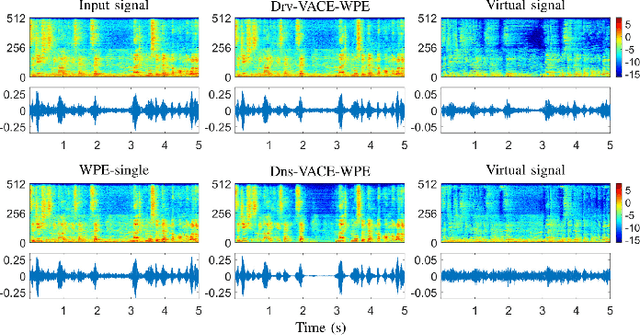
Developing a single-microphone speech denoising or dereverberation front-end for robust automatic speaker verification (ASV) in noisy far-field speaking scenarios is challenging. To address this problem, we present a novel front-end design that involves a recently proposed extension of the weighted prediction error (WPE) speech dereverberation algorithm, the virtual acoustic channel expansion (VACE)-WPE. It is demonstrated experimentally in this study that unlike the conventional WPE algorithm, the VACE-WPE can be explicitly trained to cancel out both late reverberation and background noise. To build the front-end, the VACE-WPE is first independently (pre)trained to produce "noisy" dereverberated signals. Subsequently, given a pretrained speaker embedding model, the VACE-WPE is additionally fine-tuned within a task-specific optimization (TSO) framework, causing the speaker embedding extracted from the processed signal to be similar to that extracted from the "noise-free" target signal. Moreover, to extend the application of the proposed front-end to more general, unconstrained "in-the-wild" ASV scenarios beyond controlled far-field conditions, we propose a distortion regularization method for the VACE-WPE within the TSO framework. The effectiveness of the proposed approach is verified on both far-field and in-the-wild ASV benchmarks, demonstrating its superiority over fully neural front-ends and other TSO methods in various cases.
Learning ASR pathways: A sparse multilingual ASR model
Sep 13, 2022
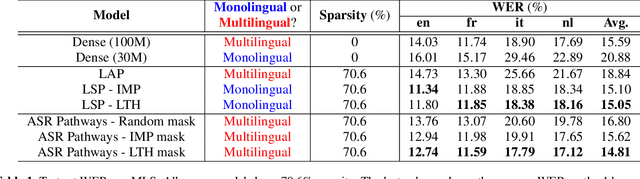
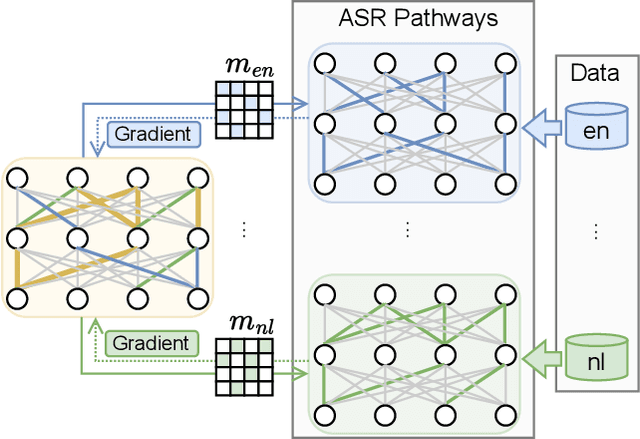
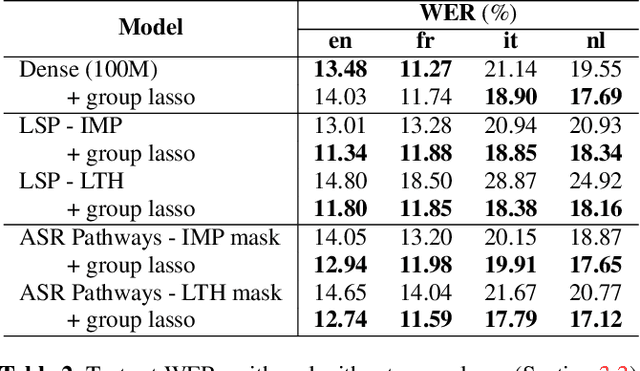
Neural network pruning can be effectively applied to compress automatic speech recognition (ASR) models. However, in multilingual ASR, performing language-agnostic pruning may lead to severe performance degradation on some languages because language-agnostic pruning masks may not fit all languages and discard important language-specific parameters. In this work, we present ASR pathways, a sparse multilingual ASR model that activates language-specific sub-networks ("pathways"), such that the parameters for each language are learned explicitly. With the overlapping sub-networks, the shared parameters can also enable knowledge transfer for lower resource languages via joint multilingual training. We propose a novel algorithm to learn ASR pathways, and evaluate the proposed method on 4 languages with a streaming RNN-T model. Our proposed ASR pathways outperform both dense models (-5.0% average WER) and a language-agnostically pruned model (-21.4% average WER), and provide better performance on low-resource languages compared to the monolingual sparse models.
Enhancing Speech Intelligibility in Text-To-Speech Synthesis using Speaking Style Conversion
Aug 13, 2020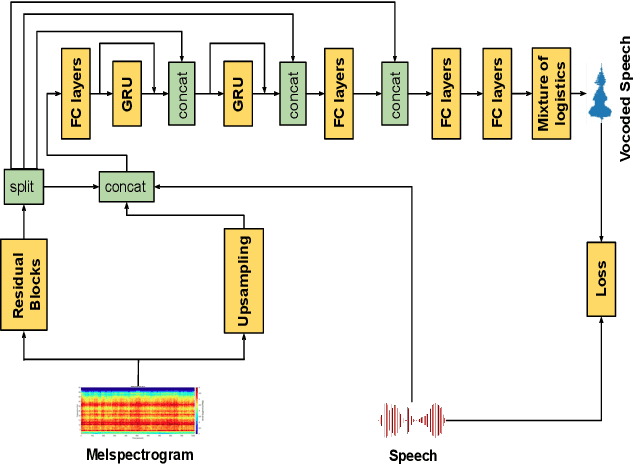
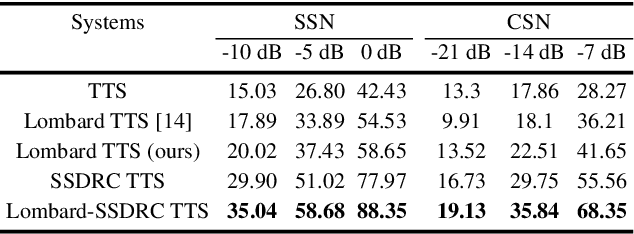
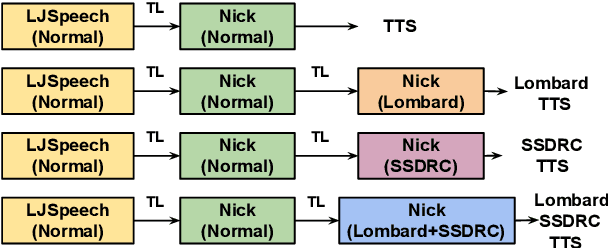
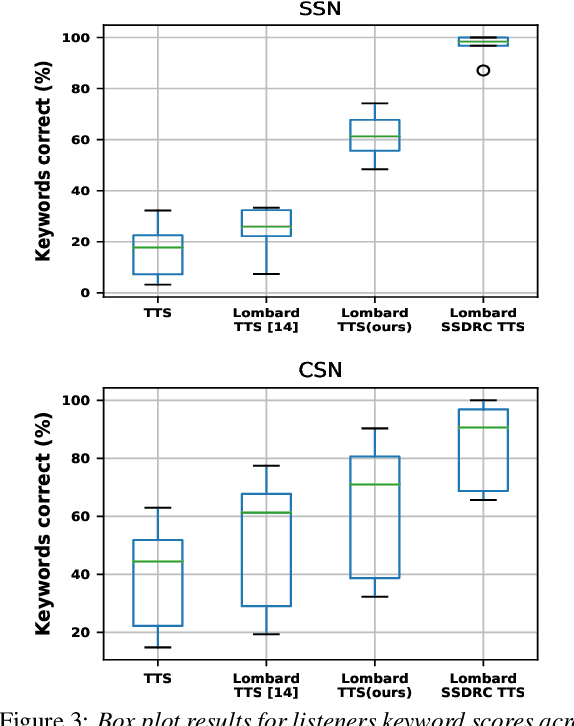
The increased adoption of digital assistants makes text-to-speech (TTS) synthesis systems an indispensable feature of modern mobile devices. It is hence desirable to build a system capable of generating highly intelligible speech in the presence of noise. Past studies have investigated style conversion in TTS synthesis, yet degraded synthesized quality often leads to worse intelligibility. To overcome such limitations, we proposed a novel transfer learning approach using Tacotron and WaveRNN based TTS synthesis. The proposed speech system exploits two modification strategies: (a) Lombard speaking style data and (b) Spectral Shaping and Dynamic Range Compression (SSDRC) which has been shown to provide high intelligibility gains by redistributing the signal energy on the time-frequency domain. We refer to this extension as Lombard-SSDRC TTS system. Intelligibility enhancement as quantified by the Intelligibility in Bits (SIIB-Gauss) measure shows that the proposed Lombard-SSDRC TTS system shows significant relative improvement between 110% and 130% in speech-shaped noise (SSN), and 47% to 140% in competing-speaker noise (CSN) against the state-of-the-art TTS approach. Additional subjective evaluation shows that Lombard-SSDRC TTS successfully increases the speech intelligibility with relative improvement of 455% for SSN and 104% for CSN in median keyword correction rate compared to the baseline TTS method.
HateXplain: A Benchmark Dataset for Explainable Hate Speech Detection
Dec 18, 2020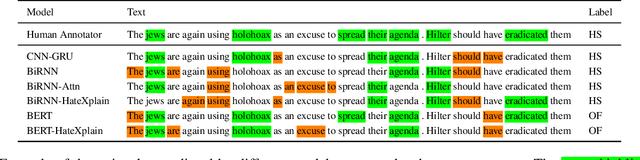
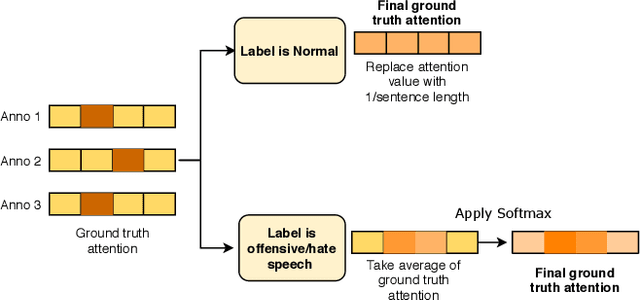
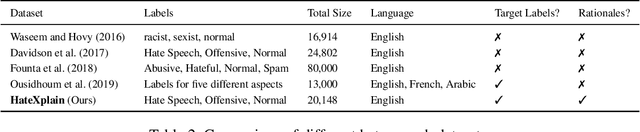
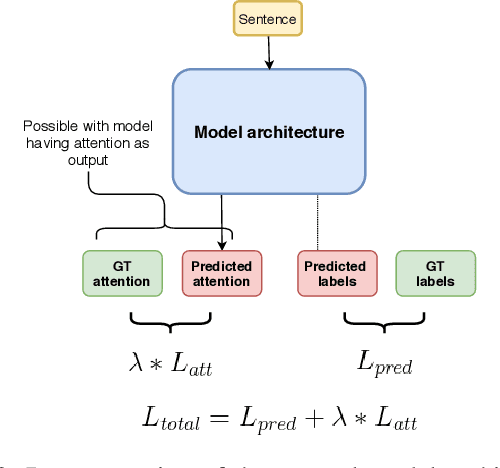
Hate speech is a challenging issue plaguing the online social media. While better models for hate speech detection are continuously being developed, there is little research on the bias and interpretability aspects of hate speech. In this paper, we introduce HateXplain, the first benchmark hate speech dataset covering multiple aspects of the issue. Each post in our dataset is annotated from three different perspectives: the basic, commonly used 3-class classification (i.e., hate, offensive or normal), the target community (i.e., the community that has been the victim of hate speech/offensive speech in the post), and the rationales, i.e., the portions of the post on which their labelling decision (as hate, offensive or normal) is based. We utilize existing state-of-the-art models and observe that even models that perform very well in classification do not score high on explainability metrics like model plausibility and faithfulness. We also observe that models, which utilize the human rationales for training, perform better in reducing unintended bias towards target communities. We have made our code and dataset public at https://github.com/punyajoy/HateXplain
Referee: Towards reference-free cross-speaker style transfer with low-quality data for expressive speech synthesis
Sep 08, 2021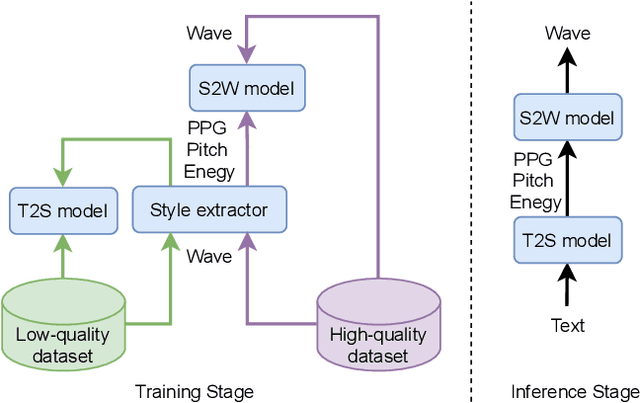
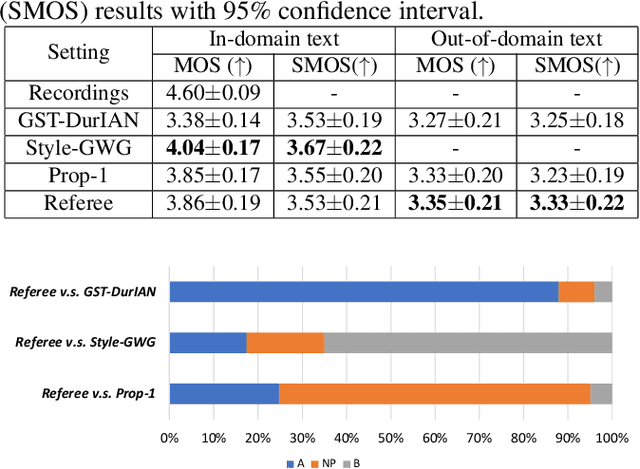
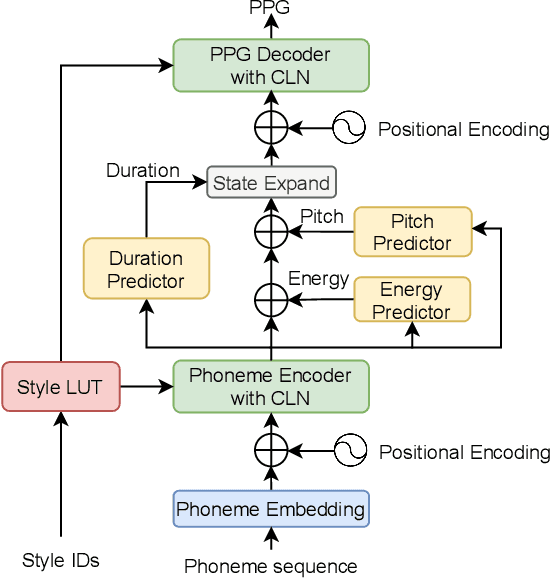
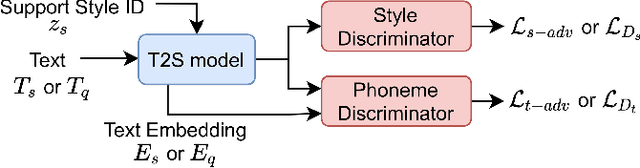
Cross-speaker style transfer (CSST) in text-to-speech (TTS) synthesis aims at transferring a speaking style to the synthesised speech in a target speaker's voice. Most previous CSST approaches rely on expensive high-quality data carrying desired speaking style during training and require a reference utterance to obtain speaking style descriptors as conditioning on the generation of a new sentence. This work presents Referee, a robust reference-free CSST approach for expressive TTS, which fully leverages low-quality data to learn speaking styles from text. Referee is built by cascading a text-to-style (T2S) model with a style-to-wave (S2W) model. Phonetic PosteriorGram (PPG), phoneme-level pitch and energy contours are adopted as fine-grained speaking style descriptors, which are predicted from text using the T2S model. A novel pretrain-refinement method is adopted to learn a robust T2S model by only using readily accessible low-quality data. The S2W model is trained with high-quality target data, which is adopted to effectively aggregate style descriptors and generate high-fidelity speech in the target speaker's voice. Experimental results are presented, showing that Referee outperforms a global-style-token (GST)-based baseline approach in CSST.
MM-ALT: A Multimodal Automatic Lyric Transcription System
Jul 13, 2022
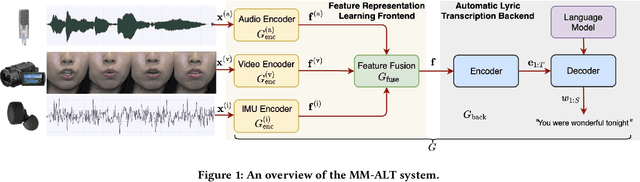
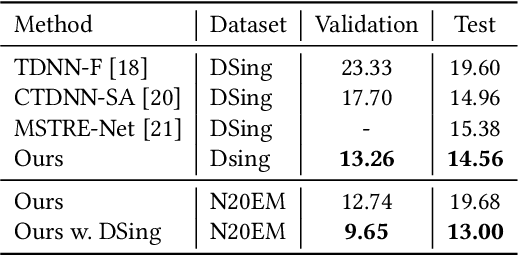
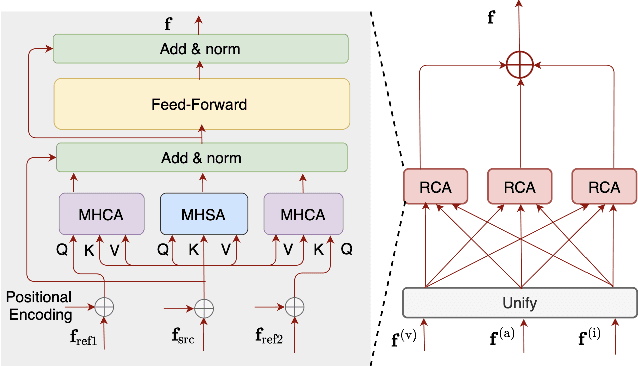
Automatic lyric transcription (ALT) is a nascent field of study attracting increasing interest from both the speech and music information retrieval communities, given its significant application potential. However, ALT with audio data alone is a notoriously difficult task due to instrumental accompaniment and musical constraints resulting in degradation of both the phonetic cues and the intelligibility of sung lyrics. To tackle this challenge, we propose the MultiModal Automatic Lyric Transcription system (MM-ALT), together with a new dataset, N20EM, which consists of audio recordings, videos of lip movements, and inertial measurement unit (IMU) data of an earbud worn by the performing singer. We first adapt the wav2vec 2.0 framework from automatic speech recognition (ASR) to the ALT task. We then propose a video-based ALT method and an IMU-based voice activity detection (VAD) method. In addition, we put forward the Residual Cross Attention (RCA) mechanism to fuse data from the three modalities (i.e., audio, video, and IMU). Experiments show the effectiveness of our proposed MM-ALT system, especially in terms of noise robustness.