 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Data Bootstrapping Approaches to Improve Low Resource Abusive Language Detection for Indic Languages
Apr 26, 2022
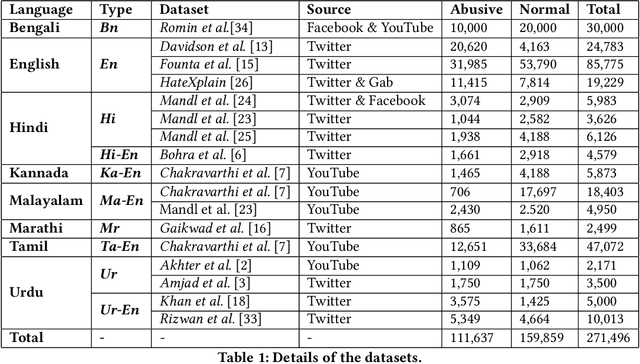
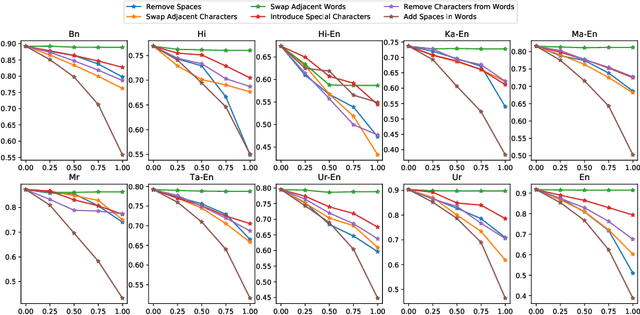
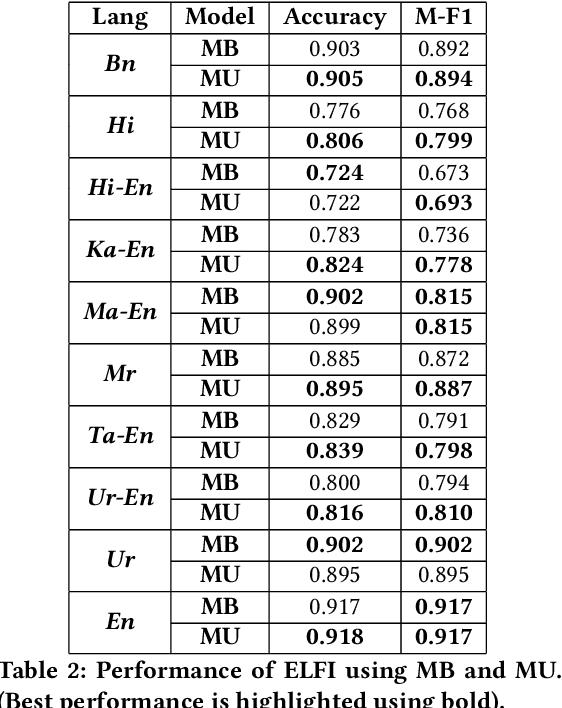
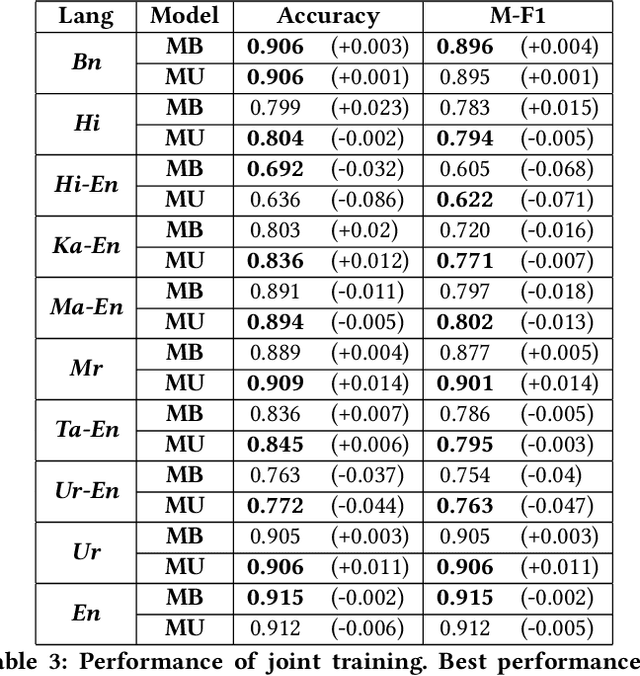
Abusive language is a growing concern in many social media platforms. Repeated exposure to abusive speech has created physiological effects on the target users. Thus, the problem of abusive language should be addressed in all forms for online peace and safety. While extensive research exists in abusive speech detection, most studies focus on English. Recently, many smearing incidents have occurred in India, which provoked diverse forms of abusive speech in online space in various languages based on the geographic location. Therefore it is essential to deal with such malicious content. In this paper, to bridge the gap, we demonstrate a large-scale analysis of multilingual abusive speech in Indic languages. We examine different interlingual transfer mechanisms and observe the performance of various multilingual models for abusive speech detection for eight different Indic languages. We also experiment to show how robust these models are on adversarial attacks. Finally, we conduct an in-depth error analysis by looking into the models' misclassified posts across various settings. We have made our code and models public for other researchers.
Urdu Speech and Text Based Sentiment Analyzer
Jul 19, 2022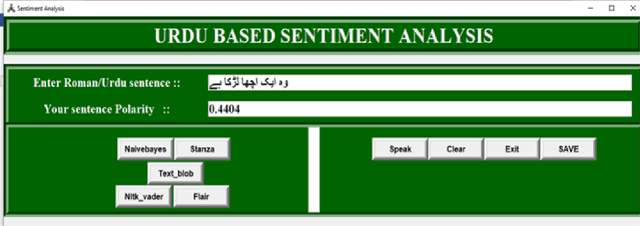
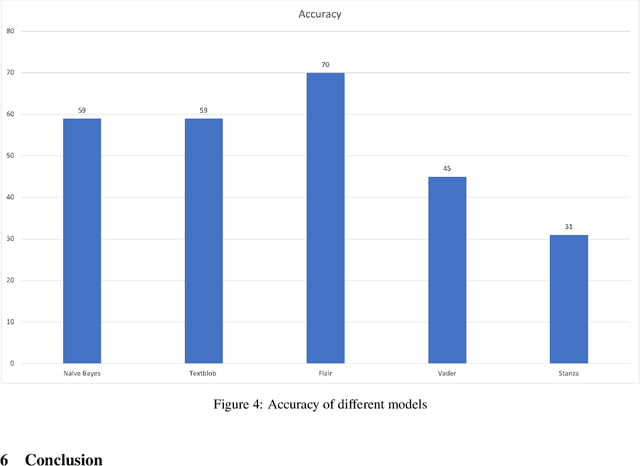
Discovering what other people think has always been a key aspect of our information-gathering strategy. People can now actively utilize information technology to seek out and comprehend the ideas of others, thanks to the increased availability and popularity of opinion-rich resources such as online review sites and personal blogs. Because of its crucial function in understanding people's opinions, sentiment analysis (SA) is a crucial task. Existing research, on the other hand, is primarily focused on the English language, with just a small amount of study devoted to low-resource languages. For sentiment analysis, this work presented a new multi-class Urdu dataset based on user evaluations. The tweeter website was used to get Urdu dataset. Our proposed dataset includes 10,000 reviews that have been carefully classified into two categories by human experts: positive, negative. The primary purpose of this research is to construct a manually annotated dataset for Urdu sentiment analysis and to establish the baseline result. Five different lexicon- and rule-based algorithms including Naivebayes, Stanza, Textblob, Vader, and Flair are employed and the experimental results show that Flair with an accuracy of 70% outperforms other tested algorithms.
AtteSTNet -- An attention and subword tokenization based approach for code-switched Hindi-English hate speech detection
Dec 10, 2021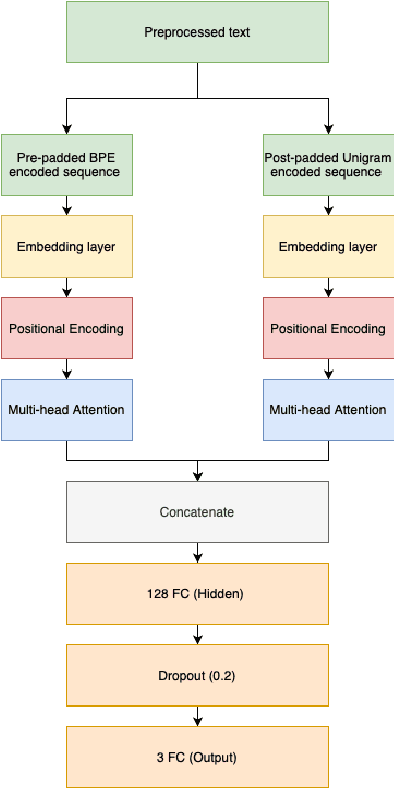
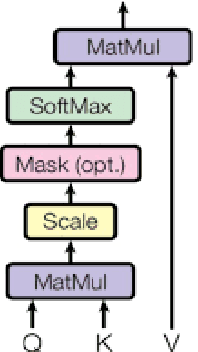
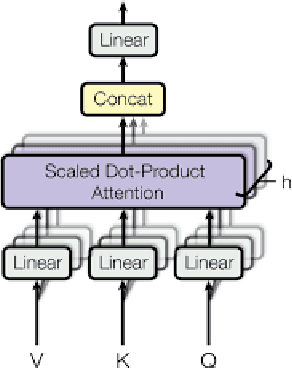
Recent advancements in technology have led to a boost in social media usage which has ultimately led to large amounts of user-generated data which also includes hateful and offensive speech. The language used in social media is often a combination of English and the native language in the region. In India, Hindi is used predominantly and is often code-switched with English, giving rise to the Hinglish (Hindi+English) language. Various approaches have been made in the past to classify the code-mixed Hinglish hate speech using different machine learning and deep learning-based techniques. However, these techniques make use of recurrence on convolution mechanisms which are computationally expensive and have high memory requirements. Past techniques also make use of complex data processing making the existing techniques very complex and non-sustainable to change in data. We propose a much simpler approach which is not only at par with these complex networks but also exceeds performance with the use of subword tokenization algorithms like BPE and Unigram along with multi-head attention-based technique giving an accuracy of 87.41% and F1 score of 0.851 on standard datasets. Efficient use of BPE and Unigram algorithms help handle the non-conventional Hinglish vocabulary making our technique simple, efficient and sustainable to use in the real world.
Large-Scale Self- and Semi-Supervised Learning for Speech Translation
Apr 14, 2021
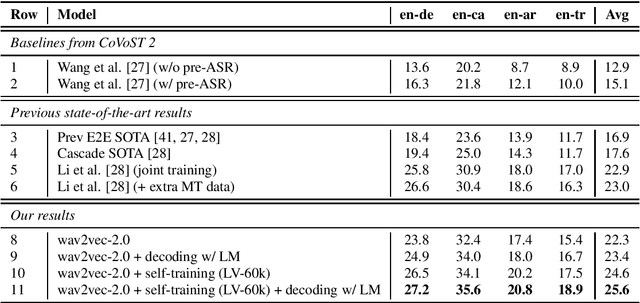

In this paper, we improve speech translation (ST) through effectively leveraging large quantities of unlabeled speech and text data in different and complementary ways. We explore both pretraining and self-training by using the large Libri-Light speech audio corpus and language modeling with CommonCrawl. Our experiments improve over the previous state of the art by 2.6 BLEU on average on all four considered CoVoST 2 language pairs via a simple recipe of combining wav2vec 2.0 pretraining, a single iteration of self-training and decoding with a language model. Different to existing work, our approach does not leverage any other supervision than ST data. Code and models will be publicly released.
An exploratory experiment on Hindi, Bengali hate-speech detection and transfer learning using neural networks
Jan 06, 2022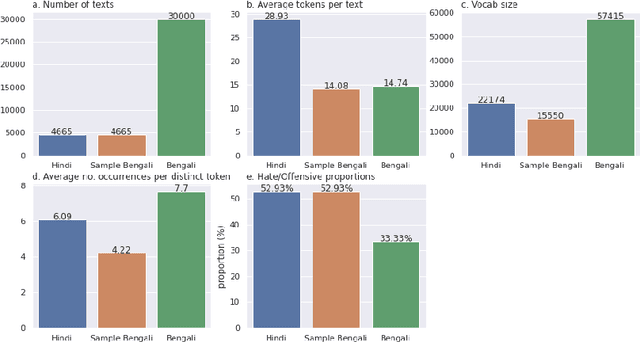
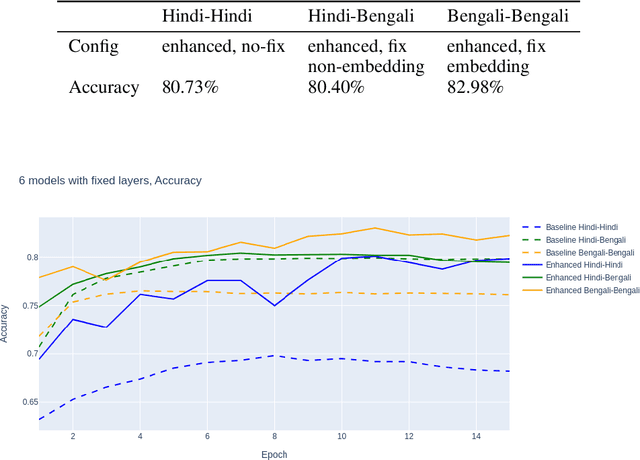
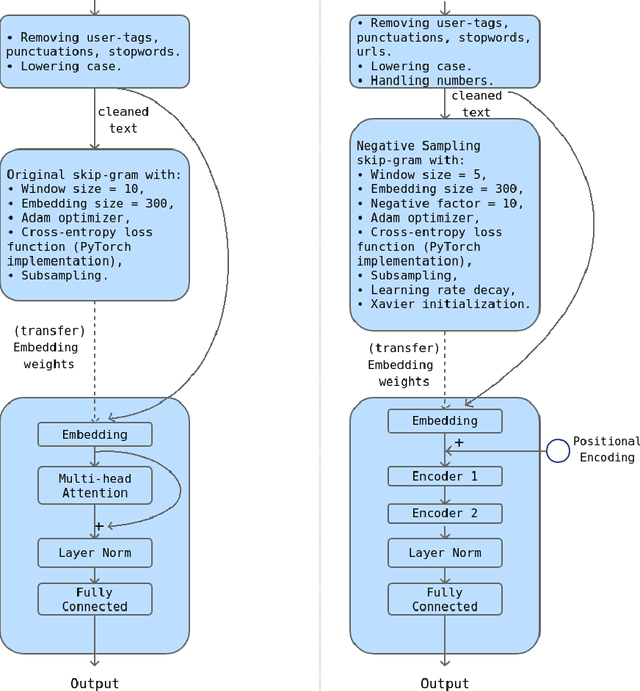
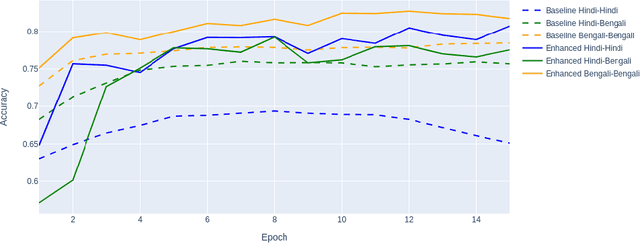
This work presents our approach to train a neural network to detect hate-speech texts in Hindi and Bengali. We also explore how transfer learning can be applied to learning these languages, given that they have the same origin and thus, are similar to some extend. Even though the whole experiment was conducted with low computational power, the obtained result is comparable to the results of other, more expensive, models. Furthermore, since the training data in use is relatively small and the two languages are almost entirely unknown to us, this work can be generalized as an effort to demystify lost or alien languages that no human is capable of understanding.
Generalized Representations Learning for Time Series Classification
Sep 15, 2022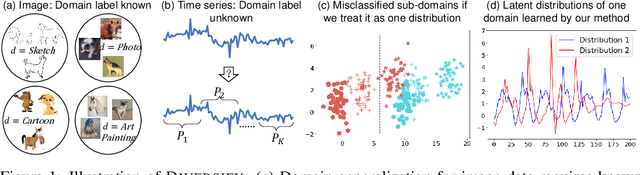
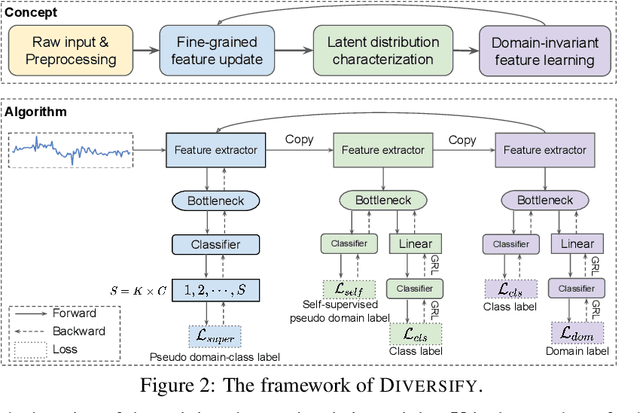
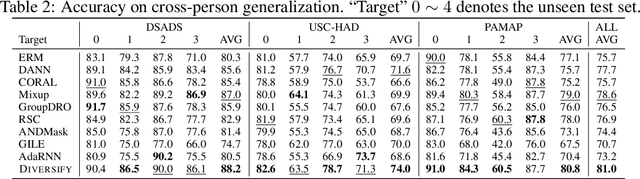
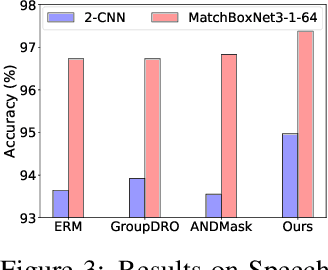
Time series classification is an important problem in real world. Due to its non-stationary property that the distribution changes over time, it remains challenging to build models for generalization to unseen distributions. In this paper, we propose to view the time series classification problem from the distribution perspective. We argue that the temporal complexity attributes to the unknown latent distributions within. To this end, we propose DIVERSIFY to learn generalized representations for time series classification. DIVERSIFY takes an iterative process: it first obtains the worst-case distribution scenario via adversarial training, then matches the distributions of the obtained sub-domains. We also present some theoretical insights. We conduct experiments on gesture recognition, speech commands recognition, wearable stress and affect detection, and sensor-based human activity recognition with a total of seven datasets in different settings. Results demonstrate that DIVERSIFY significantly outperforms other baselines and effectively characterizes the latent distributions by qualitative and quantitative analysis.
Cross-speaker Style Transfer with Prosody Bottleneck in Neural Speech Synthesis
Jul 27, 2021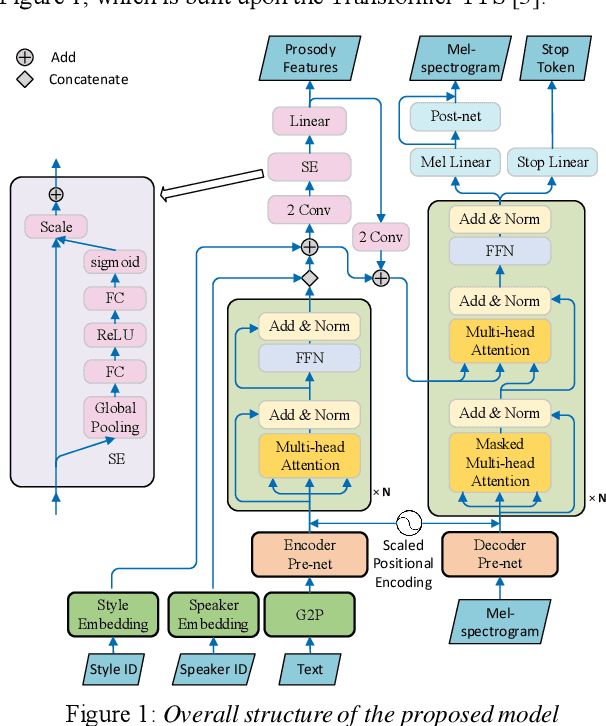
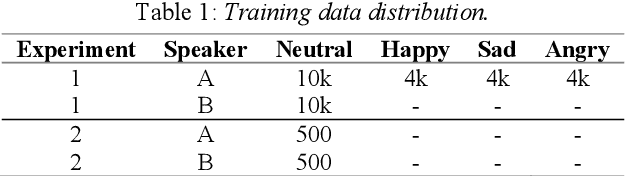
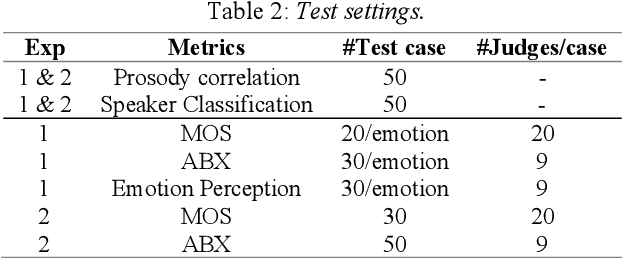
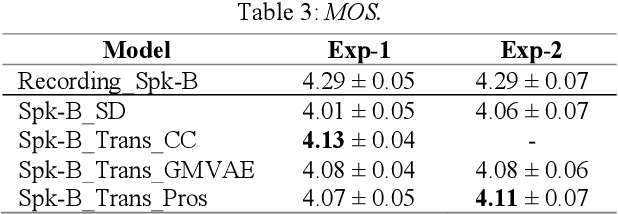
Cross-speaker style transfer is crucial to the applications of multi-style and expressive speech synthesis at scale. It does not require the target speakers to be experts in expressing all styles and to collect corresponding recordings for model training. However, the performances of existing style transfer methods are still far behind real application needs. The root causes are mainly twofold. Firstly, the style embedding extracted from single reference speech can hardly provide fine-grained and appropriate prosody information for arbitrary text to synthesize. Secondly, in these models the content/text, prosody, and speaker timbre are usually highly entangled, it's therefore not realistic to expect a satisfied result when freely combining these components, such as to transfer speaking style between speakers. In this paper, we propose a cross-speaker style transfer text-to-speech (TTS) model with explicit prosody bottleneck. The prosody bottleneck builds up the kernels accounting for speaking style robustly, and disentangles the prosody from content and speaker timbre, therefore guarantees high quality cross-speaker style transfer. Evaluation result shows the proposed method even achieves on-par performance with source speaker's speaker-dependent (SD) model in objective measurement of prosody, and significantly outperforms the cycle consistency and GMVAE-based baselines in objective and subjective evaluations.
Mandarin Singing Voice Synthesis with Denoising Diffusion Probabilistic Wasserstein GAN
Sep 21, 2022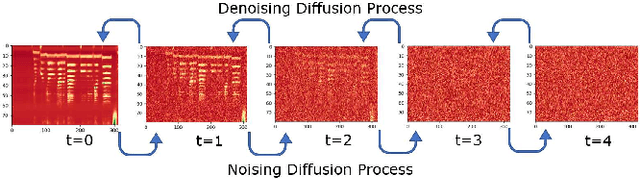

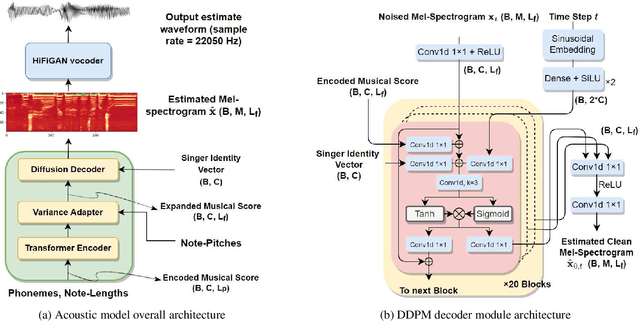
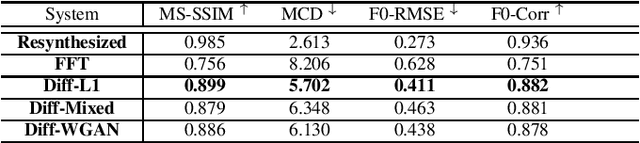
Singing voice synthesis (SVS) is the computer production of a human-like singing voice from given musical scores. To accomplish end-to-end SVS effectively and efficiently, this work adopts the acoustic model-neural vocoder architecture established for high-quality speech and singing voice synthesis. Specifically, this work aims to pursue a higher level of expressiveness in synthesized voices by combining the diffusion denoising probabilistic model (DDPM) and \emph{Wasserstein} generative adversarial network (WGAN) to construct the backbone of the acoustic model. On top of the proposed acoustic model, a HiFi-GAN neural vocoder is adopted with integrated fine-tuning to ensure optimal synthesis quality for the resulting end-to-end SVS system. This end-to-end system was evaluated with the multi-singer Mpop600 Mandarin singing voice dataset. In the experiments, the proposed system exhibits improvements over previous landmark counterparts in terms of musical expressiveness and high-frequency acoustic details. Moreover, the adversarial acoustic model converged stably without the need to enforce reconstruction objectives, indicating the convergence stability of the proposed DDPM and WGAN combined architecture over alternative GAN-based SVS systems.
Adversarial and Safely Scaled Question Generation
Oct 17, 2022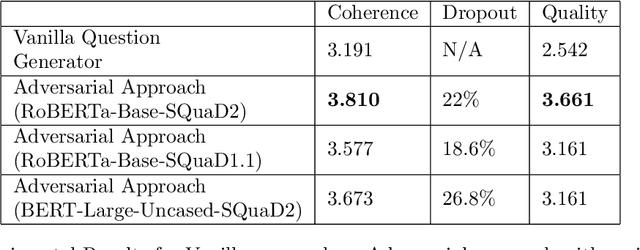
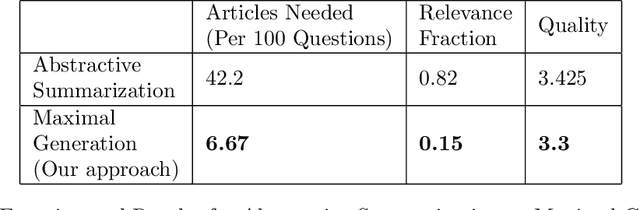
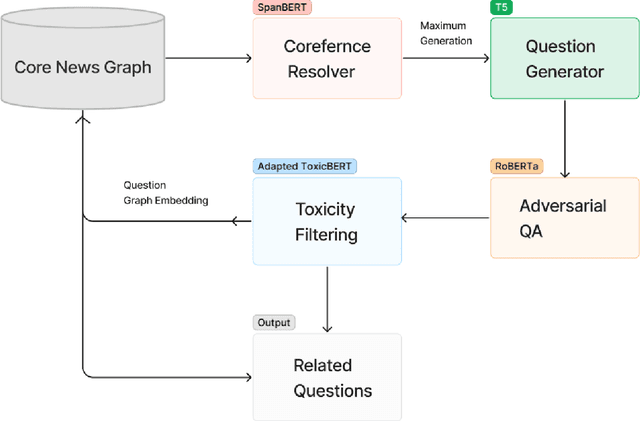
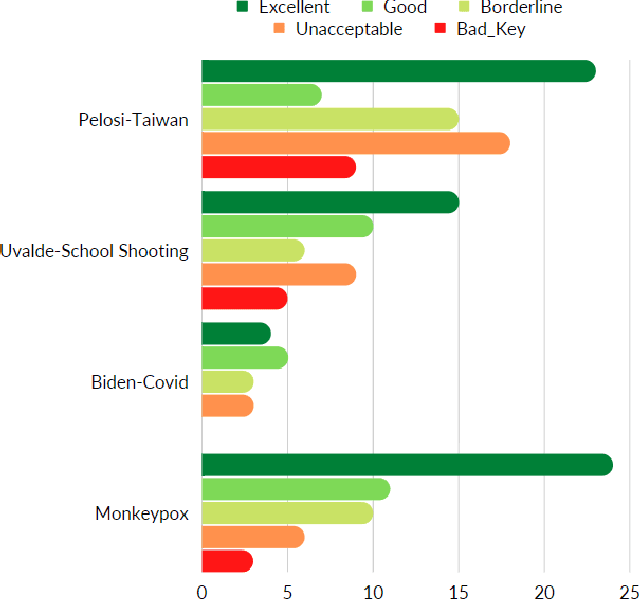
Question generation has recently gained a lot of research interest, especially with the advent of large language models. In and of itself, question generation can be considered 'AI-hard', as there is a lack of unanimously agreed sense of what makes a question 'good' or 'bad'. In this paper, we tackle two fundamental problems in parallel: on one hand, we try to solve the scaling problem, where question-generation and answering applications have to be applied to a massive amount of text without ground truth labeling. The usual approach to solve this problem is to either downsample or summarize. However, there are critical risks of misinformation with these approaches. On the other hand, and related to the misinformation problem, we try to solve the 'safety' problem, as many public institutions rely on a much higher level of accuracy for the content they provide. We introduce an adversarial approach to tackle the question generation safety problem with scale. Specifically, we designed a question-answering system that specifically prunes out unanswerable questions that may be generated, and further increases the quality of the answers that are generated. We build a production-ready, easily-plugged pipeline that can be used on any given body of text, that is scalable and immune from generating any hate speech, profanity, or misinformation. Based on the results, we are able to generate more than six times the number of quality questions generated by the abstractive approach, with a perceived quality being 44% higher, according to a survey of 168 participants.
Continuous Pseudo-Labeling from the Start
Oct 17, 2022
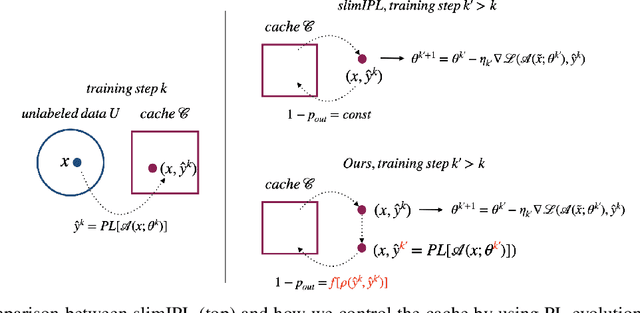
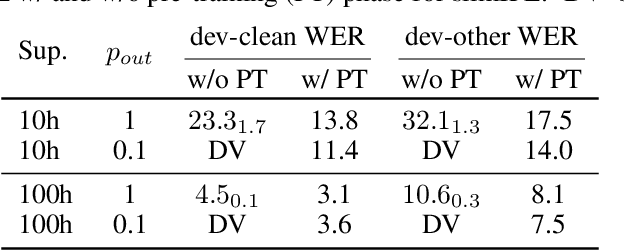
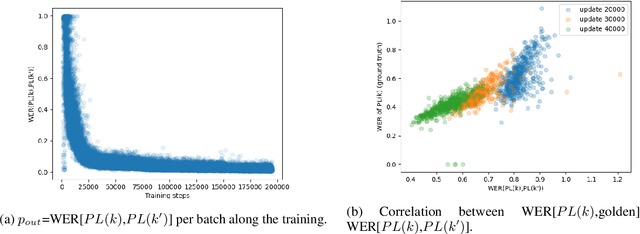
Self-training (ST), or pseudo-labeling has sparked significant interest in the automatic speech recognition (ASR) community recently because of its success in harnessing unlabeled data. Unlike prior semi-supervised learning approaches that relied on iteratively regenerating pseudo-labels (PLs) from a trained model and using them to train a new model, recent state-of-the-art methods perform `continuous training' where PLs are generated using a very recent version of the model being trained. Nevertheless, these approaches still rely on bootstrapping the ST using an initial supervised learning phase where the model is trained on labeled data alone. We believe this has the potential for over-fitting to the labeled dataset in low resource settings and that ST from the start of training should reduce over-fitting. In this paper we show how we can do this by dynamically controlling the evolution of PLs during the training process in ASR. To the best of our knowledge, this is the first study that shows the feasibility of generating PLs from the very start of the training. We are able to achieve this using two techniques that avoid instabilities which lead to degenerate models that do not generalize. Firstly, we control the evolution of PLs through a curriculum that uses the online changes in PLs to control the membership of the cache of PLs and improve generalization. Secondly, we find that by sampling transcriptions from the predictive distribution, rather than only using the best transcription, we can stabilize training further. With these techniques, our ST models match prior works without an external language model.