 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Adaptive Natural Language Generation for Task-oriented Dialogue via Reinforcement Learning
Sep 16, 2022
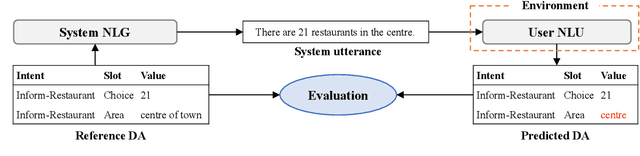
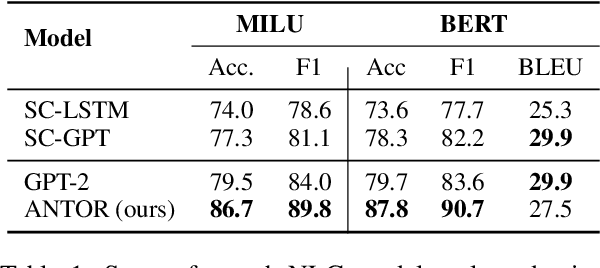
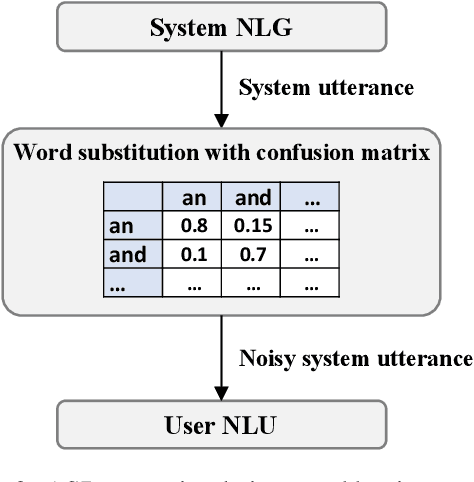
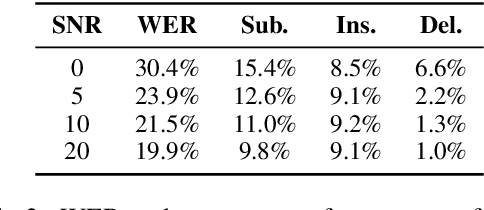
When a natural language generation (NLG) component is implemented in a real-world task-oriented dialogue system, it is necessary to generate not only natural utterances as learned on training data but also utterances adapted to the dialogue environment (e.g., noise from environmental sounds) and the user (e.g., users with low levels of understanding ability). Inspired by recent advances in reinforcement learning (RL) for language generation tasks, we propose ANTOR, a method for Adaptive Natural language generation for Task-Oriented dialogue via Reinforcement learning. In ANTOR, a natural language understanding (NLU) module, which corresponds to the user's understanding of system utterances, is incorporated into the objective function of RL. If the NLG's intentions are correctly conveyed to the NLU, which understands a system's utterances, the NLG is given a positive reward. We conducted experiments on the MultiWOZ dataset, and we confirmed that ANTOR could generate adaptive utterances against speech recognition errors and the different vocabulary levels of users.
Improving Distinction between ASR Errors and Speech Disfluencies with Feature Space Interpolation
Aug 04, 2021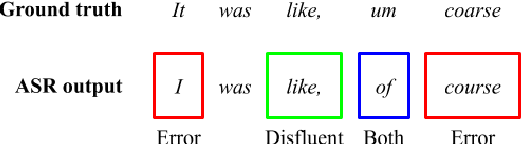
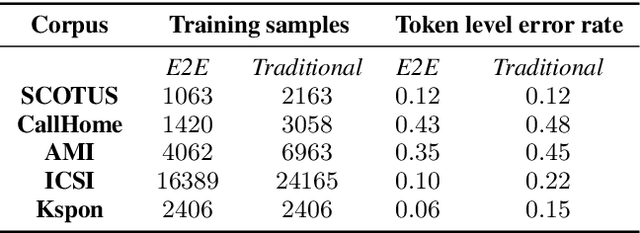
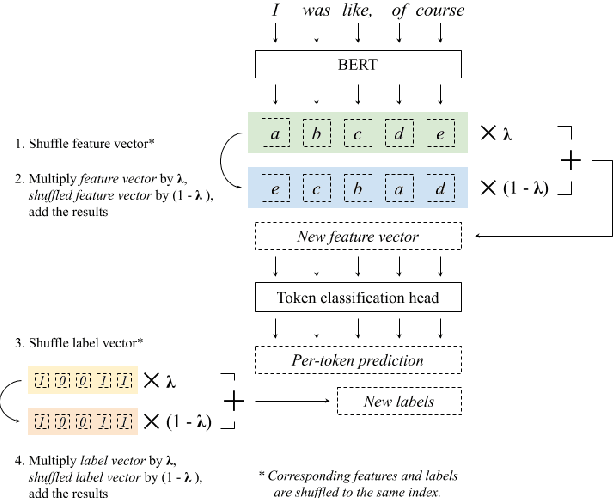
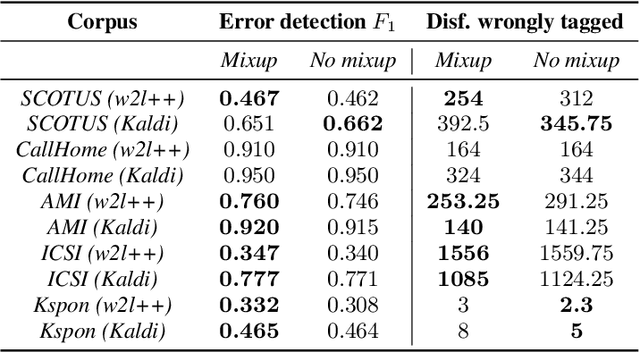
Fine-tuning pretrained language models (LMs) is a popular approach to automatic speech recognition (ASR) error detection during post-processing. While error detection systems often take advantage of statistical language archetypes captured by LMs, at times the pretrained knowledge can hinder error detection performance. For instance, presence of speech disfluencies might confuse the post-processing system into tagging disfluent but accurate transcriptions as ASR errors. Such confusion occurs because both error detection and disfluency detection tasks attempt to identify tokens at statistically unlikely positions. This paper proposes a scheme to improve existing LM-based ASR error detection systems, both in terms of detection scores and resilience to such distracting auxiliary tasks. Our approach adopts the popular mixup method in text feature space and can be utilized with any black-box ASR output. To demonstrate the effectiveness of our method, we conduct post-processing experiments with both traditional and end-to-end ASR systems (both for English and Korean languages) with 5 different speech corpora. We find that our method improves both ASR error detection F 1 scores and reduces the number of correctly transcribed disfluencies wrongly detected as ASR errors. Finally, we suggest methods to utilize resulting LMs directly in semi-supervised ASR training.
Digital Einstein Experience: Fast Text-to-Speech for Conversational AI
Jul 21, 2021
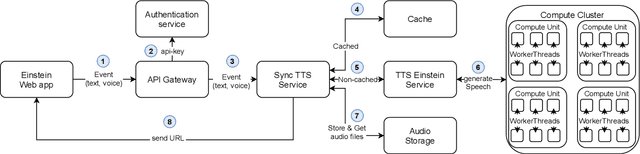
We describe our approach to create and deliver a custom voice for a conversational AI use-case. More specifically, we provide a voice for a Digital Einstein character, to enable human-computer interaction within the digital conversation experience. To create the voice which fits the context well, we first design a voice character and we produce the recordings which correspond to the desired speech attributes. We then model the voice. Our solution utilizes Fastspeech 2 for log-scaled mel-spectrogram prediction from phonemes and Parallel WaveGAN to generate the waveforms. The system supports a character input and gives a speech waveform at the output. We use a custom dictionary for selected words to ensure their proper pronunciation. Our proposed cloud architecture enables for fast voice delivery, making it possible to talk to the digital version of Albert Einstein in real-time.
Towards the evaluation of simultaneous speech translation from a communicative perspective
Mar 15, 2021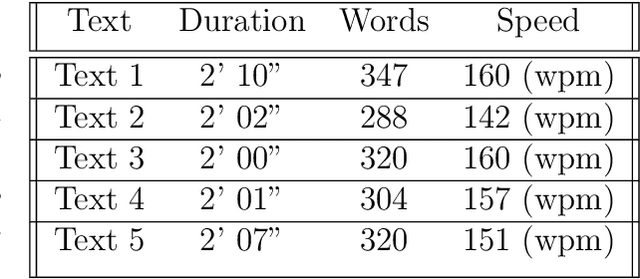
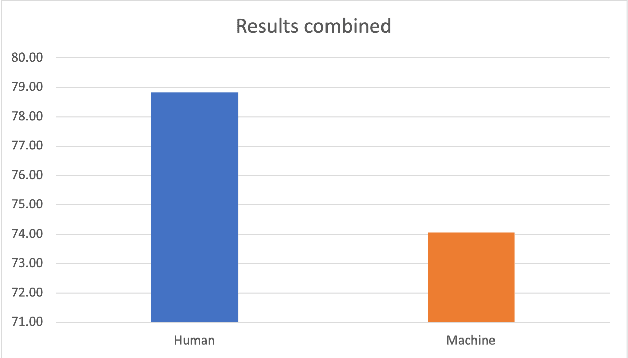
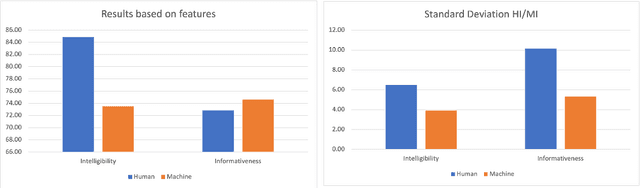
In recent years, machine speech-to-speech and speech-to-text translation has gained momentum thanks to advances in artificial intelligence, especially in the domains of speech recognition and machine translation. The quality of such applications is commonly tested with automatic metrics, such as BLEU, primarily with the goal of assessing improvements of releases or in the context of evaluation campaigns. However, little is known about how such systems compare to human performances in similar communicative tasks or how the performance of such systems is perceived by final users. In this paper, we present the results of an experiment aimed at evaluating the quality of a simultaneous speech translation engine by comparing it to the performance of professional interpreters. To do so, we select a framework developed for the assessment of human interpreters and use it to perform a manual evaluation on both human and machine performances. In our sample, we found better performance for the human interpreters in terms of intelligibility, while the machine performs slightly better in terms of informativeness. The limitations of the study and the possible enhancements of the chosen framework are discussed. Despite its intrinsic limitations, the use of this framework represents a first step towards a user-centric and communication-oriented methodology for evaluating simultaneous speech translation.
Deep Multi-Frame MVDR Filtering for Binaural Noise Reduction
May 18, 2022
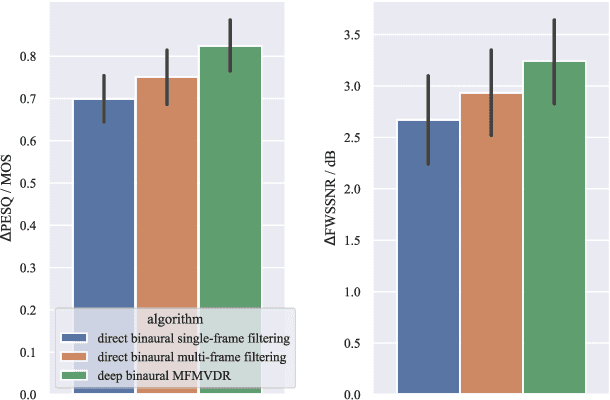
To improve speech intelligibility and speech quality in noisy environments, binaural noise reduction algorithms for head-mounted assistive listening devices are of crucial importance. Several binaural noise reduction algorithms such as the well-known binaural minimum variance distortionless response (MVDR) beamformer have been proposed, which exploit spatial correlations of both the target speech and the noise components. Furthermore, for single-microphone scenarios, multi-frame algorithms such as the multi-frame MVDR (MFMVDR) filter have been proposed, which exploit temporal instead of spatial correlations. In this contribution, we propose a binaural extension of the MFMVDR filter, which exploits both spatial and temporal correlations. The binaural MFMVDR filters are embedded in an end-to-end deep learning framework, where the required parameters, i.e., the speech spatio-temporal correlation vectors as well as the (inverse) noise spatio-temporal covariance matrix, are estimated by temporal convolutional networks (TCNs) that are trained by minimizing the mean spectral absolute error loss function. Simulation results comprising measured binaural room impulses and diverse noise sources at signal-to-noise ratios from -5 dB to 20 dB demonstrate the advantage of utilizing the binaural MFMVDR filter structure over directly estimating the binaural multi-frame filter coefficients with TCNs.
Effectiveness of Mining Audio and Text Pairs from Public Data for Improving ASR Systems for Low-Resource Languages
Aug 26, 2022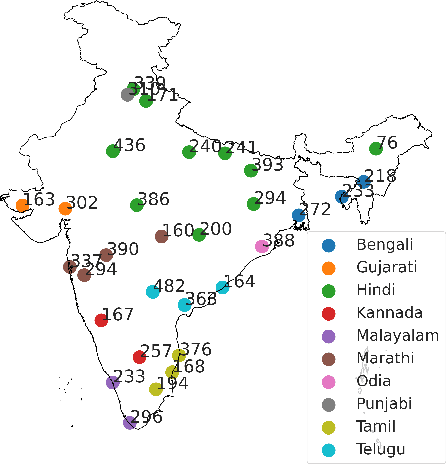
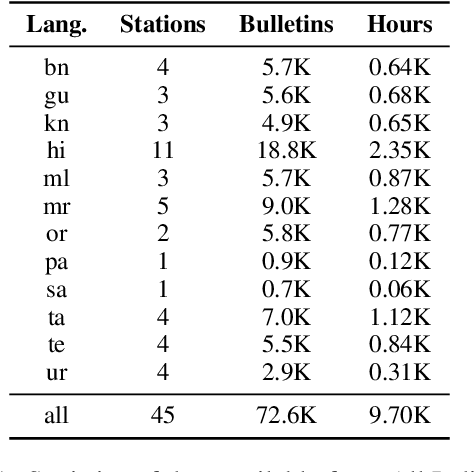

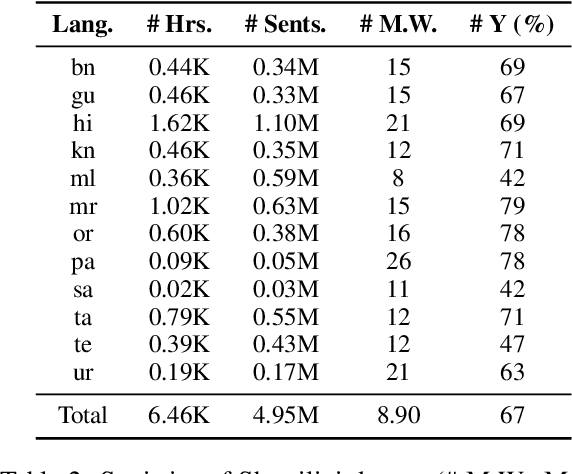
End-to-end (E2E) models have become the default choice for state-of-the-art speech recognition systems. Such models are trained on large amounts of labelled data, which are often not available for low-resource languages. Techniques such as self-supervised learning and transfer learning hold promise, but have not yet been effective in training accurate models. On the other hand, collecting labelled datasets on a diverse set of domains and speakers is very expensive. In this work, we demonstrate an inexpensive and effective alternative to these approaches by ``mining'' text and audio pairs for Indian languages from public sources, specifically from the public archives of All India Radio. As a key component, we adapt the Needleman-Wunsch algorithm to align sentences with corresponding audio segments given a long audio and a PDF of its transcript, while being robust to errors due to OCR, extraneous text, and non-transcribed speech. We thus create Shrutilipi, a dataset which contains over 6,400 hours of labelled audio across 12 Indian languages totalling to 4.95M sentences. On average, Shrutilipi results in a 2.3x increase over publicly available labelled data. We establish the quality of Shrutilipi with 21 human evaluators across the 12 languages. We also establish the diversity of Shrutilipi in terms of represented regions, speakers, and mentioned named entities. Significantly, we show that adding Shrutilipi to the training set of Wav2Vec models leads to an average decrease in WER of 5.8\% for 7 languages on the IndicSUPERB benchmark. For Hindi, which has the most benchmarks (7), the average WER falls from 18.8% to 13.5%. This improvement extends to efficient models: We show a 2.3% drop in WER for a Conformer model (10x smaller than Wav2Vec). Finally, we demonstrate the diversity of Shrutilipi by showing that the model trained with it is more robust to noisy input.
End-to-end label uncertainty modeling for speech emotion recognition using Bayesian neural networks
Oct 07, 2021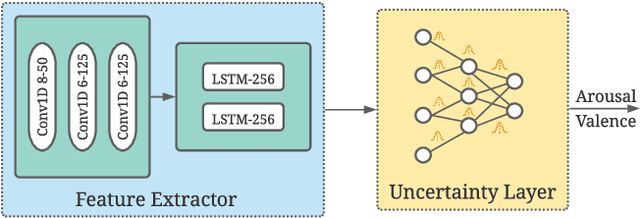
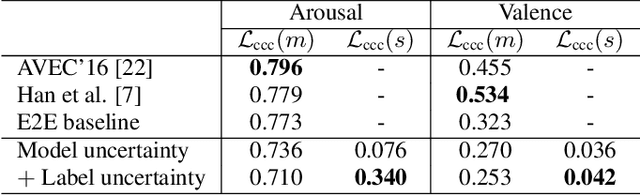

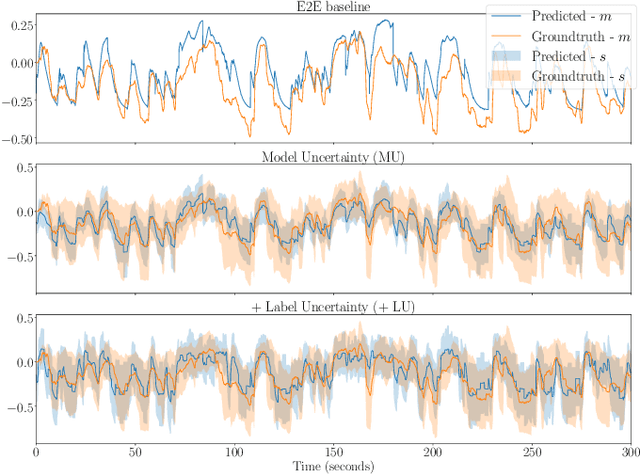
Emotions are subjective constructs. Recent end-to-end speech emotion recognition systems are typically agnostic to the subjective nature of emotions, despite their state-of-the-art performances. In this work, we introduce an end-to-end Bayesian neural network architecture to capture the inherent subjectivity in emotions. To the best of our knowledge, this work is the first to use Bayesian neural networks for speech emotion recognition. At training, the network learns a distribution of weights to capture the inherent uncertainty related to subjective emotion annotations. For this, we introduce a loss term which enables the model to be explicitly trained on a distribution of emotion annotations, rather than training them exclusively on mean or gold-standard labels. We evaluate the proposed approach on the AVEC'16 emotion recognition dataset. Qualitative and quantitative analysis of the results reveal that the proposed model can aptly capture the distribution of subjective emotion annotations with a compromise between mean and standard deviation estimations.
Noise Classification Aided Attention-Based Neural Network for Monaural Speech Enhancement
May 31, 2021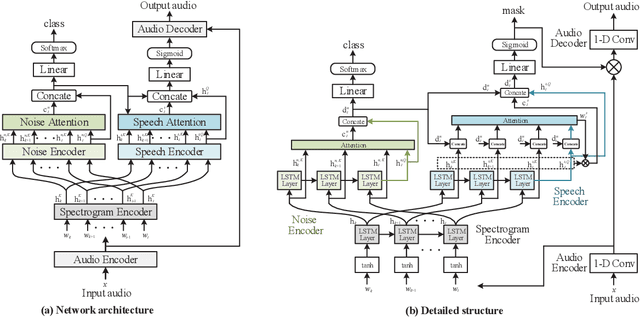
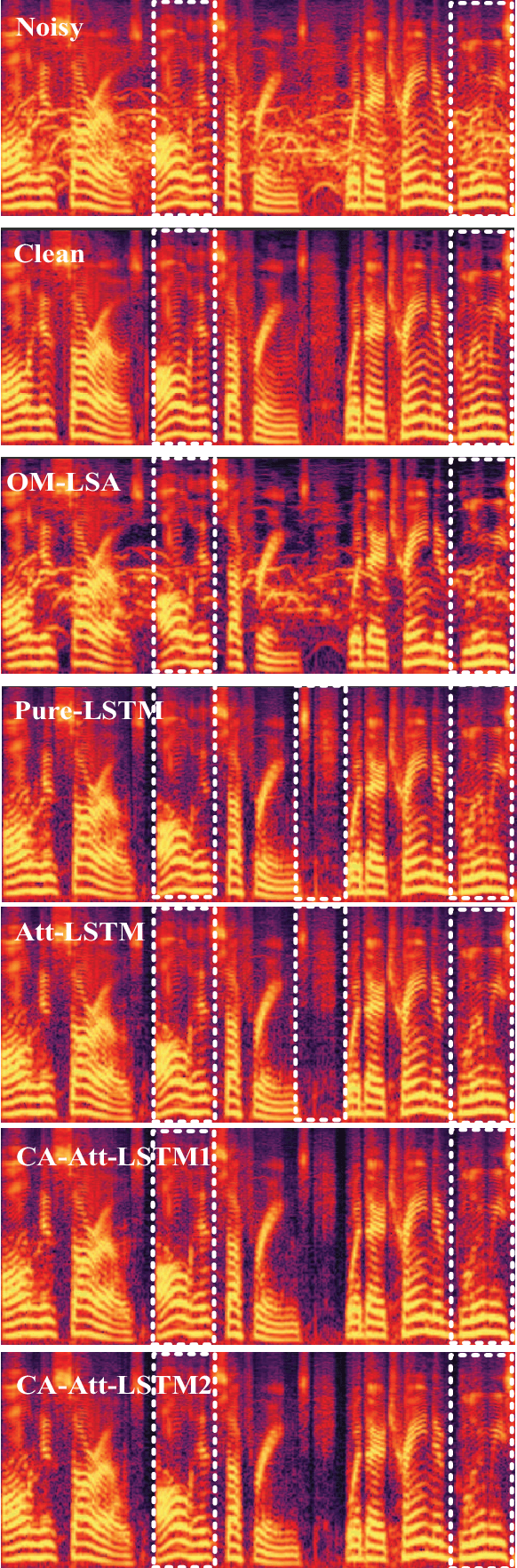
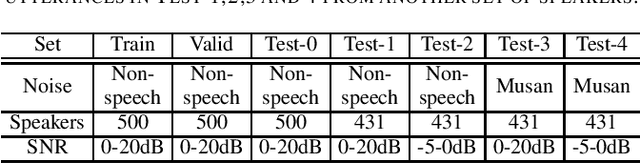

This paper proposes an noise type classification aided attention-based neural network approach for monaural speech enhancement. The network is constructed based on a previous work by introducing a noise classification subnetwork into the structure and taking the classification embedding into the attention mechanism for guiding the network to make better feature extraction. Specifically, to make the network an end-to-end way, an audio encoder and decoder constructed by temporal convolution is used to make transformation between waveform and spectrogram. Additionally, our model is composed of two long short term memory (LSTM) based encoders, two attention mechanism, a noise classifier and a speech mask generator. Experiments show that, compared with OM-LSA and the previous work, the proposed noise classification aided attention-based approach can achieve better performance in terms of speech quality (PESQ). More promisingly, our approach has better generalization ability to unseen noise conditions.
ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection
Sep 01, 2021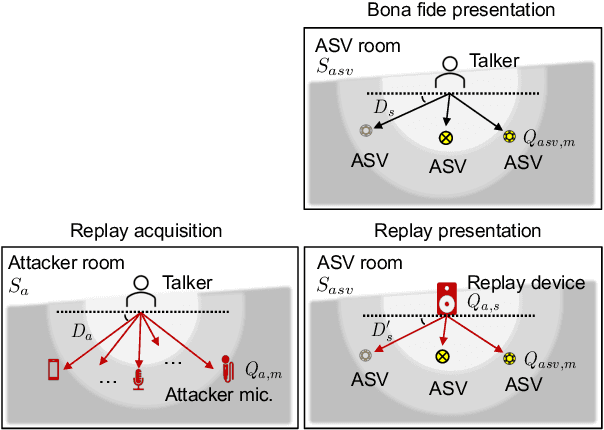
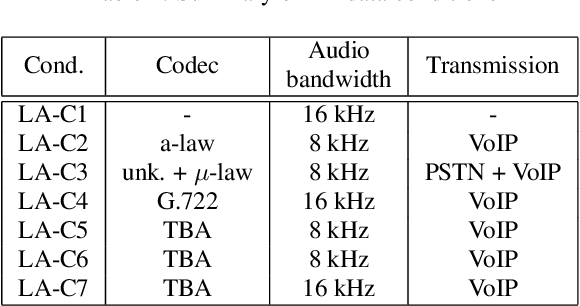
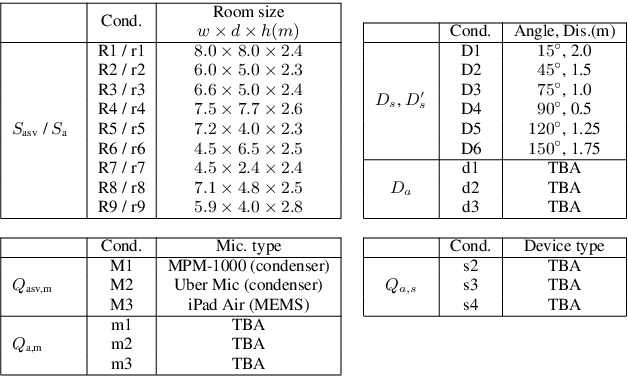
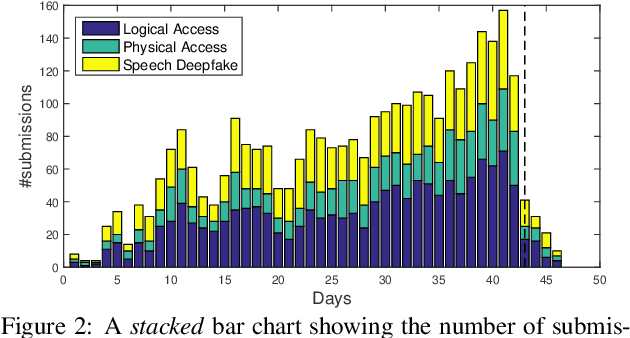
ASVspoof 2021 is the forth edition in the series of bi-annual challenges which aim to promote the study of spoofing and the design of countermeasures to protect automatic speaker verification systems from manipulation. In addition to a continued focus upon logical and physical access tasks in which there are a number of advances compared to previous editions, ASVspoof 2021 introduces a new task involving deepfake speech detection. This paper describes all three tasks, the new databases for each of them, the evaluation metrics, four challenge baselines, the evaluation platform and a summary of challenge results. Despite the introduction of channel and compression variability which compound the difficulty, results for the logical access and deepfake tasks are close to those from previous ASVspoof editions. Results for the physical access task show the difficulty in detecting attacks in real, variable physical spaces. With ASVspoof 2021 being the first edition for which participants were not provided with any matched training or development data and with this reflecting real conditions in which the nature of spoofed and deepfake speech can never be predicated with confidence, the results are extremely encouraging and demonstrate the substantial progress made in the field in recent years.
Predicting pairwise preferences between TTS audio stimuli using parallel ratings data and anti-symmetric twin neural networks
Sep 22, 2022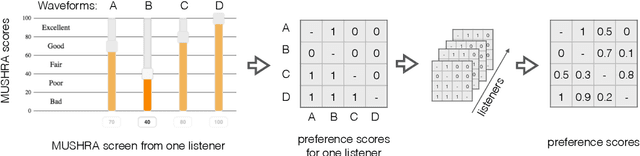
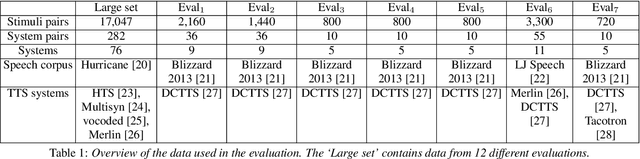
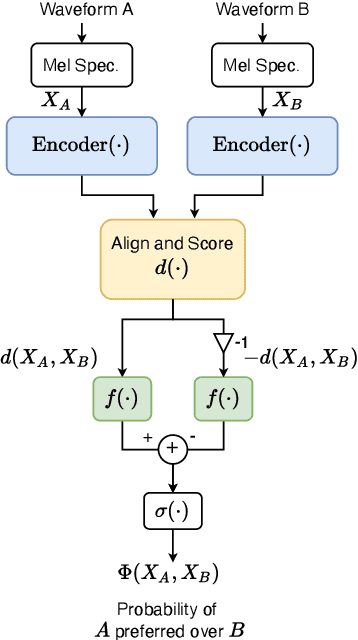
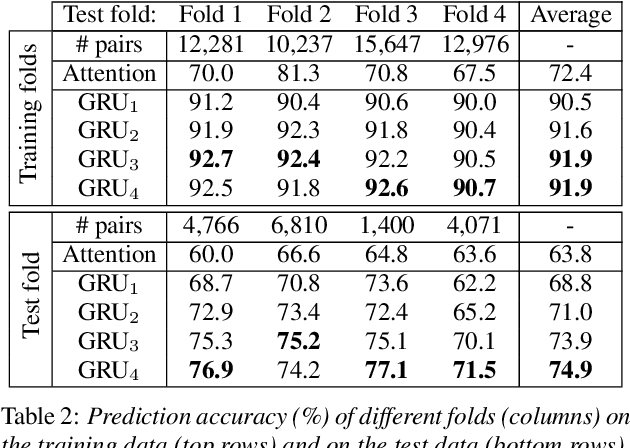
Automatically predicting the outcome of subjective listening tests is a challenging task. Ratings may vary from person to person even if preferences are consistent across listeners. While previous work has focused on predicting listeners' ratings (mean opinion scores) of individual stimuli, we focus on the simpler task of predicting subjective preference given two speech stimuli for the same text. We propose a model based on anti-symmetric twin neural networks, trained on pairs of waveforms and their corresponding preference scores. We explore both attention and recurrent neural nets to account for the fact that stimuli in a pair are not time aligned. To obtain a large training set we convert listeners' ratings from MUSHRA tests to values that reflect how often one stimulus in the pair was rated higher than the other. Specifically, we evaluate performance on data obtained from twelve MUSHRA evaluations conducted over five years, containing different TTS systems, built from data of different speakers. Our results compare favourably to a state-of-the-art model trained to predict MOS scores.