 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Data Bootstrapping Approaches to Improve Low Resource Abusive Language Detection for Indic Languages
Apr 26, 2022
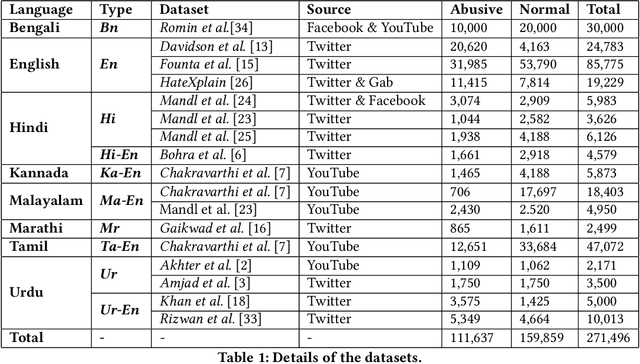
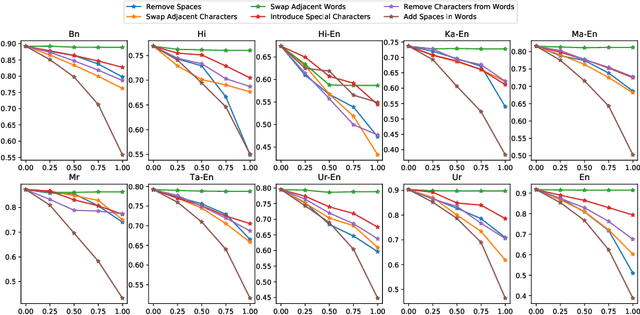
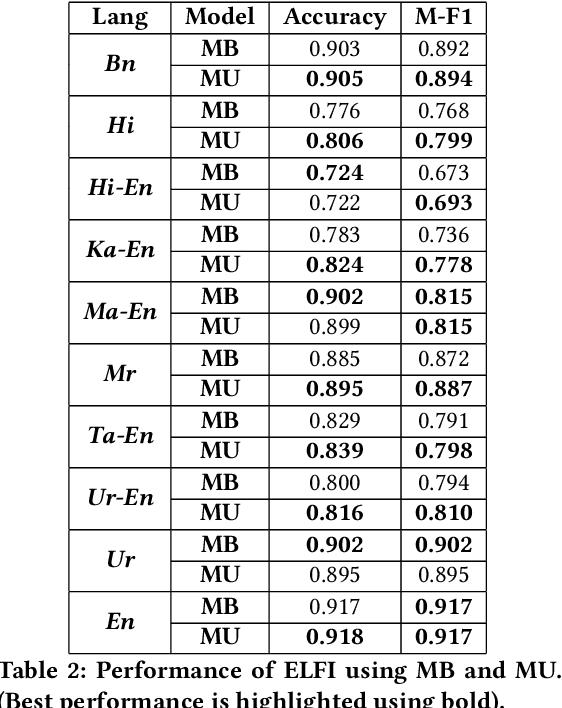
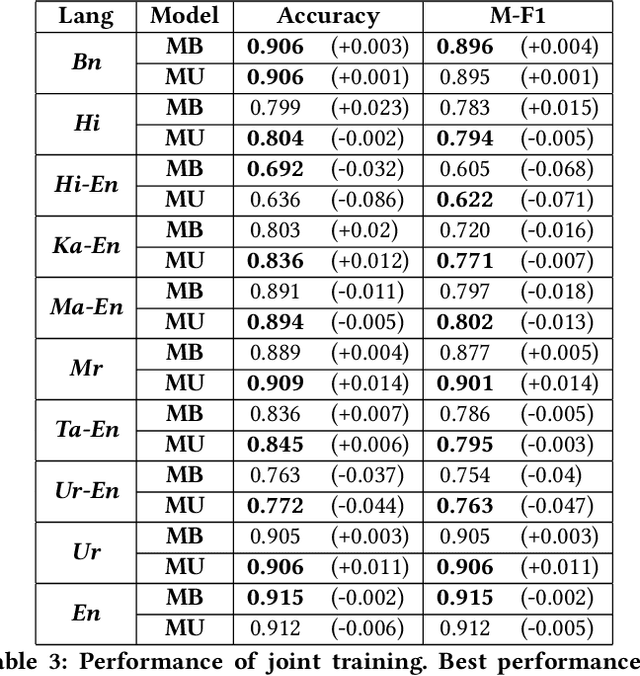
Abusive language is a growing concern in many social media platforms. Repeated exposure to abusive speech has created physiological effects on the target users. Thus, the problem of abusive language should be addressed in all forms for online peace and safety. While extensive research exists in abusive speech detection, most studies focus on English. Recently, many smearing incidents have occurred in India, which provoked diverse forms of abusive speech in online space in various languages based on the geographic location. Therefore it is essential to deal with such malicious content. In this paper, to bridge the gap, we demonstrate a large-scale analysis of multilingual abusive speech in Indic languages. We examine different interlingual transfer mechanisms and observe the performance of various multilingual models for abusive speech detection for eight different Indic languages. We also experiment to show how robust these models are on adversarial attacks. Finally, we conduct an in-depth error analysis by looking into the models' misclassified posts across various settings. We have made our code and models public for other researchers.
Longitudinal Sentiment Analyses for Radicalization Research: Intertemporal Dynamics on Social Media Platforms and their Implications
Oct 01, 2022This discussion paper demonstrates how longitudinal sentiment analyses can depict intertemporal dynamics on social media platforms, what challenges are inherent and how further research could benefit from a longitudinal perspective. Furthermore and since tools for sentiment analyses shall simplify and accelerate the analytical process regarding qualitative data at acceptable inter-rater reliability, their applicability in the context of radicalization research will be examined regarding the Tweets collected on January 6th 2021, the day of the storming of the U.S. Capitol in Washington. Therefore, a total of 49,350 Tweets will be analyzed evenly distributed within three different sequences: before, during and after the U.S. Capitol in Washington was stormed. These sequences highlight the intertemporal dynamics within comments on social media platforms as well as the possible benefits of a longitudinal perspective when using conditional means and conditional variances. Limitations regarding the identification of supporters of such events and associated hate speech as well as common application errors will be demonstrated as well. As a result, only under certain conditions a longitudinal sentiment analysis can increase the accuracy of evidence based predictions in the context of radicalization research.
OkwuGbé: End-to-End Speech Recognition for Fon and Igbo
Mar 16, 2021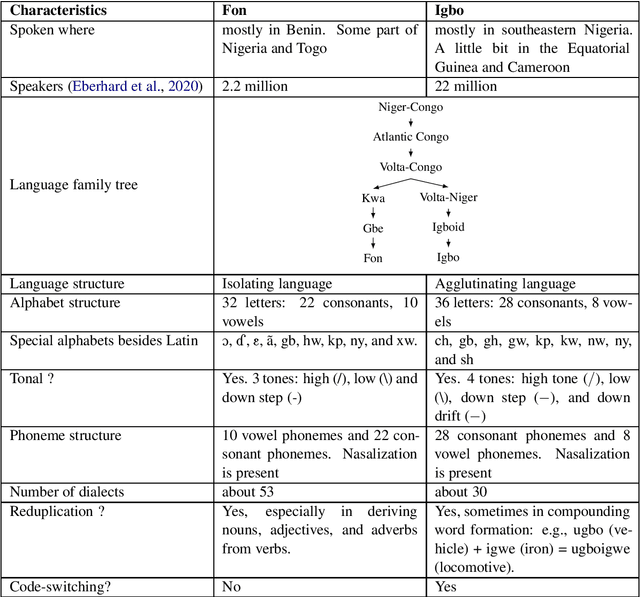
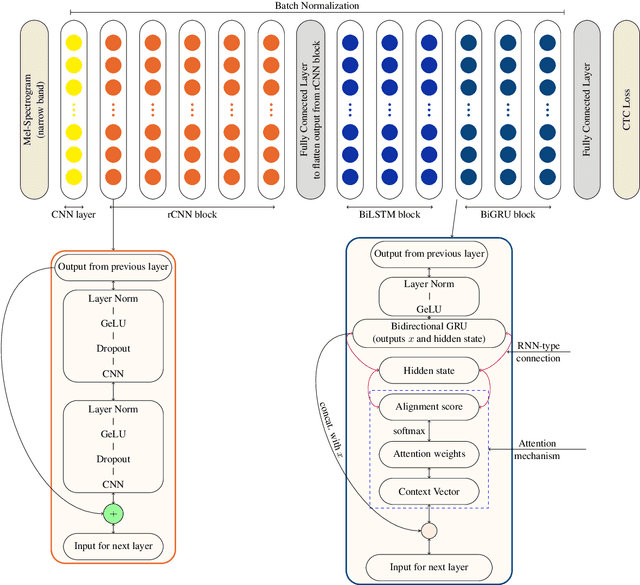
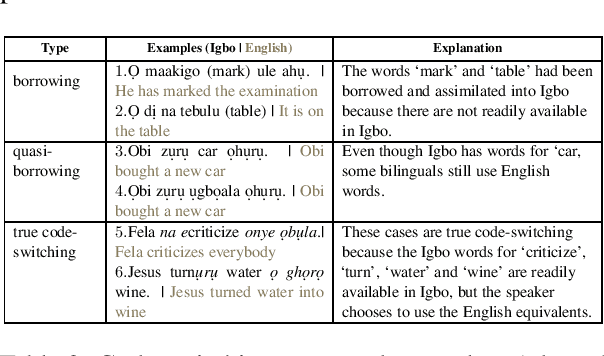
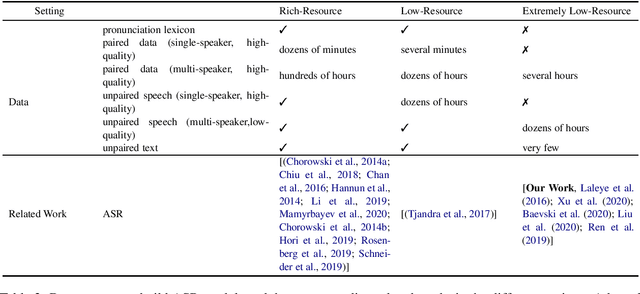
Language is inherent and compulsory for human communication. Whether expressed in a written or spoken way, it ensures understanding between people of the same and different regions. With the growing awareness and effort to include more low-resourced languages in NLP research, African languages have recently been a major subject of research in machine translation, and other text-based areas of NLP. However, there is still very little comparable research in speech recognition for African languages. Interestingly, some of the unique properties of African languages affecting NLP, like their diacritical and tonal complexities, have a major root in their speech, suggesting that careful speech interpretation could provide more intuition on how to deal with the linguistic complexities of African languages for text-based NLP. OkwuGb\'e is a step towards building speech recognition systems for African low-resourced languages. Using Fon and Igbo as our case study, we conduct a comprehensive linguistic analysis of each language and describe the creation of end-to-end, deep neural network-based speech recognition models for both languages. We present a state-of-art ASR model for Fon, as well as benchmark ASR model results for Igbo. Our linguistic analyses (for Fon and Igbo) provide valuable insights and guidance into the creation of speech recognition models for other African low-resourced languages, as well as guide future NLP research for Fon and Igbo. The Fon and Igbo models source code have been made publicly available.
Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Aug 04, 2021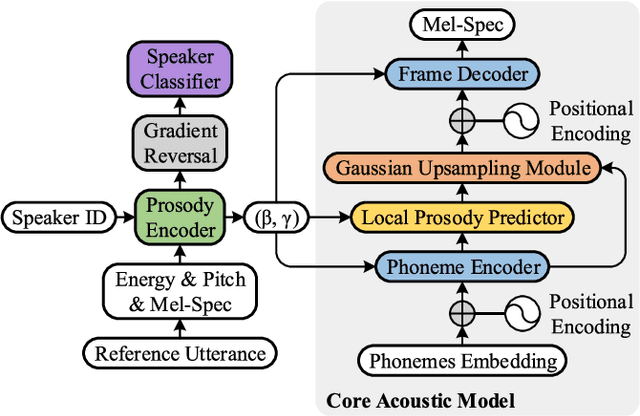

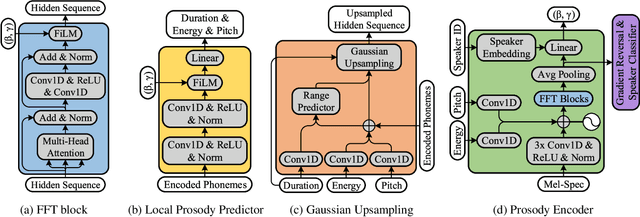

This paper presents Daft-Exprt, a multi-speaker acoustic model advancing the state-of-the-art on inter-speaker and inter-text prosody transfer. This improvement is achieved using FiLM conditioning layers, alongside adversarial training that encourages disentanglement between prosodic information and speaker identity. The acoustic model inherits attractive qualities from FastSpeech 2, such as fast inference and local prosody attributes prediction for finer grained control over generation. Experimental results show that Daft-Exprt significantly outperforms strong baselines on prosody transfer tasks, while yielding naturalness comparable to state-of-the-art expressive models. Moreover, results indicate that adversarial training effectively discards speaker identity information from the prosody representation, which ensures Daft-Exprt will consistently generate speech with the desired voice. We publicly release our code and provide speech samples from our experiments.
Dropout Regularization for Self-Supervised Learning of Transformer Encoder Speech Representation
Jul 09, 2021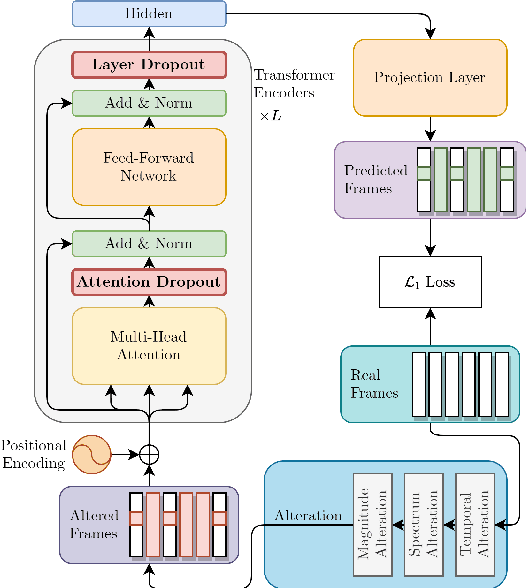
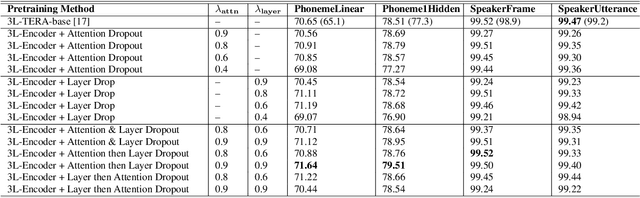

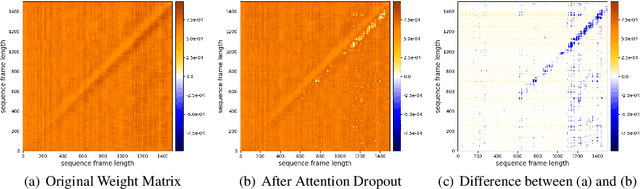
Predicting the altered acoustic frames is an effective way of self-supervised learning for speech representation. However, it is challenging to prevent the pretrained model from overfitting. In this paper, we proposed to introduce two dropout regularization methods into the pretraining of transformer encoder: (1) attention dropout, (2) layer dropout. Both of the two dropout methods encourage the model to utilize global speech information, and avoid just copying local spectrum features when reconstructing the masked frames. We evaluated the proposed methods on phoneme classification and speaker recognition tasks. The experiments demonstrate that our dropout approaches achieve competitive results, and improve the performance of classification accuracy on downstream tasks.
Direct Simultaneous Speech-to-Text Translation Assisted by Synchronized Streaming ASR
Jun 11, 2021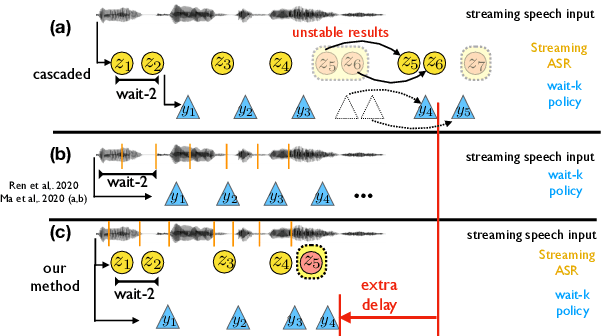
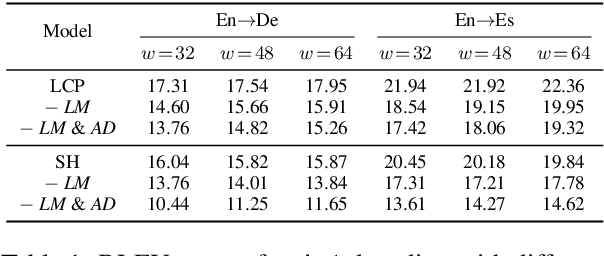
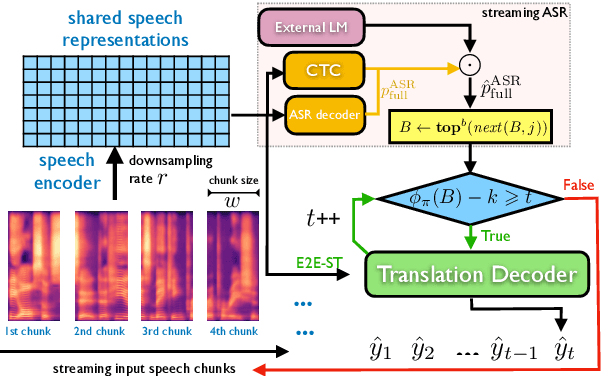
Simultaneous speech-to-text translation is widely useful in many scenarios. The conventional cascaded approach uses a pipeline of streaming ASR followed by simultaneous MT, but suffers from error propagation and extra latency. To alleviate these issues, recent efforts attempt to directly translate the source speech into target text simultaneously, but this is much harder due to the combination of two separate tasks. We instead propose a new paradigm with the advantages of both cascaded and end-to-end approaches. The key idea is to use two separate, but synchronized, decoders on streaming ASR and direct speech-to-text translation (ST), respectively, and the intermediate results of ASR guide the decoding policy of (but is not fed as input to) ST. During training time, we use multitask learning to jointly learn these two tasks with a shared encoder. En-to-De and En-to-Es experiments on the MuSTC dataset demonstrate that our proposed technique achieves substantially better translation quality at similar levels of latency.
Offensive Language and Hate Speech Detection with Deep Learning and Transfer Learning
Aug 06, 2021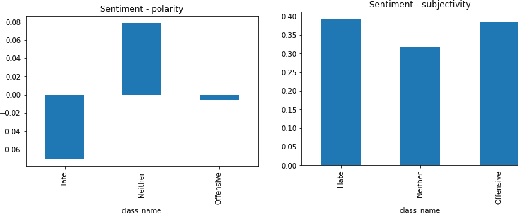

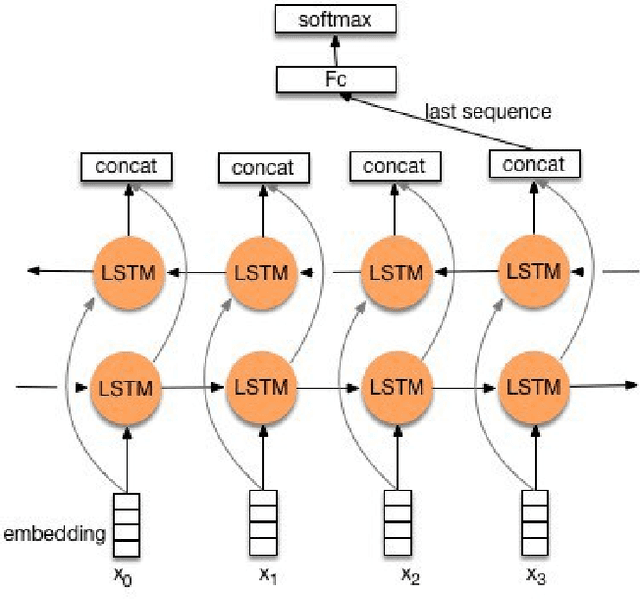
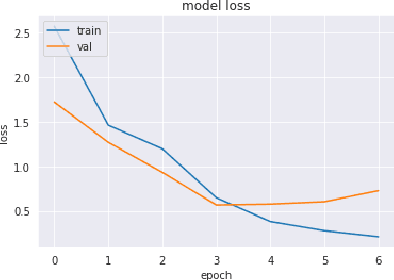
Toxic online speech has become a crucial problem nowadays due to an exponential increase in the use of internet by people from different cultures and educational backgrounds. Differentiating if a text message belongs to hate speech and offensive language is a key challenge in automatic detection of toxic text content. In this paper, we propose an approach to automatically classify tweets into three classes: Hate, offensive and Neither. Using public tweet data set, we first perform experiments to build BI-LSTM models from empty embedding and then we also try the same neural network architecture with pre-trained Glove embedding. Next, we introduce a transfer learning approach for hate speech detection using an existing pre-trained language model BERT (Bidirectional Encoder Representations from Transformers), DistilBert (Distilled version of BERT) and GPT-2 (Generative Pre-Training). We perform hyper parameters tuning analysis of our best model (BI-LSTM) considering different neural network architectures, learn-ratings and normalization methods etc. After tuning the model and with the best combination of parameters, we achieve over 92 percent accuracy upon evaluating it on test data. We also create a class module which contains main functionality including text classification, sentiment checking and text data augmentation. This model could serve as an intermediate module between user and Twitter.
Towards generalisable hate speech detection: a review on obstacles and solutions
Feb 17, 2021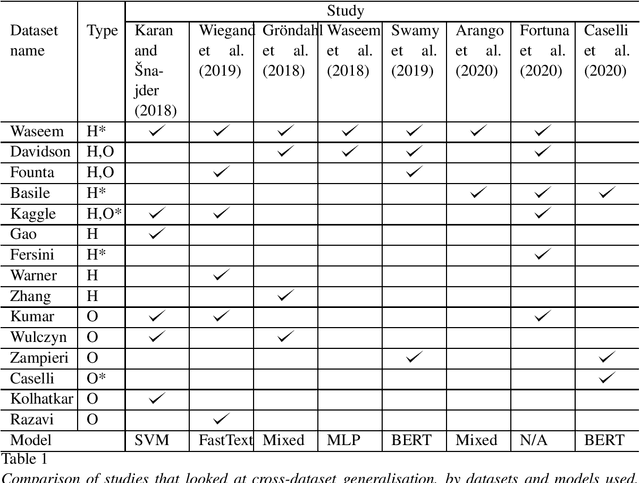
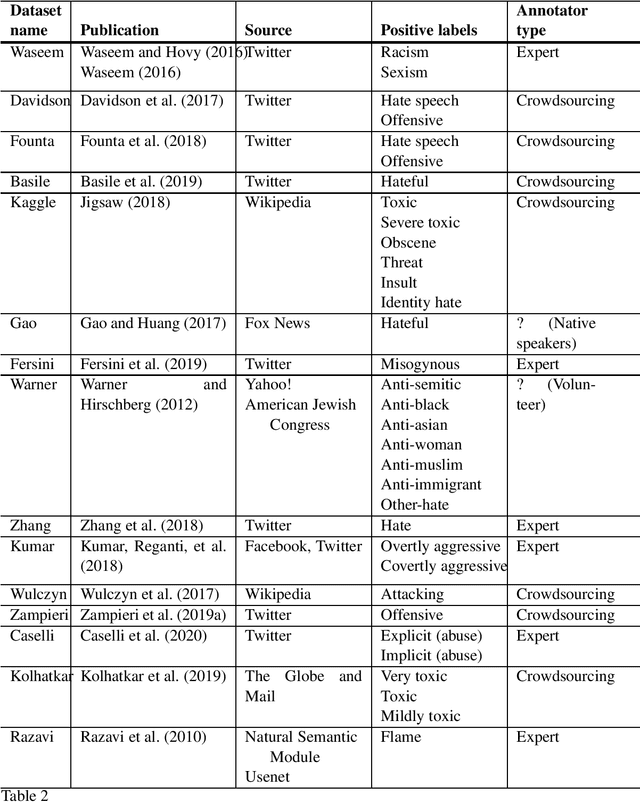
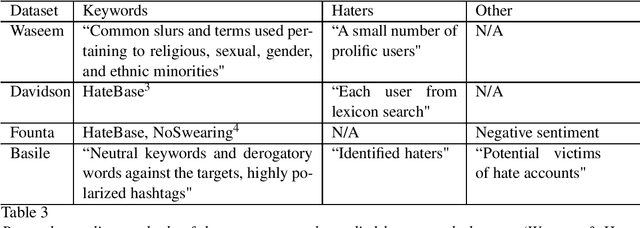
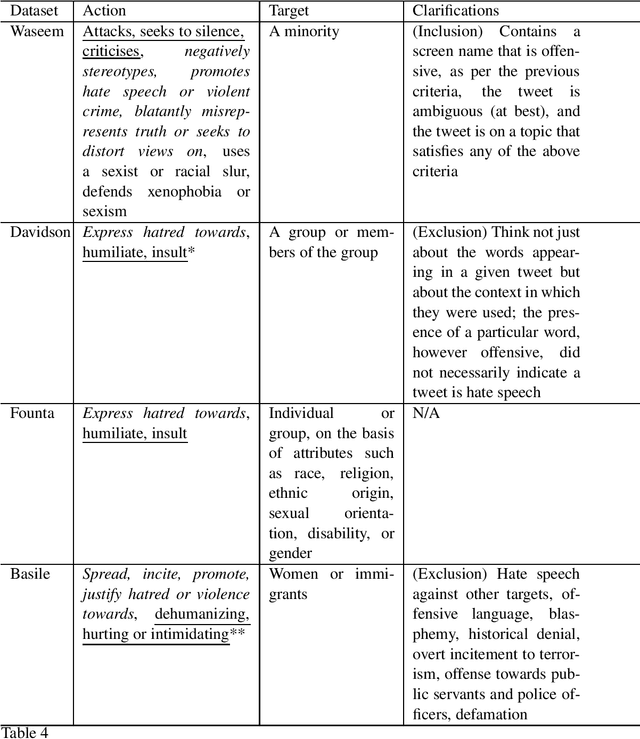
Hate speech is one type of harmful online content which directly attacks or promotes hate towards a group or an individual member based on their actual or perceived aspects of identity, such as ethnicity, religion, and sexual orientation. With online hate speech on the rise, its automatic detection as a natural language processing task is gaining increasing interest. However, it is only recently that it has been shown that existing models generalise poorly to unseen data. This survey paper attempts to summarise how generalisable existing hate speech detection models are, reason why hate speech models struggle to generalise, sums up existing attempts at addressing the main obstacles, and then proposes directions of future research to improve generalisation in hate speech detection.
Overview of the HASOC track at FIRE 2020: Hate Speech and Offensive Content Identification in Indo-European Languages
Aug 12, 2021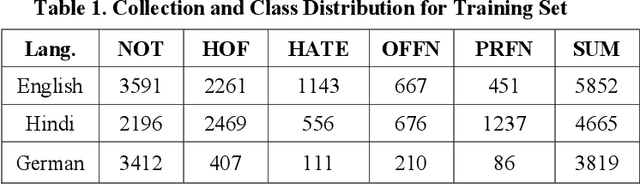
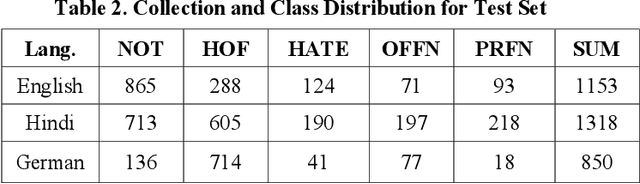
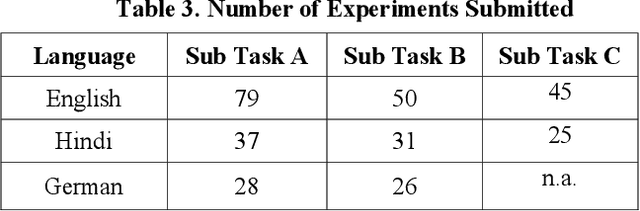
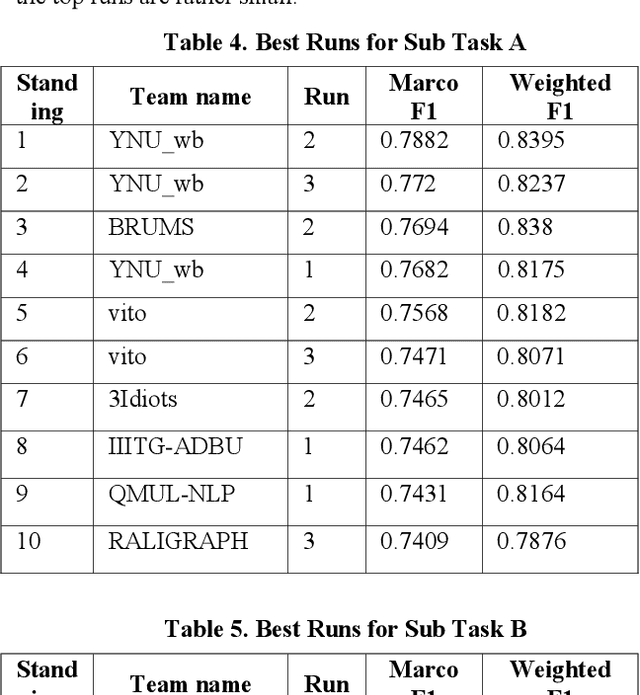
With the growth of social media, the spread of hate speech is also increasing rapidly. Social media are widely used in many countries. Also Hate Speech is spreading in these countries. This brings a need for multilingual Hate Speech detection algorithms. Much research in this area is dedicated to English at the moment. The HASOC track intends to provide a platform to develop and optimize Hate Speech detection algorithms for Hindi, German and English. The dataset is collected from a Twitter archive and pre-classified by a machine learning system. HASOC has two sub-task for all three languages: task A is a binary classification problem (Hate and Not Offensive) while task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY. Overall, 252 runs were submitted by 40 teams. The performance of the best classification algorithms for task A are F1 measures of 0.51, 0.53 and 0.52 for English, Hindi, and German, respectively. For task B, the best classification algorithms achieved F1 measures of 0.26, 0.33 and 0.29 for English, Hindi, and German, respectively. This article presents the tasks and the data development as well as the results. The best performing algorithms were mainly variants of the transformer architecture BERT. However, also other systems were applied with good success
Speech recognition for air traffic control via feature learning and end-to-end training
Nov 04, 2021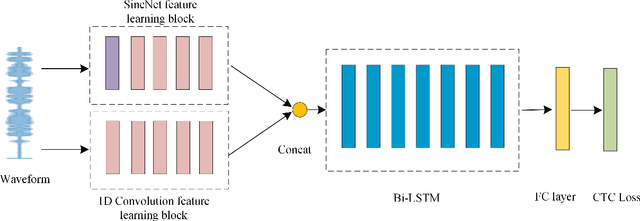
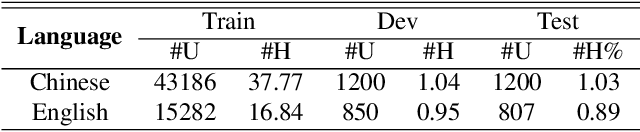
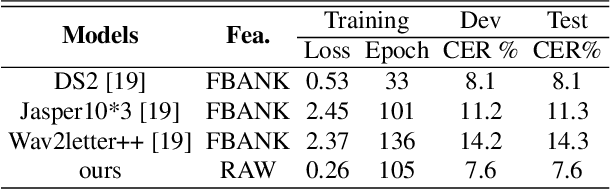
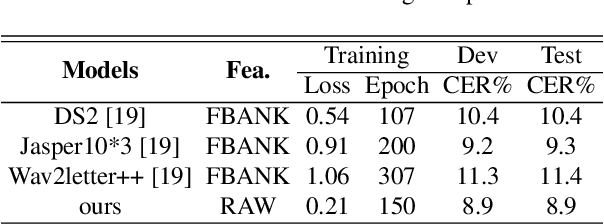
In this work, we propose a new automatic speech recognition (ASR) system based on feature learning and an end-to-end training procedure for air traffic control (ATC) systems. The proposed model integrates the feature learning block, recurrent neural network (RNN), and connectionist temporal classification loss to build an end-to-end ASR model. Facing the complex environments of ATC speech, instead of the handcrafted features, a learning block is designed to extract informative features from raw waveforms for acoustic modeling. Both the SincNet and 1D convolution blocks are applied to process the raw waveforms, whose outputs are concatenated to the RNN layers for the temporal modeling. Thanks to the ability to learn representations from raw waveforms, the proposed model can be optimized in a complete end-to-end manner, i.e., from waveform to text. Finally, the multilingual issue in the ATC domain is also considered to achieve the ASR task by constructing a combined vocabulary of Chinese characters and English letters. The proposed approach is validated on a multilingual real-world corpus (ATCSpeech), and the experimental results demonstrate that the proposed approach outperforms other baselines, achieving a 6.9\% character error rate.