 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
DeepHate: Hate Speech Detection via Multi-Faceted Text Representations
Mar 14, 2021
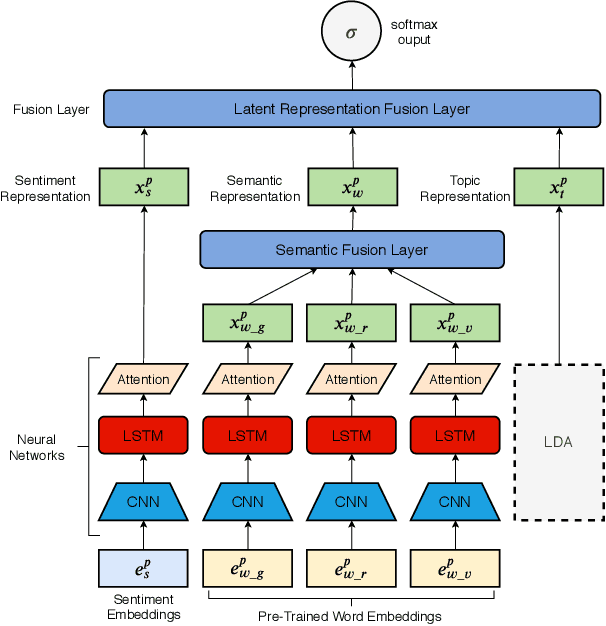
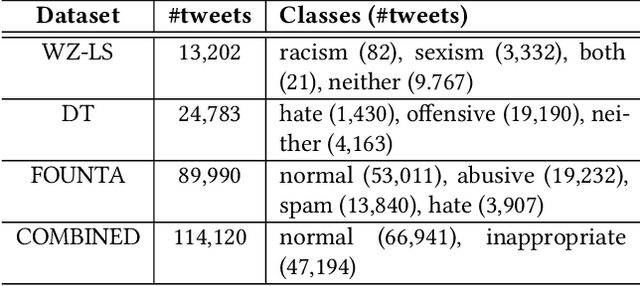
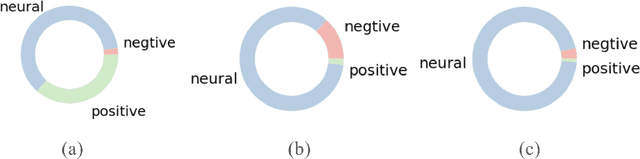
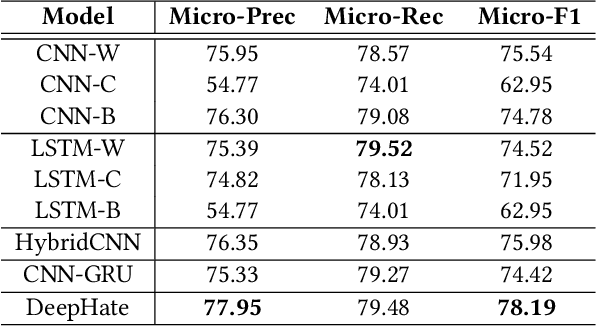
Online hate speech is an important issue that breaks the cohesiveness of online social communities and even raises public safety concerns in our societies. Motivated by this rising issue, researchers have developed many traditional machine learning and deep learning methods to detect hate speech in online social platforms automatically. However, most of these methods have only considered single type textual feature, e.g., term frequency, or using word embeddings. Such approaches neglect the other rich textual information that could be utilized to improve hate speech detection. In this paper, we propose DeepHate, a novel deep learning model that combines multi-faceted text representations such as word embeddings, sentiments, and topical information, to detect hate speech in online social platforms. We conduct extensive experiments and evaluate DeepHate on three large publicly available real-world datasets. Our experiment results show that DeepHate outperforms the state-of-the-art baselines on the hate speech detection task. We also perform case studies to provide insights into the salient features that best aid in detecting hate speech in online social platforms.
Cross-Lingual Machine Speech Chain for Javanese, Sundanese, Balinese, and Bataks Speech Recognition and Synthesis
Nov 04, 2020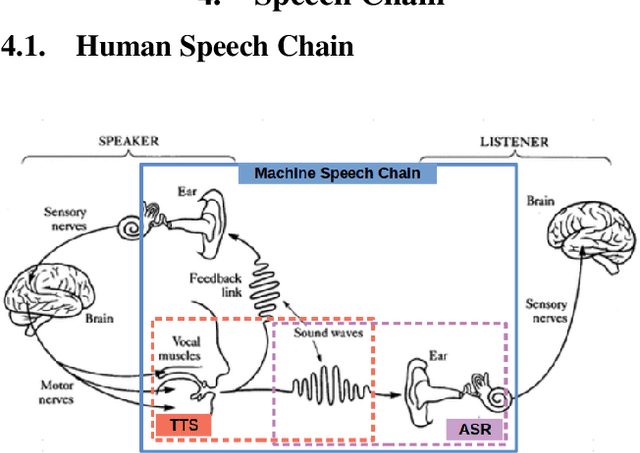

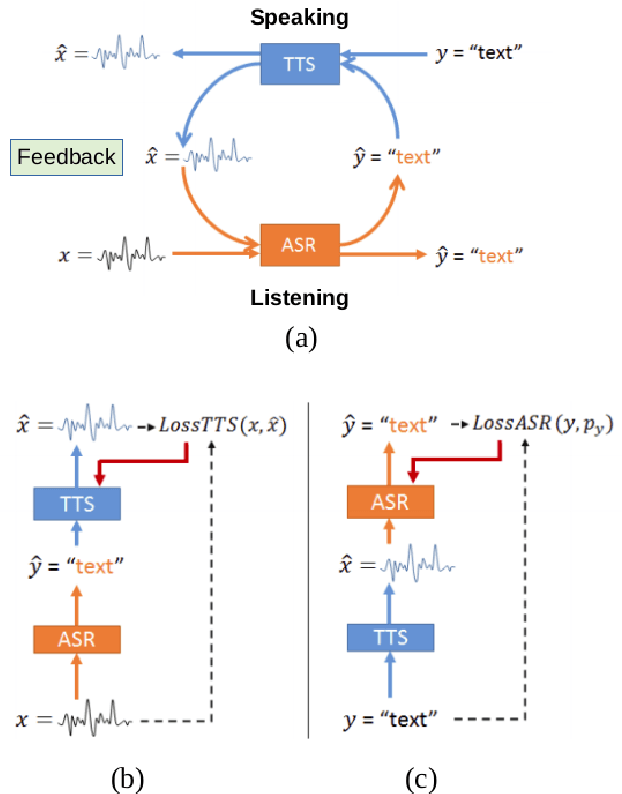

Even though over seven hundred ethnic languages are spoken in Indonesia, the available technology remains limited that could support communication within indigenous communities as well as with people outside the villages. As a result, indigenous communities still face isolation due to cultural barriers; languages continue to disappear. To accelerate communication, speech-to-speech translation (S2ST) technology is one approach that can overcome language barriers. However, S2ST systems require machine translation (MT), speech recognition (ASR), and synthesis (TTS) that rely heavily on supervised training and a broad set of language resources that can be difficult to collect from ethnic communities. Recently, a machine speech chain mechanism was proposed to enable ASR and TTS to assist each other in semi-supervised learning. The framework was initially implemented only for monolingual languages. In this study, we focus on developing speech recognition and synthesis for these Indonesian ethnic languages: Javanese, Sundanese, Balinese, and Bataks. We first separately train ASR and TTS of standard Indonesian in supervised training. We then develop ASR and TTS of ethnic languages by utilizing Indonesian ASR and TTS in a cross-lingual machine speech chain framework with only text or only speech data removing the need for paired speech-text data of those ethnic languages.
TEASEL: A Transformer-Based Speech-Prefixed Language Model
Sep 12, 2021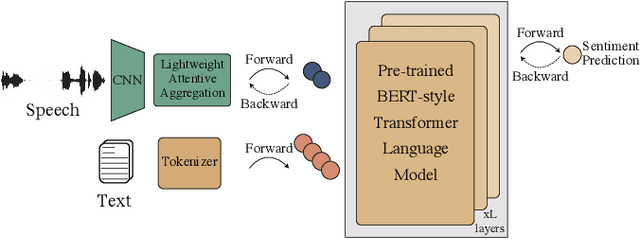
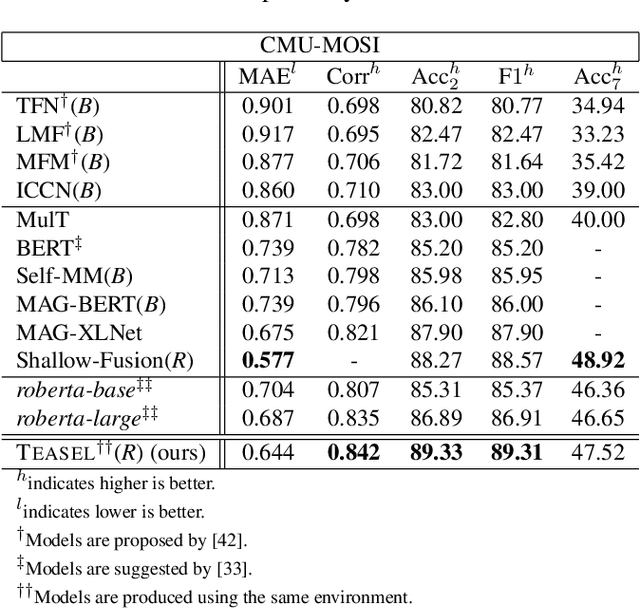
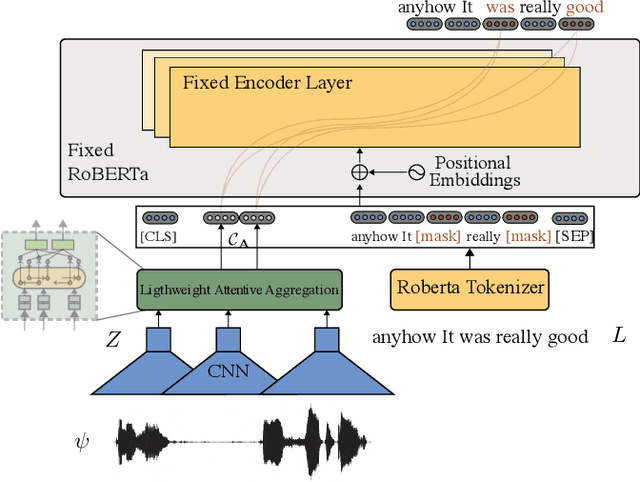
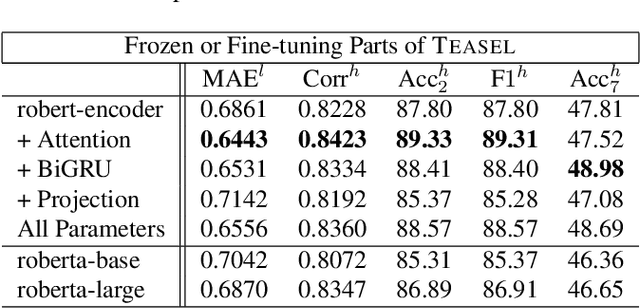
Multimodal language analysis is a burgeoning field of NLP that aims to simultaneously model a speaker's words, acoustical annotations, and facial expressions. In this area, lexicon features usually outperform other modalities because they are pre-trained on large corpora via Transformer-based models. Despite their strong performance, training a new self-supervised learning (SSL) Transformer on any modality is not usually attainable due to insufficient data, which is the case in multimodal language learning. This work proposes a Transformer-Based Speech-Prefixed Language Model called TEASEL to approach the mentioned constraints without training a complete Transformer model. TEASEL model includes speech modality as a dynamic prefix besides the textual modality compared to a conventional language model. This method exploits a conventional pre-trained language model as a cross-modal Transformer model. We evaluated TEASEL for the multimodal sentiment analysis task defined by CMU-MOSI dataset. Extensive experiments show that our model outperforms unimodal baseline language models by 4% and outperforms the current multimodal state-of-the-art (SoTA) model by 1% in F1-score. Additionally, our proposed method is 72% smaller than the SoTA model.
TC-SKNet with GridMask for Low-complexity Classification of Acoustic scene
Oct 05, 2022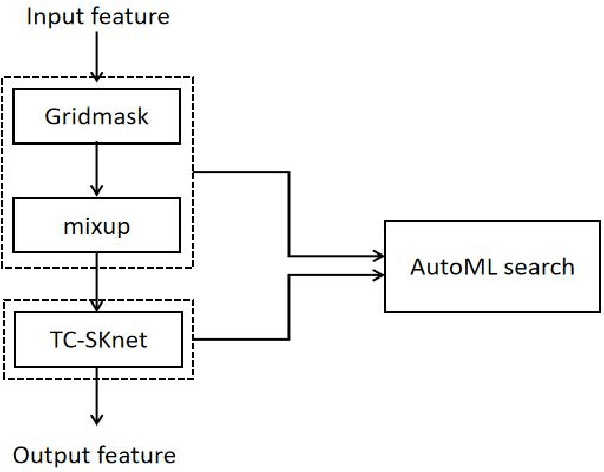

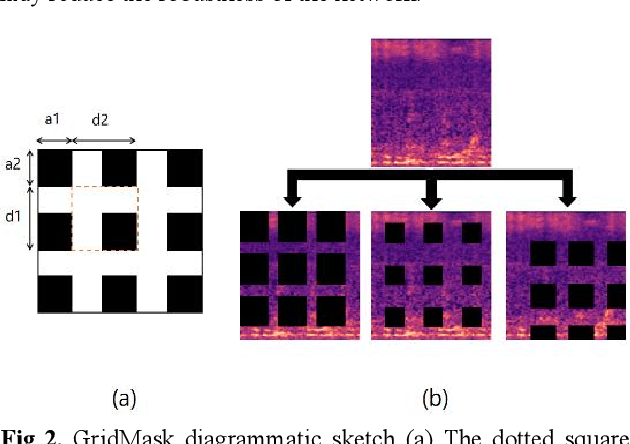
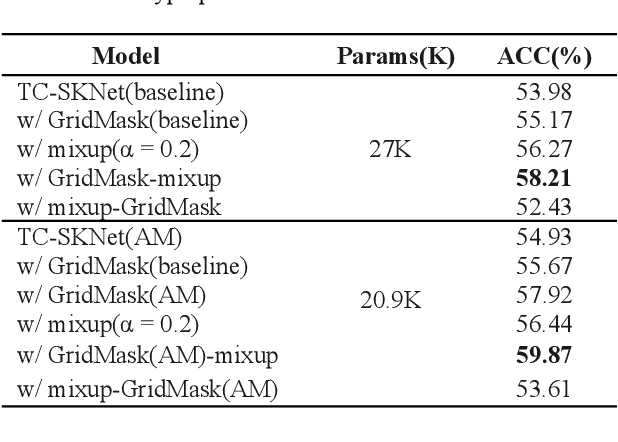
Convolution neural networks (CNNs) have good performance in low-complexity classification tasks such as acoustic scene classifications (ASCs). However, there are few studies on the relationship between the length of target speech and the size of the convolution kernels. In this paper, we combine Selective Kernel Network with Temporal-Convolution (TC-SKNet) to adjust the receptive field of convolution kernels to solve the problem of variable length of target voice while keeping low-complexity. GridMask is a data augmentation strategy by masking part of the raw data or feature area. It can enhance the generalization of the model as the role of dropout. In our experiments, the performance gain brought by GridMask is stronger than spectrum augmentation in ASCs. Finally, we adopt AutoML to search best structure of TC-SKNet and hyperparameters of GridMask for improving the classification performance. As a result, a peak accuracy of 59.87% TC-SKNet is equivalent to that of SOTA, but the parameters only use 20.9 K.
StarGAN-VC+ASR: StarGAN-based Non-Parallel Voice Conversion Regularized by Automatic Speech Recognition
Aug 10, 2021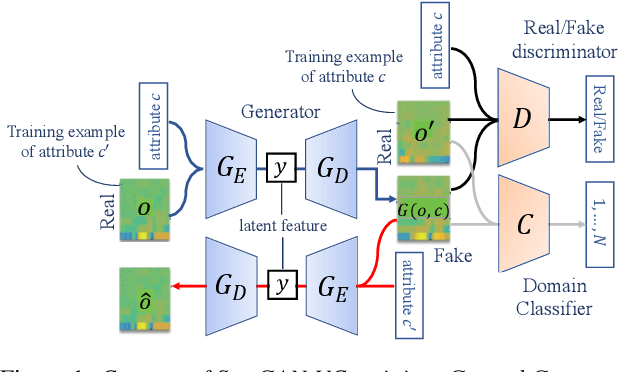
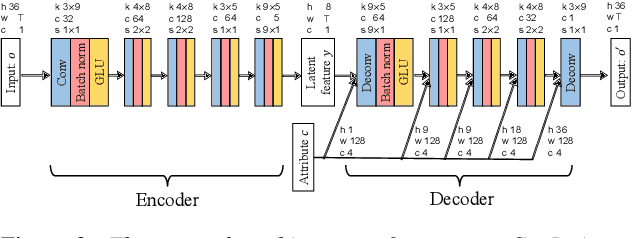
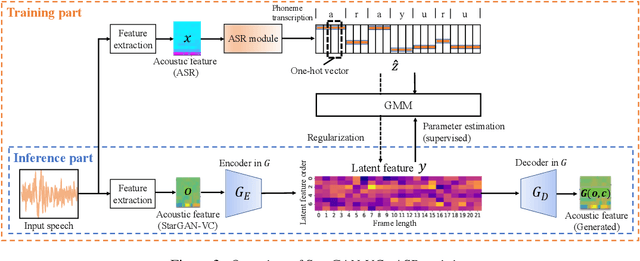
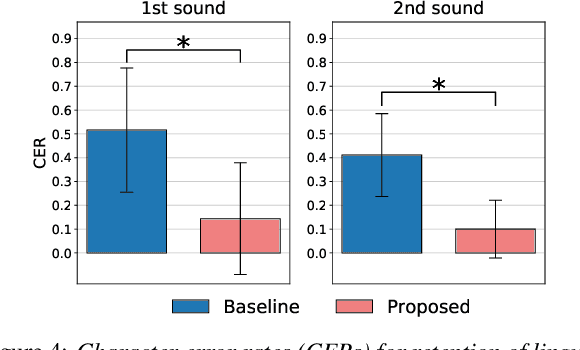
Preserving the linguistic content of input speech is essential during voice conversion (VC). The star generative adversarial network-based VC method (StarGAN-VC) is a recently developed method that allows non-parallel many-to-many VC. Although this method is powerful, it can fail to preserve the linguistic content of input speech when the number of available training samples is extremely small. To overcome this problem, we propose the use of automatic speech recognition to assist model training, to improve StarGAN-VC, especially in low-resource scenarios. Experimental results show that using our proposed method, StarGAN-VC can retain more linguistic information than vanilla StarGAN-VC.
Improving Speech Recognition Accuracy of Local POI Using Geographical Models
Jul 07, 2021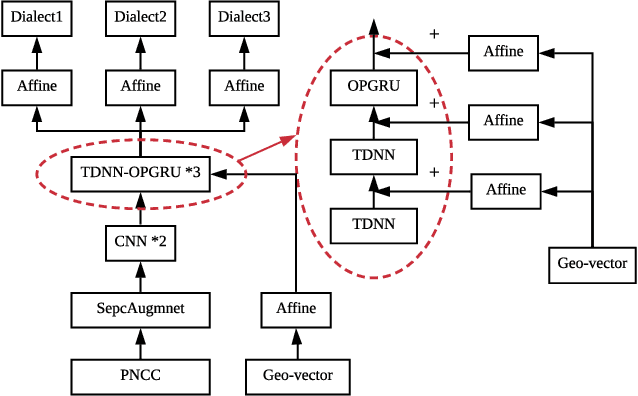
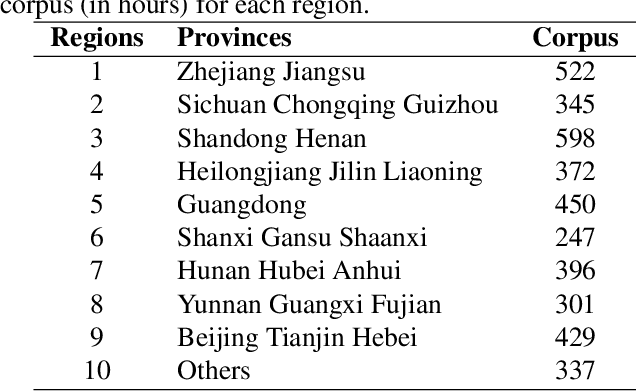
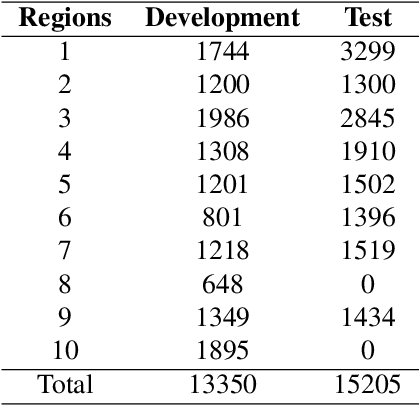
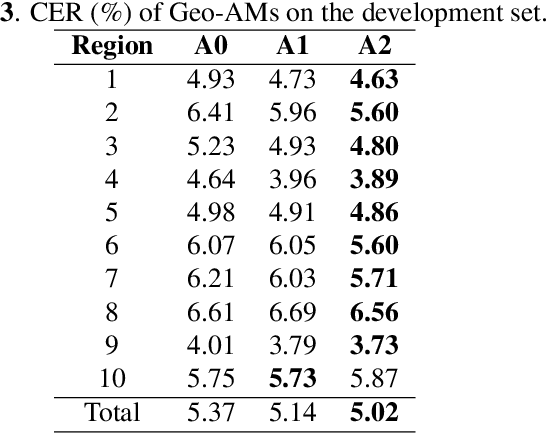
Nowadays voice search for points of interest (POI) is becoming increasingly popular. However, speech recognition for local POI has remained to be a challenge due to multi-dialect and massive POI. This paper improves speech recognition accuracy for local POI from two aspects. Firstly, a geographic acoustic model (Geo-AM) is proposed. The Geo-AM deals with multi-dialect problem using dialect-specific input feature and dialect-specific top layer. Secondly, a group of geo-specific language models (Geo-LMs) are integrated into our speech recognition system to improve recognition accuracy of long tail and homophone POI. During decoding, specific language models are selected on demand according to users' geographic location. Experiments show that the proposed Geo-AM achieves 6.5%$\sim$10.1% relative character error rate (CER) reduction on an accent testset and the proposed Geo-AM and Geo-LM totally achieve over 18.7% relative CER reduction on Tencent Map task.
DHASP: Differentiable Hearing Aid Speech Processing
Mar 15, 2021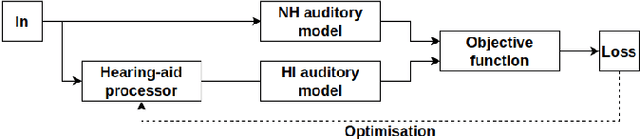

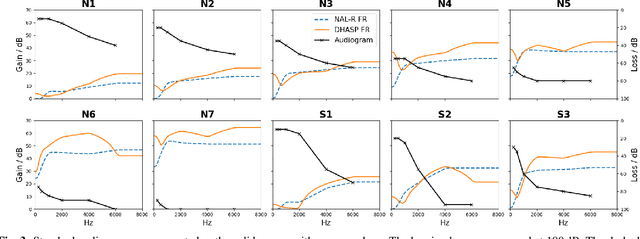
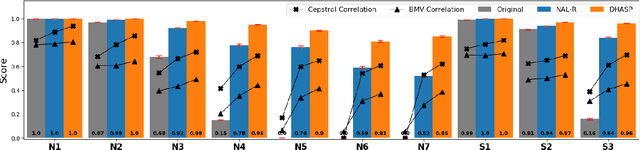
Hearing aids are expected to improve speech intelligibility for listeners with hearing impairment. An appropriate amplification fitting tuned for the listener's hearing disability is critical for good performance. The developments of most prescriptive fittings are based on data collected in subjective listening experiments, which are usually expensive and time-consuming. In this paper, we explore an alternative approach to finding the optimal fitting by introducing a hearing aid speech processing framework, in which the fitting is optimised in an automated way using an intelligibility objective function based on the HASPI physiological auditory model. The framework is fully differentiable, thus can employ the back-propagation algorithm for efficient, data-driven optimisation. Our initial objective experiments show promising results for noise-free speech amplification, where the automatically optimised processors outperform one of the well recognised hearing aid prescriptions.
Detecting Hate Speech with GPT-3
Mar 23, 2021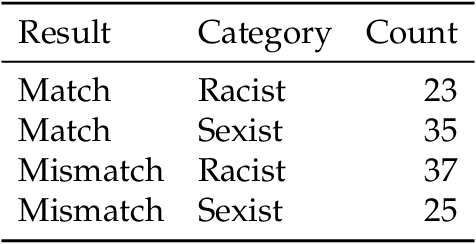
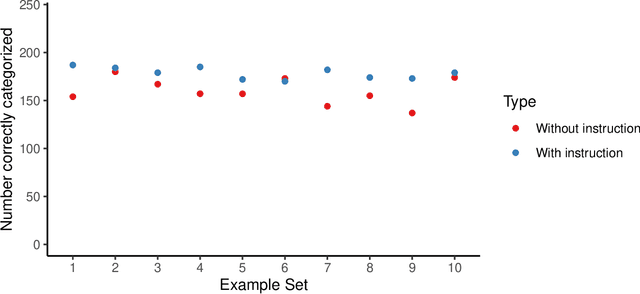

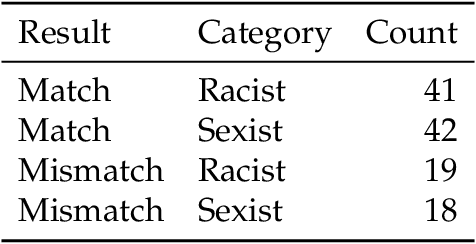
Sophisticated language models such as OpenAI's GPT-3 can generate hateful text that targets marginalized groups. Given this capacity, we are interested in whether large language models can be used to identify hate speech and classify text as sexist or racist? We use GPT-3 to identify sexist and racist text passages with zero-, one-, and few-shot learning. We find that with zero- and one-shot learning, GPT-3 is able to identify sexist or racist text with an accuracy between 48 per cent and 69 per cent. With few-shot learning and an instruction included in the prompt, the model's accuracy can be as high as 78 per cent. We conclude that large language models have a role to play in hate speech detection, and that with further development language models could be used to counter hate speech and even self-police.
Three-class Overlapped Speech Detection using a Convolutional Recurrent Neural Network
Apr 07, 2021
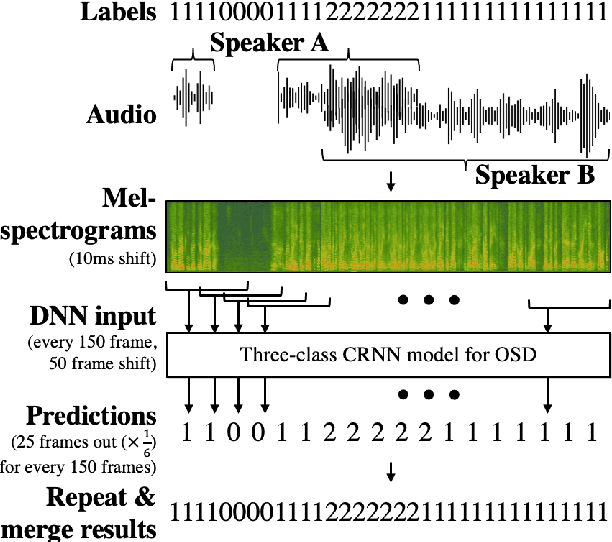
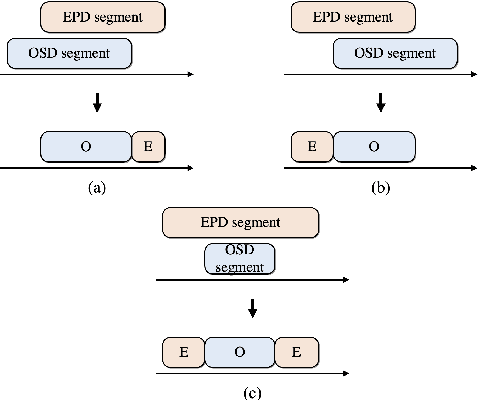
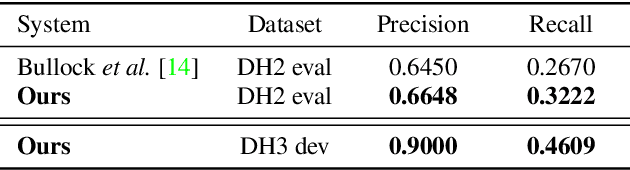
In this work, we propose an overlapped speech detection system trained as a three-class classifier. Unlike conventional systems that perform binary classification as to whether or not a frame contains overlapped speech, the proposed approach classifies into three classes: non-speech, single speaker speech, and overlapped speech. By training a network with the more detailed label definition, the model can learn a better notion on deciding the number of speakers included in a given frame. A convolutional recurrent neural network architecture is explored to benefit from both convolutional layer's capability to model local patterns and recurrent layer's ability to model sequential information. The proposed overlapped speech detection model establishes a state-of-the-art performance with a precision of 0.6648 and a recall of 0.3222 on the DIHARD II evaluation set, showing a 20% increase in recall along with higher precision. In addition, we also introduce a simple approach to utilize the proposed overlapped speech detection model for speaker diarization which ranked third place in the Track 1 of the DIHARD III challenge.
Subband-based Generative Adversarial Network for Non-parallel Many-to-many Voice Conversion
Jul 13, 2022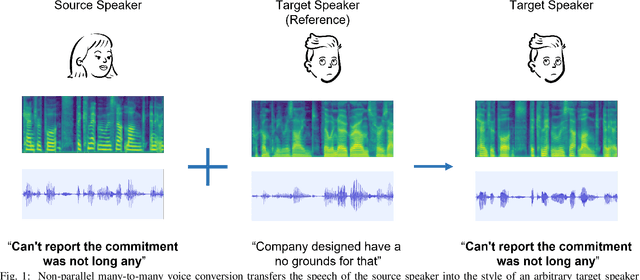
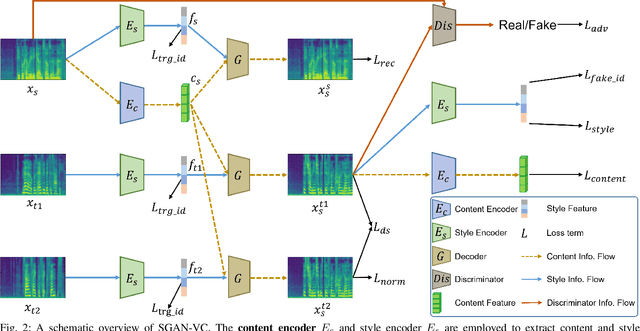
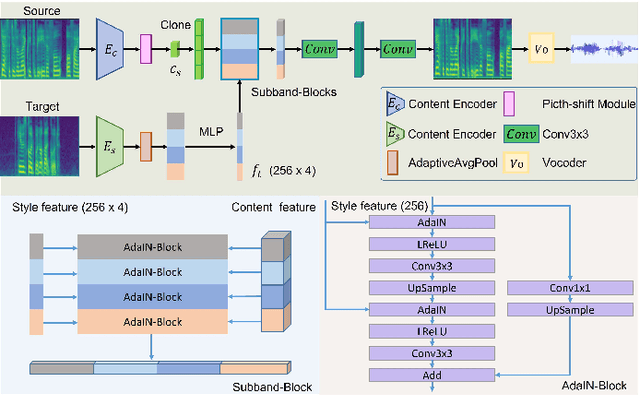
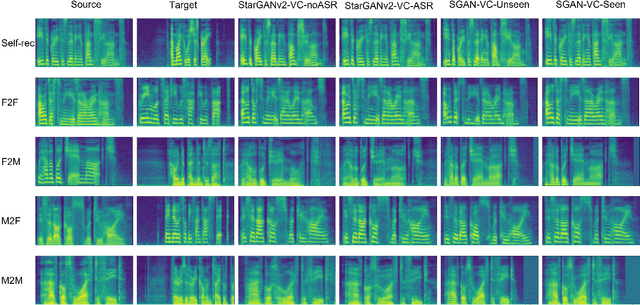
Voice conversion is to generate a new speech with the source content and a target voice style. In this paper, we focus on one general setting, i.e., non-parallel many-to-many voice conversion, which is close to the real-world scenario. As the name implies, non-parallel many-to-many voice conversion does not require the paired source and reference speeches and can be applied to arbitrary voice transfer. In recent years, Generative Adversarial Networks (GANs) and other techniques such as Conditional Variational Autoencoders (CVAEs) have made considerable progress in this field. However, due to the sophistication of voice conversion, the style similarity of the converted speech is still unsatisfactory. Inspired by the inherent structure of mel-spectrogram, we propose a new voice conversion framework, i.e., Subband-based Generative Adversarial Network for Voice Conversion (SGAN-VC). SGAN-VC converts each subband content of the source speech separately by explicitly utilizing the spatial characteristics between different subbands. SGAN-VC contains one style encoder, one content encoder, and one decoder. In particular, the style encoder network is designed to learn style codes for different subbands of the target speaker. The content encoder network can capture the content information on the source speech. Finally, the decoder generates particular subband content. In addition, we propose a pitch-shift module to fine-tune the pitch of the source speaker, making the converted tone more accurate and explainable. Extensive experiments demonstrate that the proposed approach achieves state-of-the-art performance on VCTK Corpus and AISHELL3 datasets both qualitatively and quantitatively, whether on seen or unseen data. Furthermore, the content intelligibility of SGAN-VC on unseen data even exceeds that of StarGANv2-VC with ASR network assistance.