 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Learning Phone Recognition from Unpaired Audio and Phone Sequences Based on Generative Adversarial Network
Jul 29, 2022
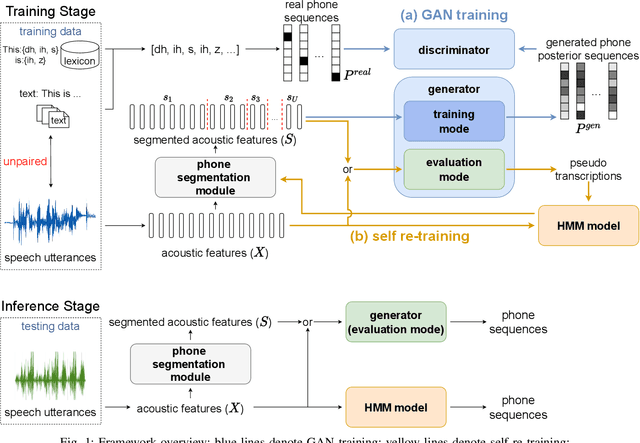
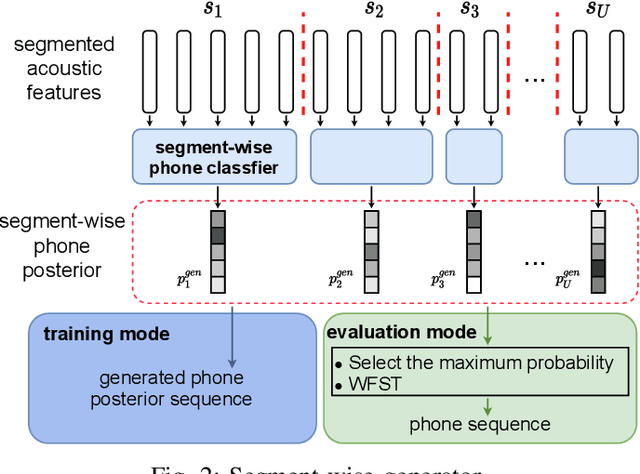
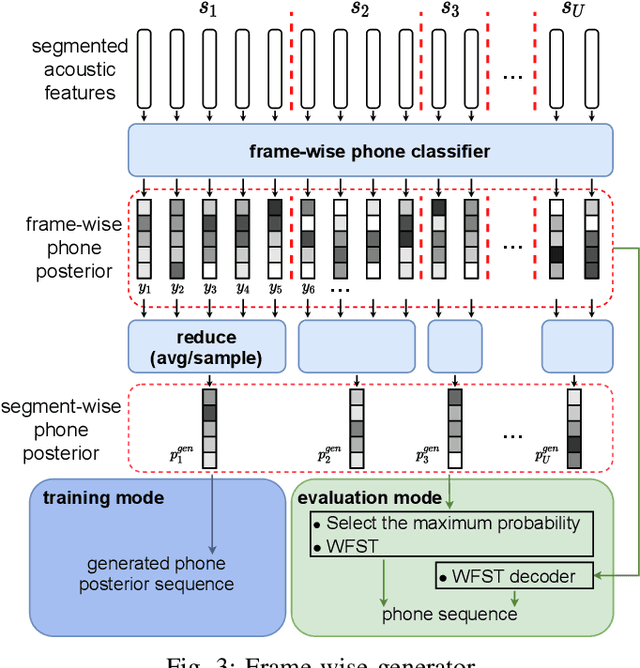
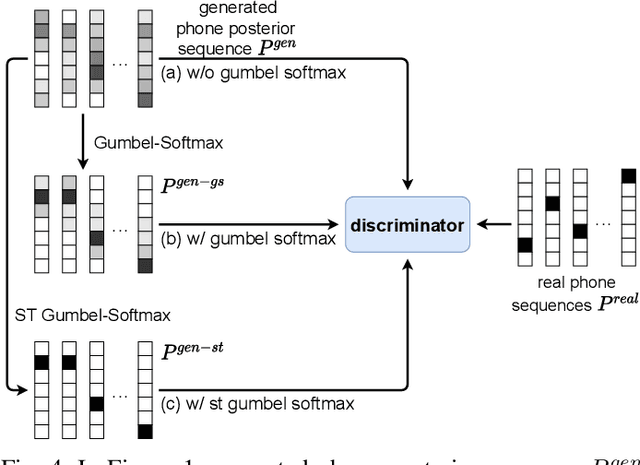
ASR has been shown to achieve great performance recently. However, most of them rely on massive paired data, which is not feasible for low-resource languages worldwide. This paper investigates how to learn directly from unpaired phone sequences and speech utterances. We design a two-stage iterative framework. GAN training is adopted in the first stage to find the mapping relationship between unpaired speech and phone sequence. In the second stage, another HMM model is introduced to train from the generator's output, which boosts the performance and provides a better segmentation for the next iteration. In the experiment, we first investigate different choices of model designs. Then we compare the framework to different types of baselines: (i) supervised methods (ii) acoustic unit discovery based methods (iii) methods learning from unpaired data. Our framework performs consistently better than all acoustic unit discovery methods and previous methods learning from unpaired data based on the TIMIT dataset.
Reducing Target Group Bias in Hate Speech Detectors
Dec 07, 2021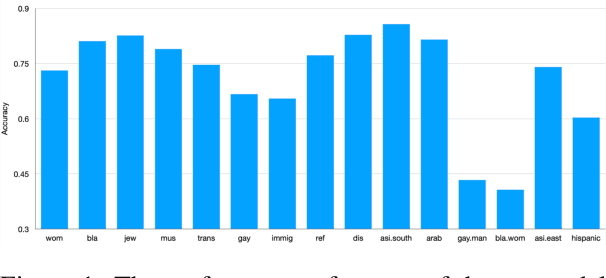
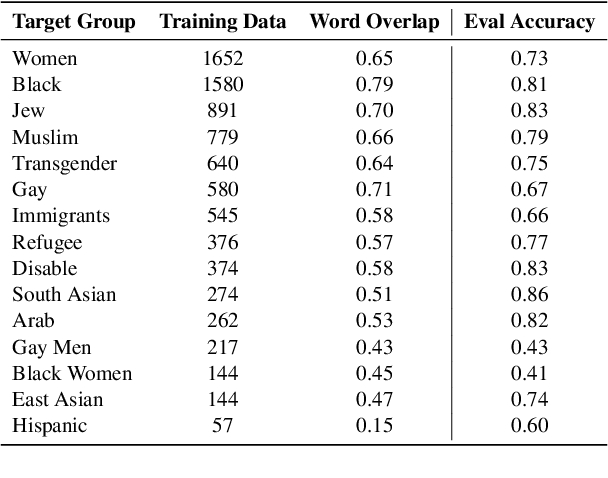
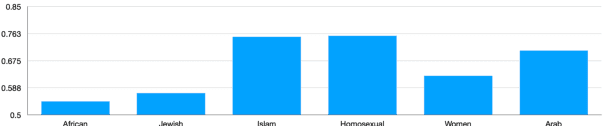
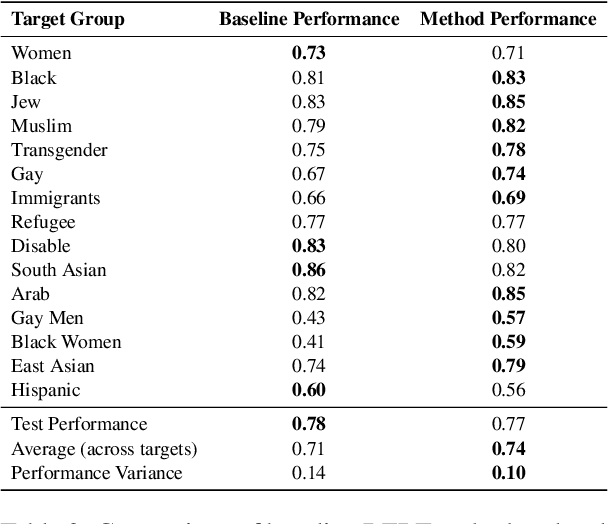
The ubiquity of offensive and hateful content on online fora necessitates the need for automatic solutions that detect such content competently across target groups. In this paper we show that text classification models trained on large publicly available datasets despite having a high overall performance, may significantly under-perform on several protected groups. On the \citet{vidgen2020learning} dataset, we find the accuracy to be 37\% lower on an under annotated Black Women target group and 12\% lower on Immigrants, where hate speech involves a distinct style. To address this, we propose to perform token-level hate sense disambiguation, and utilize tokens' hate sense representations for detection, modeling more general signals. On two publicly available datasets, we observe that the variance in model accuracy across target groups drops by at least 30\%, improving the average target group performance by 4\% and worst case performance by 13\%.
Unsupervised low-rank representations for speech emotion recognition
Apr 14, 2021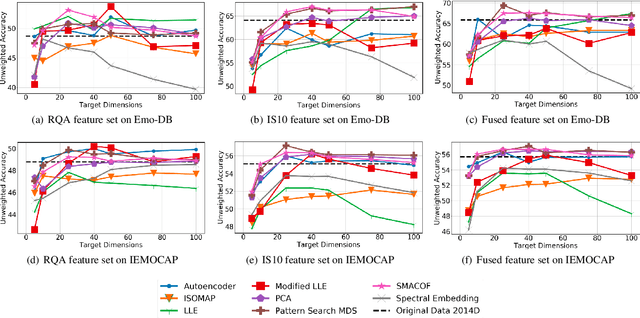
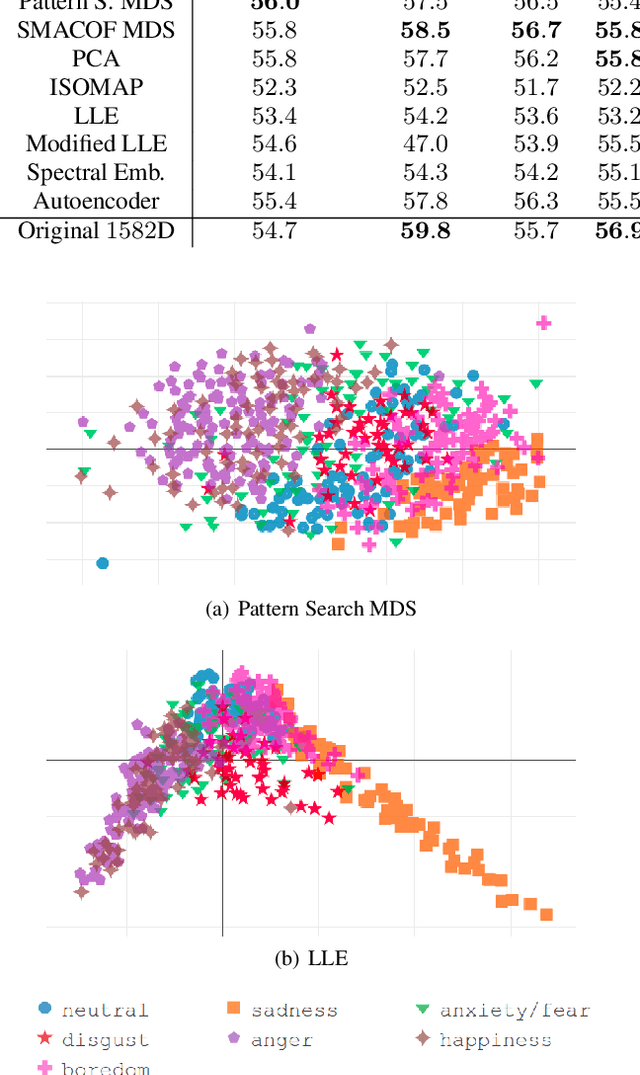
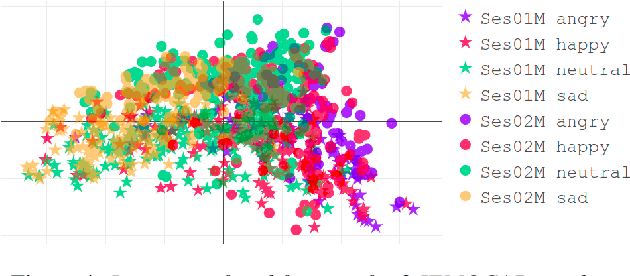
We examine the use of linear and non-linear dimensionality reduction algorithms for extracting low-rank feature representations for speech emotion recognition. Two feature sets are used, one based on low-level descriptors and their aggregations (IS10) and one modeling recurrence dynamics of speech (RQA), as well as their fusion. We report speech emotion recognition (SER) results for learned representations on two databases using different classification methods. Classification with low-dimensional representations yields performance improvement in a variety of settings. This indicates that dimensionality reduction is an effective way to combat the curse of dimensionality for SER. Visualization of features in two dimensions provides insight into discriminatory abilities of reduced feature sets.
An Improved Model for Voicing Silent Speech
Jun 03, 2021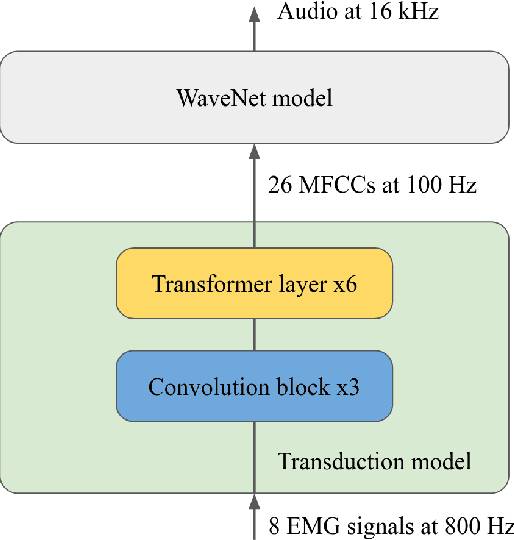

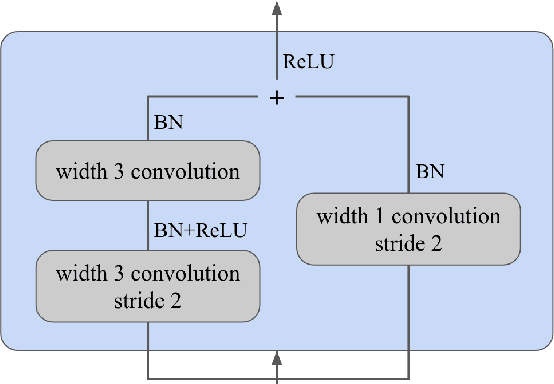
In this paper, we present an improved model for voicing silent speech, where audio is synthesized from facial electromyography (EMG) signals. To give our model greater flexibility to learn its own input features, we directly use EMG signals as input in the place of hand-designed features used by prior work. Our model uses convolutional layers to extract features from the signals and Transformer layers to propagate information across longer distances. To provide better signal for learning, we also introduce an auxiliary task of predicting phoneme labels in addition to predicting speech audio features. On an open vocabulary intelligibility evaluation, our model improves the state of the art for this task by an absolute 25.8%.
Codes, Patterns and Shapes of Contemporary Online Antisemitism and Conspiracy Narratives -- an Annotation Guide and Labeled German-Language Dataset in the Context of COVID-19
Oct 13, 2022
Over the course of the COVID-19 pandemic, existing conspiracy theories were refreshed and new ones were created, often interwoven with antisemitic narratives, stereotypes and codes. The sheer volume of antisemitic and conspiracy theory content on the Internet makes data-driven algorithmic approaches essential for anti-discrimination organizations and researchers alike. However, the manifestation and dissemination of these two interrelated phenomena is still quite under-researched in scholarly empirical research of large text corpora. Algorithmic approaches for the detection and classification of specific contents usually require labeled datasets, annotated based on conceptually sound guidelines. While there is a growing number of datasets for the more general phenomenon of hate speech, the development of corpora and annotation guidelines for antisemitic and conspiracy content is still in its infancy, especially for languages other than English. We contribute to closing this gap by developing an annotation guide for antisemitic and conspiracy theory online content in the context of the COVID-19 pandemic. We provide working definitions, including specific forms of antisemitism such as encoded and post-Holocaust antisemitism. We use these to annotate a German-language dataset consisting of ~3,700 Telegram messages sent between 03/2020 and 12/2021.
Incorporating Multi-Target in Multi-Stage Speech Enhancement Model for Better Generalization
Jul 09, 2021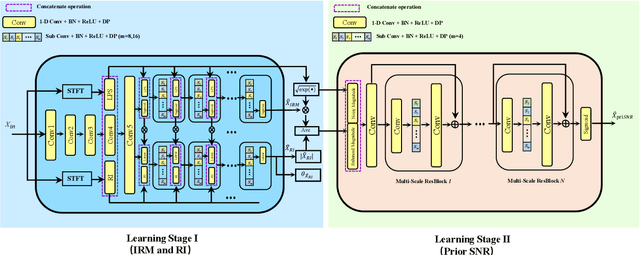
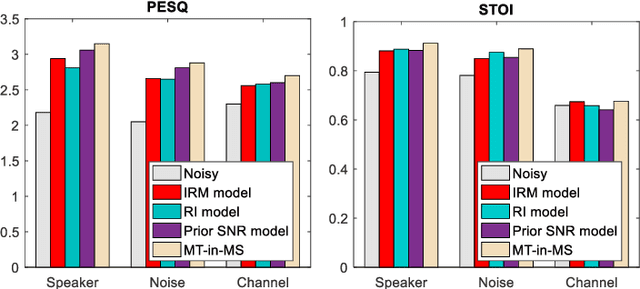
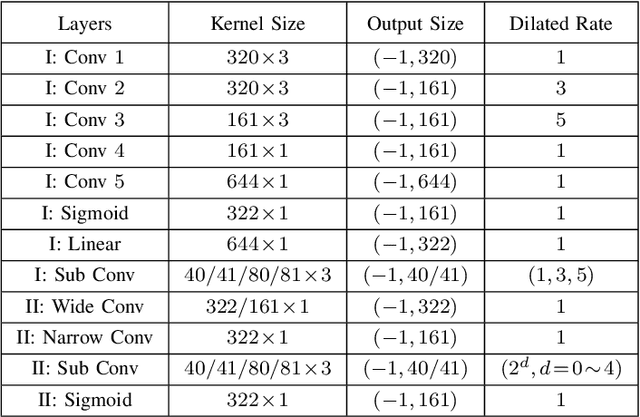
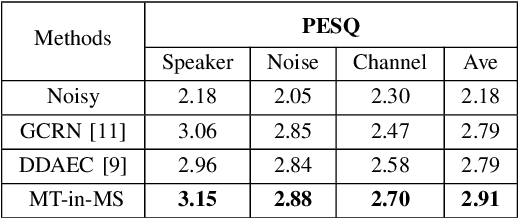
Recent single-channel speech enhancement methods based on deep neural networks (DNNs) have achieved remarkable results, but there are still generalization problems in real scenes. Like other data-driven methods, DNN-based speech enhancement models produce significant performance degradation on untrained data. In this study, we make full use of the contribution of multi-target joint learning to the model generalization capability, and propose a lightweight and low-computing dilated convolutional network (DCN) model for a more robust speech denoising task. Our goal is to integrate the masking target, the mapping target, and the parameters of the traditional speech enhancement estimator into a DCN model to maximize their complementary advantages. To do this, we build a multi-stage learning framework to deal with multiple targets in stages to achieve their joint learning, namely `MT-in-MS'. Our experimental results show that compared with the state-of-the-art time domain and time-frequency domain models, this proposed low-cost DCN model can achieve better generalization performance in speaker, noise, and channel mismatch cases.
KeypartX: Graph-based Perception (Text) Representation
Sep 23, 2022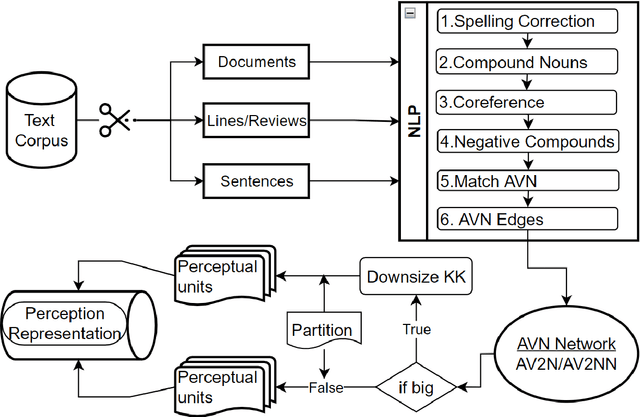

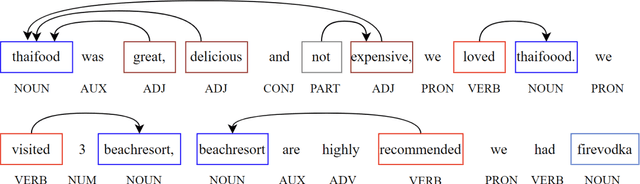
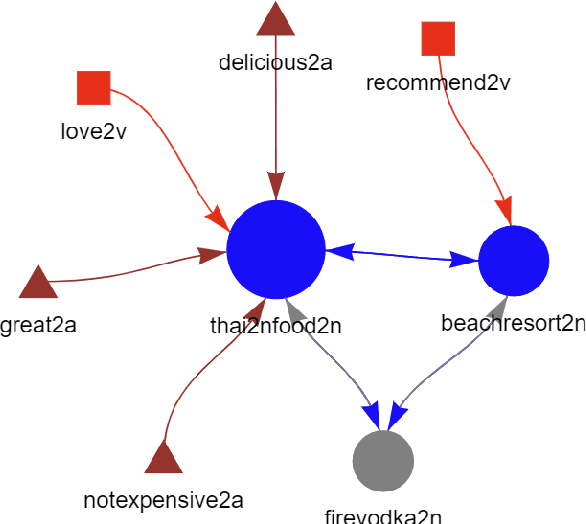
The availability of big data has opened up big opportunities for individuals, businesses and academics to view big into what is happening in their world. Previous works of text representation mostly focused on informativeness from massive words' frequency or cooccurrence. However, big data is a double-edged sword which is big in volume but unstructured in format. The unstructured edge requires specific techniques to transform 'big' into meaningful instead of informative alone. This study presents KeypartX, a graph-based approach to represent perception (text in general) by key parts of speech. Different from bag-of-words/vector-based machine learning, this technique is human-like learning that could extracts meanings from linguistic (semantic, syntactic and pragmatic) information. Moreover, KeypartX is big-data capable but not hungry, which is even applicable to the minimum unit of text:sentence.
Defense against Adversarial Attacks on Hybrid Speech Recognition using Joint Adversarial Fine-tuning with Denoiser
Apr 08, 2022
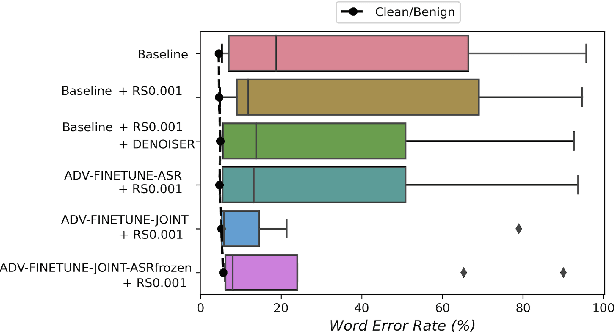

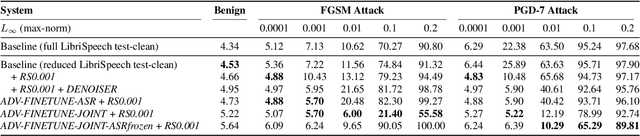
Adversarial attacks are a threat to automatic speech recognition (ASR) systems, and it becomes imperative to propose defenses to protect them. In this paper, we perform experiments to show that K2 conformer hybrid ASR is strongly affected by white-box adversarial attacks. We propose three defenses--denoiser pre-processor, adversarially fine-tuning ASR model, and adversarially fine-tuning joint model of ASR and denoiser. Our evaluation shows denoiser pre-processor (trained on offline adversarial examples) fails to defend against adaptive white-box attacks. However, adversarially fine-tuning the denoiser using a tandem model of denoiser and ASR offers more robustness. We evaluate two variants of this defense--one updating parameters of both models and the second keeping ASR frozen. The joint model offers a mean absolute decrease of 19.3\% ground truth (GT) WER with reference to baseline against fast gradient sign method (FGSM) attacks with different $L_\infty$ norms. The joint model with frozen ASR parameters gives the best defense against projected gradient descent (PGD) with 7 iterations, yielding a mean absolute increase of 22.3\% GT WER with reference to baseline; and against PGD with 500 iterations, yielding a mean absolute decrease of 45.08\% GT WER and an increase of 68.05\% adversarial target WER.
Speech Enhancement by Noise Self-Supervised Rank-Constrained Spatial Covariance Matrix Estimation via Independent Deeply Learned Matrix Analysis
Sep 10, 2021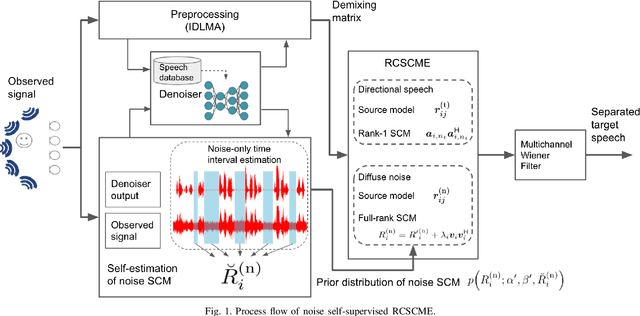
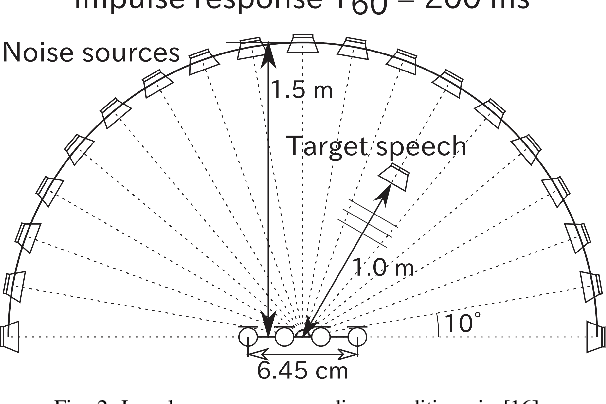
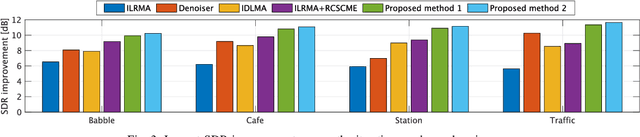
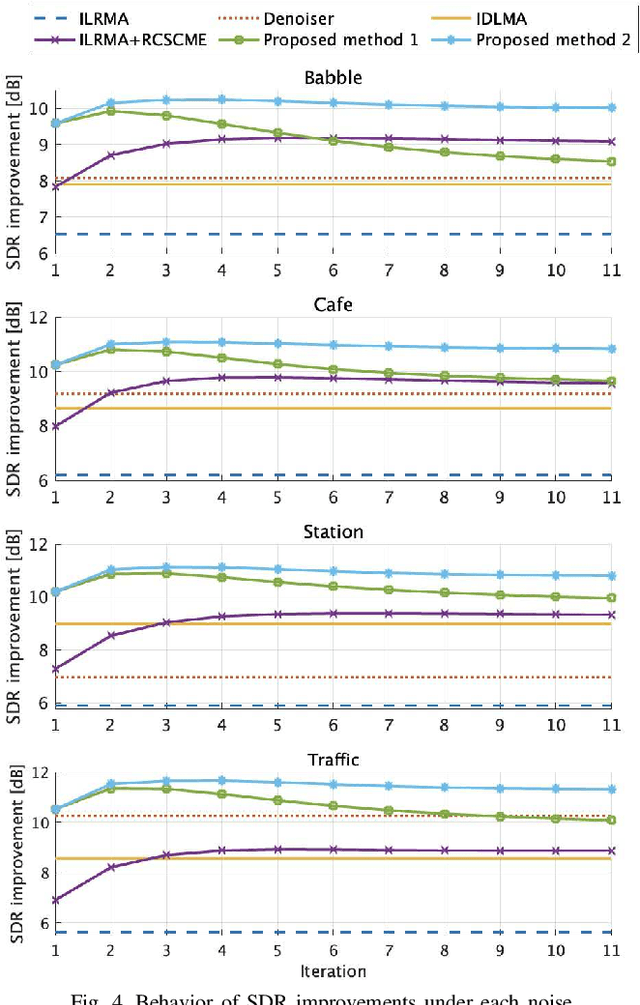
Rank-constrained spatial covariance matrix estimation (RCSCME) is a method for the situation that the directional target speech and the diffuse noise are mixed. In conventional RCSCME, independent low-rank matrix analysis (ILRMA) is used as the preprocessing method. We propose RCSCME using independent deeply learned matrix analysis (IDLMA), which is a supervised extension of ILRMA. In this method, IDLMA requires deep neural networks (DNNs) to separate the target speech and the noise. We use Denoiser, which is a single-channel speech enhancement DNN, in IDLMA to estimate not only the target speech but also the noise. We also propose noise self-supervised RCSCME, in which we estimate the noise-only time intervals using the output of Denoiser and design the prior distribution of the noise spatial covariance matrix for RCSCME. We confirm that the proposed methods outperform the conventional methods under several noise conditions.
Does a PESQNet (Loss) Require a Clean Reference Input? The Original PESQ Does, But ACR Listening Tests Don't
May 13, 2022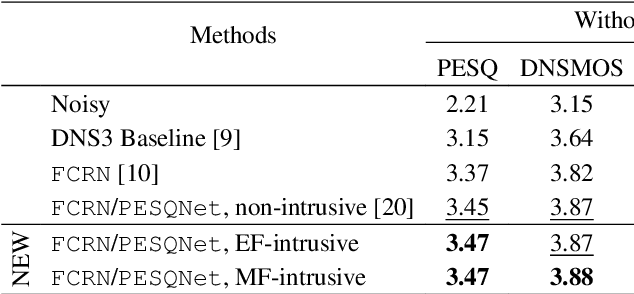
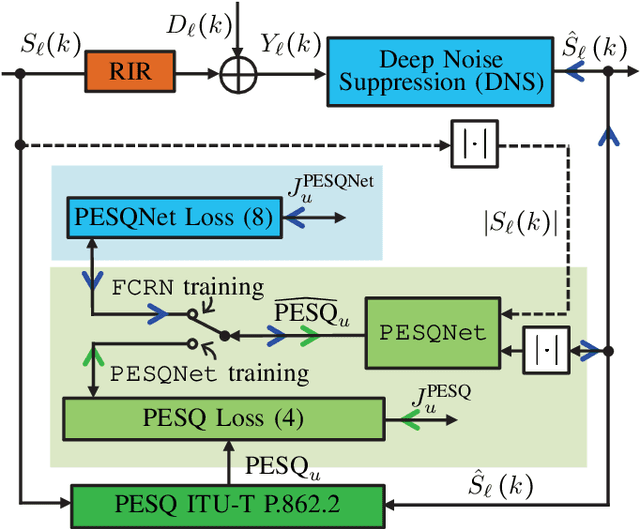
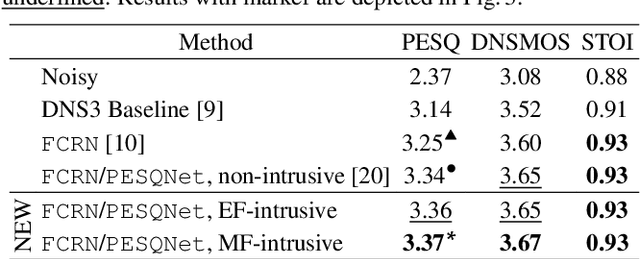
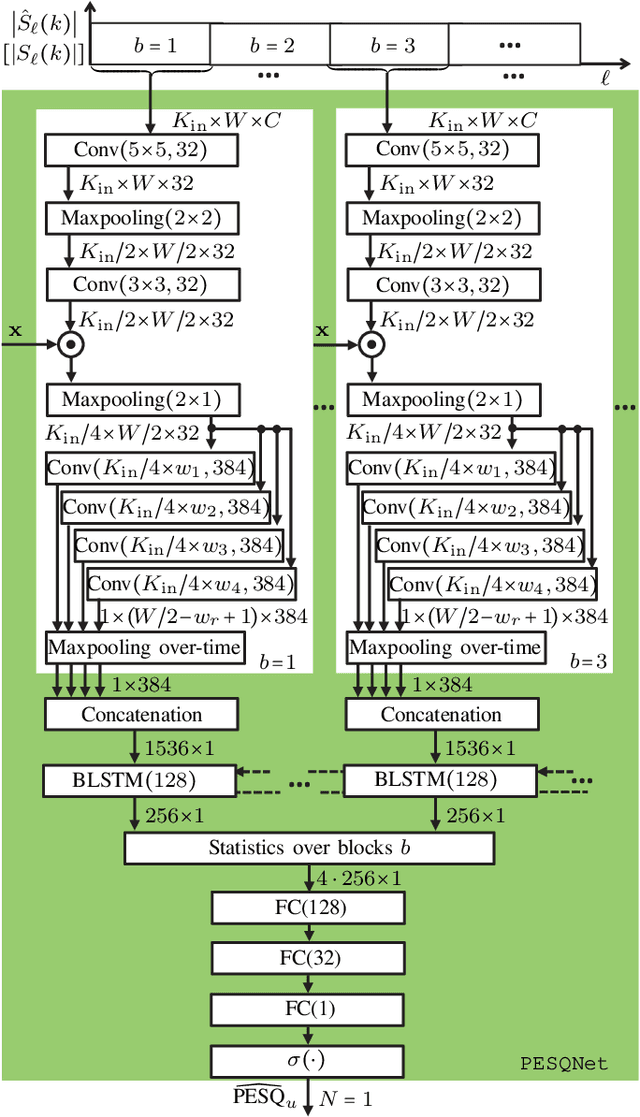
Perceptual evaluation of speech quality (PESQ) requires a clean speech reference as input, but predicts the results from (reference-free) absolute category rating (ACR) tests. In this work, we train a fully convolutional recurrent neural network (FCRN) as deep noise suppression (DNS) model, with either a non-intrusive or an intrusive PESQNet, where only the latter has access to a clean speech reference. The PESQNet is used as a mediator providing a perceptual loss during the DNS training to maximize the PESQ score of the enhanced speech signal. For the intrusive PESQNet, we investigate two topologies, called early-fusion (EF) and middle-fusion (MF) PESQNet, and compare to the non-intrusive PESQNet to evaluate and to quantify the benefits of employing a clean speech reference input during DNS training. Detailed analyses show that the DNS trained with the MF-intrusive PESQNet outperforms the Interspeech 2021 DNS Challenge baseline and the same DNS trained with an MSE loss by 0.23 and 0.12 PESQ points, respectively. Furthermore, we can show that only marginal benefits are obtained compared to the DNS trained with the non-intrusive PESQNet. Therefore, as ACR listening tests, the PESQNet does not necessarily require a clean speech reference input, opening the possibility of using real data for DNS training.