 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
CopyCat2: A Single Model for Multi-Speaker TTS and Many-to-Many Fine-Grained Prosody Transfer
Jun 27, 2022
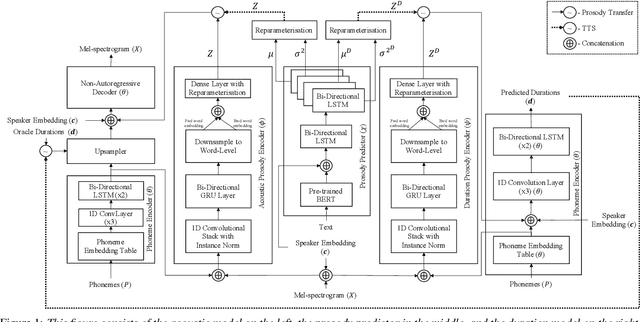
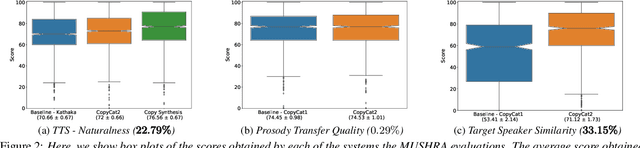
In this paper, we present CopyCat2 (CC2), a novel model capable of: a) synthesizing speech with different speaker identities, b) generating speech with expressive and contextually appropriate prosody, and c) transferring prosody at fine-grained level between any pair of seen speakers. We do this by activating distinct parts of the network for different tasks. We train our model using a novel approach to two-stage training. In Stage I, the model learns speaker-independent word-level prosody representations from speech which it uses for many-to-many fine-grained prosody transfer. In Stage II, we learn to predict these prosody representations using the contextual information available in text, thereby, enabling multi-speaker TTS with contextually appropriate prosody. We compare CC2 to two strong baselines, one in TTS with contextually appropriate prosody, and one in fine-grained prosody transfer. CC2 reduces the gap in naturalness between our baseline and copy-synthesised speech by $22.79\%$. In fine-grained prosody transfer evaluations, it obtains a relative improvement of $33.15\%$ in target speaker similarity.
OCD: Learning to Overfit with Conditional Diffusion Models
Oct 10, 2022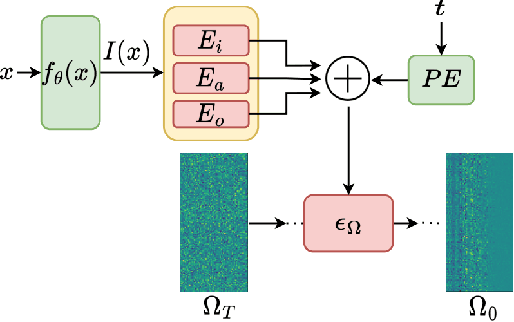
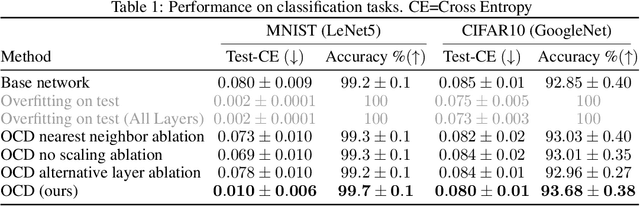
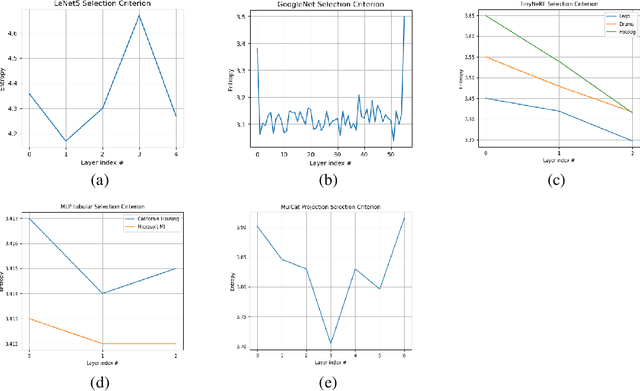
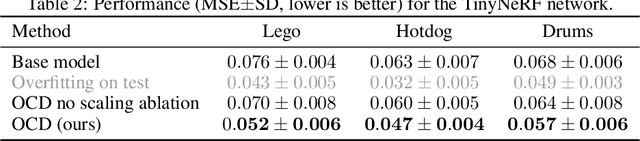
We present a dynamic model in which the weights are conditioned on an input sample x and are learned to match those that would be obtained by finetuning a base model on x and its label y. This mapping between an input sample and network weights is shown to be approximated by a linear transformation of the sample distribution, which suggests that a denoising diffusion model can be suitable for this task. The diffusion model we therefore employ focuses on modifying a single layer of the base model and is conditioned on the input, activations, and output of this layer. Our experiments demonstrate the wide applicability of the method for image classification, 3D reconstruction, tabular data, and speech separation. Our code is available at https://github.com/ShaharLutatiPersonal/OCD.
Speech Resynthesis from Discrete Disentangled Self-Supervised Representations
Apr 01, 2021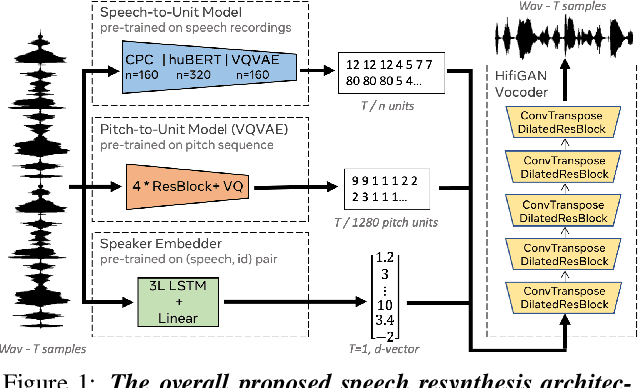
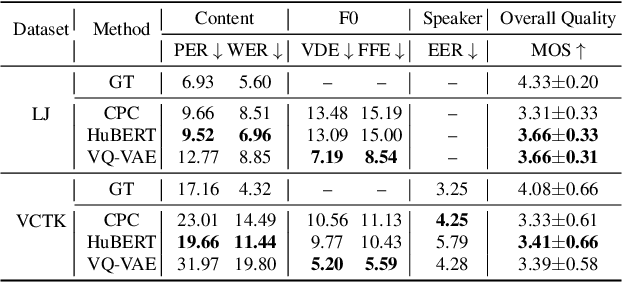
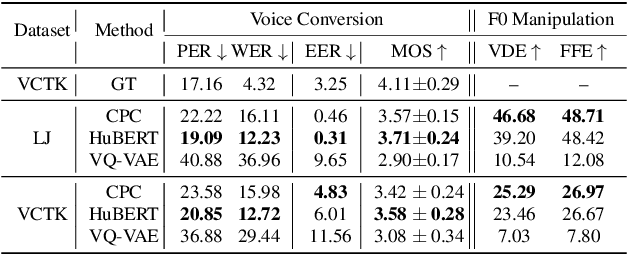
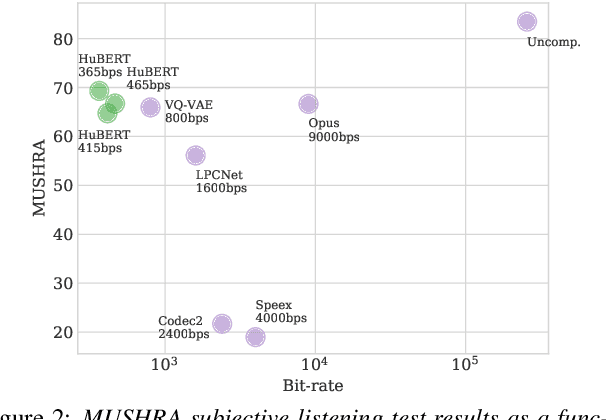
We propose using self-supervised discrete representations for the task of speech resynthesis. To generate disentangled representation, we separately extract low-bitrate representations for speech content, prosodic information, and speaker identity. This allows to synthesize speech in a controllable manner. We analyze various state-of-the-art, self-supervised representation learning methods and shed light on the advantages of each method while considering reconstruction quality and disentanglement properties. Specifically, we evaluate the F0 reconstruction, speaker identification performance (for both resynthesis and voice conversion), recordings' intelligibility, and overall quality using subjective human evaluation. Lastly, we demonstrate how these representations can be used for an ultra-lightweight speech codec. Using the obtained representations, we can get to a rate of 365 bits per second while providing better speech quality than the baseline methods. Audio samples can be found under the following link: \url{https://resynthesis-ssl.github.io/}.
End-to-End Speech Recognition With Joint Dereverberation Of Sub-Band Autoregressive Envelopes
Aug 09, 2021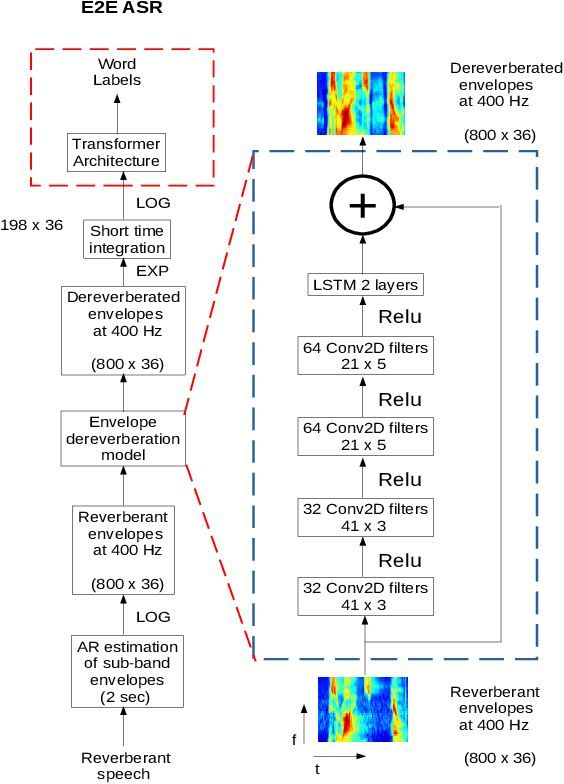
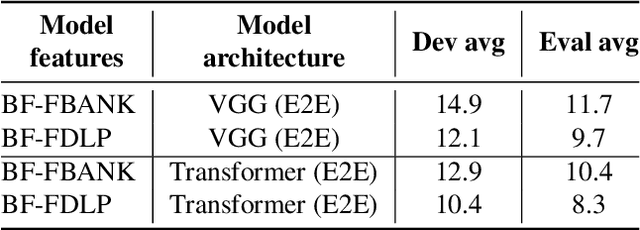
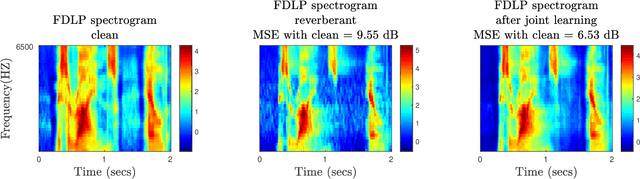
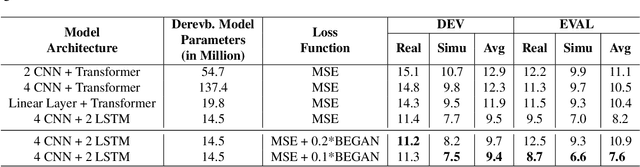
The end-to-end (E2E) automatic speech recognition (ASR) offers several advantages over previous efforts for recognizing speech. However, in reverberant conditions, E2E ASR is a challenging task as the long-term sub-band envelopes of the reverberant speech are temporally smeared. In this paper, we develop a feature enhancement approach using a neural model operating on sub-band temporal envelopes. The temporal envelopes are modeled using the framework of frequency domain linear prediction (FDLP). The neural enhancement model proposed in this paper performs an envelope gain based enhancement of temporal envelopes. The model architecture consists of a combination of convolutional and long short term memory (LSTM) neural network layers. Further, the envelope dereverberation, feature extraction and acoustic modeling using transformer based E2E ASR can all be jointly optimized for the speech recognition task. The joint optimization ensures that the dereverberation model targets the ASR cost function. We perform E2E speech recognition experiments on the REVERB challenge dataset as well as on the VOiCES dataset. In these experiments, the proposed joint modeling approach yields significant improvements compared to baseline E2E ASR system (average relative improvements of 21% on the REVERB challenge dataset and about 10% on the VOiCES dataset).
A Flow-Based Neural Network for Time Domain Speech Enhancement
Jun 16, 2021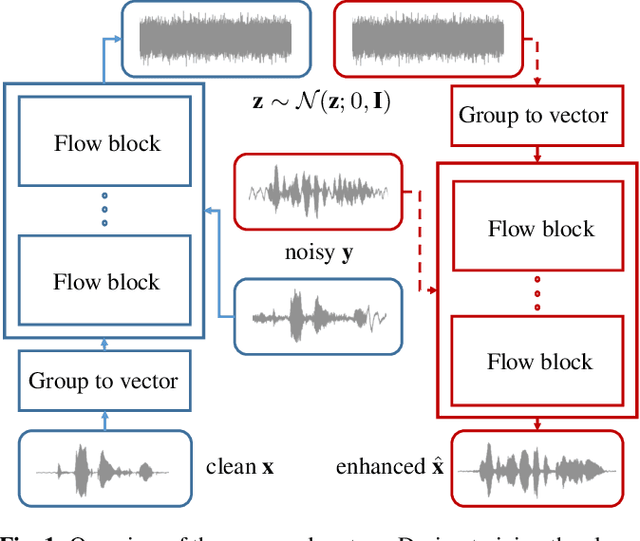
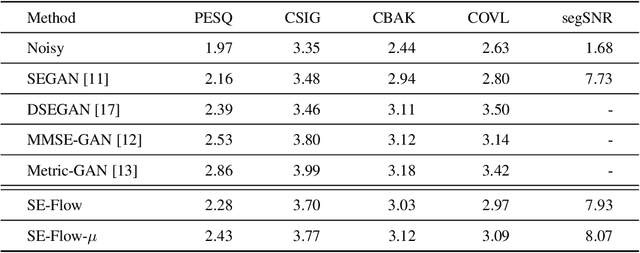
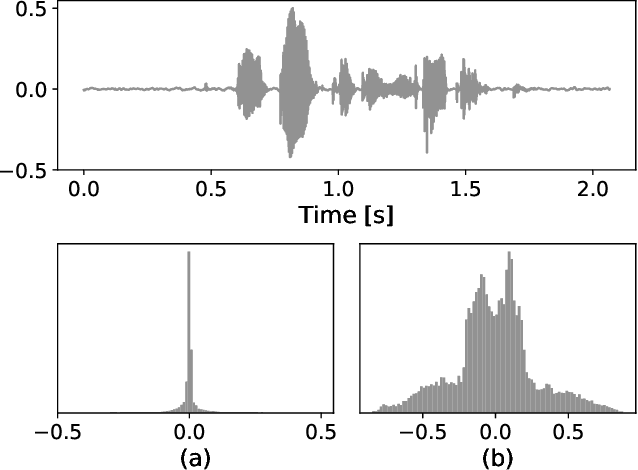
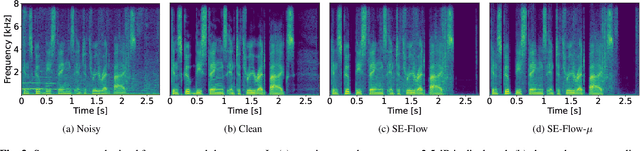
Speech enhancement involves the distinction of a target speech signal from an intrusive background. Although generative approaches using Variational Autoencoders or Generative Adversarial Networks (GANs) have increasingly been used in recent years, normalizing flow (NF) based systems are still scarse, despite their success in related fields. Thus, in this paper we propose a NF framework to directly model the enhancement process by density estimation of clean speech utterances conditioned on their noisy counterpart. The WaveGlow model from speech synthesis is adapted to enable direct enhancement of noisy utterances in time domain. In addition, we demonstrate that nonlinear input companding benefits the model performance by equalizing the distribution of input samples. Experimental evaluation on a publicly available dataset shows comparable results to current state-of-the-art GAN-based approaches, while surpassing the chosen baselines using objective evaluation metrics.
Neural-FST Class Language Model for End-to-End Speech Recognition
Jan 31, 2022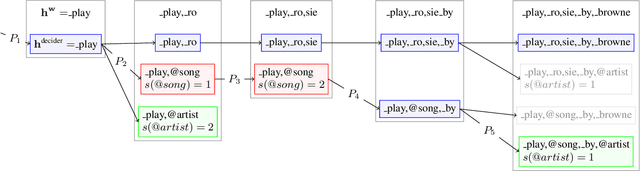
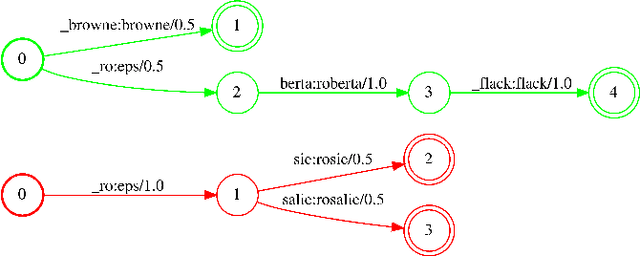
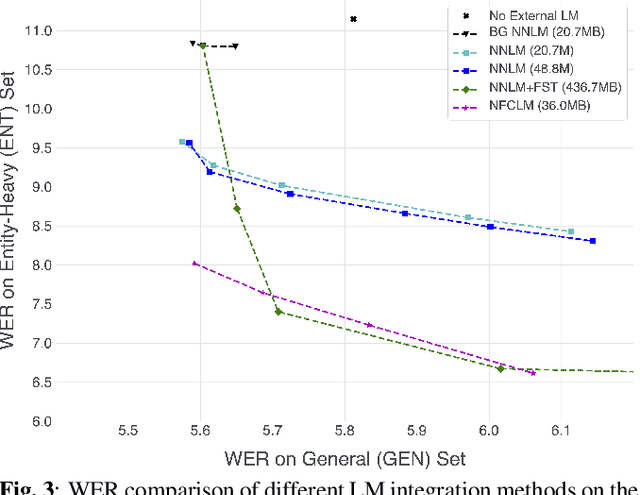
We propose Neural-FST Class Language Model (NFCLM) for end-to-end speech recognition, a novel method that combines neural network language models (NNLMs) and finite state transducers (FSTs) in a mathematically consistent framework. Our method utilizes a background NNLM which models generic background text together with a collection of domain-specific entities modeled as individual FSTs. Each output token is generated by a mixture of these components; the mixture weights are estimated with a separately trained neural decider. We show that NFCLM significantly outperforms NNLM by 15.8% relative in terms of Word Error Rate. NFCLM achieves similar performance as traditional NNLM and FST shallow fusion while being less prone to overbiasing and 12 times more compact, making it more suitable for on-device usage.
PoeticTTS -- Controllable Poetry Reading for Literary Studies
Jul 11, 2022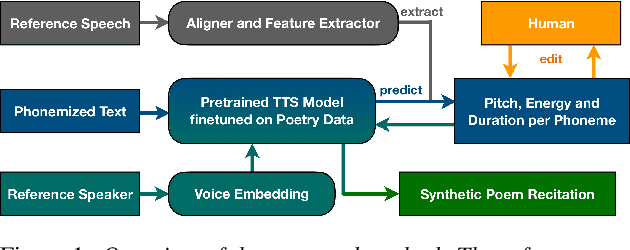

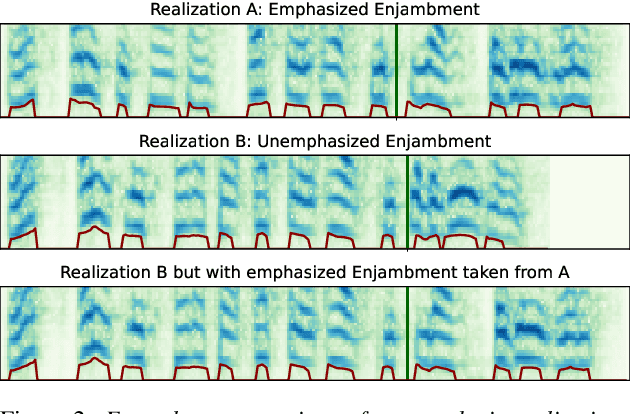
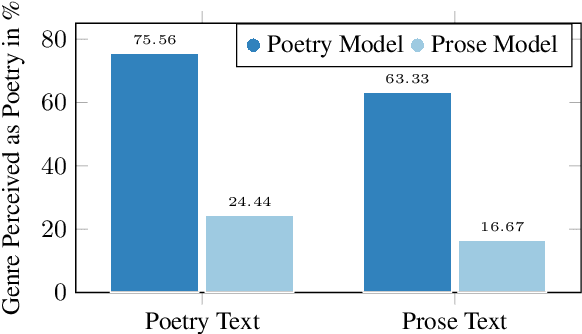
Speech synthesis for poetry is challenging due to specific intonation patterns inherent to poetic speech. In this work, we propose an approach to synthesise poems with almost human like naturalness in order to enable literary scholars to systematically examine hypotheses on the interplay between text, spoken realisation, and the listener's perception of poems. To meet these special requirements for literary studies, we resynthesise poems by cloning prosodic values from a human reference recitation, and afterwards make use of fine-grained prosody control to manipulate the synthetic speech in a human-in-the-loop setting to alter the recitation w.r.t. specific phenomena. We find that finetuning our TTS model on poetry captures poetic intonation patterns to a large extent which is beneficial for prosody cloning and manipulation and verify the success of our approach both in an objective evaluation as well as in human studies.
On TasNet for Low-Latency Single-Speaker Speech Enhancement
Mar 27, 2021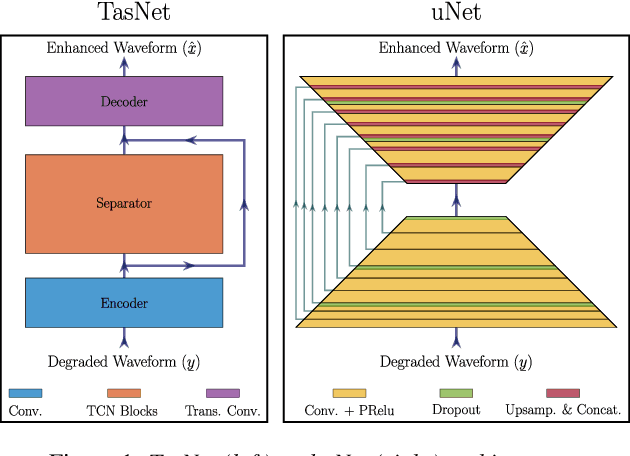
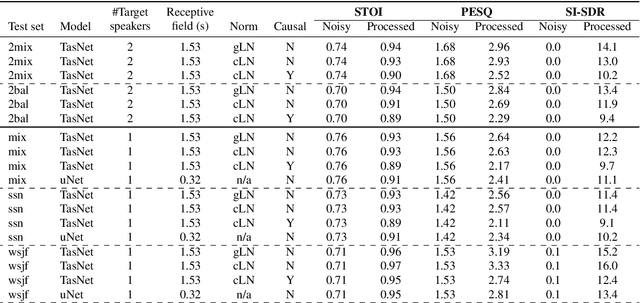
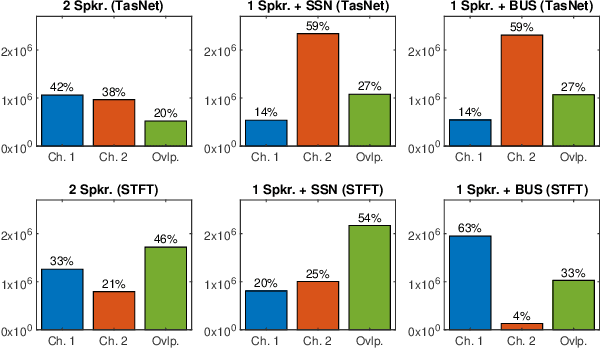
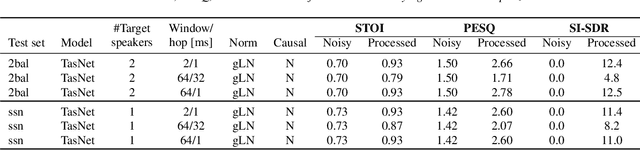
In recent years, speech processing algorithms have seen tremendous progress primarily due to the deep learning renaissance. This is especially true for speech separation where the time-domain audio separation network (TasNet) has led to significant improvements. However, for the related task of single-speaker speech enhancement, which is of obvious importance, it is yet unknown, if the TasNet architecture is equally successful. In this paper, we show that TasNet improves state-of-the-art also for speech enhancement, and that the largest gains are achieved for modulated noise sources such as speech. Furthermore, we show that TasNet learns an efficient inner-domain representation, where target and noise signal components are highly separable. This is especially true for noise in terms of interfering speech signals, which might explain why TasNet performs so well on the separation task. Additionally, we show that TasNet performs poorly for large frame hops and conjecture that aliasing might be the main cause of this performance drop. Finally, we show that TasNet consistently outperforms a state-of-the-art single-speaker speech enhancement system.
Ctrl-P: Temporal Control of Prosodic Variation for Speech Synthesis
Jun 15, 2021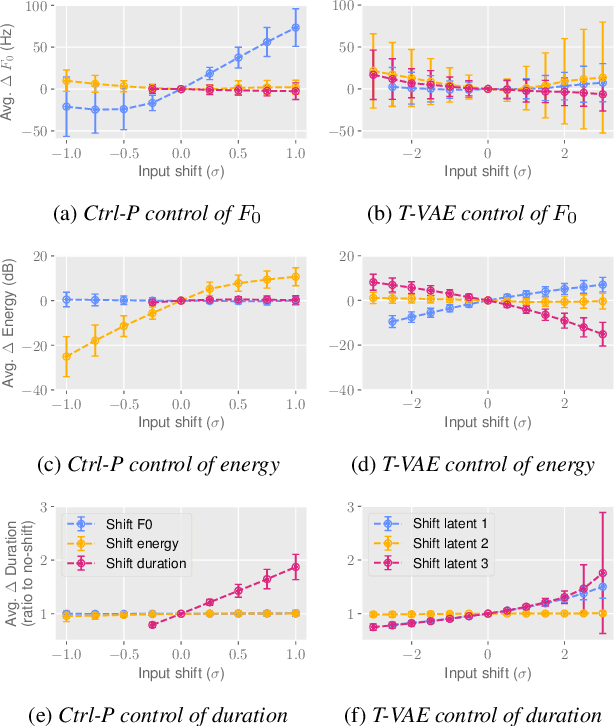
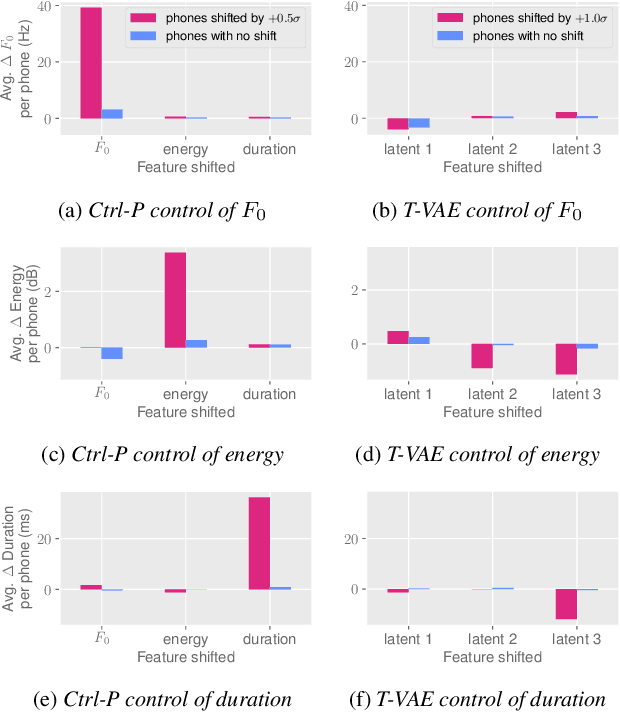
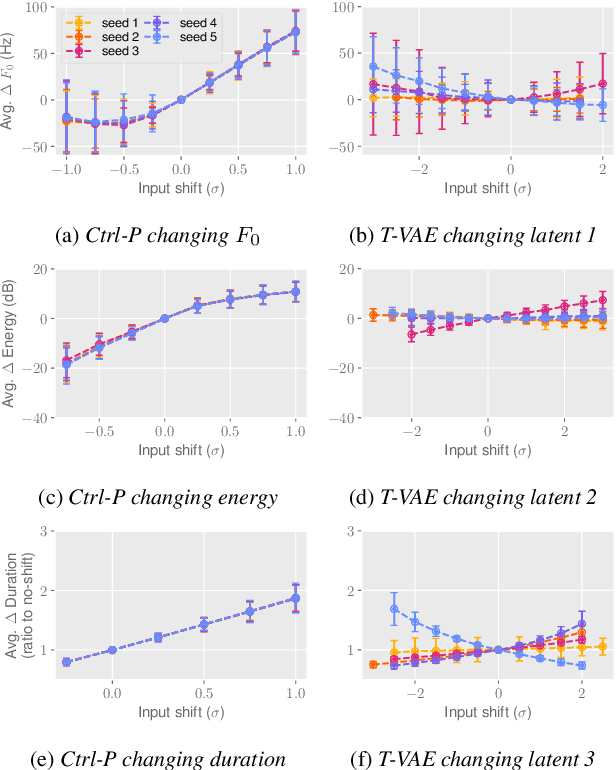
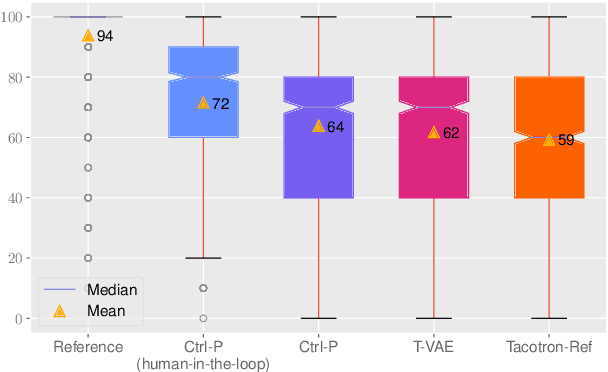
Text does not fully specify the spoken form, so text-to-speech models must be able to learn from speech data that vary in ways not explained by the corresponding text. One way to reduce the amount of unexplained variation in training data is to provide acoustic information as an additional learning signal. When generating speech, modifying this acoustic information enables multiple distinct renditions of a text to be produced. Since much of the unexplained variation is in the prosody, we propose a model that generates speech explicitly conditioned on the three primary acoustic correlates of prosody: $F_{0}$, energy and duration. The model is flexible about how the values of these features are specified: they can be externally provided, or predicted from text, or predicted then subsequently modified. Compared to a model that employs a variational auto-encoder to learn unsupervised latent features, our model provides more interpretable, temporally-precise, and disentangled control. When automatically predicting the acoustic features from text, it generates speech that is more natural than that from a Tacotron 2 model with reference encoder. Subsequent human-in-the-loop modification of the predicted acoustic features can significantly further increase naturalness.
Self-Supervised Attention Networks and Uncertainty Loss Weighting for Multi-Task Emotion Recognition on Vocal Bursts
Sep 15, 2022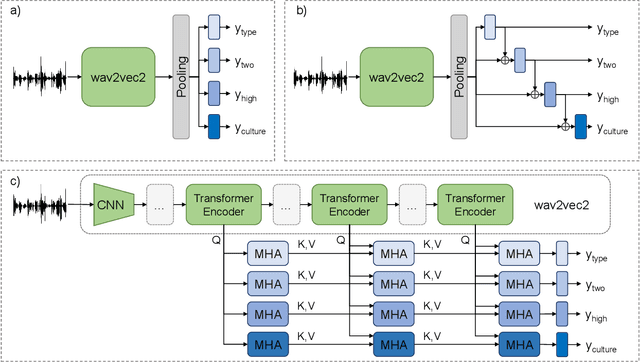
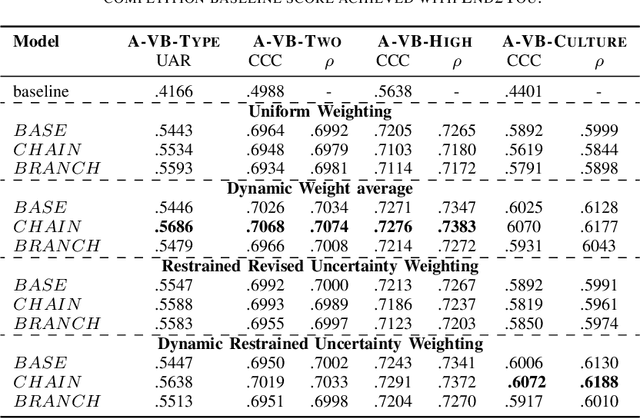

Vocal bursts play an important role in communicating affect, making them valuable for improving speech emotion recognition. Here, we present our approach for classifying vocal bursts and predicting their emotional significance in the ACII Affective Vocal Burst Workshop & Challenge 2022 (A-VB). We use a large self-supervised audio model as shared feature extractor and compare multiple architectures built on classifier chains and attention networks, combined with uncertainty loss weighting strategies. Our approach surpasses the challenge baseline by a wide margin on all four tasks.