 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Freetalker: Controllable Speech and Text-Driven Gesture Generation Based on Diffusion Models for Enhanced Speaker Naturalness
Jan 07, 2024
Current talking avatars mostly generate co-speech gestures based on audio and text of the utterance, without considering the non-speaking motion of the speaker. Furthermore, previous works on co-speech gesture generation have designed network structures based on individual gesture datasets, which results in limited data volume, compromised generalizability, and restricted speaker movements. To tackle these issues, we introduce FreeTalker, which, to the best of our knowledge, is the first framework for the generation of both spontaneous (e.g., co-speech gesture) and non-spontaneous (e.g., moving around the podium) speaker motions. Specifically, we train a diffusion-based model for speaker motion generation that employs unified representations of both speech-driven gestures and text-driven motions, utilizing heterogeneous data sourced from various motion datasets. During inference, we utilize classifier-free guidance to highly control the style in the clips. Additionally, to create smooth transitions between clips, we utilize DoubleTake, a method that leverages a generative prior and ensures seamless motion blending. Extensive experiments show that our method generates natural and controllable speaker movements. Our code, model, and demo are are available at \url{https://youngseng.github.io/FreeTalker/}.
Utilizing Neural Transducers for Two-Stage Text-to-Speech via Semantic Token Prediction
Jan 03, 2024We propose a novel text-to-speech (TTS) framework centered around a neural transducer. Our approach divides the whole TTS pipeline into semantic-level sequence-to-sequence (seq2seq) modeling and fine-grained acoustic modeling stages, utilizing discrete semantic tokens obtained from wav2vec2.0 embeddings. For a robust and efficient alignment modeling, we employ a neural transducer named token transducer for the semantic token prediction, benefiting from its hard monotonic alignment constraints. Subsequently, a non-autoregressive (NAR) speech generator efficiently synthesizes waveforms from these semantic tokens. Additionally, a reference speech controls temporal dynamics and acoustic conditions at each stage. This decoupled framework reduces the training complexity of TTS while allowing each stage to focus on semantic and acoustic modeling. Our experimental results on zero-shot adaptive TTS demonstrate that our model surpasses the baseline in terms of speech quality and speaker similarity, both objectively and subjectively. We also delve into the inference speed and prosody control capabilities of our approach, highlighting the potential of neural transducers in TTS frameworks.
Data-driven grapheme-to-phoneme representations for a lexicon-free text-to-speech
Jan 19, 2024Grapheme-to-Phoneme (G2P) is an essential first step in any modern, high-quality Text-to-Speech (TTS) system. Most of the current G2P systems rely on carefully hand-crafted lexicons developed by experts. This poses a two-fold problem. Firstly, the lexicons are generated using a fixed phoneme set, usually, ARPABET or IPA, which might not be the most optimal way to represent phonemes for all languages. Secondly, the man-hours required to produce such an expert lexicon are very high. In this paper, we eliminate both of these issues by using recent advances in self-supervised learning to obtain data-driven phoneme representations instead of fixed representations. We compare our lexicon-free approach against strong baselines that utilize a well-crafted lexicon. Furthermore, we show that our data-driven lexicon-free method performs as good or even marginally better than the conventional rule-based or lexicon-based neural G2Ps in terms of Mean Opinion Score (MOS) while using no prior language lexicon or phoneme set, i.e. no linguistic expertise.
Who Said What? An Automated Approach to Analyzing Speech in Preschool Classrooms
Jan 14, 2024Young children spend substantial portions of their waking hours in noisy preschool classrooms. In these environments, children's vocal interactions with teachers are critical contributors to their language outcomes, but manually transcribing these interactions is prohibitive. Using audio from child- and teacher-worn recorders, we propose an automated framework that uses open source software both to classify speakers (ALICE) and to transcribe their utterances (Whisper). We compare results from our framework to those from a human expert for 110 minutes of classroom recordings, including 85 minutes from child-word microphones (n=4 children) and 25 minutes from teacher-worn microphones (n=2 teachers). The overall proportion of agreement, that is, the proportion of correctly classified teacher and child utterances, was .76, with an error-corrected kappa of .50 and a weighted F1 of .76. The word error rate for both teacher and child transcriptions was .15, meaning that 15% of words would need to be deleted, added, or changed to equate the Whisper and expert transcriptions. Moreover, speech features such as the mean length of utterances in words, the proportion of teacher and child utterances that were questions, and the proportion of utterances that were responded to within 2.5 seconds were similar when calculated separately from expert and automated transcriptions. The results suggest substantial progress in analyzing classroom speech that may support children's language development. Future research using natural language processing is underway to improve speaker classification and to analyze results from the application of the automated it framework to a larger dataset containing classroom recordings from 13 children and 4 teachers observed on 17 occasions over one year.
Enhancing dysarthria speech feature representation with empirical mode decomposition and Walsh-Hadamard transform
Dec 30, 2023Dysarthria speech contains the pathological characteristics of vocal tract and vocal fold, but so far, they have not yet been included in traditional acoustic feature sets. Moreover, the nonlinearity and non-stationarity of speech have been ignored. In this paper, we propose a feature enhancement algorithm for dysarthria speech called WHFEMD. It combines empirical mode decomposition (EMD) and fast Walsh-Hadamard transform (FWHT) to enhance features. With the proposed algorithm, the fast Fourier transform of the dysarthria speech is first performed and then followed by EMD to get intrinsic mode functions (IMFs). After that, FWHT is used to output new coefficients and to extract statistical features based on IMFs, power spectral density, and enhanced gammatone frequency cepstral coefficients. To evaluate the proposed approach, we conducted experiments on two public pathological speech databases including UA Speech and TORGO. The results show that our algorithm performed better than traditional features in classification. We achieved improvements of 13.8% (UA Speech) and 3.84% (TORGO), respectively. Furthermore, the incorporation of an imbalanced classification algorithm to address data imbalance has resulted in a 12.18% increase in recognition accuracy. This algorithm effectively addresses the challenges of the imbalanced dataset and non-linearity in dysarthric speech and simultaneously provides a robust representation of the local pathological features of the vocal folds and tracts.
Hyperbolic Distance-Based Speech Separation
Jan 07, 2024In this work, we explore the task of hierarchical distance-based speech separation defined on a hyperbolic manifold. Based on the recent advent of audio-related tasks performed in non-Euclidean spaces, we propose to make use of the Poincar\'e ball to effectively unveil the inherent hierarchical structure found in complex speaker mixtures. We design two sets of experiments in which the distance-based parent sound classes, namely "near" and "far", can contain up to two or three speakers (i.e., children) each. We show that our hyperbolic approach is suitable for unveiling hierarchical structure from the problem definition, resulting in improved child-level separation. We further show that a clear correlation emerges between the notion of hyperbolic certainty (i.e., the distance to the ball's origin) and acoustic semantics such as speaker density, inter-source location, and microphone-to-speaker distance.
ZMM-TTS: Zero-shot Multilingual and Multispeaker Speech Synthesis Conditioned on Self-supervised Discrete Speech Representations
Dec 22, 2023Neural text-to-speech (TTS) has achieved human-like synthetic speech for single-speaker, single-language synthesis. Multilingual TTS systems are limited to resource-rich languages due to the lack of large paired text and studio-quality audio data. In most cases, TTS systems are built using a single speaker's voice. However, there is growing interest in developing systems that can synthesize voices for new speakers using only a few seconds of their speech. This paper presents ZMM-TTS, a multilingual and multispeaker framework utilizing quantized latent speech representations from a large-scale, pre-trained, self-supervised model. Our paper is the first to incorporate the representations from text-based and speech-based self-supervised learning models into multilingual speech synthesis tasks. We conducted comprehensive subjective and objective evaluations through a series of experiments. Our model has been proven effective in terms of speech naturalness and similarity for both seen and unseen speakers in six high-resource languages. We also tested the efficiency of our method on two hypothetical low-resource languages. The results are promising, indicating that our proposed approach can synthesize audio that is intelligible and has a high degree of similarity to the target speaker's voice, even without any training data for the new, unseen language.
USM-Lite: Quantization and Sparsity Aware Fine-tuning for Speech Recognition with Universal Speech Models
Jan 03, 2024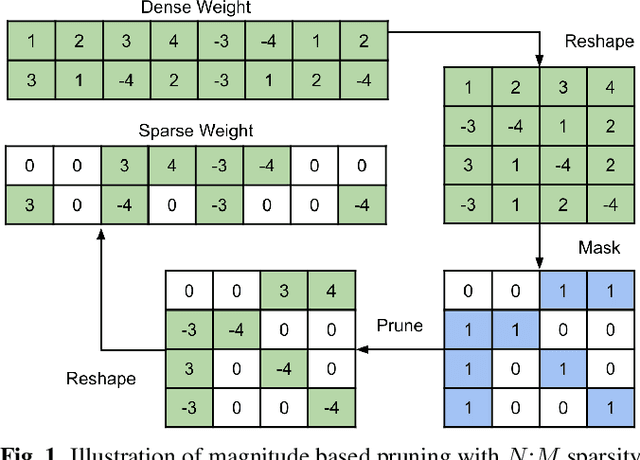
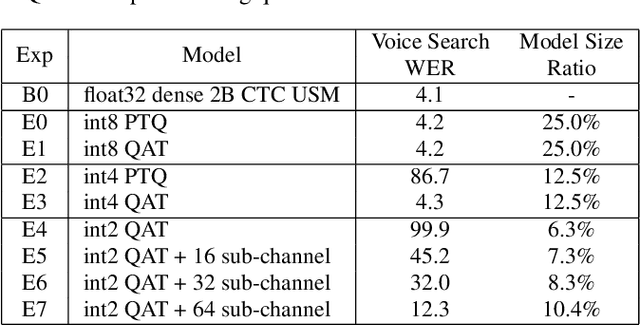
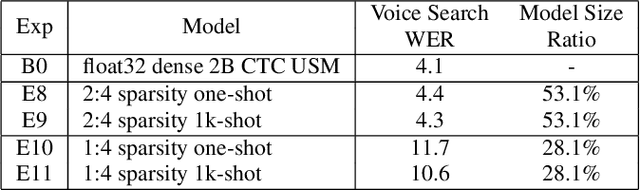
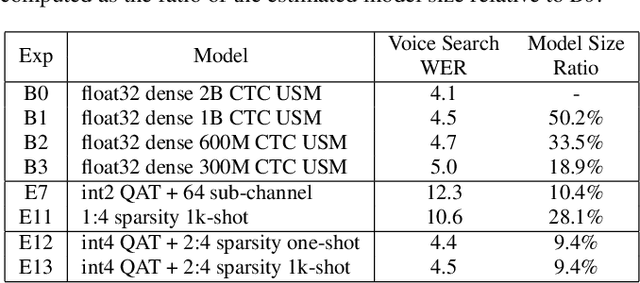
End-to-end automatic speech recognition (ASR) models have seen revolutionary quality gains with the recent development of large-scale universal speech models (USM). However, deploying these massive USMs is extremely expensive due to the enormous memory usage and computational cost. Therefore, model compression is an important research topic to fit USM-based ASR under budget in real-world scenarios. In this study, we propose a USM fine-tuning approach for ASR, with a low-bit quantization and N:M structured sparsity aware paradigm on the model weights, reducing the model complexity from parameter precision and matrix topology perspectives. We conducted extensive experiments with a 2-billion parameter USM on a large-scale voice search dataset to evaluate our proposed method. A series of ablation studies validate the effectiveness of up to int4 quantization and 2:4 sparsity. However, a single compression technique fails to recover the performance well under extreme setups including int2 quantization and 1:4 sparsity. By contrast, our proposed method can compress the model to have 9.4% of the size, at the cost of only 7.3% relative word error rate (WER) regressions. We also provided in-depth analyses on the results and discussions on the limitations and potential solutions, which would be valuable for future studies.
A unified multichannel far-field speech recognition system: combining neural beamforming with attention based end-to-end model
Jan 05, 2024Far-field speech recognition is a challenging task that conventionally uses signal processing beamforming to attack noise and interference problem. But the performance has been found usually limited due to heavy reliance on environmental assumption. In this paper, we propose a unified multichannel far-field speech recognition system that combines the neural beamforming and transformer-based Listen, Spell, Attend (LAS) speech recognition system, which extends the end-to-end speech recognition system further to include speech enhancement. Such framework is then jointly trained to optimize the final objective of interest. Specifically, factored complex linear projection (fCLP) has been adopted to form the neural beamforming. Several pooling strategies to combine look directions are then compared in order to find the optimal approach. Moreover, information of the source direction is also integrated in the beamforming to explore the usefulness of source direction as a prior, which is usually available especially in multi-modality scenario. Experiments on different microphone array geometry are conducted to evaluate the robustness against spacing variance of microphone array. Large in-house databases are used to evaluate the effectiveness of the proposed framework and the proposed method achieve 19.26\% improvement when compared with a strong baseline.
Joint Unsupervised and Supervised Training for Automatic Speech Recognition via Bilevel Optimization
Jan 13, 2024In this paper, we present a novel bilevel optimization-based training approach to training acoustic models for automatic speech recognition (ASR) tasks that we term {bi-level joint unsupervised and supervised training (BL-JUST)}. {BL-JUST employs a lower and upper level optimization with an unsupervised loss and a supervised loss respectively, leveraging recent advances in penalty-based bilevel optimization to solve this challenging ASR problem with affordable complexity and rigorous convergence guarantees.} To evaluate BL-JUST, extensive experiments on the LibriSpeech and TED-LIUM v2 datasets have been conducted. BL-JUST achieves superior performance over the commonly used pre-training followed by fine-tuning strategy.