 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Predicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation
Oct 31, 2022
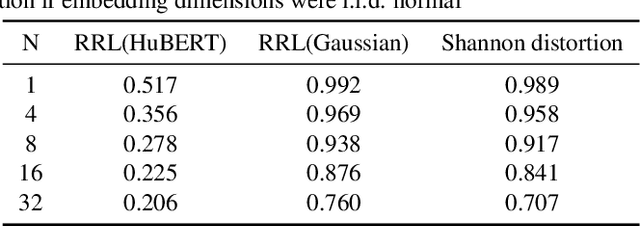
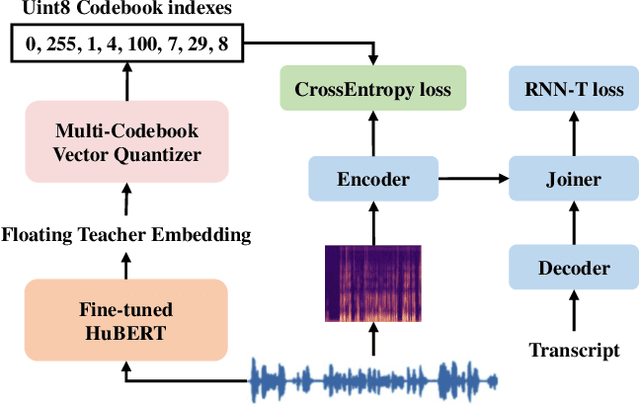

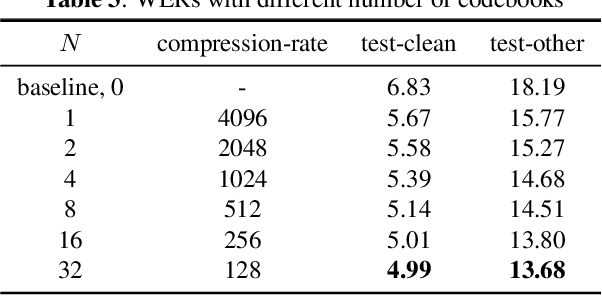
Knowledge distillation(KD) is a common approach to improve model performance in automatic speech recognition (ASR), where a student model is trained to imitate the output behaviour of a teacher model. However, traditional KD methods suffer from teacher label storage issue, especially when the training corpora are large. Although on-the-fly teacher label generation tackles this issue, the training speed is significantly slower as the teacher model has to be evaluated every batch. In this paper, we reformulate the generation of teacher label as a codec problem. We propose a novel Multi-codebook Vector Quantization (MVQ) approach that compresses teacher embeddings to codebook indexes (CI). Based on this, a KD training framework (MVQ-KD) is proposed where a student model predicts the CI generated from the embeddings of a self-supervised pre-trained teacher model. Experiments on the LibriSpeech clean-100 hour show that MVQ-KD framework achieves comparable performance as traditional KD methods (l1, l2), while requiring 256 times less storage. When the full LibriSpeech dataset is used, MVQ-KD framework results in 13.8% and 8.2% relative word error rate reductions (WERRs) for non -streaming transducer on test-clean and test-other and 4.0% and 4.9% for streaming transducer. The implementation of this work is already released as a part of the open-source project icefall.
FlowVocoder: A small Footprint Neural Vocoder based Normalizing flow for Speech Synthesis
Sep 27, 2021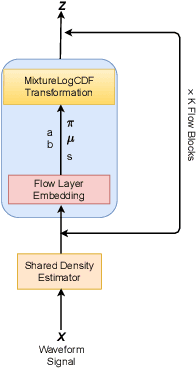

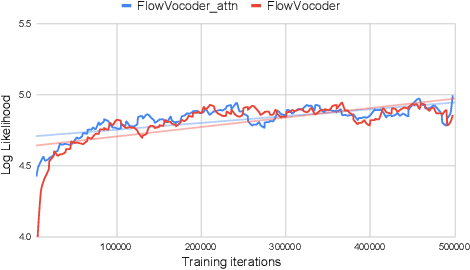
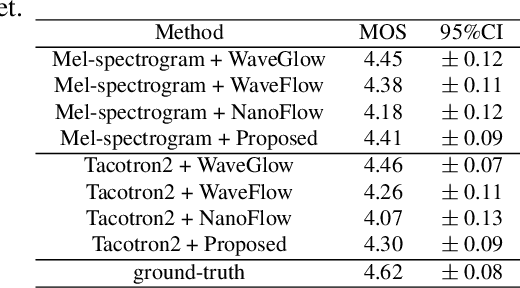
Recently, non-autoregressive neural vocoders have provided remarkable performance in generating high-fidelity speech and have been able to produce synthetic speech in real-time. However, non-autoregressive neural vocoders such as WaveGlow are far behind autoregressive neural vocoders like WaveFlow in terms of modeling audio signals due to their limitation in expressiveness. In addition, though NanoFlow is a state-of-the-art autoregressive neural vocoder that has immensely small parameters, its performance is marginally lower than WaveFlow. Therefore, in this paper, we propose a new type of autoregressive neural vocoder called FlowVocoder, which has a small memory footprint and is able to generate high-fidelity audio in real-time. Our proposed model improves the expressiveness of flow blocks by operating a mixture of Cumulative Distribution Function(CDF) for bipartite transformation. Hence, the proposed model is capable of modeling waveform signals as well as WaveFlow, while its memory footprint is much smaller thanWaveFlow. As shown in experiments, FlowVocoder achieves competitive results with baseline methods in terms of both subjective and objective evaluation, also, it is more suitable for real-time text-to-speech applications.
Preserving the beamforming effect for spatial cue-based pseudo-binaural dereverberation of a single source
Aug 10, 2022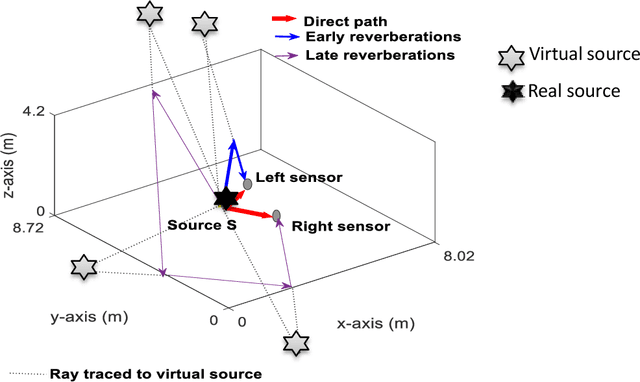

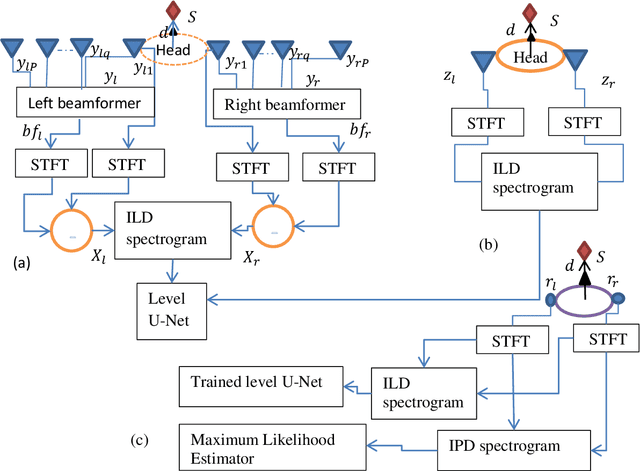
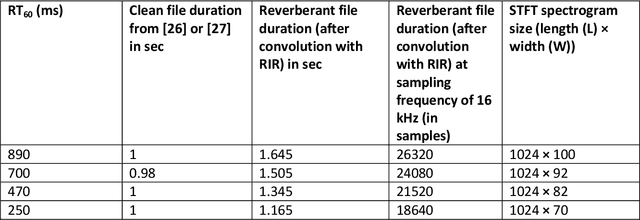
Reverberations are unavoidable in enclosures, resulting in reduced intelligibility for hearing impaired and non native listeners and even for the normal hearing listeners in noisy circumstances. It also degrades the performance of machine listening applications. In this paper, we propose a novel approach of binaural dereverberation of a single speech source, using the differences in the interaural cues of the direct path signal and the reverberations. Two beamformers, spaced at an interaural distance, are used to extract the reverberations from the reverberant speech. The interaural cues generated by these reverberations and those generated by the direct path signal act as a two class dataset, used for the training of U-Net (a deep convolutional neural network). After its training, the beamformers are removed and the trained U-Net along with the maximum likelihood estimation (MLE) algorithm is used to discriminate between the direct path cues from the reverberation cues, when the system is exposed to the interaural spectrogram of the reverberant speech signal. Our proposed model has outperformed the classical signal processing dereverberation model weighted prediction error in terms of cepstral distance (CEP), frequency weighted segmental signal to noise ratio (FWSEGSNR) and signal to reverberation modulation energy ratio (SRMR) by 1.4 points, 8 dB and 0.6dB. It has achieved better performance than the deep learning based dereverberation model by gaining 1.3 points improvement in CEP with comparable FWSEGSNR, using training dataset which is almost 8 times smaller than required for that model. The proposed model also sustained its performance under relatively similar unseen acoustic conditions and at positions in the vicinity of its training position.
Dürfen Maschinen denken (können)? Warum Künstliche Intelligenz eine Ethik braucht. (Are Machines Allowed to (be able to) Think? Why Artificial Intelligence Needs Ethics)
Aug 15, 2022Speech manuscript (German + English) of the impulse lecture for the panel discussion "May machines (be able to) think?" at the 102nd Katholikentag on May 28, 2022 in Stuttgart. Panel: Winfried Kretschmann (MdL, Prime Minister Baden-W\"urttemberg, Stuttgart), Ursula Nothelle-Wildfeuer (Freiburg), Michael Resch (Stuttgart),Karsten Wendland (Aalen). Moderation: Stefanie Rentsch (Fulda). Advocate of the audience: Verena Neuhausen (Stuttgart).
The NTNU System for Formosa Speech Recognition Challenge 2020
Apr 14, 2021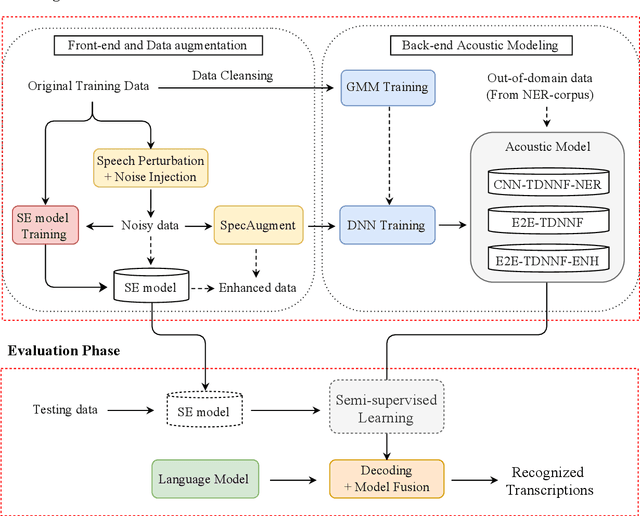
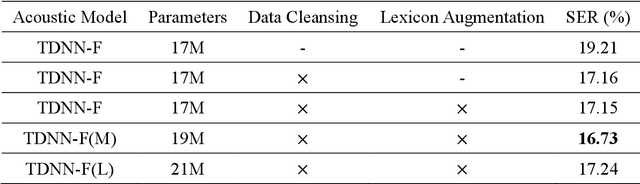
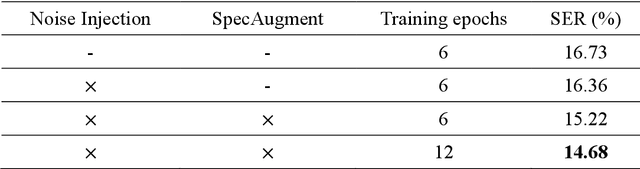
This paper describes the NTNU ASR system participating in the Formosa Speech Recognition Challenge 2020 (FSR-2020) supported by the Formosa Speech in the Wild project (FSW). FSR-2020 aims at fostering the development of Taiwanese speech recognition. Apart from the issues on tonal and dialectical variations of the Taiwanese language, speech artificially contaminated with different types of real-world noise also has to be dealt with in the final test stage; all of these make FSR-2020 much more challenging than before. To work around the under-resourced issue, the main technical aspects of our ASR system include various deep learning techniques, such as transfer learning, semi-supervised learning, front-end speech enhancement and model ensemble, as well as data cleansing and data augmentation conducted on the training data. With the best configuration, our system takes the first place among all participating systems in Track 3.
HiFi-WaveGAN: Generative Adversarial Network with Auxiliary Spectrogram-Phase Loss for High-Fidelity Singing Voice Generation
Oct 26, 2022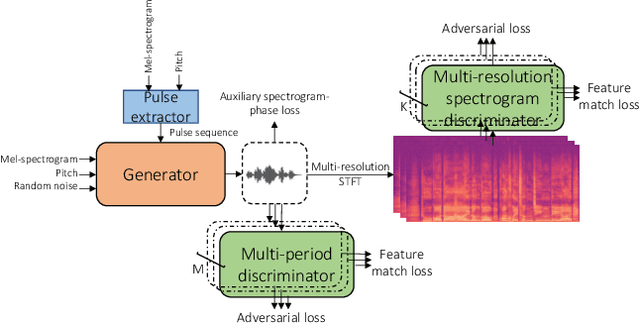
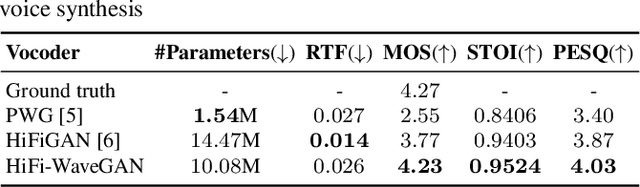
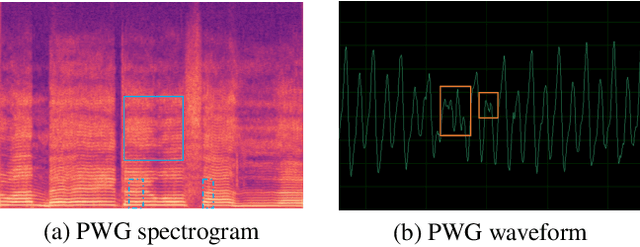
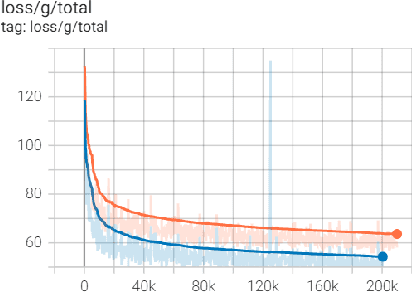
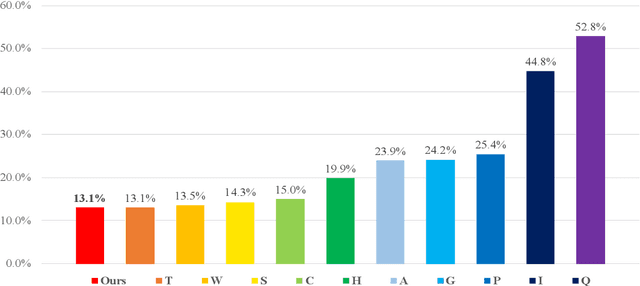
Entertainment-oriented singing voice synthesis (SVS) requires a vocoder to generate high-fidelity (e.g. 48kHz) audio. However, most text-to-speech (TTS) vocoders cannot work well in this scenario even if the neural vocoder for TTS has achieved significant progress. In this paper, we propose HiFi-WaveGAN which is designed for synthesizing the 48kHz high-quality singing voices from the full-band mel-spectrogram in real-time. Specifically, it consists of a generator improved from WaveNet, a multi-period discriminator same to HiFiGAN, and a multi-resolution spectrogram discriminator borrowed from UnivNet. To better reconstruct the high-frequency part from the full-band mel-spectrogram, we design a novel auxiliary spectrogram-phase loss to train the neural network, which can also accelerate the training process. The experimental result shows that our proposed HiFi-WaveGAN significantly outperforms other neural vocoders such as Parallel WaveGAN (PWG) and HiFiGAN in the mean opinion score (MOS) metric for the 48kHz SVS task. And a comparative study of HiFi-WaveGAN with/without phase loss term proves that phase loss indeed improves the training speed. Besides, we also compare the spectrogram generated by our HiFi-WaveGAN and PWG, which shows our HiFi-WaveGAN has a more powerful ability to model the high-frequency parts.
CCC-wav2vec 2.0: Clustering aided Cross Contrastive Self-supervised learning of speech representations
Oct 05, 2022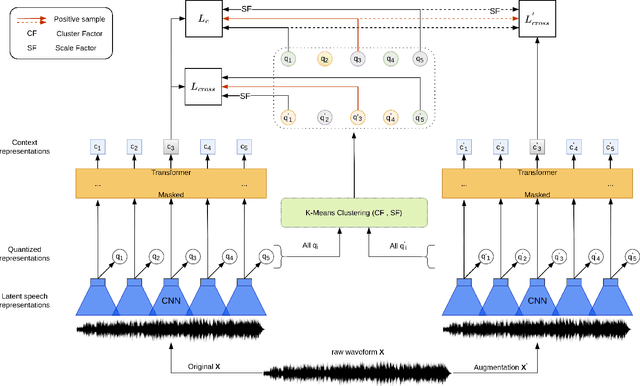
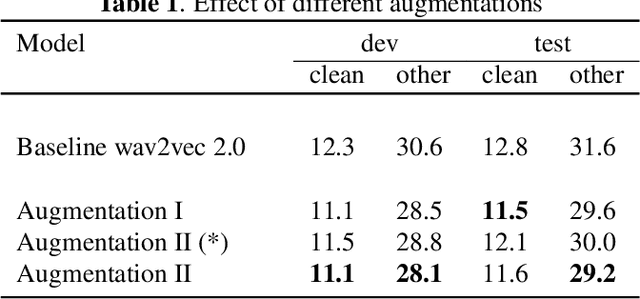
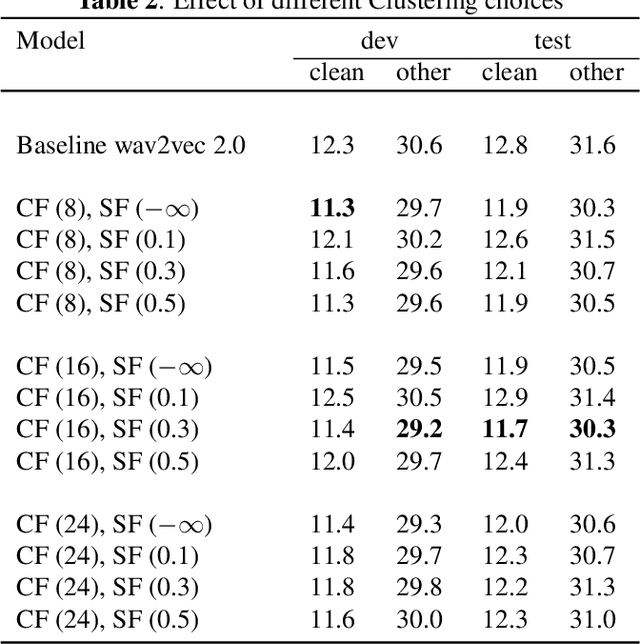
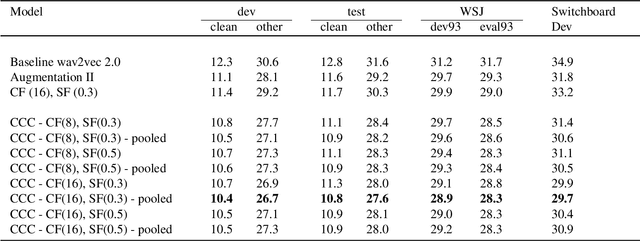
While Self-Supervised Learning has helped reap the benefit of the scale from the available unlabeled data, the learning paradigms are continuously being bettered. We present a new pre-training strategy named ccc-wav2vec 2.0, which uses clustering and an augmentation-based cross-contrastive loss as its self-supervised objective. Through the clustering module, we scale down the influence of those negative examples that are highly similar to the positive. The Cross-Contrastive loss is computed between the encoder output of the original sample and the quantizer output of its augmentation and vice-versa, bringing robustness to the pre-training strategy. ccc-wav2vec 2.0 achieves up to 15.6% and 12.7% relative WER improvement over the baseline wav2vec 2.0 on the test-clean and test-other sets, respectively, of LibriSpeech, without the use of any language model. The proposed method also achieves up to 14.9% relative WER improvement over the baseline wav2vec 2.0 when fine-tuned on Switchboard data. We make all our codes publicly available on GitHub.
ML-Based Analysis to Identify Speech Features Relevant in Predicting Alzheimer's Disease
Oct 25, 2021
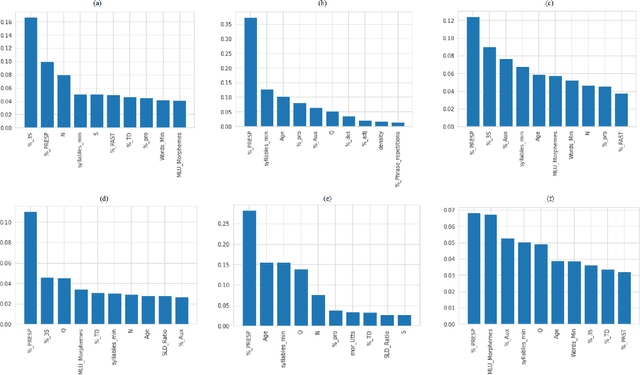

Alzheimer's disease (AD) is a neurodegenerative disease that affects nearly 50 million individuals across the globe and is one of the leading causes of deaths globally. It is projected that by 2050, the number of people affected by the disease would more than double. Consequently, the growing advancements in technology beg the question, can technology be used to predict Alzheimer's for a better and early diagnosis? In this paper, we focus on this very problem. Specifically, we have trained both ML models and neural networks to predict and classify participants based on their speech patterns. We computed a number of linguistic variables using DementiaBank's Pitt Corpus, a database consisting of transcripts of interviews with subjects suffering from multiple neurodegenerative diseases. We then trained both binary classifiers, as well as multiclass classifiers to distinguish AD from normal aging and other neurodegenerative diseases. We also worked on establishing the link between specific speech factors that can help determine the onset of AD. Confusion matrices and feature importance graphs have been plotted model-wise to compare the performances of our models. In both multiclass and binary classification, neural networks were found to outperform the other models with a testing accuracy of 76.44% and 92.05% respectively. For the feature importance, it was concluded that '%_PRESP' (present participle), '%_3S' (3rd person present tense markers) were two of the most important speech features for our classifiers in predicting AD.
Multilingual Speech Translation with Unified Transformer: Huawei Noah's Ark Lab at IWSLT 2021
Jun 22, 2021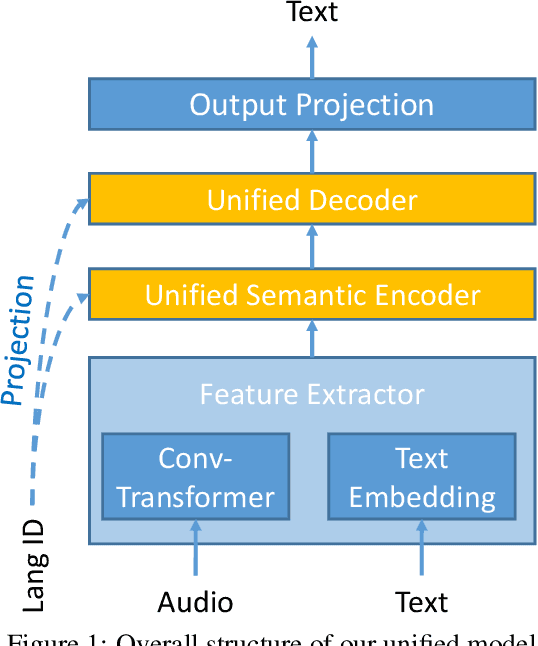
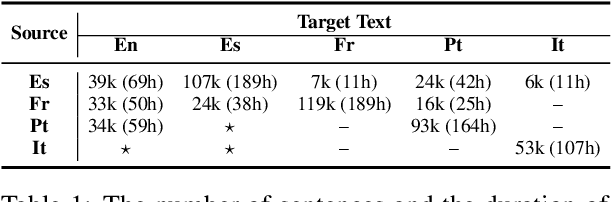
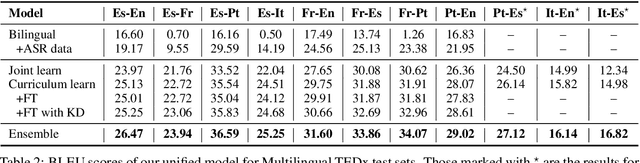
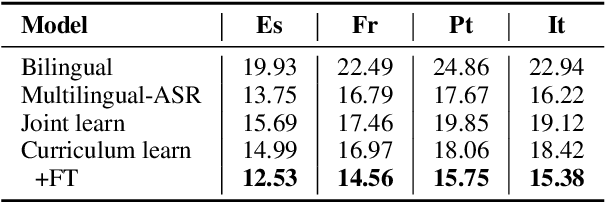
This paper describes the system submitted to the IWSLT 2021 Multilingual Speech Translation (MultiST) task from Huawei Noah's Ark Lab. We use a unified transformer architecture for our MultiST model, so that the data from different modalities (i.e., speech and text) and different tasks (i.e., Speech Recognition, Machine Translation, and Speech Translation) can be exploited to enhance the model's ability. Specifically, speech and text inputs are firstly fed to different feature extractors to extract acoustic and textual features, respectively. Then, these features are processed by a shared encoder--decoder architecture. We apply several training techniques to improve the performance, including multi-task learning, task-level curriculum learning, data augmentation, etc. Our final system achieves significantly better results than bilingual baselines on supervised language pairs and yields reasonable results on zero-shot language pairs.
Multi-speaker Multi-style Text-to-speech Synthesis With Single-speaker Single-style Training Data Scenarios
Dec 23, 2021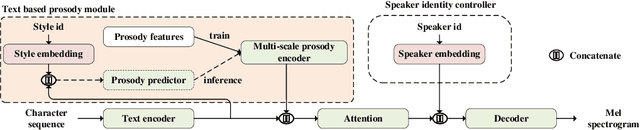
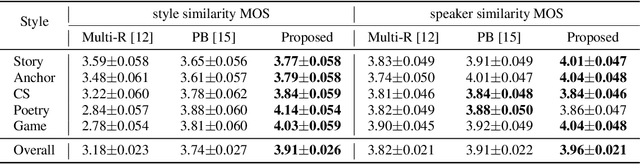
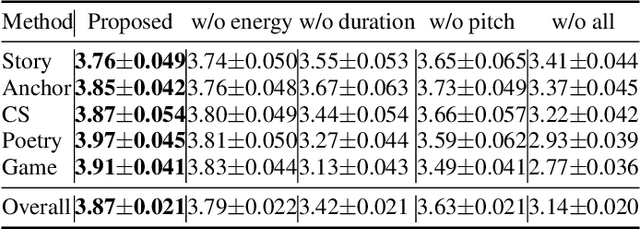
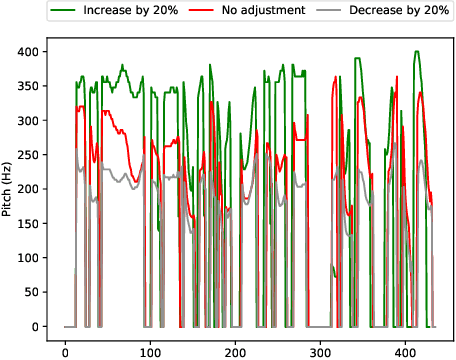
In the existing cross-speaker style transfer task, a source speaker with multi-style recordings is necessary to provide the style for a target speaker. However, it is hard for one speaker to express all expected styles. In this paper, a more general task, which is to produce expressive speech by combining any styles and timbres from a multi-speaker corpus in which each speaker has a unique style, is proposed. To realize this task, a novel method is proposed. This method is a Tacotron2-based framework but with a fine-grained text-based prosody predicting module and a speaker identity controller. Experiments demonstrate that the proposed method can successfully express a style of one speaker with the timber of another speaker bypassing the dependency on a single speaker's multi-style corpus. Moreover, the explicit prosody features used in the prosody predicting module can increase the diversity of synthetic speech by adjusting the value of prosody features.