 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Towards Energy-Efficient, Low-Latency and Accurate Spiking LSTMs
Oct 23, 2022
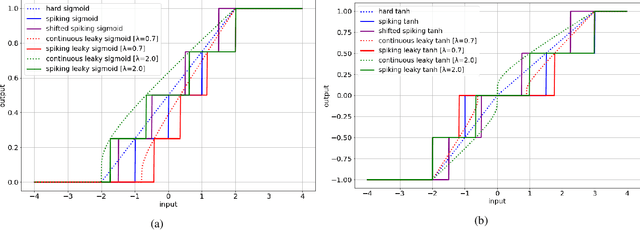
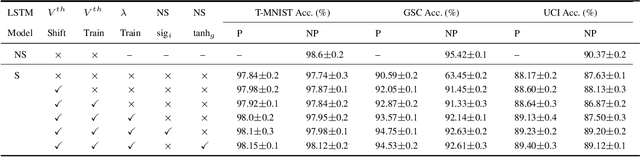

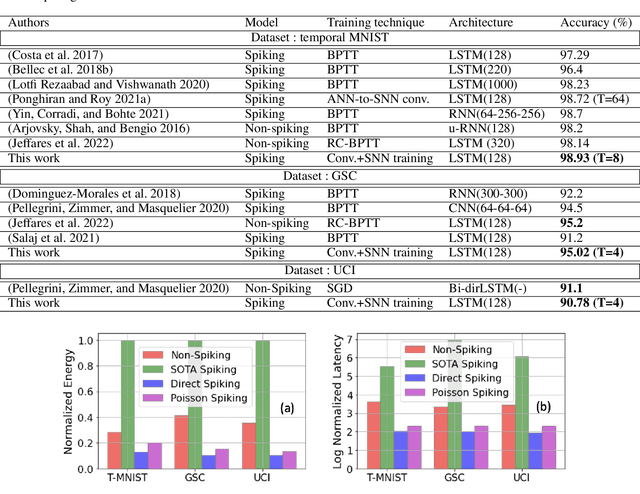
Spiking Neural Networks (SNNs) have emerged as an attractive spatio-temporal computing paradigm for complex vision tasks. However, most existing works yield models that require many time steps and do not leverage the inherent temporal dynamics of spiking neural networks, even for sequential tasks. Motivated by this observation, we propose an \rev{optimized spiking long short-term memory networks (LSTM) training framework that involves a novel ANN-to-SNN conversion framework, followed by SNN training}. In particular, we propose novel activation functions in the source LSTM architecture and judiciously select a subset of them for conversion to integrate-and-fire (IF) activations with optimal bias shifts. Additionally, we derive the leaky-integrate-and-fire (LIF) activation functions converted from their non-spiking LSTM counterparts which justifies the need to jointly optimize the weights, threshold, and leak parameter. We also propose a pipelined parallel processing scheme which hides the SNN time steps, significantly improving system latency, especially for long sequences. The resulting SNNs have high activation sparsity and require only accumulate operations (AC), in contrast to expensive multiply-and-accumulates (MAC) needed for ANNs, except for the input layer when using direct encoding, yielding significant improvements in energy efficiency. We evaluate our framework on sequential learning tasks including temporal MNIST, Google Speech Commands (GSC), and UCI Smartphone datasets on different LSTM architectures. We obtain test accuracy of 94.75% with only 2 time steps with direct encoding on the GSC dataset with 4.1x lower energy than an iso-architecture standard LSTM.
Improving spatial cues for hearables using a parameterized binaural CDR estimator
Jul 17, 2022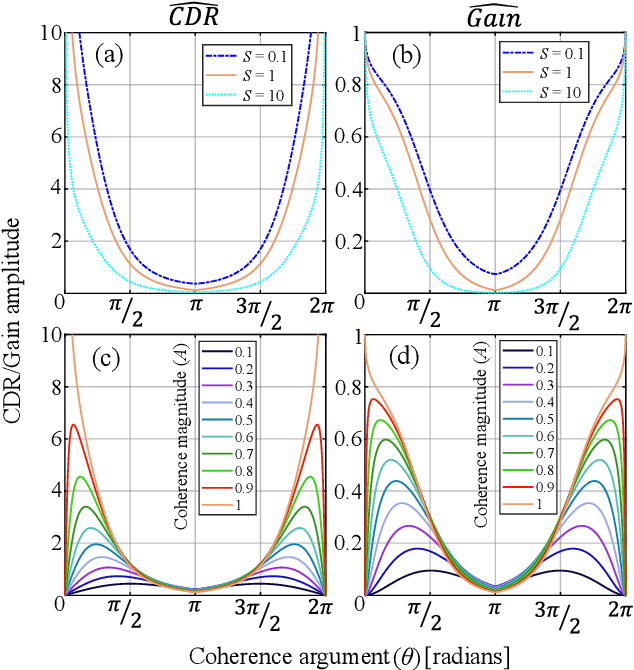
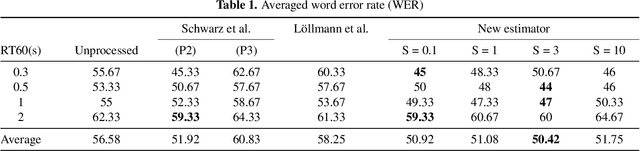
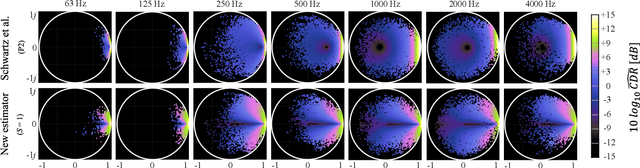
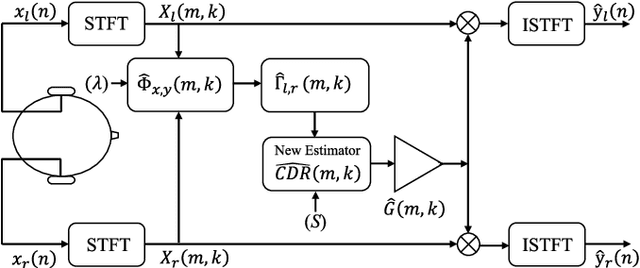
We investigate a speech enhancement method based on the binaural coherence-to-diffuse power ratio (CDR), which preserves auditory spatial cues for maskers and a broadside target. Conventional CDR estimators typically rely on a mathematical coherence model of the desired signal and/or diffuse noise field in their formulation, which may influence their accuracy in natural environments. This work proposes a new robust and parameterized directional binaural CDR estimator. The estimator is calculated in the time-frequency domain and is based on a geometrical interpretation of the spatial coherence function between the binaural microphone signals. The binaural performance of the new CDR estimator is compared with three state-of-the-art CDR estimators in cocktail-party-like environments and has shown improvements in terms of several objective speech quality metrics such as PESQ and SRMR. We also discuss the benefits of the parameterizable CDR estimator for varying sound environments and briefly reflect on several informal subjective evaluations using a low-latency real-time framework.
A Transfer Learning Method for Speech Emotion Recognition from Automatic Speech Recognition
Aug 15, 2020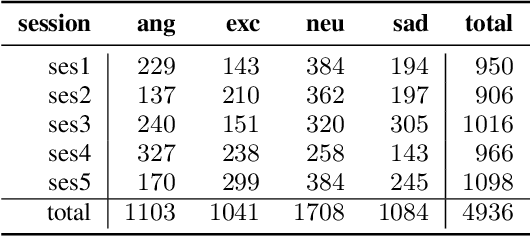
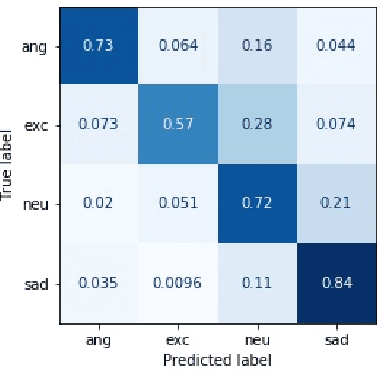

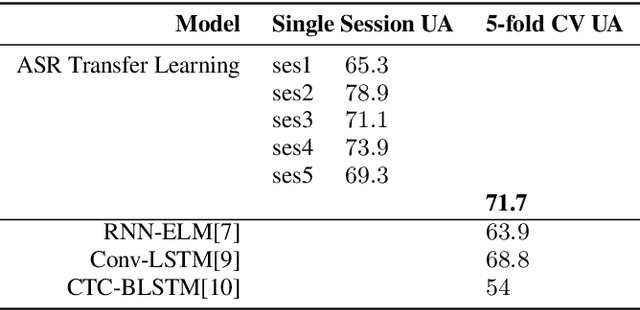
This paper presents a transfer learning method in speech emotion recognition based on a Time-Delay Neural Network (TDNN) architecture. A major challenge in the current speech-based emotion detection research is data scarcity. The proposed method resolves this problem by applying transfer learning techniques in order to leverage data from the automatic speech recognition (ASR) task for which ample data is available. Our experiments also show the advantage of speaker-class adaptation modeling techniques by adopting identity-vector (i-vector) based features in addition to standard Mel-Frequency Cepstral Coefficient (MFCC) features.[1] We show the transfer learning models significantly outperform the other methods without pretraining on ASR. The experiments performed on the publicly available IEMOCAP dataset which provides 12 hours of motional speech data. The transfer learning was initialized by using the Ted-Lium v.2 speech dataset providing 207 hours of audio with the corresponding transcripts. We achieve the highest significantly higher accuracy when compared to state-of-the-art, using five-fold cross validation. Using only speech, we obtain an accuracy 71.7% for anger, excitement, sadness, and neutrality emotion content.
Meta-Learning for Adaptive Filters with Higher-Order Frequency Dependencies
Sep 20, 2022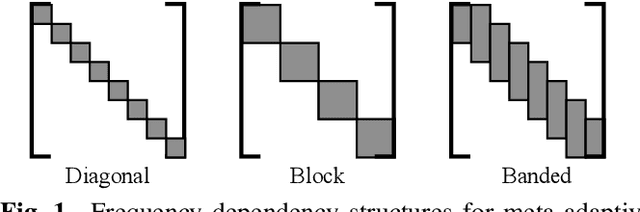
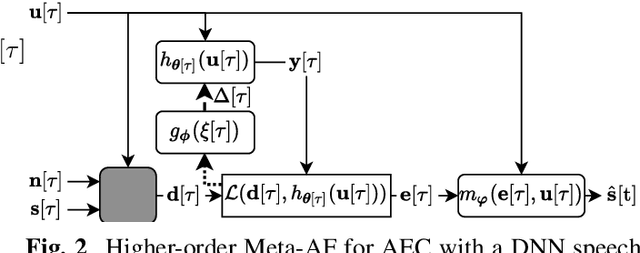
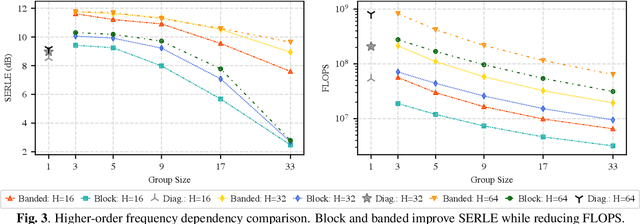
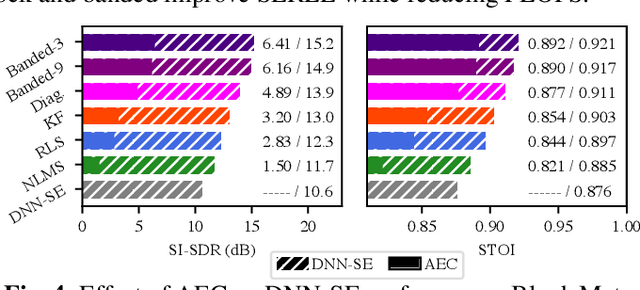
Adaptive filters are applicable to many signal processing tasks including acoustic echo cancellation, beamforming, and more. Adaptive filters are typically controlled using algorithms such as least-mean squares(LMS), recursive least squares(RLS), or Kalman filter updates. Such models are often applied in the frequency domain, assume frequency independent processing, and do not exploit higher-order frequency dependencies, for simplicity. Recent work on meta-adaptive filters, however, has shown that we can control filter adaptation using neural networks without manual derivation, motivating new work to exploit such information. In this work, we present higher-order meta-adaptive filters, a key improvement to meta-adaptive filters that incorporates higher-order frequency dependencies. We demonstrate our approach on acoustic echo cancellation and develop a family of filters that yield multi-dB improvements over competitive baselines, and are at least an order-of-magnitude less complex. Moreover, we show our improvements hold with or without a downstream speech enhancer.
Generalizing in the Real World with Representation Learning
Oct 18, 2022
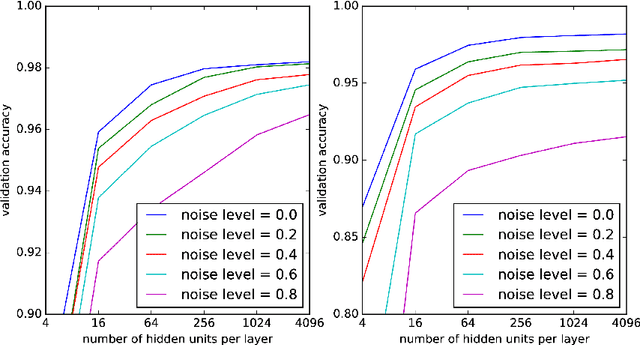
Machine learning (ML) formalizes the problem of getting computers to learn from experience as optimization of performance according to some metric(s) on a set of data examples. This is in contrast to requiring behaviour specified in advance (e.g. by hard-coded rules). Formalization of this problem has enabled great progress in many applications with large real-world impact, including translation, speech recognition, self-driving cars, and drug discovery. But practical instantiations of this formalism make many assumptions - for example, that data are i.i.d.: independent and identically distributed - whose soundness is seldom investigated. And in making great progress in such a short time, the field has developed many norms and ad-hoc standards, focused on a relatively small range of problem settings. As applications of ML, particularly in artificial intelligence (AI) systems, become more pervasive in the real world, we need to critically examine these assumptions, norms, and problem settings, as well as the methods that have become de-facto standards. There is much we still do not understand about how and why deep networks trained with stochastic gradient descent are able to generalize as well as they do, why they fail when they do, and how they will perform on out-of-distribution data. In this thesis I cover some of my work towards better understanding deep net generalization, identify several ways assumptions and problem settings fail to generalize to the real world, and propose ways to address those failures in practice.
Exploiting ultrasound tongue imaging for the automatic detection of speech articulation errors
Feb 27, 2021

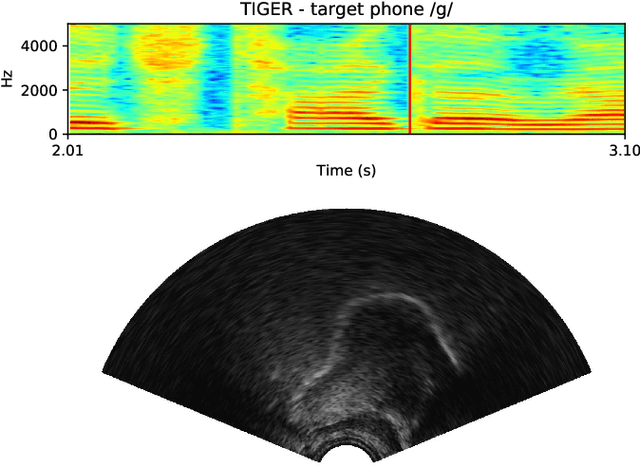
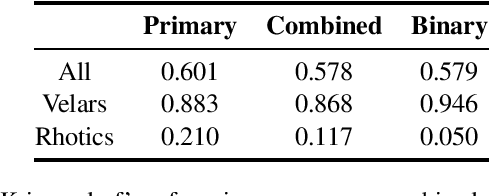
Speech sound disorders are a common communication impairment in childhood. Because speech disorders can negatively affect the lives and the development of children, clinical intervention is often recommended. To help with diagnosis and treatment, clinicians use instrumented methods such as spectrograms or ultrasound tongue imaging to analyse speech articulations. Analysis with these methods can be laborious for clinicians, therefore there is growing interest in its automation. In this paper, we investigate the contribution of ultrasound tongue imaging for the automatic detection of speech articulation errors. Our systems are trained on typically developing child speech and augmented with a database of adult speech using audio and ultrasound. Evaluation on typically developing speech indicates that pre-training on adult speech and jointly using ultrasound and audio gives the best results with an accuracy of 86.9%. To evaluate on disordered speech, we collect pronunciation scores from experienced speech and language therapists, focusing on cases of velar fronting and gliding of /r/. The scores show good inter-annotator agreement for velar fronting, but not for gliding errors. For automatic velar fronting error detection, the best results are obtained when jointly using ultrasound and audio. The best system correctly detects 86.6% of the errors identified by experienced clinicians. Out of all the segments identified as errors by the best system, 73.2% match errors identified by clinicians. Results on automatic gliding detection are harder to interpret due to poor inter-annotator agreement, but appear promising. Overall findings suggest that automatic detection of speech articulation errors has potential to be integrated into ultrasound intervention software for automatically quantifying progress during speech therapy.
* 15 pages, 9 figures, 6 tables
Blind Room Parameter Estimation Using Multiple-Multichannel Speech Recordings
Jul 29, 2021
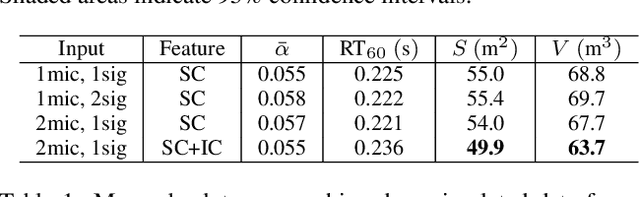
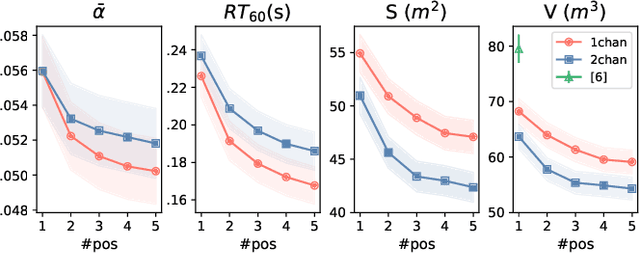
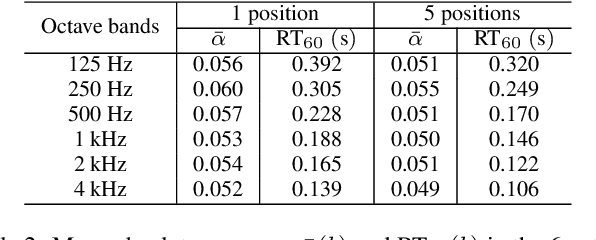
Knowing the geometrical and acoustical parameters of a room may benefit applications such as audio augmented reality, speech dereverberation or audio forensics. In this paper, we study the problem of jointly estimating the total surface area, the volume, as well as the frequency-dependent reverberation time and mean surface absorption of a room in a blind fashion, based on two-channel noisy speech recordings from multiple, unknown source-receiver positions. A novel convolutional neural network architecture leveraging both single- and inter-channel cues is proposed and trained on a large, realistic simulated dataset. Results on both simulated and real data show that using multiple observations in one room significantly reduces estimation errors and variances on all target quantities, and that using two channels helps the estimation of surface and volume. The proposed model outperforms a recently proposed blind volume estimation method on the considered datasets.
A Neural Text-to-Speech Model Utilizing Broadcast Data Mixed with Background Music
Mar 04, 2021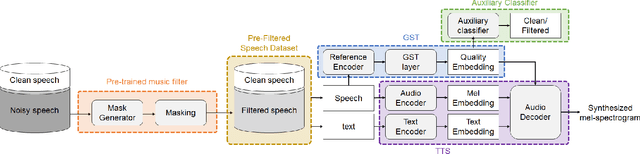
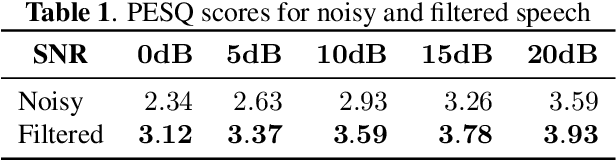
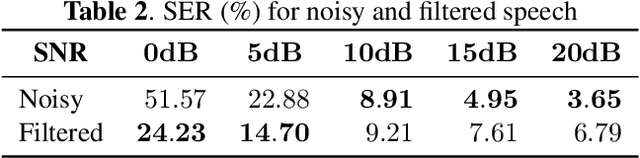
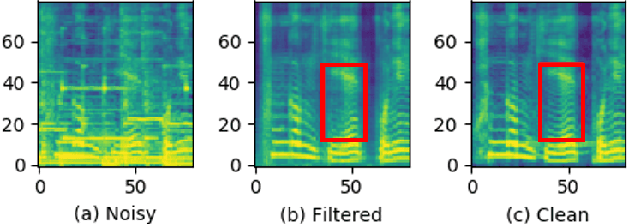
Recently, it has become easier to obtain speech data from various media such as the internet or YouTube, but directly utilizing them to train a neural text-to-speech (TTS) model is difficult. The proportion of clean speech is insufficient and the remainder includes background music. Even with the global style token (GST). Therefore, we propose the following method to successfully train an end-to-end TTS model with limited broadcast data. First, the background music is removed from the speech by introducing a music filter. Second, the GST-TTS model with an auxiliary quality classifier is trained with the filtered speech and a small amount of clean speech. In particular, the quality classifier makes the embedding vector of the GST layer focus on representing the speech quality (filtered or clean) of the input speech. The experimental results verified that the proposed method synthesized much more high-quality speech than conventional methods.
A Crowdsourced Open-Source Kazakh Speech Corpus and Initial Speech Recognition Baseline
Sep 22, 2020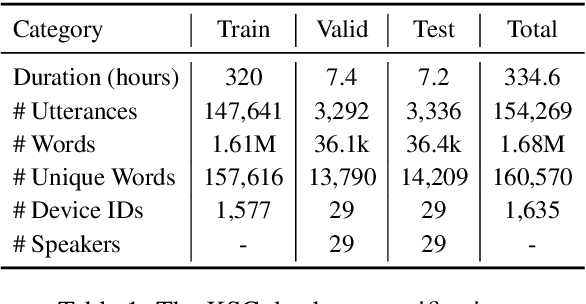
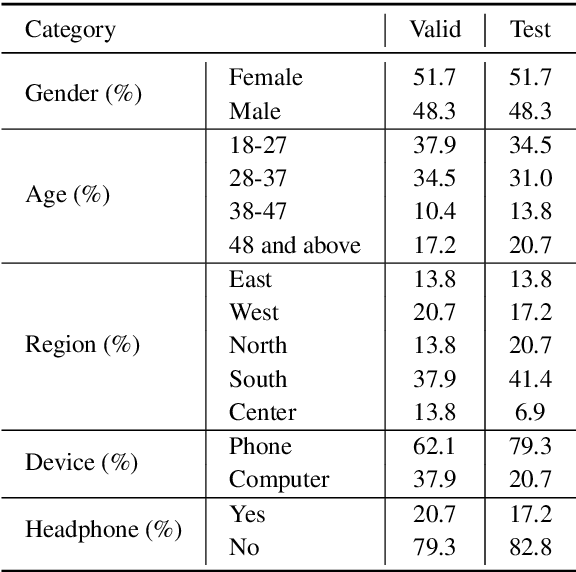
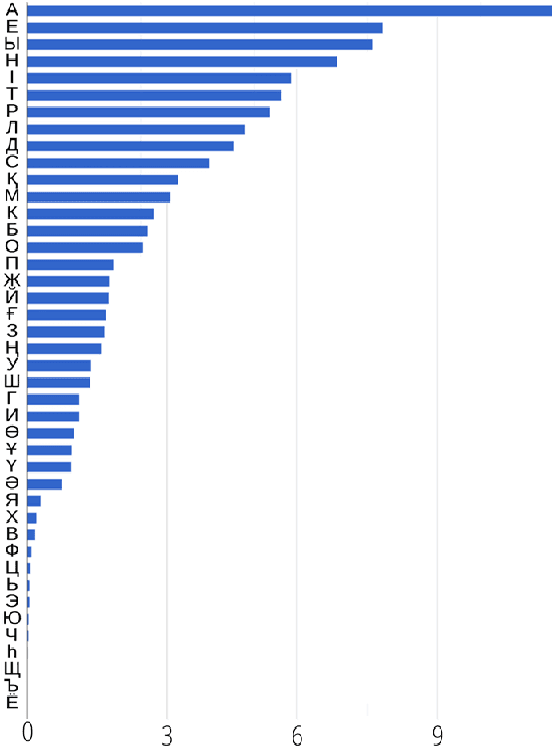
We present an open-source speech corpus for the Kazakh language. The Kazakh speech corpus (KSC) contains around 335 hours of transcribed audio comprising over 154,000 utterances spoken by participants from different regions, age groups, and gender. It was carefully inspected by native Kazakh speakers to ensure high quality. The KSC is the largest publicly available database developed to advance various Kazakh speech and language processing applications. In this paper, we first describe the data collection and prepossessing procedures followed by the description of the database specifications. We also share our experience and challenges faced during database construction. To demonstrate the reliability of the database, we performed the preliminary speech recognition experiments. The experimental results imply that the quality of audio and transcripts are promising. To enable experiment reproducibility and ease the corpus usage, we also released the ESPnet recipe.
VocBench: A Neural Vocoder Benchmark for Speech Synthesis
Dec 06, 2021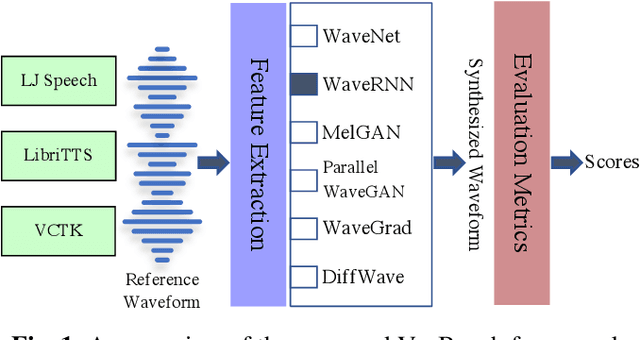
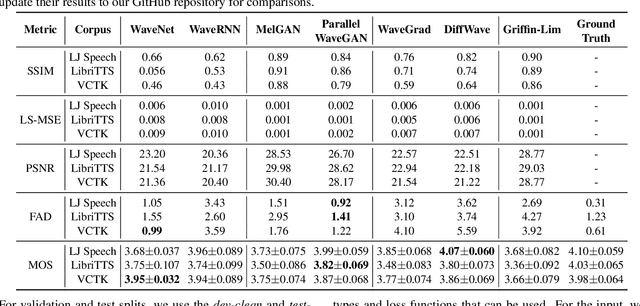
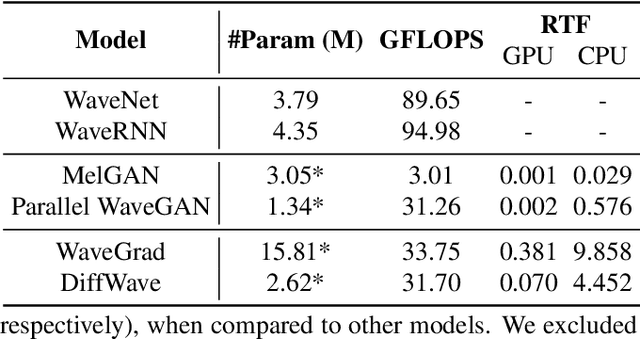
Neural vocoders, used for converting the spectral representations of an audio signal to the waveforms, are a commonly used component in speech synthesis pipelines. It focuses on synthesizing waveforms from low-dimensional representation, such as Mel-Spectrograms. In recent years, different approaches have been introduced to develop such vocoders. However, it becomes more challenging to assess these new vocoders and compare their performance to previous ones. To address this problem, we present VocBench, a framework that benchmark the performance of state-of-the art neural vocoders. VocBench uses a systematic study to evaluate different neural vocoders in a shared environment that enables a fair comparison between them. In our experiments, we use the same setup for datasets, training pipeline, and evaluation metrics for all neural vocoders. We perform a subjective and objective evaluation to compare the performance of each vocoder along a different axis. Our results demonstrate that the framework is capable of showing the competitive efficacy and the quality of the synthesized samples for each vocoder. VocBench framework is available at https://github.com/facebookresearch/vocoder-benchmark.