 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Non-Autoregressive TTS with Explicit Duration Modelling for Low-Resource Highly Expressive Speech
Jun 25, 2021
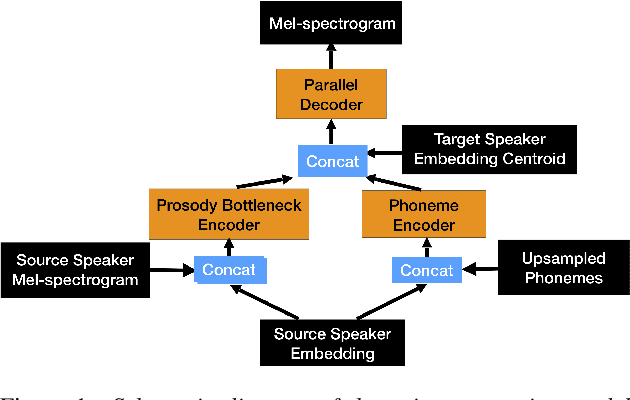
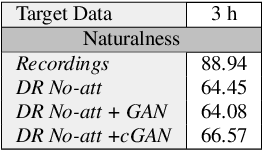
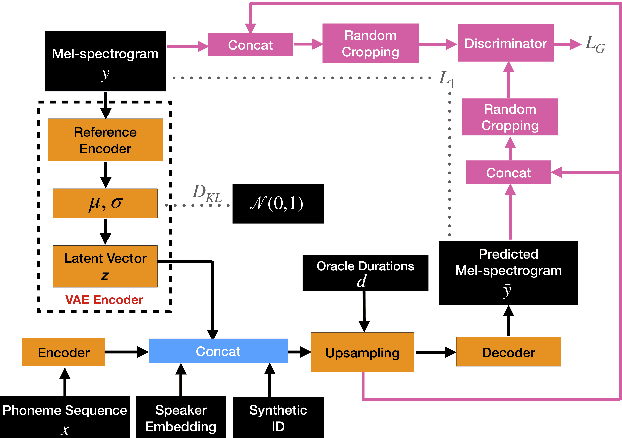
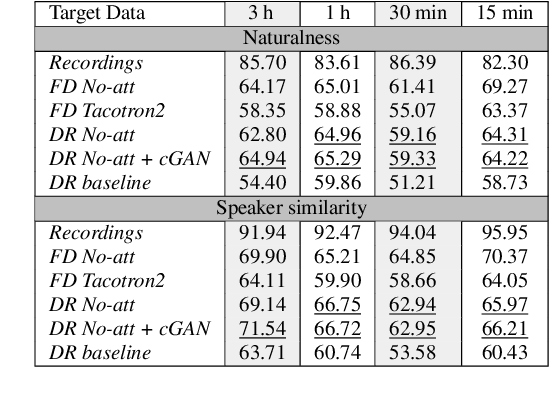
Whilst recent neural text-to-speech (TTS) approaches produce high-quality speech, they typically require a large amount of recordings from the target speaker. In previous work, a 3-step method was proposed to generate high-quality TTS while greatly reducing the amount of data required for training. However, we have observed a ceiling effect in the level of naturalness achievable for highly expressive voices when using this approach. In this paper, we present a method for building highly expressive TTS voices with as little as 15 minutes of speech data from the target speaker. Compared to the current state-of-the-art approach, our proposed improvements close the gap to recordings by 23.3% for naturalness of speech and by 16.3% for speaker similarity. Further, we match the naturalness and speaker similarity of a Tacotron2-based full-data (~10 hours) model using only 15 minutes of target speaker data, whereas with 30 minutes or more, we significantly outperform it. The following improvements are proposed: 1) changing from an autoregressive, attention-based TTS model to a non-autoregressive model replacing attention with an external duration model and 2) an additional Conditional Generative Adversarial Network (cGAN) based fine-tuning step.
Contextual Hate Speech Detection in Code Mixed Text using Transformer Based Approaches
Nov 01, 2021
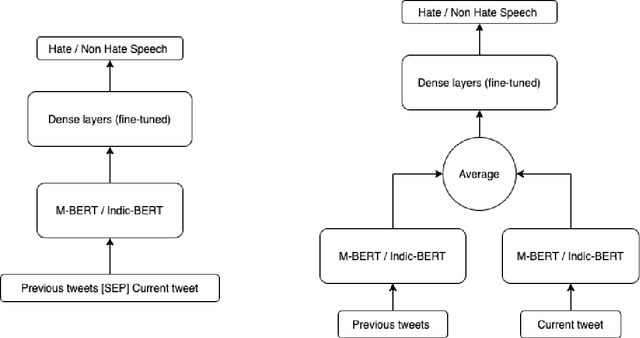
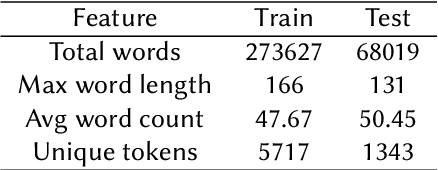
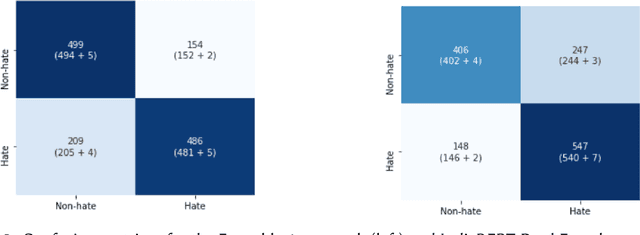
In the recent past, social media platforms have helped people in connecting and communicating to a wider audience. But this has also led to a drastic increase in cyberbullying. It is essential to detect and curb hate speech to keep the sanity of social media platforms. Also, code mixed text containing more than one language is frequently used on these platforms. We, therefore, propose automated techniques for hate speech detection in code mixed text from scraped Twitter. We specifically focus on code mixed English-Hindi text and transformer-based approaches. While regular approaches analyze the text independently, we also make use of content text in the form of parent tweets. We try to evaluate the performances of multilingual BERT and Indic-BERT in single-encoder and dual-encoder settings. The first approach is to concatenate the target text and context text using a separator token and get a single representation from the BERT model. The second approach encodes the two texts independently using a dual BERT encoder and the corresponding representations are averaged. We show that the dual-encoder approach using independent representations yields better performance. We also employ simple ensemble methods to further improve the performance. Using these methods we report the best F1 score of 73.07% on the HASOC 2021 ICHCL code mixed data set.
Generative Speech Coding with Predictive Variance Regularization
Feb 18, 2021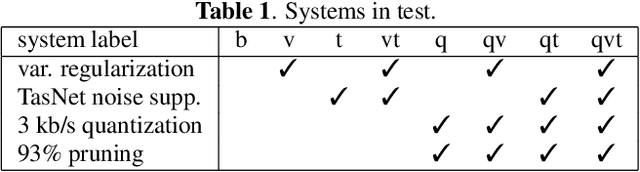
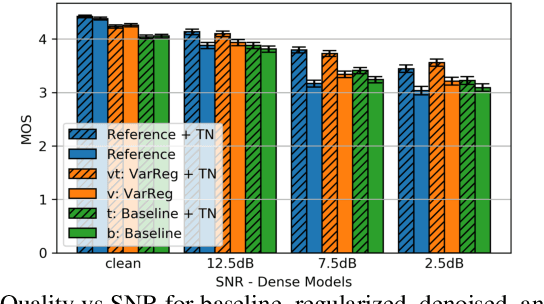
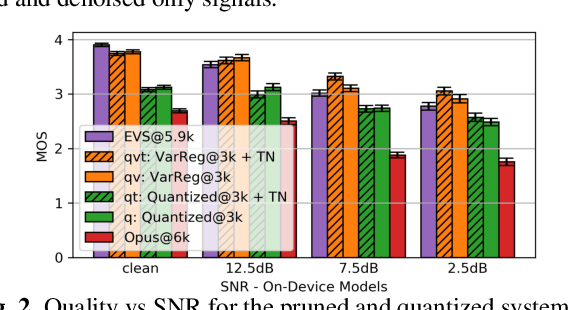
The recent emergence of machine-learning based generative models for speech suggests a significant reduction in bit rate for speech codecs is possible. However, the performance of generative models deteriorates significantly with the distortions present in real-world input signals. We argue that this deterioration is due to the sensitivity of the maximum likelihood criterion to outliers and the ineffectiveness of modeling a sum of independent signals with a single autoregressive model. We introduce predictive-variance regularization to reduce the sensitivity to outliers, resulting in a significant increase in performance. We show that noise reduction to remove unwanted signals can significantly increase performance. We provide extensive subjective performance evaluations that show that our system based on generative modeling provides state-of-the-art coding performance at 3 kb/s for real-world speech signals at reasonable computational complexity.
Efficient Speech Emotion Recognition Using Multi-Scale CNN and Attention
Jun 08, 2021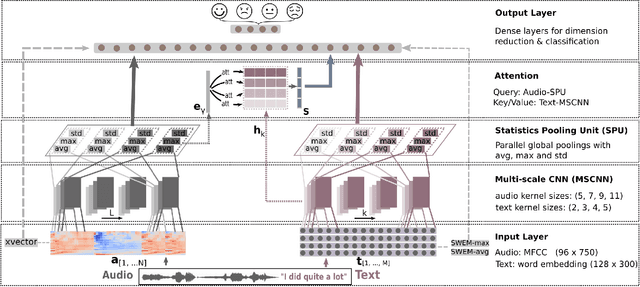
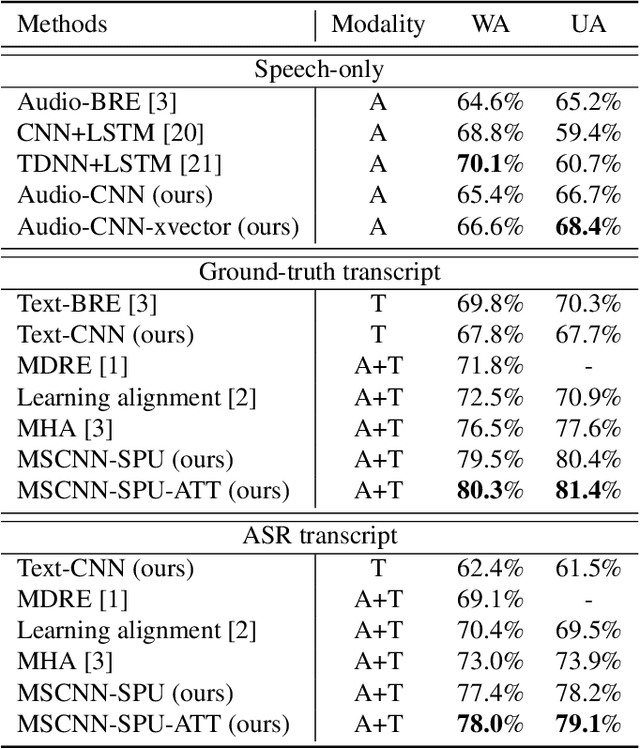

Emotion recognition from speech is a challenging task. Re-cent advances in deep learning have led bi-directional recur-rent neural network (Bi-RNN) and attention mechanism as astandard method for speech emotion recognition, extractingand attending multi-modal features - audio and text, and thenfusing them for downstream emotion classification tasks. Inthis paper, we propose a simple yet efficient neural networkarchitecture to exploit both acoustic and lexical informationfrom speech. The proposed framework using multi-scale con-volutional layers (MSCNN) to obtain both audio and text hid-den representations. Then, a statistical pooling unit (SPU)is used to further extract the features in each modality. Be-sides, an attention module can be built on top of the MSCNN-SPU (audio) and MSCNN (text) to further improve the perfor-mance. Extensive experiments show that the proposed modeloutperforms previous state-of-the-art methods on IEMOCAPdataset with four emotion categories (i.e., angry, happy, sadand neutral) in both weighted accuracy (WA) and unweightedaccuracy (UA), with an improvement of 5.0% and 5.2% respectively under the ASR setting.
* First two authors contributed equally.Accepted by ICASSP 2021
Context-Aware Transformer Transducer for Speech Recognition
Nov 05, 2021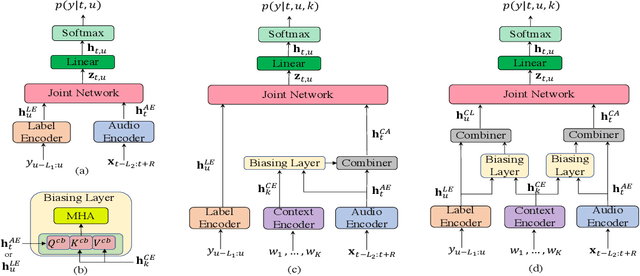

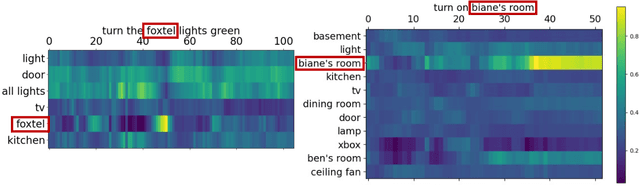
End-to-end (E2E) automatic speech recognition (ASR) systems often have difficulty recognizing uncommon words, that appear infrequently in the training data. One promising method, to improve the recognition accuracy on such rare words, is to latch onto personalized/contextual information at inference. In this work, we present a novel context-aware transformer transducer (CATT) network that improves the state-of-the-art transformer-based ASR system by taking advantage of such contextual signals. Specifically, we propose a multi-head attention-based context-biasing network, which is jointly trained with the rest of the ASR sub-networks. We explore different techniques to encode contextual data and to create the final attention context vectors. We also leverage both BLSTM and pretrained BERT based models to encode contextual data and guide the network training. Using an in-house far-field dataset, we show that CATT, using a BERT based context encoder, improves the word error rate of the baseline transformer transducer and outperforms an existing deep contextual model by 24.2% and 19.4% respectively.
Low Bit-Rate Wideband Speech Coding: A Deep Generative Model based Approach
Feb 04, 2021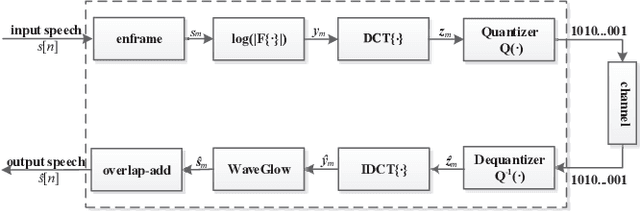



Traditional low bit-rate speech coding approach only handles narrowband speech at 8kHz, which limits further improvements in speech quality. Motivated by recent successful exploration of deep learning methods for image and speech compression, this paper presents a new approach through vector quantization (VQ) of mel-frequency cepstral coefficients (MFCCs) and using a deep generative model called WaveGlow to provide efficient and high-quality speech coding. The coding feature is sorely an 80-dimension MFCCs vector for 16kHz wideband speech, then speech coding at the bit-rate throughout 1000-2000 bit/s could be scalably implemented by applying different VQ schemes for MFCCs vector. This new deep generative network based codec works fast as the WaveGlow model abandons the sample-by-sample autoregressive mechanism. We evaluated this new approach over the multi-speaker TIMIT corpus, and experimental results demonstrate that it provides better speech quality compared with the state-of-the-art classic MELPe codec at lower bit-rate.
Time Domain Adversarial Voice Conversion for ADD 2022
Apr 20, 2022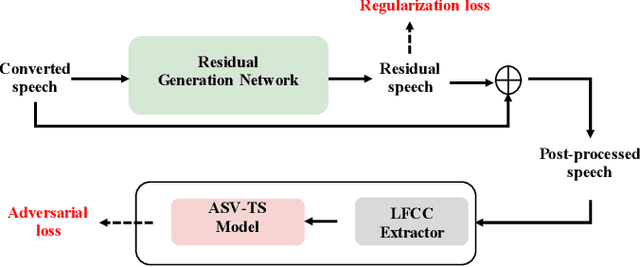

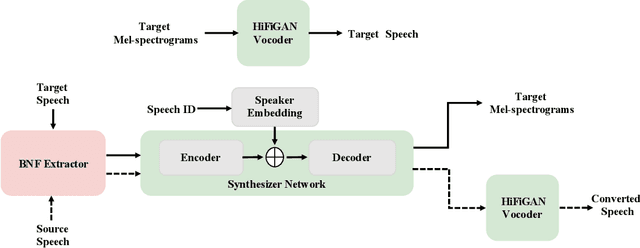
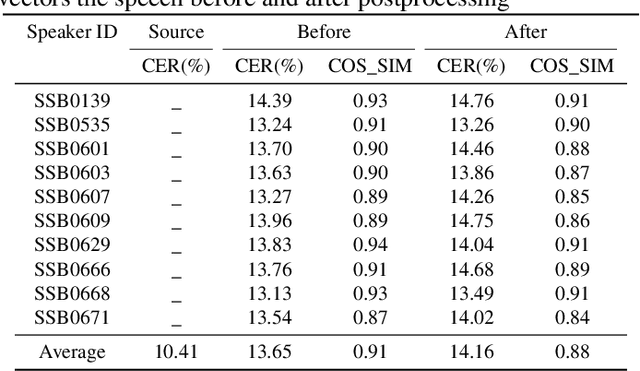
In this paper, we describe our speech generation system for the first Audio Deep Synthesis Detection Challenge (ADD 2022). Firstly, we build an any-to-many voice conversion (VC) system to convert source speech with arbitrary language content into the target speaker%u2019s fake speech. Then the converted speech generated from VC is post-processed in the time domain to improve the deception ability. The experimental results show that our system has adversarial ability against anti-spoofing detectors with a little compromise in audio quality and speaker similarity. This system ranks top in Track 3.1 in the ADD 2022, showing that our method could also gain good generalization ability against different detectors.
Lightweight Adapter Tuning for Multilingual Speech Translation
Jun 02, 2021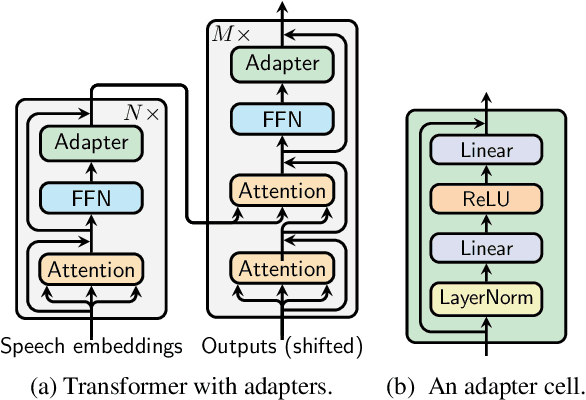
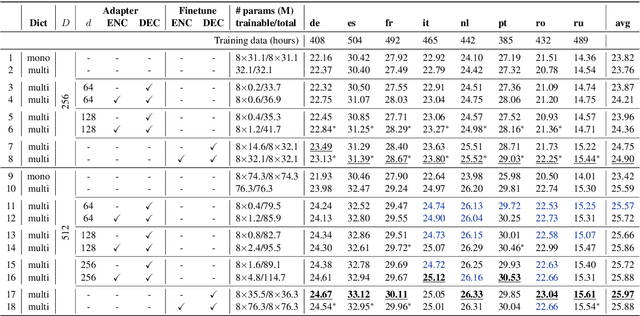
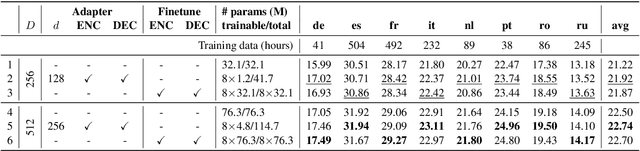
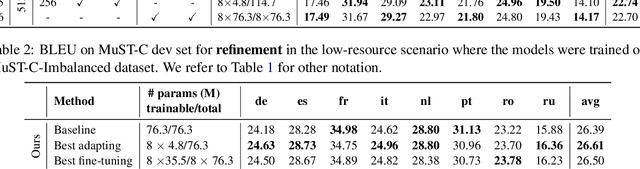
Adapter modules were recently introduced as an efficient alternative to fine-tuning in NLP. Adapter tuning consists in freezing pretrained parameters of a model and injecting lightweight modules between layers, resulting in the addition of only a small number of task-specific trainable parameters. While adapter tuning was investigated for multilingual neural machine translation, this paper proposes a comprehensive analysis of adapters for multilingual speech translation (ST). Starting from different pre-trained models (a multilingual ST trained on parallel data or a multilingual BART (mBART) trained on non-parallel multilingual data), we show that adapters can be used to: (a) efficiently specialize ST to specific language pairs with a low extra cost in terms of parameters, and (b) transfer from an automatic speech recognition (ASR) task and an mBART pre-trained model to a multilingual ST task. Experiments show that adapter tuning offer competitive results to full fine-tuning, while being much more parameter-efficient.
Generalized Representations Learning for Time Series Classification
Sep 15, 2022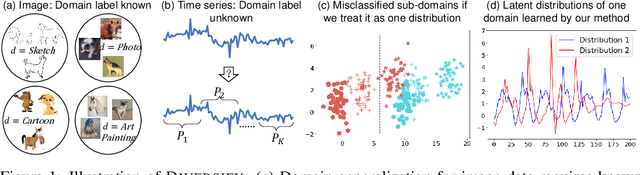
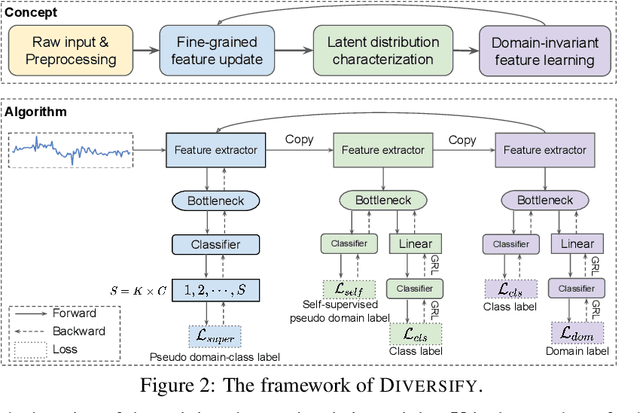
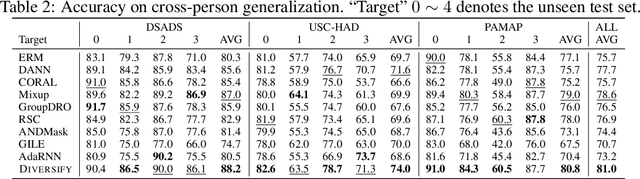
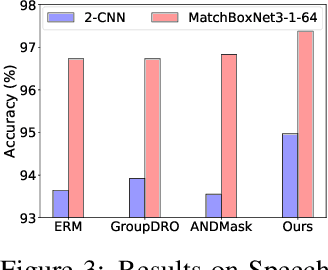
Time series classification is an important problem in real world. Due to its non-stationary property that the distribution changes over time, it remains challenging to build models for generalization to unseen distributions. In this paper, we propose to view the time series classification problem from the distribution perspective. We argue that the temporal complexity attributes to the unknown latent distributions within. To this end, we propose DIVERSIFY to learn generalized representations for time series classification. DIVERSIFY takes an iterative process: it first obtains the worst-case distribution scenario via adversarial training, then matches the distributions of the obtained sub-domains. We also present some theoretical insights. We conduct experiments on gesture recognition, speech commands recognition, wearable stress and affect detection, and sensor-based human activity recognition with a total of seven datasets in different settings. Results demonstrate that DIVERSIFY significantly outperforms other baselines and effectively characterizes the latent distributions by qualitative and quantitative analysis.
MetricGAN+: An Improved Version of MetricGAN for Speech Enhancement
Apr 08, 2021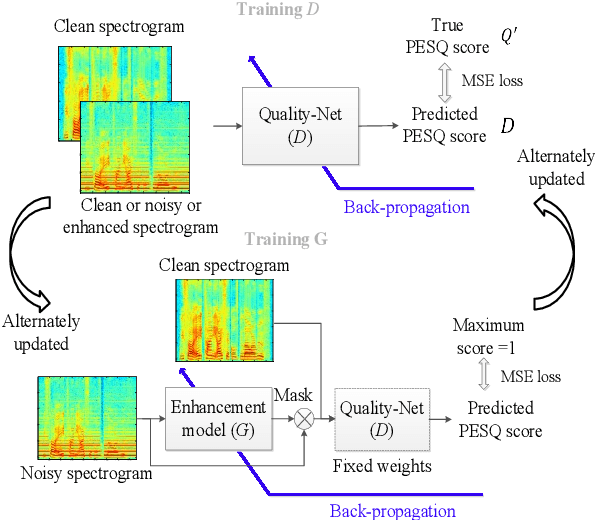
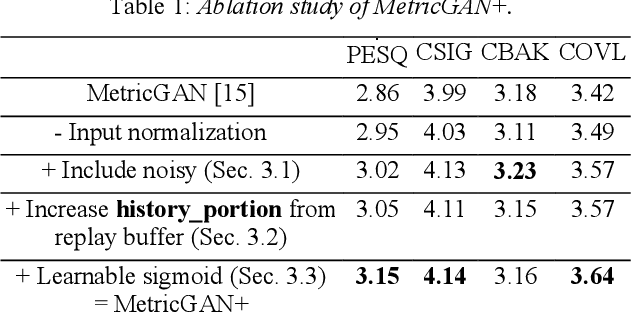
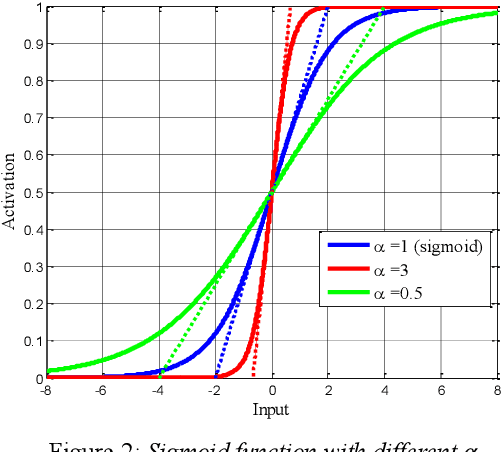

The discrepancy between the cost function used for training a speech enhancement model and human auditory perception usually makes the quality of enhanced speech unsatisfactory. Objective evaluation metrics which consider human perception can hence serve as a bridge to reduce the gap. Our previously proposed MetricGAN was designed to optimize objective metrics by connecting the metric with a discriminator. Because only the scores of the target evaluation functions are needed during training, the metrics can even be non-differentiable. In this study, we propose a MetricGAN+ in which three training techniques incorporating domain-knowledge of speech processing are proposed. With these techniques, experimental results on the VoiceBank-DEMAND dataset show that MetricGAN+ can increase PESQ score by 0.3 compared to the previous MetricGAN and achieve state-of-the-art results (PESQ score = 3.15).