 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations
Oct 28, 2021
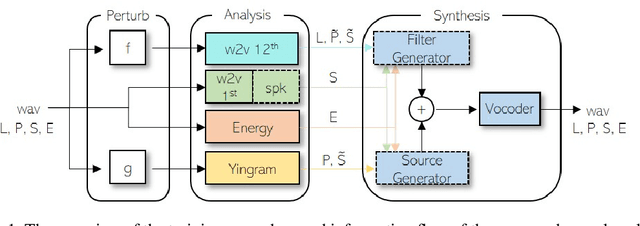

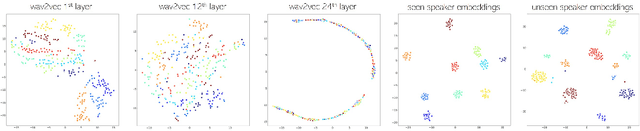
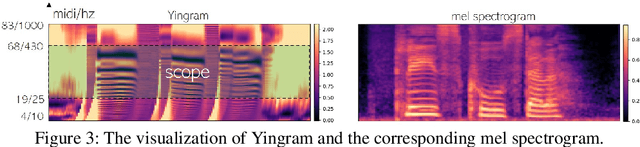
We present a neural analysis and synthesis (NANSY) framework that can manipulate voice, pitch, and speed of an arbitrary speech signal. Most of the previous works have focused on using information bottleneck to disentangle analysis features for controllable synthesis, which usually results in poor reconstruction quality. We address this issue by proposing a novel training strategy based on information perturbation. The idea is to perturb information in the original input signal (e.g., formant, pitch, and frequency response), thereby letting synthesis networks selectively take essential attributes to reconstruct the input signal. Because NANSY does not need any bottleneck structures, it enjoys both high reconstruction quality and controllability. Furthermore, NANSY does not require any labels associated with speech data such as text and speaker information, but rather uses a new set of analysis features, i.e., wav2vec feature and newly proposed pitch feature, Yingram, which allows for fully self-supervised training. Taking advantage of fully self-supervised training, NANSY can be easily extended to a multilingual setting by simply training it with a multilingual dataset. The experiments show that NANSY can achieve significant improvement in performance in several applications such as zero-shot voice conversion, pitch shift, and time-scale modification.
An Ensemble 1D-CNN-LSTM-GRU Model with Data Augmentation for Speech Emotion Recognition
Dec 10, 2021
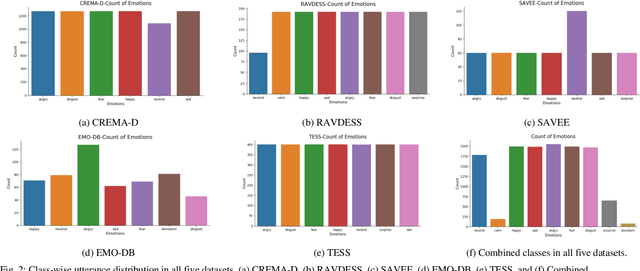
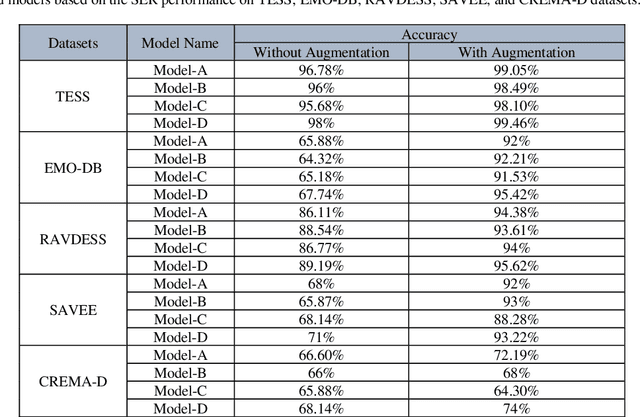
In this paper, we propose an ensemble of deep neural networks along with data augmentation (DA) learned using effective speech-based features to recognize emotions from speech. Our ensemble model is built on three deep neural network-based models. These neural networks are built using the basic local feature acquiring blocks (LFAB) which are consecutive layers of dilated 1D Convolutional Neural networks followed by the max pooling and batch normalization layers. To acquire the long-term dependencies in speech signals further two variants are proposed by adding Gated Recurrent Unit (GRU) and Long Short Term Memory (LSTM) layers respectively. All three network models have consecutive fully connected layers before the final softmax layer for classification. The ensemble model uses a weighted average to provide the final classification. We have utilized five standard benchmark datasets: TESS, EMO-DB, RAVDESS, SAVEE, and CREMA-D for evaluation. We have performed DA by injecting Additive White Gaussian Noise, pitch shifting, and stretching the signal level to generalize the models, and thus increasing the accuracy of the models and reducing the overfitting as well. We handcrafted five categories of features: Mel-frequency cepstral coefficients, Log Mel-Scaled Spectrogram, Zero-Crossing Rate, Chromagram, and statistical Root Mean Square Energy value from each audio sample. These features are used as the input to the LFAB blocks that further extract the hidden local features which are then fed to either fully connected layers or to LSTM or GRU based on the model type to acquire the additional long-term contextual representations. LFAB followed by GRU or LSTM results in better performance compared to the baseline model. The ensemble model achieves the state-of-the-art weighted average accuracy in all the datasets.
Full-Reference Speech Quality Estimation with Attentional Siamese Neural Networks
May 03, 2021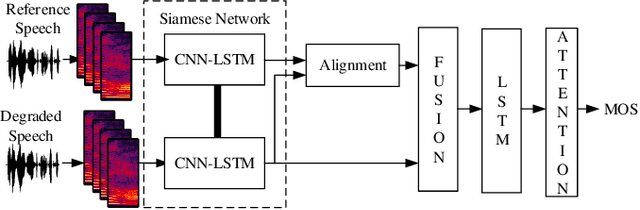
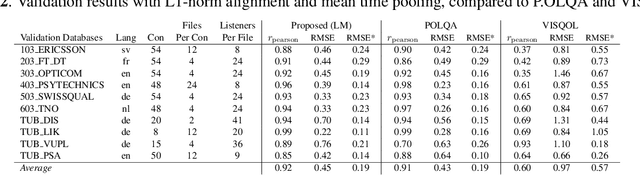
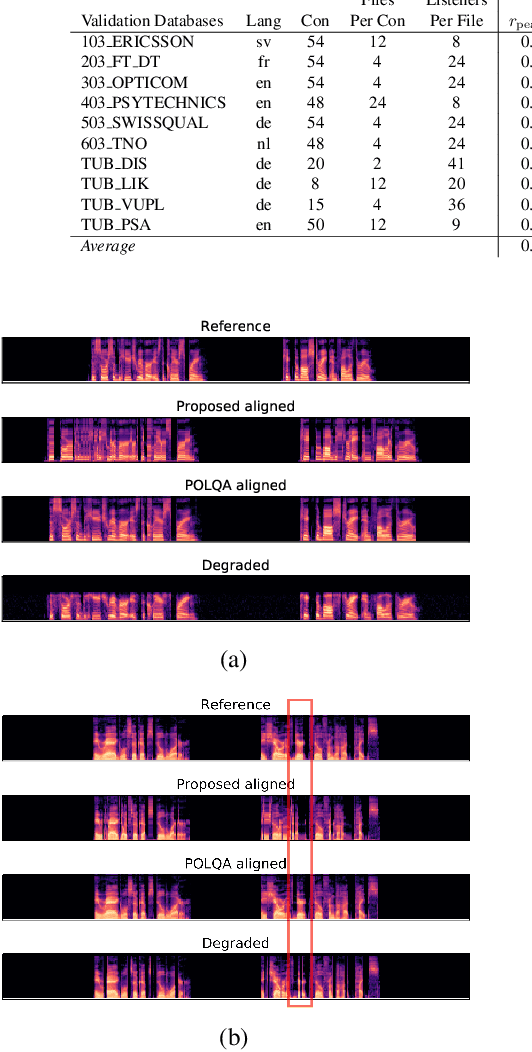
In this paper, we present a full-reference speech quality prediction model with a deep learning approach. The model determines a feature representation of the reference and the degraded signal through a siamese recurrent convolutional network that shares the weights for both signals as input. The resulting features are then used to align the signals with an attention mechanism and are finally combined to estimate the overall speech quality. The proposed network architecture represents a simple solution for the time-alignment problem that occurs for speech signals transmitted through Voice-Over-IP networks and shows how the clean reference signal can be incorporated into speech quality models that are based on end-to-end trained neural networks.
Attention-based Region of Interest (ROI) Detection for Speech Emotion Recognition
Mar 03, 2022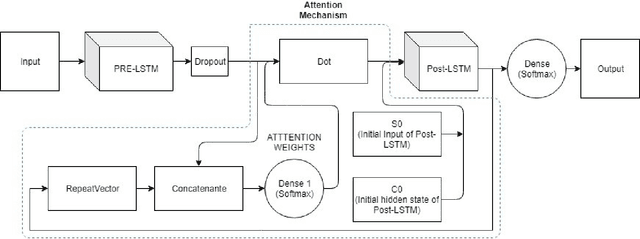
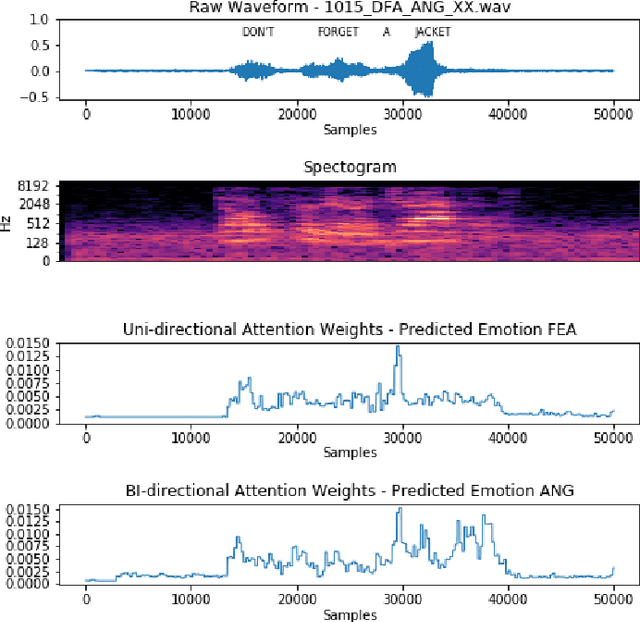

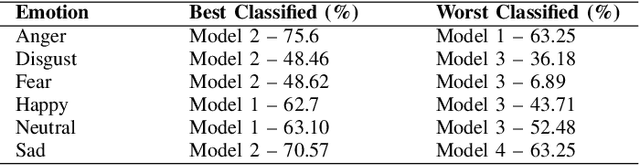
Automatic emotion recognition for real-life appli-cations is a challenging task. Human emotion expressions aresubtle, and can be conveyed by a combination of several emo-tions. In most existing emotion recognition studies, each audioutterance/video clip is labelled/classified in its entirety. However,utterance/clip-level labelling and classification can be too coarseto capture the subtle intra-utterance/clip temporal dynamics. Forexample, an utterance/video clip usually contains only a fewemotion-salient regions and many emotionless regions. In thisstudy, we propose to use attention mechanism in deep recurrentneural networks to detection the Regions-of-Interest (ROI) thatare more emotionally salient in human emotional speech/video,and further estimate the temporal emotion dynamics by aggre-gating those emotionally salient regions-of-interest. We comparethe ROI from audio and video and analyse them. We comparethe performance of the proposed attention networks with thestate-of-the-art LSTM models on multi-class classification task ofrecognizing six basic human emotions, and the proposed attentionmodels exhibit significantly better performance. Furthermore, theattention weight distribution can be used to interpret how anutterance can be expressed as a mixture of possible emotions.
A context-aware knowledge transferring strategy for CTC-based ASR
Oct 12, 2022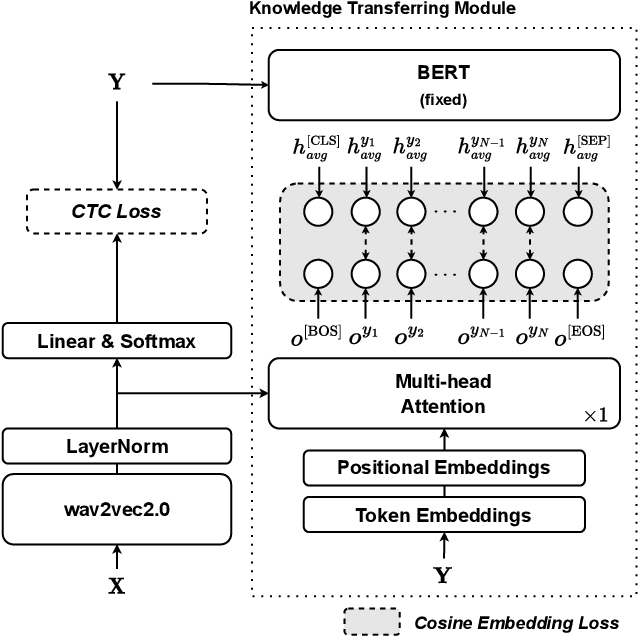
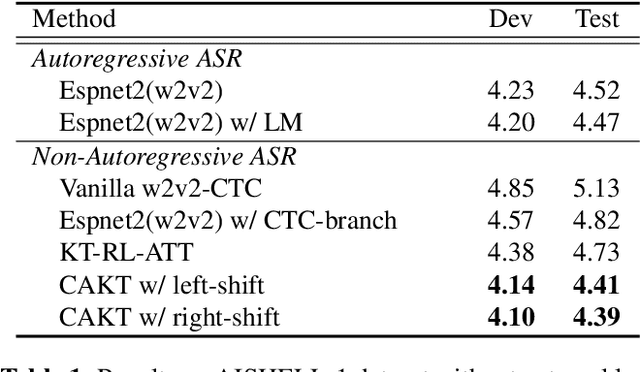
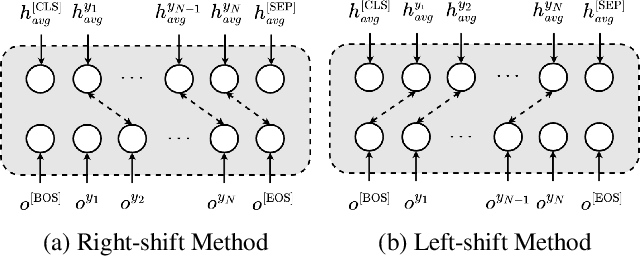
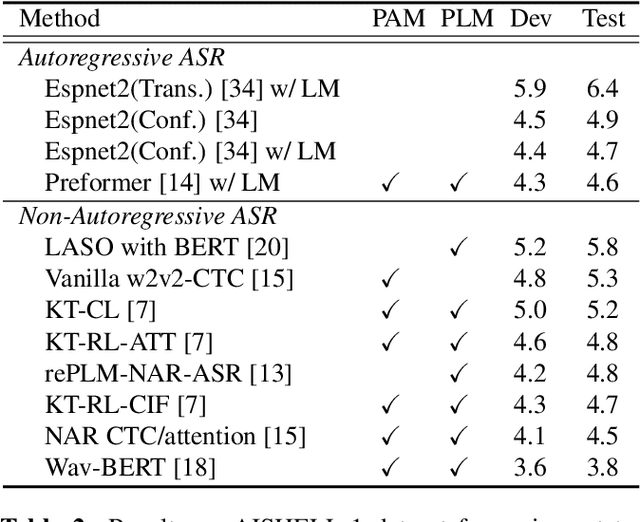
Non-autoregressive automatic speech recognition (ASR) modeling has received increasing attention recently because of its fast decoding speed and superior performance. Among representatives, methods based on the connectionist temporal classification (CTC) are still a dominating stream. However, the theoretically inherent flaw, the assumption of independence between tokens, creates a performance barrier for the school of works. To mitigate the challenge, we propose a context-aware knowledge transferring strategy, consisting of a knowledge transferring module and a context-aware training strategy, for CTC-based ASR. The former is designed to distill linguistic information from a pre-trained language model, and the latter is framed to modulate the limitations caused by the conditional independence assumption. As a result, a knowledge-injected context-aware CTC-based ASR built upon the wav2vec2.0 is presented in this paper. A series of experiments on the AISHELL-1 and AISHELL-2 datasets demonstrate the effectiveness of the proposed method.
Deep scattering network for speech emotion recognition
May 11, 2021
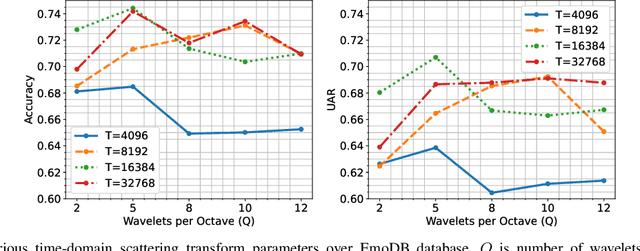

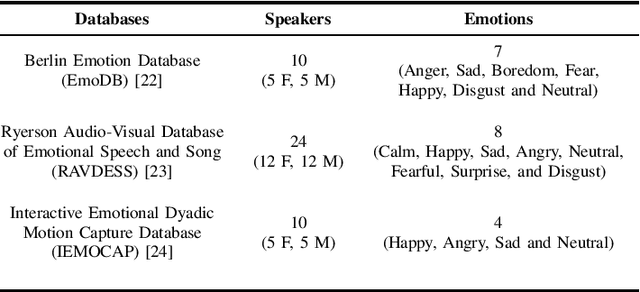
This paper introduces scattering transform for speech emotion recognition (SER). Scattering transform generates feature representations which remain stable to deformations and shifting in time and frequency without much loss of information. In speech, the emotion cues are spread across time and localised in frequency. The time and frequency invariance characteristic of scattering coefficients provides a representation robust against emotion irrelevant variations e.g., different speakers, language, gender etc. while preserving the variations caused by emotion cues. Hence, such a representation captures the emotion information more efficiently from speech. We perform experiments to compare scattering coefficients with standard mel-frequency cepstral coefficients (MFCCs) over different databases. It is observed that frequency scattering performs better than time-domain scattering and MFCCs. We also investigate layer-wise scattering coefficients to analyse the importance of time shift and deformation stable scalogram and modulation spectrum coefficients for SER. We observe that layer-wise coefficients taken independently also perform better than MFCCs.
Configurable Privacy-Preserving Automatic Speech Recognition
Apr 01, 2021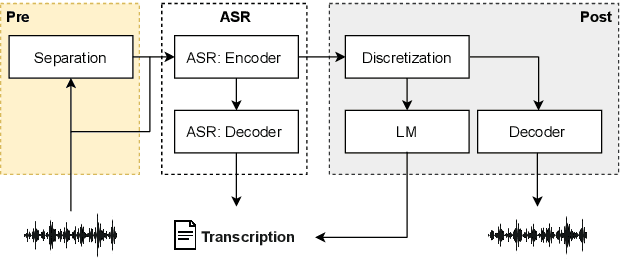

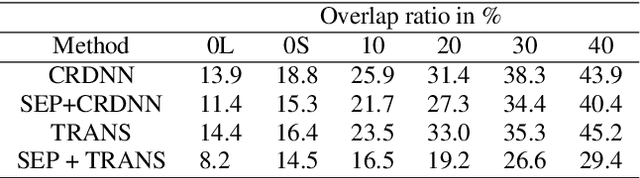
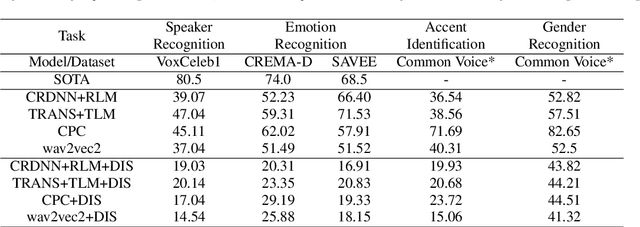
Voice assistive technologies have given rise to far-reaching privacy and security concerns. In this paper we investigate whether modular automatic speech recognition (ASR) can improve privacy in voice assistive systems by combining independently trained separation, recognition, and discretization modules to design configurable privacy-preserving ASR systems. We evaluate privacy concerns and the effects of applying various state-of-the-art techniques at each stage of the system, and report results using task-specific metrics (i.e. WER, ABX, and accuracy). We show that overlapping speech inputs to ASR systems present further privacy concerns, and how these may be mitigated using speech separation and optimization techniques. Our discretization module is shown to minimize paralinguistics privacy leakage from ASR acoustic models to levels commensurate with random guessing. We show that voice privacy can be configurable, and argue this presents new opportunities for privacy-preserving applications incorporating ASR.
Improving User's Sense of Participation in Robot-Driven Dialogue
Oct 18, 2022
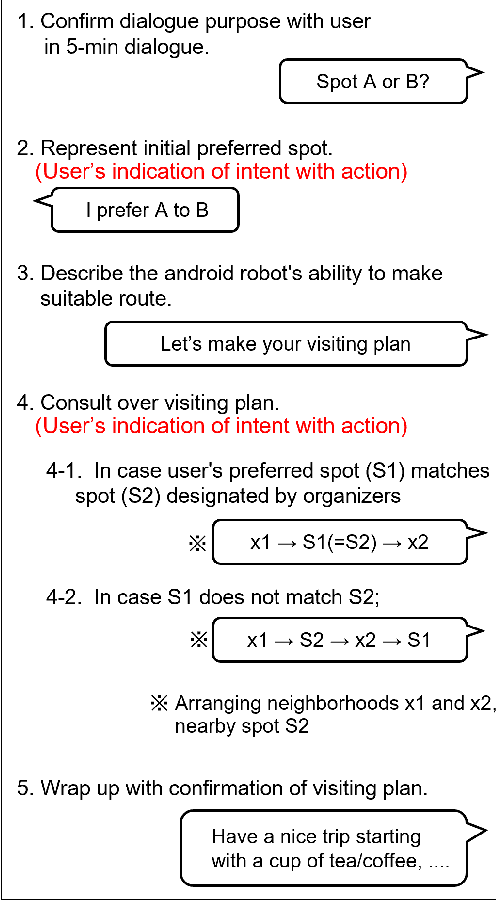
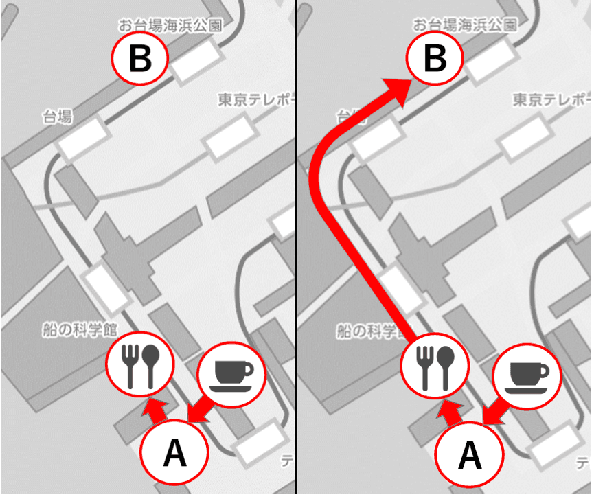
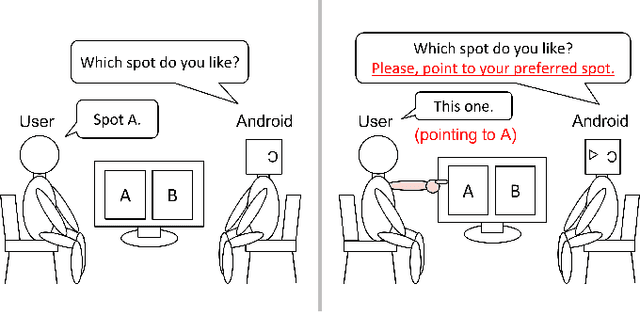
In task-oriented dialogues with symbiotic robots, the robot usually takes the initiative in dialogue progression and topic selection. In such robot-driven dialogue, the user's sense of participation in the dialogue is reduced because the degree of freedom in timing and content of speech is limited, and as a result, the user's familiarity with and trust in the robot as a dialogue partner and the level of dialogue satisfaction decrease. In this study, we constructed a travel agent dialogue system focusing on improving the sense of dialogue participation. At the beginning of the dialogue, the robot tells the user the purpose of the upcoming dialogue and indicates that it is responsible for assisting the user in making decisions. In addition, in situations where users were asked to state their preferences, the robot encourages them to express their intentions with actions, as well as spoken language responses. In addition, we attempted to reduce the sense of discomfort felt toward the android robot by devising a timing control for the robot's detailed movements and facial expressions.
Type Information Utilized Event Detection via Multi-Channel GNNs in Electrical Power Systems
Nov 15, 2022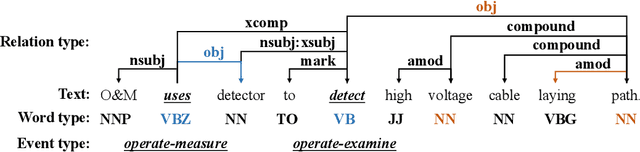

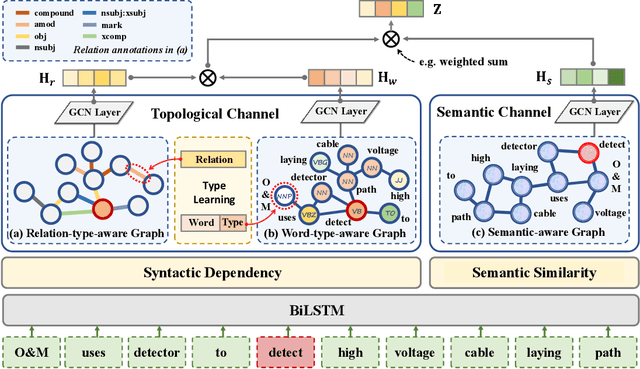
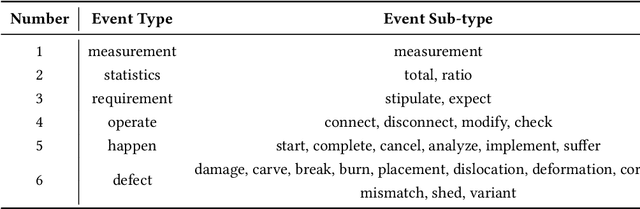
Event detection in power systems aims to identify triggers and event types, which helps relevant personnel respond to emergencies promptly and facilitates the optimization of power supply strategies. However, the limited length of short electrical record texts causes severe information sparsity, and numerous domain-specific terminologies of power systems makes it difficult to transfer knowledge from language models pre-trained on general-domain texts. Traditional event detection approaches primarily focus on the general domain and ignore these two problems in the power system domain. To address the above issues, we propose a Multi-Channel graph neural network utilizing Type information for Event Detection in power systems, named MC-TED, leveraging a semantic channel and a topological channel to enrich information interaction from short texts. Concretely, the semantic channel refines textual representations with semantic similarity, building the semantic information interaction among potential event-related words. The topological channel generates a relation-type-aware graph modeling word dependencies, and a word-type-aware graph integrating part-of-speech tags. To further reduce errors worsened by professional terminologies in type analysis, a type learning mechanism is designed for updating the representations of both the word type and relation type in the topological channel. In this way, the information sparsity and professional term occurrence problems can be alleviated by enabling interaction between topological and semantic information. Furthermore, to address the lack of labeled data in power systems, we built a Chinese event detection dataset based on electrical Power Event texts, named PoE. In experiments, our model achieves compelling results not only on the PoE dataset, but on general-domain event detection datasets including ACE 2005 and MAVEN.
Reconstructing Speech from Real-Time Articulatory MRI Using Neural Vocoders
Apr 23, 2021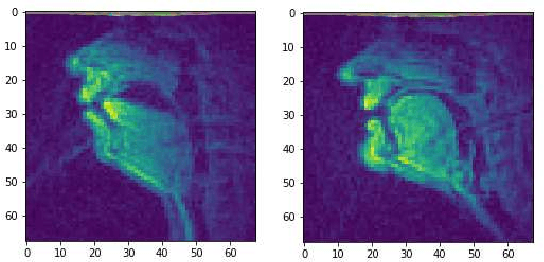
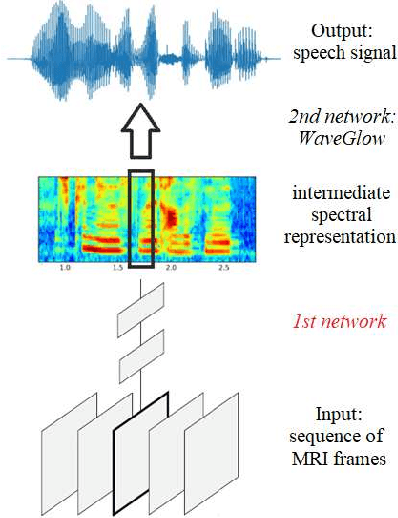
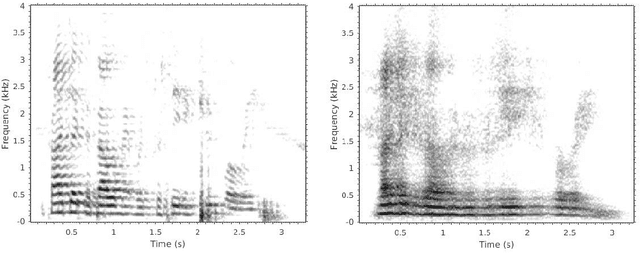

Several approaches exist for the recording of articulatory movements, such as eletromagnetic and permanent magnetic articulagraphy, ultrasound tongue imaging and surface electromyography. Although magnetic resonance imaging (MRI) is more costly than the above approaches, the recent developments in this area now allow the recording of real-time MRI videos of the articulators with an acceptable resolution. Here, we experiment with the reconstruction of the speech signal from a real-time MRI recording using deep neural networks. Instead of estimating speech directly, our networks are trained to output a spectral vector, from which we reconstruct the speech signal using the WaveGlow neural vocoder. We compare the performance of three deep neural architectures for the estimation task, combining convolutional (CNN) and recurrence-based (LSTM) neural layers. Besides the mean absolute error (MAE) of our networks, we also evaluate our models by comparing the speech signals obtained using several objective speech quality metrics like the mean cepstral distortion (MCD), Short-Time Objective Intelligibility (STOI), Perceptual Evaluation of Speech Quality (PESQ) and Signal-to-Distortion Ratio (SDR). The results indicate that our approach can successfully reconstruct the gross spectral shape, but more improvements are needed to reproduce the fine spectral details.