 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
TS-RIR: Translated synthetic room impulse responses for speech augmentation
Apr 03, 2021
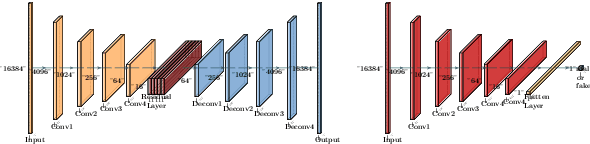
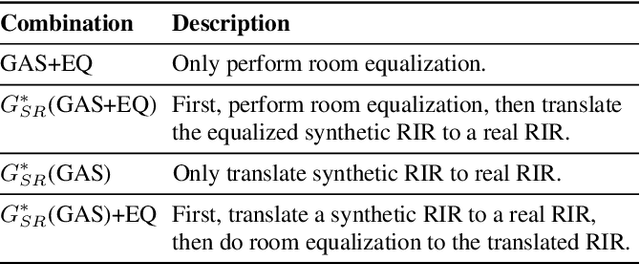
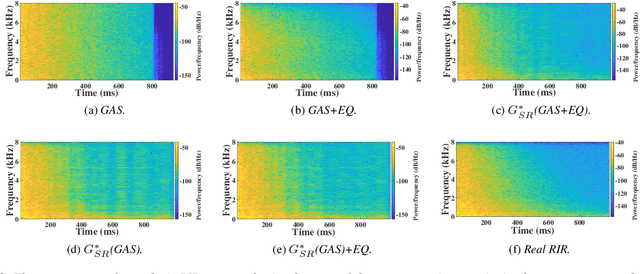
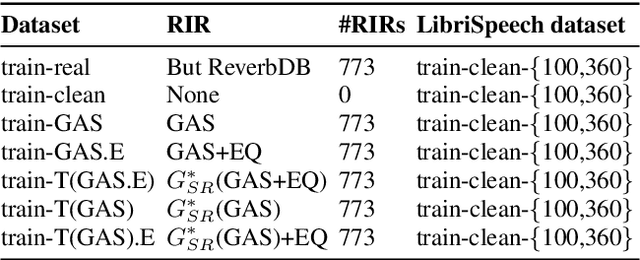
We present a method for improving the quality of synthetic room impulse responses for far-field speech recognition. We bridge the gap between the fidelity of synthetic room impulse responses (RIRs) and the real room impulse responses using our novel, TS-RIRGAN architecture. Given a synthetic RIR in the form of raw audio, we use TS-RIRGAN to translate it into a real RIR. We also perform real-world sub-band room equalization on the translated synthetic RIR. Our overall approach improves the quality of synthetic RIRs by compensating low-frequency wave effects, similar to those in real RIRs. We evaluate the performance of improved synthetic RIRs on a far-field speech dataset augmented by convolving the LibriSpeech clean speech dataset [1] with RIRs and adding background noise. We show that far-field speech augmented using our improved synthetic RIRs reduces the word error rate by up to 19.9% in Kaldi far-field automatic speech recognition benchmark [2].
Formant Estimation and Tracking using Probabilistic Heat-Maps
Jun 23, 2022

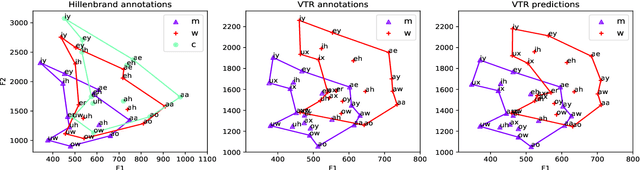
Formants are the spectral maxima that result from acoustic resonances of the human vocal tract, and their accurate estimation is among the most fundamental speech processing problems. Recent work has been shown that those frequencies can accurately be estimated using deep learning techniques. However, when presented with a speech from a different domain than that in which they have been trained on, these methods exhibit a decline in performance, limiting their usage as generic tools. The contribution of this paper is to propose a new network architecture that performs well on a variety of different speaker and speech domains. Our proposed model is composed of a shared encoder that gets as input a spectrogram and outputs a domain-invariant representation. Then, multiple decoders further process this representation, each responsible for predicting a different formant while considering the lower formant predictions. An advantage of our model is that it is based on heatmaps that generate a probability distribution over formant predictions. Results suggest that our proposed model better represents the signal over various domains and leads to better formant frequency tracking and estimation.
Provable Subspace Identification Under Post-Nonlinear Mixtures
Oct 14, 2022

Unsupervised mixture learning (UML) aims at identifying linearly or nonlinearly mixed latent components in a blind manner. UML is known to be challenging: Even learning linear mixtures requires highly nontrivial analytical tools, e.g., independent component analysis or nonnegative matrix factorization. In this work, the post-nonlinear (PNL) mixture model -- where unknown element-wise nonlinear functions are imposed onto a linear mixture -- is revisited. The PNL model is widely employed in different fields ranging from brain signal classification, speech separation, remote sensing, to causal discovery. To identify and remove the unknown nonlinear functions, existing works often assume different properties on the latent components (e.g., statistical independence or probability-simplex structures). This work shows that under a carefully designed UML criterion, the existence of a nontrivial null space associated with the underlying mixing system suffices to guarantee identification/removal of the unknown nonlinearity. Compared to prior works, our finding largely relaxes the conditions of attaining PNL identifiability, and thus may benefit applications where no strong structural information on the latent components is known. A finite-sample analysis is offered to characterize the performance of the proposed approach under realistic settings. To implement the proposed learning criterion, a block coordinate descent algorithm is proposed. A series of numerical experiments corroborate our theoretical claims.
End-to-End Video-To-Speech Synthesis using Generative Adversarial Networks
Apr 30, 2021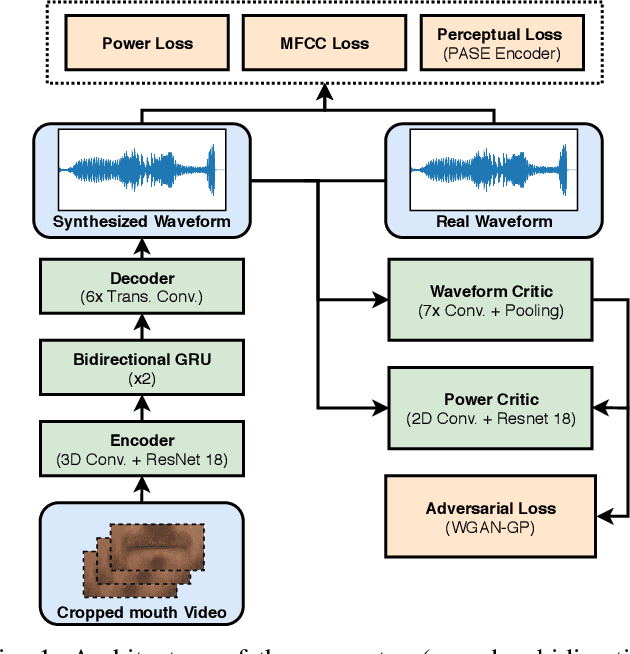
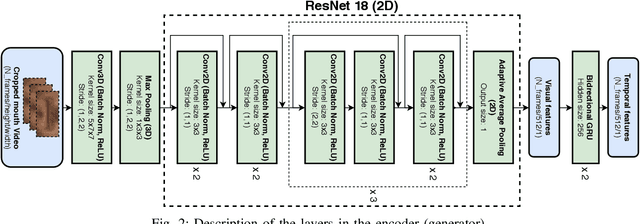
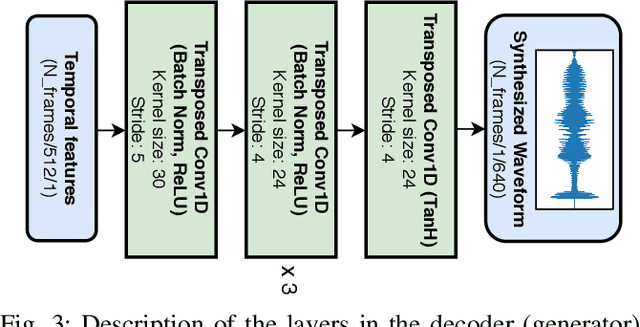
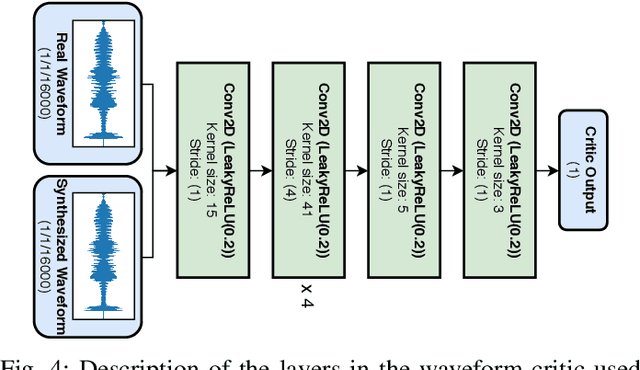
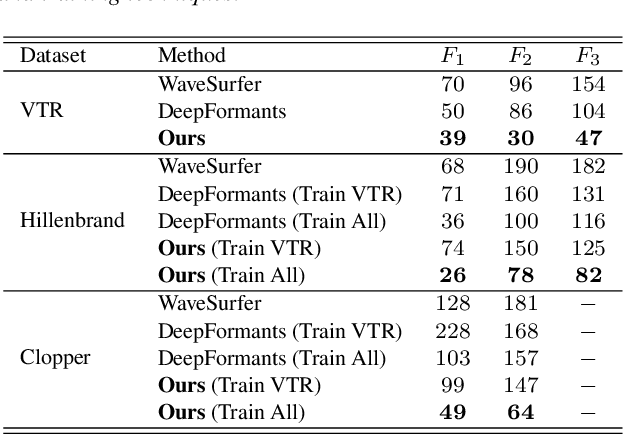
Video-to-speech is the process of reconstructing the audio speech from a video of a spoken utterance. Previous approaches to this task have relied on a two-step process where an intermediate representation is inferred from the video, and is then decoded into waveform audio using a vocoder or a waveform reconstruction algorithm. In this work, we propose a new end-to-end video-to-speech model based on Generative Adversarial Networks (GANs) which translates spoken video to waveform end-to-end without using any intermediate representation or separate waveform synthesis algorithm. Our model consists of an encoder-decoder architecture that receives raw video as input and generates speech, which is then fed to a waveform critic and a power critic. The use of an adversarial loss based on these two critics enables the direct synthesis of raw audio waveform and ensures its realism. In addition, the use of our three comparative losses helps establish direct correspondence between the generated audio and the input video. We show that this model is able to reconstruct speech with remarkable realism for constrained datasets such as GRID, and that it is the first end-to-end model to produce intelligible speech for LRW (Lip Reading in the Wild), featuring hundreds of speakers recorded entirely `in the wild'. We evaluate the generated samples in two different scenarios -- seen and unseen speakers -- using four objective metrics which measure the quality and intelligibility of artificial speech. We demonstrate that the proposed approach outperforms all previous works in most metrics on GRID and LRW.
Out-of-Distribution Representation Learning for Time Series Classification
Sep 26, 2022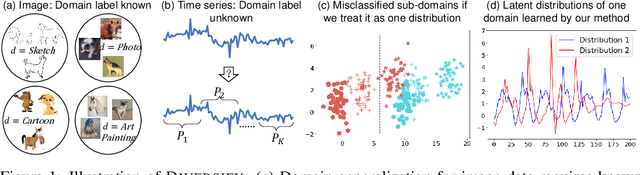
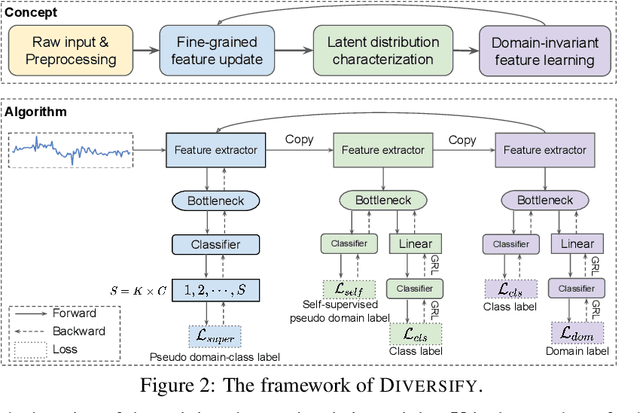
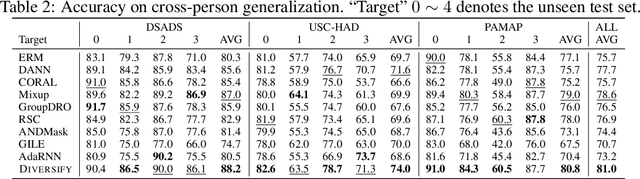
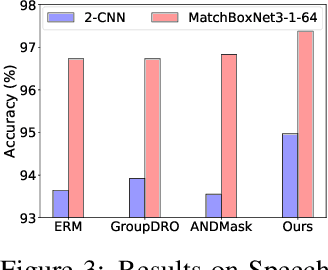
Time series classification is an important problem in real world. Due to its non-stationary property that the distribution changes over time, it remains challenging to build models for generalization to unseen distributions. In this paper, we propose to view the time series classification problem from the distribution perspective. We argue that the temporal complexity attributes to the unknown latent distributions within. To this end, we propose DIVERSIFY to learn generalized representations for time series classification. DIVERSIFY takes an iterative process: it first obtains the worst-case distribution scenario via adversarial training, then matches the distributions of the obtained sub-domains. We also present some theoretical insights. We conduct experiments on gesture recognition, speech commands recognition, wearable stress and affect detection, and sensor-based human activity recognition with a total of seven datasets in different settings. Results demonstrate that DIVERSIFY significantly outperforms other baselines and effectively characterizes the latent distributions by qualitative and quantitative analysis.
BSTC: A Large-Scale Chinese-English Speech Translation Dataset
Apr 19, 2021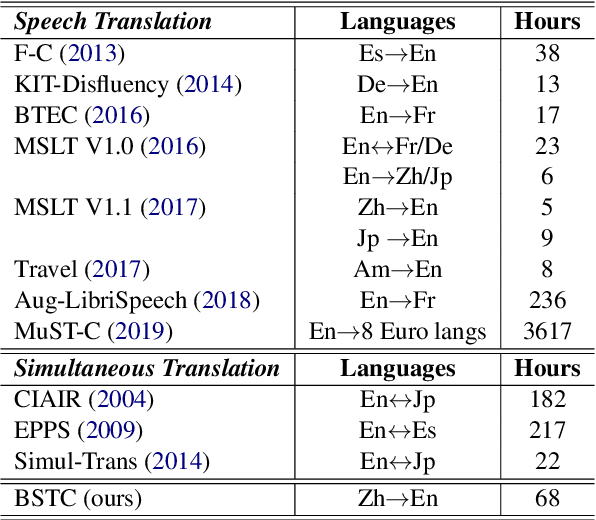
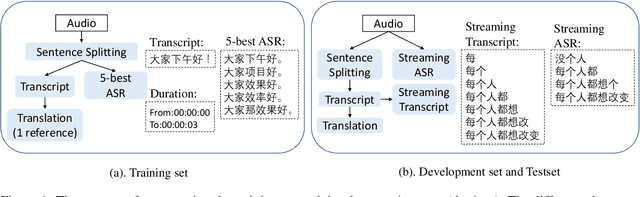

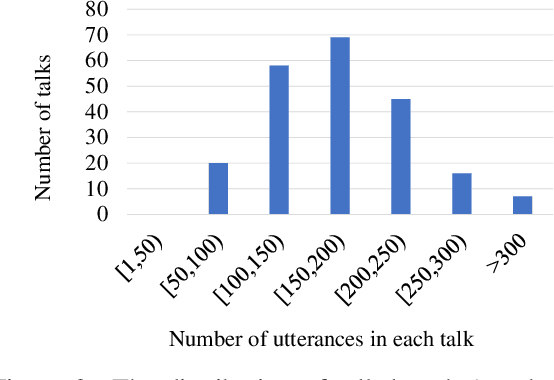
This paper presents BSTC (Baidu Speech Translation Corpus), a large-scale Chinese-English speech translation dataset. This dataset is constructed based on a collection of licensed videos of talks or lectures, including about 68 hours of Mandarin data, their manual transcripts and translations into English, as well as automated transcripts by an automatic speech recognition (ASR) model. We have further asked three experienced interpreters to simultaneously interpret the testing talks in a mock conference setting. This corpus is expected to promote the research of automatic simultaneous translation as well as the development of practical systems. We have organized simultaneous translation tasks and used this corpus to evaluate automatic simultaneous translation systems.
Unsupervised Cross-Lingual Speech Emotion Recognition Using Pseudo Multilabel
Aug 19, 2021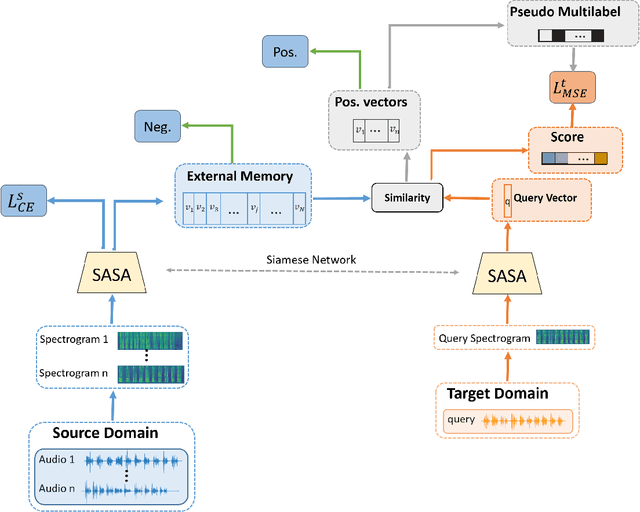
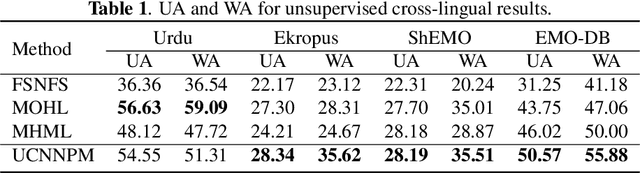

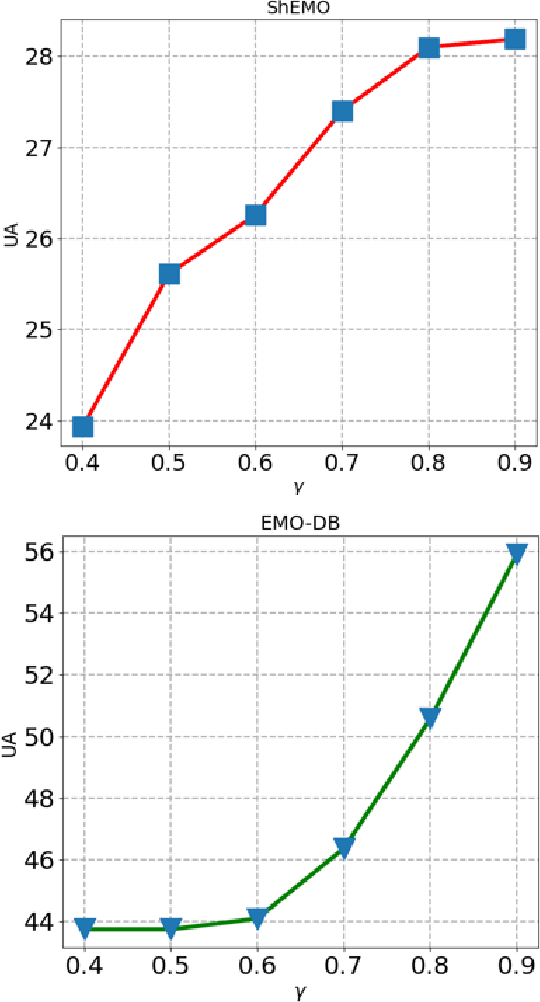
Speech Emotion Recognition (SER) in a single language has achieved remarkable results through deep learning approaches in the last decade. However, cross-lingual SER remains a challenge in real-world applications due to a great difference between the source and target domain distributions. To address this issue, we propose an Unsupervised Cross-Lingual Neural Network with Pseudo Multilabel (UCNNPM) that is trained to learn the emotion similarities between source domain features inside an external memory adjusted to identify emotion in cross-lingual databases. UCNNPM introduces a novel approach that leverages external memory to store source domain features and generates pseudo multilabel for each target domain data by computing the similarities between the external memory and the target domain features. We evaluate our approach on multiple different languages of speech emotion databases. Experimental results show our proposed approach significantly improves the weighted accuracy (WA) across multiple low-resource languages on Urdu, Skropus, ShEMO, and EMO-DB corpus.
Personalized Speech Enhancement through Self-Supervised Data Augmentation and Purification
Apr 05, 2021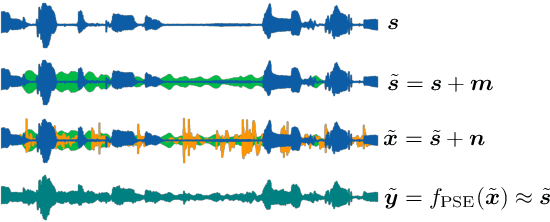
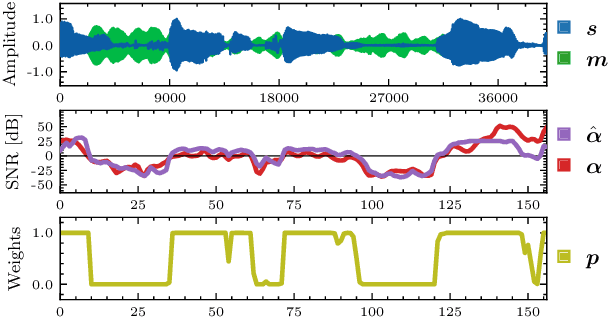
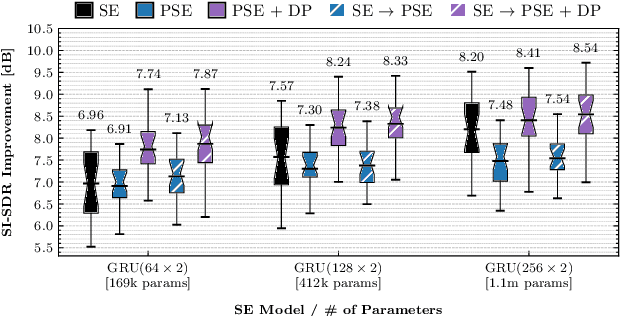
Training personalized speech enhancement models is innately a no-shot learning problem due to privacy constraints and limited access to noise-free speech from the target user. If there is an abundance of unlabeled noisy speech from the test-time user, a personalized speech enhancement model can be trained using self-supervised learning. One straightforward approach to model personalization is to use the target speaker's noisy recordings as pseudo-sources. Then, a pseudo denoising model learns to remove injected training noises and recover the pseudo-sources. However, this approach is volatile as it depends on the quality of the pseudo-sources, which may be too noisy. As a remedy, we propose an improvement to the self-supervised approach through data purification. We first train an SNR predictor model to estimate the frame-by-frame SNR of the pseudo-sources. Then, the predictor's estimates are converted into weights which adjust the frame-by-frame contribution of the pseudo-sources towards training the personalized model. We empirically show that the proposed data purification step improves the usability of the speaker-specific noisy data in the context of personalized speech enhancement. Without relying on any clean speech recordings or speaker embeddings, our approach may be seen as privacy-preserving.
Position Prediction as an Effective Pretraining Strategy
Jul 15, 2022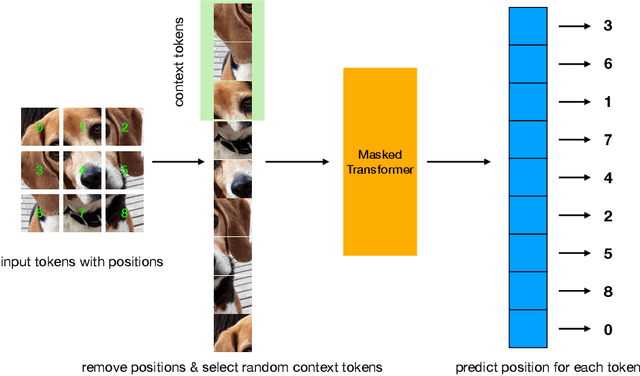


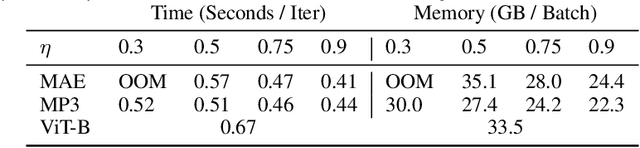
Transformers have gained increasing popularity in a wide range of applications, including Natural Language Processing (NLP), Computer Vision and Speech Recognition, because of their powerful representational capacity. However, harnessing this representational capacity effectively requires a large amount of data, strong regularization, or both, to mitigate overfitting. Recently, the power of the Transformer has been unlocked by self-supervised pretraining strategies based on masked autoencoders which rely on reconstructing masked inputs, directly, or contrastively from unmasked content. This pretraining strategy which has been used in BERT models in NLP, Wav2Vec models in Speech and, recently, in MAE models in Vision, forces the model to learn about relationships between the content in different parts of the input using autoencoding related objectives. In this paper, we propose a novel, but surprisingly simple alternative to content reconstruction~-- that of predicting locations from content, without providing positional information for it. Doing so requires the Transformer to understand the positional relationships between different parts of the input, from their content alone. This amounts to an efficient implementation where the pretext task is a classification problem among all possible positions for each input token. We experiment on both Vision and Speech benchmarks, where our approach brings improvements over strong supervised training baselines and is comparable to modern unsupervised/self-supervised pretraining methods. Our method also enables Transformers trained without position embeddings to outperform ones trained with full position information.
Understanding effect of speech perception in EEG based speech recognition systems
May 29, 2020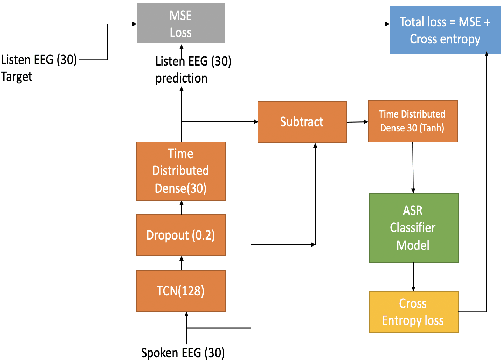
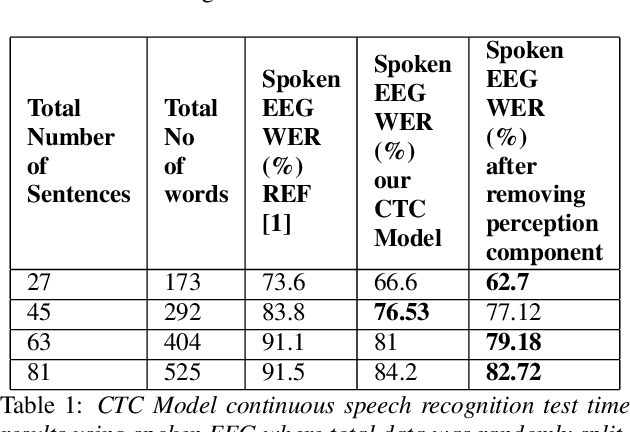
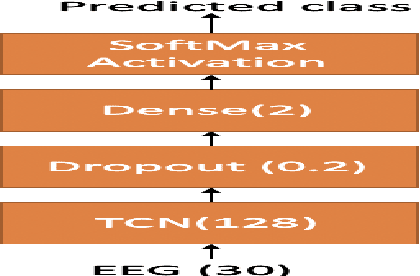
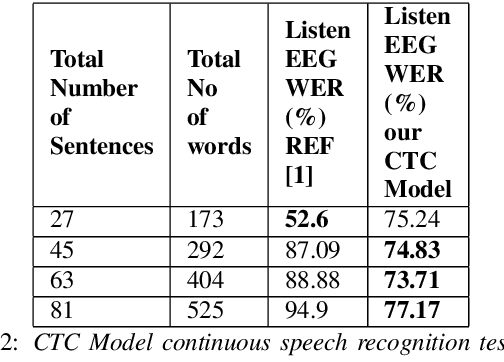
The electroencephalography (EEG) signals recorded in parallel with speech are used to perform isolated and continuous speech recognition. During speaking process, one also hears his or her own speech and this speech perception is also reflected in the recorded EEG signals. In this paper we investigate whether it is possible to separate out this speech perception component from EEG signals in order to design more robust EEG based speech recognition systems. We further demonstrate predicting EEG signals recorded in parallel with speaking from EEG signals recorded in parallel with passive listening and vice versa with very low normalized root mean squared error (RMSE). We finally demonstrate both isolated and continuous speech recognition using EEG signals recorded in parallel with listening, speaking and improve the previous connectionist temporal classification (CTC) model results demonstrated by authors in [1] using their data set.