 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Modeling Animal Vocalizations through Synthesizers
Oct 19, 2022
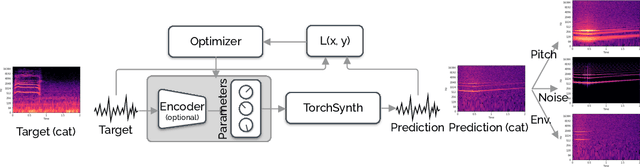
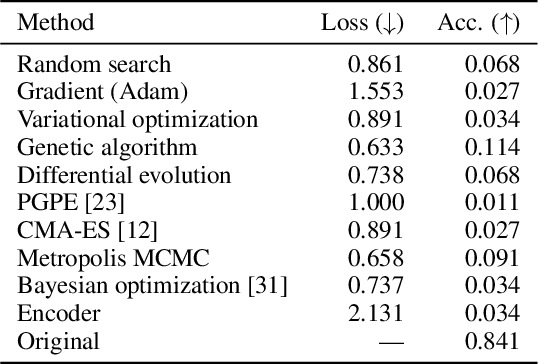
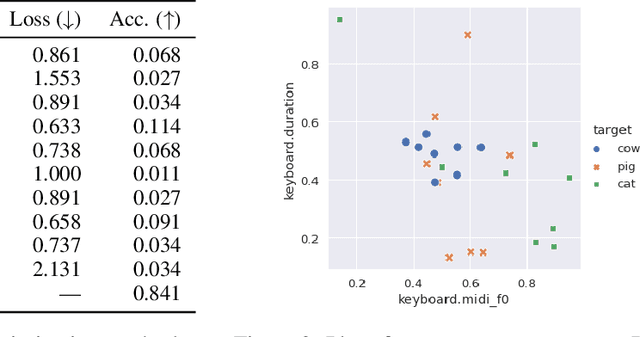
Modeling real-world sound is a fundamental problem in the creative use of machine learning and many other fields, including human speech processing and bioacoustics. Transformer-based generative models and some prior work (e.g., DDSP) are known to produce realistic sound, although they have limited control and are hard to interpret. As an alternative, we aim to use modular synthesizers, i.e., compositional, parametric electronic musical instruments, for modeling non-music sounds. However, inferring synthesizer parameters given a target sound, i.e., the parameter inference task, is not trivial for general sounds, and past research has typically focused on musical sound. In this work, we optimize a differentiable synthesizer from TorchSynth in order to model, emulate, and creatively generate animal vocalizations. We compare an array of optimization methods, from gradient-based search to genetic algorithms, for inferring its parameters, and then demonstrate how one can control and interpret the parameters for modeling non-music sounds.
G-Augment: Searching For The Meta-Structure Of Data Augmentation Policies For ASR
Oct 19, 2022
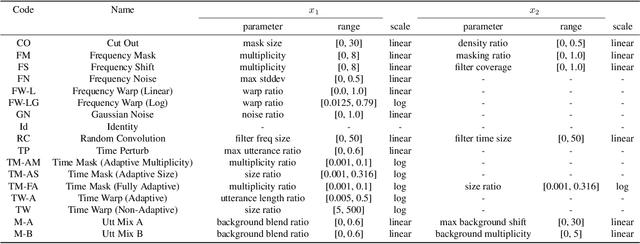
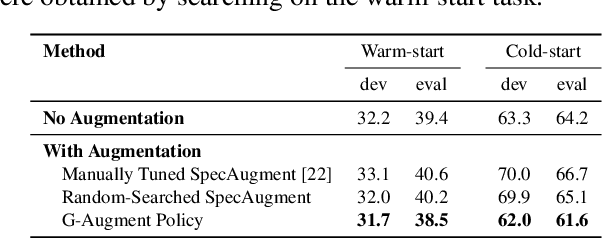
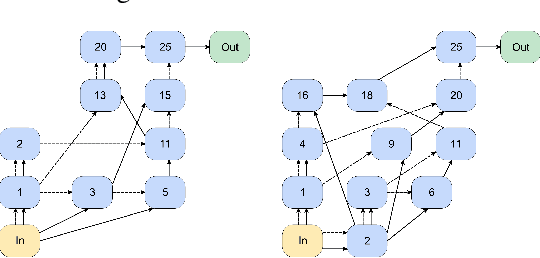
Data augmentation is a ubiquitous technique used to provide robustness to automatic speech recognition (ASR) training. However, even as so much of the ASR training process has become automated and more "end-to-end", the data augmentation policy (what augmentation functions to use, and how to apply them) remains hand-crafted. We present Graph-Augment, a technique to define the augmentation space as directed acyclic graphs (DAGs) and search over this space to optimize the augmentation policy itself. We show that given the same computational budget, policies produced by G-Augment are able to perform better than SpecAugment policies obtained by random search on fine-tuning tasks on CHiME-6 and AMI. G-Augment is also able to establish a new state-of-the-art ASR performance on the CHiME-6 evaluation set (30.7% WER). We further demonstrate that G-Augment policies show better transfer properties across warm-start to cold-start training and model size compared to random-searched SpecAugment policies.
LAE: Language-Aware Encoder for Monolingual and Multilingual ASR
Jun 05, 2022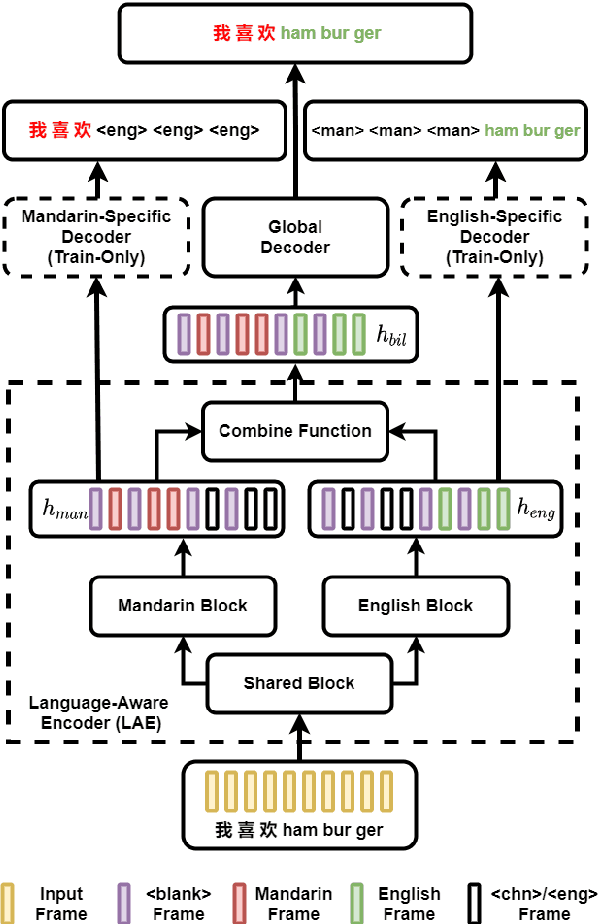
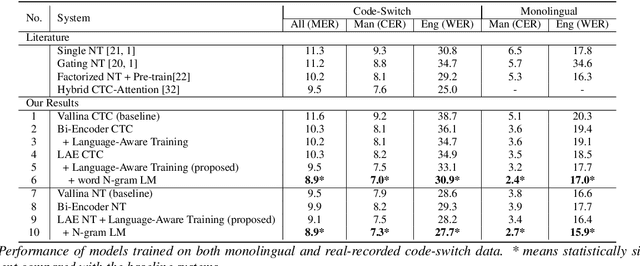
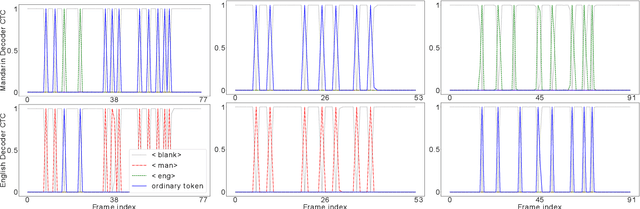
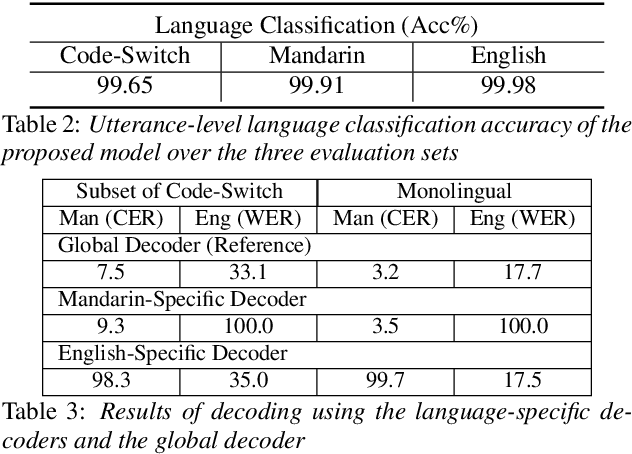
Despite the rapid progress in automatic speech recognition (ASR) research, recognizing multilingual speech using a unified ASR system remains highly challenging. Previous works on multilingual speech recognition mainly focus on two directions: recognizing multiple monolingual speech or recognizing code-switched speech that uses different languages interchangeably within a single utterance. However, a pragmatic multilingual recognizer is expected to be compatible with both directions. In this work, a novel language-aware encoder (LAE) architecture is proposed to handle both situations by disentangling language-specific information and generating frame-level language-aware representations during encoding. In the LAE, the primary encoding is implemented by the shared block while the language-specific blocks are used to extract specific representations for each language. To learn language-specific information discriminatively, a language-aware training method is proposed to optimize the language-specific blocks in LAE. Experiments conducted on Mandarin-English code-switched speech suggest that the proposed LAE is capable of discriminating different languages in frame-level and shows superior performance on both monolingual and multilingual ASR tasks. With either a real-recorded or simulated code-switched dataset, the proposed LAE achieves statistically significant improvements on both CTC and neural transducer systems. Code is released
Streaming Multi-talker Speech Recognition with Joint Speaker Identification
Apr 05, 2021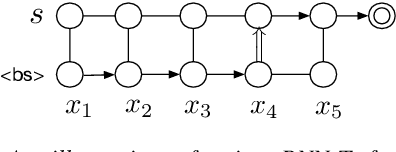
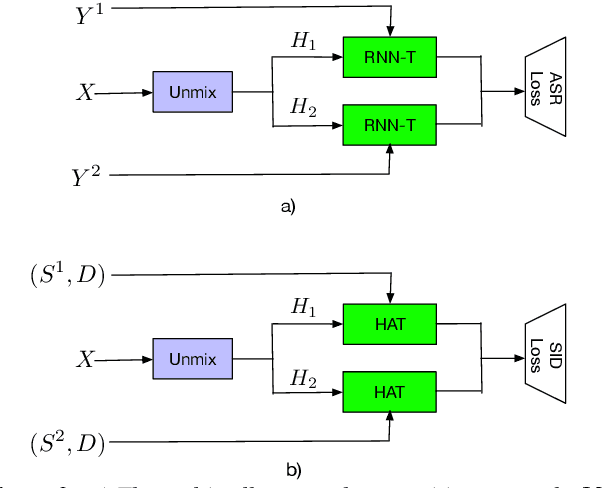
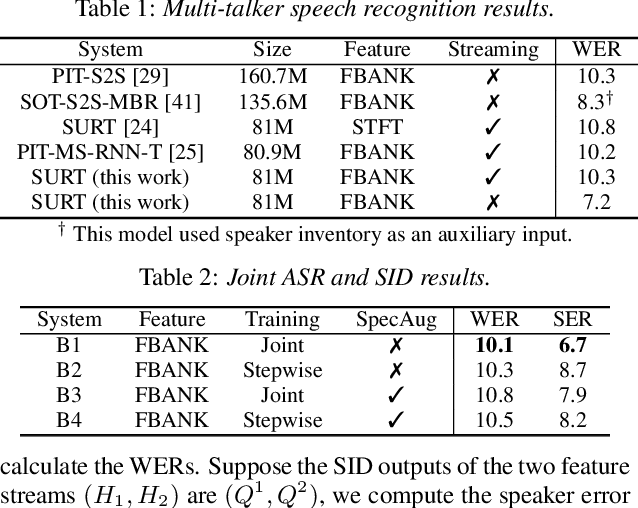
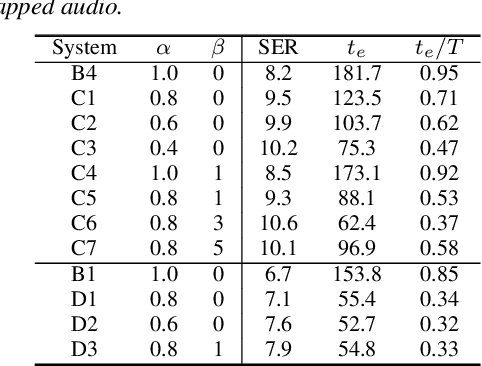
In multi-talker scenarios such as meetings and conversations, speech processing systems are usually required to transcribe the audio as well as identify the speakers for downstream applications. Since overlapped speech is common in this case, conventional approaches usually address this problem in a cascaded fashion that involves speech separation, speech recognition and speaker identification that are trained independently. In this paper, we propose Streaming Unmixing, Recognition and Identification Transducer (SURIT) -- a new framework that deals with this problem in an end-to-end streaming fashion. SURIT employs the recurrent neural network transducer (RNN-T) as the backbone for both speech recognition and speaker identification. We validate our idea on the LibrispeechMix dataset -- a multi-talker dataset derived from Librispeech, and present encouraging results.
Disentanglement Learning for Variational Autoencoders Applied to Audio-Visual Speech Enhancement
May 19, 2021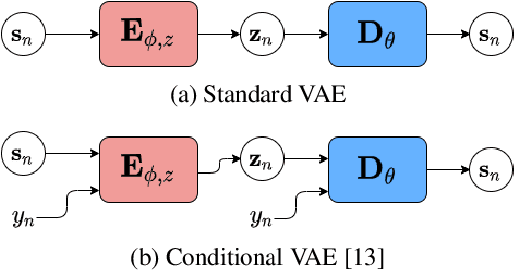

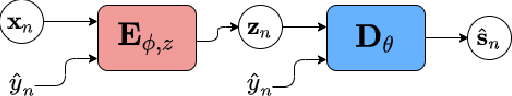
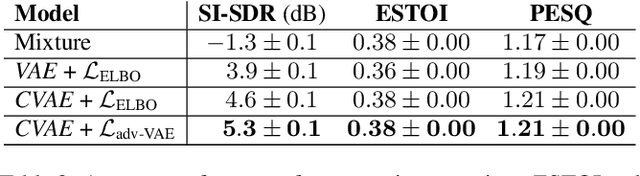
Recently, the standard variational autoencoder has been successfully used to learn a probabilistic prior over speech signals, which is then used to perform speech enhancement. Variational autoencoders have then been conditioned on a label describing a high-level speech attribute (e.g. speech activity) that allows for a more explicit control of speech generation. However, the label is not guaranteed to be disentangled from the other latent variables, which results in limited performance improvements compared to the standard variational autoencoder. In this work, we propose to use an adversarial training scheme for variational autoencoders to disentangle the label from the other latent variables. At training, we use a discriminator that competes with the encoder of the variational autoencoder. Simultaneously, we also use an additional encoder that estimates the label for the decoder of the variational autoencoder, which proves to be crucial to learn disentanglement. We show the benefit of the proposed disentanglement learning when a voice activity label, estimated from visual data, is used for speech enhancement.
MLP-ASR: Sequence-length agnostic all-MLP architectures for speech recognition
Feb 17, 2022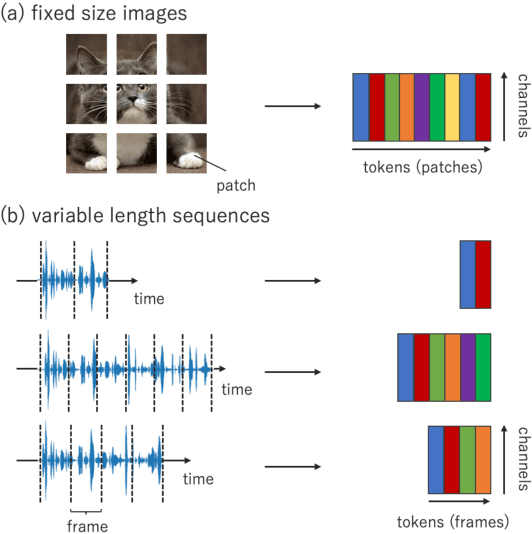

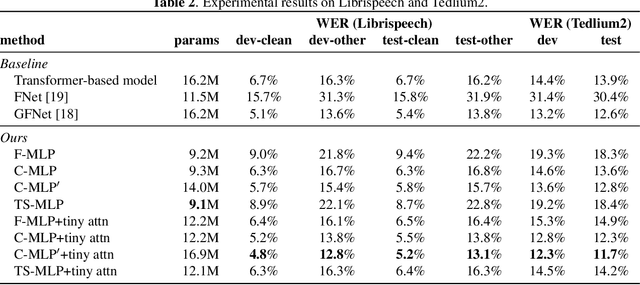
We propose multi-layer perceptron (MLP)-based architectures suitable for variable length input. MLP-based architectures, recently proposed for image classification, can only be used for inputs of a fixed, pre-defined size. However, many types of data are naturally variable in length, for example, acoustic signals. We propose three approaches to extend MLP-based architectures for use with sequences of arbitrary length. The first one uses a circular convolution applied in the Fourier domain, the second applies a depthwise convolution, and the final relies on a shift operation. We evaluate the proposed architectures on an automatic speech recognition task with the Librispeech and Tedlium2 corpora. The best proposed MLP-based architectures improves WER by 1.0 / 0.9%, 0.9 / 0.5% on Librispeech dev-clean/dev-other, test-clean/test-other set, and 0.8 / 1.1% on Tedlium2 dev/test set using 86.4% the size of self-attention-based architecture.
STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech
Mar 28, 2021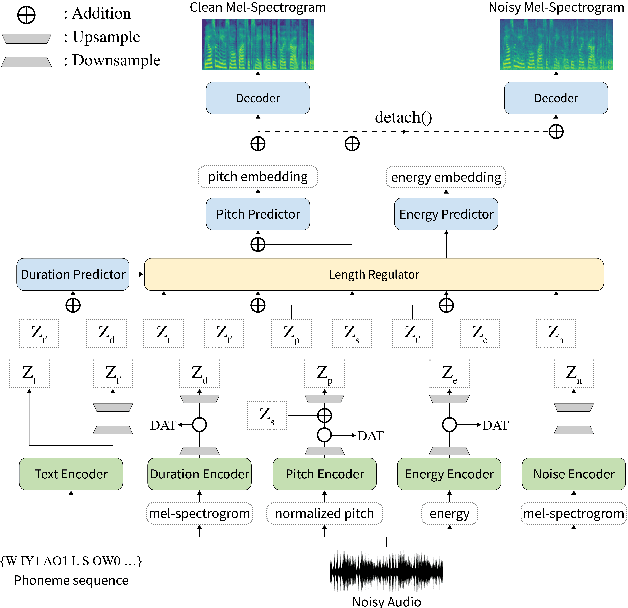
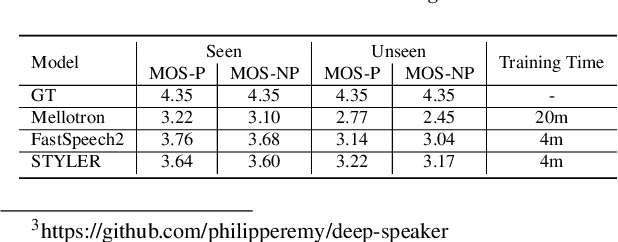
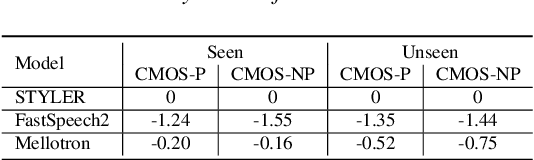
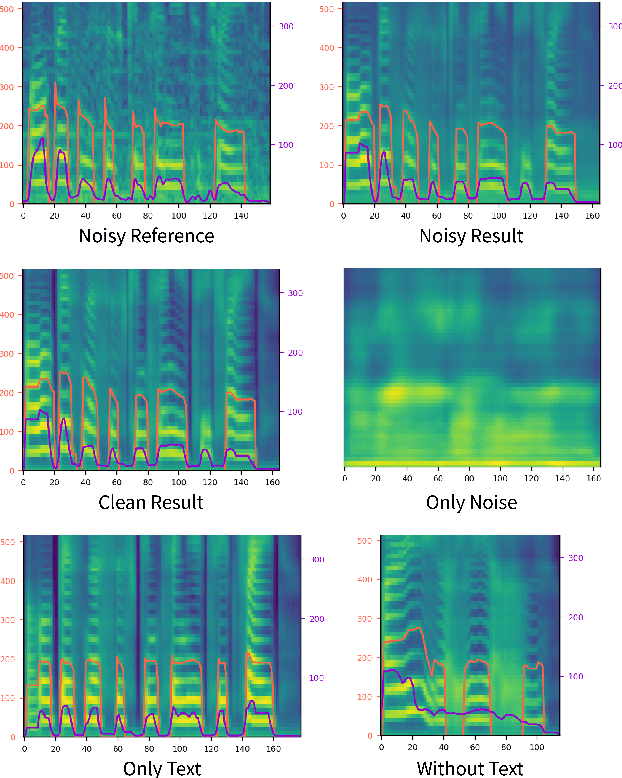
Previous works on neural text-to-speech (TTS) have been tackled on limited speed in training and inference time, robustness for difficult synthesis conditions, expressiveness, and controllability. Although several approaches resolve some limitations, none of them has resolved all weaknesses at once. In this paper, we propose STYLER, an expressive and controllable text-to-speech model with robust speech synthesis and high speed. Excluding autoregressive decoding and introducing a novel audio-text aligning method called Mel Calibrator leads speech synthesis more robust on long, unseen data. Disentangled style factor modeling under supervision enlarges the controllability of synthesizing speech with fruitful expressivity. Moreover, our novel noise modeling pipeline using domain adversarial training and Residual Decoding enables noise-robust style transfer, decomposing the noise without any additional label. Our extensive and various experiments demonstrate STYLER's effectiveness in the aspects of speed, robustness, expressiveness, and controllability by comparison with existing neural TTS models and ablation studies. Synthesis samples of our model and experiment results are provided via our demo page.
Using Pre-Trained Language Models for Producing Counter Narratives Against Hate Speech: a Comparative Study
Apr 04, 2022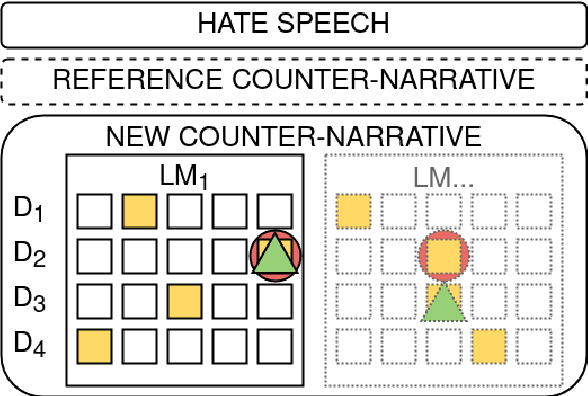


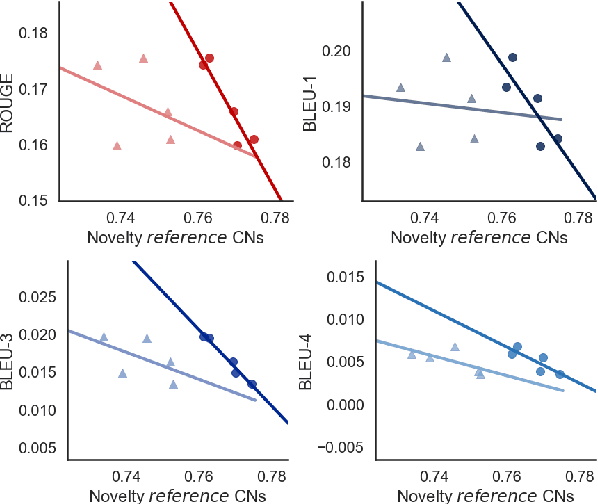
In this work, we present an extensive study on the use of pre-trained language models for the task of automatic Counter Narrative (CN) generation to fight online hate speech in English. We first present a comparative study to determine whether there is a particular Language Model (or class of LMs) and a particular decoding mechanism that are the most appropriate to generate CNs. Findings show that autoregressive models combined with stochastic decodings are the most promising. We then investigate how an LM performs in generating a CN with regard to an unseen target of hate. We find out that a key element for successful `out of target' experiments is not an overall similarity with the training data but the presence of a specific subset of training data, i.e. a target that shares some commonalities with the test target that can be defined a-priori. We finally introduce the idea of a pipeline based on the addition of an automatic post-editing step to refine generated CNs.
An Evaluation of Three-Stage Voice Conversion Framework for Noisy and Reverberant Conditions
Jun 30, 2022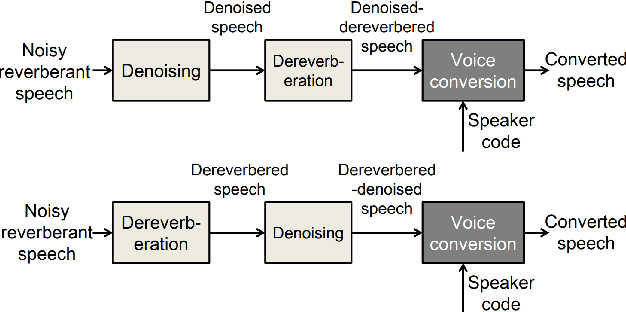
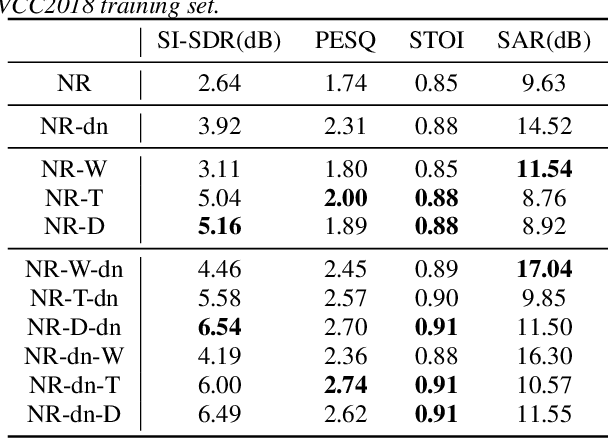
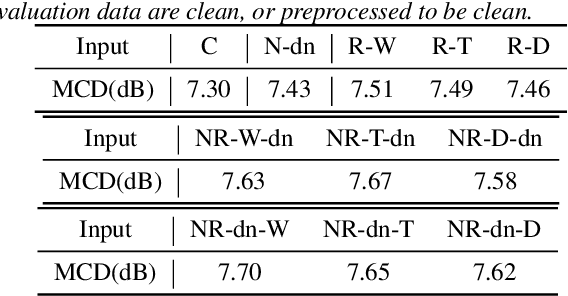
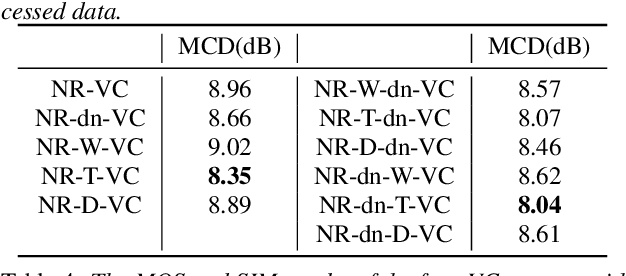
This paper presents a new voice conversion (VC) framework capable of dealing with both additive noise and reverberation, and its performance evaluation. There have been studied some VC researches focusing on real-world circumstances where speech data are interfered with background noise and reverberation. To deal with more practical conditions where no clean target dataset is available, one possible approach is zero-shot VC, but its performance tends to degrade compared with VC using sufficient amount of target speech data. To leverage large amount of noisy-reverberant target speech data, we propose a three-stage VC framework based on denoising process using a pretrained denoising model, dereverberation process using a dereverberation model, and VC process using a nonparallel VC model based on a variational autoencoder. The experimental results show that 1) noise and reverberation additively cause significant VC performance degradation, 2) the proposed method alleviates the adverse effects caused by both noise and reverberation, and significantly outperforms the baseline directly trained on the noisy-reverberant speech data, and 3) the potential degradation introduced by the denoising and dereverberation still causes noticeable adverse effects on VC performance.
Improving Automatic Hate Speech Detection with Multiword Expression Features
Jun 01, 2021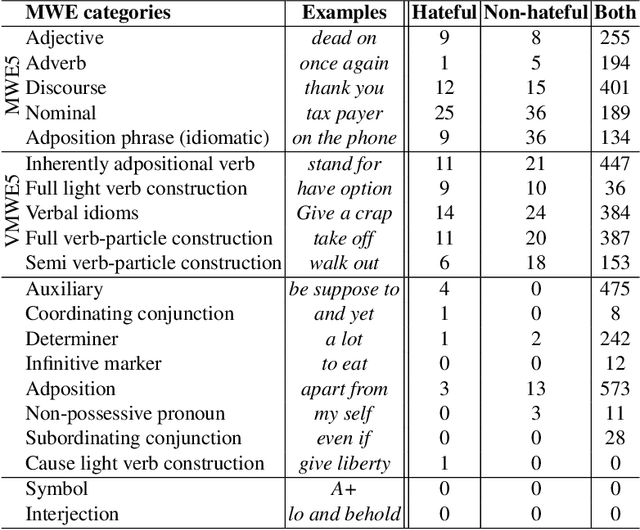
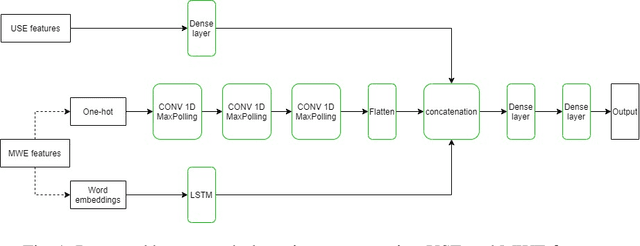
The task of automatically detecting hate speech in social media is gaining more and more attention. Given the enormous volume of content posted daily, human monitoring of hate speech is unfeasible. In this work, we propose new word-level features for automatic hate speech detection (HSD): multiword expressions (MWEs). MWEs are lexical units greater than a word that have idiomatic and compositional meanings. We propose to integrate MWE features in a deep neural network-based HSD framework. Our baseline HSD system relies on Universal Sentence Encoder (USE). To incorporate MWE features, we create a three-branch deep neural network: one branch for USE, one for MWE categories, and one for MWE embeddings. We conduct experiments on two hate speech tweet corpora with different MWE categories and with two types of MWE embeddings, word2vec and BERT. Our experiments demonstrate that the proposed HSD system with MWE features significantly outperforms the baseline system in terms of macro-F1.