 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Parameter-efficient transfer learning of pre-trained Transformer models for speaker verification using adapters
Oct 28, 2022
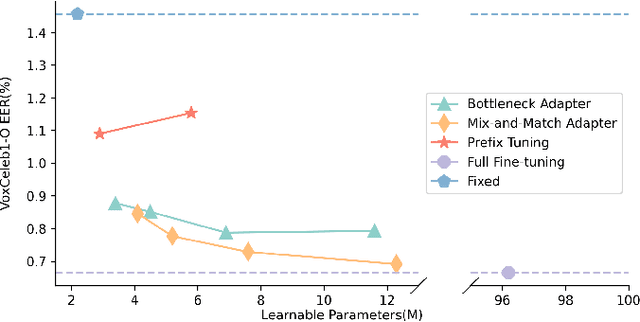
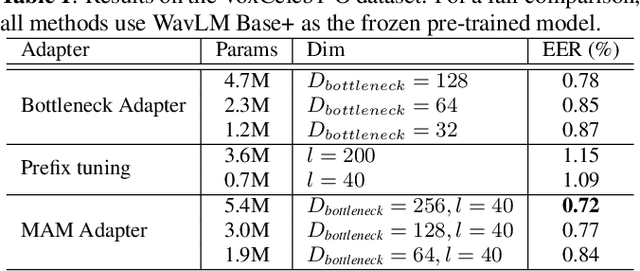
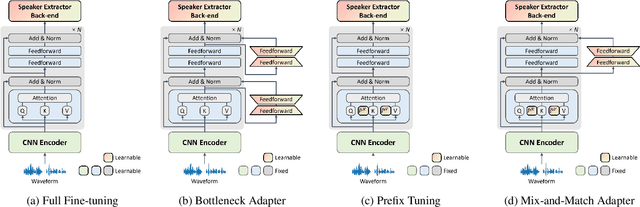
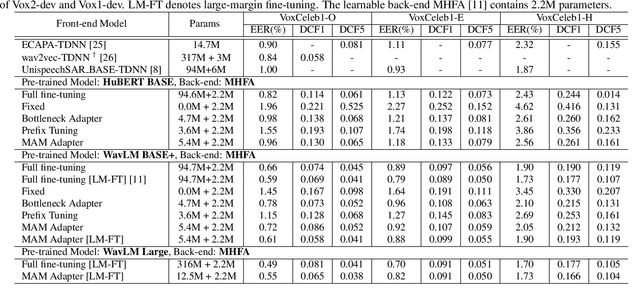
Recently, the pre-trained Transformer models have received a rising interest in the field of speech processing thanks to their great success in various downstream tasks. However, most fine-tuning approaches update all the parameters of the pre-trained model, which becomes prohibitive as the model size grows and sometimes results in overfitting on small datasets. In this paper, we conduct a comprehensive analysis of applying parameter-efficient transfer learning (PETL) methods to reduce the required learnable parameters for adapting to speaker verification tasks. Specifically, during the fine-tuning process, the pre-trained models are frozen, and only lightweight modules inserted in each Transformer block are trainable (a method known as adapters). Moreover, to boost the performance in a cross-language low-resource scenario, the Transformer model is further tuned on a large intermediate dataset before directly fine-tuning it on a small dataset. With updating fewer than 4% of parameters, (our proposed) PETL-based methods achieve comparable performances with full fine-tuning methods (Vox1-O: 0.55%, Vox1-E: 0.82%, Vox1-H:1.73%).
TPARN: Triple-path Attentive Recurrent Network for Time-domain Multichannel Speech Enhancement
Oct 20, 2021
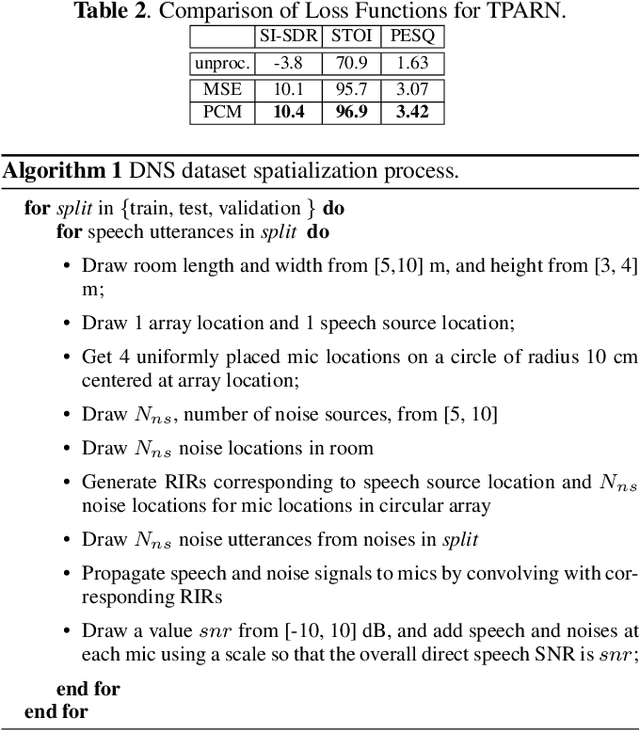
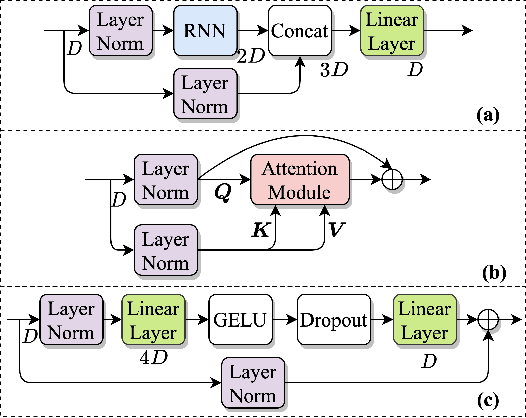
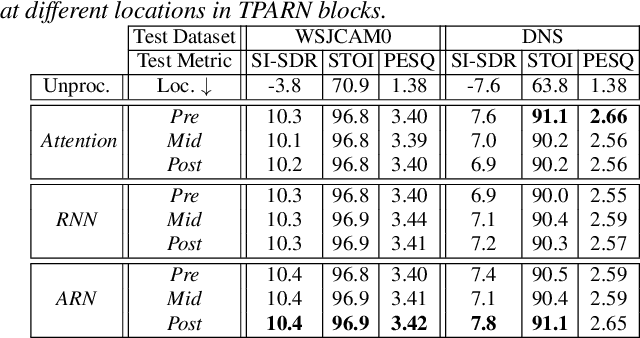
In this work, we propose a new model called triple-path attentive recurrent network (TPARN) for multichannel speech enhancement in the time domain. TPARN extends a single-channel dual-path network to a multichannel network by adding a third path along the spatial dimension. First, TPARN processes speech signals from all channels independently using a dual-path attentive recurrent network (ARN), which is a recurrent neural network (RNN) augmented with self-attention. Next, an ARN is introduced along the spatial dimension for spatial context aggregation. TPARN is designed as a multiple-input and multiple-output architecture to enhance all input channels simultaneously. Experimental results demonstrate the superiority of TPARN over existing state-of-the-art approaches.
Speech Denoising without Clean Training Data: a Noise2Noise Approach
Apr 08, 2021
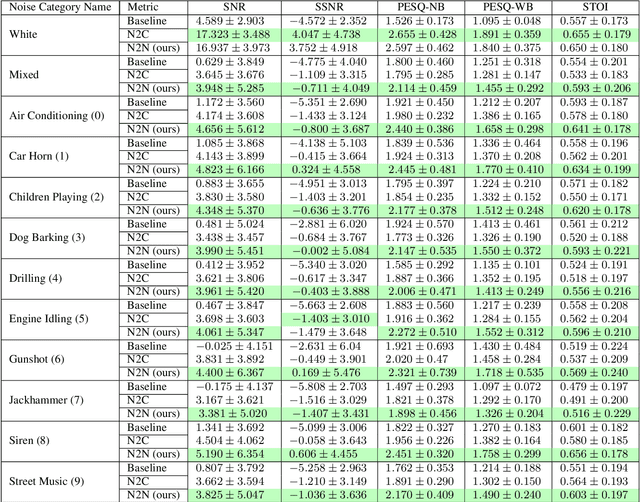
This paper tackles the problem of the heavy dependence of clean speech data required by deep learning based audio-denoising methods by showing that it is possible to train deep speech denoising networks using only noisy speech samples. Conventional wisdom dictates that in order to achieve good speech denoising performance, there is a requirement for a large quantity of both noisy speech samples and perfectly clean speech samples, resulting in a need for expensive audio recording equipment and extremely controlled soundproof recording studios. These requirements pose significant challenges in data collection, especially in economically disadvantaged regions and for low resource languages. This work shows that speech denoising deep neural networks can be successfully trained utilizing only noisy training audio. Furthermore it is revealed that such training regimes achieve superior denoising performance over conventional training regimes utilizing clean training audio targets, in cases involving complex noise distributions and low Signal-to-Noise ratios (high noise environments). This is demonstrated through experiments studying the efficacy of our proposed approach over both real-world noises and synthetic noises using the 20 layered Deep Complex U-Net architecture.
Generating coherent spontaneous speech and gesture from text
Jan 14, 2021
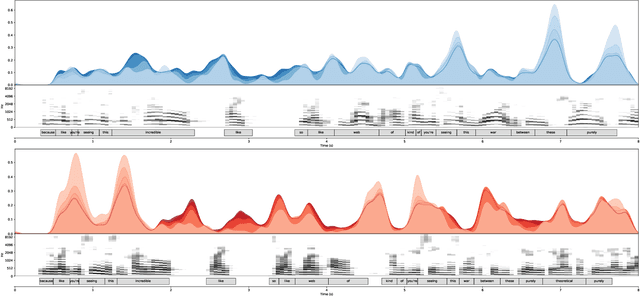
Embodied human communication encompasses both verbal (speech) and non-verbal information (e.g., gesture and head movements). Recent advances in machine learning have substantially improved the technologies for generating synthetic versions of both of these types of data: On the speech side, text-to-speech systems are now able to generate highly convincing, spontaneous-sounding speech using unscripted speech audio as the source material. On the motion side, probabilistic motion-generation methods can now synthesise vivid and lifelike speech-driven 3D gesticulation. In this paper, we put these two state-of-the-art technologies together in a coherent fashion for the first time. Concretely, we demonstrate a proof-of-concept system trained on a single-speaker audio and motion-capture dataset, that is able to generate both speech and full-body gestures together from text input. In contrast to previous approaches for joint speech-and-gesture generation, we generate full-body gestures from speech synthesis trained on recordings of spontaneous speech from the same person as the motion-capture data. We illustrate our results by visualising gesture spaces and text-speech-gesture alignments, and through a demonstration video at https://simonalexanderson.github.io/IVA2020 .
* 3 pages, 2 figures, published at the ACM International Conference on Intelligent Virtual Agents (IVA) 2020
TransPOS: Transformers for Consolidating Different POS Tagset Datasets
Sep 24, 2022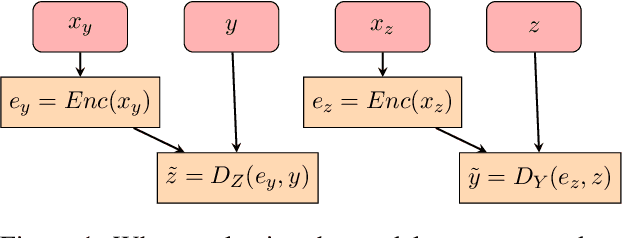
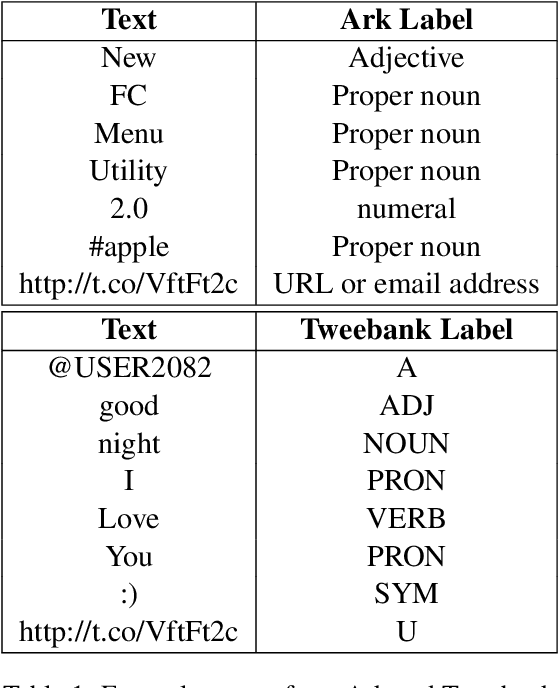
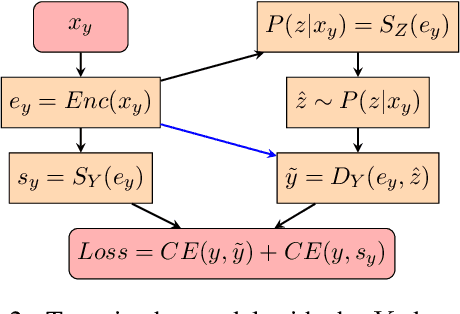
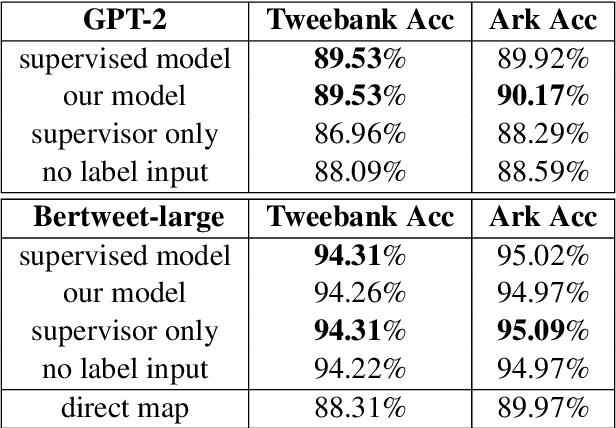
In hope of expanding training data, researchers often want to merge two or more datasets that are created using different labeling schemes. This paper considers two datasets that label part-of-speech (POS) tags under different tagging schemes and leverage the supervised labels of one dataset to help generate labels for the other dataset. This paper further discusses the theoretical difficulties of this approach and proposes a novel supervised architecture employing Transformers to tackle the problem of consolidating two completely disjoint datasets. The results diverge from initial expectations and discourage exploration into the use of disjoint labels to consolidate datasets with different labels.
Egocentric Audio-Visual Noise Suppression
Nov 07, 2022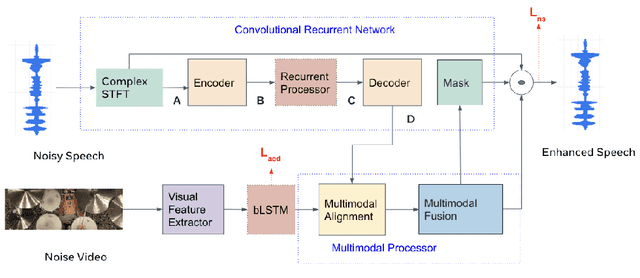
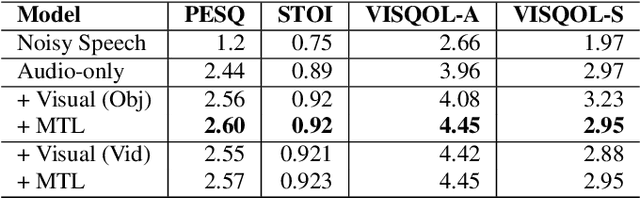
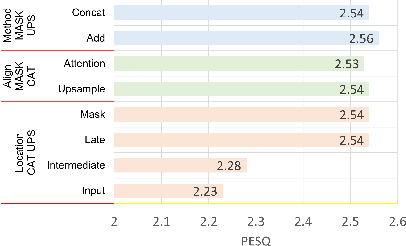

This paper studies audio-visual suppression for egocentric videos -- where the speaker is not captured in the video. Instead, potential noise sources are visible on screen with the camera emulating the off-screen speaker's view of the outside world. This setting is different from prior work in audio-visual speech enhancement that relies on lip and facial visuals. In this paper, we first demonstrate that egocentric visual information is helpful for noise suppression. We compare object recognition and action classification based visual feature extractors, and investigate methods to align audio and visual representations. Then, we examine different fusion strategies for the aligned features, and locations within the noise suppression model to incorporate visual information. Experiments demonstrate that visual features are most helpful when used to generate additive correction masks. Finally, in order to ensure that the visual features are discriminative with respect to different noise types, we introduce a multi-task learning framework that jointly optimizes audio-visual noise suppression and video based acoustic event detection. This proposed multi-task framework outperforms the audio only baseline on all metrics, including a 0.16 PESQ improvement. Extensive ablations reveal the improved performance of the proposed model with multiple active distractors, over all noise types and across different SNRs.
Generalized Product-of-Experts for Learning Multimodal Representations in Noisy Environments
Nov 07, 2022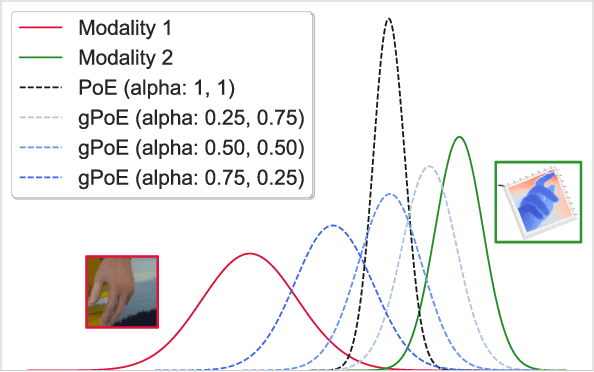
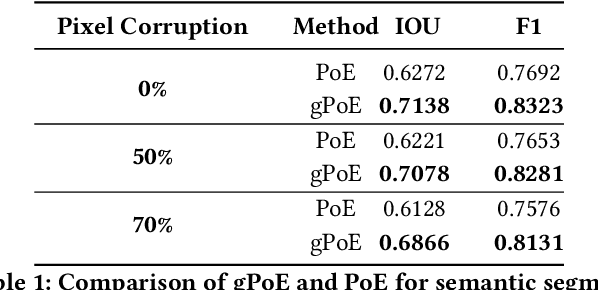
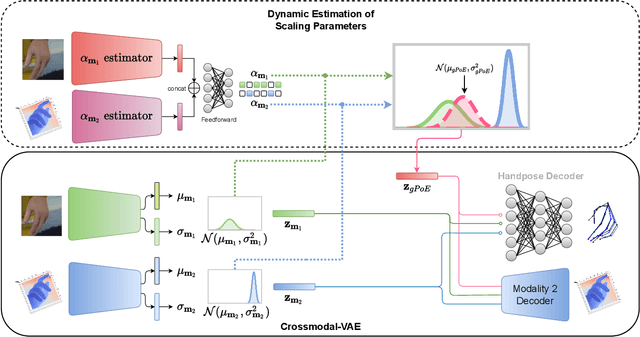
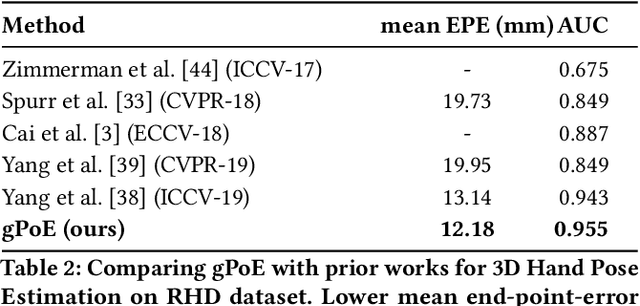
A real-world application or setting involves interaction between different modalities (e.g., video, speech, text). In order to process the multimodal information automatically and use it for an end application, Multimodal Representation Learning (MRL) has emerged as an active area of research in recent times. MRL involves learning reliable and robust representations of information from heterogeneous sources and fusing them. However, in practice, the data acquired from different sources are typically noisy. In some extreme cases, a noise of large magnitude can completely alter the semantics of the data leading to inconsistencies in the parallel multimodal data. In this paper, we propose a novel method for multimodal representation learning in a noisy environment via the generalized product of experts technique. In the proposed method, we train a separate network for each modality to assess the credibility of information coming from that modality, and subsequently, the contribution from each modality is dynamically varied while estimating the joint distribution. We evaluate our method on two challenging benchmarks from two diverse domains: multimodal 3D hand-pose estimation and multimodal surgical video segmentation. We attain state-of-the-art performance on both benchmarks. Our extensive quantitative and qualitative evaluations show the advantages of our method compared to previous approaches.
Dual-Encoder Architecture with Encoder Selection for Joint Close-Talk and Far-Talk Speech Recognition
Sep 17, 2021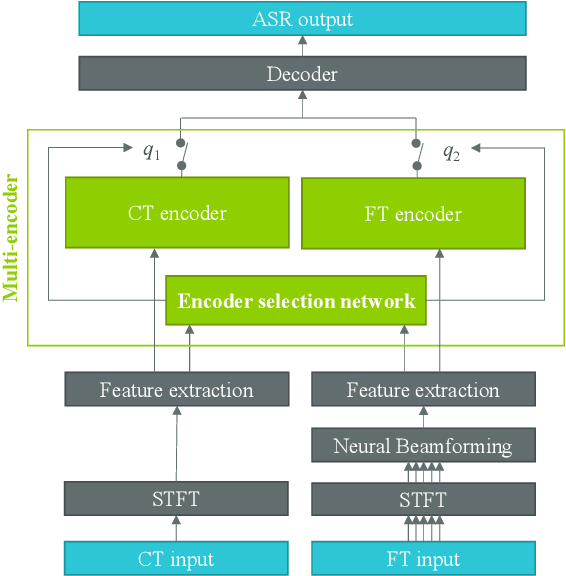

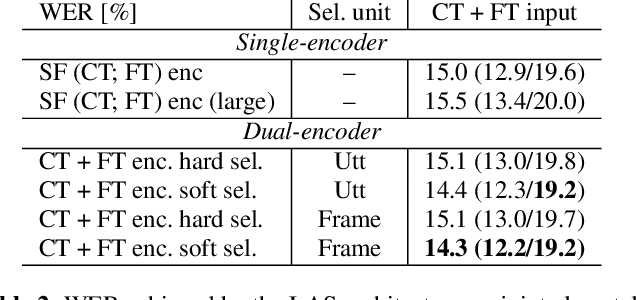
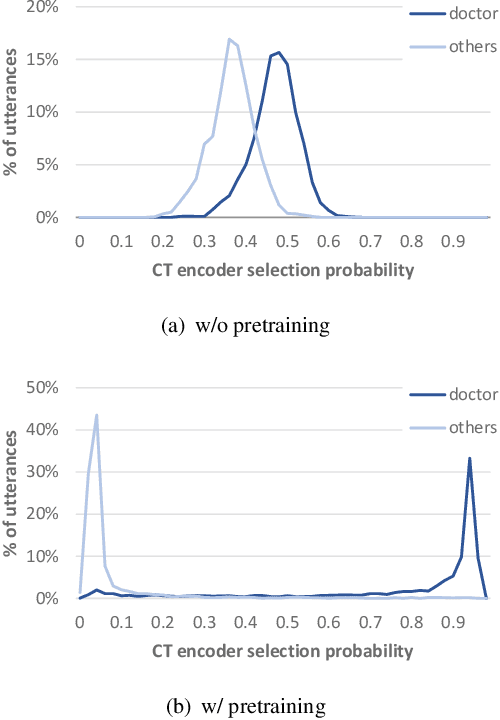
In this paper, we propose a dual-encoder ASR architecture for joint modeling of close-talk (CT) and far-talk (FT) speech, in order to combine the advantages of CT and FT devices for better accuracy. The key idea is to add an encoder selection network to choose the optimal input source (CT or FT) and the corresponding encoder. We use a single-channel encoder for CT speech and a multi-channel encoder with Spatial Filtering neural beamforming for FT speech, which are jointly trained with the encoder selection. We validate our approach on both attention-based and RNN Transducer end-to-end ASR systems. The experiments are done with conversational speech from a medical use case, which is recorded simultaneously with a CT device and a microphone array. Our results show that the proposed dual-encoder architecture obtains up to 9% relative WER reduction when using both CT and FT input, compared to the best single-encoder system trained and tested in matched condition.
An Efficient Multitask Learning Architecture for Affective Vocal Burst Analysis
Sep 28, 2022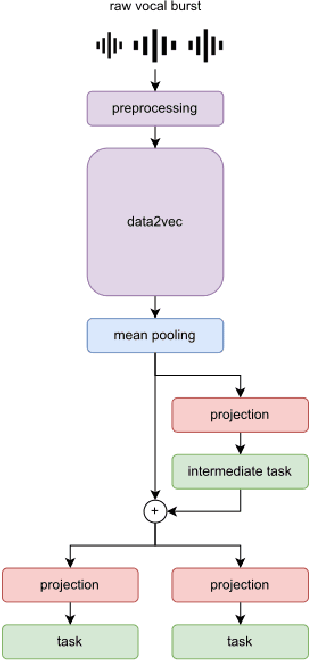
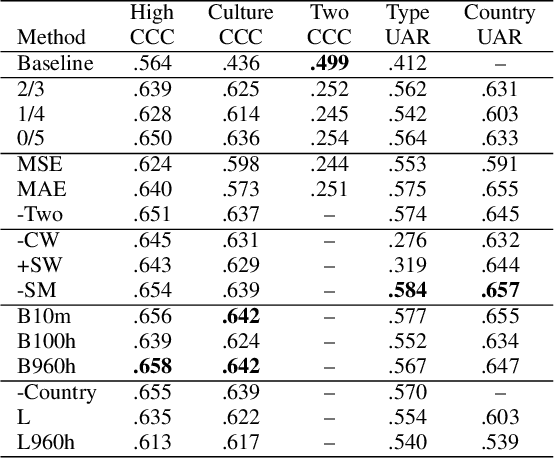
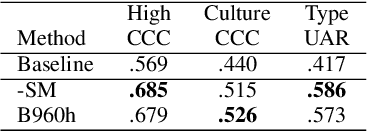
Affective speech analysis is an ongoing topic of research. A relatively new problem in this field is the analysis of vocal bursts, which are nonverbal vocalisations such as laughs or sighs. Current state-of-the-art approaches to address affective vocal burst analysis are mostly based on wav2vec2 or HuBERT features. In this paper, we investigate the use of the wav2vec successor data2vec in combination with a multitask learning pipeline to tackle different analysis problems at once. To assess the performance of our efficient multitask learning architecture, we participate in the 2022 ACII Affective Vocal Burst Challenge, showing that our approach substantially outperforms the baseline established there in three different subtasks.
Token-level Sequence Labeling for Spoken Language Understanding using Compositional End-to-End Models
Oct 27, 2022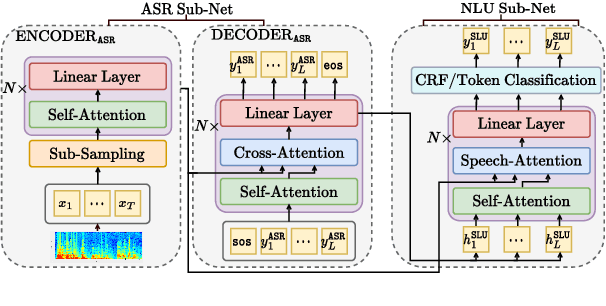
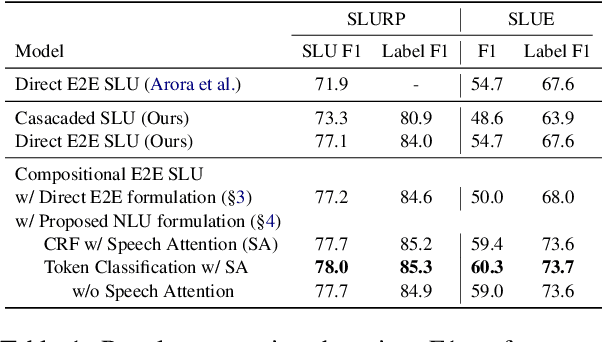
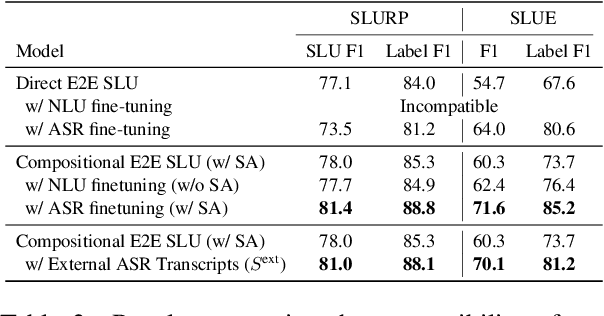

End-to-end spoken language understanding (SLU) systems are gaining popularity over cascaded approaches due to their simplicity and ability to avoid error propagation. However, these systems model sequence labeling as a sequence prediction task causing a divergence from its well-established token-level tagging formulation. We build compositional end-to-end SLU systems that explicitly separate the added complexity of recognizing spoken mentions in SLU from the NLU task of sequence labeling. By relying on intermediate decoders trained for ASR, our end-to-end systems transform the input modality from speech to token-level representations that can be used in the traditional sequence labeling framework. This composition of ASR and NLU formulations in our end-to-end SLU system offers direct compatibility with pre-trained ASR and NLU systems, allows performance monitoring of individual components and enables the use of globally normalized losses like CRF, making them attractive in practical scenarios. Our models outperform both cascaded and direct end-to-end models on a labeling task of named entity recognition across SLU benchmarks.