 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Review of end-to-end speech synthesis technology based on deep learning
Apr 20, 2021
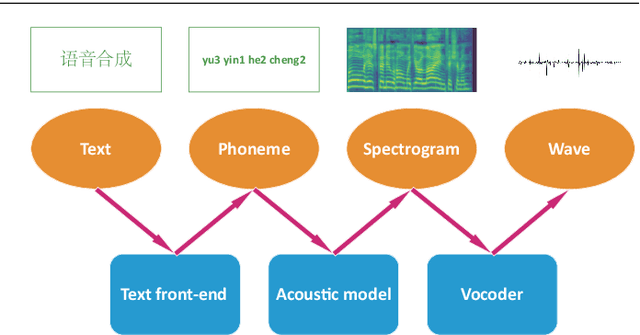
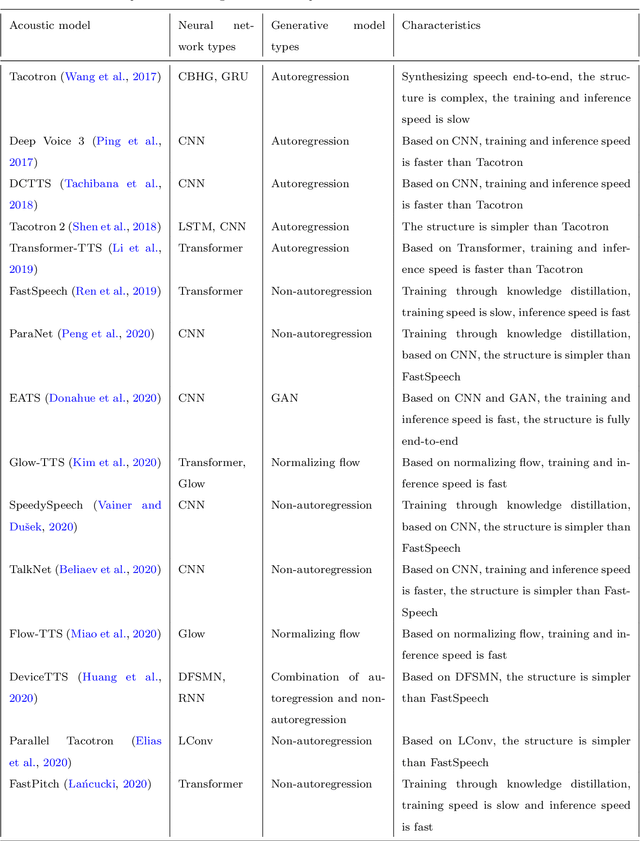
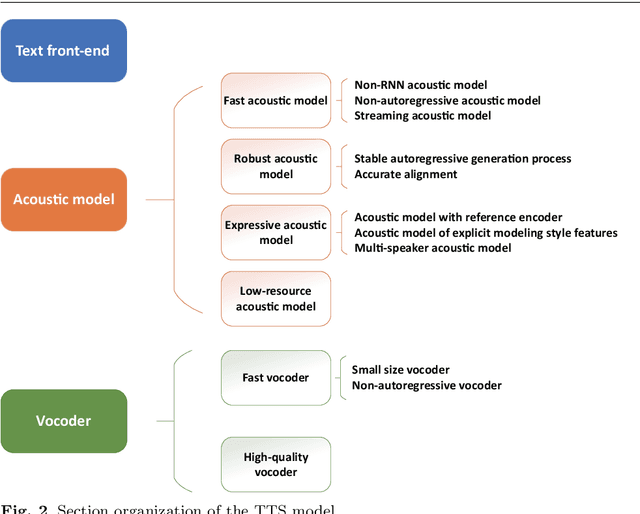
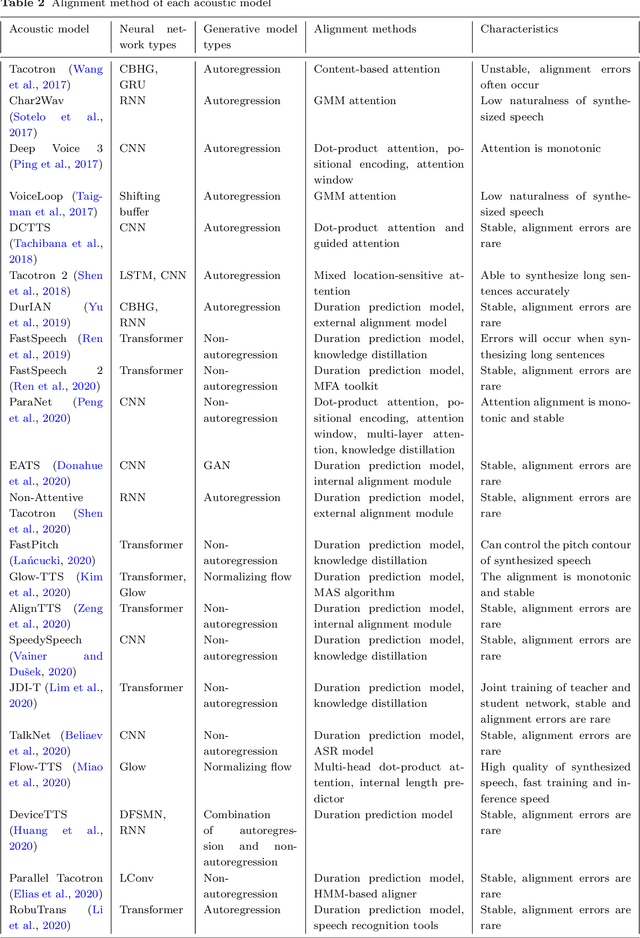
As an indispensable part of modern human-computer interaction system, speech synthesis technology helps users get the output of intelligent machine more easily and intuitively, thus has attracted more and more attention. Due to the limitations of high complexity and low efficiency of traditional speech synthesis technology, the current research focus is the deep learning-based end-to-end speech synthesis technology, which has more powerful modeling ability and a simpler pipeline. It mainly consists of three modules: text front-end, acoustic model, and vocoder. This paper reviews the research status of these three parts, and classifies and compares various methods according to their emphasis. Moreover, this paper also summarizes the open-source speech corpus of English, Chinese and other languages that can be used for speech synthesis tasks, and introduces some commonly used subjective and objective speech quality evaluation method. Finally, some attractive future research directions are pointed out.
Neural Sequence-to-Sequence Speech Synthesis Using a Hidden Semi-Markov Model Based Structured Attention Mechanism
Aug 31, 2021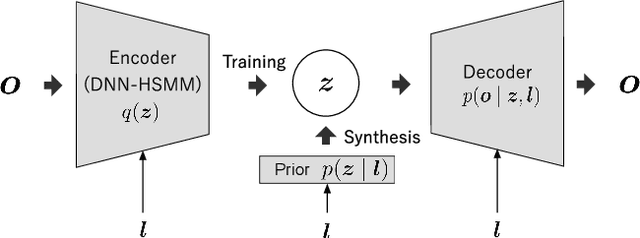
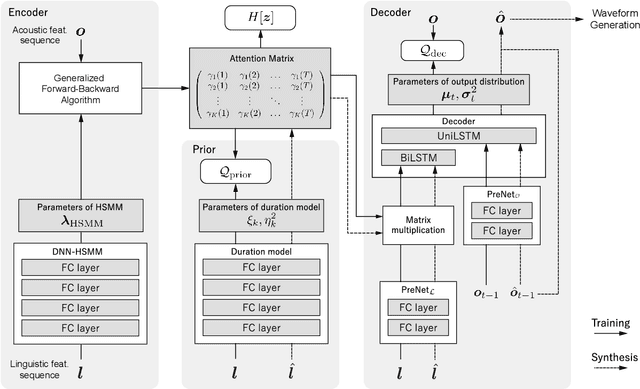
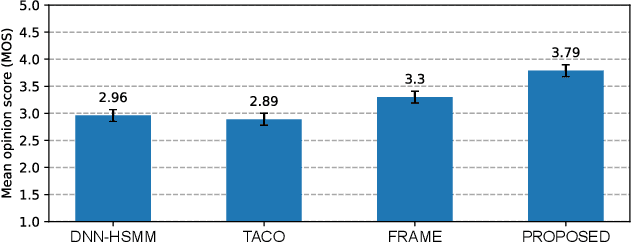
This paper proposes a novel Sequence-to-Sequence (Seq2Seq) model integrating the structure of Hidden Semi-Markov Models (HSMMs) into its attention mechanism. In speech synthesis, it has been shown that methods based on Seq2Seq models using deep neural networks can synthesize high quality speech under the appropriate conditions. However, several essential problems still have remained, i.e., requiring large amounts of training data due to an excessive degree for freedom in alignment (mapping function between two sequences), and the difficulty in handling duration due to the lack of explicit duration modeling. The proposed method defines a generative models to realize the simultaneous optimization of alignments and model parameters based on the Variational Auto-Encoder (VAE) framework, and provides monotonic alignments and explicit duration modeling based on the structure of HSMM. The proposed method can be regarded as an integration of Hidden Markov Model (HMM) based speech synthesis and deep learning based speech synthesis using Seq2Seq models, incorporating both the benefits. Subjective evaluation experiments showed that the proposed method obtained higher mean opinion scores than Tacotron 2 on relatively small amount of training data.
Can We Trust Deep Speech Prior?
Nov 04, 2020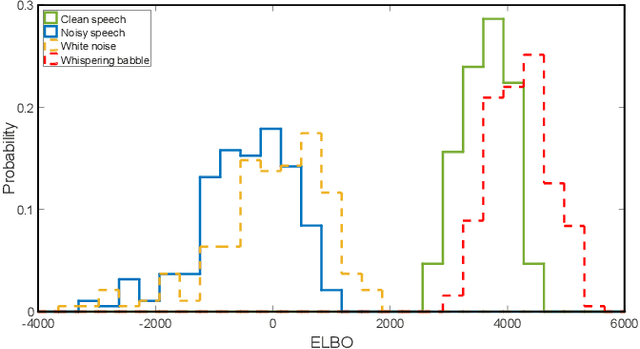
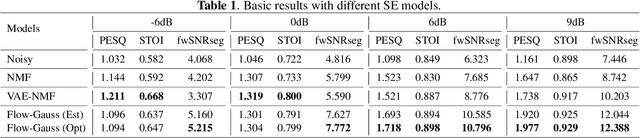
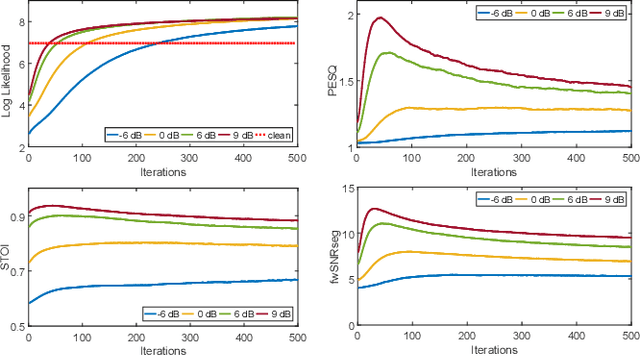
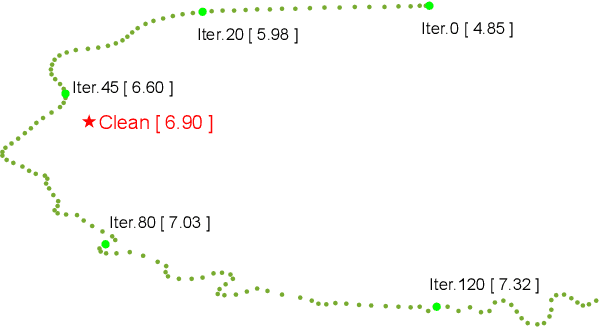
Recently, speech enhancement (SE) based on deep speech prior has attracted much attention, such as the variational auto-encoder with non-negative matrix factorization (VAE-NMF) architecture. Compared to conventional approaches that represent clean speech by shallow models such as Gaussians with a low-rank covariance, the new approach employs deep generative models to represent the clean speech, which often provides a better prior. Despite the clear advantage in theory, we argue that deep priors must be used with much caution, since the likelihood produced by a deep generative model does not always coincide with the speech quality. We designed a comprehensive study on this issue and demonstrated that based on deep speech priors, a reasonable SE performance can be achieved, but the results might be suboptimal. A careful analysis showed that this problem is deeply rooted in the disharmony between the flexibility of deep generative models and the nature of the maximum-likelihood (ML) training.
Mega: Moving Average Equipped Gated Attention
Sep 26, 2022
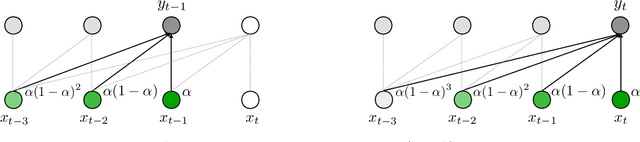
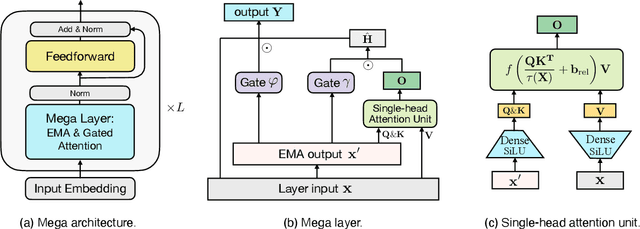
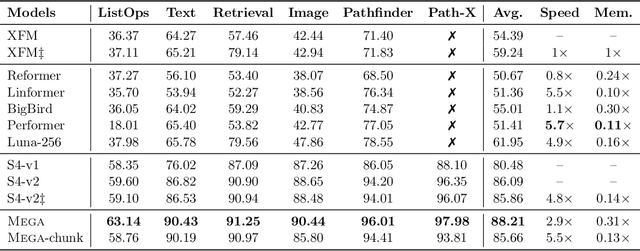
The design choices in the Transformer attention mechanism, including weak inductive bias and quadratic computational complexity, have limited its application for modeling long sequences. In this paper, we introduce Mega, a simple, theoretically grounded, single-head gated attention mechanism equipped with (exponential) moving average to incorporate inductive bias of position-aware local dependencies into the position-agnostic attention mechanism. We further propose a variant of Mega that offers linear time and space complexity yet yields only minimal quality loss, by efficiently splitting the whole sequence into multiple chunks with fixed length. Extensive experiments on a wide range of sequence modeling benchmarks, including the Long Range Arena, neural machine translation, auto-regressive language modeling, and image and speech classification, show that Mega achieves significant improvements over other sequence models, including variants of Transformers and recent state space models.
Automatic Speech Recognition in Sanskrit: A New Speech Corpus and Modelling Insights
Jun 02, 2021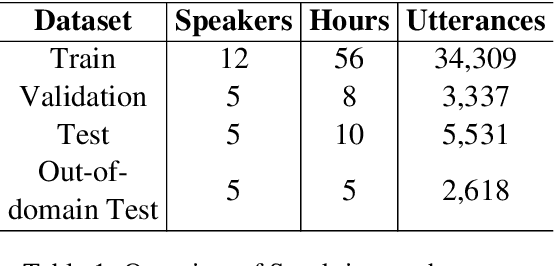
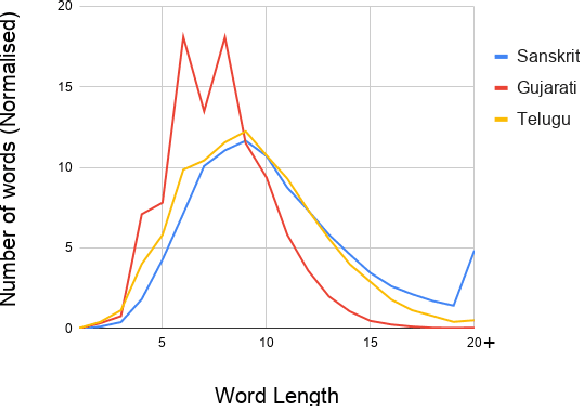
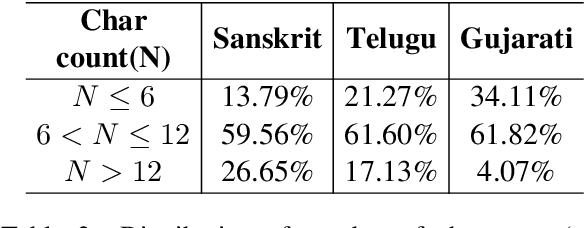

Automatic speech recognition (ASR) in Sanskrit is interesting, owing to the various linguistic peculiarities present in the language. The Sanskrit language is lexically productive, undergoes euphonic assimilation of phones at the word boundaries and exhibits variations in spelling conventions and in pronunciations. In this work, we propose the first large scale study of automatic speech recognition (ASR) in Sanskrit, with an emphasis on the impact of unit selection in Sanskrit ASR. In this work, we release a 78 hour ASR dataset for Sanskrit, which faithfully captures several of the linguistic characteristics expressed by the language. We investigate the role of different acoustic model and language model units in ASR systems for Sanskrit. We also propose a new modelling unit, inspired by the syllable level unit selection, that captures character sequences from one vowel in the word to the next vowel. We also highlight the importance of choosing graphemic representations for Sanskrit and show the impact of this choice on word error rates (WER). Finally, we extend these insights from Sanskrit ASR for building ASR systems in two other Indic languages, Gujarati and Telugu. For both these languages, our experimental results show that the use of phonetic based graphemic representations in ASR results in performance improvements as compared to ASR systems that use native scripts.
Language-Independent Approach for Automatic Computation of Vowel Articulation Features in Dysarthric Speech Assessment
Aug 17, 2021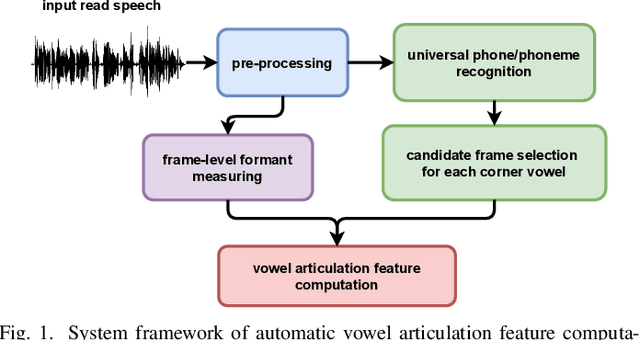
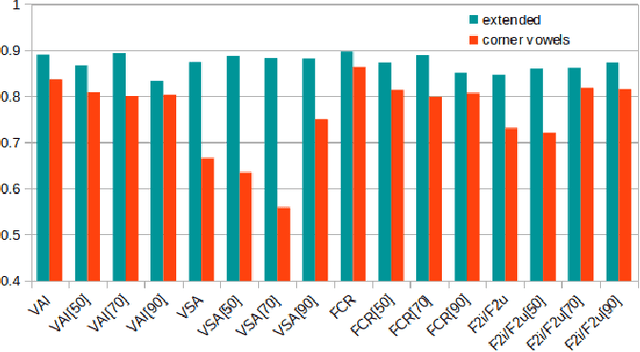
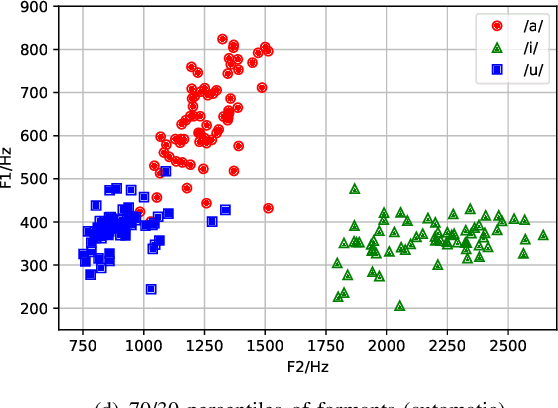
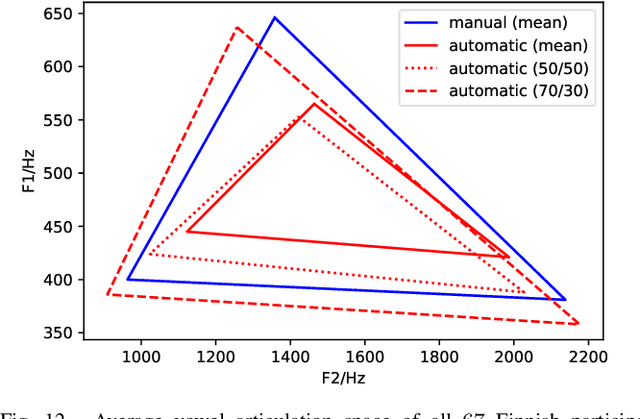
Imprecise vowel articulation can be observed in people with Parkinson's disease (PD). Acoustic features measuring vowel articulation have been demonstrated to be effective indicators of PD in its assessment. Standard clinical vowel articulation features of vowel working space area (VSA), vowel articulation index (VAI) and formants centralization ratio (FCR), are derived the first two formants of the three corner vowels /a/, /i/ and /u/. Conventionally, manual annotation of the corner vowels from speech data is required before measuring vowel articulation. This process is time-consuming. The present work aims to reduce human effort in clinical analysis of PD speech by proposing an automatic pipeline for vowel articulation assessment. The method is based on automatic corner vowel detection using a language universal phoneme recognizer, followed by statistical analysis of the formant data. The approach removes the restrictions of prior knowledge of speaking content and the language in question. Experimental results on a Finnish PD speech corpus demonstrate the efficacy and reliability of the proposed automatic method in deriving VAI, VSA, FCR and F2i/F2u (the second formant ratio for vowels /i/ and /u/). The automatically computed parameters are shown to be highly correlated with features computed with manual annotations of corner vowels. In addition, automatically and manually computed vowel articulation features have comparable correlations with experts' ratings on speech intelligibility, voice impairment and overall severity of communication disorder. Language-independence of the proposed approach is further validated on a Spanish PD database, PC-GITA, as well as on TORGO corpus of English dysarthric speech.
* 16 pages
3M: An Effective Multi-view, Multi-granularity, and Multi-aspect Modeling Approach to English Pronunciation Assessment
Aug 19, 2022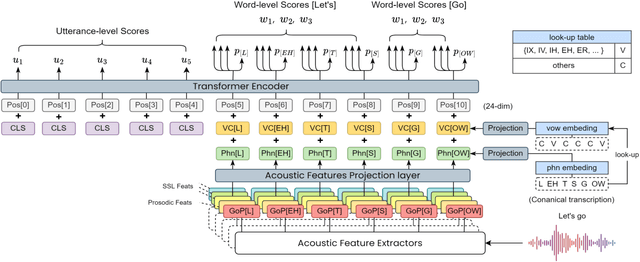
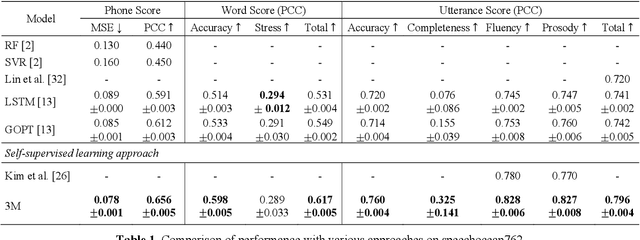
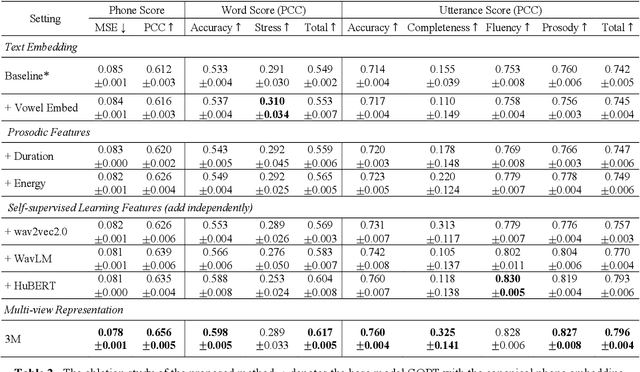
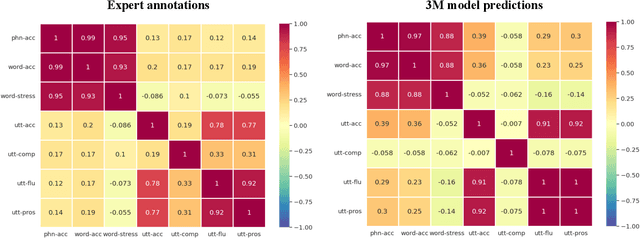
As an indispensable ingredient of computer-assisted pronunciation training (CAPT), automatic pronunciation assessment (APA) plays a pivotal role in aiding self-directed language learners by providing multi-aspect and timely feedback. However, there are at least two potential obstacles that might hinder its performance for practical use. On one hand, most of the studies focus exclusively on leveraging segmental (phonetic)-level features such as goodness of pronunciation (GOP); this, however, may cause a discrepancy of feature granularity when performing suprasegmental (prosodic)-level pronunciation assessment. On the other hand, automatic pronunciation assessments still suffer from the lack of large-scale labeled speech data of non-native speakers, which inevitably limits the performance of pronunciation assessment. In this paper, we tackle these problems by integrating multiple prosodic and phonological features to provide a multi-view, multi-granularity, and multi-aspect (3M) pronunciation modeling. Specifically, we augment GOP with prosodic and self-supervised learning (SSL) features, and meanwhile develop a vowel/consonant positional embedding for a more phonology-aware automatic pronunciation assessment. A series of experiments conducted on the publicly-available speechocean762 dataset show that our approach can obtain significant improvements on several assessment granularities in comparison with previous work, especially on the assessment of speaking fluency and speech prosody.
Defense against Adversarial Attacks on Hybrid Speech Recognition using Joint Adversarial Fine-tuning with Denoiser
Apr 08, 2022
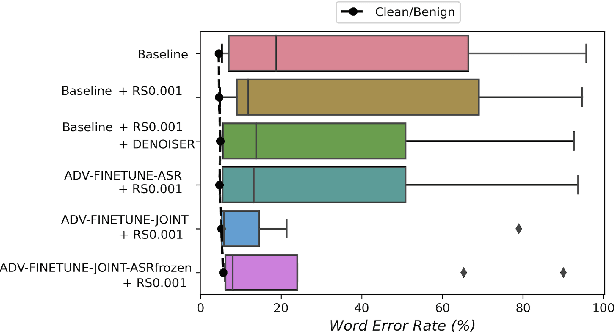

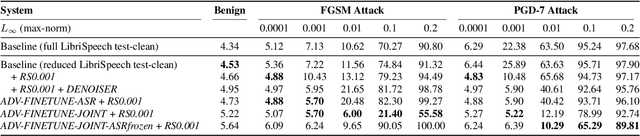
Adversarial attacks are a threat to automatic speech recognition (ASR) systems, and it becomes imperative to propose defenses to protect them. In this paper, we perform experiments to show that K2 conformer hybrid ASR is strongly affected by white-box adversarial attacks. We propose three defenses--denoiser pre-processor, adversarially fine-tuning ASR model, and adversarially fine-tuning joint model of ASR and denoiser. Our evaluation shows denoiser pre-processor (trained on offline adversarial examples) fails to defend against adaptive white-box attacks. However, adversarially fine-tuning the denoiser using a tandem model of denoiser and ASR offers more robustness. We evaluate two variants of this defense--one updating parameters of both models and the second keeping ASR frozen. The joint model offers a mean absolute decrease of 19.3\% ground truth (GT) WER with reference to baseline against fast gradient sign method (FGSM) attacks with different $L_\infty$ norms. The joint model with frozen ASR parameters gives the best defense against projected gradient descent (PGD) with 7 iterations, yielding a mean absolute increase of 22.3\% GT WER with reference to baseline; and against PGD with 500 iterations, yielding a mean absolute decrease of 45.08\% GT WER and an increase of 68.05\% adversarial target WER.
Digital Voicing of Silent Speech
Oct 06, 2020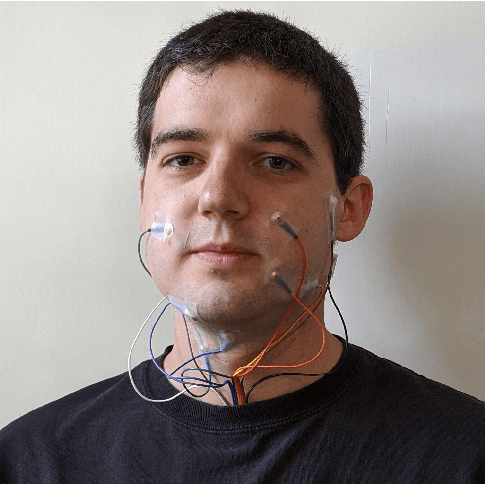

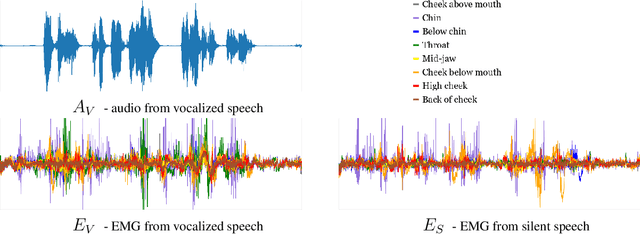

In this paper, we consider the task of digitally voicing silent speech, where silently mouthed words are converted to audible speech based on electromyography (EMG) sensor measurements that capture muscle impulses. While prior work has focused on training speech synthesis models from EMG collected during vocalized speech, we are the first to train from EMG collected during silently articulated speech. We introduce a method of training on silent EMG by transferring audio targets from vocalized to silent signals. Our method greatly improves intelligibility of audio generated from silent EMG compared to a baseline that only trains with vocalized data, decreasing transcription word error rate from 64% to 4% in one data condition and 88% to 68% in another. To spur further development on this task, we share our new dataset of silent and vocalized facial EMG measurements.