 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
End-to-End Neural Systems for Automatic Children Speech Recognition: An Empirical Study
Feb 19, 2021

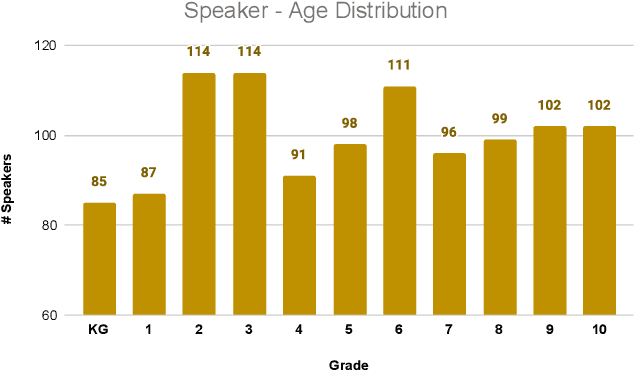
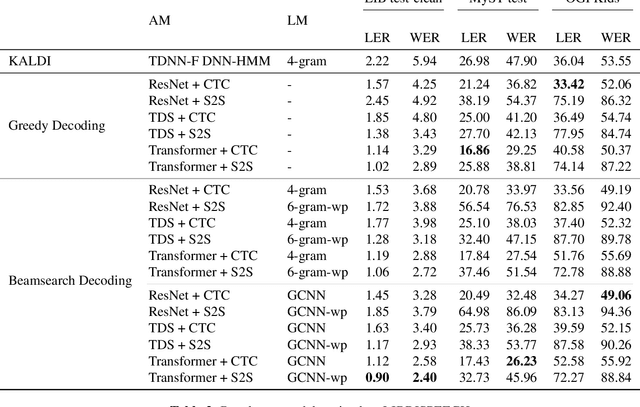
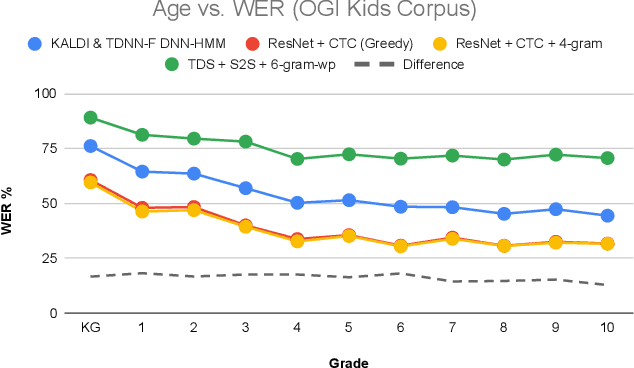
A key desiderata for inclusive and accessible speech recognition technology is ensuring its robust performance to children's speech. Notably, this includes the rapidly advancing neural network based end-to-end speech recognition systems. Children speech recognition is more challenging due to the larger intra-inter speaker variability in terms of acoustic and linguistic characteristics compared to adult speech. Furthermore, the lack of adequate and appropriate children speech resources adds to the challenge of designing robust end-to-end neural architectures. This study provides a critical assessment of automatic children speech recognition through an empirical study of contemporary state-of-the-art end-to-end speech recognition systems. Insights are provided on the aspects of training data requirements, adaptation on children data, and the effect of children age, utterance lengths, different architectures and loss functions for end-to-end systems and role of language models on the speech recognition performance.
Automatic Speaker Independent Dysarthric Speech Intelligibility Assessment System
Mar 10, 2021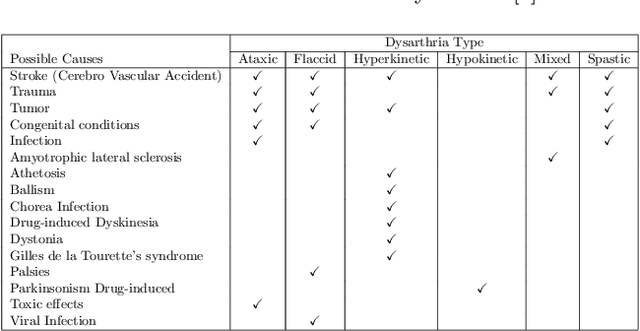
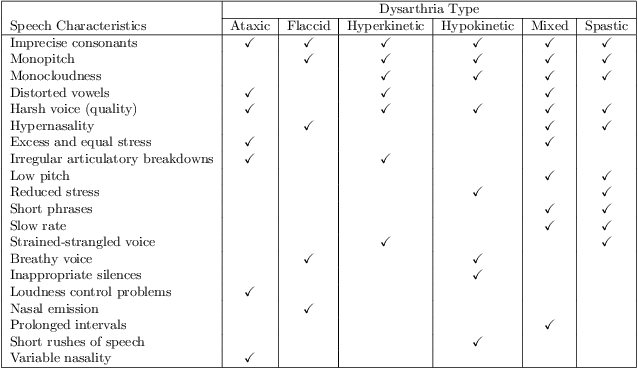
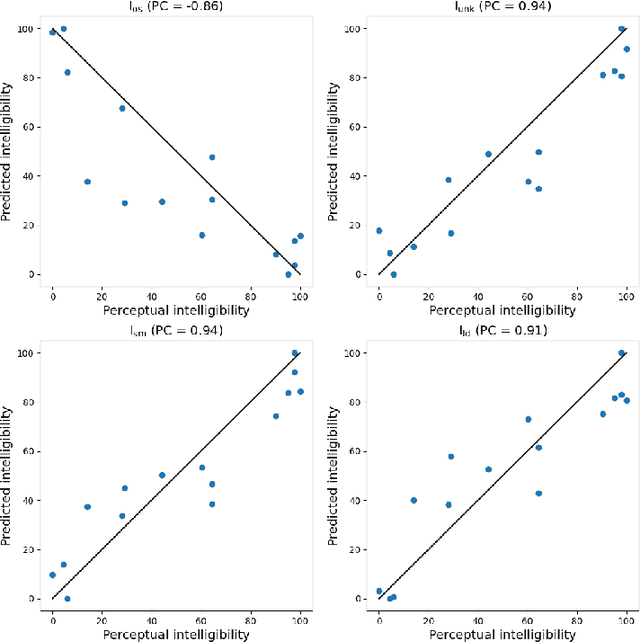
Dysarthria is a condition which hampers the ability of an individual to control the muscles that play a major role in speech delivery. The loss of fine control over muscles that assist the movement of lips, vocal chords, tongue and diaphragm results in abnormal speech delivery. One can assess the severity level of dysarthria by analyzing the intelligibility of speech spoken by an individual. Continuous intelligibility assessment helps speech language pathologists not only study the impact of medication but also allows them to plan personalized therapy. It helps the clinicians immensely if the intelligibility assessment system is reliable, automatic, simple for (a) patients to undergo and (b) clinicians to interpret. Lack of availability of dysarthric data has resulted in development of speaker dependent automatic intelligibility assessment systems which requires patients to speak a large number of utterances. In this paper, we propose (a) a cost minimization procedure to select an optimal (small) number of utterances that need to be spoken by the dysarthric patient, (b) four different speaker independent intelligibility assessment systems which require the patient to speak a small number of words, and (c) the assessment score is close to the perceptual score that the Speech Language Pathologist (SLP) can relate to. The need for small number of utterances to be spoken by the patient and the score being relatable to the SLP benefits both the dysarthric patient and the clinician from usability perspective.
From Speech-to-Speech Translation to Automatic Dubbing
Jan 19, 2020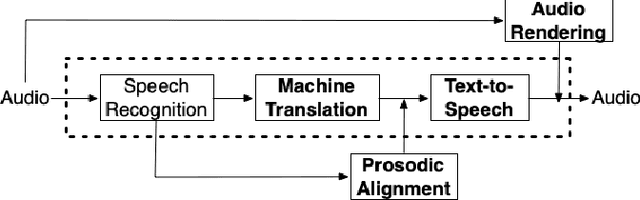

We present enhancements to a speech-to-speech translation pipeline in order to perform automatic dubbing. Our architecture features neural machine translation generating output of preferred length, prosodic alignment of the translation with the original speech segments, neural text-to-speech with fine tuning of the duration of each utterance, and, finally, audio rendering to enriches text-to-speech output with background noise and reverberation extracted from the original audio. We report on a subjective evaluation of automatic dubbing of excerpts of TED Talks from English into Italian, which measures the perceived naturalness of automatic dubbing and the relative importance of each proposed enhancement.
Improving spatial cues for hearables using a parameterized binaural CDR estimator
Jul 17, 2022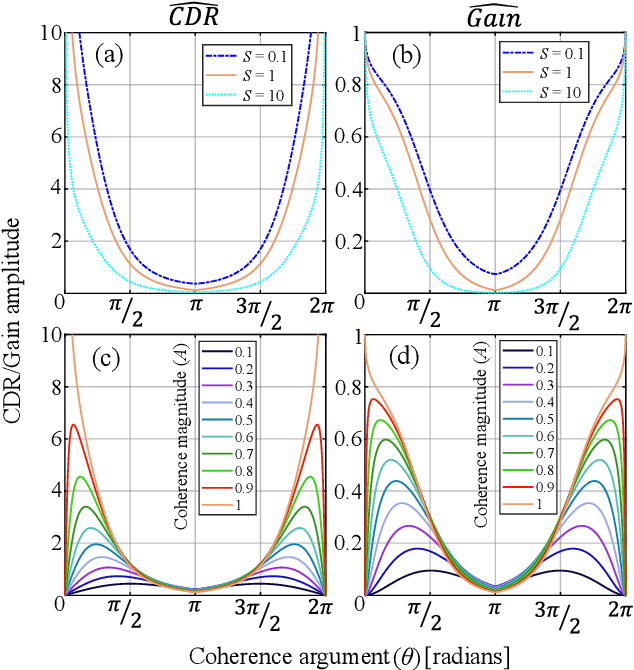
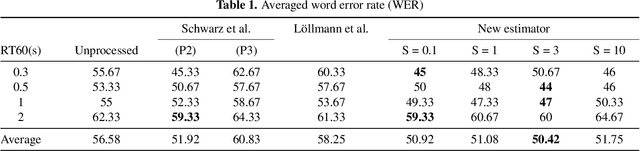
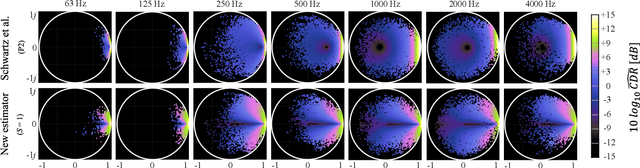
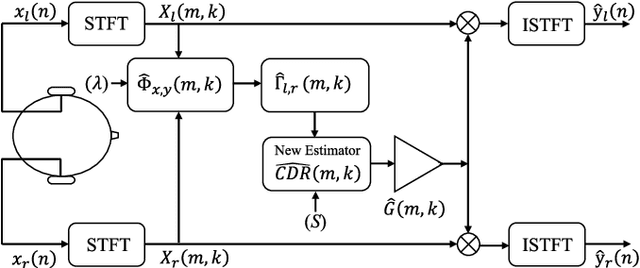
We investigate a speech enhancement method based on the binaural coherence-to-diffuse power ratio (CDR), which preserves auditory spatial cues for maskers and a broadside target. Conventional CDR estimators typically rely on a mathematical coherence model of the desired signal and/or diffuse noise field in their formulation, which may influence their accuracy in natural environments. This work proposes a new robust and parameterized directional binaural CDR estimator. The estimator is calculated in the time-frequency domain and is based on a geometrical interpretation of the spatial coherence function between the binaural microphone signals. The binaural performance of the new CDR estimator is compared with three state-of-the-art CDR estimators in cocktail-party-like environments and has shown improvements in terms of several objective speech quality metrics such as PESQ and SRMR. We also discuss the benefits of the parameterizable CDR estimator for varying sound environments and briefly reflect on several informal subjective evaluations using a low-latency real-time framework.
MIMO Self-attentive RNN Beamformer for Multi-speaker Speech Separation
Apr 26, 2021
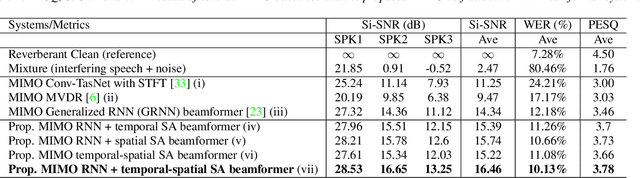

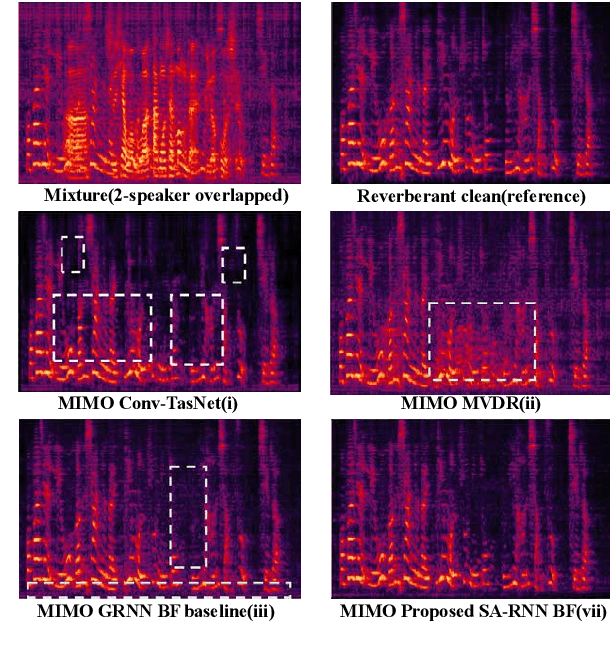
Recently, our proposed recurrent neural network (RNN) based all deep learning minimum variance distortionless response (ADL-MVDR) beamformer method yielded superior performance over the conventional MVDR by replacing the matrix inversion and eigenvalue decomposition with two recurrent neural networks. In this work, we present a self-attentive RNN beamformer to further improve our previous RNN-based beamformer by leveraging on the powerful modeling capability of self-attention. Temporal-spatial self-attention module is proposed to better learn the beamforming weights from the speech and noise spatial covariance matrices. The temporal self-attention module could help RNN to learn global statistics of covariance matrices. The spatial self-attention module is designed to attend on the cross-channel correlation in the covariance matrices. Furthermore, a multi-channel input with multi-speaker directional features and multi-speaker speech separation outputs (MIMO) model is developed to improve the inference efficiency. The evaluations demonstrate that our proposed MIMO self-attentive RNN beamformer improves both the automatic speech recognition (ASR) accuracy and the perceptual estimation of speech quality (PESQ) against prior arts.
Improving Attention-Based Interpretability of Text Classification Transformers
Sep 22, 2022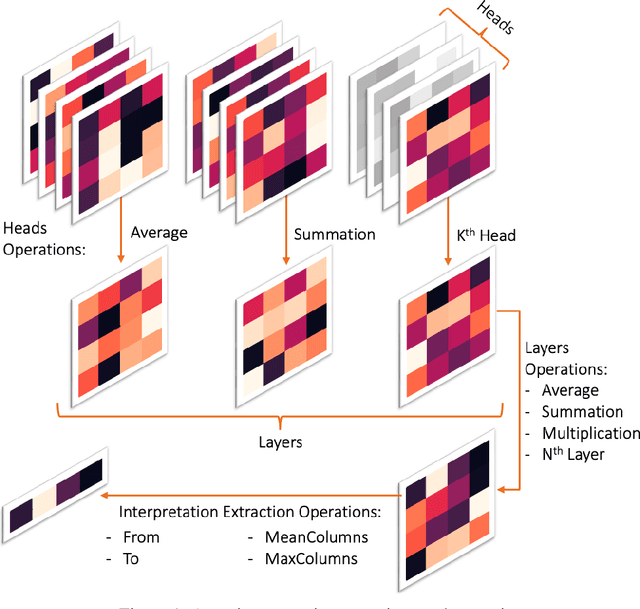
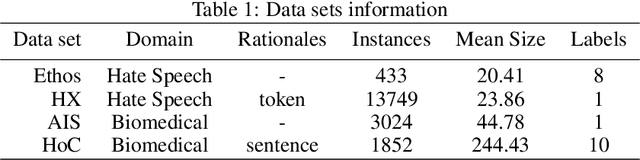
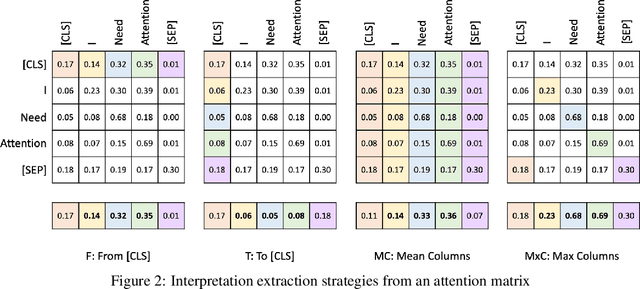
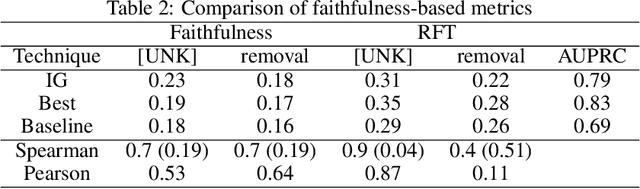
Transformers are widely used in NLP, where they consistently achieve state-of-the-art performance. This is due to their attention-based architecture, which allows them to model rich linguistic relations between words. However, transformers are difficult to interpret. Being able to provide reasoning for its decisions is an important property for a model in domains where human lives are affected, such as hate speech detection and biomedicine. With transformers finding wide use in these fields, the need for interpretability techniques tailored to them arises. The effectiveness of attention-based interpretability techniques for transformers in text classification is studied in this work. Despite concerns about attention-based interpretations in the literature, we show that, with proper setup, attention may be used in such tasks with results comparable to state-of-the-art techniques, while also being faster and friendlier to the environment. We validate our claims with a series of experiments that employ a new feature importance metric.
End-to-end Ensemble-based Feature Selection for Paralinguistics Tasks
Oct 28, 2022
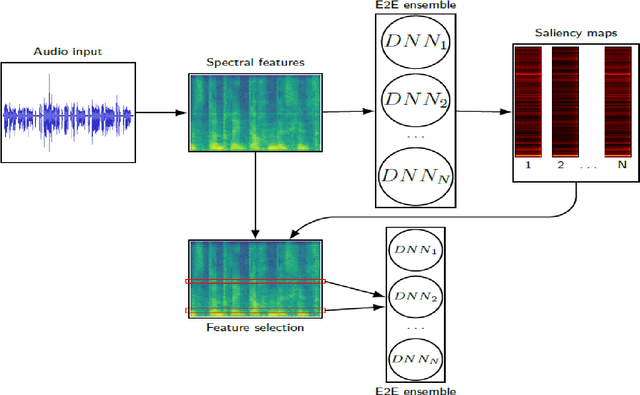
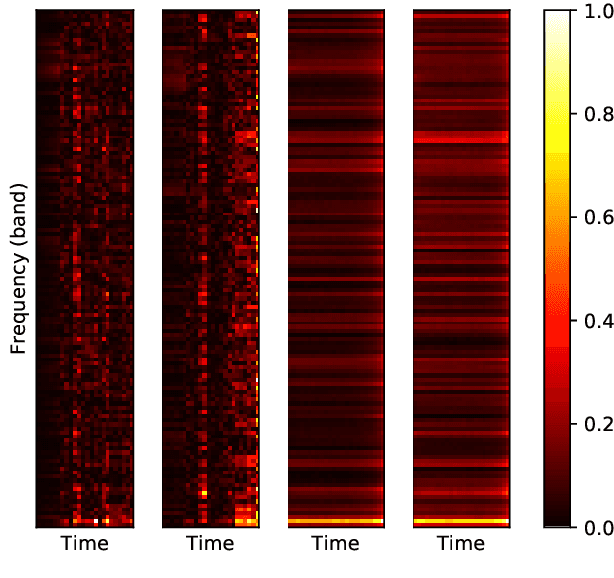
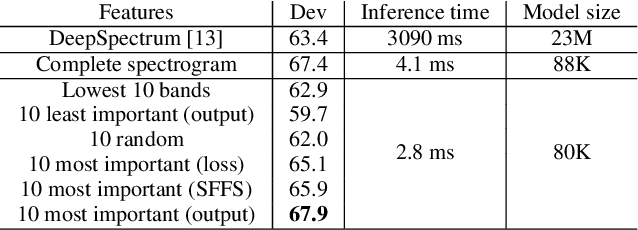
The events of recent years have highlighted the importance of telemedicine solutions which could potentially allow remote treatment and diagnosis. Relatedly, Computational Paralinguistics, a unique subfield of Speech Processing, aims to extract information about the speaker and form an important part of telemedicine applications. In this work, we focus on two paralinguistic problems: mask detection and breathing state prediction. Solutions developed for these tasks could be invaluable and have the potential to help monitor and limit the spread of a virus like COVID-19. The current state-of-the-art methods proposed for these tasks are ensembles based on deep neural networks like ResNets in conjunction with feature engineering. Although these ensembles can achieve high accuracy, they also have a large footprint and require substantial computational power reducing portability to devices with limited resources. These drawbacks also mean that the previously proposed solutions are infeasible to be used in a telemedicine system due to their size and speed. On the other hand, employing lighter feature-engineered systems can be laborious and add further complexity making them difficult to create a deployable system quickly. This work proposes an ensemble-based automatic feature selection method to enable the development of fast and memory-efficient systems. In particular, we propose an output-gradient-based method to discover essential features using large, well-performing ensembles before training a smaller one. In our experiments, we observed considerable (25-32%) reductions in inference times using neural network ensembles based on output-gradient-based features. Our method offers a simple way to increase the speed of the system and enable real-time usage while maintaining competitive results with larger-footprint ensemble using all spectral features.
Continual Learning for Monolingual End-to-End Automatic Speech Recognition
Dec 17, 2021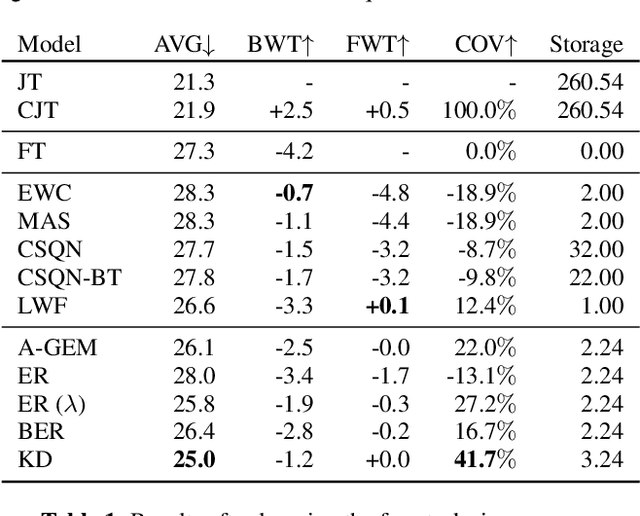
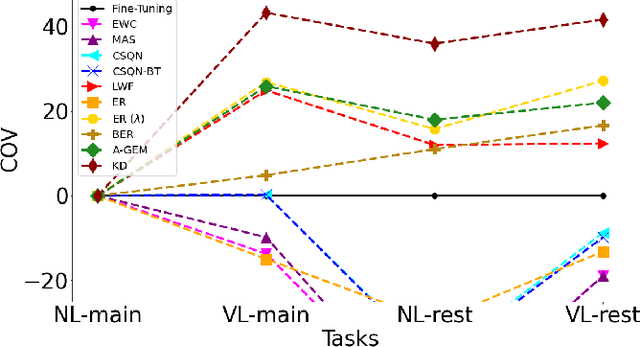
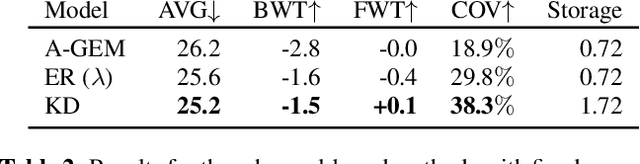
Adapting Automatic Speech Recognition (ASR) models to new domains leads to a deterioration of performance on the original domain(s), a phenomenon called Catastrophic Forgetting (CF). Even monolingual ASR models cannot be extended to new accents, dialects, topics, etc. without suffering from CF, making them unable to be continually enhanced without storing all past data. Fortunately, Continual Learning (CL) methods, which aim to enable continual adaptation while overcoming CF, can be used. In this paper, we implement an extensive number of CL methods for End-to-End ASR and test and compare their ability to extend a monolingual Hybrid CTC-Transformer model across four new tasks. We find that the best performing CL method closes the gap between the fine-tuned model (lower bound) and the model trained jointly on all tasks (upper bound) by more than 40%, while requiring access to only 0.6% of the original data.
UniST: Unified End-to-end Model for Streaming and Non-streaming Speech Translation
Sep 15, 2021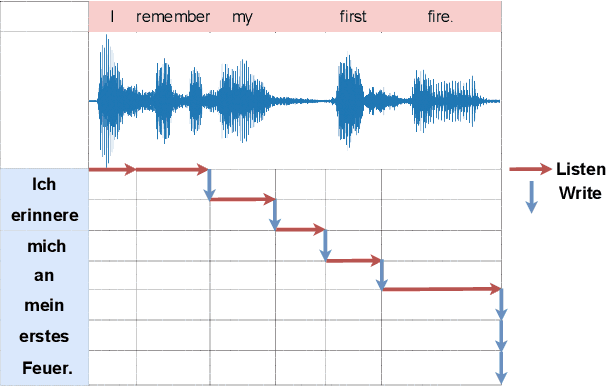

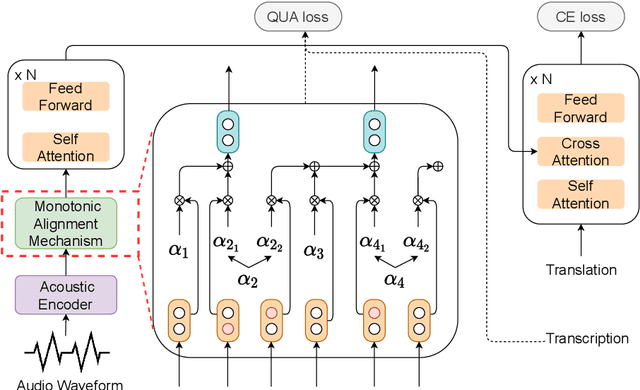

This paper presents a unified end-to-end frame-work for both streaming and non-streamingspeech translation. While the training recipes for non-streaming speech translation have been mature, the recipes for streaming speechtranslation are yet to be built. In this work, wefocus on developing a unified model (UniST) which supports streaming and non-streaming ST from the perspective of fundamental components, including training objective, attention mechanism and decoding policy. Experiments on the most popular speech-to-text translation benchmark dataset, MuST-C, show that UniST achieves significant improvement for non-streaming ST, and a better-learned trade-off for BLEU score and latency metrics for streaming ST, compared with end-to-end baselines and the cascaded models. We will make our codes and evaluation tools publicly available.
Mixer-TTS: non-autoregressive, fast and compact text-to-speech model conditioned on language model embeddings
Oct 07, 2021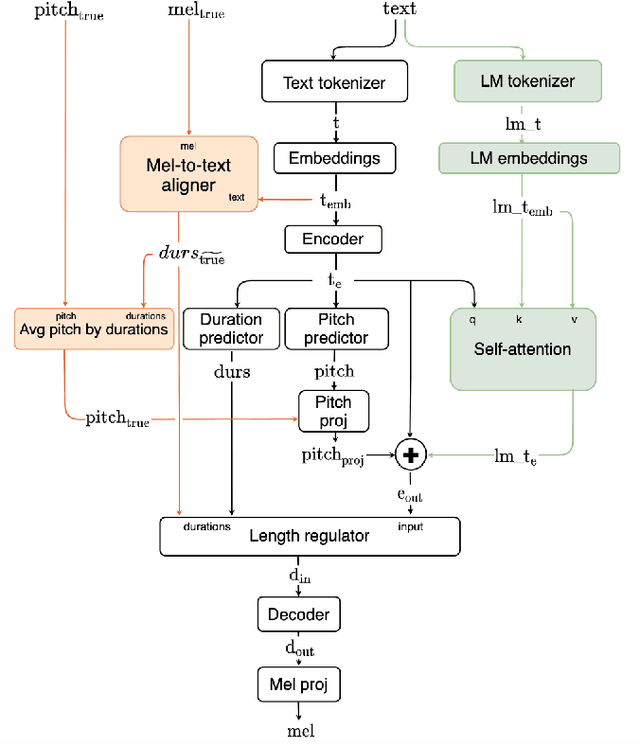
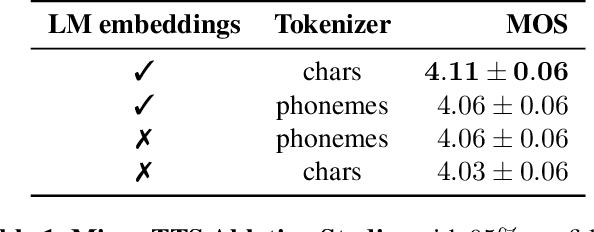
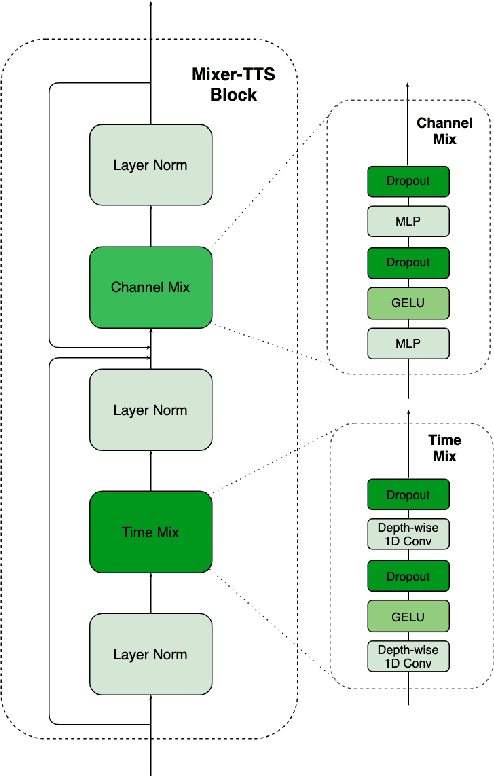
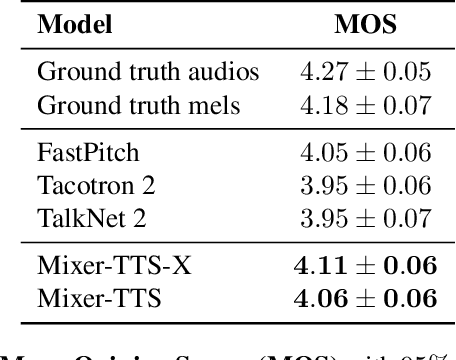
This paper describes Mixer-TTS, a non-autoregressive model for mel-spectrogram generation. The model is based on the MLP-Mixer architecture adapted for speech synthesis. The basic Mixer-TTS contains pitch and duration predictors, with the latter being trained with an unsupervised TTS alignment framework. Alongside the basic model, we propose the extended version which additionally uses token embeddings from a pre-trained language model. Basic Mixer-TTS and its extended version achieve a mean opinion score (MOS) of 4.05 and 4.11, respectively, compared to a MOS of 4.27 of original LJSpeech samples. Both versions have a small number of parameters and enable much faster speech synthesis compared to the models with similar quality.