 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Cross-Lingual Machine Speech Chain for Javanese, Sundanese, Balinese, and Bataks Speech Recognition and Synthesis
Nov 04, 2020
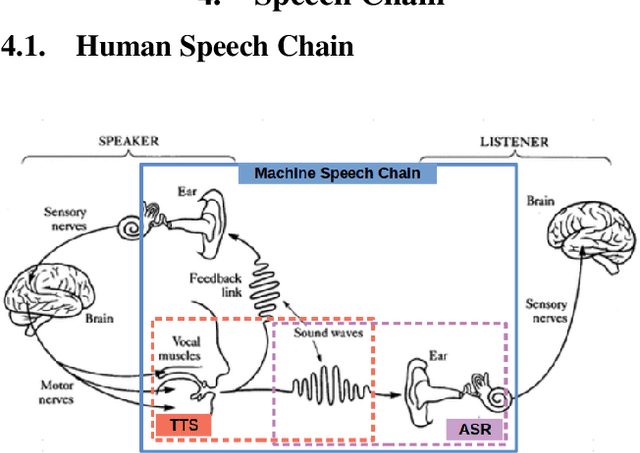

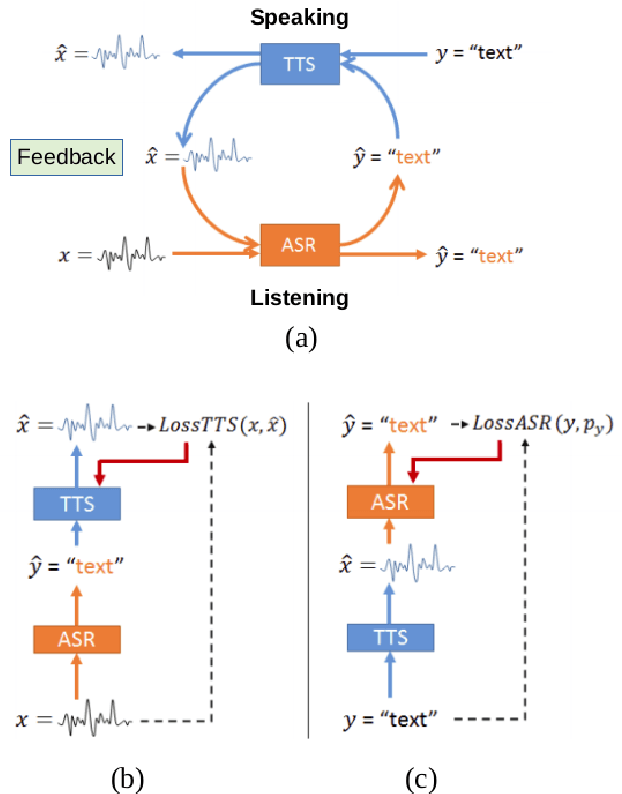

Even though over seven hundred ethnic languages are spoken in Indonesia, the available technology remains limited that could support communication within indigenous communities as well as with people outside the villages. As a result, indigenous communities still face isolation due to cultural barriers; languages continue to disappear. To accelerate communication, speech-to-speech translation (S2ST) technology is one approach that can overcome language barriers. However, S2ST systems require machine translation (MT), speech recognition (ASR), and synthesis (TTS) that rely heavily on supervised training and a broad set of language resources that can be difficult to collect from ethnic communities. Recently, a machine speech chain mechanism was proposed to enable ASR and TTS to assist each other in semi-supervised learning. The framework was initially implemented only for monolingual languages. In this study, we focus on developing speech recognition and synthesis for these Indonesian ethnic languages: Javanese, Sundanese, Balinese, and Bataks. We first separately train ASR and TTS of standard Indonesian in supervised training. We then develop ASR and TTS of ethnic languages by utilizing Indonesian ASR and TTS in a cross-lingual machine speech chain framework with only text or only speech data removing the need for paired speech-text data of those ethnic languages.
Deformable TDNN with adaptive receptive fields for speech recognition
Apr 30, 2021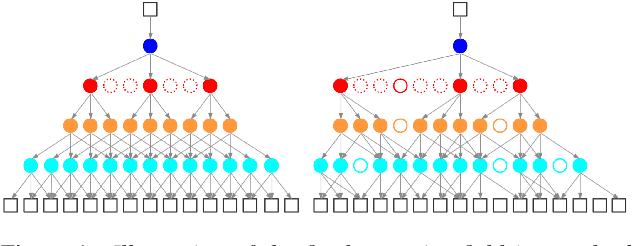
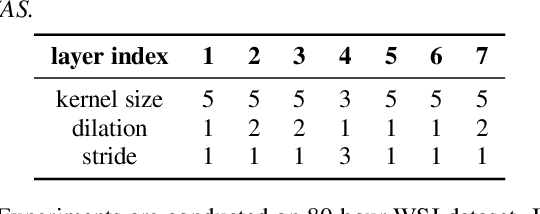
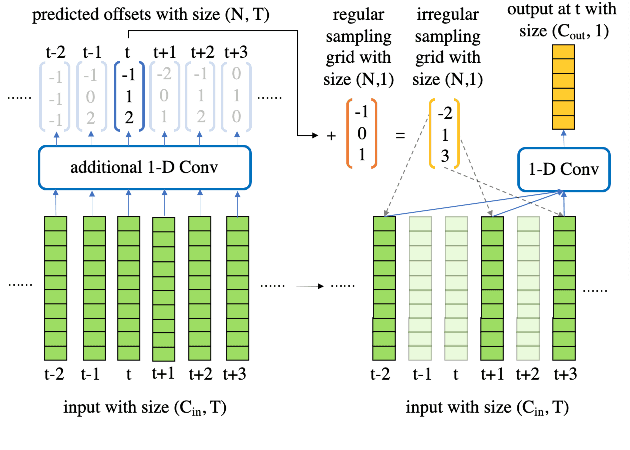
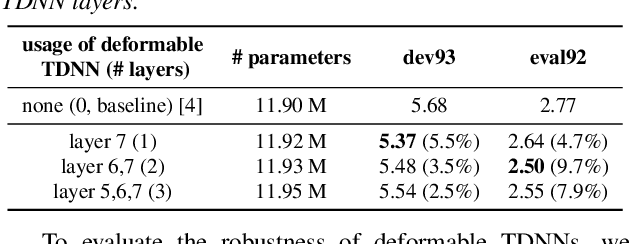
Time Delay Neural Networks (TDNNs) are widely used in both DNN-HMM based hybrid speech recognition systems and recent end-to-end systems. Nevertheless, the receptive fields of TDNNs are limited and fixed, which is not desirable for tasks like speech recognition, where the temporal dynamics of speech are varied and affected by many factors. This paper proposes to use deformable TDNNs for adaptive temporal dynamics modeling in end-to-end speech recognition. Inspired by deformable ConvNets, deformable TDNNs augment the temporal sampling locations with additional offsets and learn the offsets automatically based on the ASR criterion, without additional supervision. Experiments show that deformable TDNNs obtain state-of-the-art results on WSJ benchmarks (1.42\%/3.45\% WER on WSJ eval92/dev93 respectively), outperforming standard TDNNs significantly. Furthermore, we propose the latency control mechanism for deformable TDNNs, which enables deformable TDNNs to do streaming ASR without accuracy degradation.
Semantic Communication Systems for Speech Transmission
Feb 24, 2021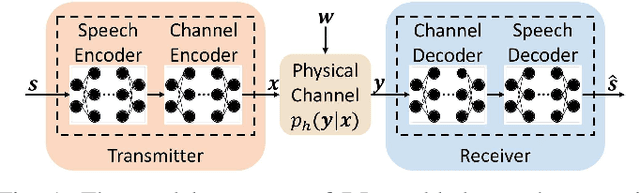



Semantic communications could improve the transmission efficiency significantly by exploring the input semantic information. Motivated by the breakthroughs in deep learning (DL), we make an effort to recover the transmitted speech signals in the semantic communication systems, which minimizes the error at the semantic level rather than the bit level or symbol level as in the traditional communication systems. Particularly, we design a DL-enabled semantic communication system for speech signals, named DeepSC-S. Based on an attention mechanism employing squeeze-and-excitation (SE) networks, DeepSC-S is able to identify the essential speech information and assign high values to the weights corresponding to the essential information when training the neural network. Moreover, in order to facilitate the proposed DeepSC-S to cater to dynamic channel environments, we dedicate to find a general model to cope with various channel conditions without retraining. Furthermore, to verify the model adaptation in practice, we investigate DeepSC-S in the telephone systems as well as the multimedia transmission systems, which usually requires higher data rates and lower transmission latency. The simulation results demonstrate that our proposed DeepSC-S achieves higher system performance than the traditional communications in both telephone systems and multimedia transmission systems by comparing the speech signals metrics, signal-to-distortion ration and perceptual evaluation of speech distortion. Besides, DeepSC-S is more robust to channel variations than the traditional approaches, especially in the low signal-to-noise (SNR) regime.
Audio Input Generates Continuous Frames to Synthesize Facial Video Using Generative Adiversarial Networks
Jul 18, 2022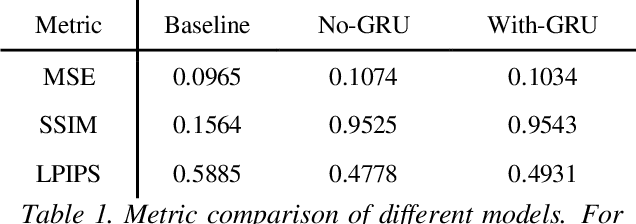
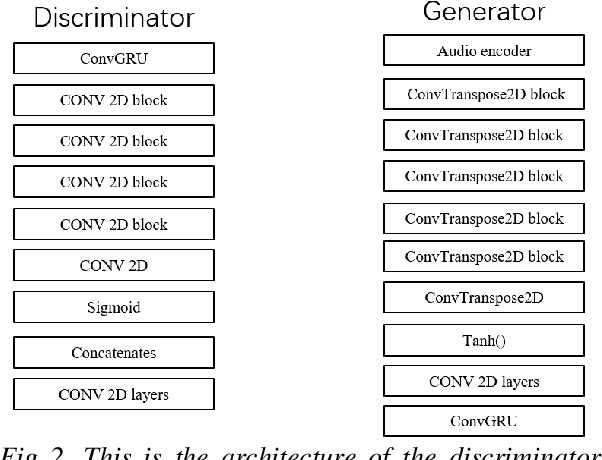

This paper presents a simple method for speech videos generation based on audio: given a piece of audio, we can generate a video of the target face speaking this audio. We propose Generative Adversarial Networks (GAN) with cut speech audio input as condition and use Convolutional Gate Recurrent Unit (GRU) in generator and discriminator. Our model is trained by exploiting the short audio and the frames in this duration. For training, we cut the audio and extract the face in the corresponding frames. We designed a simple encoder and compare the generated frames using GAN with and without GRU. We use GRU for temporally coherent frames and the results show that short audio can produce relatively realistic output results.
LeBenchmark: A Reproducible Framework for Assessing Self-Supervised Representation Learning from Speech
Apr 23, 2021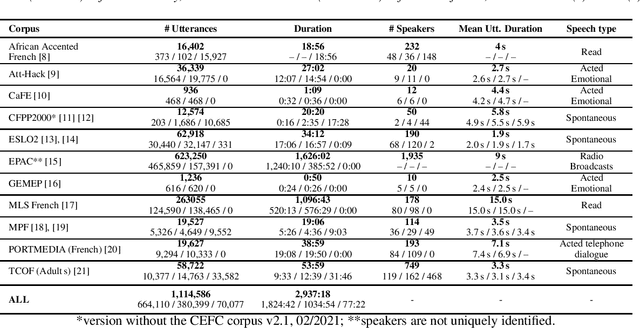
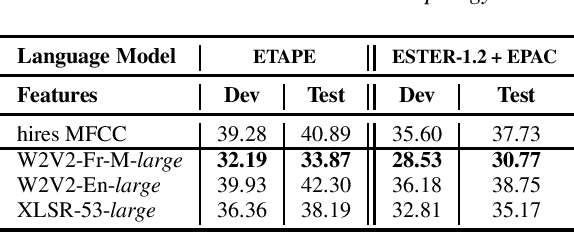
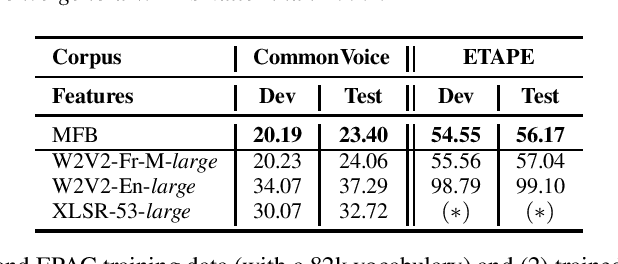
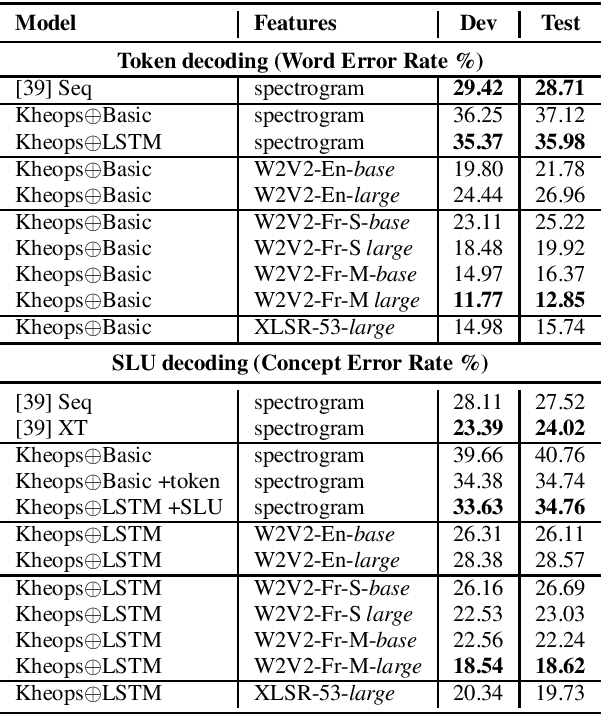
Self-Supervised Learning (SSL) using huge unlabeled data has been successfully explored for image and natural language processing. Recent works also investigated SSL from speech. They were notably successful to improve performance on downstream tasks such as automatic speech recognition (ASR). While these works suggest it is possible to reduce dependence on labeled data for building efficient speech systems, their evaluation was mostly made on ASR and using multiple and heterogeneous experimental settings (most of them for English). This renders difficult the objective comparison between SSL approaches and the evaluation of their impact on building speech systems. In this paper, we propose LeBenchmark: a reproducible framework for assessing SSL from speech. It not only includes ASR (high and low resource) tasks but also spoken language understanding, speech translation and emotion recognition. We also target speech technologies in a language different than English: French. SSL models of different sizes are trained from carefully sourced and documented datasets. Experiments show that SSL is beneficial for most but not all tasks which confirms the need for exhaustive and reliable benchmarks to evaluate its real impact. LeBenchmark is shared with the scientific community for reproducible research in SSL from speech.
DeepHate: Hate Speech Detection via Multi-Faceted Text Representations
Mar 14, 2021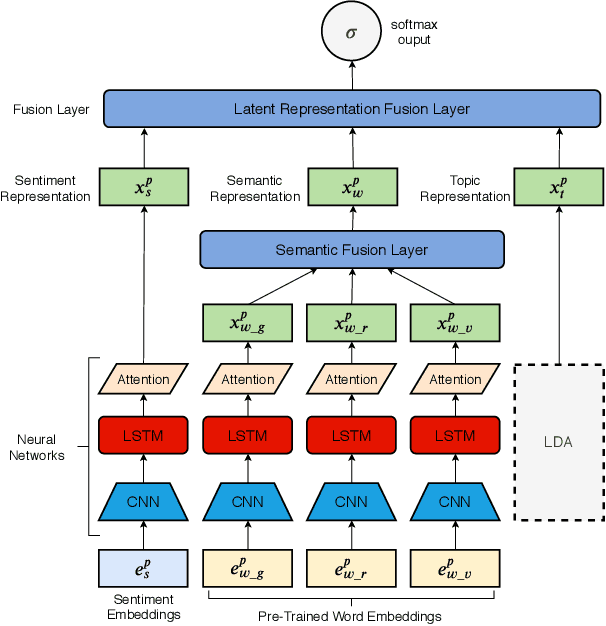
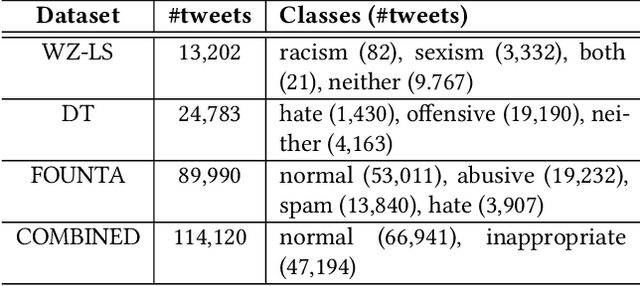
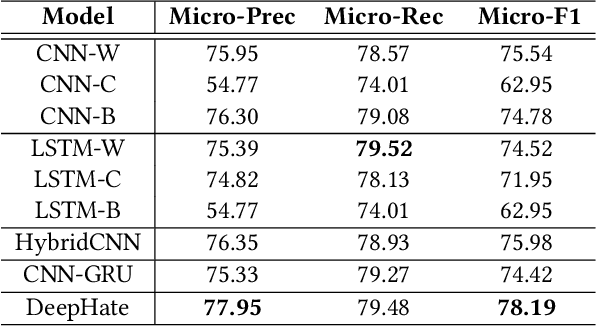
Online hate speech is an important issue that breaks the cohesiveness of online social communities and even raises public safety concerns in our societies. Motivated by this rising issue, researchers have developed many traditional machine learning and deep learning methods to detect hate speech in online social platforms automatically. However, most of these methods have only considered single type textual feature, e.g., term frequency, or using word embeddings. Such approaches neglect the other rich textual information that could be utilized to improve hate speech detection. In this paper, we propose DeepHate, a novel deep learning model that combines multi-faceted text representations such as word embeddings, sentiments, and topical information, to detect hate speech in online social platforms. We conduct extensive experiments and evaluate DeepHate on three large publicly available real-world datasets. Our experiment results show that DeepHate outperforms the state-of-the-art baselines on the hate speech detection task. We also perform case studies to provide insights into the salient features that best aid in detecting hate speech in online social platforms.
Star DGT: a Robust Gabor Transform for Speech Denoising
Apr 29, 2021
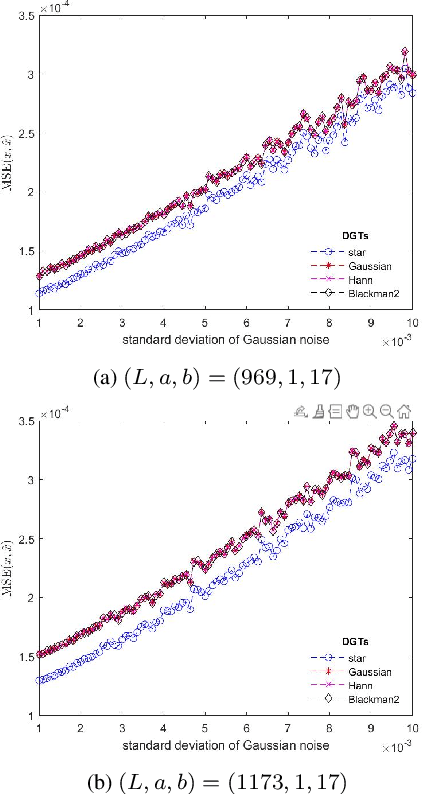

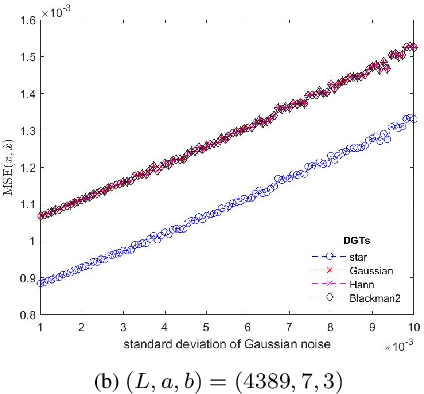
In this paper, we address the speech denoising problem, where white Gaussian additive noise is to be removed from a given speech signal. Our approach is based on a redundant, analysis-sparse representation of the original speech signal. We pick an eigenvector of the Zauner unitary matrix and -- under certain assumptions on the ambient dimension -- we use it as window vector to generate a spark deficient Gabor frame. The analysis operator associated with such a frame, is a (highly) redundant Gabor transform, which we use as a sparsifying transform in denoising procedure. We conduct computational experiments on real-world speech data, solving the analysis basis pursuit denoising problem, with four different choices of analysis operators, including our Gabor analysis operator. The results show that our proposed redundant Gabor transform outperforms -- in all cases -- Gabor transforms generated by state-of-the-art window vectors of time-frequency analysis.
Speak Like a Dog: Human to Non-human creature Voice Conversion
Jun 09, 2022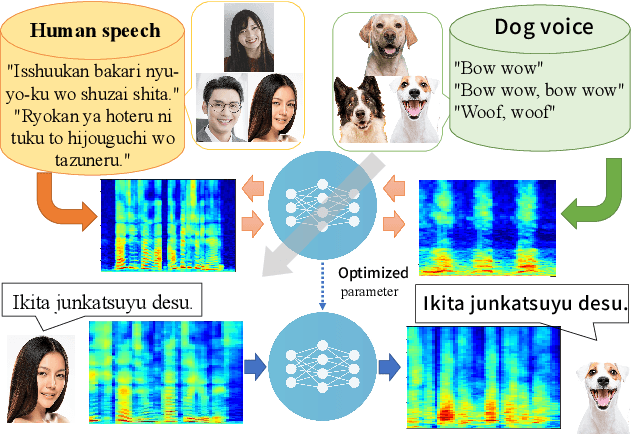
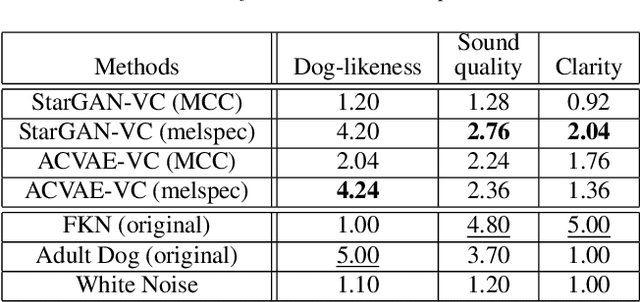
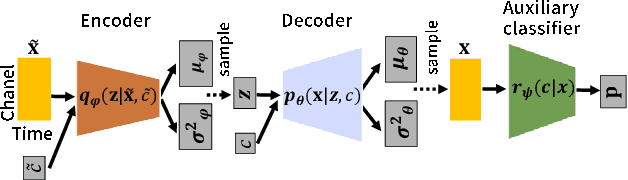
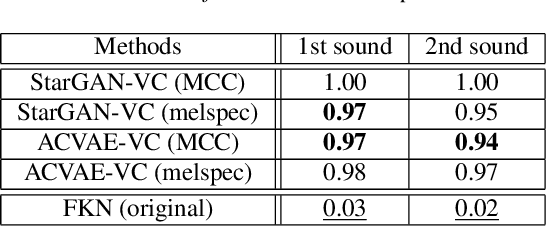
This paper proposes a new voice conversion (VC) task from human speech to dog-like speech while preserving linguistic information as an example of human to non-human creature voice conversion (H2NH-VC) tasks. Although most VC studies deal with human to human VC, H2NH-VC aims to convert human speech into non-human creature-like speech. Non-parallel VC allows us to develop H2NH-VC, because we cannot collect a parallel dataset that non-human creatures speak human language. In this study, we propose to use dogs as an example of a non-human creature target domain and define the "speak like a dog" task. To clarify the possibilities and characteristics of the "speak like a dog" task, we conducted a comparative experiment using existing representative non-parallel VC methods in acoustic features (Mel-cepstral coefficients and Mel-spectrograms), network architectures (five different kernel-size settings), and training criteria (variational autoencoder (VAE)- based and generative adversarial network-based). Finally, the converted voices were evaluated using mean opinion scores: dog-likeness, sound quality and intelligibility, and character error rate (CER). The experiment showed that the employment of the Mel-spectrogram improved the dog-likeness of the converted speech, while it is challenging to preserve linguistic information. Challenges and limitations of the current VC methods for H2NH-VC are highlighted.
Lombard Effect for Bilingual Speakers in Cantonese and English: importance of spectro-temporal features
Apr 14, 2022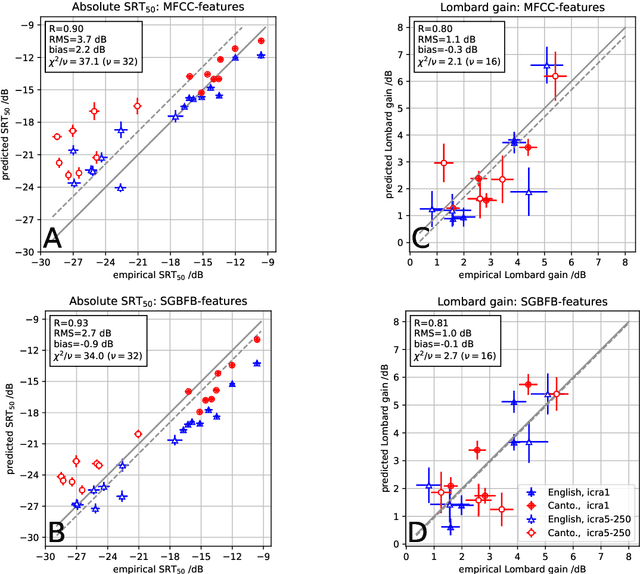
For a better understanding of the mechanisms underlying speech perception and the contribution of different signal features, computational models of speech recognition have a long tradition in hearing research. Due to the diverse range of situations in which speech needs to be recognized, these models need to be generalizable across many acoustic conditions, speakers, and languages. This contribution examines the importance of different features for speech recognition predictions of plain and Lombard speech for English in comparison to Cantonese in stationary and modulated noise. While Cantonese is a tonal language that encodes information in spectro-temporal features, the Lombard effect is known to be associated with spectral changes in the speech signal. These contrasting properties of tonal languages and the Lombard effect form an interesting basis for the assessment of speech recognition models. Here, an automatic speech recognition-based ASR model using spectral or spectro-temporal features is evaluated with empirical data. The results indicate that spectro-temporal features are crucial in order to predict the speaker-specific speech recognition threshold SRT$_{50}$ in both Cantonese and English as well as to account for the improvement of speech recognition in modulated noise, while effects due to Lombard speech can already be predicted by spectral features.
IMS' Systems for the IWSLT 2021 Low-Resource Speech Translation Task
Jun 30, 2021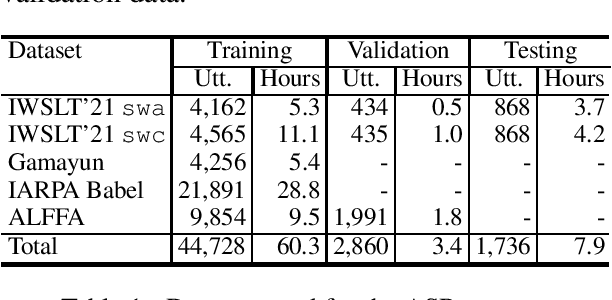
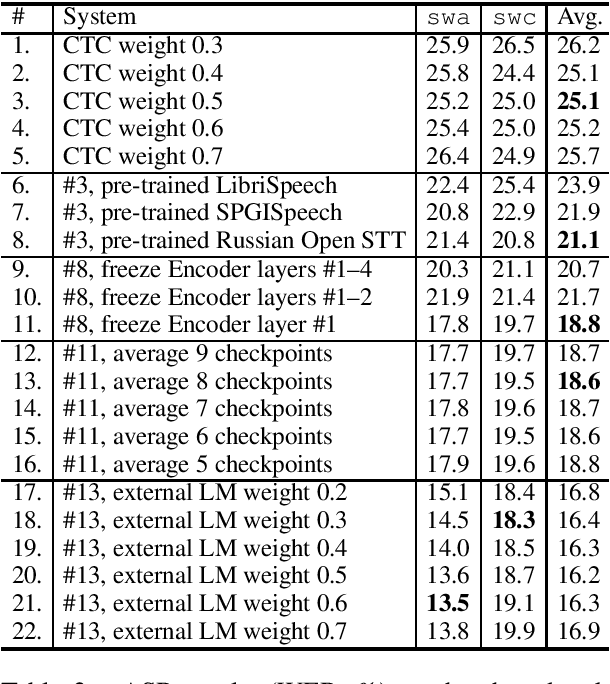
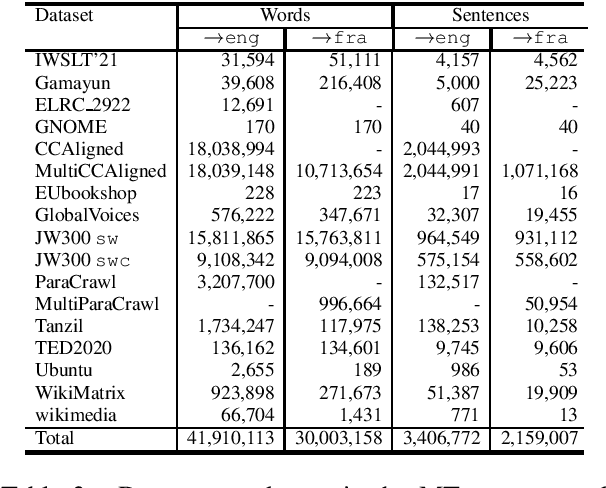
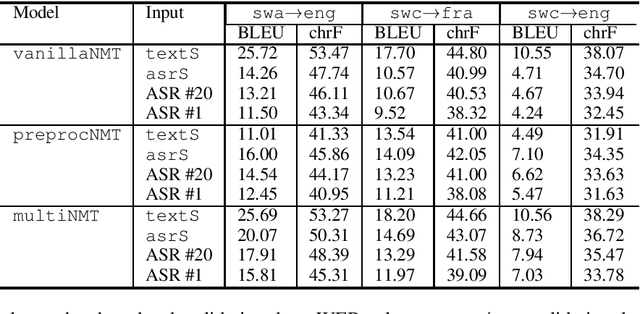
This paper describes the submission to the IWSLT 2021 Low-Resource Speech Translation Shared Task by IMS team. We utilize state-of-the-art models combined with several data augmentation, multi-task and transfer learning approaches for the automatic speech recognition (ASR) and machine translation (MT) steps of our cascaded system. Moreover, we also explore the feasibility of a full end-to-end speech translation (ST) model in the case of very constrained amount of ground truth labeled data. Our best system achieves the best performance among all submitted systems for Congolese Swahili to English and French with BLEU scores 7.7 and 13.7 respectively, and the second best result for Coastal Swahili to English with BLEU score 14.9.