 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Offensive Language and Hate Speech Detection with Deep Learning and Transfer Learning
Aug 23, 2021
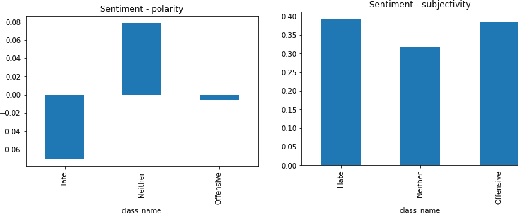

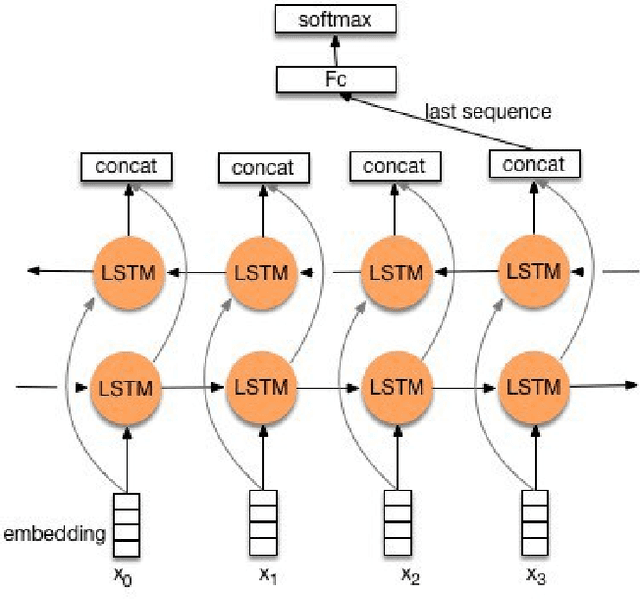
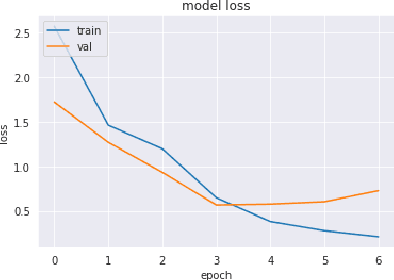
Toxic online speech has become a crucial problem nowadays due to an exponential increase in the use of internet by people from different cultures and educational backgrounds. Differentiating if a text message belongs to hate speech and offensive language is a key challenge in automatic detection of toxic text content. In this paper, we propose an approach to automatically classify tweets into three classes: Hate, offensive and Neither. Using public tweet data set, we first perform experiments to build BI-LSTM models from empty embedding and then we also try the same neural network architecture with pre-trained Glove embedding. Next, we introduce a transfer learning approach for hate speech detection using an existing pre-trained language model BERT (Bidirectional Encoder Representations from Transformers), DistilBert (Distilled version of BERT) and GPT-2 (Generative Pre-Training). We perform hyper parameters tuning analysis of our best model (BI-LSTM) considering different neural network architectures, learn-ratings and normalization methods etc. After tuning the model and with the best combination of parameters, we achieve over 92 percent accuracy upon evaluating it on test data. We also create a class module which contains main functionality including text classification, sentiment checking and text data augmentation. This model could serve as an intermediate module between user and Twitter.
Exploiting ultrasound tongue imaging for the automatic detection of speech articulation errors
Feb 27, 2021

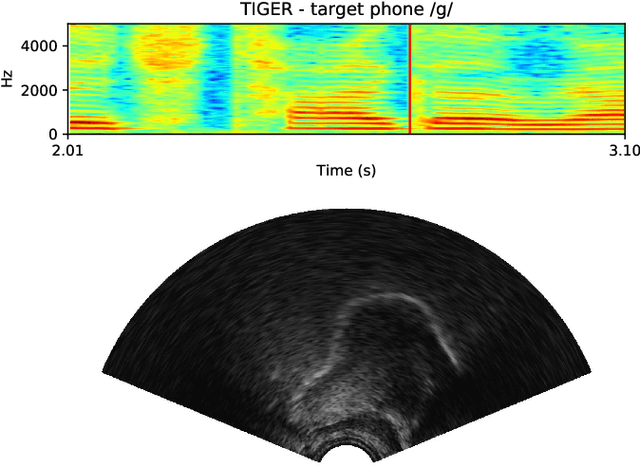
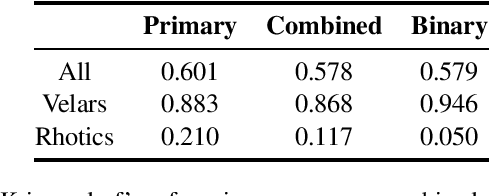
Speech sound disorders are a common communication impairment in childhood. Because speech disorders can negatively affect the lives and the development of children, clinical intervention is often recommended. To help with diagnosis and treatment, clinicians use instrumented methods such as spectrograms or ultrasound tongue imaging to analyse speech articulations. Analysis with these methods can be laborious for clinicians, therefore there is growing interest in its automation. In this paper, we investigate the contribution of ultrasound tongue imaging for the automatic detection of speech articulation errors. Our systems are trained on typically developing child speech and augmented with a database of adult speech using audio and ultrasound. Evaluation on typically developing speech indicates that pre-training on adult speech and jointly using ultrasound and audio gives the best results with an accuracy of 86.9%. To evaluate on disordered speech, we collect pronunciation scores from experienced speech and language therapists, focusing on cases of velar fronting and gliding of /r/. The scores show good inter-annotator agreement for velar fronting, but not for gliding errors. For automatic velar fronting error detection, the best results are obtained when jointly using ultrasound and audio. The best system correctly detects 86.6% of the errors identified by experienced clinicians. Out of all the segments identified as errors by the best system, 73.2% match errors identified by clinicians. Results on automatic gliding detection are harder to interpret due to poor inter-annotator agreement, but appear promising. Overall findings suggest that automatic detection of speech articulation errors has potential to be integrated into ultrasound intervention software for automatically quantifying progress during speech therapy.
* 15 pages, 9 figures, 6 tables
A Neural Text-to-Speech Model Utilizing Broadcast Data Mixed with Background Music
Mar 04, 2021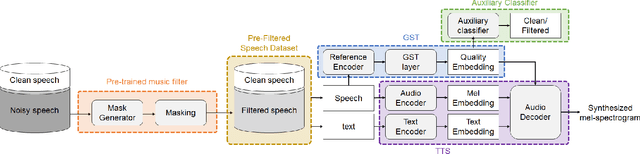
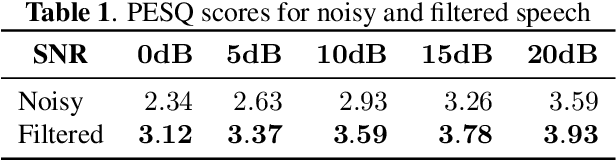
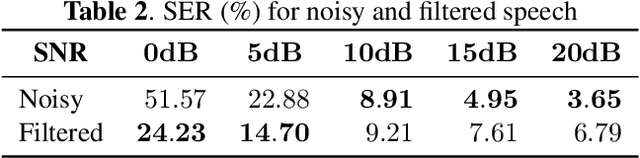
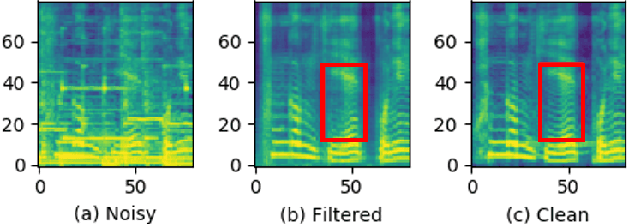
Recently, it has become easier to obtain speech data from various media such as the internet or YouTube, but directly utilizing them to train a neural text-to-speech (TTS) model is difficult. The proportion of clean speech is insufficient and the remainder includes background music. Even with the global style token (GST). Therefore, we propose the following method to successfully train an end-to-end TTS model with limited broadcast data. First, the background music is removed from the speech by introducing a music filter. Second, the GST-TTS model with an auxiliary quality classifier is trained with the filtered speech and a small amount of clean speech. In particular, the quality classifier makes the embedding vector of the GST layer focus on representing the speech quality (filtered or clean) of the input speech. The experimental results verified that the proposed method synthesized much more high-quality speech than conventional methods.
A Crowdsourced Open-Source Kazakh Speech Corpus and Initial Speech Recognition Baseline
Sep 22, 2020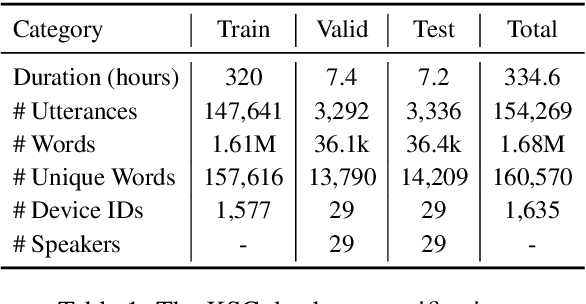
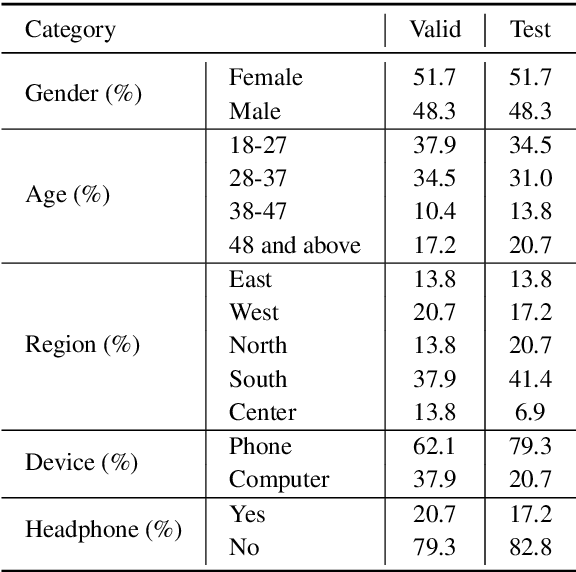
We present an open-source speech corpus for the Kazakh language. The Kazakh speech corpus (KSC) contains around 335 hours of transcribed audio comprising over 154,000 utterances spoken by participants from different regions, age groups, and gender. It was carefully inspected by native Kazakh speakers to ensure high quality. The KSC is the largest publicly available database developed to advance various Kazakh speech and language processing applications. In this paper, we first describe the data collection and prepossessing procedures followed by the description of the database specifications. We also share our experience and challenges faced during database construction. To demonstrate the reliability of the database, we performed the preliminary speech recognition experiments. The experimental results imply that the quality of audio and transcripts are promising. To enable experiment reproducibility and ease the corpus usage, we also released the ESPnet recipe.
Learning to Inference with Early Exit in the Progressive Speech Enhancement
Jun 22, 2021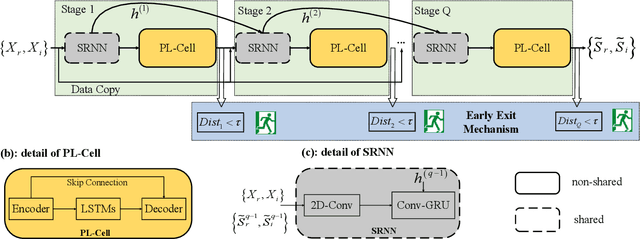
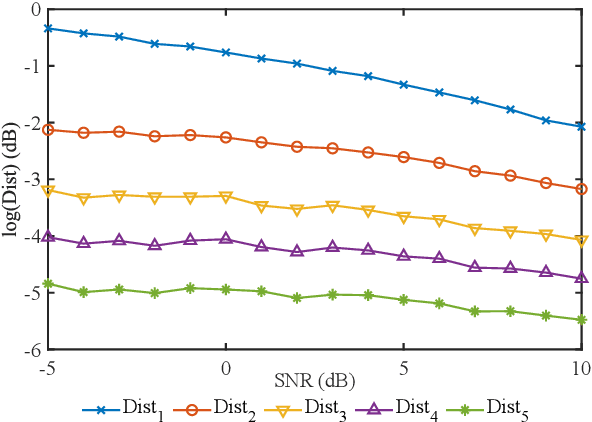
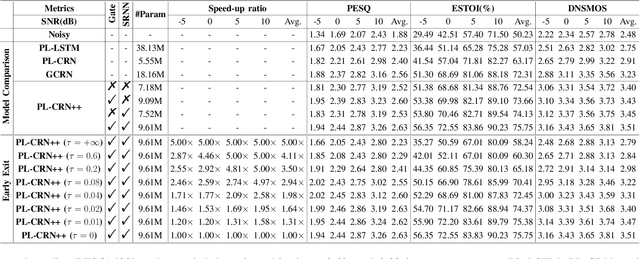
In real scenarios, it is often necessary and significant to control the inference speed of speech enhancement systems under different conditions. To this end, we propose a stage-wise adaptive inference approach with early exit mechanism for progressive speech enhancement. Specifically, in each stage, once the spectral distance between adjacent stages lowers the empirically preset threshold, the inference will terminate and output the estimation, which can effectively accelerate the inference speed. To further improve the performance of existing speech enhancement systems, PL-CRN++ is proposed, which is an improved version over our preliminary work PL-CRN and combines stage recurrent mechanism and complex spectral mapping. Extensive experiments are conducted on the TIMIT corpus, the results demonstrate the superiority of our system over state-of-the-art baselines in terms of PESQ, ESTOI and DNSMOS. Moreover, by adjusting the threshold, we can easily control the inference efficiency while sustaining the system performance.
Context-Aware Prosody Correction for Text-Based Speech Editing
Feb 16, 2021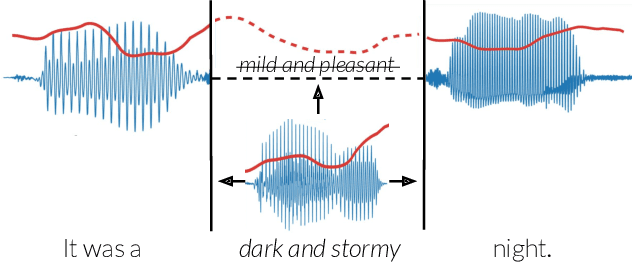

Text-based speech editors expedite the process of editing speech recordings by permitting editing via intuitive cut, copy, and paste operations on a speech transcript. A major drawback of current systems, however, is that edited recordings often sound unnatural because of prosody mismatches around edited regions. In our work, we propose a new context-aware method for more natural sounding text-based editing of speech. To do so, we 1) use a series of neural networks to generate salient prosody features that are dependent on the prosody of speech surrounding the edit and amenable to fine-grained user control 2) use the generated features to control a standard pitch-shift and time-stretch method and 3) apply a denoising neural network to remove artifacts induced by the signal manipulation to yield a high-fidelity result. We evaluate our approach using a subjective listening test, provide a detailed comparative analysis, and conclude several interesting insights.
TADRN: Triple-Attentive Dual-Recurrent Network for Ad-hoc Array Multichannel Speech Enhancement
Oct 22, 2021


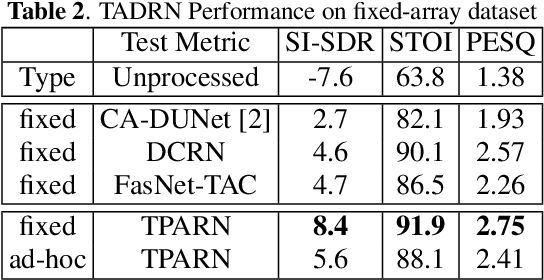
Deep neural networks (DNNs) have been successfully used for multichannel speech enhancement in fixed array geometries. However, challenges remain for ad-hoc arrays with unknown microphone placements. We propose a deep neural network based approach for ad-hoc array processing: Triple-Attentive Dual-Recurrent Network (TADRN). TADRN uses self-attention across channels for learning spatial information and a dual-path attentive recurrent network (ARN) for temporal modeling. Temporal modeling is done independently for all channels by dividing a signal into smaller chunks and using an intra-chunk ARN for local modeling and an inter-chunk ARN for global modeling. Consequently, TADRN uses triple-path attention: inter-channel, intra-chunk, and inter-chunk, and dual-path recurrence: intra-chunk and inter-chunk. Experimental results show excellent performance of TADRN. We demonstrate that TADRN improves speech enhancement by leveraging additional randomly placed microphones, even at locations far from the target source. Additionally, large improvements in objective scores are observed when poorly placed microphones in the scene are complemented with more effective microphone positions, such as those closer to a target source.
Longitudinal Sentiment Analyses for Radicalization Research: Intertemporal Dynamics on Social Media Platforms and their Implications
Oct 01, 2022This discussion paper demonstrates how longitudinal sentiment analyses can depict intertemporal dynamics on social media platforms, what challenges are inherent and how further research could benefit from a longitudinal perspective. Furthermore and since tools for sentiment analyses shall simplify and accelerate the analytical process regarding qualitative data at acceptable inter-rater reliability, their applicability in the context of radicalization research will be examined regarding the Tweets collected on January 6th 2021, the day of the storming of the U.S. Capitol in Washington. Therefore, a total of 49,350 Tweets will be analyzed evenly distributed within three different sequences: before, during and after the U.S. Capitol in Washington was stormed. These sequences highlight the intertemporal dynamics within comments on social media platforms as well as the possible benefits of a longitudinal perspective when using conditional means and conditional variances. Limitations regarding the identification of supporters of such events and associated hate speech as well as common application errors will be demonstrated as well. As a result, only under certain conditions a longitudinal sentiment analysis can increase the accuracy of evidence based predictions in the context of radicalization research.
Adversarial synthesis based data-augmentation for code-switched spoken language identification
May 30, 2022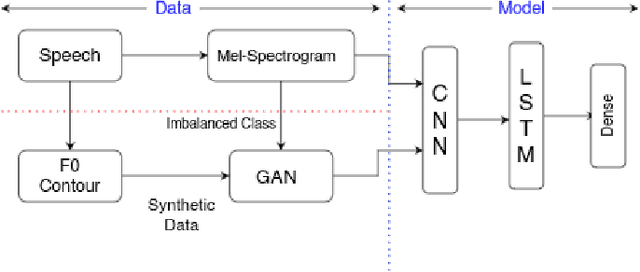
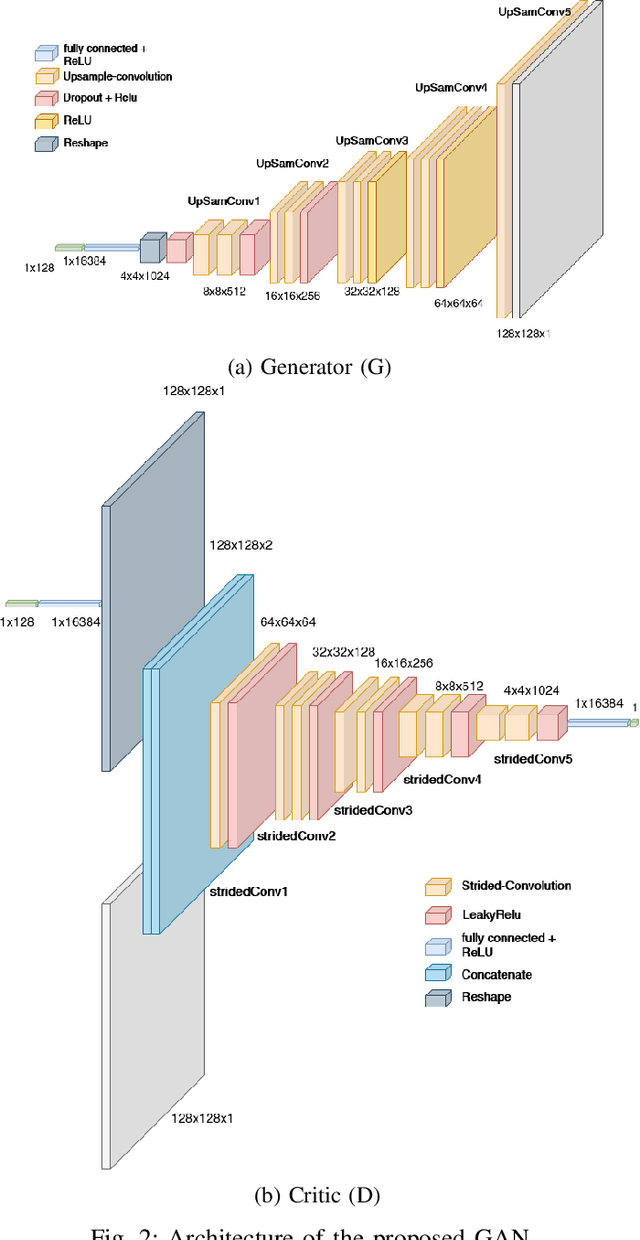
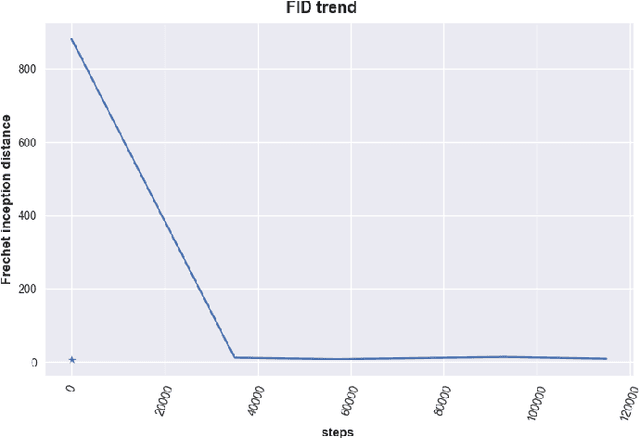
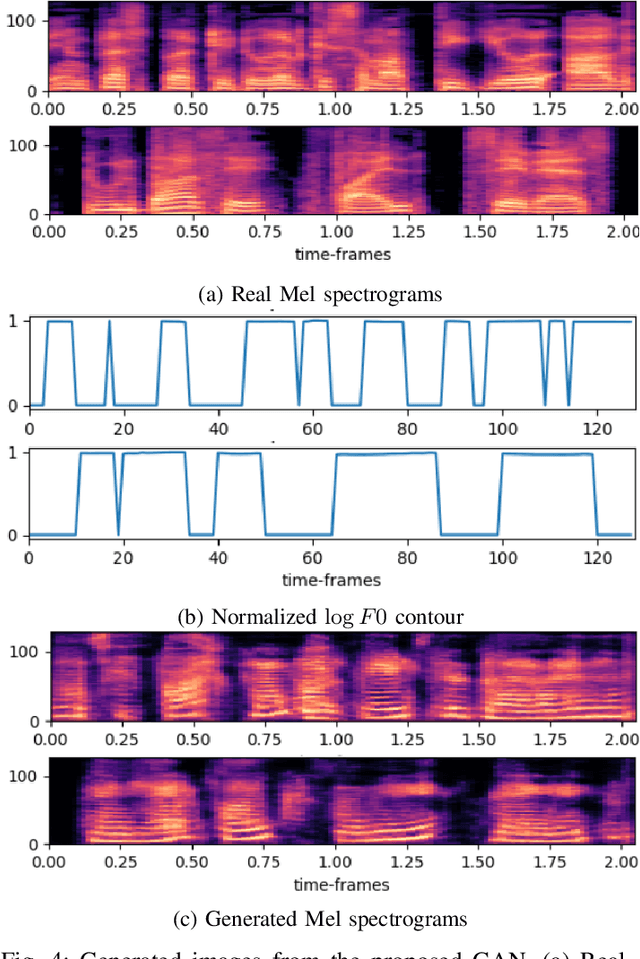
Spoken Language Identification (LID) is an important sub-task of Automatic Speech Recognition(ASR) that is used to classify the language(s) in an audio segment. Automatic LID plays an useful role in multilingual countries. In various countries, identifying a language becomes hard, due to the multilingual scenario where two or more than two languages are mixed together during conversation. Such phenomenon of speech is called as code-mixing or code-switching. This nature is followed not only in India but also in many Asian countries. Such code-mixed data is hard to find, which further reduces the capabilities of the spoken LID. Due to the lack of avalibility of this code-mixed data, it becomes a minority class in LID task. Hence, this work primarily addresses this problem using data augmentation as a solution on the minority code-switched class. This study focuses on Indic language code-mixed with English. Spoken LID is performed on Hindi, code-mixed with English. This research proposes Generative Adversarial Network (GAN) based data augmentation technique performed using Mel spectrograms for audio data. GANs have already been proven to be accurate in representing the real data distribution in the image domain. Proposed research exploits these capabilities of GANs in speech domains such as speech classification, automatic speech recognition,etc. GANs are trained to generate Mel spectrograms of the minority code-mixed class which are then used to augment data for the classifier. Utilizing GANs give an overall improvement on Unweighted Average Recall by an amount of 3.5\% as compared to a Convolutional Recurrent Neural Network (CRNN) classifier used as the baseline reference.
Embedding and Beamforming: All-neural Causal Beamformer for Multichannel Speech Enhancement
Sep 02, 2021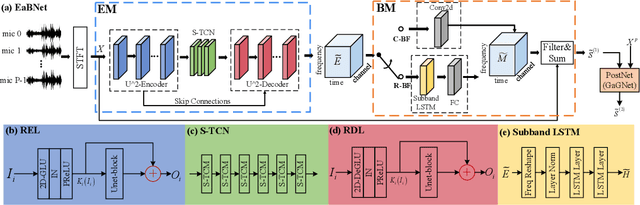
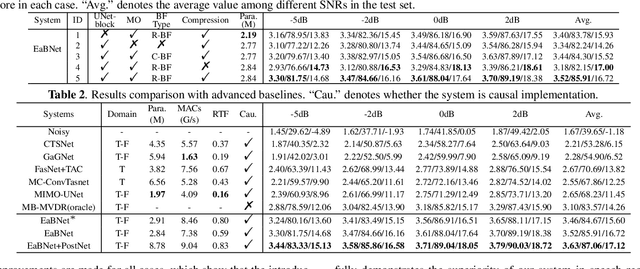
The spatial covariance matrix has been considered to be significant for beamformers. Standing upon the intersection of traditional beamformers and deep neural networks, we propose a causal neural beamformer paradigm called Embedding and Beamforming, and two core modules are designed accordingly, namely EM and BM. For EM, instead of estimating spatial covariance matrix explicitly, the 3-D embedding tensor is learned with the network, where both spectral and spatial discriminative information can be represented. For BM, a network is directly leveraged to derive the beamforming weights so as to implement filter-and-sum operation. To further improve the speech quality, a post-processing module is introduced to further suppress the residual noise. Based on the DNS-Challenge dataset, we conduct the experiments for multichannel speech enhancement and the results show that the proposed system outperforms previous advanced baselines by a large margin in multiple evaluation metrics.