 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Mathematical Vocoder Algorithm : Modified Spectral Inversion for Efficient Neural Speech Synthesis
Jun 16, 2021
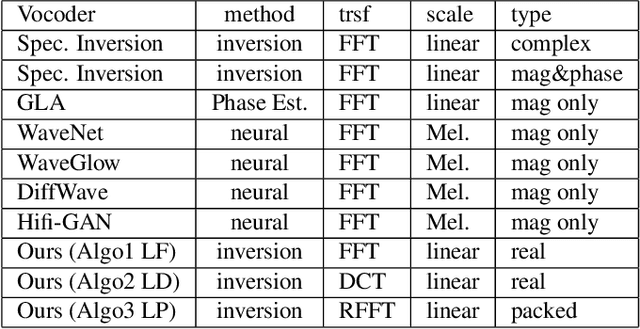
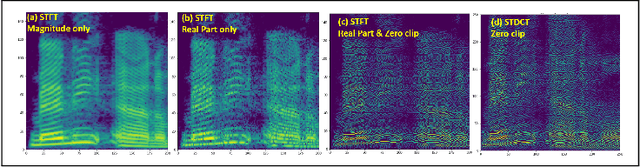
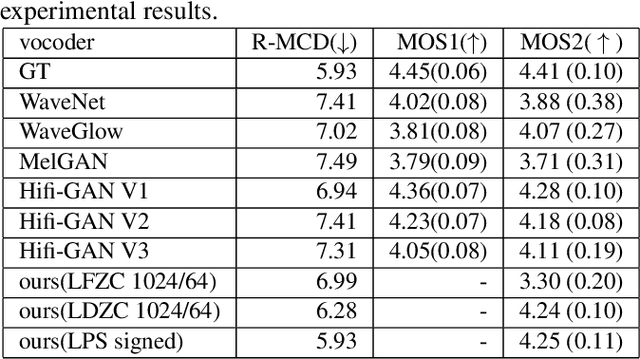
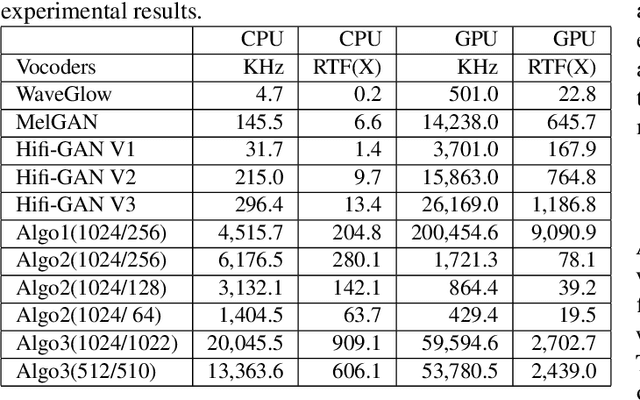
In this work, we propose a new mathematical vocoder algorithm(modified spectral inversion) that generates a waveform from acoustic features without phase estimation. The main benefit of using our proposed method is that it excludes the training stage of the neural vocoder from the end-to-end speech synthesis model. Our implementation can synthesize high fidelity speech at approximately 20 Mhz on CPU and 59.6MHz on GPU. This is 909 and 2,702 times faster compared to real-time. Since the proposed methodology is not a data-driven method, it is applicable to unseen voices and multiple languages without any additional work. The proposed method is expected to adapt for researching on neural network models capable of synthesizing speech at the studio recording level.
End-to-End Video-To-Speech Synthesis using Generative Adversarial Networks
Apr 27, 2021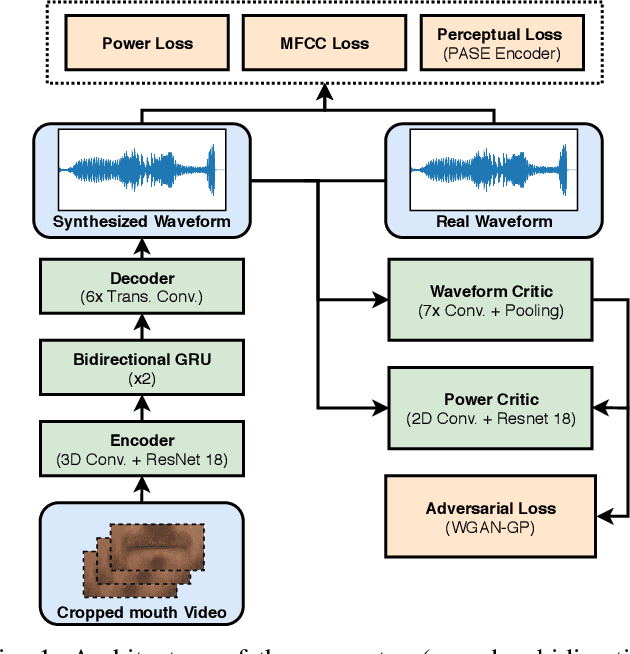
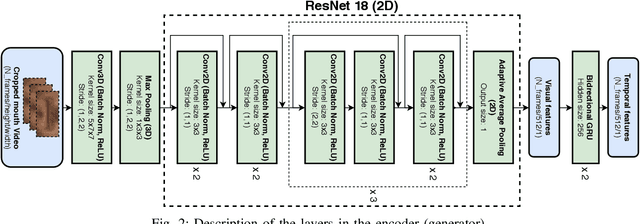
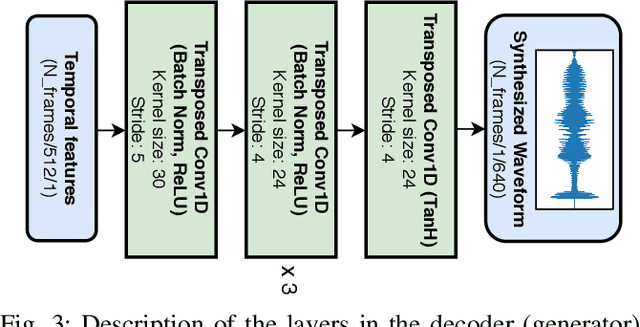
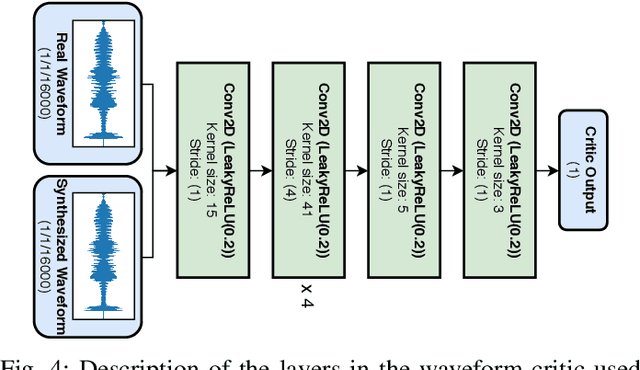
Video-to-speech is the process of reconstructing the audio speech from a video of a spoken utterance. Previous approaches to this task have relied on a two-step process where an intermediate representation is inferred from the video, and is then decoded into waveform audio using a vocoder or a waveform reconstruction algorithm. In this work, we propose a new end-to-end video-to-speech model based on Generative Adversarial Networks (GANs) which translates spoken video to waveform end-to-end without using any intermediate representation or separate waveform synthesis algorithm. Our model consists of an encoder-decoder architecture that receives raw video as input and generates speech, which is then fed to a waveform critic and a power critic. The use of an adversarial loss based on these two critics enables the direct synthesis of raw audio waveform and ensures its realism. In addition, the use of our three comparative losses helps establish direct correspondence between the generated audio and the input video. We show that this model is able to reconstruct speech with remarkable realism for constrained datasets such as GRID, and that it is the first end-to-end model to produce intelligible speech for LRW (Lip Reading in the Wild), featuring hundreds of speakers recorded entirely `in the wild'. We evaluate the generated samples in two different scenarios -- seen and unseen speakers -- using four objective metrics which measure the quality and intelligibility of artificial speech. We demonstrate that the proposed approach outperforms all previous works in most metrics on GRID and LRW.
Codes, Patterns and Shapes of Contemporary Online Antisemitism and Conspiracy Narratives -- an Annotation Guide and Labeled German-Language Dataset in the Context of COVID-19
Oct 13, 2022
Over the course of the COVID-19 pandemic, existing conspiracy theories were refreshed and new ones were created, often interwoven with antisemitic narratives, stereotypes and codes. The sheer volume of antisemitic and conspiracy theory content on the Internet makes data-driven algorithmic approaches essential for anti-discrimination organizations and researchers alike. However, the manifestation and dissemination of these two interrelated phenomena is still quite under-researched in scholarly empirical research of large text corpora. Algorithmic approaches for the detection and classification of specific contents usually require labeled datasets, annotated based on conceptually sound guidelines. While there is a growing number of datasets for the more general phenomenon of hate speech, the development of corpora and annotation guidelines for antisemitic and conspiracy content is still in its infancy, especially for languages other than English. We contribute to closing this gap by developing an annotation guide for antisemitic and conspiracy theory online content in the context of the COVID-19 pandemic. We provide working definitions, including specific forms of antisemitism such as encoded and post-Holocaust antisemitism. We use these to annotate a German-language dataset consisting of ~3,700 Telegram messages sent between 03/2020 and 12/2021.
An Investigation of End-to-End Models for Robust Speech Recognition
Feb 11, 2021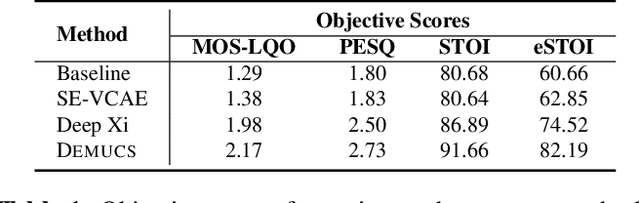
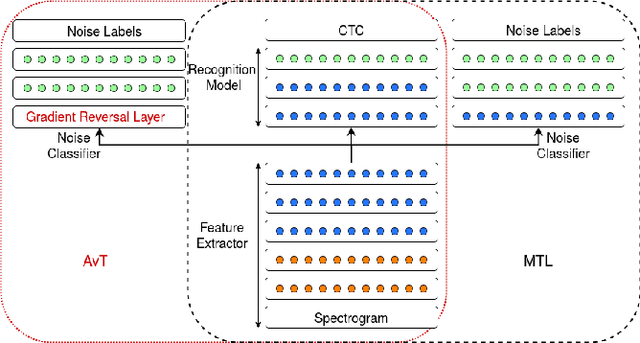
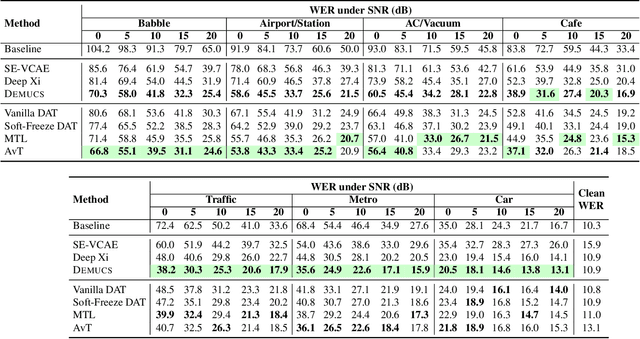
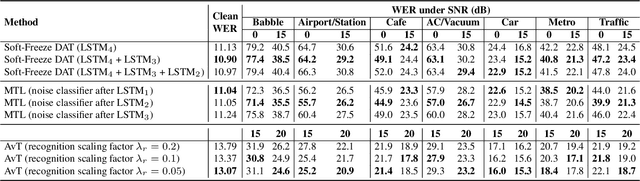
End-to-end models for robust automatic speech recognition (ASR) have not been sufficiently well-explored in prior work. With end-to-end models, one could choose to preprocess the input speech using speech enhancement techniques and train the model using enhanced speech. Another alternative is to pass the noisy speech as input and modify the model architecture to adapt to noisy speech. A systematic comparison of these two approaches for end-to-end robust ASR has not been attempted before. We address this gap and present a detailed comparison of speech enhancement-based techniques and three different model-based adaptation techniques covering data augmentation, multi-task learning, and adversarial learning for robust ASR. While adversarial learning is the best-performing technique on certain noise types, it comes at the cost of degrading clean speech WER. On other relatively stationary noise types, a new speech enhancement technique outperformed all the model-based adaptation techniques. This suggests that knowledge of the underlying noise type can meaningfully inform the choice of adaptation technique.
ASR4REAL: An extended benchmark for speech models
Oct 16, 2021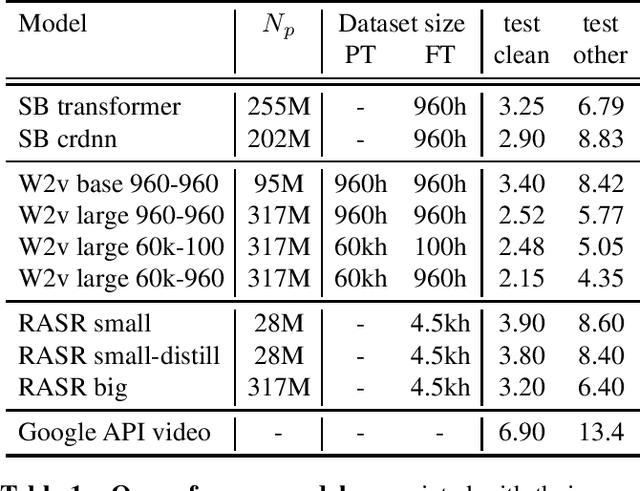
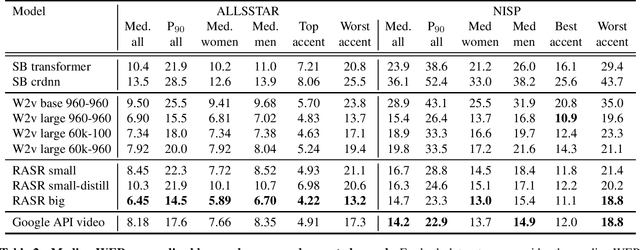
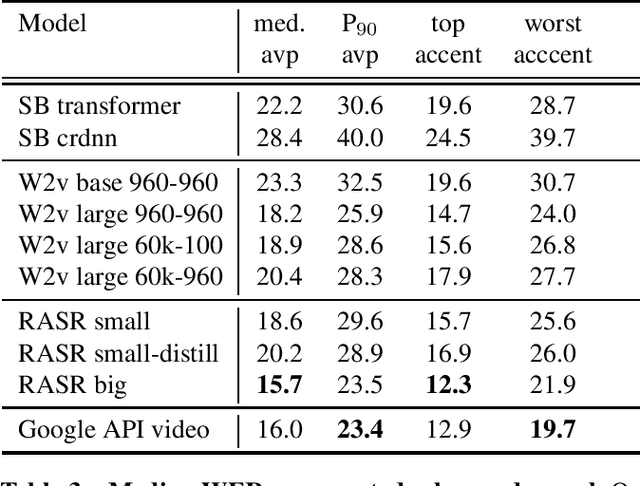
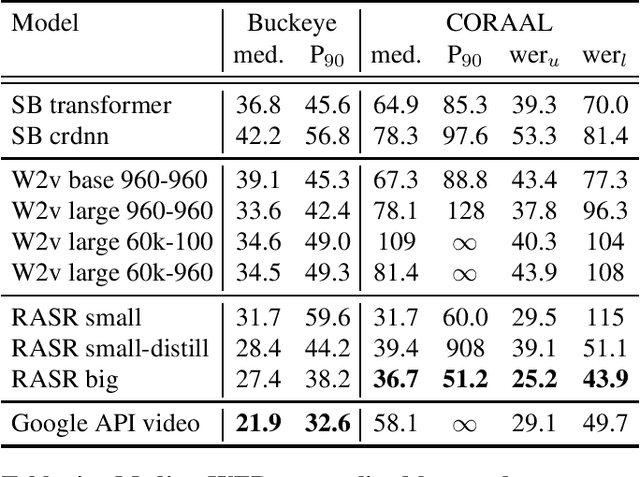
Popular ASR benchmarks such as Librispeech and Switchboard are limited in the diversity of settings and speakers they represent. We introduce a set of benchmarks matching real-life conditions, aimed at spotting possible biases and weaknesses in models. We have found out that even though recent models do not seem to exhibit a gender bias, they usually show important performance discrepancies by accent, and even more important ones depending on the socio-economic status of the speakers. Finally, all tested models show a strong performance drop when tested on conversational speech, and in this precise context even a language model trained on a dataset as big as Common Crawl does not seem to have significant positive effect which reiterates the importance of developing conversational language models
The Role of Phonetic Units in Speech Emotion Recognition
Aug 02, 2021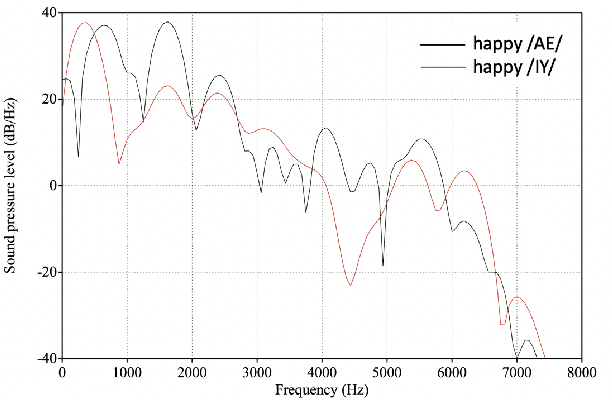
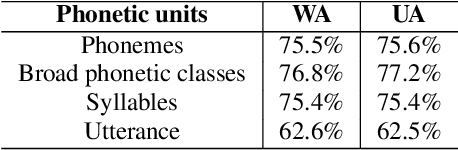
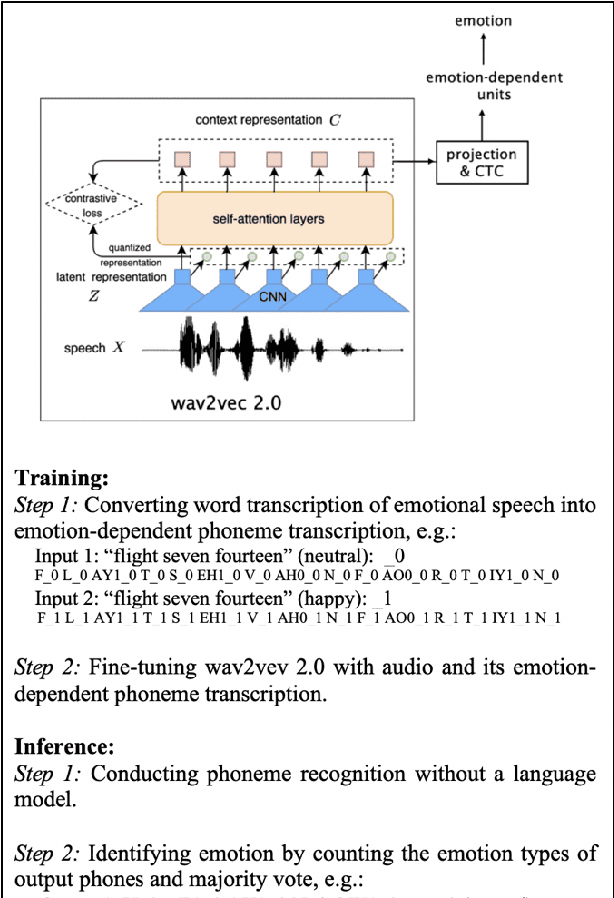
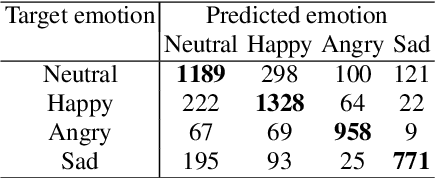
We propose a method for emotion recognition through emotiondependent speech recognition using Wav2vec 2.0. Our method achieved a significant improvement over most previously reported results on IEMOCAP, a benchmark emotion dataset. Different types of phonetic units are employed and compared in terms of accuracy and robustness of emotion recognition within and across datasets and languages. Models of phonemes, broad phonetic classes, and syllables all significantly outperform the utterance model, demonstrating that phonetic units are helpful and should be incorporated in speech emotion recognition. The best performance is from using broad phonetic classes. Further research is needed to investigate the optimal set of broad phonetic classes for the task of emotion recognition. Finally, we found that Wav2vec 2.0 can be fine-tuned to recognize coarser-grained or larger phonetic units than phonemes, such as broad phonetic classes and syllables.
Multimodal generation of upper-facial and head gestures with a Transformer Network using speech and text
Oct 09, 2021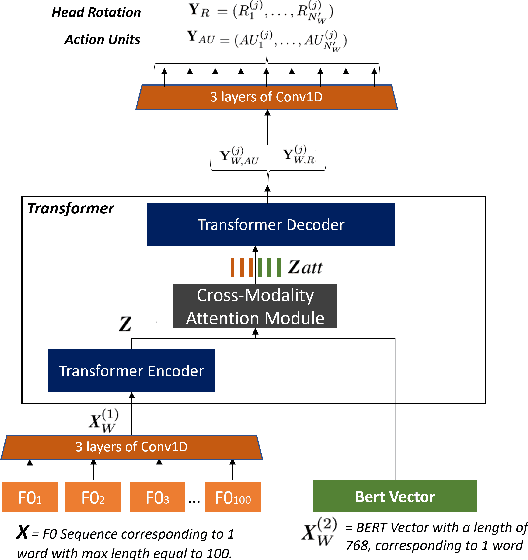
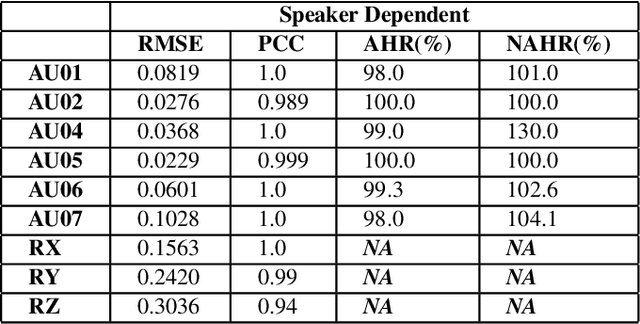
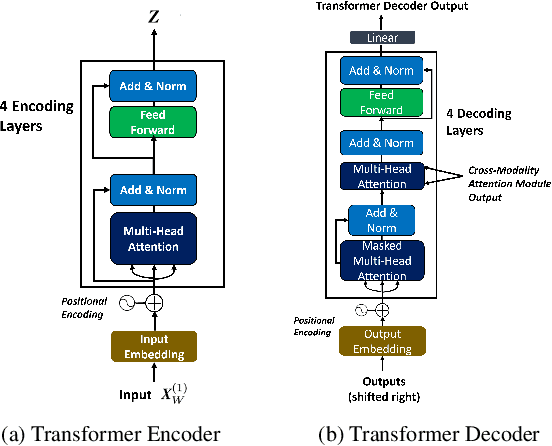
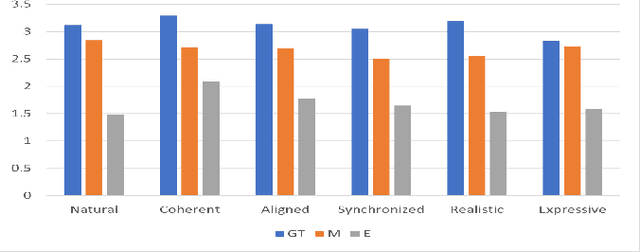
We propose a semantically-aware speech driven method to generate expressive and natural upper-facial and head motion for Embodied Conversational Agents (ECA). In this work, we tackle two key challenges: produce natural and continuous head motion and upper-facial gestures. We propose a model that generates gestures based on multimodal input features: the first modality is text, and the second one is speech prosody. Our model makes use of Transformers and Convolutions to map the multimodal features that correspond to an utterance to continuous eyebrows and head gestures. We conduct subjective and objective evaluations to validate our approach.
AutoLV: Automatic Lecture Video Generator
Sep 19, 2022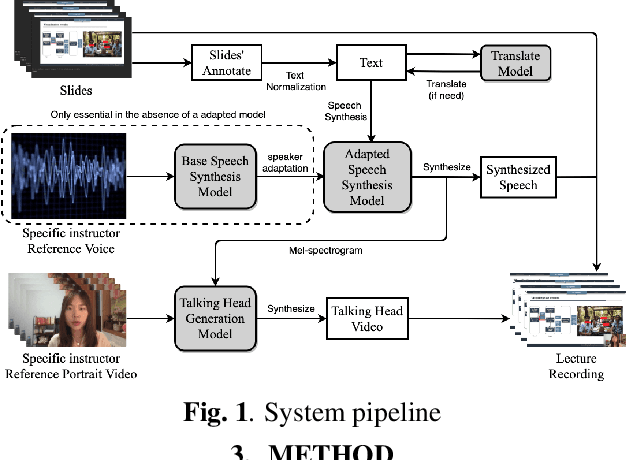
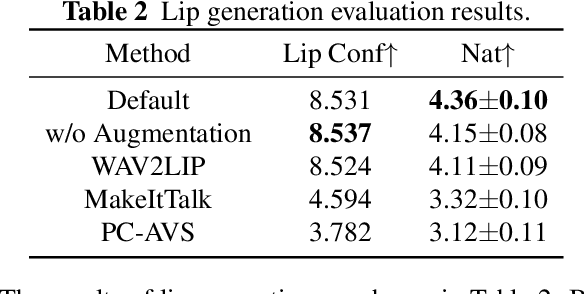

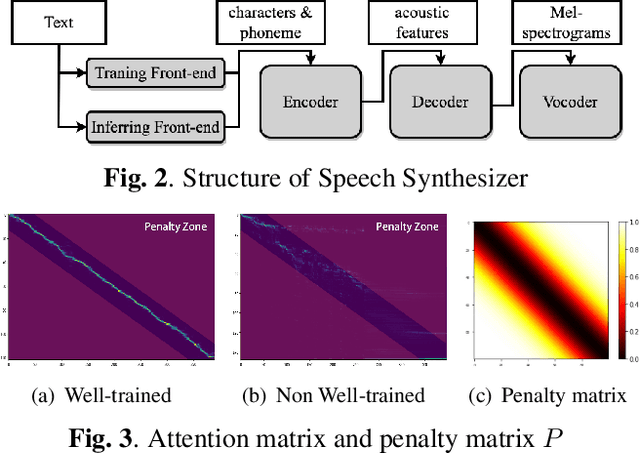
We propose an end-to-end lecture video generation system that can generate realistic and complete lecture videos directly from annotated slides, instructor's reference voice and instructor's reference portrait video. Our system is primarily composed of a speech synthesis module with few-shot speaker adaptation and an adversarial learning-based talking-head generation module. It is capable of not only reducing instructors' workload but also changing the language and accent which can help the students follow the lecture more easily and enable a wider dissemination of lecture contents. Our experimental results show that the proposed model outperforms other current approaches in terms of authenticity, naturalness and accuracy. Here is a video demonstration of how our system works, and the outcomes of the evaluation and comparison: https://youtu.be/cY6TYkI0cog.
PARP: Prune, Adjust and Re-Prune for Self-Supervised Speech Recognition
Jun 10, 2021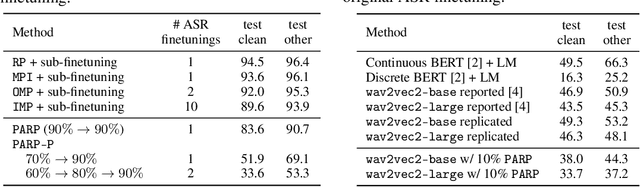
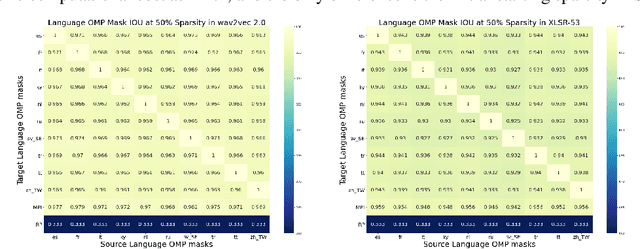
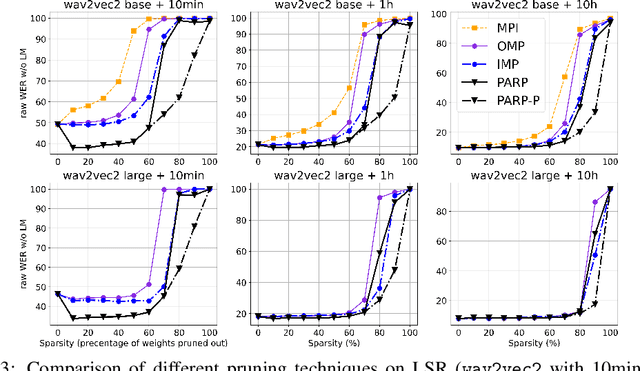
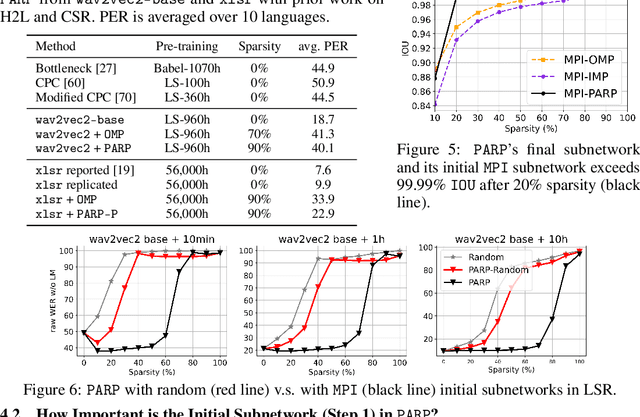
Recent work on speech self-supervised learning (speech SSL) demonstrated the benefits of scale in learning rich and transferable representations for Automatic Speech Recognition (ASR) with limited parallel data. It is then natural to investigate the existence of sparse and transferrable subnetworks in pre-trained speech SSL models that can achieve even better low-resource ASR performance. However, directly applying widely adopted pruning methods such as the Lottery Ticket Hypothesis (LTH) is suboptimal in the computational cost needed. Moreover, contrary to what LTH predicts, the discovered subnetworks yield minimal performance gain compared to the original dense network. In this work, we propose Prune-Adjust- Re-Prune (PARP), which discovers and finetunes subnetworks for much better ASR performance, while only requiring a single downstream finetuning run. PARP is inspired by our surprising observation that subnetworks pruned for pre-training tasks only needed to be slightly adjusted to achieve a sizeable performance boost in downstream ASR tasks. Extensive experiments on low-resource English and multi-lingual ASR show (1) sparse subnetworks exist in pre-trained speech SSL, and (2) the computational advantage and performance gain of PARP over baseline pruning methods. On the 10min Librispeech split without LM decoding, PARP discovers subnetworks from wav2vec 2.0 with an absolute 10.9%/12.6% WER decrease compared to the full model. We demonstrate PARP mitigates performance degradation in cross-lingual mask transfer, and investigate the possibility of discovering a single subnetwork for 10 spoken languages in one run.
Convolutional Learning on Multigraphs
Sep 23, 2022
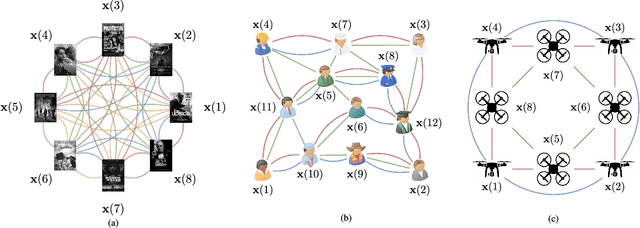

Graph convolutional learning has led to many exciting discoveries in diverse areas. However, in some applications, traditional graphs are insufficient to capture the structure and intricacies of the data. In such scenarios, multigraphs arise naturally as discrete structures in which complex dynamics can be embedded. In this paper, we develop convolutional information processing on multigraphs and introduce convolutional multigraph neural networks (MGNNs). To capture the complex dynamics of information diffusion within and across each of the multigraph's classes of edges, we formalize a convolutional signal processing model, defining the notions of signals, filtering, and frequency representations on multigraphs. Leveraging this model, we develop a multigraph learning architecture, including a sampling procedure to reduce computational complexity. The introduced architecture is applied towards optimal wireless resource allocation and a hate speech localization task, offering improved performance over traditional graph neural networks.