 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Personalized Speech Enhancement through Self-Supervised Data Augmentation and Purification
Apr 05, 2021
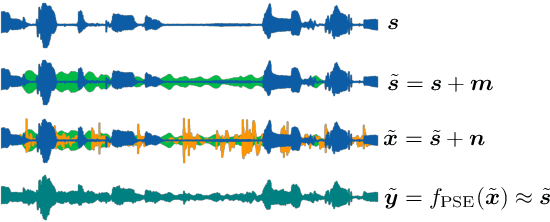
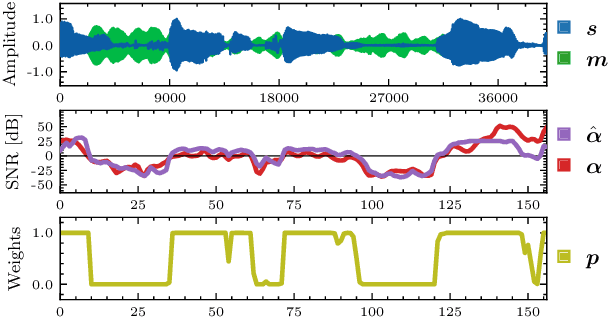
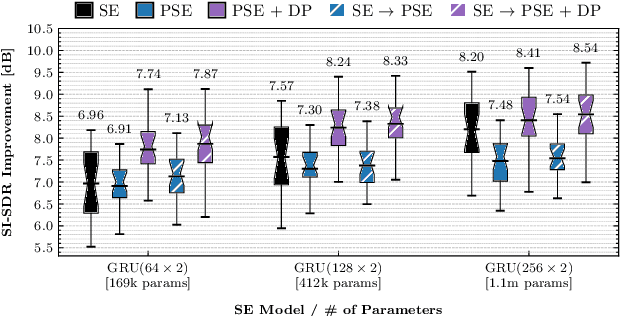
Training personalized speech enhancement models is innately a no-shot learning problem due to privacy constraints and limited access to noise-free speech from the target user. If there is an abundance of unlabeled noisy speech from the test-time user, a personalized speech enhancement model can be trained using self-supervised learning. One straightforward approach to model personalization is to use the target speaker's noisy recordings as pseudo-sources. Then, a pseudo denoising model learns to remove injected training noises and recover the pseudo-sources. However, this approach is volatile as it depends on the quality of the pseudo-sources, which may be too noisy. As a remedy, we propose an improvement to the self-supervised approach through data purification. We first train an SNR predictor model to estimate the frame-by-frame SNR of the pseudo-sources. Then, the predictor's estimates are converted into weights which adjust the frame-by-frame contribution of the pseudo-sources towards training the personalized model. We empirically show that the proposed data purification step improves the usability of the speaker-specific noisy data in the context of personalized speech enhancement. Without relying on any clean speech recordings or speaker embeddings, our approach may be seen as privacy-preserving.
Audiovisual Speech Synthesis using Tacotron2
Aug 03, 2020
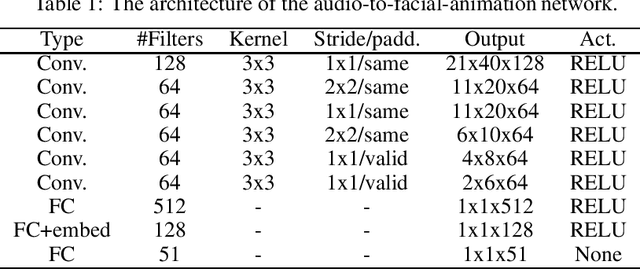
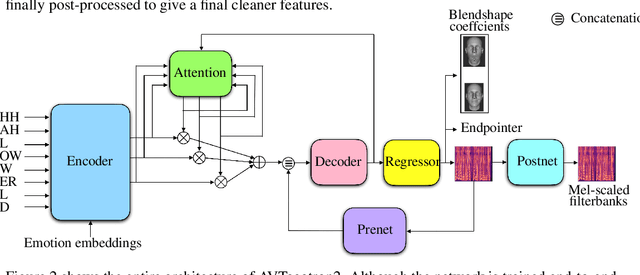
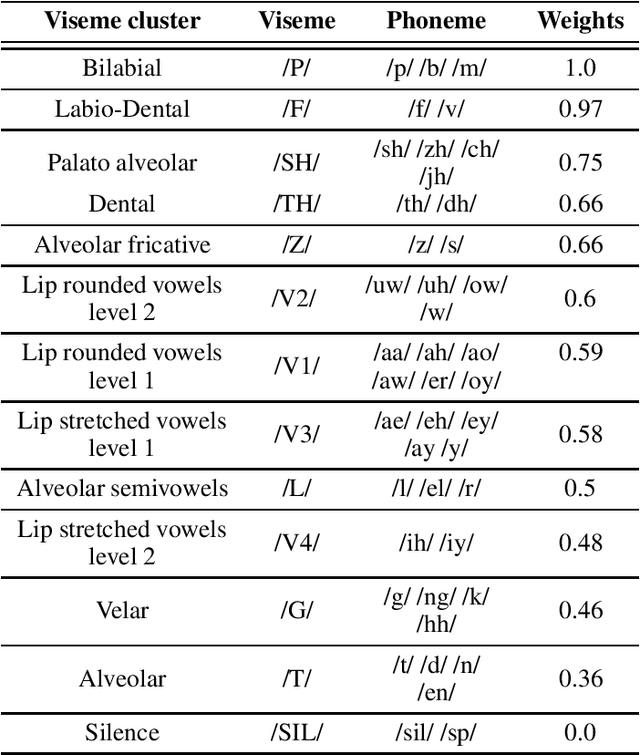
Audiovisual speech synthesis is the problem of synthesizing a talking face while maximizing the coherency of the acoustic and visual speech. In this paper, we propose and compare two audiovisual speech synthesis systems for 3D face models. The first system is the AVTacotron2, which is an end-to-end text-to-audiovisual speech synthesizer based on the Tacotron2 architecture. AVTacotron2 converts a sequence of phonemes representing the sentence to synthesize into a sequence of acoustic features and the corresponding controllers of a face model. The output acoustic features are used to condition a WaveRNN to reconstruct the speech waveform, and the output facial controllers are used to generate the corresponding video of the talking face. The second audiovisual speech synthesis system is modular, where acoustic speech is synthesized from text using the traditional Tacotron2. The reconstructed acoustic speech signal is then used to drive the facial controls of the face model using an independently trained audio-to-facial-animation neural network. We further condition both the end-to-end and modular approaches on emotion embeddings that encode the required prosody to generate emotional audiovisual speech. We analyze the performance of the two systems and compare them to the ground truth videos using subjective evaluation tests. The end-to-end and modular systems are able to synthesize close to human-like audiovisual speech with mean opinion scores (MOS) of 4.1 and 3.9, respectively, compared to a MOS of 4.1 for the ground truth generated from professionally recorded videos. While the end-to-end system gives a better overall quality, the modular approach is more flexible and the quality of acoustic speech and visual speech synthesis is almost independent of each other.
TransMask: A Compact and Fast Speech Separation Model Based on Transformer
Feb 19, 2021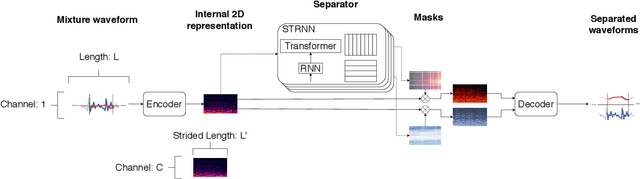
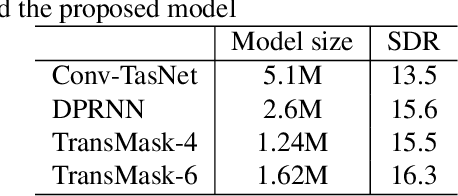
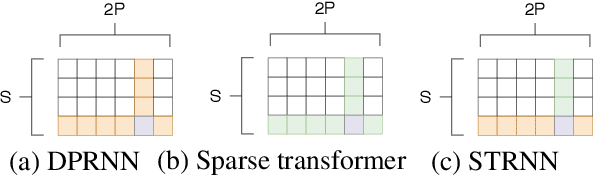
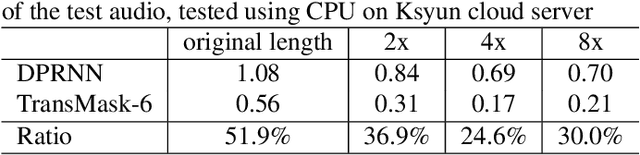
Speech separation is an important problem in speech processing, which targets to separate and generate clean speech from a mixed audio containing speech from different speakers. Empowered by the deep learning technologies over sequence-to-sequence domain, recent neural speech separation models are now capable of generating highly clean speech audios. To make these models more practical by reducing the model size and inference time while maintaining high separation quality, we propose a new transformer-based speech separation approach, called TransMask. By fully un-leashing the power of self-attention on long-term dependency exception, we demonstrate the size of TransMask is more than 60% smaller and the inference is more than 2 times faster than state-of-the-art solutions. TransMask fully utilizes the parallelism during inference, and achieves nearly linear inference time within reasonable input audio lengths. It also outperforms existing solutions on output speech audio quality, achieving SDR above 16 over Librimix benchmark.
A comparison of streaming models and data augmentation methods for robust speech recognition
Nov 19, 2021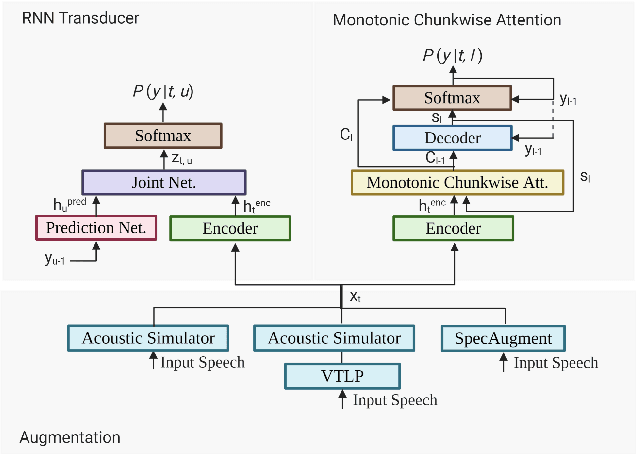

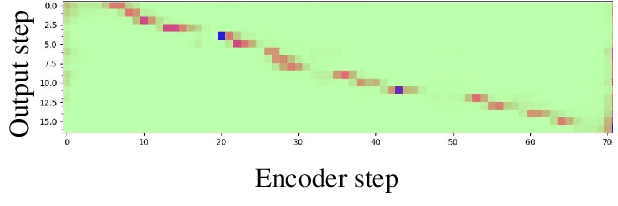

In this paper, we present a comparative study on the robustness of two different online streaming speech recognition models: Monotonic Chunkwise Attention (MoChA) and Recurrent Neural Network-Transducer (RNN-T). We explore three recently proposed data augmentation techniques, namely, multi-conditioned training using an acoustic simulator, Vocal Tract Length Perturbation (VTLP) for speaker variability, and SpecAugment. Experimental results show that unidirectional models are in general more sensitive to noisy examples in the training set. It is observed that the final performance of the model depends on the proportion of training examples processed by data augmentation techniques. MoChA models generally perform better than RNN-T models. However, we observe that training of MoChA models seems to be more sensitive to various factors such as the characteristics of training sets and the incorporation of additional augmentations techniques. On the other hand, RNN-T models perform better than MoChA models in terms of latency, inference time, and the stability of training. Additionally, RNN-T models are generally more robust against noise and reverberation. All these advantages make RNN-T models a better choice for streaming on-device speech recognition compared to MoChA models.
Speaker Attentive Speech Emotion Recognition
Apr 15, 2021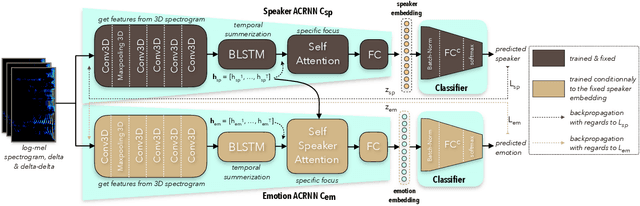
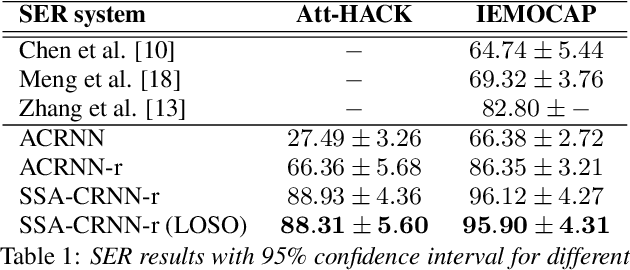
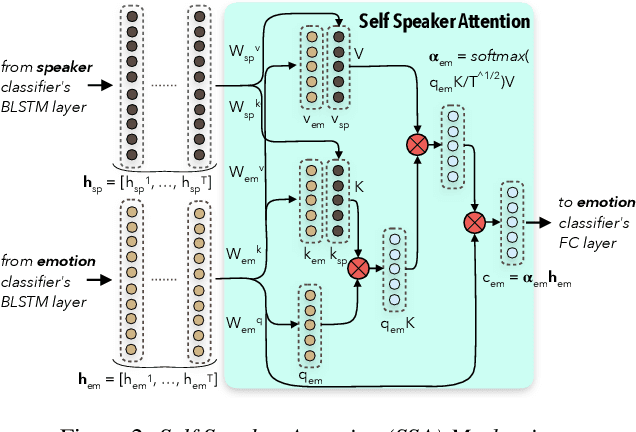
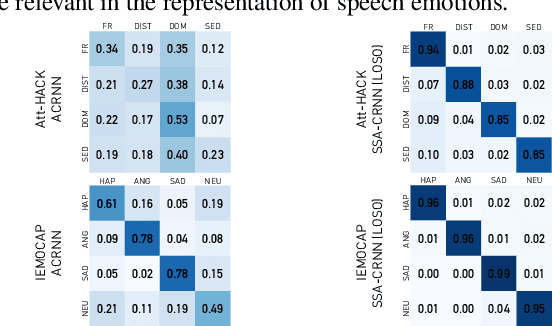
Speech Emotion Recognition (SER) task has known significant improvements over the last years with the advent of Deep Neural Networks (DNNs). However, even the most successful methods are still rather failing when adaptation to specific speakers and scenarios is needed, inevitably leading to poorer performances when compared to humans. In this paper, we present novel work based on the idea of teaching the emotion recognition network about speaker identity. Our system is a combination of two ACRNN classifiers respectively dedicated to speaker and emotion recognition. The first informs the latter through a Self Speaker Attention (SSA) mechanism that is shown to considerably help to focus on emotional information of the speech signal. Experiments on social attitudes database Att-HACK and IEMOCAP corpus demonstrate the effectiveness of the proposed method and achieve the state-of-the-art performance in terms of unweighted average recall.
AdaSpeech: Adaptive Text to Speech for Custom Voice
Mar 01, 2021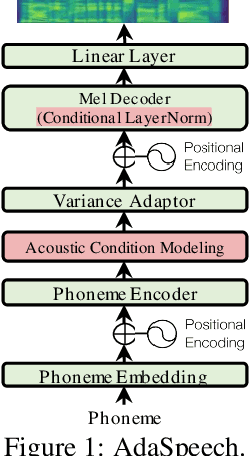
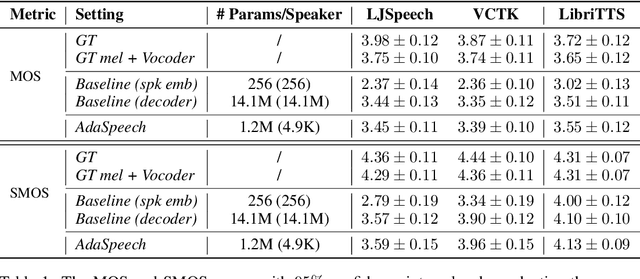
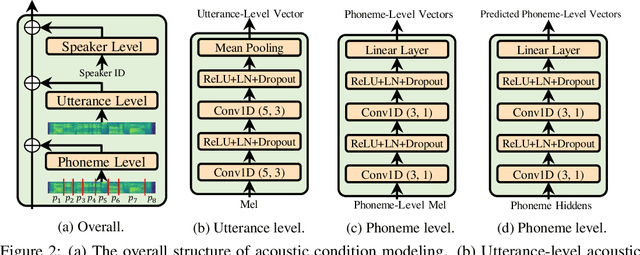
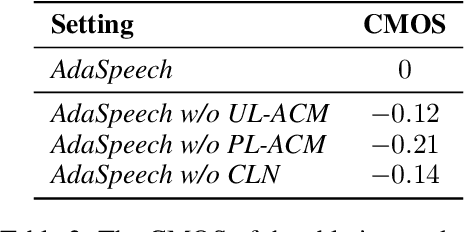
Custom voice, a specific text to speech (TTS) service in commercial speech platforms, aims to adapt a source TTS model to synthesize personal voice for a target speaker using few speech data. Custom voice presents two unique challenges for TTS adaptation: 1) to support diverse customers, the adaptation model needs to handle diverse acoustic conditions that could be very different from source speech data, and 2) to support a large number of customers, the adaptation parameters need to be small enough for each target speaker to reduce memory usage while maintaining high voice quality. In this work, we propose AdaSpeech, an adaptive TTS system for high-quality and efficient customization of new voices. We design several techniques in AdaSpeech to address the two challenges in custom voice: 1) To handle different acoustic conditions, we use two acoustic encoders to extract an utterance-level vector and a sequence of phoneme-level vectors from the target speech during training; in inference, we extract the utterance-level vector from a reference speech and use an acoustic predictor to predict the phoneme-level vectors. 2) To better trade off the adaptation parameters and voice quality, we introduce conditional layer normalization in the mel-spectrogram decoder of AdaSpeech, and fine-tune this part in addition to speaker embedding for adaptation. We pre-train the source TTS model on LibriTTS datasets and fine-tune it on VCTK and LJSpeech datasets (with different acoustic conditions from LibriTTS) with few adaptation data, e.g., 20 sentences, about 1 minute speech. Experiment results show that AdaSpeech achieves much better adaptation quality than baseline methods, with only about 5K specific parameters for each speaker, which demonstrates its effectiveness for custom voice. Audio samples are available at https://speechresearch.github.io/adaspeech/.
TS-RIR: Translated synthetic room impulse responses for speech augmentation
Mar 31, 2021
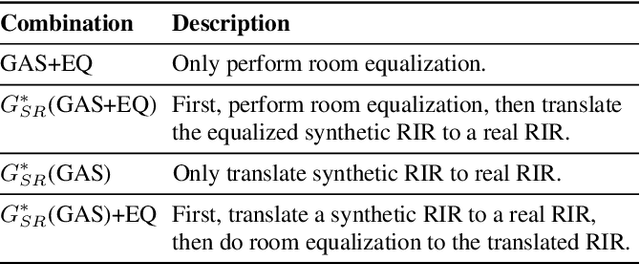
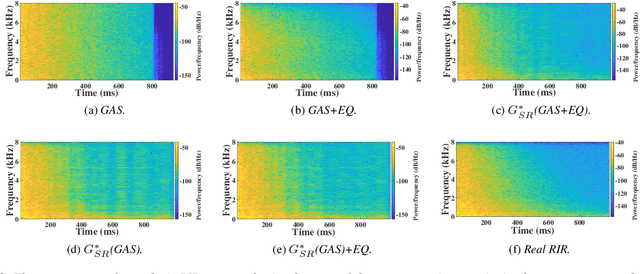
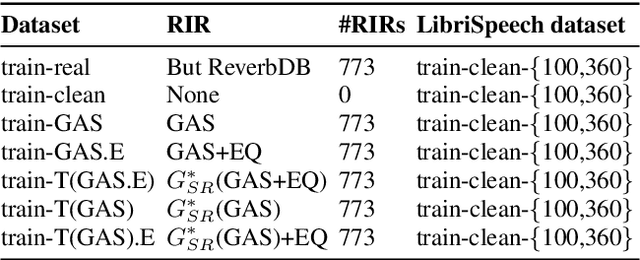
We propose a method for improving the quality of synthetic room impulse responses generated using acoustic simulators for far-field speech recognition tasks. We bridge the gap between the synthetic room impulse responses and the real room impulse responses using our novel, one-dimensional CycleGAN architecture. We pass a synthetic room impulse response in the form of raw-waveform audio to our one-dimensional CycleGAN and translate it into a real room impulse response. We also perform sub-band room equalization to the translated room impulse response to further improve the quality of the room impulse response. We artificially create far-field speech by convolving the LibriSpeech clean speech dataset [1] with room impulse response and adding background noise. We show that far-field speech simulated with the improved room impulse response using our approach reduces the word error rate by up to 19.9% compared to the unmodified room impulse response in Kaldi LibriSpeech far-field automatic speech recognition benchmark [2].
Unsupervised Cross-Lingual Speech Emotion Recognition Using Pseudo Multilabel
Aug 19, 2021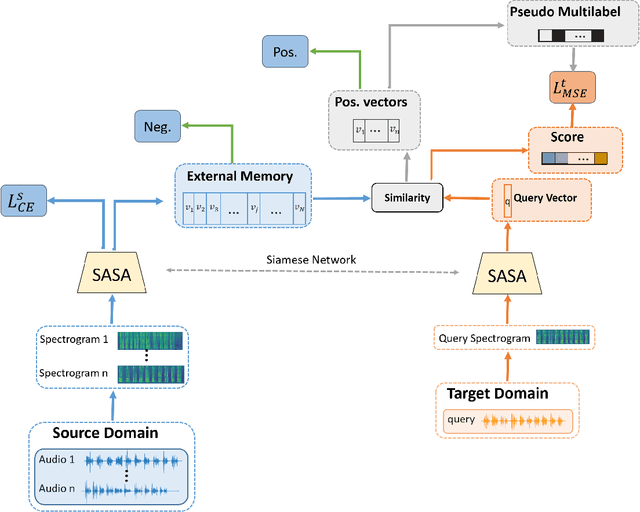
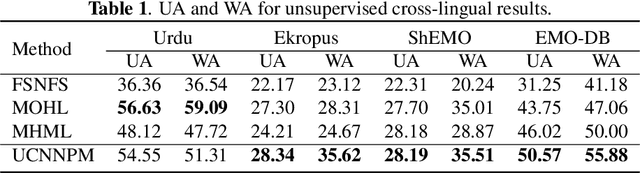

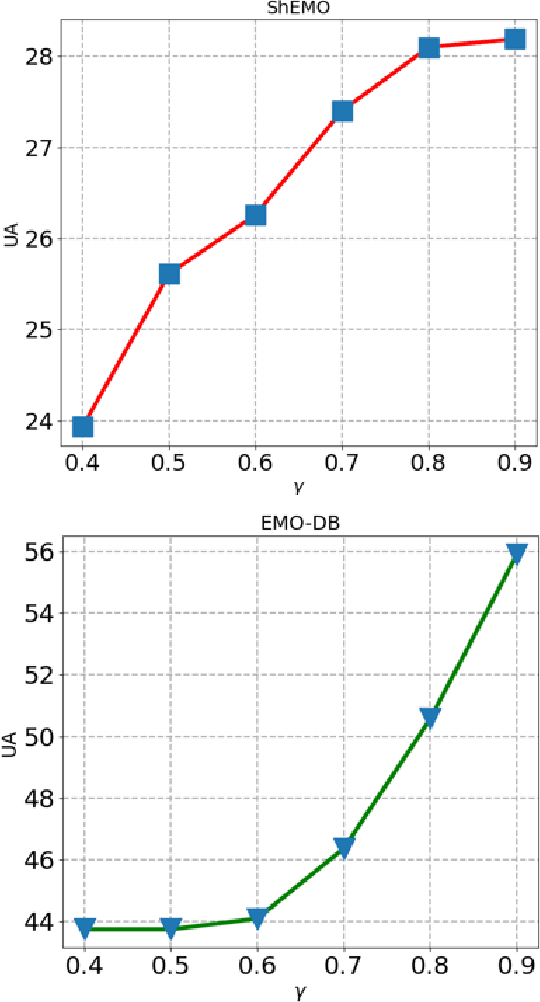
Speech Emotion Recognition (SER) in a single language has achieved remarkable results through deep learning approaches in the last decade. However, cross-lingual SER remains a challenge in real-world applications due to a great difference between the source and target domain distributions. To address this issue, we propose an Unsupervised Cross-Lingual Neural Network with Pseudo Multilabel (UCNNPM) that is trained to learn the emotion similarities between source domain features inside an external memory adjusted to identify emotion in cross-lingual databases. UCNNPM introduces a novel approach that leverages external memory to store source domain features and generates pseudo multilabel for each target domain data by computing the similarities between the external memory and the target domain features. We evaluate our approach on multiple different languages of speech emotion databases. Experimental results show our proposed approach significantly improves the weighted accuracy (WA) across multiple low-resource languages on Urdu, Skropus, ShEMO, and EMO-DB corpus.
KeypartX: Graph-based Perception (Text) Representation
Sep 23, 2022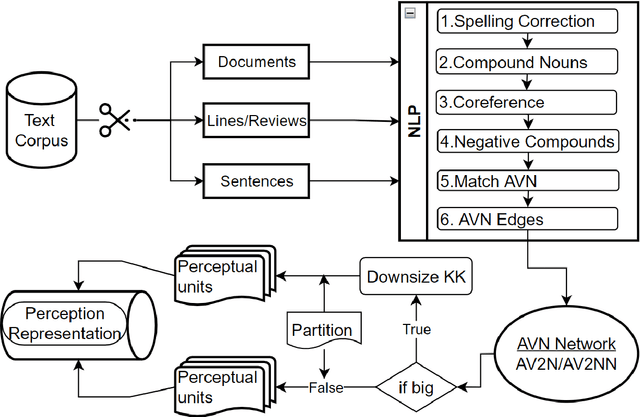

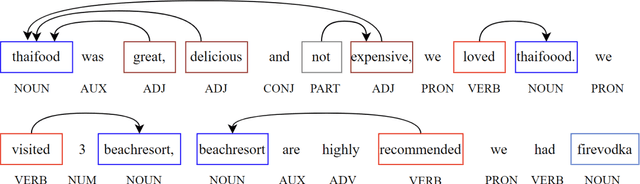
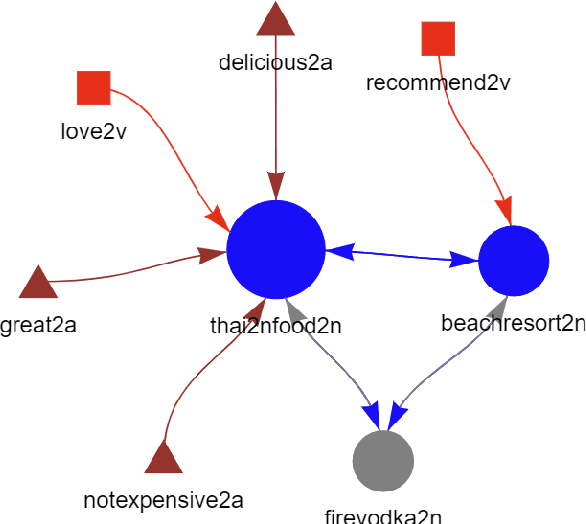
The availability of big data has opened up big opportunities for individuals, businesses and academics to view big into what is happening in their world. Previous works of text representation mostly focused on informativeness from massive words' frequency or cooccurrence. However, big data is a double-edged sword which is big in volume but unstructured in format. The unstructured edge requires specific techniques to transform 'big' into meaningful instead of informative alone. This study presents KeypartX, a graph-based approach to represent perception (text in general) by key parts of speech. Different from bag-of-words/vector-based machine learning, this technique is human-like learning that could extracts meanings from linguistic (semantic, syntactic and pragmatic) information. Moreover, KeypartX is big-data capable but not hungry, which is even applicable to the minimum unit of text:sentence.
W2v-BERT: Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training
Aug 07, 2021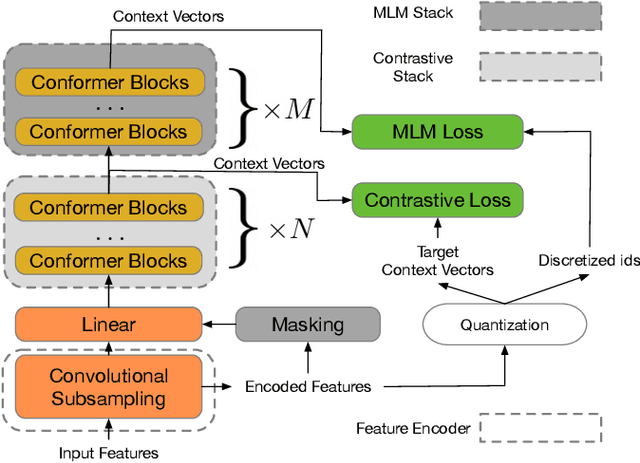

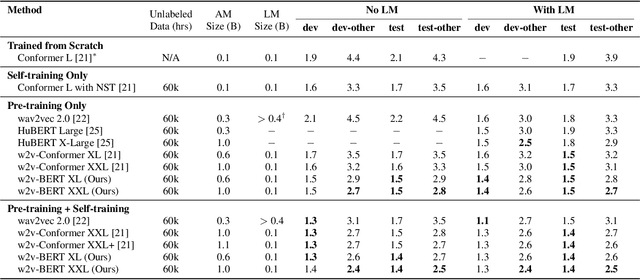
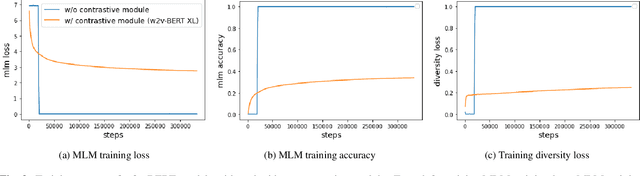
Motivated by the success of masked language modeling~(MLM) in pre-training natural language processing models, we propose w2v-BERT that explores MLM for self-supervised speech representation learning. w2v-BERT is a framework that combines contrastive learning and MLM, where the former trains the model to discretize input continuous speech signals into a finite set of discriminative speech tokens, and the latter trains the model to learn contextualized speech representations via solving a masked prediction task consuming the discretized tokens. In contrast to existing MLM-based speech pre-training frameworks such as HuBERT, which relies on an iterative re-clustering and re-training process, or vq-wav2vec, which concatenates two separately trained modules, w2v-BERT can be optimized in an end-to-end fashion by solving the two self-supervised tasks~(the contrastive task and MLM) simultaneously. Our experiments show that w2v-BERT achieves competitive results compared to current state-of-the-art pre-trained models on the LibriSpeech benchmarks when using the Libri-Light~60k corpus as the unsupervised data. In particular, when compared to published models such as conformer-based wav2vec~2.0 and HuBERT, our model shows~5\% to~10\% relative WER reduction on the test-clean and test-other subsets. When applied to the Google's Voice Search traffic dataset, w2v-BERT outperforms our internal conformer-based wav2vec~2.0 by more than~30\% relatively.