 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SCaLa: Supervised Contrastive Learning for End-to-End Automatic Speech Recognition
Oct 08, 2021
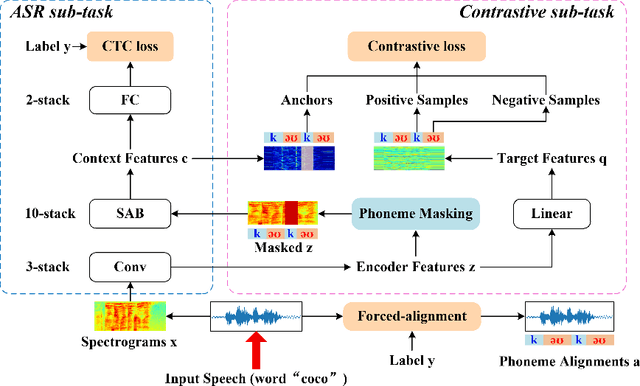
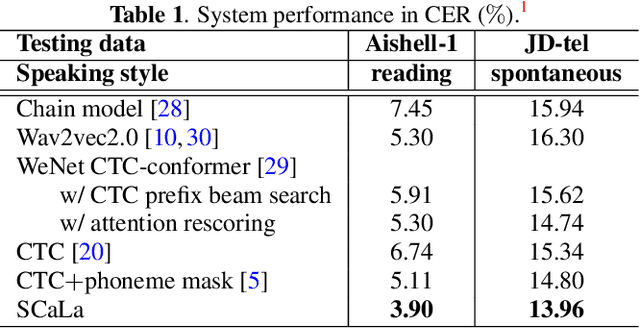
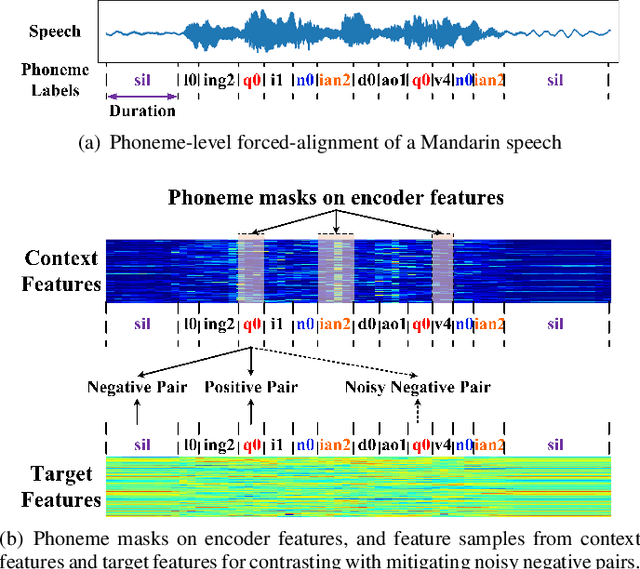
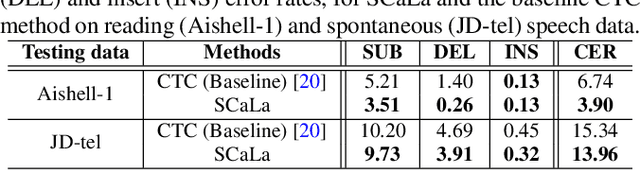
End-to-end Automatic Speech Recognition (ASR) models are usually trained to reduce the losses of the whole token sequences, while neglecting explicit phonemic-granularity supervision. This could lead to recognition errors due to similar-phoneme confusion or phoneme reduction. To alleviate this problem, this paper proposes a novel framework of Supervised Contrastive Learning (SCaLa) to enhance phonemic information learning for end-to-end ASR systems. Specifically, we introduce the self-supervised Masked Contrastive Predictive Coding (MCPC) into the fully-supervised setting. To supervise phoneme learning explicitly, SCaLa first masks the variable-length encoder features corresponding to phonemes given phoneme forced-alignment extracted from a pre-trained acoustic model, and then predicts the masked phonemes via contrastive learning. The phoneme forced-alignment can mitigate the noise of positive-negative pairs in self-supervised MCPC. Experimental results conducted on reading and spontaneous speech datasets show that the proposed approach achieves 2.84% and 1.38% Character Error Rate (CER) reductions compared to the baseline, respectively.
VQTTS: High-Fidelity Text-to-Speech Synthesis with Self-Supervised VQ Acoustic Feature
Apr 02, 2022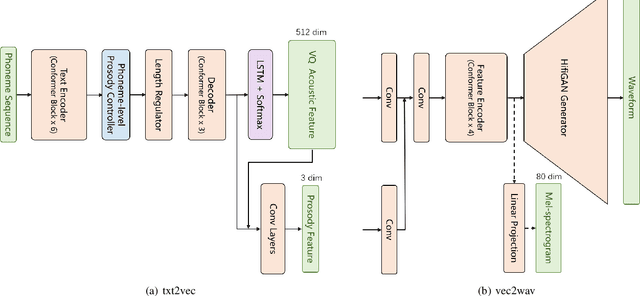
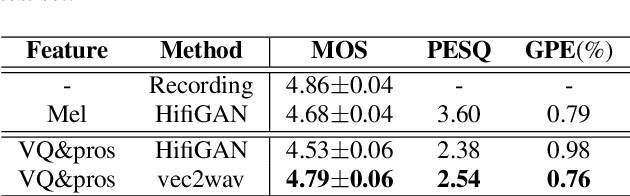
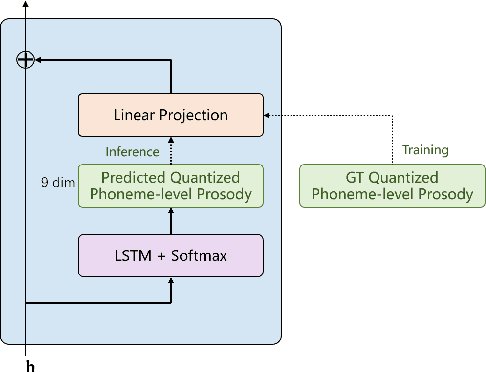
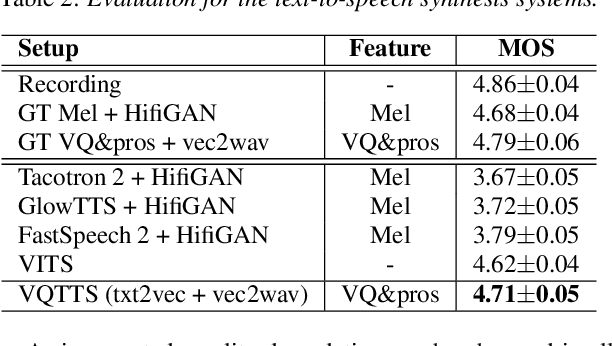
The mainstream neural text-to-speech(TTS) pipeline is a cascade system, including an acoustic model(AM) that predicts acoustic feature from the input transcript and a vocoder that generates waveform according to the given acoustic feature. However, the acoustic feature in current TTS systems is typically mel-spectrogram, which is highly correlated along both time and frequency axes in a complicated way, leading to a great difficulty for the AM to predict. Although high-fidelity audio can be generated by recent neural vocoders from ground-truth(GT) mel-spectrogram, the gap between the GT and the predicted mel-spectrogram from AM degrades the performance of the entire TTS system. In this work, we propose VQTTS, consisting of an AM txt2vec and a vocoder vec2wav, which uses self-supervised vector-quantized(VQ) acoustic feature rather than mel-spectrogram. We redesign both the AM and the vocoder accordingly. In particular, txt2vec basically becomes a classification model instead of a traditional regression model while vec2wav uses an additional feature encoder before HifiGAN generator for smoothing the discontinuous quantized feature. Our experiments show that vec2wav achieves better reconstruction performance than HifiGAN when using self-supervised VQ acoustic feature. Moreover, our entire TTS system VQTTS achieves state-of-the-art performance in terms of naturalness among all current publicly available TTS systems.
Lifelong Learning of Hate Speech Classification on Social Media
Jun 05, 2021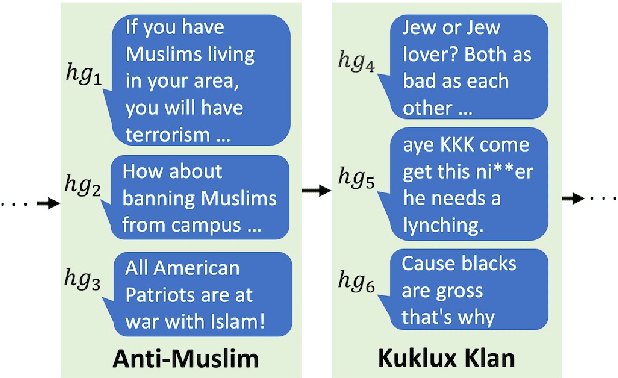
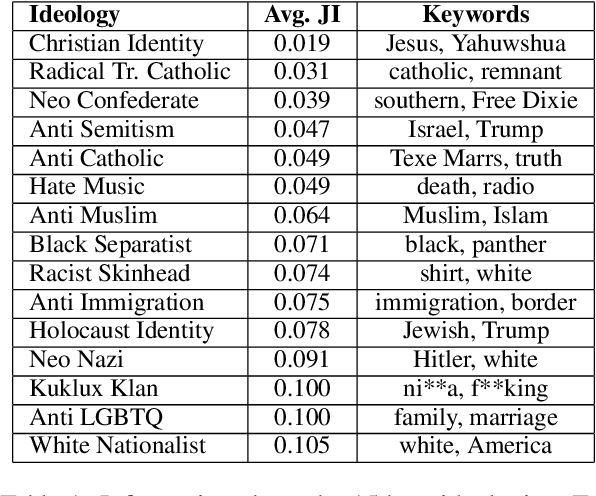
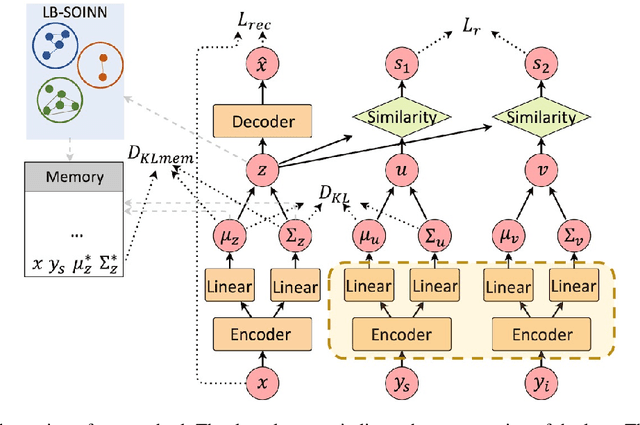
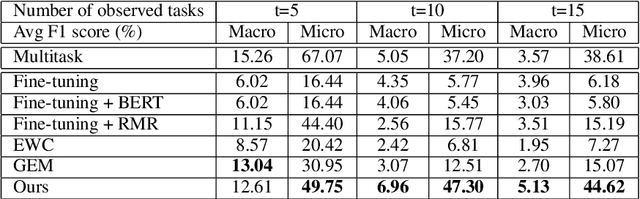
Existing work on automated hate speech classification assumes that the dataset is fixed and the classes are pre-defined. However, the amount of data in social media increases every day, and the hot topics changes rapidly, requiring the classifiers to be able to continuously adapt to new data without forgetting the previously learned knowledge. This ability, referred to as lifelong learning, is crucial for the real-word application of hate speech classifiers in social media. In this work, we propose lifelong learning of hate speech classification on social media. To alleviate catastrophic forgetting, we propose to use Variational Representation Learning (VRL) along with a memory module based on LB-SOINN (Load-Balancing Self-Organizing Incremental Neural Network). Experimentally, we show that combining variational representation learning and the LB-SOINN memory module achieves better performance than the commonly-used lifelong learning techniques.
Deep generative factorization for speech signal
Oct 27, 2020
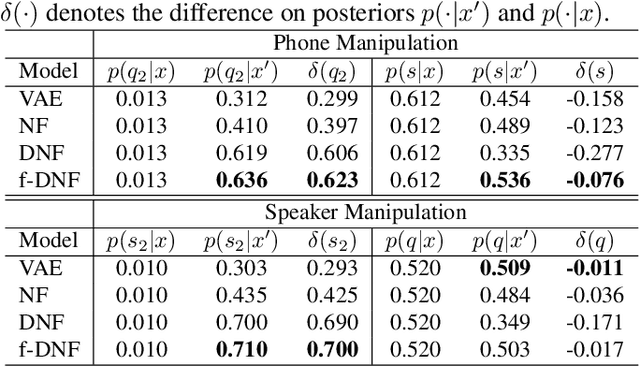
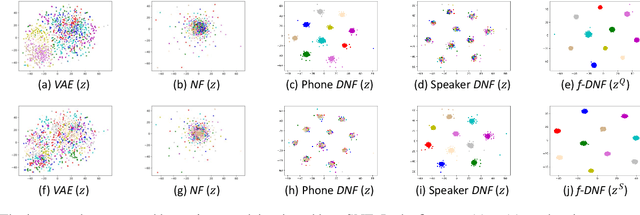
Various information factors are blended in speech signals, which forms the primary difficulty for most speech information processing tasks. An intuitive idea is to factorize speech signal into individual information factors (e.g., phonetic content and speaker trait), though it turns out to be highly challenging. This paper presents a speech factorization approach based on a novel factorial discriminative normalization flow model (factorial DNF). Experiments conducted on a two-factor case that involves phonetic content and speaker trait demonstrates that the proposed factorial DNF has powerful capability to factorize speech signals and outperforms several comparative models in terms of information representation and manipulation.
Multichannel Speech Enhancement without Beamforming
Oct 25, 2021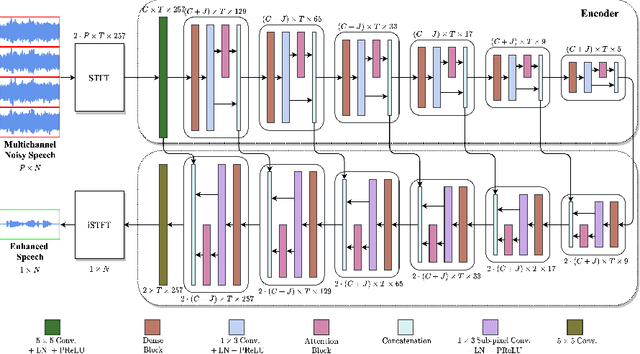
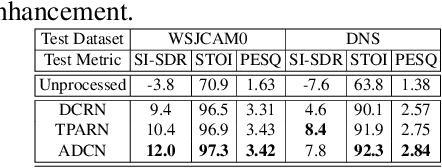
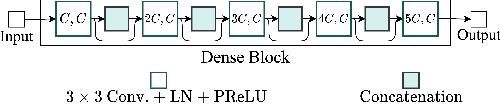
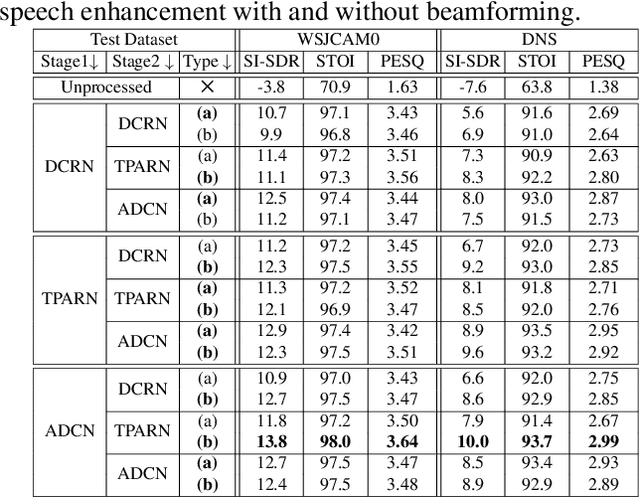
Deep neural networks are often coupled with traditional spatial filters, such as MVDR beamformers for effectively exploiting spatial information. Even though single-stage end-to-end supervised models can obtain impressive enhancement, combining them with a beamformer and a DNN-based post-filter in a multistage processing provides additional improvements. In this work, we propose a two-stage strategy for multi-channel speech enhancement that does not need a beamformer for additional performance. First, we propose a novel attentive dense convolutional network (ADCN) for predicting real and imaginary parts of complex spectrogram. ADCN obtains state-of-the-art results among single-stage models. Next, we use ADCN in the proposed strategy with a recently proposed triple-path attentive recurrent network (TPARN) for predicting waveform samples. The proposed strategy uses two insights; first, using different approaches in two stages; and second, using a stronger model in the first stage. We illustrate the efficacy of our strategy by evaluating multiple models in a two-stage approach with and without beamformer.
Talk, Don't Write: A Study of Direct Speech-Based Image Retrieval
Apr 08, 2021
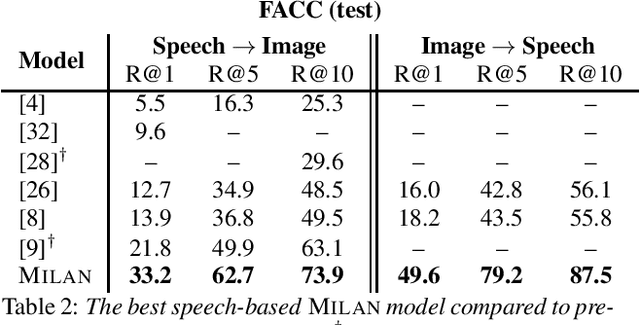
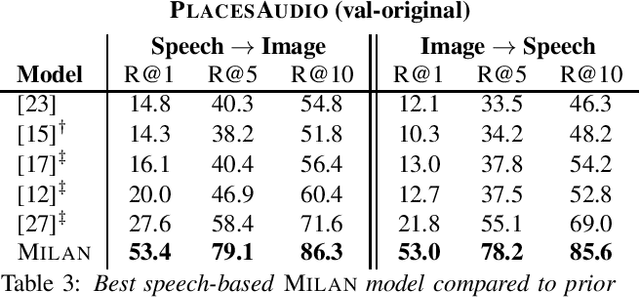
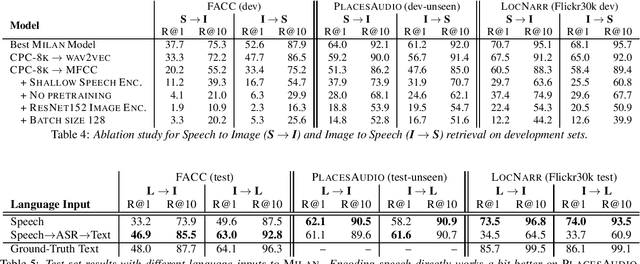
Speech-based image retrieval has been studied as a proxy for joint representation learning, usually without emphasis on retrieval itself. As such, it is unclear how well speech-based retrieval can work in practice -- both in an absolute sense and versus alternative strategies that combine automatic speech recognition (ASR) with strong text encoders. In this work, we extensively study and expand choices of encoder architectures, training methodology (including unimodal and multimodal pretraining), and other factors. Our experiments cover different types of speech in three datasets: Flickr Audio, Places Audio, and Localized Narratives. Our best model configuration achieves large gains over state of the art, e.g., pushing recall-at-one from 21.8% to 33.2% for Flickr Audio and 27.6% to 53.4% for Places Audio. We also show our best speech-based models can match or exceed cascaded ASR-to-text encoding when speech is spontaneous, accented, or otherwise hard to automatically transcribe.
Weakly-supervised word-level pronunciation error detection in non-native English speech
Jun 07, 2021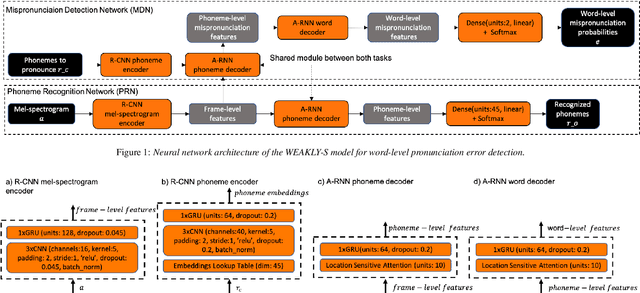
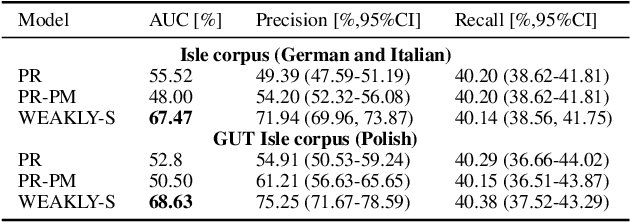

We propose a weakly-supervised model for word-level mispronunciation detection in non-native (L2) English speech. To train this model, phonetically transcribed L2 speech is not required and we only need to mark mispronounced words. The lack of phonetic transcriptions for L2 speech means that the model has to learn only from a weak signal of word-level mispronunciations. Because of that and due to the limited amount of mispronounced L2 speech, the model is more likely to overfit. To limit this risk, we train it in a multi-task setup. In the first task, we estimate the probabilities of word-level mispronunciation. For the second task, we use a phoneme recognizer trained on phonetically transcribed L1 speech that is easily accessible and can be automatically annotated. Compared to state-of-the-art approaches, we improve the accuracy of detecting word-level pronunciation errors in AUC metric by 30% on the GUT Isle Corpus of L2 Polish speakers, and by 21.5% on the Isle Corpus of L2 German and Italian speakers.
Preparing an Endangered Language for the Digital Age: The Case of Judeo-Spanish
May 31, 2022


We develop machine translation and speech synthesis systems to complement the efforts of revitalizing Judeo-Spanish, the exiled language of Sephardic Jews, which survived for centuries, but now faces the threat of extinction in the digital age. Building on resources created by the Sephardic community of Turkey and elsewhere, we create corpora and tools that would help preserve this language for future generations. For machine translation, we first develop a Spanish to Judeo-Spanish rule-based machine translation system, in order to generate large volumes of synthetic parallel data in the relevant language pairs: Turkish, English and Spanish. Then, we train baseline neural machine translation engines using this synthetic data and authentic parallel data created from translations by the Sephardic community. For text-to-speech synthesis, we present a 3.5 hour single speaker speech corpus for building a neural speech synthesis engine. Resources, model weights and online inference engines are shared publicly.
Multilingual Hate Speech and Offensive Content Detection using Modified Cross-entropy Loss
Feb 05, 2022
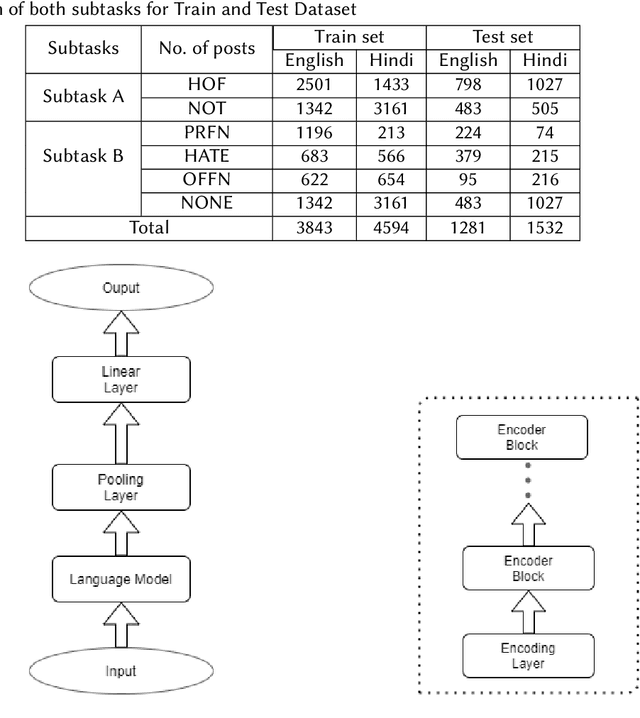
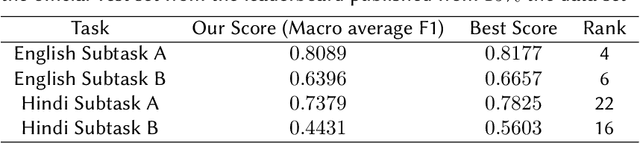
The number of increased social media users has led to a lot of people misusing these platforms to spread offensive content and use hate speech. Manual tracking the vast amount of posts is impractical so it is necessary to devise automated methods to identify them quickly. Large language models are trained on a lot of data and they also make use of contextual embeddings. We fine-tune the large language models to help in our task. The data is also quite unbalanced; so we used a modified cross-entropy loss to tackle the issue. We observed that using a model which is fine-tuned in hindi corpora performs better. Our team (HNLP) achieved the macro F1-scores of 0.808, 0.639 in English Subtask A and English Subtask B respectively. For Hindi Subtask A, Hindi Subtask B our team achieved macro F1-scores of 0.737, 0.443 respectively in HASOC 2021.
Read it to me: An emotionally aware Speech Narration Application
Sep 06, 2022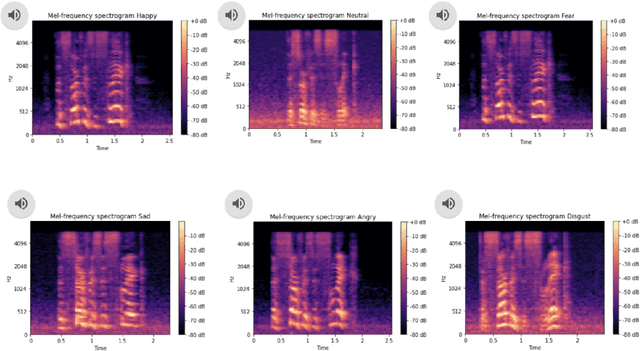

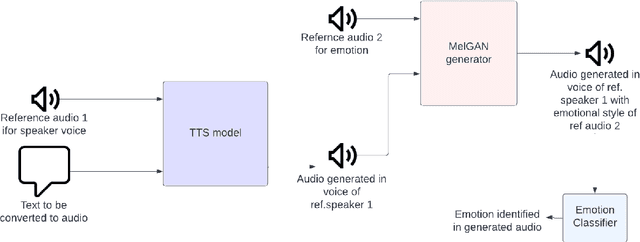
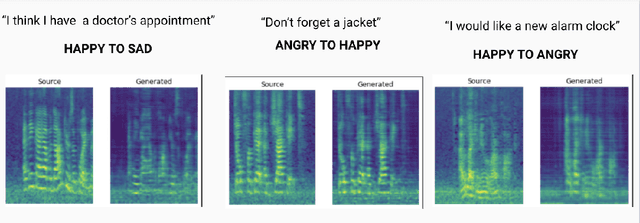
In this work we try to perform emotional style transfer on audios. In particular, MelGAN-VC architecture is explored for various emotion-pair transfers. The generated audio is then classified using an LSTM-based emotion classifier for audio. We find that "sad" audio is generated well as compared to "happy" or "anger" as people have similar expressions of sadness.