 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
VQTTS: High-Fidelity Text-to-Speech Synthesis with Self-Supervised VQ Acoustic Feature
Apr 02, 2022
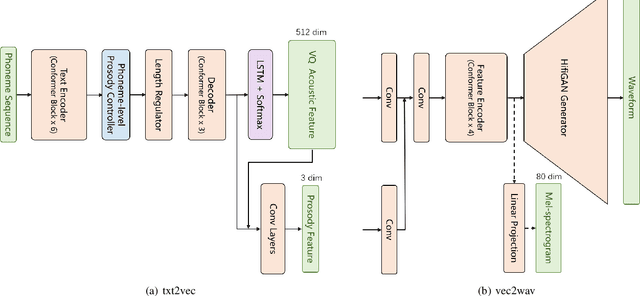
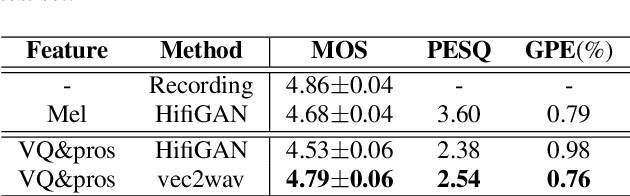
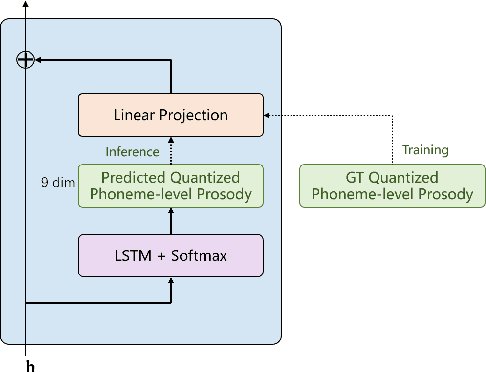
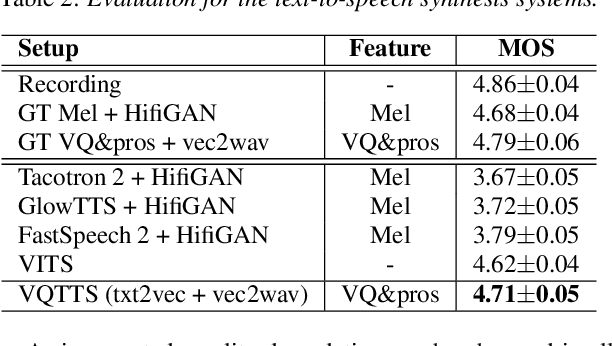
The mainstream neural text-to-speech(TTS) pipeline is a cascade system, including an acoustic model(AM) that predicts acoustic feature from the input transcript and a vocoder that generates waveform according to the given acoustic feature. However, the acoustic feature in current TTS systems is typically mel-spectrogram, which is highly correlated along both time and frequency axes in a complicated way, leading to a great difficulty for the AM to predict. Although high-fidelity audio can be generated by recent neural vocoders from ground-truth(GT) mel-spectrogram, the gap between the GT and the predicted mel-spectrogram from AM degrades the performance of the entire TTS system. In this work, we propose VQTTS, consisting of an AM txt2vec and a vocoder vec2wav, which uses self-supervised vector-quantized(VQ) acoustic feature rather than mel-spectrogram. We redesign both the AM and the vocoder accordingly. In particular, txt2vec basically becomes a classification model instead of a traditional regression model while vec2wav uses an additional feature encoder before HifiGAN generator for smoothing the discontinuous quantized feature. Our experiments show that vec2wav achieves better reconstruction performance than HifiGAN when using self-supervised VQ acoustic feature. Moreover, our entire TTS system VQTTS achieves state-of-the-art performance in terms of naturalness among all current publicly available TTS systems.
Temporal envelope and fine structure cues for dysarthric speech detection using CNNs
Aug 25, 2021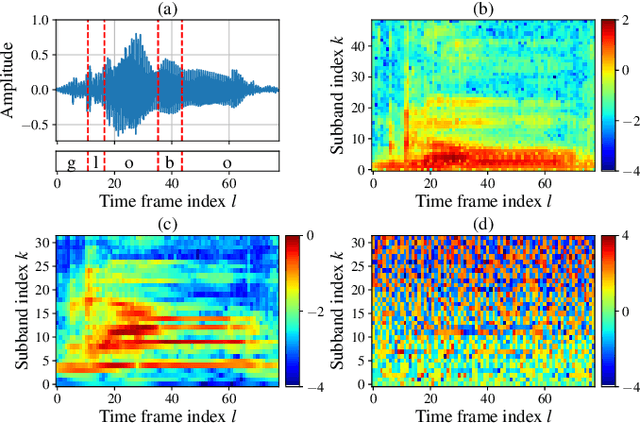
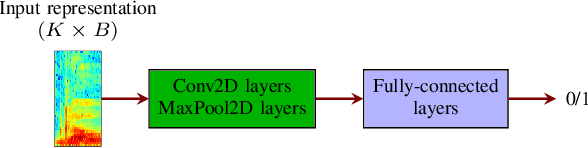
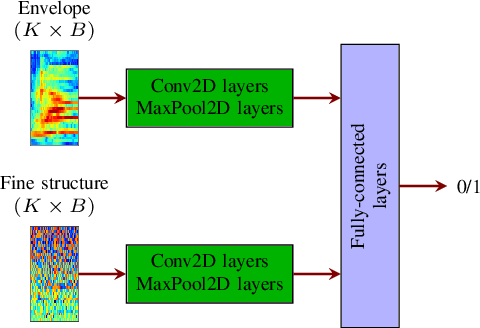
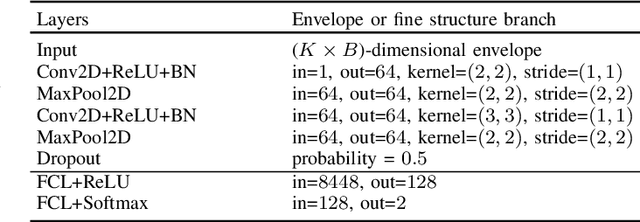
Deep learning-based techniques for automatic dysarthric speech detection have recently attracted interest in the research community. State-of-the-art techniques typically learn neurotypical and dysarthric discriminative representations by processing time-frequency input representations such as the magnitude spectrum of the short-time Fourier transform (STFT). Although these techniques are expected to leverage perceptual dysarthric cues, representations such as the magnitude spectrum of the STFT do not necessarily convey perceptual aspects of complex sounds. Inspired by the temporal processing mechanisms of the human auditory system, in this paper we factor signals into the product of a slowly varying envelope and a rapidly varying fine structure. Separately exploiting the different perceptual cues present in the envelope (i.e., phonetic information, stress, and voicing) and fine structure (i.e., pitch, vowel quality, and breathiness), two discriminative representations are learned through a convolutional neural network and used for automatic dysarthric speech detection. Experimental results show that processing both the envelope and fine structure representations yields a considerably better dysarthric speech detection performance than processing only the envelope, fine structure, or magnitude spectrum of the STFT representation.
Incorporating Multi-Target in Multi-Stage Speech Enhancement Model for Better Generalization
Jul 09, 2021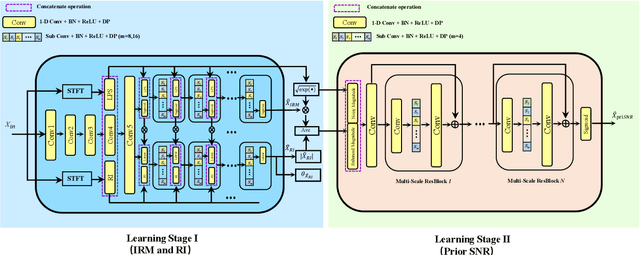
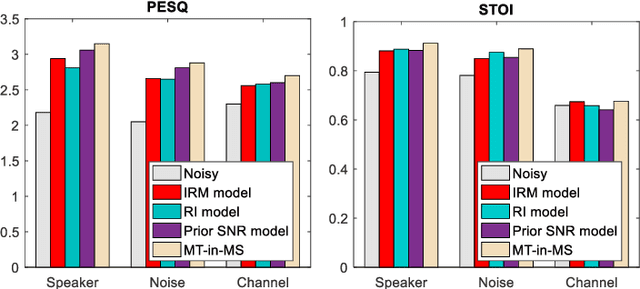
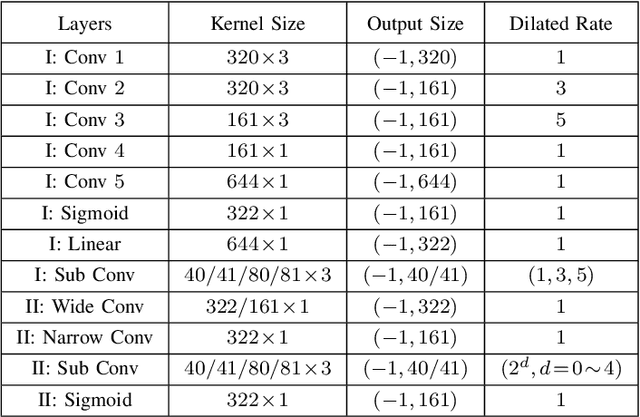
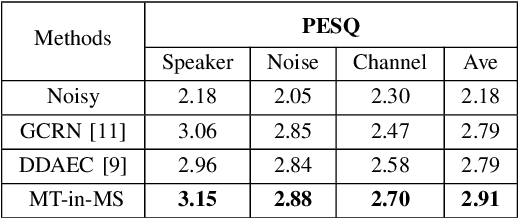
Recent single-channel speech enhancement methods based on deep neural networks (DNNs) have achieved remarkable results, but there are still generalization problems in real scenes. Like other data-driven methods, DNN-based speech enhancement models produce significant performance degradation on untrained data. In this study, we make full use of the contribution of multi-target joint learning to the model generalization capability, and propose a lightweight and low-computing dilated convolutional network (DCN) model for a more robust speech denoising task. Our goal is to integrate the masking target, the mapping target, and the parameters of the traditional speech enhancement estimator into a DCN model to maximize their complementary advantages. To do this, we build a multi-stage learning framework to deal with multiple targets in stages to achieve their joint learning, namely `MT-in-MS'. Our experimental results show that compared with the state-of-the-art time domain and time-frequency domain models, this proposed low-cost DCN model can achieve better generalization performance in speaker, noise, and channel mismatch cases.
Efficient acoustic feature transformation in mismatched environments using a Guided-GAN
Oct 06, 2022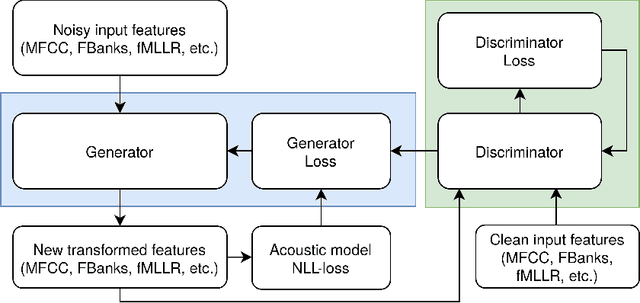

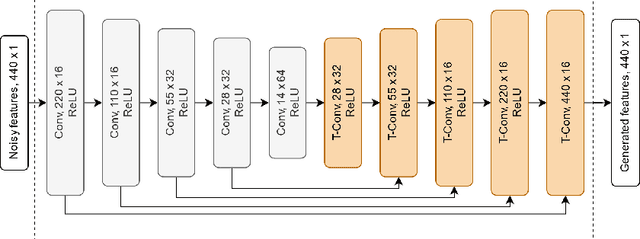
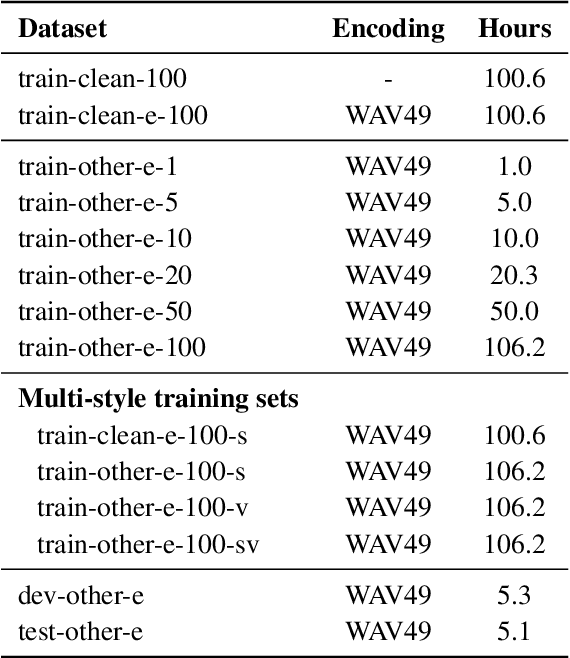
We propose a new framework to improve automatic speech recognition (ASR) systems in resource-scarce environments using a generative adversarial network (GAN) operating on acoustic input features. The GAN is used to enhance the features of mismatched data prior to decoding, or can optionally be used to fine-tune the acoustic model. We achieve improvements that are comparable to multi-style training (MTR), but at a lower computational cost. With less than one hour of data, an ASR system trained on good quality data, and evaluated on mismatched audio is improved by between 11.5% and 19.7% relative word error rate (WER). Experiments demonstrate that the framework can be very useful in under-resourced environments where training data and computational resources are limited. The GAN does not require parallel training data, because it utilises a baseline acoustic model to provide an additional loss term that guides the generator to create acoustic features that are better classified by the baseline.
* Final published version available at: Efficient acoustic feature transformation in mismatched environments using a Guided-GAN. Speech Communication, 143, pp.10-20
Subband-based Generative Adversarial Network for Non-parallel Many-to-many Voice Conversion
Jul 13, 2022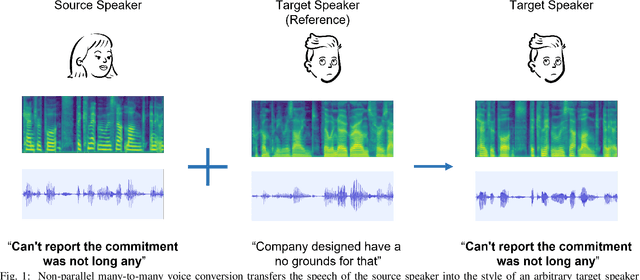
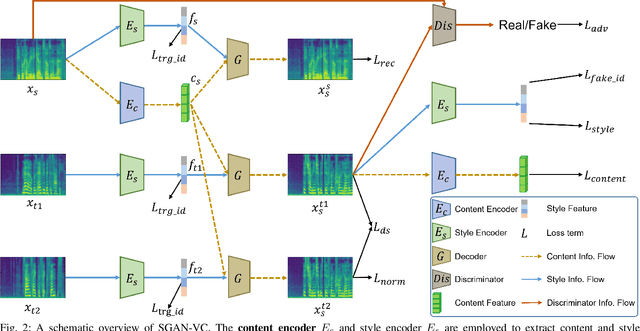
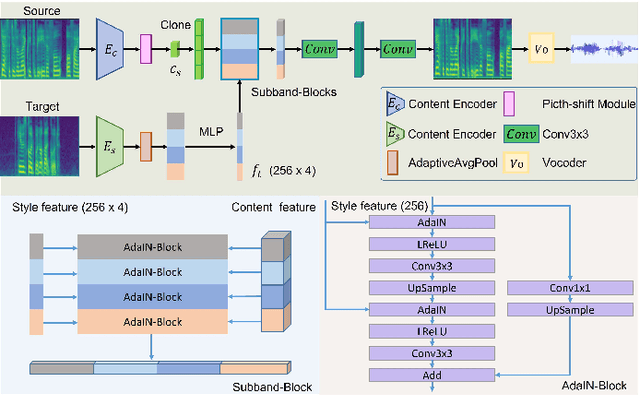
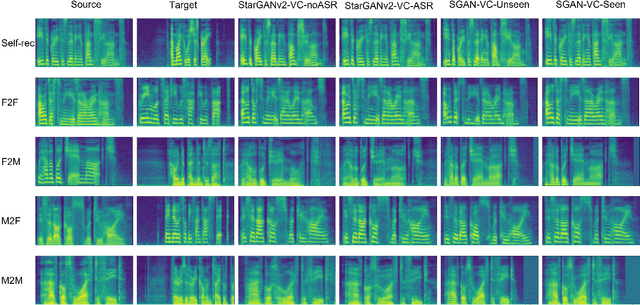
Voice conversion is to generate a new speech with the source content and a target voice style. In this paper, we focus on one general setting, i.e., non-parallel many-to-many voice conversion, which is close to the real-world scenario. As the name implies, non-parallel many-to-many voice conversion does not require the paired source and reference speeches and can be applied to arbitrary voice transfer. In recent years, Generative Adversarial Networks (GANs) and other techniques such as Conditional Variational Autoencoders (CVAEs) have made considerable progress in this field. However, due to the sophistication of voice conversion, the style similarity of the converted speech is still unsatisfactory. Inspired by the inherent structure of mel-spectrogram, we propose a new voice conversion framework, i.e., Subband-based Generative Adversarial Network for Voice Conversion (SGAN-VC). SGAN-VC converts each subband content of the source speech separately by explicitly utilizing the spatial characteristics between different subbands. SGAN-VC contains one style encoder, one content encoder, and one decoder. In particular, the style encoder network is designed to learn style codes for different subbands of the target speaker. The content encoder network can capture the content information on the source speech. Finally, the decoder generates particular subband content. In addition, we propose a pitch-shift module to fine-tune the pitch of the source speaker, making the converted tone more accurate and explainable. Extensive experiments demonstrate that the proposed approach achieves state-of-the-art performance on VCTK Corpus and AISHELL3 datasets both qualitatively and quantitatively, whether on seen or unseen data. Furthermore, the content intelligibility of SGAN-VC on unseen data even exceeds that of StarGANv2-VC with ASR network assistance.
Self-attending RNN for Speech Enhancement to Improve Cross-corpus Generalization
May 26, 2021
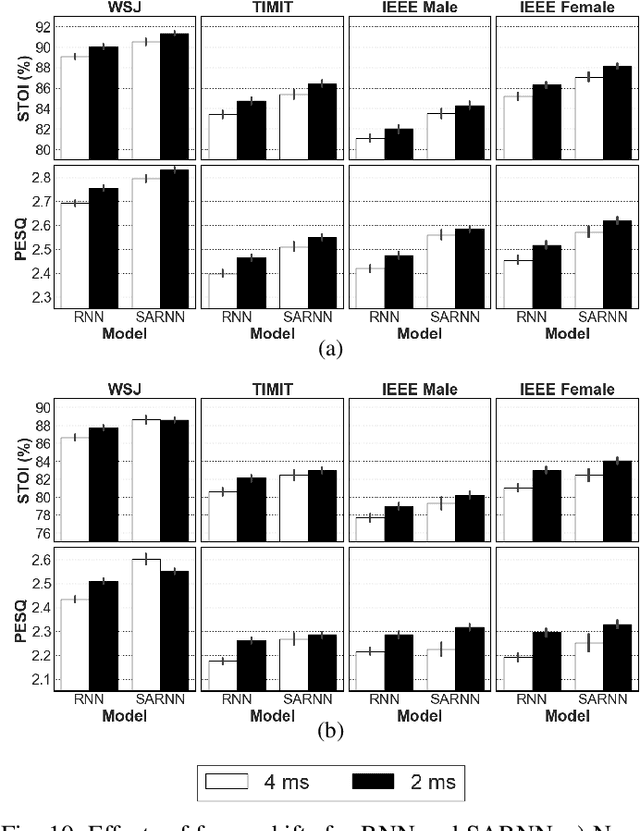
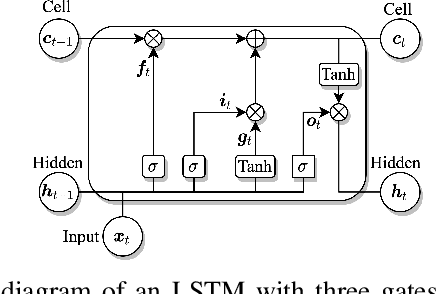
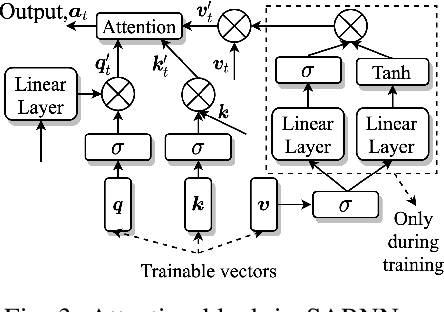
Deep neural networks (DNNs) represent the mainstream methodology for supervised speech enhancement, primarily due to their capability to model complex functions using hierarchical representations. However, a recent study revealed that DNNs trained on a single corpus fail to generalize to untrained corpora, especially in low signal-to-noise ratio (SNR) conditions. Developing a noise, speaker, and corpus independent speech enhancement algorithm is essential for real-world applications. In this study, we propose a self-attending recurrent neural network(SARNN) for time-domain speech enhancement to improve cross-corpus generalization. SARNN comprises of recurrent neural networks (RNNs) augmented with self-attention blocks and feedforward blocks. We evaluate SARNN on different corpora with nonstationary noises in low SNR conditions. Experimental results demonstrate that SARNN substantially outperforms competitive approaches to time-domain speech enhancement, such as RNNs and dual-path SARNNs. Additionally, we report an important finding that the two popular approaches to speech enhancement: complex spectral mapping and time-domain enhancement, obtain similar results for RNN and SARNN with large-scale training. We also provide a challenging subset of the test set used in this study for evaluating future algorithms and facilitating direct comparisons.
Analysis of Disfluency in Children's Speech
Oct 08, 2020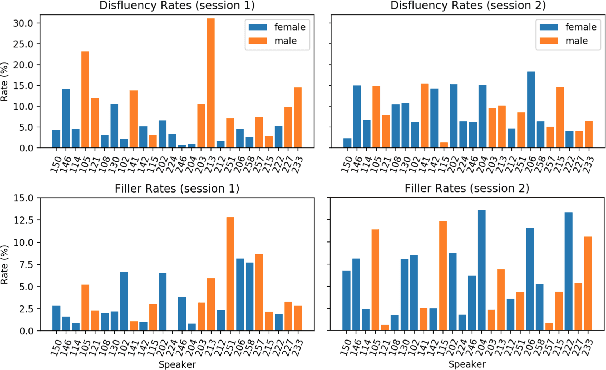
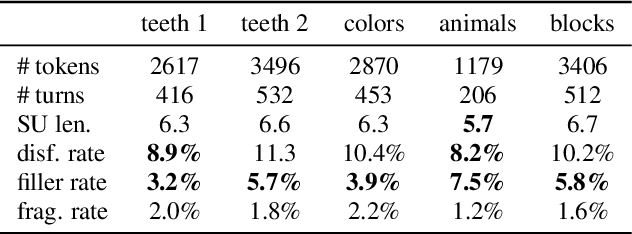
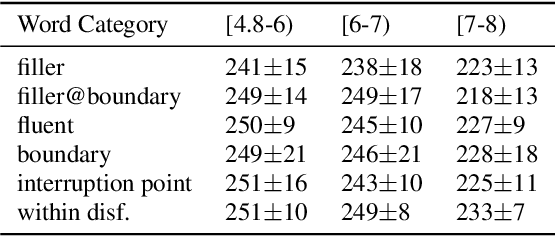
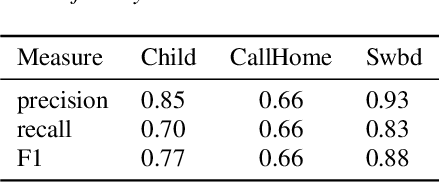
Disfluencies are prevalent in spontaneous speech, as shown in many studies of adult speech. Less is understood about children's speech, especially in pre-school children who are still developing their language skills. We present a novel dataset with annotated disfluencies of spontaneous explanations from 26 children (ages 5--8), interviewed twice over a year-long period. Our preliminary analysis reveals significant differences between children's speech in our corpus and adult spontaneous speech from two corpora (Switchboard and CallHome). Children have higher disfluency and filler rates, tend to use nasal filled pauses more frequently, and on average exhibit longer reparandums than repairs, in contrast to adult speakers. Despite the differences, an automatic disfluency detection system trained on adult (Switchboard) speech transcripts performs reasonably well on children's speech, achieving an F1 score that is 10\% higher than the score on an adult out-of-domain dataset (CallHome).
Meta Auxiliary Learning for Low-resource Spoken Language Understanding
Jun 26, 2022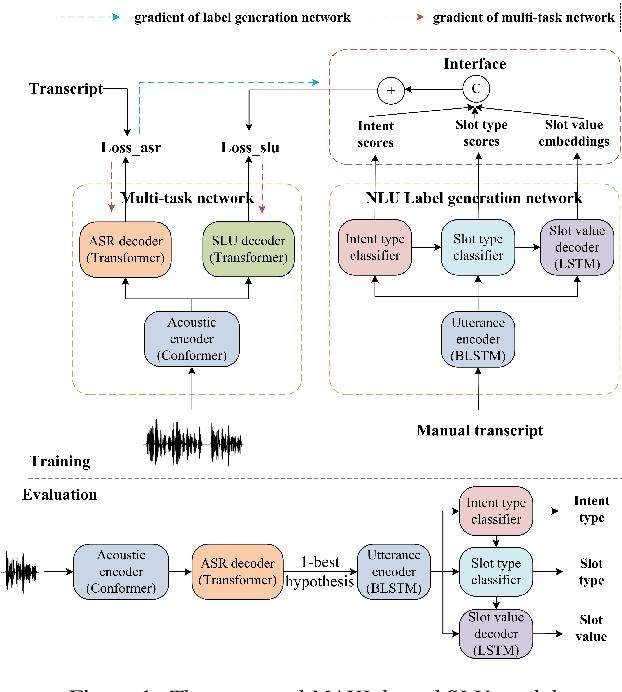

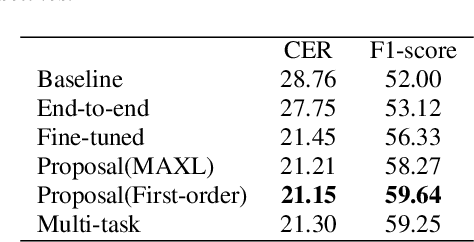

Spoken language understanding (SLU) treats automatic speech recognition (ASR) and natural language understanding (NLU) as a unified task and usually suffers from data scarcity. We exploit an ASR and NLU joint training method based on meta auxiliary learning to improve the performance of low-resource SLU task by only taking advantage of abundant manual transcriptions of speech data. One obvious advantage of such method is that it provides a flexible framework to implement a low-resource SLU training task without requiring access to any further semantic annotations. In particular, a NLU model is taken as label generation network to predict intent and slot tags from texts; a multi-task network trains ASR task and SLU task synchronously from speech; and the predictions of label generation network are delivered to the multi-task network as semantic targets. The efficiency of the proposed algorithm is demonstrated with experiments on the public CATSLU dataset, which produces more suitable ASR hypotheses for the downstream NLU task.
It's a long way! Layer-wise Relevance Propagation for Echo State Networks applied to Earth System Variability
Oct 18, 2022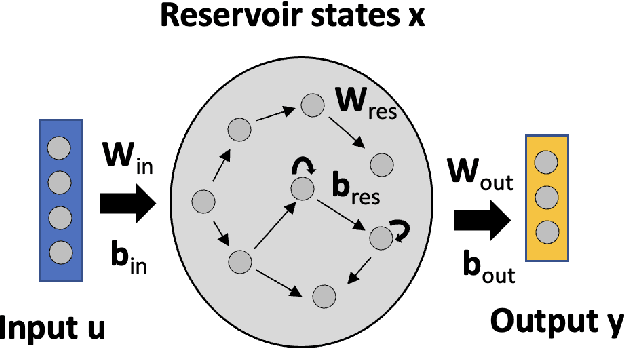
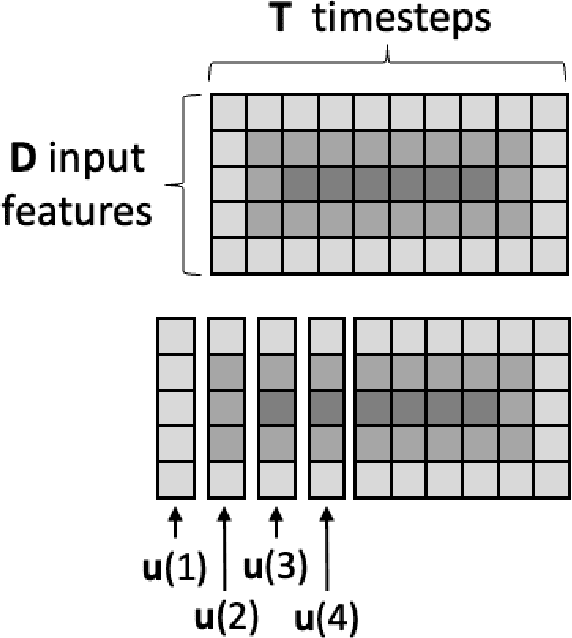
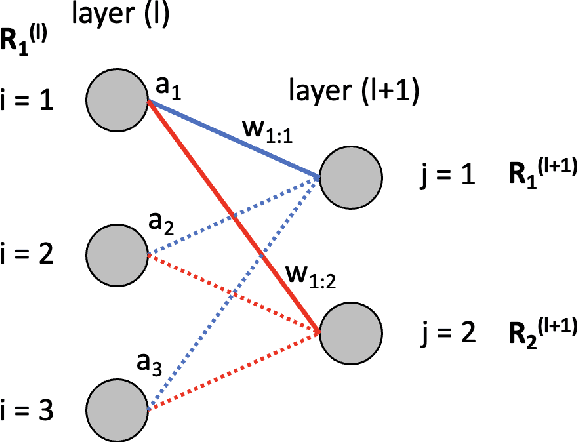
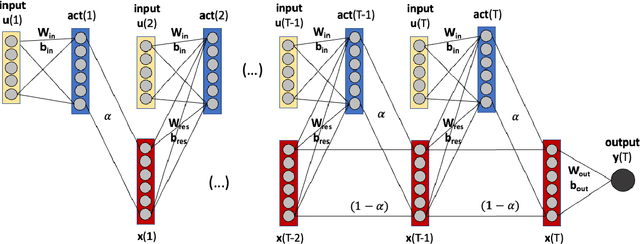
Artificial neural networks (ANNs) are known to be powerful methods for many hard problems (e.g. image classification, speech recognition or time series prediction). However, these models tend to produce black-box results and are often difficult to interpret. Layer-wise relevance propagation (LRP) is a widely used technique to understand how ANN models come to their conclusion and to understand what a model has learned. Here, we focus on Echo State Networks (ESNs) as a certain type of recurrent neural networks, also known as reservoir computing. ESNs are easy to train and only require a small number of trainable parameters, but are still black-box models. We show how LRP can be applied to ESNs in order to open the black-box. We also show how ESNs can be used not only for time series prediction but also for image classification: Our ESN model serves as a detector for El Nino Southern Oscillation (ENSO) from sea surface temperature anomalies. ENSO is actually a well-known problem and has been extensively discussed before. But here we use this simple problem to demonstrate how LRP can significantly enhance the explainablility of ESNs.
Multilingual Hate Speech and Offensive Content Detection using Modified Cross-entropy Loss
Feb 05, 2022
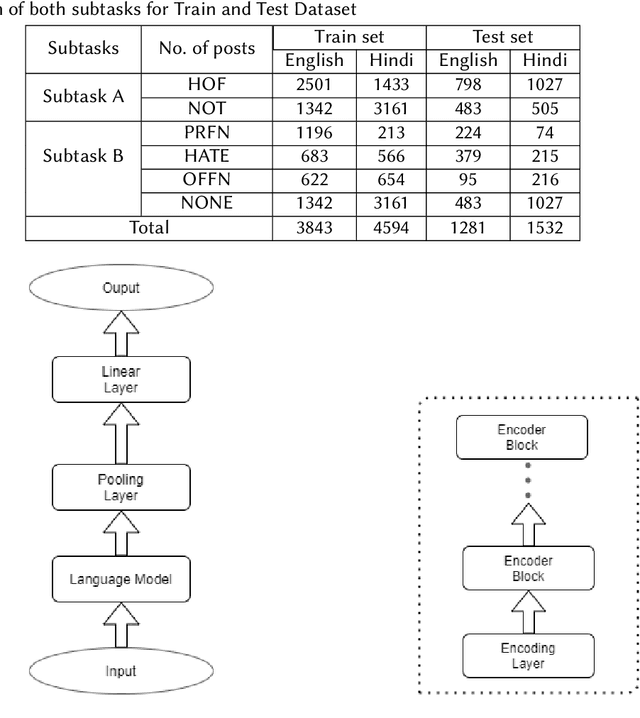
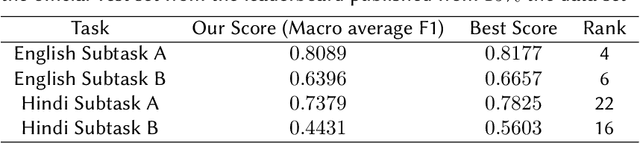
The number of increased social media users has led to a lot of people misusing these platforms to spread offensive content and use hate speech. Manual tracking the vast amount of posts is impractical so it is necessary to devise automated methods to identify them quickly. Large language models are trained on a lot of data and they also make use of contextual embeddings. We fine-tune the large language models to help in our task. The data is also quite unbalanced; so we used a modified cross-entropy loss to tackle the issue. We observed that using a model which is fine-tuned in hindi corpora performs better. Our team (HNLP) achieved the macro F1-scores of 0.808, 0.639 in English Subtask A and English Subtask B respectively. For Hindi Subtask A, Hindi Subtask B our team achieved macro F1-scores of 0.737, 0.443 respectively in HASOC 2021.