 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Advancing Speech Recognition With No Speech Or With Noisy Speech
Jul 17, 2019
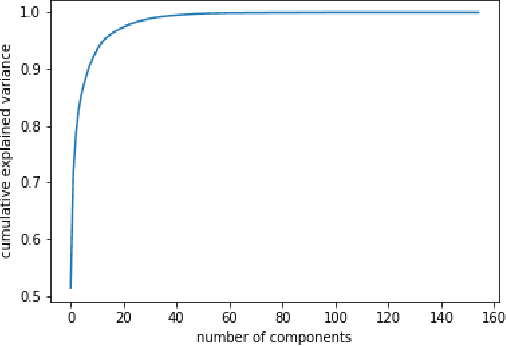
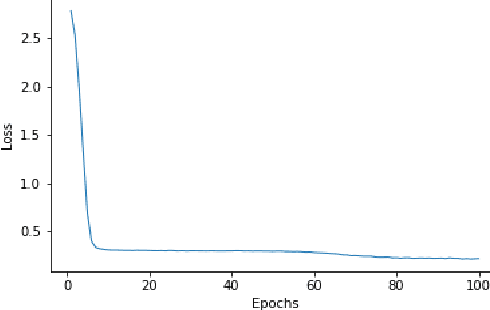
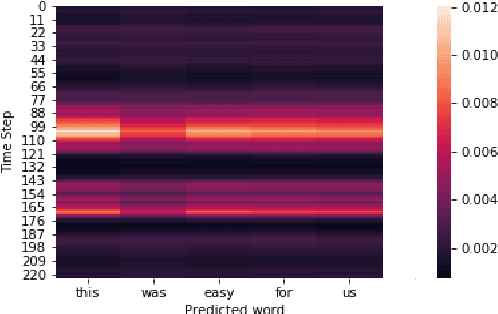
In this paper we demonstrate end to end continuous speech recognition (CSR) using electroencephalography (EEG) signals with no speech signal as input. An attention model based automatic speech recognition (ASR) and connectionist temporal classification (CTC) based ASR systems were implemented for performing recognition. We further demonstrate CSR for noisy speech by fusing with EEG features.
An exploratory experiment on Hindi, Bengali hate-speech detection and transfer learning using neural networks
Jan 06, 2022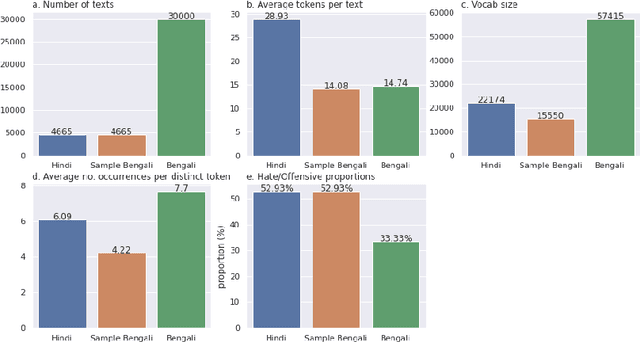
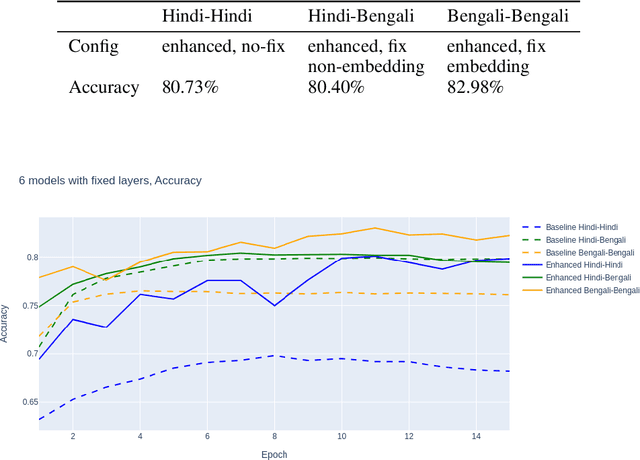
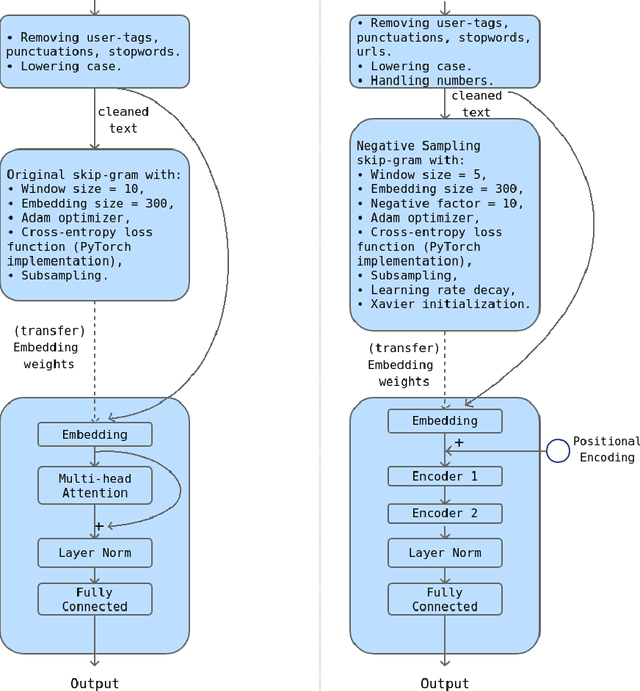
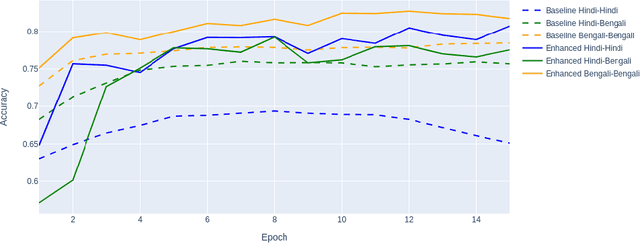
This work presents our approach to train a neural network to detect hate-speech texts in Hindi and Bengali. We also explore how transfer learning can be applied to learning these languages, given that they have the same origin and thus, are similar to some extend. Even though the whole experiment was conducted with low computational power, the obtained result is comparable to the results of other, more expensive, models. Furthermore, since the training data in use is relatively small and the two languages are almost entirely unknown to us, this work can be generalized as an effort to demystify lost or alien languages that no human is capable of understanding.
Generative Speech Coding with Predictive Variance Regularization
Feb 18, 2021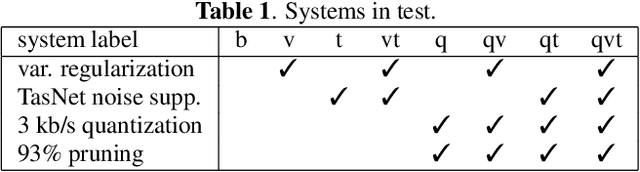
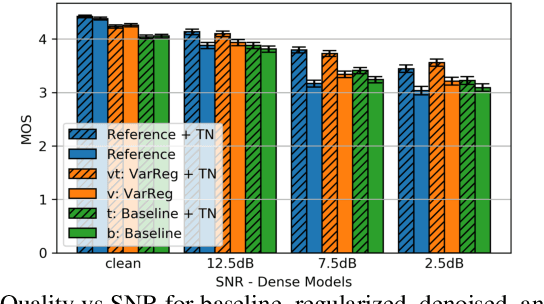
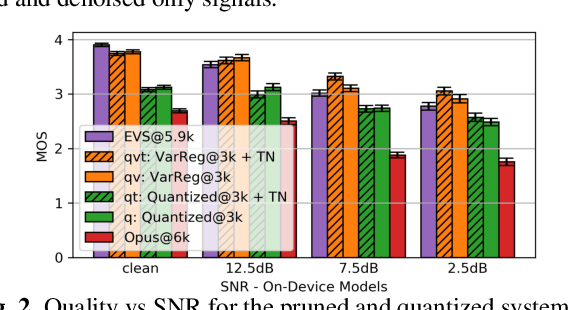
The recent emergence of machine-learning based generative models for speech suggests a significant reduction in bit rate for speech codecs is possible. However, the performance of generative models deteriorates significantly with the distortions present in real-world input signals. We argue that this deterioration is due to the sensitivity of the maximum likelihood criterion to outliers and the ineffectiveness of modeling a sum of independent signals with a single autoregressive model. We introduce predictive-variance regularization to reduce the sensitivity to outliers, resulting in a significant increase in performance. We show that noise reduction to remove unwanted signals can significantly increase performance. We provide extensive subjective performance evaluations that show that our system based on generative modeling provides state-of-the-art coding performance at 3 kb/s for real-world speech signals at reasonable computational complexity.
Low Bit-Rate Wideband Speech Coding: A Deep Generative Model based Approach
Feb 04, 2021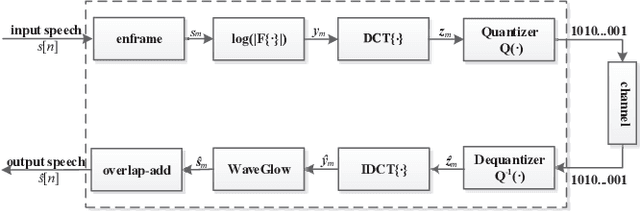



Traditional low bit-rate speech coding approach only handles narrowband speech at 8kHz, which limits further improvements in speech quality. Motivated by recent successful exploration of deep learning methods for image and speech compression, this paper presents a new approach through vector quantization (VQ) of mel-frequency cepstral coefficients (MFCCs) and using a deep generative model called WaveGlow to provide efficient and high-quality speech coding. The coding feature is sorely an 80-dimension MFCCs vector for 16kHz wideband speech, then speech coding at the bit-rate throughout 1000-2000 bit/s could be scalably implemented by applying different VQ schemes for MFCCs vector. This new deep generative network based codec works fast as the WaveGlow model abandons the sample-by-sample autoregressive mechanism. We evaluated this new approach over the multi-speaker TIMIT corpus, and experimental results demonstrate that it provides better speech quality compared with the state-of-the-art classic MELPe codec at lower bit-rate.
Longitudinal Sentiment Analyses for Radicalization Research: Intertemporal Dynamics on Social Media Platforms and their Implications
Oct 01, 2022This discussion paper demonstrates how longitudinal sentiment analyses can depict intertemporal dynamics on social media platforms, what challenges are inherent and how further research could benefit from a longitudinal perspective. Furthermore and since tools for sentiment analyses shall simplify and accelerate the analytical process regarding qualitative data at acceptable inter-rater reliability, their applicability in the context of radicalization research will be examined regarding the Tweets collected on January 6th 2021, the day of the storming of the U.S. Capitol in Washington. Therefore, a total of 49,350 Tweets will be analyzed evenly distributed within three different sequences: before, during and after the U.S. Capitol in Washington was stormed. These sequences highlight the intertemporal dynamics within comments on social media platforms as well as the possible benefits of a longitudinal perspective when using conditional means and conditional variances. Limitations regarding the identification of supporters of such events and associated hate speech as well as common application errors will be demonstrated as well. As a result, only under certain conditions a longitudinal sentiment analysis can increase the accuracy of evidence based predictions in the context of radicalization research.
Non-Autoregressive TTS with Explicit Duration Modelling for Low-Resource Highly Expressive Speech
Jun 25, 2021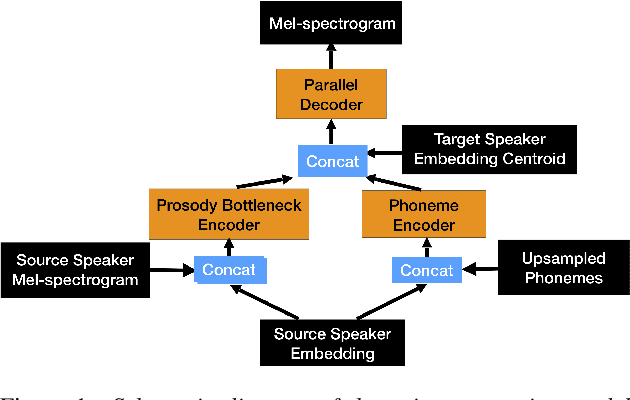
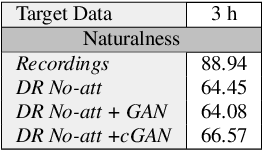
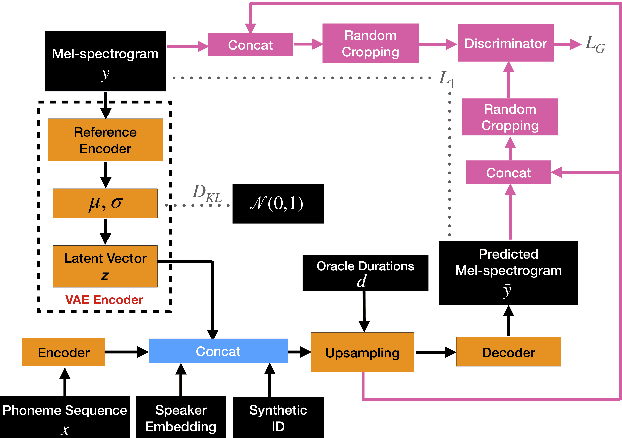
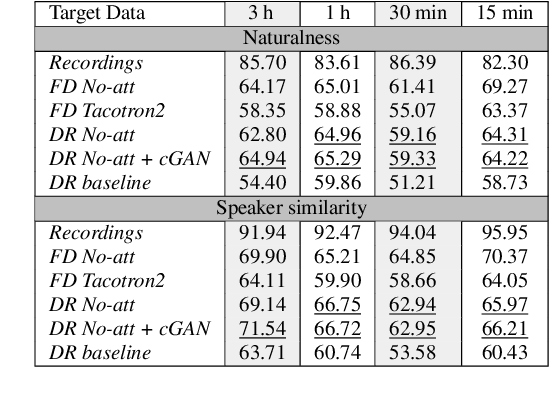
Whilst recent neural text-to-speech (TTS) approaches produce high-quality speech, they typically require a large amount of recordings from the target speaker. In previous work, a 3-step method was proposed to generate high-quality TTS while greatly reducing the amount of data required for training. However, we have observed a ceiling effect in the level of naturalness achievable for highly expressive voices when using this approach. In this paper, we present a method for building highly expressive TTS voices with as little as 15 minutes of speech data from the target speaker. Compared to the current state-of-the-art approach, our proposed improvements close the gap to recordings by 23.3% for naturalness of speech and by 16.3% for speaker similarity. Further, we match the naturalness and speaker similarity of a Tacotron2-based full-data (~10 hours) model using only 15 minutes of target speaker data, whereas with 30 minutes or more, we significantly outperform it. The following improvements are proposed: 1) changing from an autoregressive, attention-based TTS model to a non-autoregressive model replacing attention with an external duration model and 2) an additional Conditional Generative Adversarial Network (cGAN) based fine-tuning step.
Towards Transfer Learning of wav2vec 2.0 for Automatic Lyric Transcription
Jul 20, 2022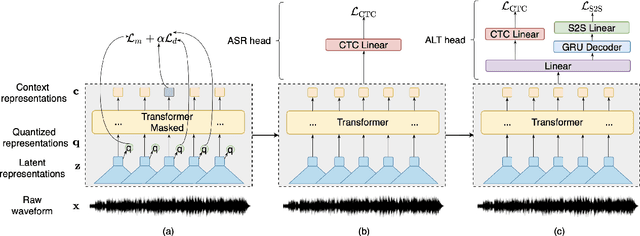
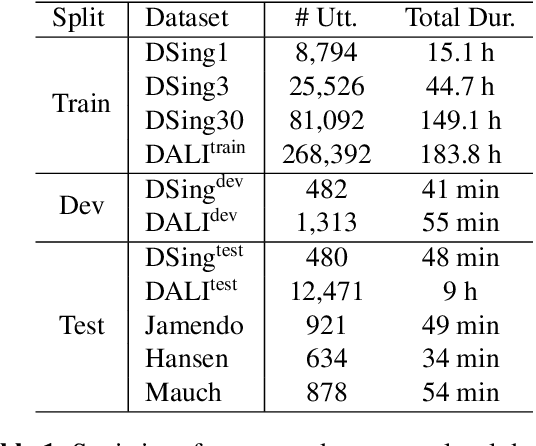
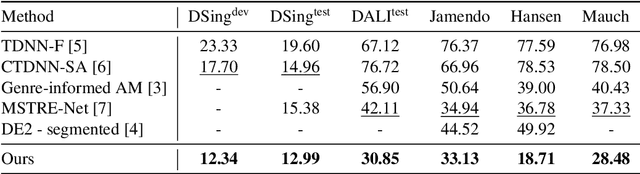
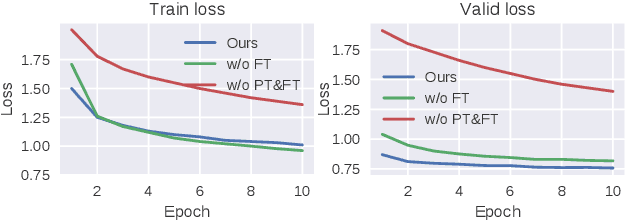
Automatic speech recognition (ASR) has progressed significantly in recent years due to large-scale datasets and the paradigm of self-supervised learning (SSL) methods. However, as its counterpart problem in the singing domain, automatic lyric transcription (ALT) suffers from limited data and degraded intelligibility of sung lyrics, which has caused it to develop at a slower pace. To fill in the performance gap between ALT and ASR, we attempt to exploit the similarities between speech and singing. In this work, we propose a transfer-learning-based ALT solution that takes advantage of these similarities by adapting wav2vec 2.0, an SSL ASR model, to the singing domain. We maximize the effectiveness of transfer learning by exploring the influence of different transfer starting points. We further enhance the performance by extending the original CTC model to a hybrid CTC/attention model. Our method surpasses previous approaches by a large margin on various ALT benchmark datasets. Further experiment shows that, with even a tiny proportion of training data, our method still achieves competitive performance.
Efficient Speech Emotion Recognition Using Multi-Scale CNN and Attention
Jun 08, 2021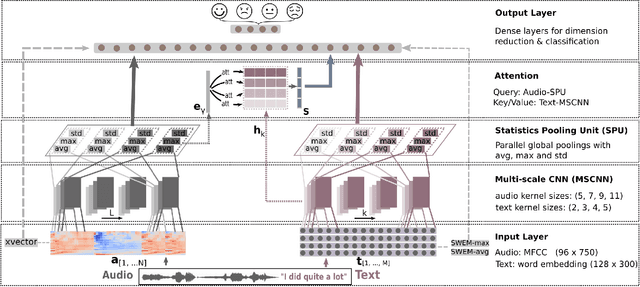
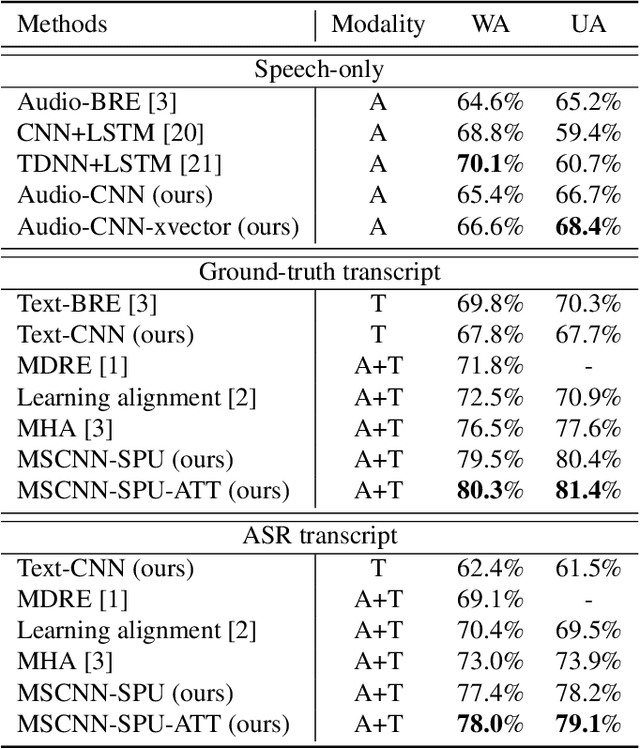

Emotion recognition from speech is a challenging task. Re-cent advances in deep learning have led bi-directional recur-rent neural network (Bi-RNN) and attention mechanism as astandard method for speech emotion recognition, extractingand attending multi-modal features - audio and text, and thenfusing them for downstream emotion classification tasks. Inthis paper, we propose a simple yet efficient neural networkarchitecture to exploit both acoustic and lexical informationfrom speech. The proposed framework using multi-scale con-volutional layers (MSCNN) to obtain both audio and text hid-den representations. Then, a statistical pooling unit (SPU)is used to further extract the features in each modality. Be-sides, an attention module can be built on top of the MSCNN-SPU (audio) and MSCNN (text) to further improve the perfor-mance. Extensive experiments show that the proposed modeloutperforms previous state-of-the-art methods on IEMOCAPdataset with four emotion categories (i.e., angry, happy, sadand neutral) in both weighted accuracy (WA) and unweightedaccuracy (UA), with an improvement of 5.0% and 5.2% respectively under the ASR setting.
* First two authors contributed equally.Accepted by ICASSP 2021
Speech Recognition by Simply Fine-tuning BERT
Jan 30, 2021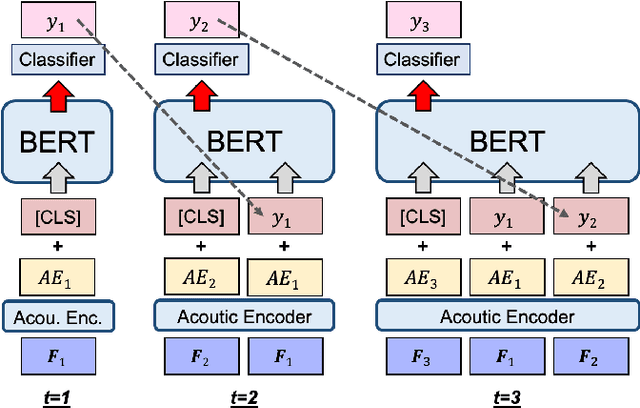
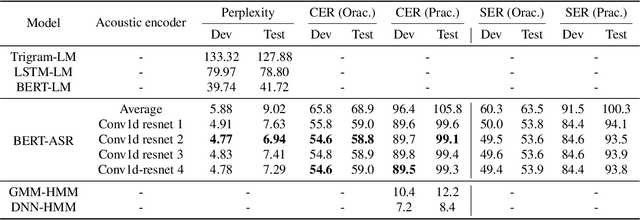
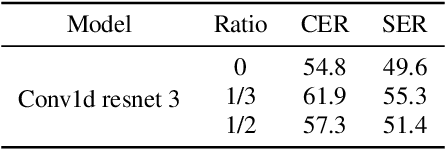
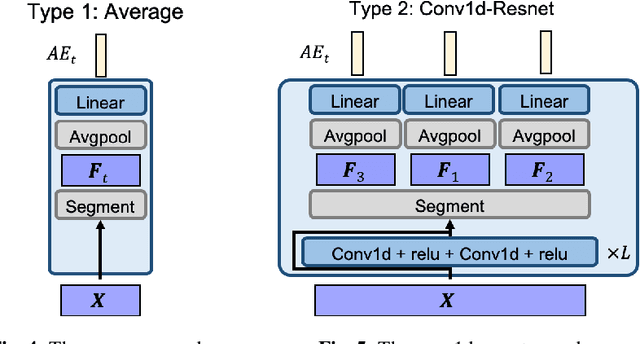
We propose a simple method for automatic speech recognition (ASR) by fine-tuning BERT, which is a language model (LM) trained on large-scale unlabeled text data and can generate rich contextual representations. Our assumption is that given a history context sequence, a powerful LM can narrow the range of possible choices and the speech signal can be used as a simple clue. Hence, comparing to conventional ASR systems that train a powerful acoustic model (AM) from scratch, we believe that speech recognition is possible by simply fine-tuning a BERT model. As an initial study, we demonstrate the effectiveness of the proposed idea on the AISHELL dataset and show that stacking a very simple AM on top of BERT can yield reasonable performance.
MetricGAN+: An Improved Version of MetricGAN for Speech Enhancement
Apr 08, 2021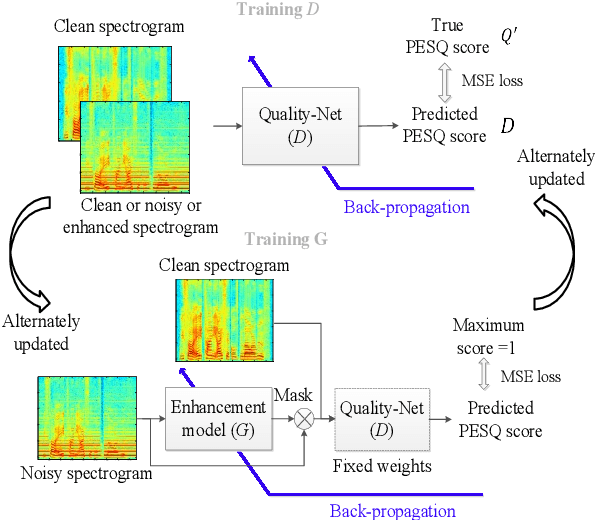
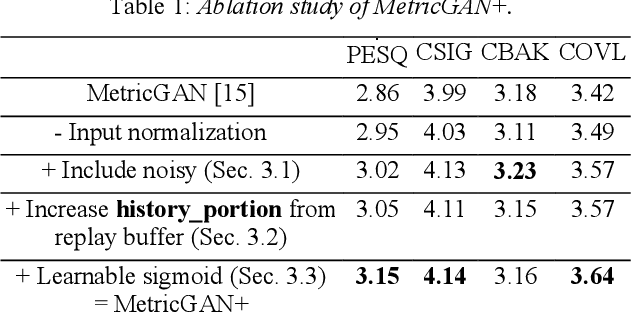

The discrepancy between the cost function used for training a speech enhancement model and human auditory perception usually makes the quality of enhanced speech unsatisfactory. Objective evaluation metrics which consider human perception can hence serve as a bridge to reduce the gap. Our previously proposed MetricGAN was designed to optimize objective metrics by connecting the metric with a discriminator. Because only the scores of the target evaluation functions are needed during training, the metrics can even be non-differentiable. In this study, we propose a MetricGAN+ in which three training techniques incorporating domain-knowledge of speech processing are proposed. With these techniques, experimental results on the VoiceBank-DEMAND dataset show that MetricGAN+ can increase PESQ score by 0.3 compared to the previous MetricGAN and achieve state-of-the-art results (PESQ score = 3.15).