 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Scribosermo: Fast Speech-to-Text models for German and other Languages
Oct 15, 2021
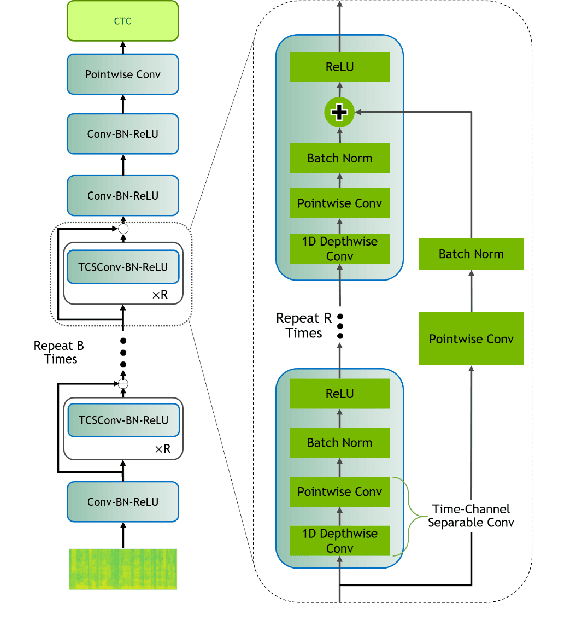


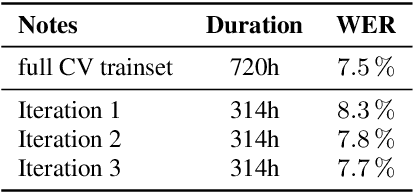
Recent Speech-to-Text models often require a large amount of hardware resources and are mostly trained in English. This paper presents Speech-to-Text models for German, as well as for Spanish and French with special features: (a) They are small and run in real-time on microcontrollers like a RaspberryPi. (b) Using a pretrained English model, they can be trained on consumer-grade hardware with a relatively small dataset. (c) The models are competitive with other solutions and outperform them in German. In this respect, the models combine advantages of other approaches, which only include a subset of the presented features. Furthermore, the paper provides a new library for handling datasets, which is focused on easy extension with additional datasets and shows an optimized way for transfer-learning new languages using a pretrained model from another language with a similar alphabet.
Efficient Transformer for Direct Speech Translation
Jul 07, 2021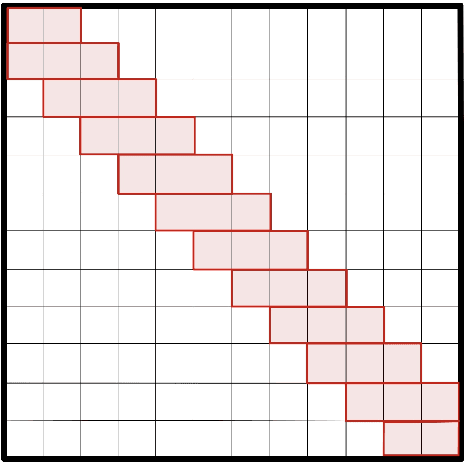
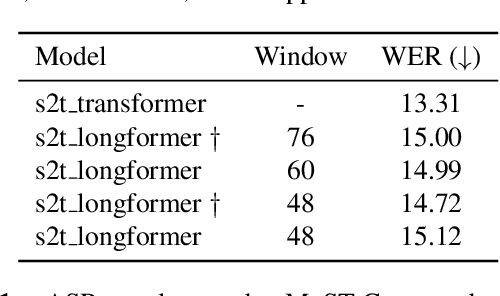
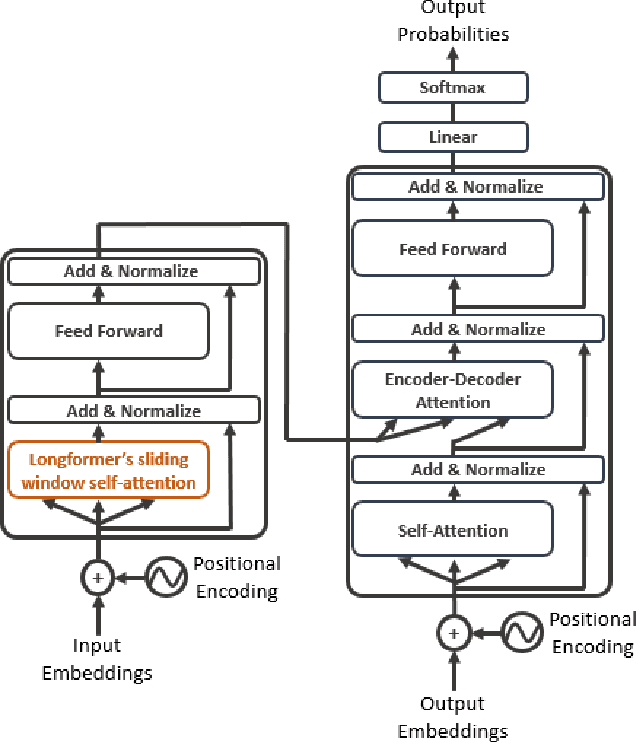
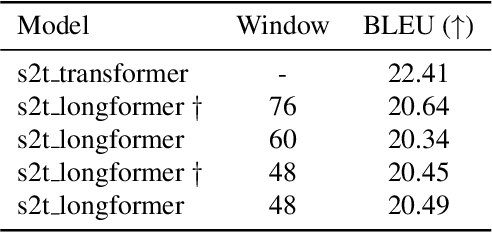
The advent of Transformer-based models has surpassed the barriers of text. When working with speech, we must face a problem: the sequence length of an audio input is not suitable for the Transformer. To bypass this problem, a usual approach is adding strided convolutional layers, to reduce the sequence length before using the Transformer. In this paper, we propose a new approach for direct Speech Translation, where thanks to an efficient Transformer we can work with a spectrogram without having to use convolutional layers before the Transformer. This allows the encoder to learn directly from the spectrogram and no information is lost. We have created an encoder-decoder model, where the encoder is an efficient Transformer -- the Longformer -- and the decoder is a traditional Transformer decoder. Our results, which are close to the ones obtained with the standard approach, show that this is a promising research direction.
Privacy attacks for automatic speech recognition acoustic models in a federated learning framework
Nov 06, 2021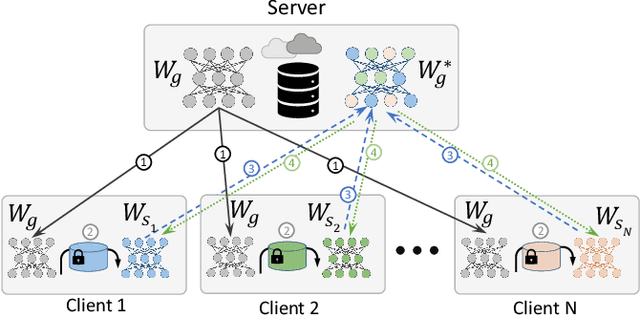
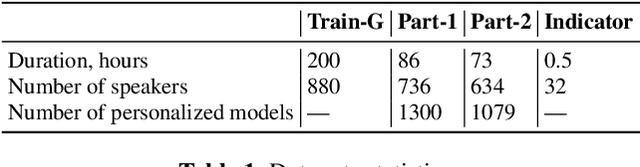
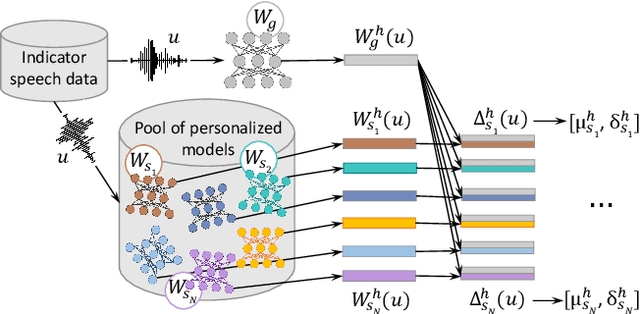

This paper investigates methods to effectively retrieve speaker information from the personalized speaker adapted neural network acoustic models (AMs) in automatic speech recognition (ASR). This problem is especially important in the context of federated learning of ASR acoustic models where a global model is learnt on the server based on the updates received from multiple clients. We propose an approach to analyze information in neural network AMs based on a neural network footprint on the so-called Indicator dataset. Using this method, we develop two attack models that aim to infer speaker identity from the updated personalized models without access to the actual users' speech data. Experiments on the TED-LIUM 3 corpus demonstrate that the proposed approaches are very effective and can provide equal error rate (EER) of 1-2%.
Improving Channel Decorrelation for Multi-Channel Target Speech Extraction
Jun 06, 2021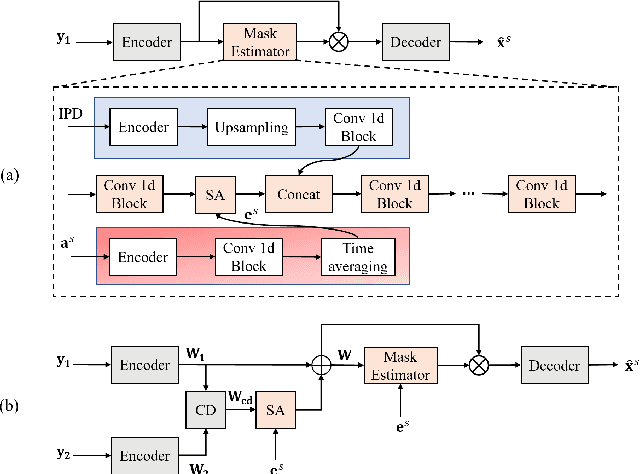
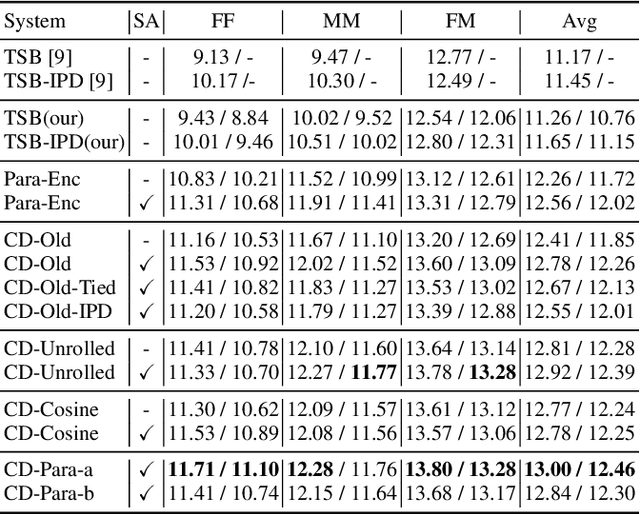
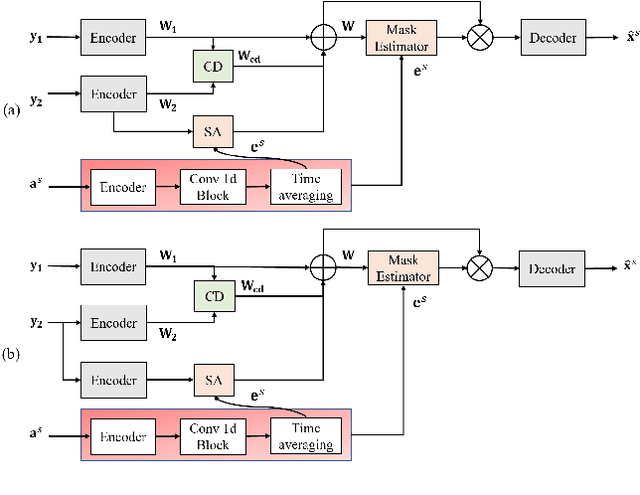
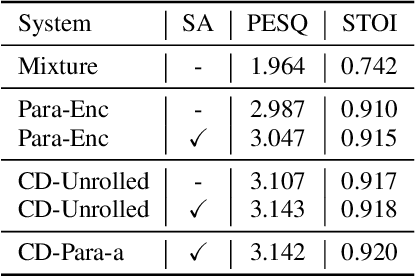
Target speech extraction has attracted widespread attention. When microphone arrays are available, the additional spatial information can be helpful in extracting the target speech. We have recently proposed a channel decorrelation (CD) mechanism to extract the inter-channel differential information to enhance the reference channel encoder representation. Although the proposed mechanism has shown promising results for extracting the target speech from mixtures, the extraction performance is still limited by the nature of the original decorrelation theory. In this paper, we propose two methods to broaden the horizon of the original channel decorrelation, by replacing the original softmax-based inter-channel similarity between encoder representations, using an unrolled probability and a normalized cosine-based similarity at the dimensional-level. Moreover, new combination strategies of the CD-based spatial information and target speaker adaptation of parallel encoder outputs are also investigated. Experiments on the reverberant WSJ0 2-mix show that the improved CD can result in more discriminative differential information and the new adaptation strategy is also very effective to improve the target speech extraction.
The NTNU System for Formosa Speech Recognition Challenge 2020
Apr 14, 2021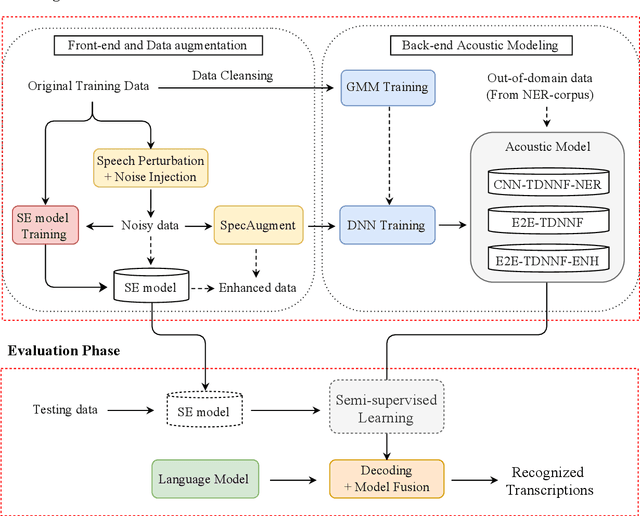
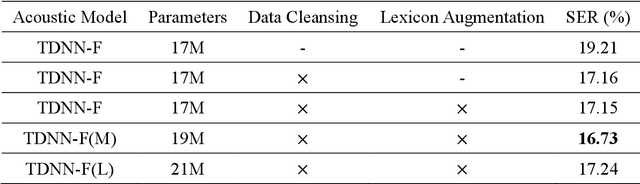
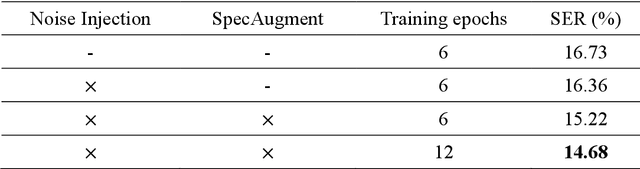
This paper describes the NTNU ASR system participating in the Formosa Speech Recognition Challenge 2020 (FSR-2020) supported by the Formosa Speech in the Wild project (FSW). FSR-2020 aims at fostering the development of Taiwanese speech recognition. Apart from the issues on tonal and dialectical variations of the Taiwanese language, speech artificially contaminated with different types of real-world noise also has to be dealt with in the final test stage; all of these make FSR-2020 much more challenging than before. To work around the under-resourced issue, the main technical aspects of our ASR system include various deep learning techniques, such as transfer learning, semi-supervised learning, front-end speech enhancement and model ensemble, as well as data cleansing and data augmentation conducted on the training data. With the best configuration, our system takes the first place among all participating systems in Track 3.
UX-NET: Filter-and-Process-based Improved U-Net for Real-time Time-domain Audio Separation
Oct 28, 2022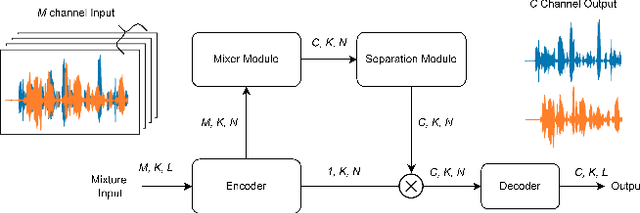
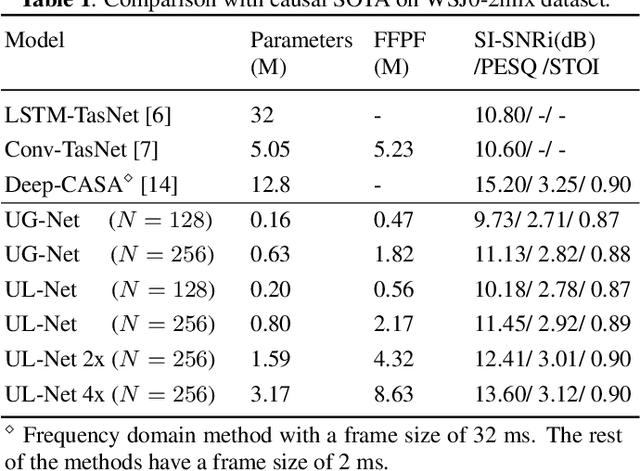
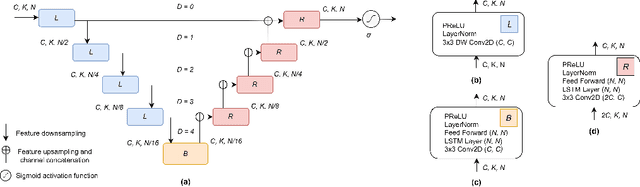
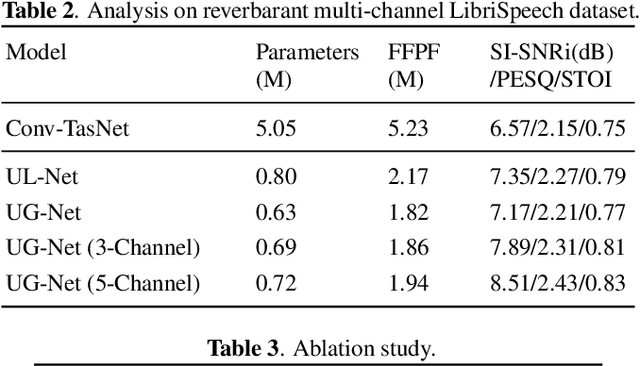
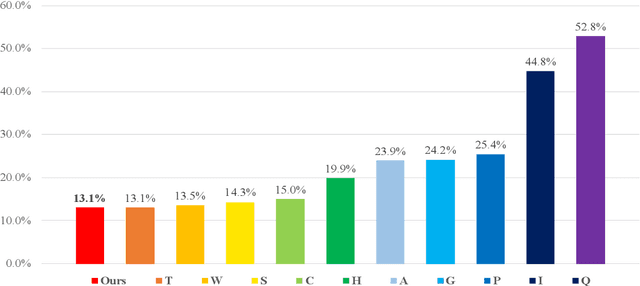
This study presents UX-Net, a time-domain audio separation network (TasNet) based on a modified U-Net architecture. The proposed UX-Net works in real-time and handles either single or multi-microphone input. Inspired by the filter-and-process-based human auditory behavior, the proposed system introduces novel mixer and separation modules, which result in cost and memory efficient modeling of speech sources. The mixer module combines encoded input in a latent feature space and outputs a desired number of output streams. Then, in the separation module, a modified U-Net (UX) block is applied. The UX block first filters the encoded input at various resolutions followed by aggregating the filtered information and applying recurrent processing to estimate masks of separated sources. The letter 'X' in UX-Net is a name placeholder for the type of recurrent layer employed in the UX block. Empirical findings on the WSJ0-2mix benchmark dataset show that one of the UX-Net configurations outperforms the state-of-the-art Conv-TasNet system by 0.85 dB SI-SNR while using only 16% of the model parameters, 58% fewer computations, and maintaining low latency.
InterMPL: Momentum Pseudo-Labeling with Intermediate CTC Loss
Nov 02, 2022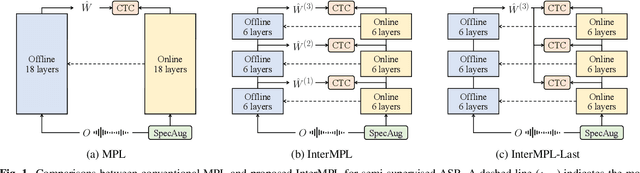
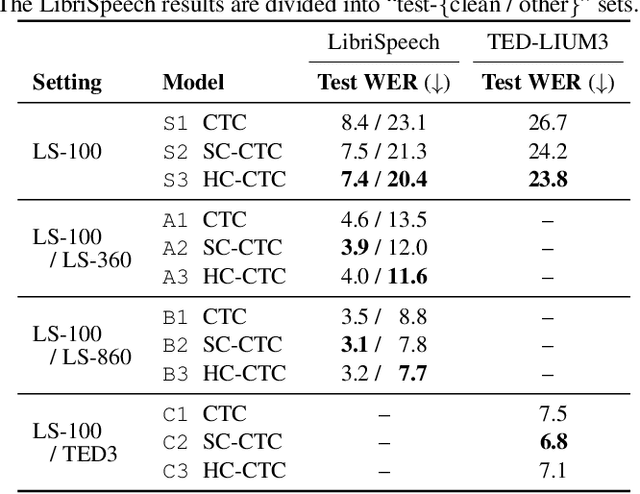
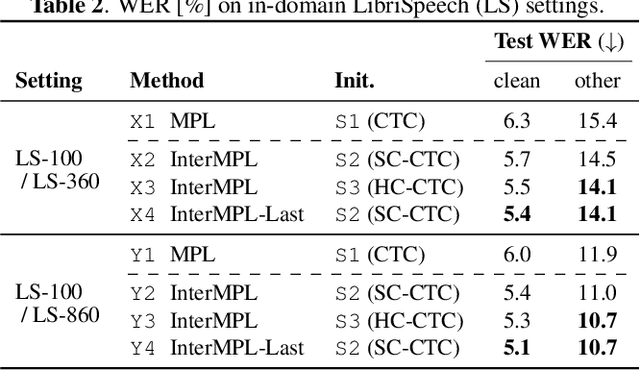
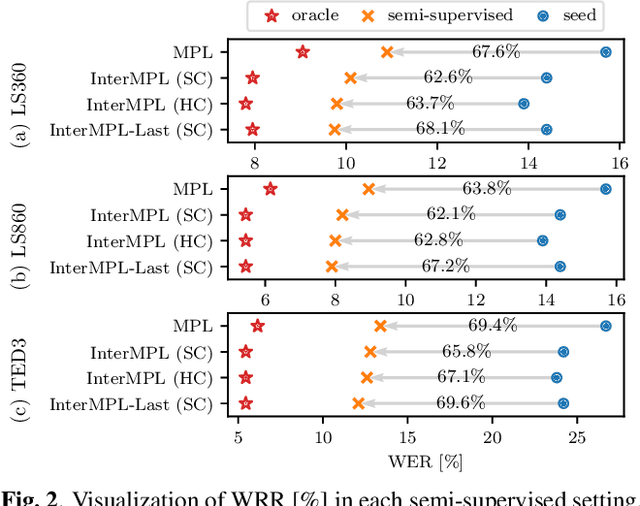
This paper presents InterMPL, a semi-supervised learning method of end-to-end automatic speech recognition (ASR) that performs pseudo-labeling (PL) with intermediate supervision. Momentum PL (MPL) trains a connectionist temporal classification (CTC)-based model on unlabeled data by continuously generating pseudo-labels on the fly and improving their quality. In contrast to autoregressive formulations, such as the attention-based encoder-decoder and transducer, CTC is well suited for MPL, or PL-based semi-supervised ASR in general, owing to its simple/fast inference algorithm and robustness against generating collapsed labels. However, CTC generally yields inferior performance than the autoregressive models due to the conditional independence assumption, thereby limiting the performance of MPL. We propose to enhance MPL by introducing intermediate loss, inspired by the recent advances in CTC-based modeling. Specifically, we focus on self-conditional and hierarchical conditional CTC, that apply auxiliary CTC losses to intermediate layers such that the conditional independence assumption is explicitly relaxed. We also explore how pseudo-labels should be generated and used as supervision for intermediate losses. Experimental results in different semi-supervised settings demonstrate that the proposed approach outperforms MPL and improves an ASR model by up to a 12.1% absolute performance gain. In addition, our detailed analysis validates the importance of the intermediate loss.
BECTRA: Transducer-based End-to-End ASR with BERT-Enhanced Encoder
Nov 02, 2022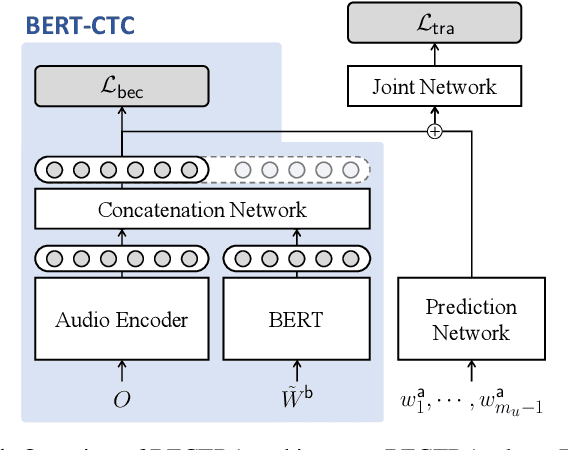

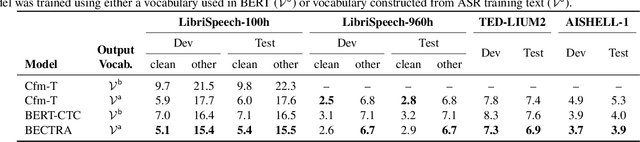
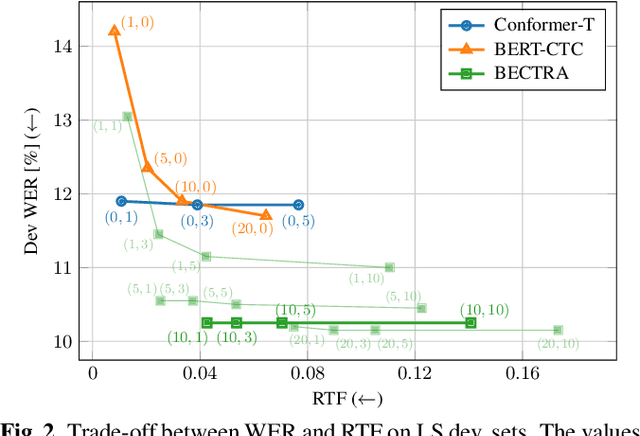
We present BERT-CTC-Transducer (BECTRA), a novel end-to-end automatic speech recognition (E2E-ASR) model formulated by the transducer with a BERT-enhanced encoder. Integrating a large-scale pre-trained language model (LM) into E2E-ASR has been actively studied, aiming to utilize versatile linguistic knowledge for generating accurate text. One crucial factor that makes this integration challenging lies in the vocabulary mismatch; the vocabulary constructed for a pre-trained LM is generally too large for E2E-ASR training and is likely to have a mismatch against a target ASR domain. To overcome such an issue, we propose BECTRA, an extended version of our previous BERT-CTC, that realizes BERT-based E2E-ASR using a vocabulary of interest. BECTRA is a transducer-based model, which adopts BERT-CTC for its encoder and trains an ASR-specific decoder using a vocabulary suitable for a target task. With the combination of the transducer and BERT-CTC, we also propose a novel inference algorithm for taking advantage of both autoregressive and non-autoregressive decoding. Experimental results on several ASR tasks, varying in amounts of data, speaking styles, and languages, demonstrate that BECTRA outperforms BERT-CTC by effectively dealing with the vocabulary mismatch while exploiting BERT knowledge.
Investigating data partitioning strategies for crosslinguistic low-resource ASR evaluation
Aug 26, 2022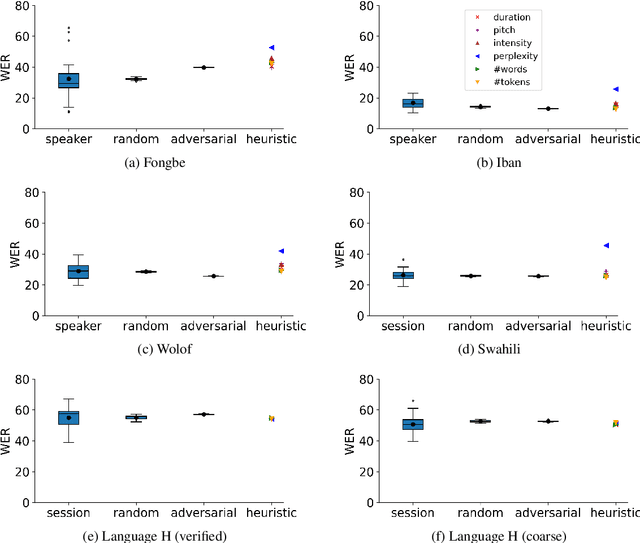
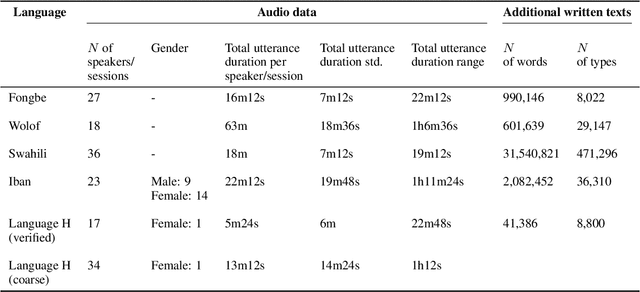
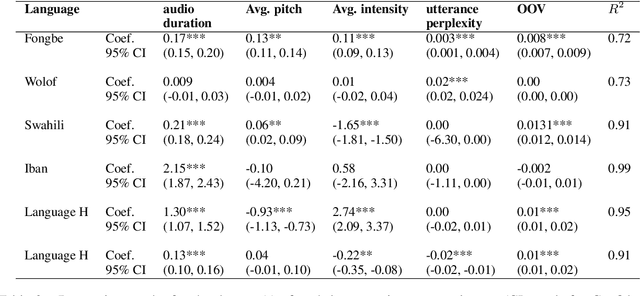
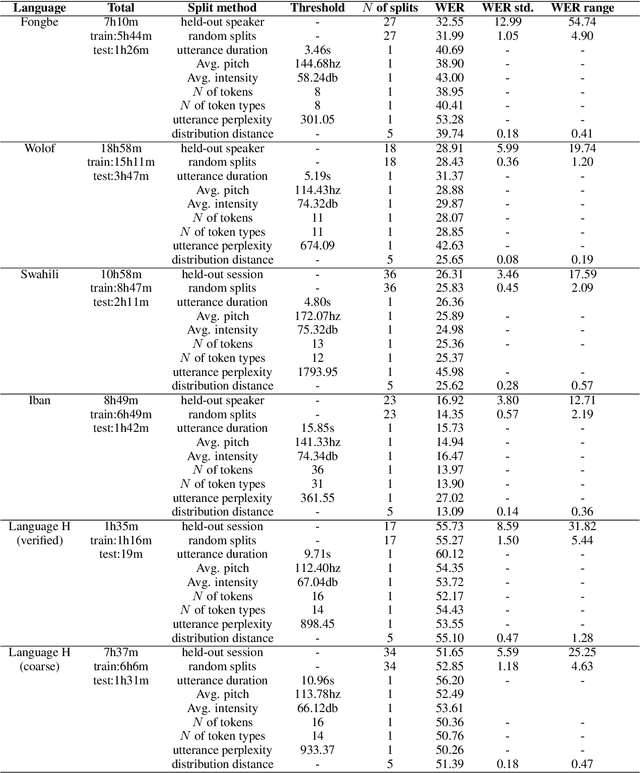
Many automatic speech recognition (ASR) data sets include a single pre-defined test set consisting of one or more speakers whose speech never appears in the training set. This "hold-speaker(s)-out" data partitioning strategy, however, may not be ideal for data sets in which the number of speakers is very small. This study investigates ten different data split methods for five languages with minimal ASR training resources. We find that (1) model performance varies greatly depending on which speaker is selected for testing; (2) the average word error rate (WER) across all held-out speakers is comparable not only to the average WER over multiple random splits but also to any given individual random split; (3) WER is also generally comparable when the data is split heuristically or adversarially; (4) utterance duration and intensity are comparatively more predictive factors of variability regardless of the data split. These results suggest that the widely used hold-speakers-out approach to ASR data partitioning can yield results that do not reflect model performance on unseen data or speakers. Random splits can yield more reliable and generalizable estimates when facing data sparsity.
Multilingual Speech Translation with Unified Transformer: Huawei Noah's Ark Lab at IWSLT 2021
Jun 22, 2021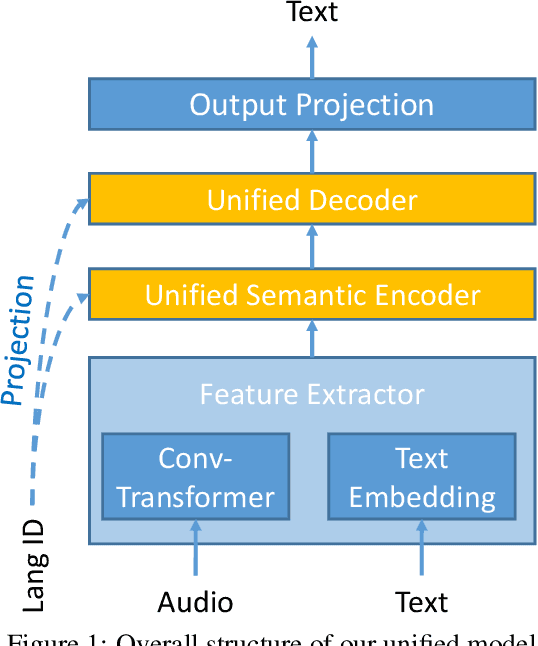
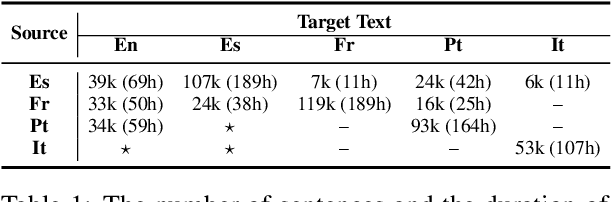
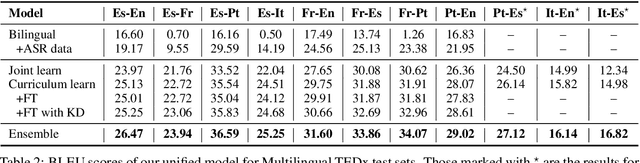
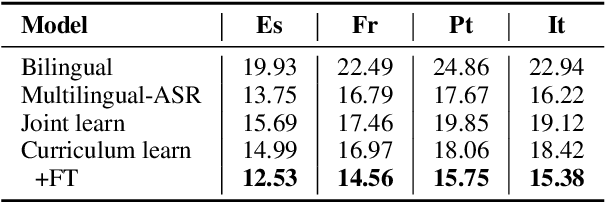
This paper describes the system submitted to the IWSLT 2021 Multilingual Speech Translation (MultiST) task from Huawei Noah's Ark Lab. We use a unified transformer architecture for our MultiST model, so that the data from different modalities (i.e., speech and text) and different tasks (i.e., Speech Recognition, Machine Translation, and Speech Translation) can be exploited to enhance the model's ability. Specifically, speech and text inputs are firstly fed to different feature extractors to extract acoustic and textual features, respectively. Then, these features are processed by a shared encoder--decoder architecture. We apply several training techniques to improve the performance, including multi-task learning, task-level curriculum learning, data augmentation, etc. Our final system achieves significantly better results than bilingual baselines on supervised language pairs and yields reasonable results on zero-shot language pairs.