 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Real-Time Packet Loss Concealment With Mixed Generative and Predictive Model
May 11, 2022
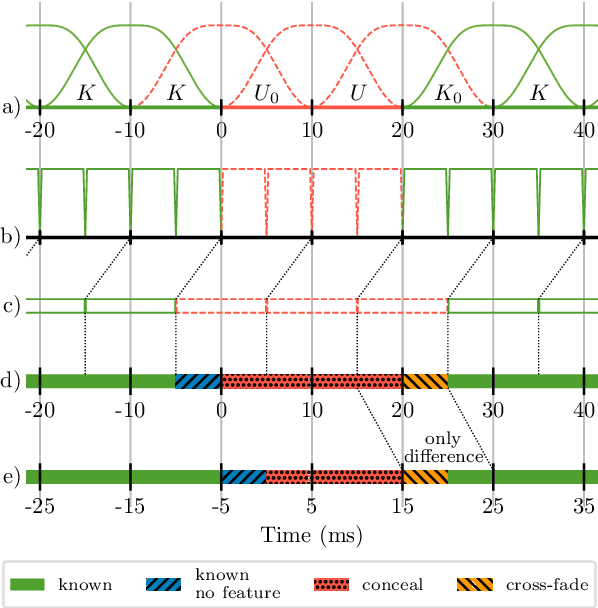

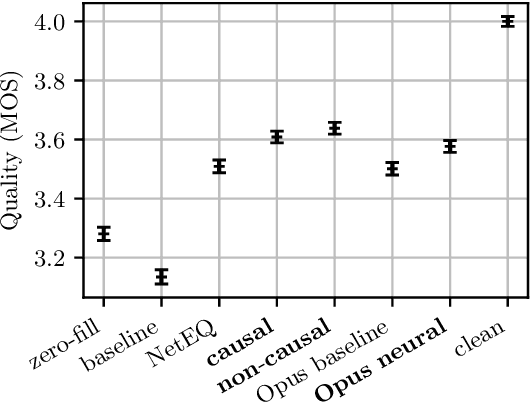
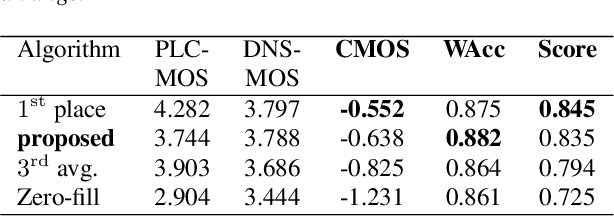
As deep speech enhancement algorithms have recently demonstrated capabilities greatly surpassing their traditional counterparts for suppressing noise, reverberation and echo, attention is turning to the problem of packet loss concealment (PLC). PLC is a challenging task because it not only involves real-time speech synthesis, but also frequent transitions between the received audio and the synthesized concealment. We propose a hybrid neural PLC architecture where the missing speech is synthesized using a generative model conditioned using a predictive model. The resulting algorithm achieves natural concealment that surpasses the quality of existing conventional PLC algorithms and ranked second in the Interspeech 2022 PLC Challenge. We show that our solution not only works for uncompressed audio, but is also applicable to a modern speech codec.
DPCRN: Dual-Path Convolution Recurrent Network for Single Channel Speech Enhancement
Jul 12, 2021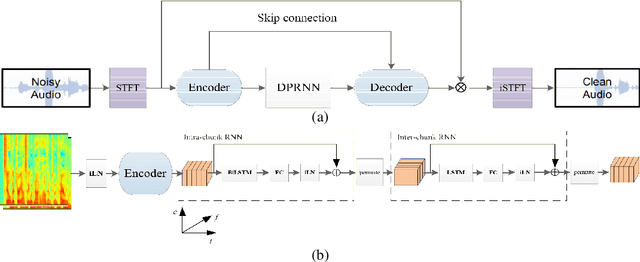
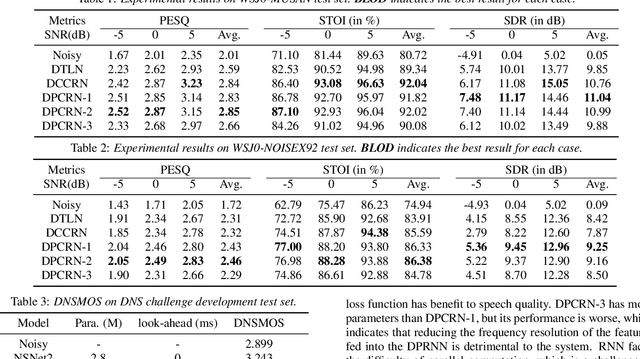
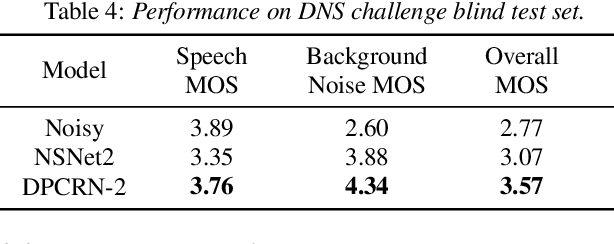
The dual-path RNN (DPRNN) was proposed to more effectively model extremely long sequences for speech separation in the time domain. By splitting long sequences to smaller chunks and applying intra-chunk and inter-chunk RNNs, the DPRNN reached promising performance in speech separation with a limited model size. In this paper, we combine the DPRNN module with Convolution Recurrent Network (CRN) and design a model called Dual-Path Convolution Recurrent Network (DPCRN) for speech enhancement in the time-frequency domain. We replace the RNNs in the CRN with DPRNN modules, where the intra-chunk RNNs are used to model the spectrum pattern in a single frame and the inter-chunk RNNs are used to model the dependence between consecutive frames. With only 0.8M parameters, the submitted DPCRN model achieves an overall mean opinion score (MOS) of 3.57 in the wide band scenario track of the Interspeech 2021 Deep Noise Suppression (DNS) challenge. Evaluations on some other test sets also show the efficacy of our model.
Speaker disentanglement in video-to-speech conversion
May 20, 2021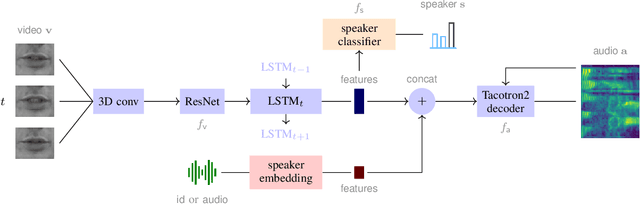
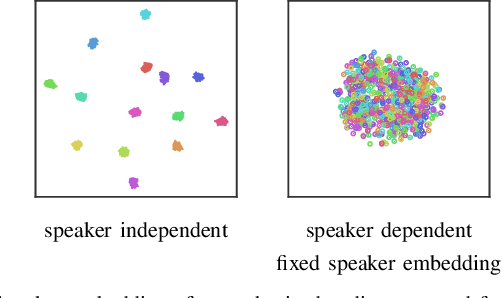
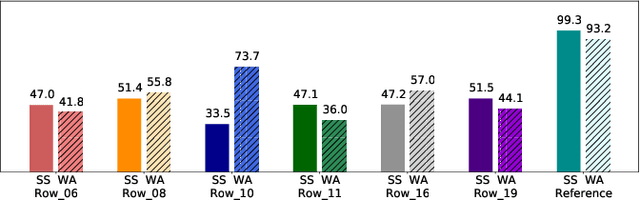
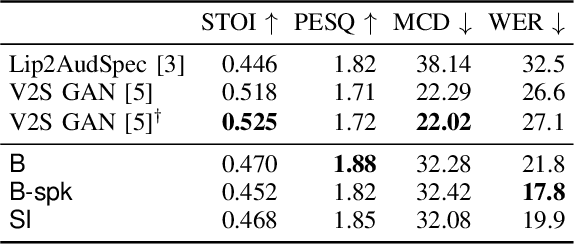
The task of video-to-speech aims to translate silent video of lip movement to its corresponding audio signal. Previous approaches to this task are generally limited to the case of a single speaker, but a method that accounts for multiple speakers is desirable as it allows to i) leverage datasets with multiple speakers or few samples per speaker; and ii) control speaker identity at inference time. In this paper, we introduce a new video-to-speech architecture and explore ways of extending it to the multi-speaker scenario: we augment the network with an additional speaker-related input, through which we feed either a discrete identity or a speaker embedding. Interestingly, we observe that the visual encoder of the network is capable of learning the speaker identity from the lip region of the face alone. To better disentangle the two inputs -- linguistic content and speaker identity -- we add adversarial losses that dispel the identity from the video embeddings. To the best of our knowledge, the proposed method is the first to provide important functionalities such as i) control of the target voice and ii) speech synthesis for unseen identities over the state-of-the-art, while still maintaining the intelligibility of the spoken output.
Word Order Does Not Matter For Speech Recognition
Oct 18, 2021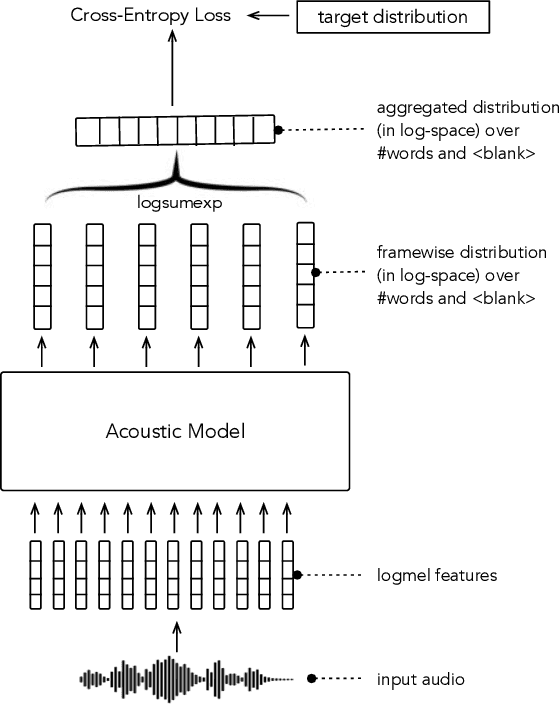
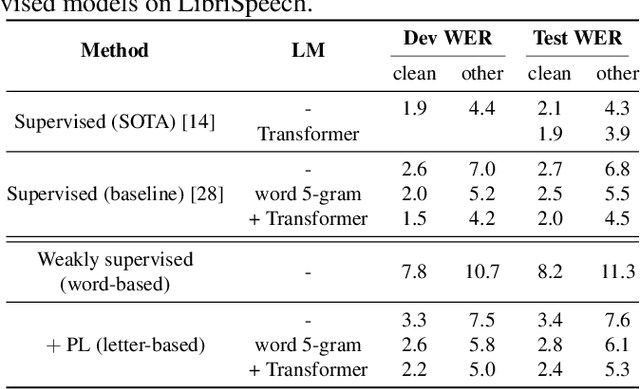
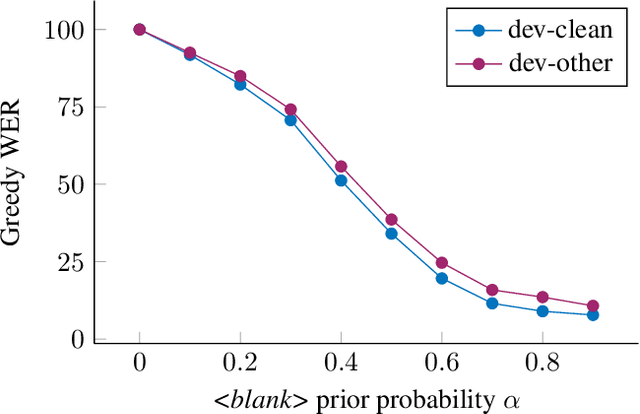

In this paper, we study training of automatic speech recognition system in a weakly supervised setting where the order of words in transcript labels of the audio training data is not known. We train a word-level acoustic model which aggregates the distribution of all output frames using LogSumExp operation and uses a cross-entropy loss to match with the ground-truth words distribution. Using the pseudo-labels generated from this model on the training set, we then train a letter-based acoustic model using Connectionist Temporal Classification loss. Our system achieves 2.3%/4.6% on test-clean/test-other subsets of LibriSpeech, which closely matches with the supervised baseline's performance.
A Study of Low-Resource Speech Commands Recognition based on Adversarial Reprogramming
Oct 08, 2021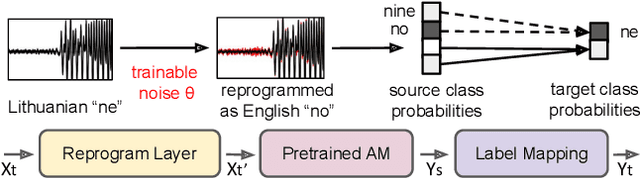
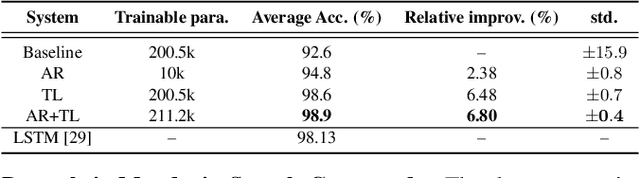
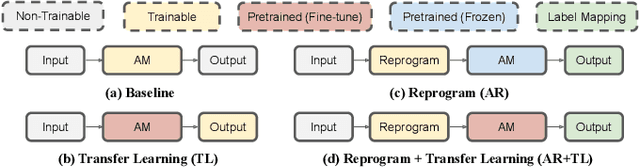
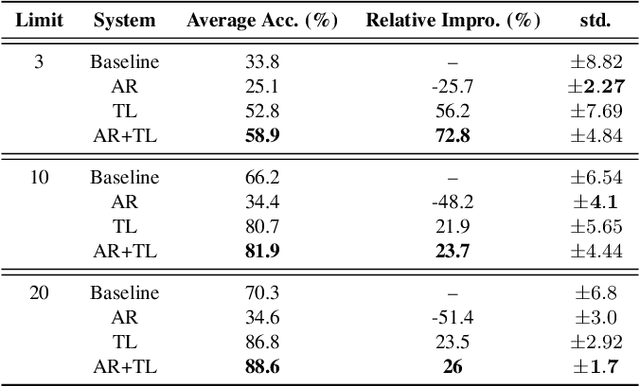
In this study, we propose a novel adversarial reprogramming (AR) approach for low-resource spoken command recognition (SCR), and build an AR-SCR system. The AR procedure aims to modify the acoustic signals (from the target domain) to repurpose a pretrained SCR model (from the source domain). To solve the label mismatches between source and target domains, and further improve the stability of AR, we propose a novel similarity-based label mapping technique to align classes. In addition, the transfer learning (TL) technique is combined with the original AR process to improve the model adaptation capability. We evaluate the proposed AR-SCR system on three low-resource SCR datasets, including Arabic, Lithuanian, and dysarthric Mandarin speech. Experimental results show that with a pretrained AM trained on a large-scale English dataset, the proposed AR-SCR system outperforms the current state-of-the-art results on Arabic and Lithuanian speech commands datasets, with only a limited amount of training data.
Neural Speech Synthesis for Estonian
Oct 06, 2020This technical report describes the results of a collaboration between the NLP research group at the University of Tartu and the Institute of Estonian Language on improving neural speech synthesis for Estonian. The report (written in Estonian) describes the project results, the summary of which is: (1) Speech synthesis data from 6 speakers for a total of 92.4 hours is collected and openly released (CC-BY-4.0). Data available at https://konekorpus.tartunlp.ai and https://www.eki.ee/litsents/. (2) software and models for neural speech synthesis is released open-source (MIT license). Available at https://koodivaramu.eesti.ee/tartunlp/text-to-speech . (3) We ran evaluations of the new models and compared them to other existing solutions (HMM-based HTS models from EKI, http://www.eki.ee/heli/, and Google's speech synthesis for Estonian, accessed via https://translate.google.com). Evaluation includes voice acceptability MOS scores for sentence-level and longer excerpts, detailed error analysis and evaluation of the pre-processing module.
Sign-to-Speech Model for Sign Language Understanding: A Case Study of Nigerian Sign Language
Nov 02, 2021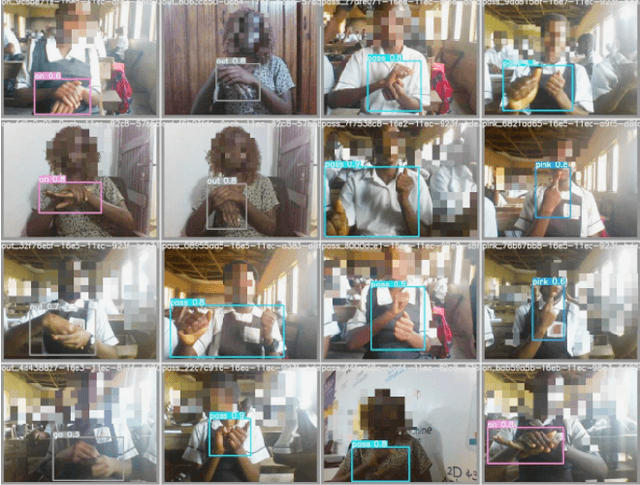
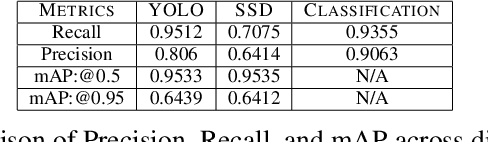
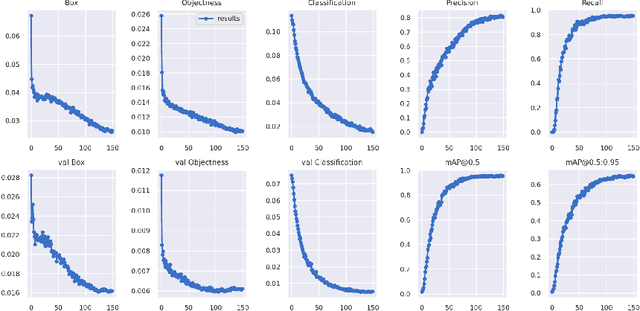
Through this paper, we seek to reduce the communication barrier between the hearing-impaired community and the larger society who are usually not familiar with sign language in the sub-Saharan region of Africa with the largest occurrences of hearing disability cases, while using Nigeria as a case study. The dataset is a pioneer dataset for the Nigerian Sign Language and was created in collaboration with relevant stakeholders. We pre-processed the data in readiness for two different object detection models and a classification model and employed diverse evaluation metrics to gauge model performance on sign-language to text conversion tasks. Finally, we convert the predicted sign texts to speech and deploy the best performing model in a lightweight application that works in real-time and achieves impressive results converting sign words/phrases to text and subsequently, into speech.
Cross-speaker style transfer for text-to-speech using data augmentation
Feb 10, 2022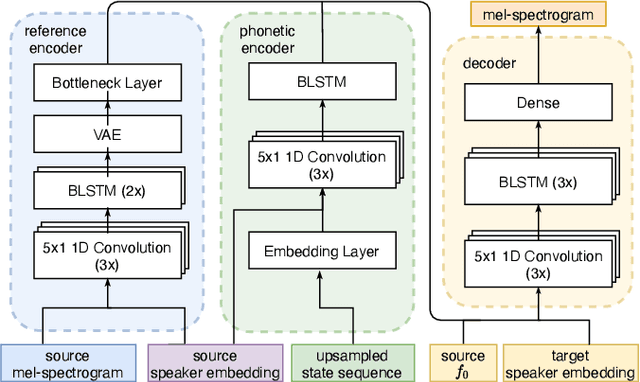
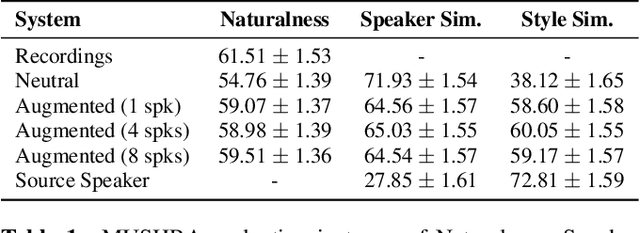
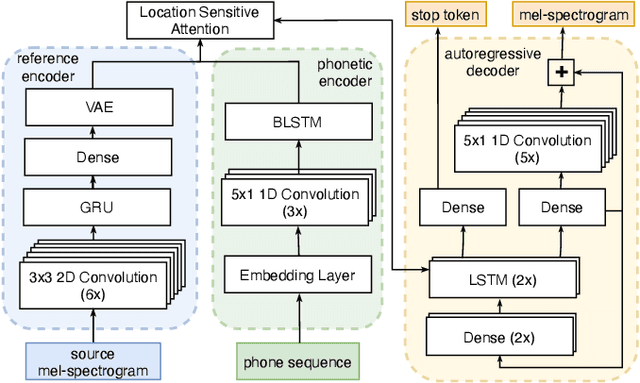
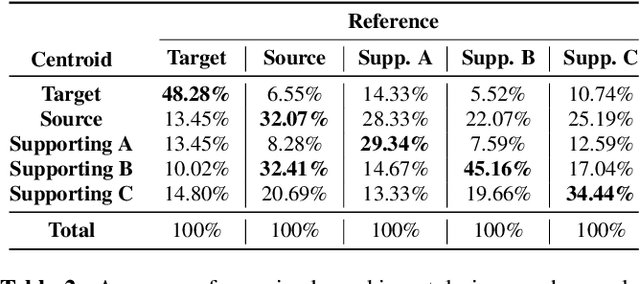
We address the problem of cross-speaker style transfer for text-to-speech (TTS) using data augmentation via voice conversion. We assume to have a corpus of neutral non-expressive data from a target speaker and supporting conversational expressive data from different speakers. Our goal is to build a TTS system that is expressive, while retaining the target speaker's identity. The proposed approach relies on voice conversion to first generate high-quality data from the set of supporting expressive speakers. The voice converted data is then pooled with natural data from the target speaker and used to train a single-speaker multi-style TTS system. We provide evidence that this approach is efficient, flexible, and scalable. The method is evaluated using one or more supporting speakers, as well as a variable amount of supporting data. We further provide evidence that this approach allows some controllability of speaking style, when using multiple supporting speakers. We conclude by scaling our proposed technology to a set of 14 speakers across 7 languages. Results indicate that our technology consistently improves synthetic samples in terms of style similarity, while retaining the target speaker's identity.
Echo State Speech Recognition
Feb 18, 2021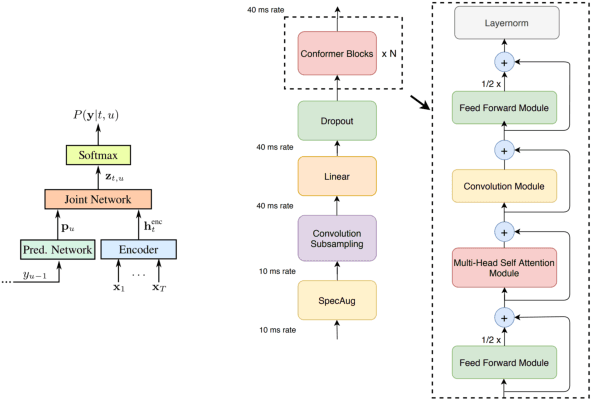
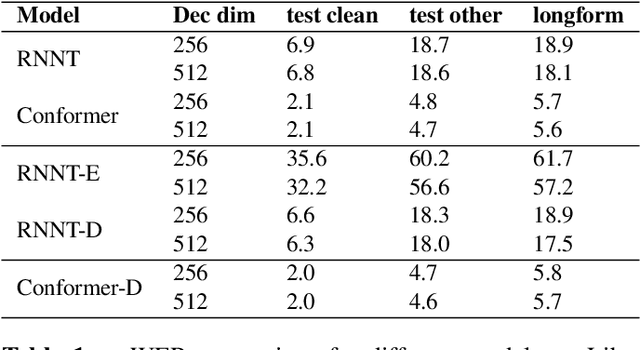

We propose automatic speech recognition (ASR) models inspired by echo state network (ESN), in which a subset of recurrent neural networks (RNN) layers in the models are randomly initialized and untrained. Our study focuses on RNN-T and Conformer models, and we show that model quality does not drop even when the decoder is fully randomized. Furthermore, such models can be trained more efficiently as the decoders do not require to be updated. By contrast, randomizing encoders hurts model quality, indicating that optimizing encoders and learn proper representations for acoustic inputs are more vital for speech recognition. Overall, we challenge the common practice of training ASR models for all components, and demonstrate that ESN-based models can perform equally well but enable more efficient training and storage than fully-trainable counterparts.
FRA-RIR: Fast Random Approximation of the Image-source Method
Aug 08, 2022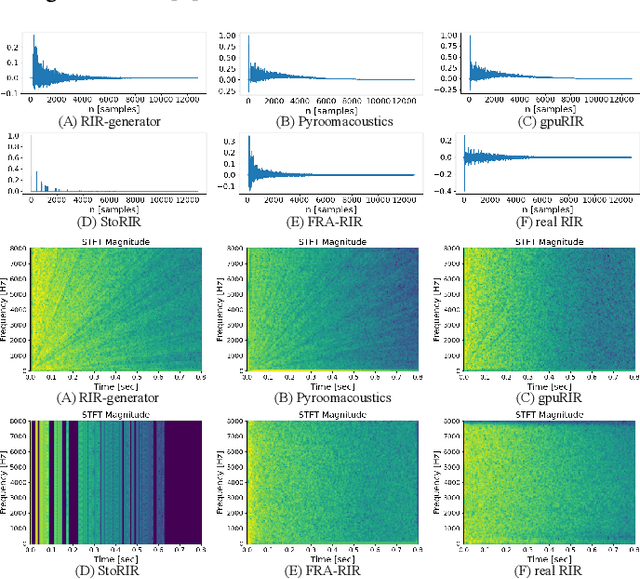
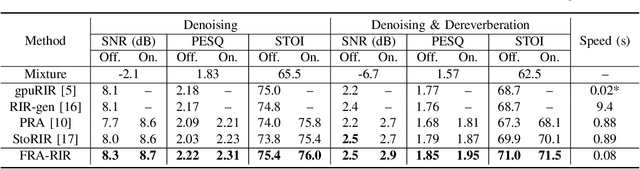
The training of modern speech processing systems often requires a large amount of simulated room impulse response (RIR) data in order to allow the systems to generalize well in real-world, reverberant environments. However, simulating realistic RIR data typically requires accurate physical modeling, and the acceleration of such simulation process typically requires certain computational platforms such as a graphics processing unit (GPU). In this paper, we propose FRA-RIR, a fast random approximation method of the widely-used image-source method (ISM), to efficiently generate realistic RIR data without specific computational devices. FRA-RIR replaces the physical simulation in the standard ISM by a series of random approximations, which significantly speeds up the simulation process and enables its application in on-the-fly data generation pipelines. Experiments show that FRA-RIR can not only be significantly faster than other existing ISM-based RIR simulation tools on standard computational platforms, but also improves the performance of speech denoising systems evaluated on real-world RIR when trained with simulated RIR. A Python implementation of FRA-RIR is available online\footnote{\url{https://github.com/yluo42/FRA-RIR}}.