 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
The impact of removing head movements on audio-visual speech enhancement
Feb 02, 2022
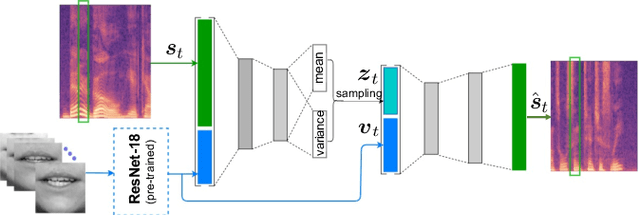
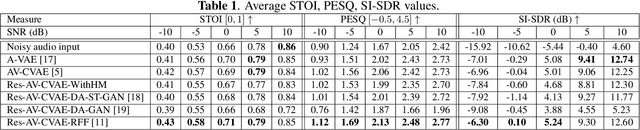
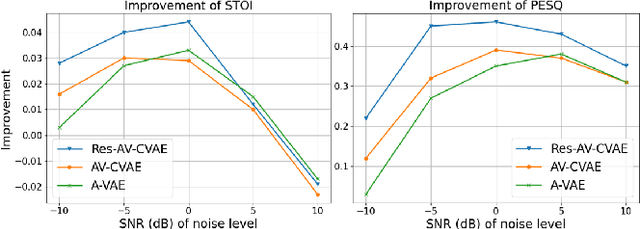
This paper investigates the impact of head movements on audio-visual speech enhancement (AVSE). Although being a common conversational feature, head movements have been ignored by past and recent studies: they challenge today's learning-based methods as they often degrade the performance of models that are trained on clean, frontal, and steady face images. To alleviate this problem, we propose to use robust face frontalization (RFF) in combination with an AVSE method based on a variational auto-encoder (VAE) model. We briefly describe the basic ingredients of the proposed pipeline and we perform experiments with a recently released audio-visual dataset. In the light of these experiments, and based on three standard metrics, namely STOI, PESQ and SI-SDR, we conclude that RFF improves the performance of AVSE by a considerable margin.
Speech Technology for Everyone: Automatic Speech Recognition for Non-Native English with Transfer Learning
Oct 15, 2021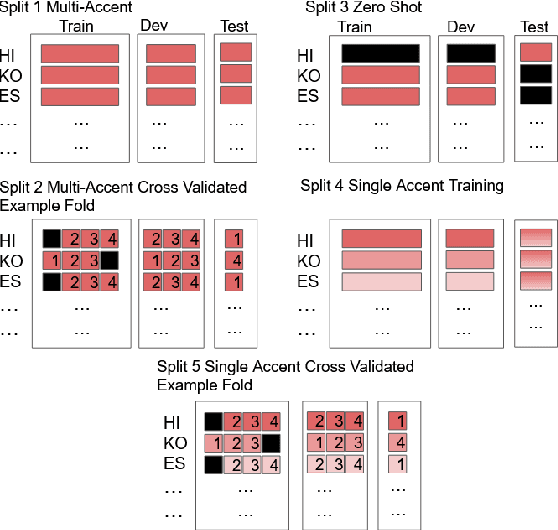


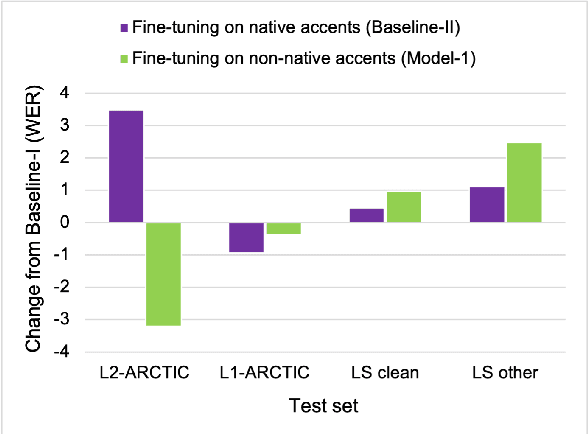
To address the performance gap of English ASR models on L2 English speakers, we evaluate fine-tuning of pretrained wav2vec 2.0 models (Baevski et al., 2020; Xu et al., 2021) on L2-ARCTIC, a non-native English speech corpus (Zhao et al., 2018) under different training settings. We compare \textbf{(a)} models trained with a combination of diverse accents to ones trained with only specific accents and \textbf{(b)} results from different single-accent models. Our experiments demonstrate the promise of developing ASR models for non-native English speakers, even with small amounts of L2 training data and even without a language model. Our models also excel in the zero-shot setting where we train on multiple L2 datasets and test on a blind L2 test set.
Audio-Visual Speech Separation Using Cross-Modal Correspondence Loss
Mar 02, 2021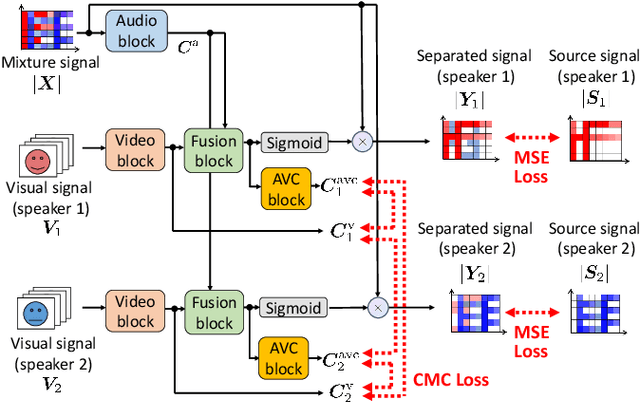
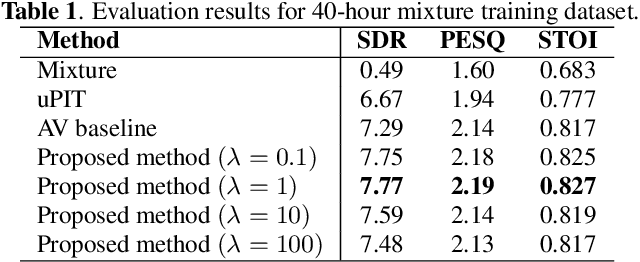
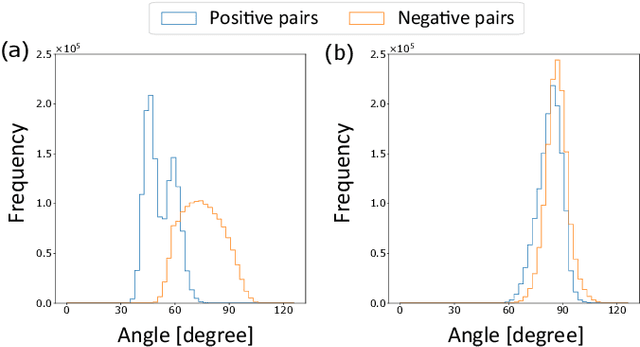

We present an audio-visual speech separation learning method that considers the correspondence between the separated signals and the visual signals to reflect the speech characteristics during training. Audio-visual speech separation is a technique to estimate the individual speech signals from a mixture using the visual signals of the speakers. Conventional studies on audio-visual speech separation mainly train the separation model on the audio-only loss, which reflects the distance between the source signals and the separated signals. However, conventional losses do not reflect the characteristics of the speech signals, including the speaker's characteristics and phonetic information, which leads to distortion or remaining noise. To address this problem, we propose the cross-modal correspondence (CMC) loss, which is based on the cooccurrence of the speech signal and the visual signal. Since the visual signal is not affected by background noise and contains speaker and phonetic information, using the CMC loss enables the audio-visual speech separation model to remove noise while preserving the speech characteristics. Experimental results demonstrate that the proposed method learns the cooccurrence on the basis of CMC loss, which improves separation performance.
Code-Switching Text Augmentation for Multilingual Speech Processing
Jan 07, 2022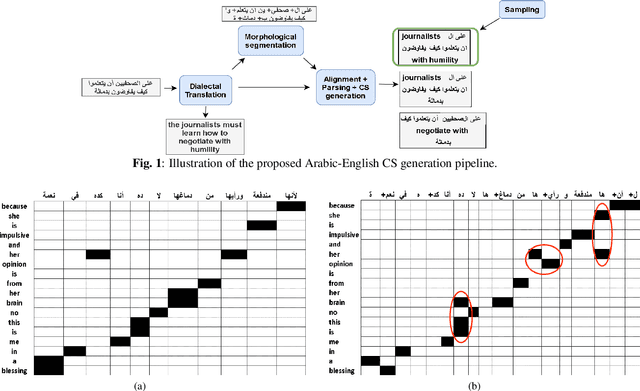
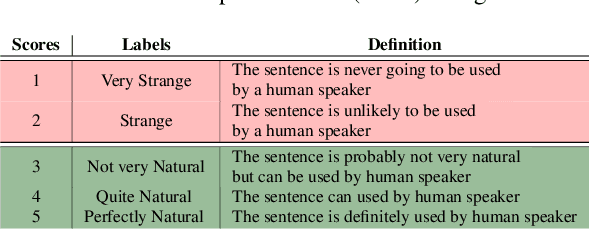
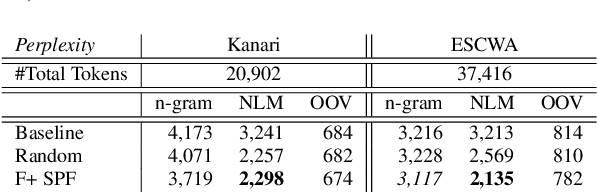
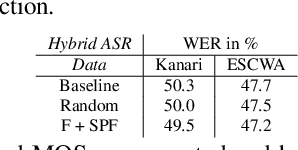
The pervasiveness of intra-utterance Code-switching (CS) in spoken content has enforced ASR systems to handle mixed input. Yet, designing a CS-ASR has many challenges, mainly due to the data scarcity, grammatical structure complexity, and mismatch along with unbalanced language usage distribution. Recent ASR studies showed the predominance of E2E-ASR using multilingual data to handle CS phenomena with little CS data. However, the dependency on the CS data still remains. In this work, we propose a methodology to augment the monolingual data for artificially generating spoken CS text to improve different speech modules. We based our approach on Equivalence Constraint theory while exploiting aligned translation pairs, to generate grammatically valid CS content. Our empirical results show a relative gain of 29-34 % in perplexity and around 2% in WER for two ecological and noisy CS test sets. Finally, the human evaluation suggests that 83.8% of the generated data is acceptable to humans.
Disentanglement Learning for Variational Autoencoders Applied to Audio-Visual Speech Enhancement
May 19, 2021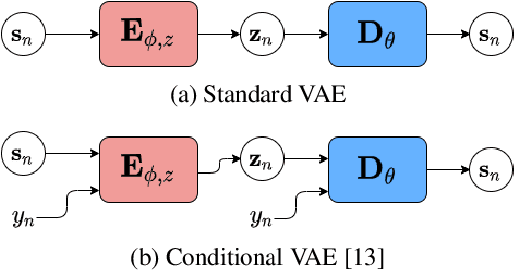

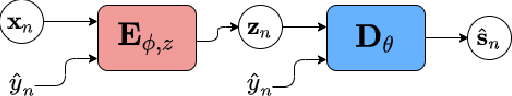
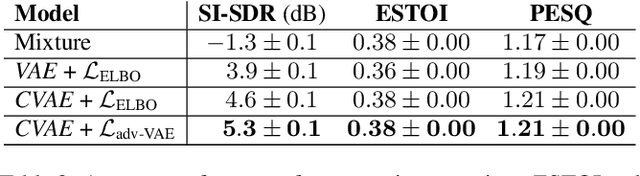
Recently, the standard variational autoencoder has been successfully used to learn a probabilistic prior over speech signals, which is then used to perform speech enhancement. Variational autoencoders have then been conditioned on a label describing a high-level speech attribute (e.g. speech activity) that allows for a more explicit control of speech generation. However, the label is not guaranteed to be disentangled from the other latent variables, which results in limited performance improvements compared to the standard variational autoencoder. In this work, we propose to use an adversarial training scheme for variational autoencoders to disentangle the label from the other latent variables. At training, we use a discriminator that competes with the encoder of the variational autoencoder. Simultaneously, we also use an additional encoder that estimates the label for the decoder of the variational autoencoder, which proves to be crucial to learn disentanglement. We show the benefit of the proposed disentanglement learning when a voice activity label, estimated from visual data, is used for speech enhancement.
Improving Emotional Speech Synthesis by Using SUS-Constrained VAE and Text Encoder Aggregation
Oct 19, 2021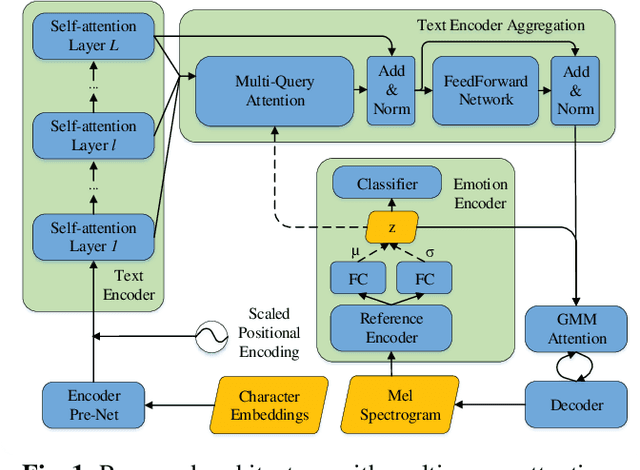

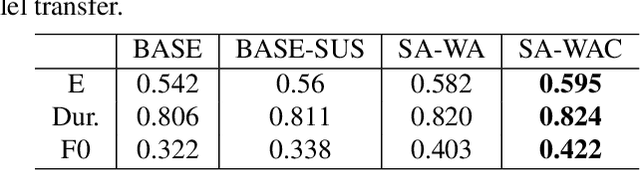
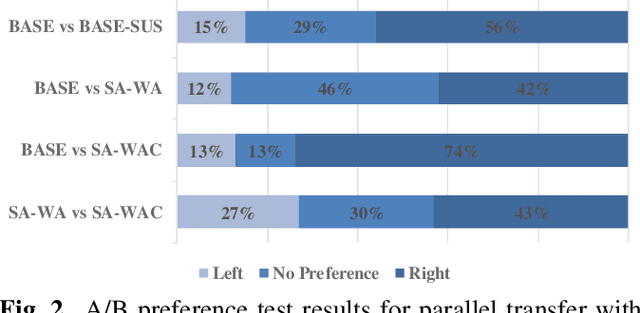
Learning emotion embedding from reference audio is a straightforward approach for multi-emotion speech synthesis in encoder-decoder systems. But how to get better emotion embedding and how to inject it into TTS acoustic model more effectively are still under investigation. In this paper, we propose an innovative constraint to help VAE extract emotion embedding with better cluster cohesion. Besides, the obtained emotion embedding is used as query to aggregate latent representations of all encoder layers via attention. Moreover, the queries from encoder layers themselves are also helpful. Experiments prove the proposed methods can enhance the encoding of comprehensive syntactic and semantic information and produce more expressive emotional speech.
Streaming Multi-talker Speech Recognition with Joint Speaker Identification
Apr 05, 2021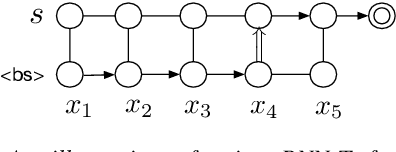
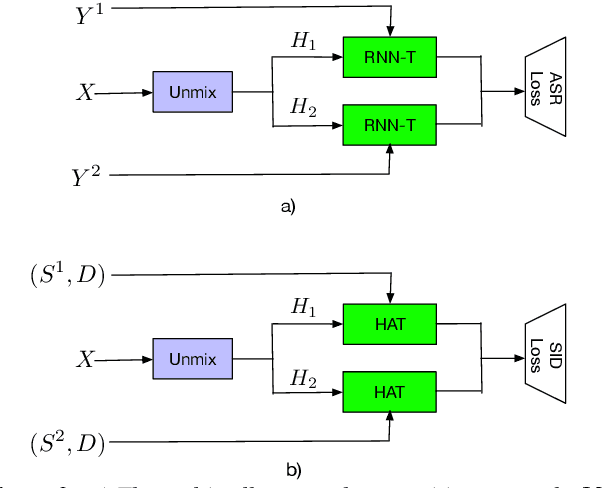
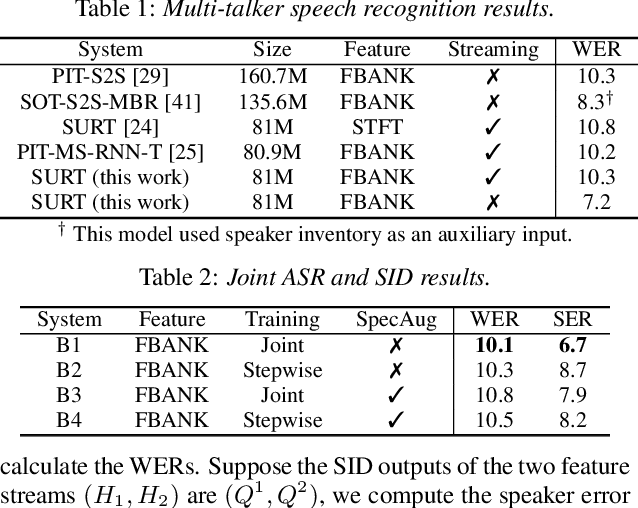
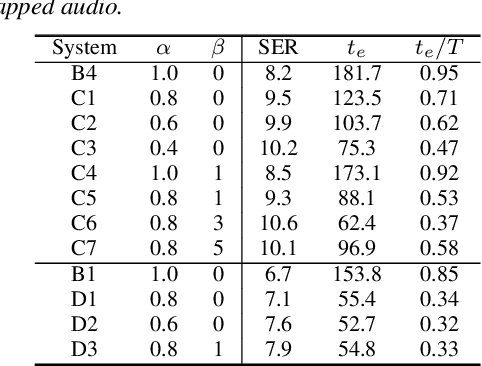
In multi-talker scenarios such as meetings and conversations, speech processing systems are usually required to transcribe the audio as well as identify the speakers for downstream applications. Since overlapped speech is common in this case, conventional approaches usually address this problem in a cascaded fashion that involves speech separation, speech recognition and speaker identification that are trained independently. In this paper, we propose Streaming Unmixing, Recognition and Identification Transducer (SURIT) -- a new framework that deals with this problem in an end-to-end streaming fashion. SURIT employs the recurrent neural network transducer (RNN-T) as the backbone for both speech recognition and speaker identification. We validate our idea on the LibrispeechMix dataset -- a multi-talker dataset derived from Librispeech, and present encouraging results.
Towards Cross-speaker Reading Style Transfer on Audiobook Dataset
Aug 19, 2022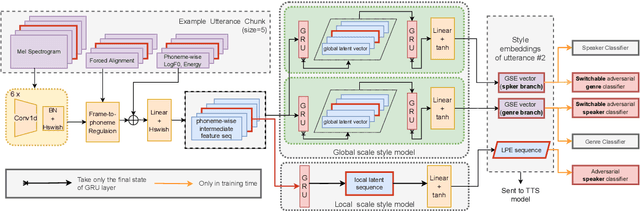
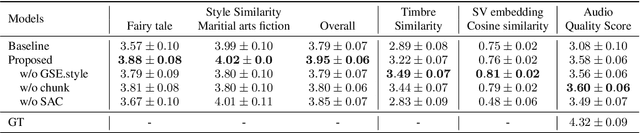
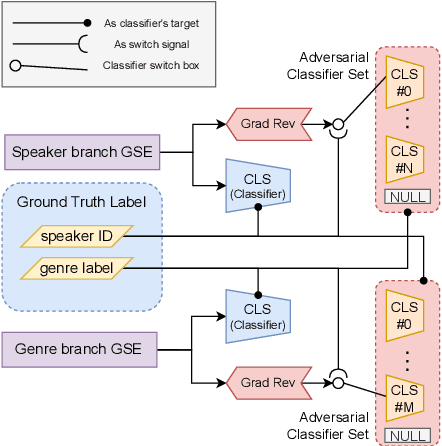
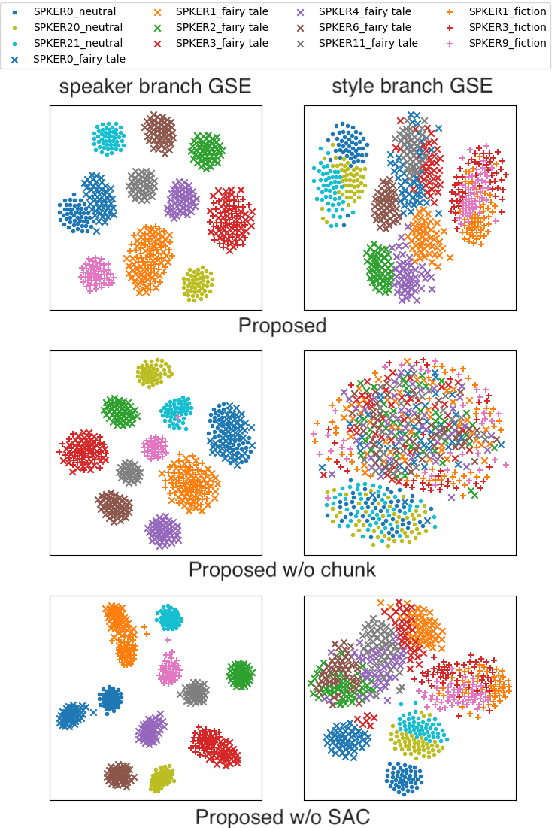
Cross-speaker style transfer aims to extract the speech style of the given reference speech, which can be reproduced in the timbre of arbitrary target speakers. Existing methods on this topic have explored utilizing utterance-level style labels to perform style transfer via either global or local scale style representations. However, audiobook datasets are typically characterized by both the local prosody and global genre, and are rarely accompanied by utterance-level style labels. Thus, properly transferring the reading style across different speakers remains a challenging task. This paper aims to introduce a chunk-wise multi-scale cross-speaker style model to capture both the global genre and the local prosody in audiobook speeches. Moreover, by disentangling speaker timbre and style with the proposed switchable adversarial classifiers, the extracted reading style is made adaptable to the timbre of different speakers. Experiment results confirm that the model manages to transfer a given reading style to new target speakers. With the support of local prosody and global genre type predictor, the potentiality of the proposed method in multi-speaker audiobook generation is further revealed.
Fluent and Low-latency Simultaneous Speech-to-Speech Translation with Self-adaptive Training
Oct 21, 2020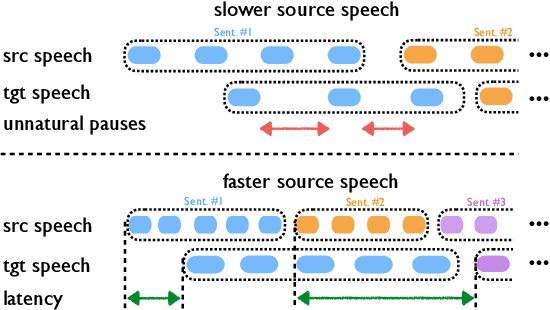
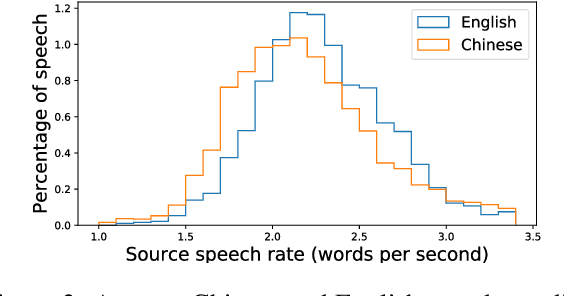
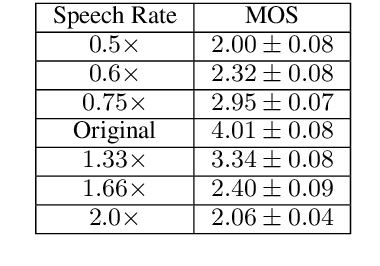
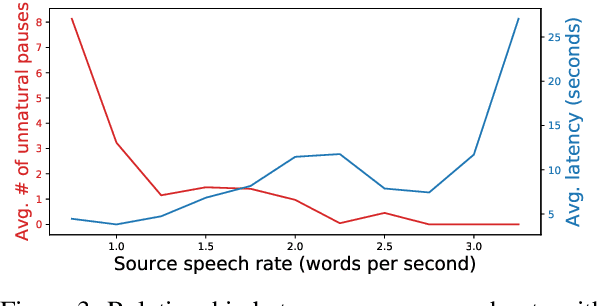
Simultaneous speech-to-speech translation is widely useful but extremely challenging, since it needs to generate target-language speech concurrently with the source-language speech, with only a few seconds delay. In addition, it needs to continuously translate a stream of sentences, but all recent solutions merely focus on the single-sentence scenario. As a result, current approaches accumulate latencies progressively when the speaker talks faster, and introduce unnatural pauses when the speaker talks slower. To overcome these issues, we propose Self-Adaptive Translation (SAT) which flexibly adjusts the length of translations to accommodate different source speech rates. At similar levels of translation quality (as measured by BLEU), our method generates more fluent target speech (as measured by the naturalness metric MOS) with substantially lower latency than the baseline, in both Zh <-> En directions.
* 10 pages, accepted by Findings of EMNLP 2020