 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Interpreting intermediate convolutional layers of CNNs trained on raw speech
Apr 21, 2021
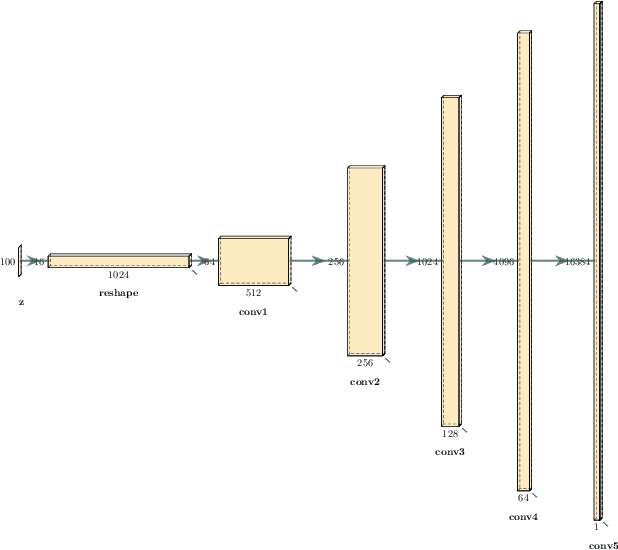
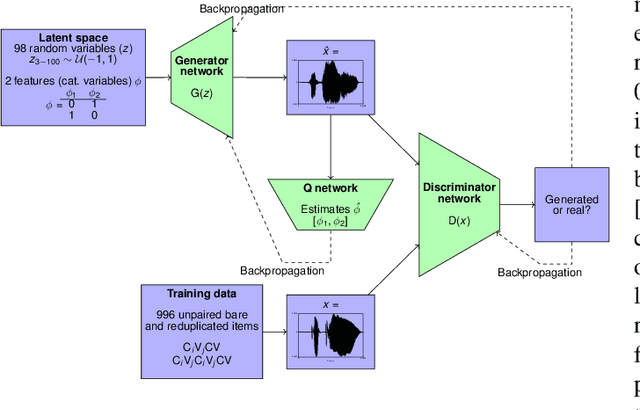
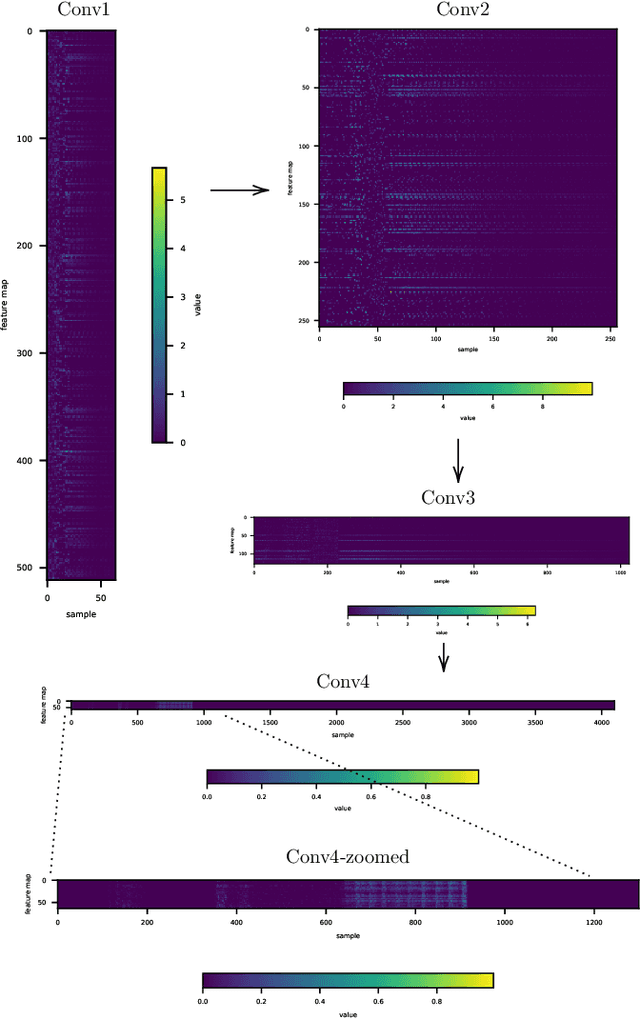
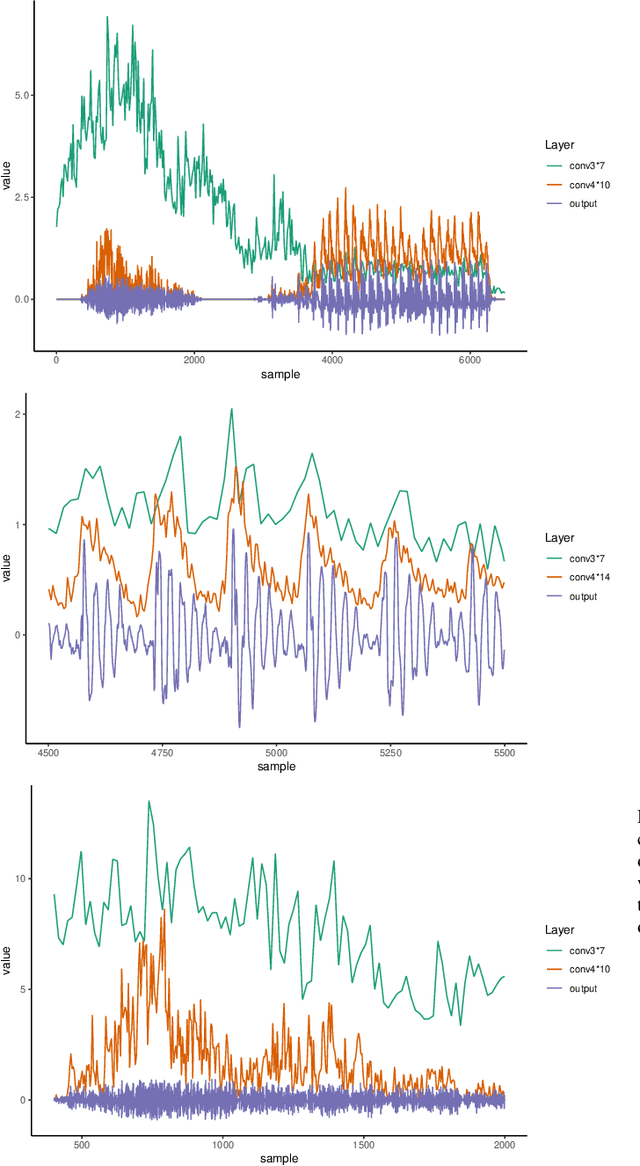
This paper presents a technique to interpret and visualize intermediate layers in CNNs trained on raw speech data in an unsupervised manner. We show that averaging over feature maps after ReLU activation in each convolutional layer yields interpretable time-series data. The proposed technique enables acoustic analysis of intermediate convolutional layers. To uncover how meaningful representation in speech gets encoded in intermediate layers of CNNs, we manipulate individual latent variables to marginal levels outside of the training range. We train and probe internal representations on two models -- a bare WaveGAN architecture and a ciwGAN extension which forces the Generator to output informative data and results in emergence of linguistically meaningful representations. Interpretation and visualization is performed for three basic acoustic properties of speech: periodic vibration (corresponding to vowels), aperiodic noise vibration (corresponding to fricatives), and silence (corresponding to stops). We also argue that the proposed technique allows acoustic analysis of intermediate layers that parallels the acoustic analysis of human speech data: we can extract F0, intensity, duration, formants, and other acoustic properties from intermediate layers in order to test where and how CNNs encode various types of information. The models are trained on two speech processes with different degrees of complexity: a simple presence of [s] and a computationally complex presence of reduplication (copied material). Observing the causal effect between interpolation and the resulting changes in intermediate layers can reveal how individual variables get transformed into spikes in activation in intermediate layers. Using the proposed technique, we can analyze how linguistically meaningful units in speech get encoded in different convolutional layers.
UniTTS: Residual Learning of Unified Embedding Space for Speech Style Control
Jun 21, 2021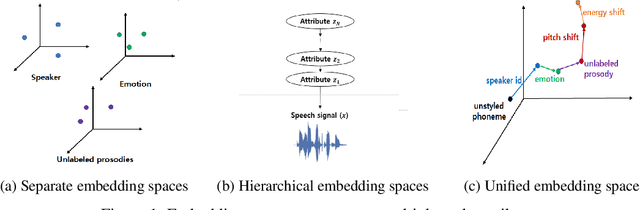
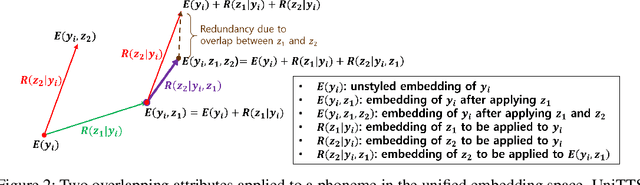

We propose a novel high-fidelity expressive speech synthesis model, UniTTS, that learns and controls overlapping style attributes avoiding interference. UniTTS represents multiple style attributes in a single unified embedding space by the residuals between the phoneme embeddings before and after applying the attributes. The proposed method is especially effective in controlling multiple attributes that are difficult to separate cleanly, such as speaker ID and emotion, because it minimizes redundancy when adding variance in speaker ID and emotion, and additionally, predicts duration, pitch, and energy based on the speaker ID and emotion. In experiments, the visualization results exhibit that the proposed methods learned multiple attributes harmoniously in a manner that can be easily separated again. As well, UniTTS synthesized high-fidelity speech signals controlling multiple style attributes. The synthesized speech samples are presented at https://jackson-kang.github.io/paper_works/UniTTS/demos.
Robustifying automatic speech recognition by extracting slowly varying features
Dec 14, 2021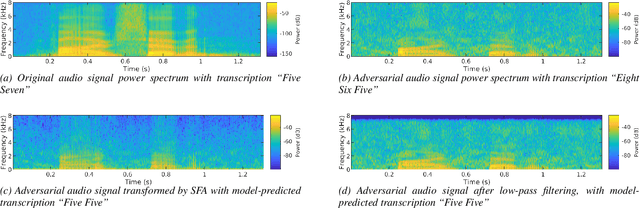
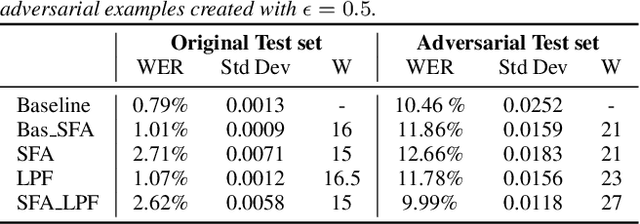
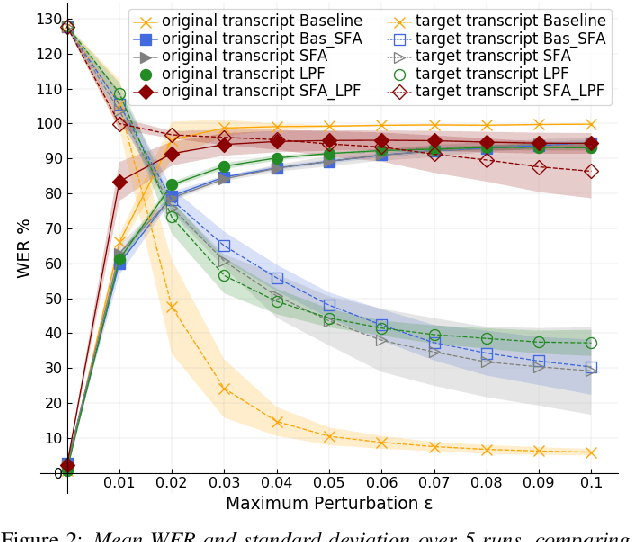
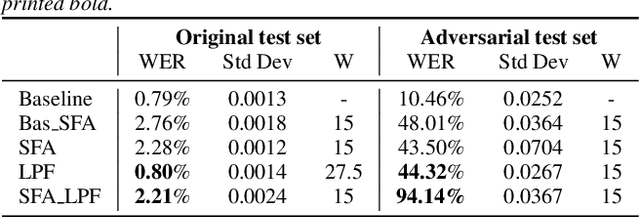
In the past few years, it has been shown that deep learning systems are highly vulnerable under attacks with adversarial examples. Neural-network-based automatic speech recognition (ASR) systems are no exception. Targeted and untargeted attacks can modify an audio input signal in such a way that humans still recognise the same words, while ASR systems are steered to predict a different transcription. In this paper, we propose a defense mechanism against targeted adversarial attacks consisting in removing fast-changing features from the audio signals, either by applying slow feature analysis, a low-pass filter, or both, before feeding the input to the ASR system. We perform an empirical analysis of hybrid ASR models trained on data pre-processed in such a way. While the resulting models perform quite well on benign data, they are significantly more robust against targeted adversarial attacks: Our final, proposed model shows a performance on clean data similar to the baseline model, while being more than four times more robust.
CAB: Comprehensive Attention Benchmarking on Long Sequence Modeling
Oct 19, 2022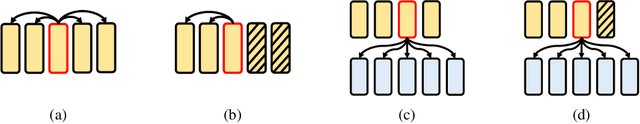
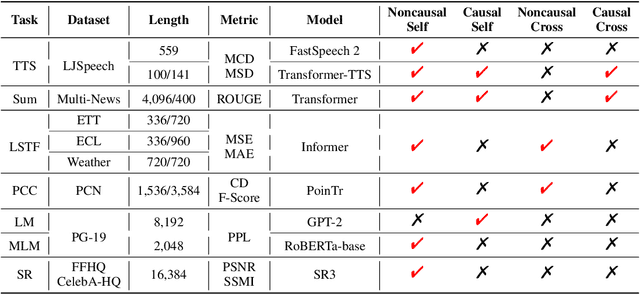
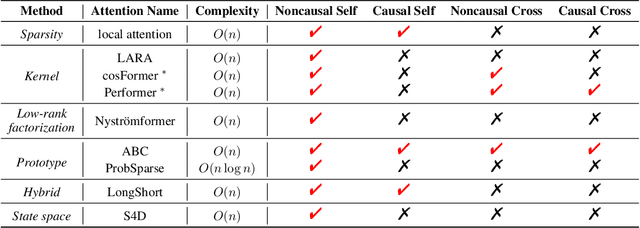
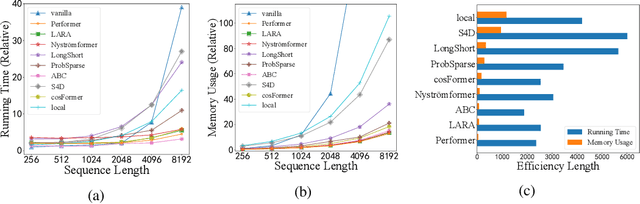
Transformer has achieved remarkable success in language, image, and speech processing. Recently, various efficient attention architectures have been proposed to improve transformer's efficiency while largely preserving its efficacy, especially in modeling long sequences. A widely-used benchmark to test these efficient methods' capability on long-range modeling is Long Range Arena (LRA). However, LRA only focuses on the standard bidirectional (or noncausal) self attention, and completely ignores cross attentions and unidirectional (or causal) attentions, which are equally important to downstream applications. Although designing cross and causal variants of an attention method is straightforward for vanilla attention, it is often challenging for efficient attentions with subquadratic time and memory complexity. In this paper, we propose Comprehensive Attention Benchmark (CAB) under a fine-grained attention taxonomy with four distinguishable attention patterns, namely, noncausal self, causal self, noncausal cross, and causal cross attentions. CAB collects seven real-world tasks from different research areas to evaluate efficient attentions under the four attention patterns. Among these tasks, CAB validates efficient attentions in eight backbone networks to show their generalization across neural architectures. We conduct exhaustive experiments to benchmark the performances of nine widely-used efficient attention architectures designed with different philosophies on CAB. Extensive experimental results also shed light on the fundamental problems of efficient attentions, such as efficiency length against vanilla attention, performance consistency across attention patterns, the benefit of attention mechanisms, and interpolation/extrapolation on long-context language modeling.
Mathematical Vocoder Algorithm : Modified Spectral Inversion for Efficient Neural Speech Synthesis
Jun 06, 2021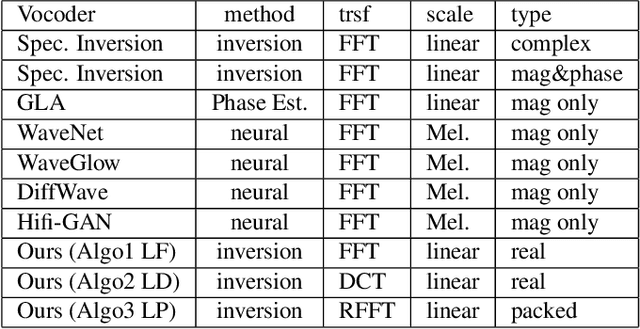
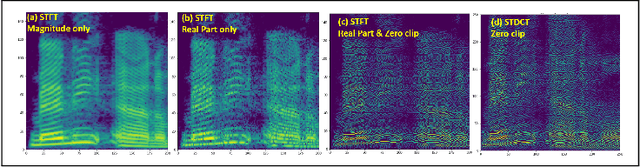
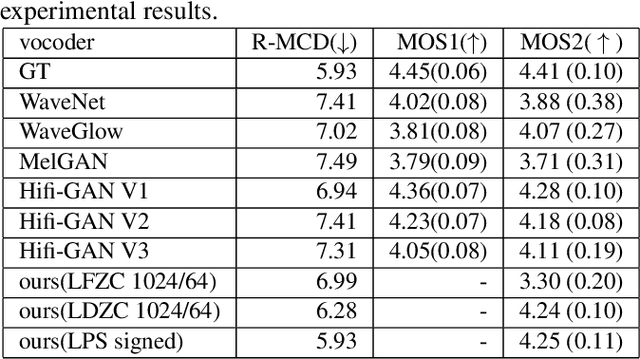
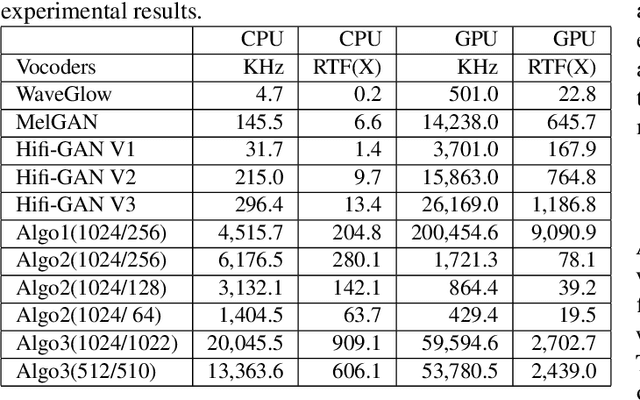
In this work, we propose a new mathematical vocoder algorithm(modified spectral inversion) that generates a waveform from acoustic features without phase estimation. The main benefit of using our proposed method is that it excludes the training stage of the neural vocoder from the end-to-end speech synthesis model. Our implementation can synthesize high fidelity speech at approximately 20 Mhz on CPU and 59.6MHz on GPU. This is 909 and 2,702 times faster compared to real-time. Since the proposed methodology is not a data-driven method, it is applicable to unseen voices and multiple languages without any additional work. The proposed method is expected to adapt for researching on neural network models capable of synthesizing speech at the studio recording level.
AngryBERT: Joint Learning Target and Emotion for Hate Speech Detection
Mar 14, 2021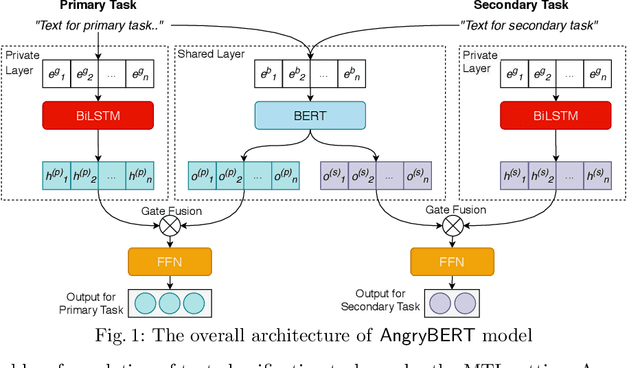
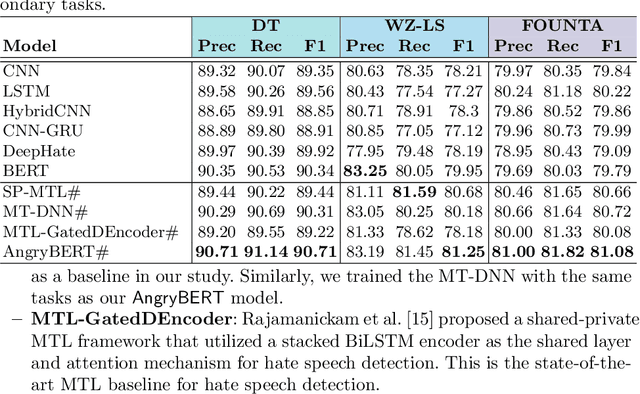
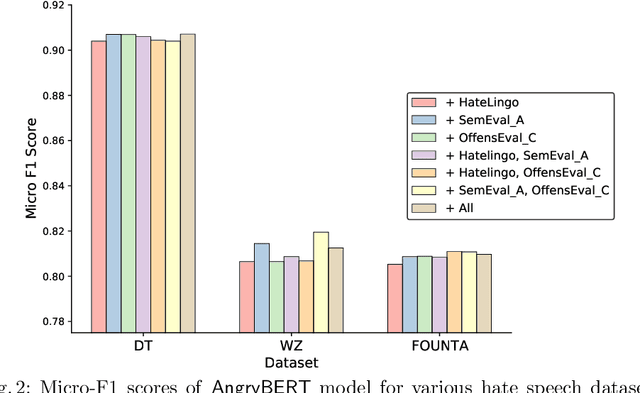

Automated hate speech detection in social media is a challenging task that has recently gained significant traction in the data mining and Natural Language Processing community. However, most of the existing methods adopt a supervised approach that depended heavily on the annotated hate speech datasets, which are imbalanced and often lack training samples for hateful content. This paper addresses the research gaps by proposing a novel multitask learning-based model, AngryBERT, which jointly learns hate speech detection with sentiment classification and target identification as secondary relevant tasks. We conduct extensive experiments to augment three commonly-used hate speech detection datasets. Our experiment results show that AngryBERT outperforms state-of-the-art single-task-learning and multitask learning baselines. We conduct ablation studies and case studies to empirically examine the strengths and characteristics of our AngryBERT model and show that the secondary tasks are able to improve hate speech detection.
Dialectal Speech Recognition and Translation of Swiss German Speech to Standard German Text: Microsoft's Submission to SwissText 2021
Jun 15, 2021

This paper describes the winning approach in the public SwissText 2021 competition on dialect recognition and translation of Swiss German speech to standard German text. Swiss German refers to the multitude of Alemannic dialects spoken in the German-speaking parts of Switzerland. Swiss German differs significantly from standard German in pronunciation, word inventory and grammar. It is mostly incomprehensible to native German speakers. Moreover, it lacks a standardized written script. To solve the challenging task, we propose a hybrid automatic speech recognition system with a lexicon that incorporates translations, a 1st pass language model that deals with Swiss German particularities, a transfer-learned acoustic model and a strong neural language model for 2nd pass rescoring. Our submission reaches 46.04% BLEU on a blind conversational test set and outperforms the second best competitor by a 12% relative margin.
Towards Energy-Efficient, Low-Latency and Accurate Spiking LSTMs
Oct 23, 2022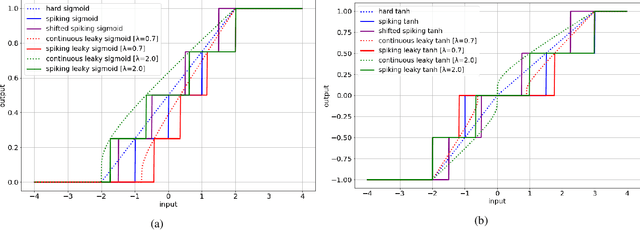
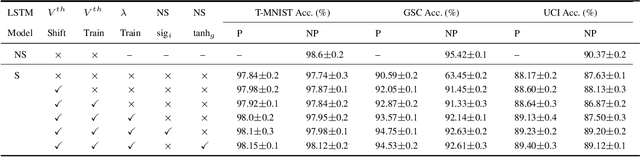

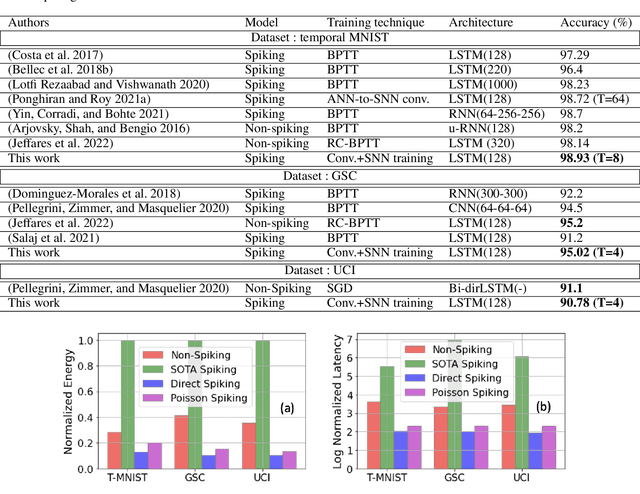
Spiking Neural Networks (SNNs) have emerged as an attractive spatio-temporal computing paradigm for complex vision tasks. However, most existing works yield models that require many time steps and do not leverage the inherent temporal dynamics of spiking neural networks, even for sequential tasks. Motivated by this observation, we propose an \rev{optimized spiking long short-term memory networks (LSTM) training framework that involves a novel ANN-to-SNN conversion framework, followed by SNN training}. In particular, we propose novel activation functions in the source LSTM architecture and judiciously select a subset of them for conversion to integrate-and-fire (IF) activations with optimal bias shifts. Additionally, we derive the leaky-integrate-and-fire (LIF) activation functions converted from their non-spiking LSTM counterparts which justifies the need to jointly optimize the weights, threshold, and leak parameter. We also propose a pipelined parallel processing scheme which hides the SNN time steps, significantly improving system latency, especially for long sequences. The resulting SNNs have high activation sparsity and require only accumulate operations (AC), in contrast to expensive multiply-and-accumulates (MAC) needed for ANNs, except for the input layer when using direct encoding, yielding significant improvements in energy efficiency. We evaluate our framework on sequential learning tasks including temporal MNIST, Google Speech Commands (GSC), and UCI Smartphone datasets on different LSTM architectures. We obtain test accuracy of 94.75% with only 2 time steps with direct encoding on the GSC dataset with 4.1x lower energy than an iso-architecture standard LSTM.
Towards Low-distortion Multi-channel Speech Enhancement: The ESPNet-SE Submission to The L3DAS22 Challenge
Feb 24, 2022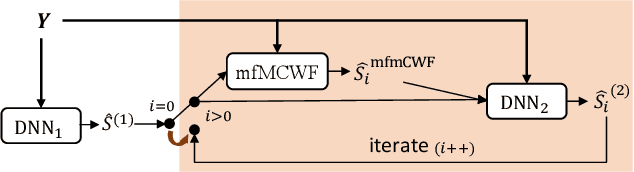
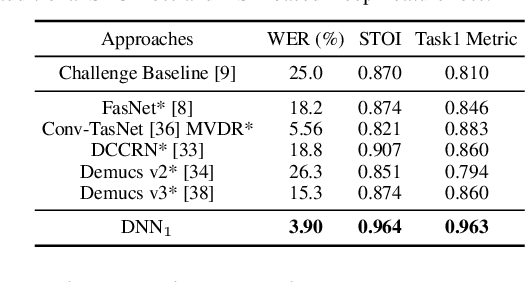
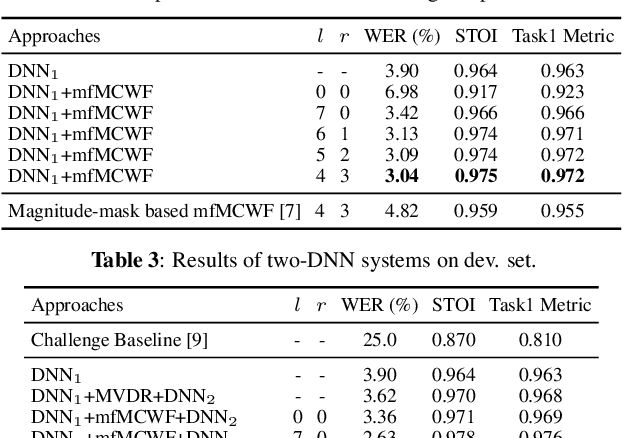
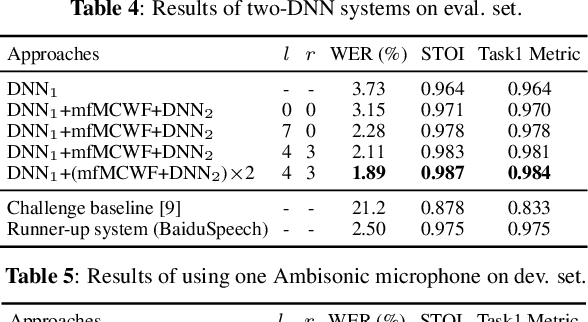
This paper describes our submission to the L3DAS22 Challenge Task 1, which consists of speech enhancement with 3D Ambisonic microphones. The core of our approach combines Deep Neural Network (DNN) driven complex spectral mapping with linear beamformers such as the multi-frame multi-channel Wiener filter. Our proposed system has two DNNs and a linear beamformer in between. Both DNNs are trained to perform complex spectral mapping, using a combination of waveform and magnitude spectrum losses. The estimated signal from the first DNN is used to drive a linear beamformer, and the beamforming result, together with this enhanced signal, are used as extra inputs for the second DNN which refines the estimation. Then, from this new estimated signal, the linear beamformer and second DNN are run iteratively. The proposed method was ranked first in the challenge, achieving, on the evaluation set, a ranking metric of 0.984, versus 0.833 of the challenge baseline.
Subject Envelope based Multitype Reconstruction Algorithm of Speech Samples of Parkinson's Disease
Aug 23, 2021



The risk of Parkinson's disease (PD) is extremely serious, and PD speech recognition is an effective method of diagnosis nowadays. However, due to the influence of the disease stage, corpus, and other factors on data collection, the ability of every samples within one subject to reflect the status of PD vary. No samples are useless totally, and not samples are 100% perfect. This characteristic means that it is not suitable just to remove some samples or keep some samples. It is necessary to consider the sample transformation for obtaining high quality new samples. Unfortunately, existing PD speech recognition methods focus mainly on feature learning and classifier design rather than sample learning, and few methods consider the sample transformation. To solve the problem above, a PD speech sample transformation algorithm based on multitype reconstruction operators is proposed in this paper. The algorithm is divided into four major steps. Three types of reconstruction operators are designed in the algorithm: types A, B and C. Concerning the type A operator, the original dataset is directly reconstructed by designing a linear transformation to obtain the first dataset. The type B operator is designed for clustering and linear transformation of the dataset to obtain the second new dataset. The third operator, namely, the type C operator, reconstructs the dataset by clustering and convolution to obtain the third dataset. Finally, the base classifier is trained based on the three new datasets, and then the classification results are fused by decision weighting. In the experimental section, two representative PD speech datasets are used for verification. The results show that the proposed algorithm is effective. Compared with other algorithms, the proposed algorithm achieves apparent improvements in terms of classification accuracy.