 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speaker and Direction Inferred Dual-channel Speech Separation
Feb 08, 2021
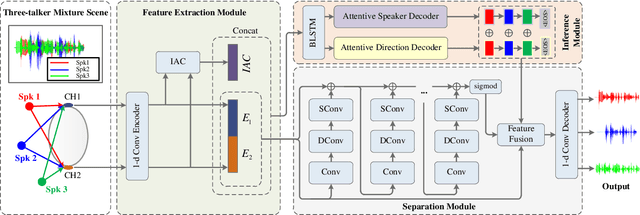
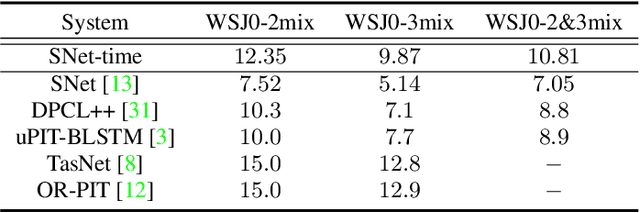
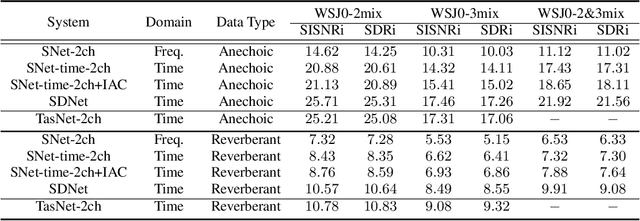
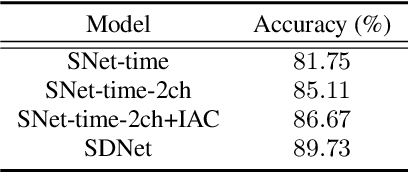
Most speech separation methods, trying to separate all channel sources simultaneously, are still far from having enough general- ization capabilities for real scenarios where the number of input sounds is usually uncertain and even dynamic. In this work, we employ ideas from auditory attention with two ears and propose a speaker and direction inferred speech separation network (dubbed SDNet) to solve the cocktail party problem. Specifically, our SDNet first parses out the respective perceptual representations with their speaker and direction characteristics from the mixture of the scene in a sequential manner. Then, the perceptual representations are utilized to attend to each corresponding speech. Our model gener- ates more precise perceptual representations with the help of spatial features and successfully deals with the problem of the unknown number of sources and the selection of outputs. The experiments on standard fully-overlapped speech separation benchmarks, WSJ0- 2mix, WSJ0-3mix, and WSJ0-2&3mix, show the effectiveness, and our method achieves SDR improvements of 25.31 dB, 17.26 dB, and 21.56 dB under anechoic settings. Our codes will be released at https://github.com/aispeech-lab/SDNet.
Fast Development of ASR in African Languages using Self Supervised Speech Representation Learning
Mar 16, 2021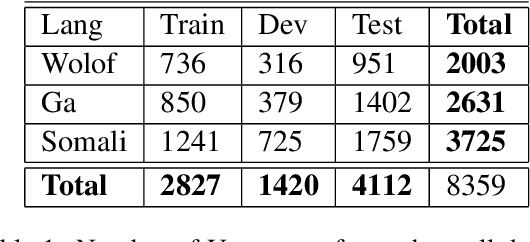
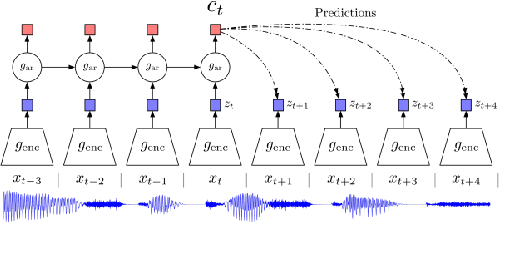
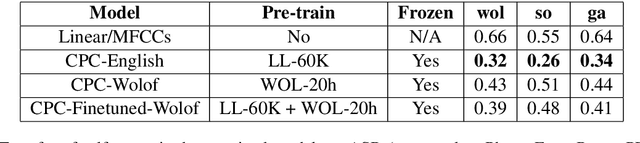
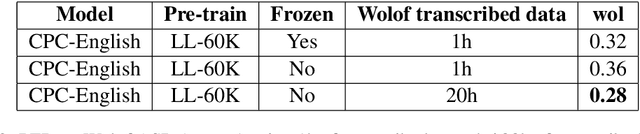
This paper describes the results of an informal collaboration launched during the African Master of Machine Intelligence (AMMI) in June 2020. After a series of lectures and labs on speech data collection using mobile applications and on self-supervised representation learning from speech, a small group of students and the lecturer continued working on automatic speech recognition (ASR) project for three languages: Wolof, Ga, and Somali. This paper describes how data was collected and ASR systems developed with a small amount (1h) of transcribed speech as training data. In these low resource conditions, pre-training a model on large amounts of raw speech was fundamental for the efficiency of ASR systems developed.
Exploiting Adapters for Cross-lingual Low-resource Speech Recognition
May 18, 2021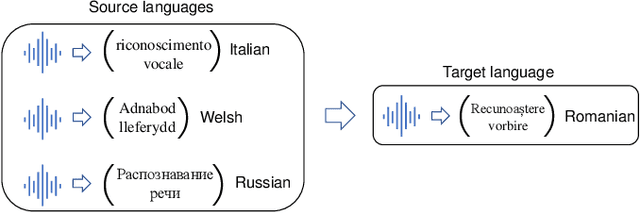
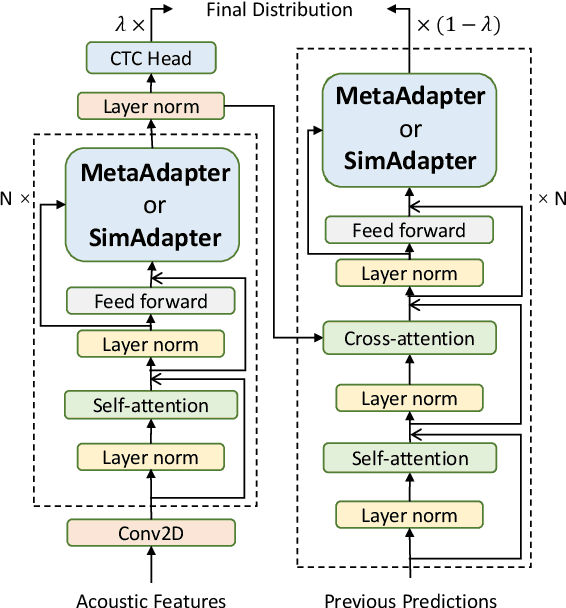
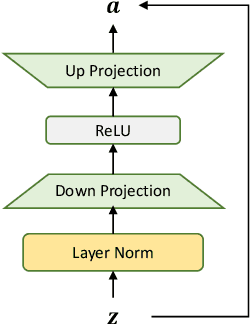
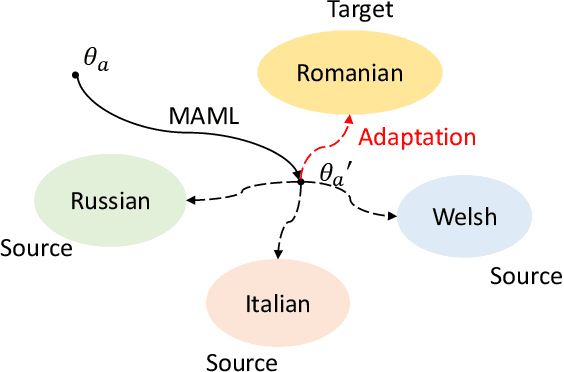
Cross-lingual speech adaptation aims to solve the problem of leveraging multiple rich-resource languages to build models for a low-resource target language. Since the low-resource language has limited training data, speech recognition models can easily overfit. In this paper, we propose to use adapters to investigate the performance of multiple adapters for parameter-efficient cross-lingual speech adaptation. Based on our previous MetaAdapter that implicitly leverages adapters, we propose a novel algorithms called SimAdapter for explicitly learning knowledge from adapters. Our algorithm leverages adapters which can be easily integrated into the Transformer structure.MetaAdapter leverages meta-learning to transfer the general knowledge from training data to the test language. SimAdapter aims to learn the similarities between the source and target languages during fine-tuning using the adapters. We conduct extensive experiments on five-low-resource languages in Common Voice dataset. Results demonstrate that our MetaAdapter and SimAdapter methods can reduce WER by 2.98% and 2.55% with only 2.5% and 15.5% of trainable parameters compared to the strong full-model fine-tuning baseline. Moreover, we also show that these two novel algorithms can be integrated for better performance with up to 3.55% relative WER reduction.
Computing with Hypervectors for Efficient Speaker Identification
Aug 28, 2022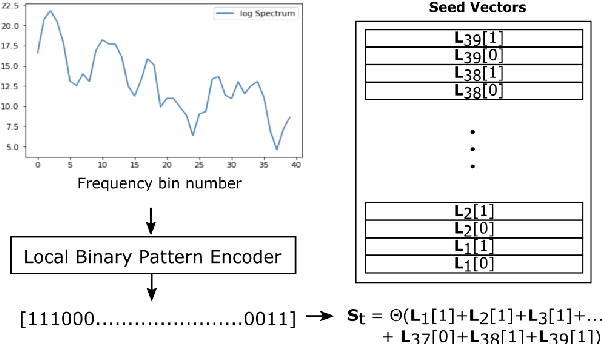

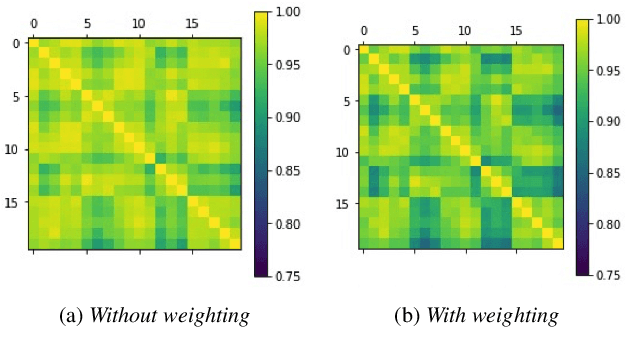
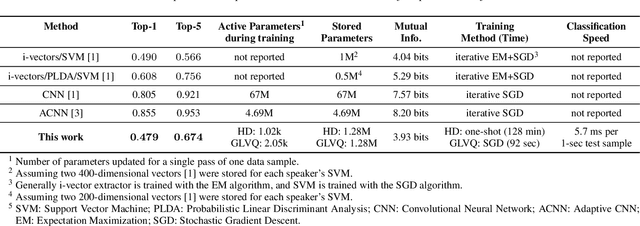
We introduce a method to identify speakers by computing with high-dimensional random vectors. Its strengths are simplicity and speed. With only 1.02k active parameters and a 128-minute pass through the training data we achieve Top-1 and Top-5 scores of 31% and 52% on the VoxCeleb1 dataset of 1,251 speakers. This is in contrast to CNN models requiring several million parameters and orders of magnitude higher computational complexity for only a 2$\times$ gain in discriminative power as measured in mutual information. An additional 92 seconds of training with Generalized Learning Vector Quantization (GLVQ) raises the scores to 48% and 67%. A trained classifier classifies 1 second of speech in 5.7 ms. All processing was done on standard CPU-based machines.
WaDeNet: Wavelet Decomposition based CNN for Speech Processing
Nov 11, 2020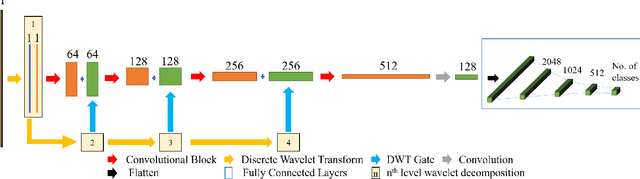
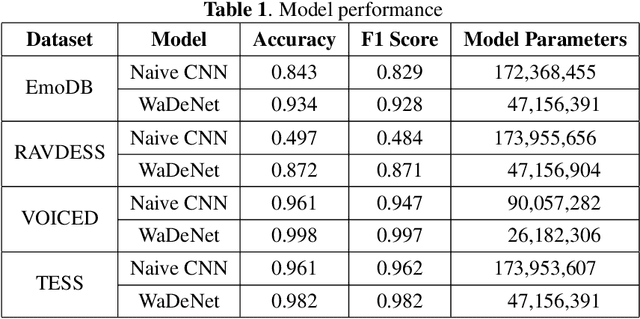
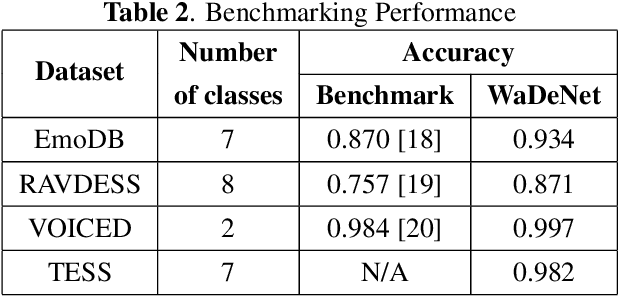
Existing speech processing systems consist of different modules, individually optimized for a specific task such as acoustic modelling or feature extraction. In addition to not assuring optimality of the system, the disjoint nature of current speech processing systems make them unsuitable for ubiquitous health applications. We propose WaDeNet, an end-to-end model for mobile speech processing. In order to incorporate spectral features, WaDeNet embeds wavelet decomposition of the speech signal within the architecture. This allows WaDeNet to learn from spectral features in an end-to-end manner, thus alleviating the need for feature extraction and successive modules that are currently present in speech processing systems. WaDeNet outperforms the current state of the art in datasets that involve speech for mobile health applications such as non-invasive emotion recognition. WaDeNet achieves an average increase in accuracy of 6.36% when compared to the existing state of the art models. Additionally, WaDeNet is considerably lighter than a simple CNNs with a similar architecture.
Visual Speech Enhancement Without A Real Visual Stream
Dec 20, 2020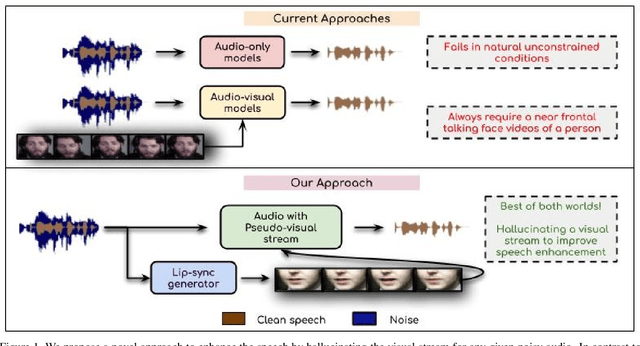

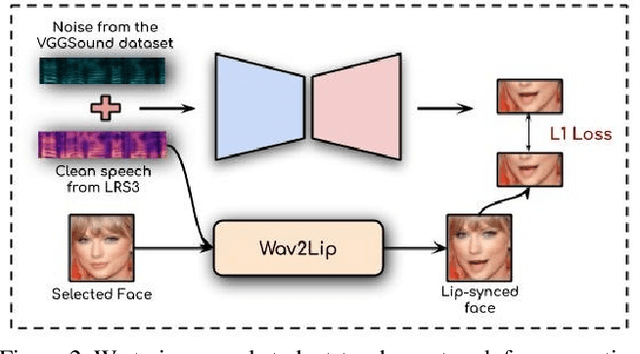
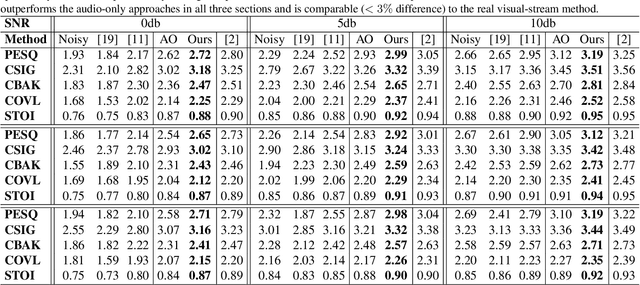
In this work, we re-think the task of speech enhancement in unconstrained real-world environments. Current state-of-the-art methods use only the audio stream and are limited in their performance in a wide range of real-world noises. Recent works using lip movements as additional cues improve the quality of generated speech over "audio-only" methods. But, these methods cannot be used for several applications where the visual stream is unreliable or completely absent. We propose a new paradigm for speech enhancement by exploiting recent breakthroughs in speech-driven lip synthesis. Using one such model as a teacher network, we train a robust student network to produce accurate lip movements that mask away the noise, thus acting as a "visual noise filter". The intelligibility of the speech enhanced by our pseudo-lip approach is comparable (< 3% difference) to the case of using real lips. This implies that we can exploit the advantages of using lip movements even in the absence of a real video stream. We rigorously evaluate our model using quantitative metrics as well as human evaluations. Additional ablation studies and a demo video on our website containing qualitative comparisons and results clearly illustrate the effectiveness of our approach. We provide a demo video which clearly illustrates the effectiveness of our proposed approach on our website: \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/visual-speech-enhancement-without-a-real-visual-stream}. The code and models are also released for future research: \url{https://github.com/Sindhu-Hegde/pseudo-visual-speech-denoising}.
Enhancing the Intelligibility of Cleft Lip and Palate Speech using Cycle-consistent Adversarial Networks
Jan 30, 2021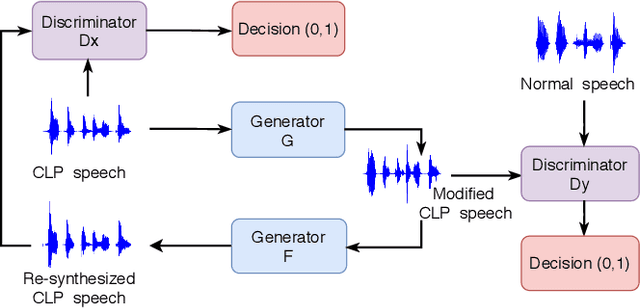
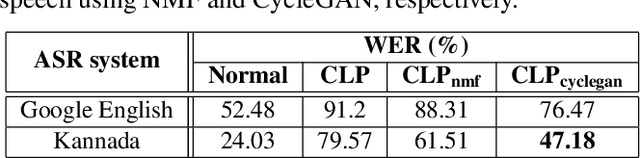
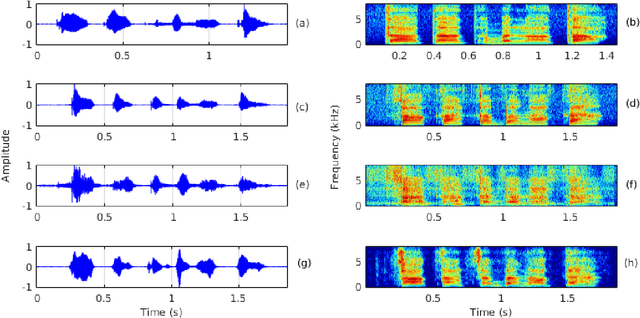
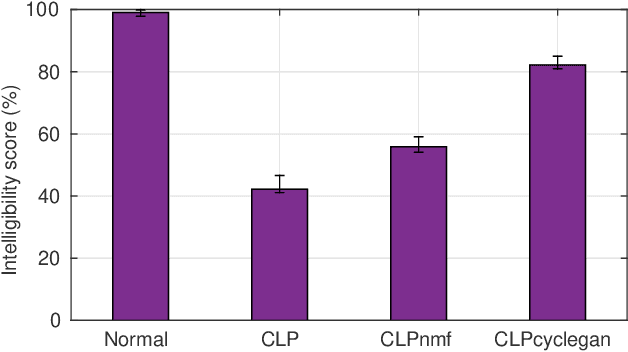
Cleft lip and palate (CLP) refer to a congenital craniofacial condition that causes various speech-related disorders. As a result of structural and functional deformities, the affected subjects' speech intelligibility is significantly degraded, limiting the accessibility and usability of speech-controlled devices. Towards addressing this problem, it is desirable to improve the CLP speech intelligibility. Moreover, it would be useful during speech therapy. In this study, the cycle-consistent adversarial network (CycleGAN) method is exploited for improving CLP speech intelligibility. The model is trained on native Kannada-speaking childrens' speech data. The effectiveness of the proposed approach is also measured using automatic speech recognition performance. Further, subjective evaluation is performed, and those results also confirm the intelligibility improvement in the enhanced speech over the original.
Speaker Separation Using Speaker Inventories and Estimated Speech
Oct 20, 2020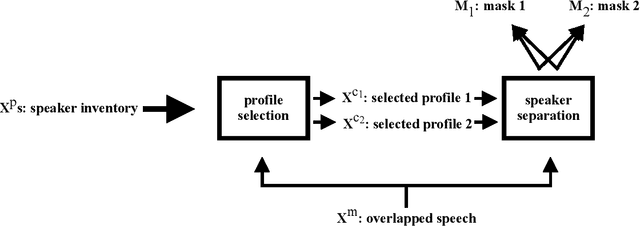
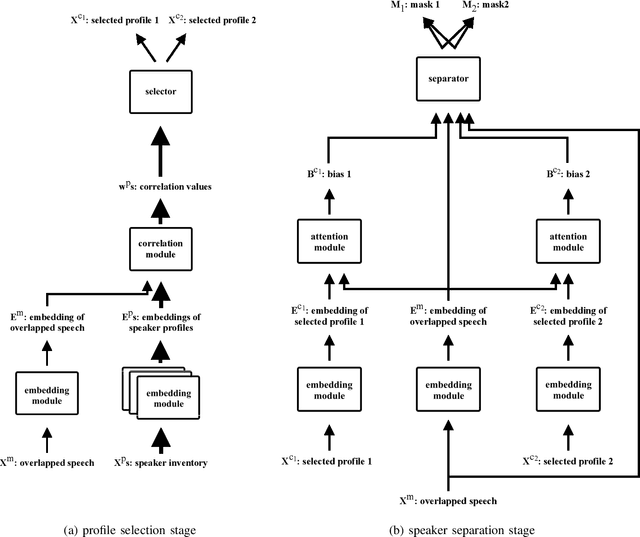
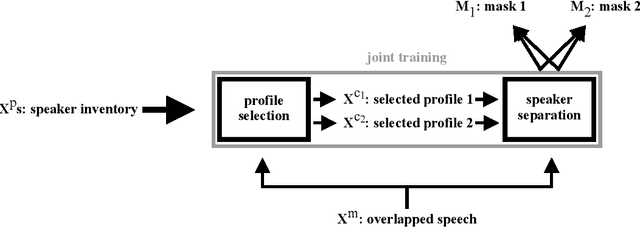
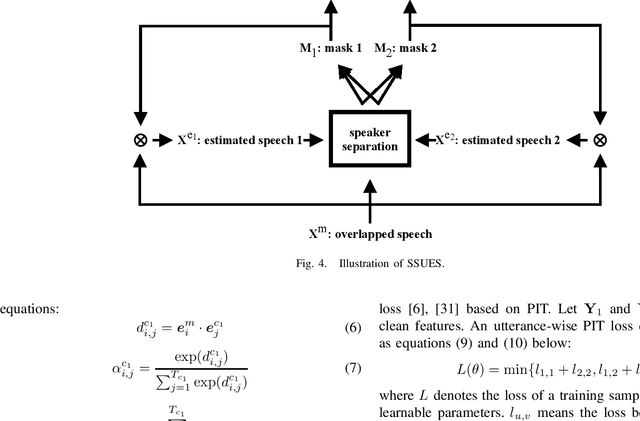
We propose speaker separation using speaker inventories and estimated speech (SSUSIES), a framework leveraging speaker profiles and estimated speech for speaker separation. SSUSIES contains two methods, speaker separation using speaker inventories (SSUSI) and speaker separation using estimated speech (SSUES). SSUSI performs speaker separation with the help of speaker inventory. By combining the advantages of permutation invariant training (PIT) and speech extraction, SSUSI significantly outperforms conventional approaches. SSUES is a widely applicable technique that can substantially improve speaker separation performance using the output of first-pass separation. We evaluate the models on both speaker separation and speech recognition metrics.
Bridging the Modality Gap for Speech-to-Text Translation
Oct 28, 2020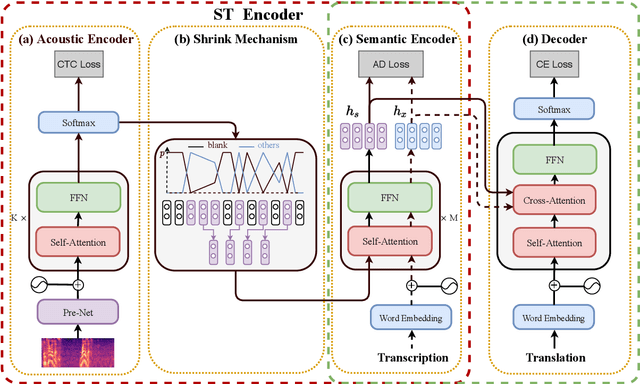
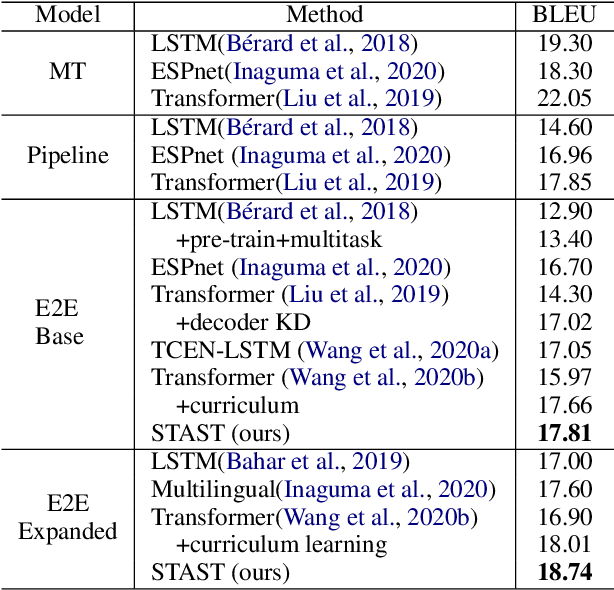

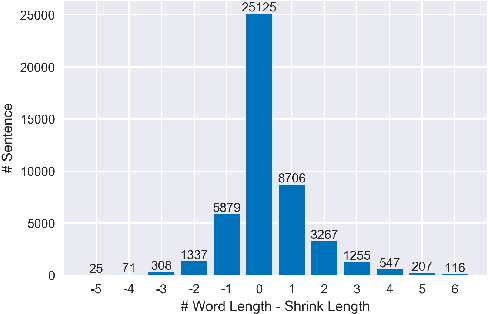
End-to-end speech translation aims to translate speech in one language into text in another language via an end-to-end way. Most existing methods employ an encoder-decoder structure with a single encoder to learn acoustic representation and semantic information simultaneously, which ignores the speech-and-text modality differences and makes the encoder overloaded, leading to great difficulty in learning such a model. To address these issues, we propose a Speech-to-Text Adaptation for Speech Translation (STAST) model which aims to improve the end-to-end model performance by bridging the modality gap between speech and text. Specifically, we decouple the speech translation encoder into three parts and introduce a shrink mechanism to match the length of speech representation with that of the corresponding text transcription. To obtain better semantic representation, we completely integrate a text-based translation model into the STAST so that two tasks can be trained in the same latent space. Furthermore, we introduce a cross-modal adaptation method to close the distance between speech and text representation. Experimental results on English-French and English-German speech translation corpora have shown that our model significantly outperforms strong baselines, and achieves the new state-of-the-art performance.
Learning ASR pathways: A sparse multilingual ASR model
Sep 13, 2022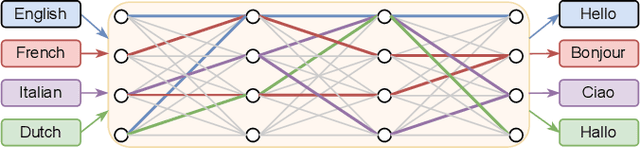
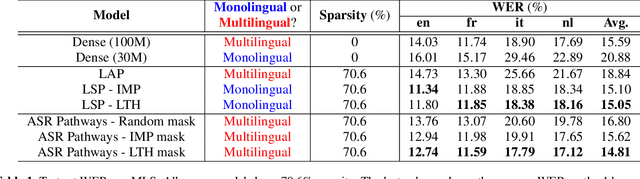
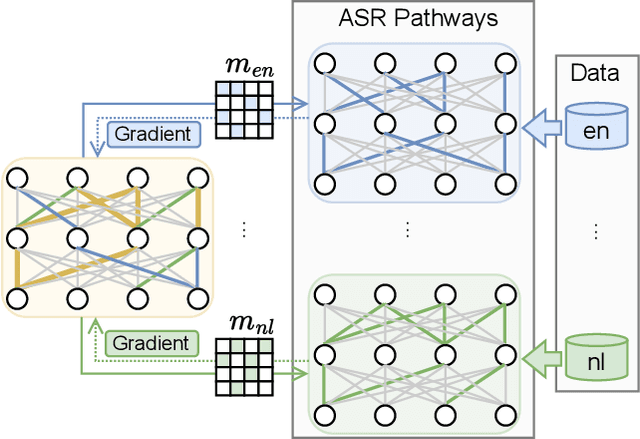
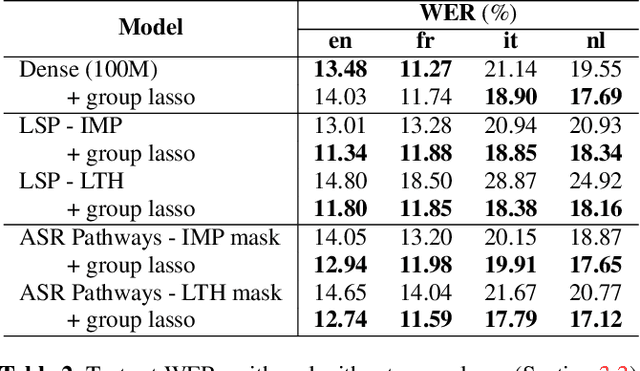
Neural network pruning can be effectively applied to compress automatic speech recognition (ASR) models. However, in multilingual ASR, performing language-agnostic pruning may lead to severe performance degradation on some languages because language-agnostic pruning masks may not fit all languages and discard important language-specific parameters. In this work, we present ASR pathways, a sparse multilingual ASR model that activates language-specific sub-networks ("pathways"), such that the parameters for each language are learned explicitly. With the overlapping sub-networks, the shared parameters can also enable knowledge transfer for lower resource languages via joint multilingual training. We propose a novel algorithm to learn ASR pathways, and evaluate the proposed method on 4 languages with a streaming RNN-T model. Our proposed ASR pathways outperform both dense models (-5.0% average WER) and a language-agnostically pruned model (-21.4% average WER), and provide better performance on low-resource languages compared to the monolingual sparse models.