 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Unsupervised Word Segmentation from Discrete Speech Units in Low-Resource Settings
Jun 08, 2021
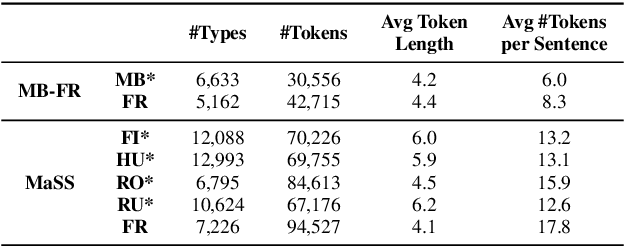
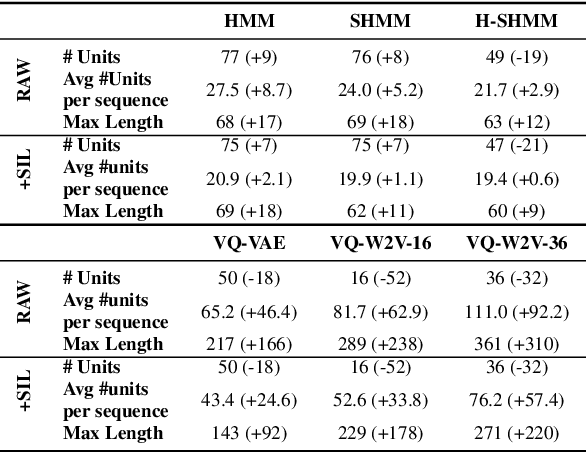
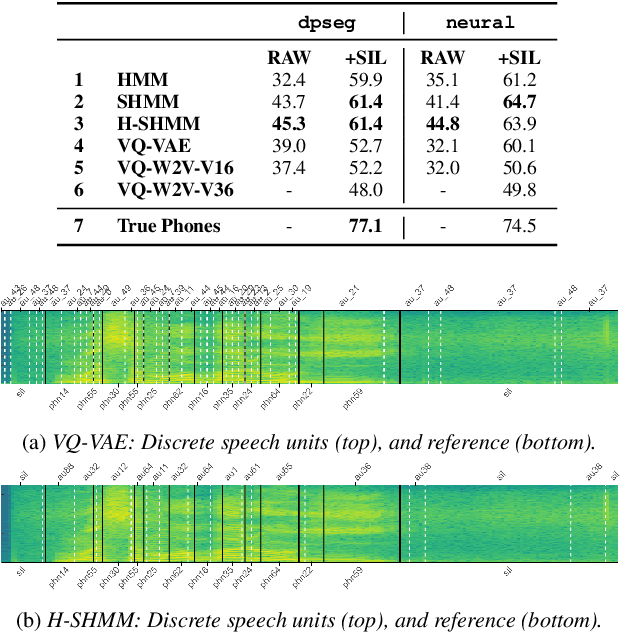
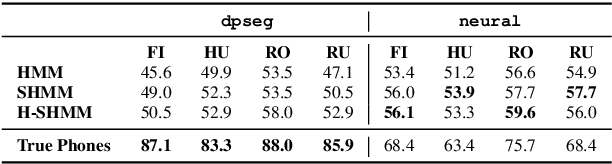
When documenting oral-languages, Unsupervised Word Segmentation (UWS) from speech is a useful, yet challenging, task. It can be performed from phonetic transcriptions, or in the absence of these, from the output of unsupervised speech discretization models. These discretization models are trained using raw speech only, producing discrete speech units which can be applied for downstream (text-based) tasks. In this paper we compare five of these models: three Bayesian and two neural approaches, with regards to the exploitability of the produced units for UWS. Two UWS models are experimented with and we report results for Finnish, Hungarian, Mboshi, Romanian and Russian in a low-resource setting (using only 5k sentences). Our results suggest that neural models for speech discretization are difficult to exploit in our setting, and that it might be necessary to adapt them to limit sequence length. We obtain our best UWS results by using the SHMM and H-SHMM Bayesian models, which produce high quality, yet compressed, discrete representations of the input speech signal.
SERAB: A multi-lingual benchmark for speech emotion recognition
Oct 07, 2021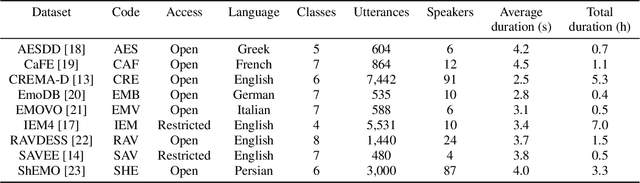
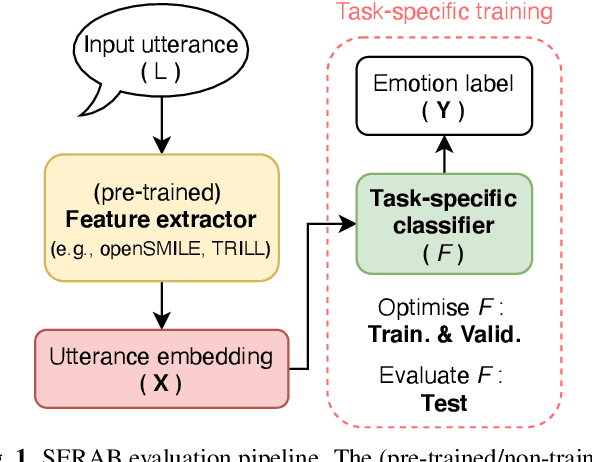
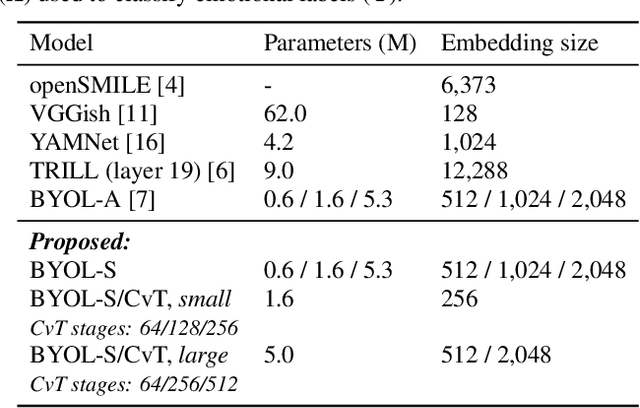
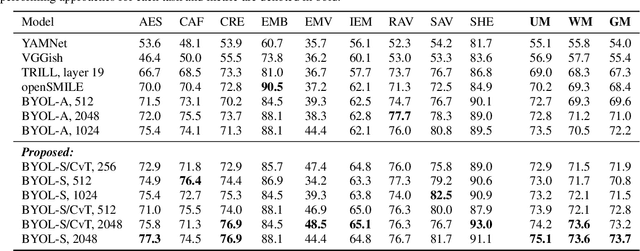
Recent developments in speech emotion recognition (SER) often leverage deep neural networks (DNNs). Comparing and benchmarking different DNN models can often be tedious due to the use of different datasets and evaluation protocols. To facilitate the process, here, we present the Speech Emotion Recognition Adaptation Benchmark (SERAB), a framework for evaluating the performance and generalization capacity of different approaches for utterance-level SER. The benchmark is composed of nine datasets for SER in six languages. Since the datasets have different sizes and numbers of emotional classes, the proposed setup is particularly suitable for estimating the generalization capacity of pre-trained DNN-based feature extractors. We used the proposed framework to evaluate a selection of standard hand-crafted feature sets and state-of-the-art DNN representations. The results highlight that using only a subset of the data included in SERAB can result in biased evaluation, while compliance with the proposed protocol can circumvent this issue.
Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development
Sep 01, 2021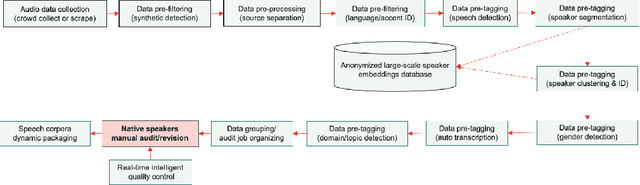
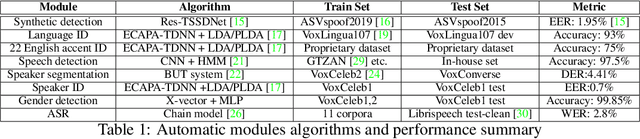

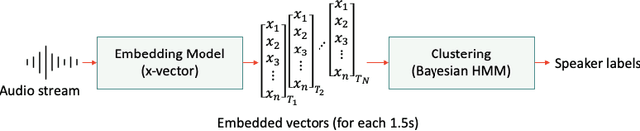
This paper introduces a human-in-the-loop (HITL) data annotation pipeline to generate high-quality, large-scale speech datasets. The pipeline combines human and machine advantages to more quickly, accurately, and cost-effectively annotate datasets with machine pre-labeling and fully manual auditing. Quality control mechanisms such as blind testing, behavior monitoring, and data validation have been adopted in the annotation pipeline to mitigate potential bias introduced by machine-generated labels. Our A/B testing and pilot results demonstrated the HITL pipeline can improve annotation speed and capacity by at least 80% and quality is comparable to or higher than manual double pass annotation. We are leveraging this scalable pipeline to create and continuously grow ultra-high volume off-the-shelf (UHV-OTS) speech corpora for multiple languages, with the capability to expand to 10,000+ hours per language annually. Customized datasets can be produced from the UHV-OTS corpora using dynamic packaging. UHV-OTS is a long-term Appen project to support commercial and academic research data needs in speech processing. Appen will donate a number of free speech datasets from the UHV-OTS each year to support academic and open source community research under the CC-BY-SA license. We are also releasing the code of the data pre-processing and pre-tagging pipeline under the Apache 2.0 license to allow reproduction of the results reported in the paper.
Deep Learning Based Assessment of Synthetic Speech Naturalness
Apr 23, 2021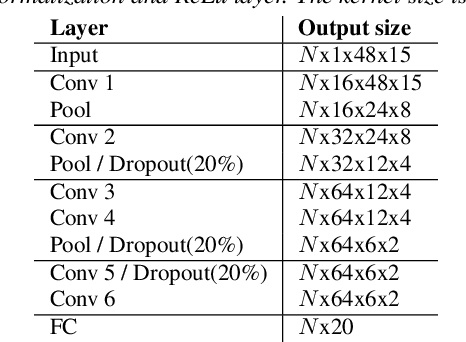
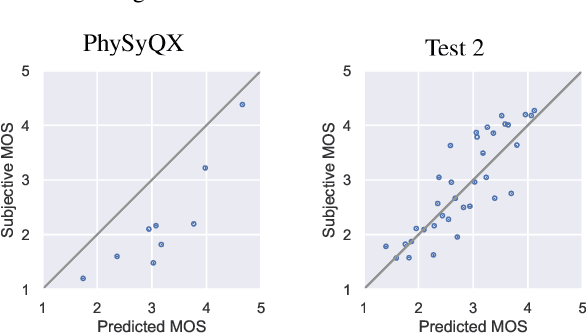
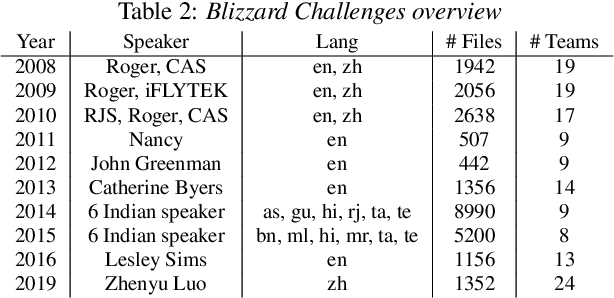
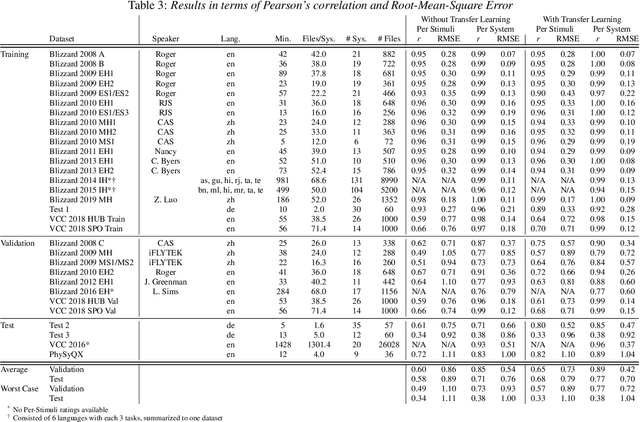
In this paper, we present a new objective prediction model for synthetic speech naturalness. It can be used to evaluate Text-To-Speech or Voice Conversion systems and works language independently. The model is trained end-to-end and based on a CNN-LSTM network that previously showed to give good results for speech quality estimation. We trained and tested the model on 16 different datasets, such as from the Blizzard Challenge and the Voice Conversion Challenge. Further, we show that the reliability of deep learning-based naturalness prediction can be improved by transfer learning from speech quality prediction models that are trained on objective POLQA scores. The proposed model is made publicly available and can, for example, be used to evaluate different TTS system configurations.
TPARN: Triple-path Attentive Recurrent Network for Time-domain Multichannel Speech Enhancement
Oct 20, 2021
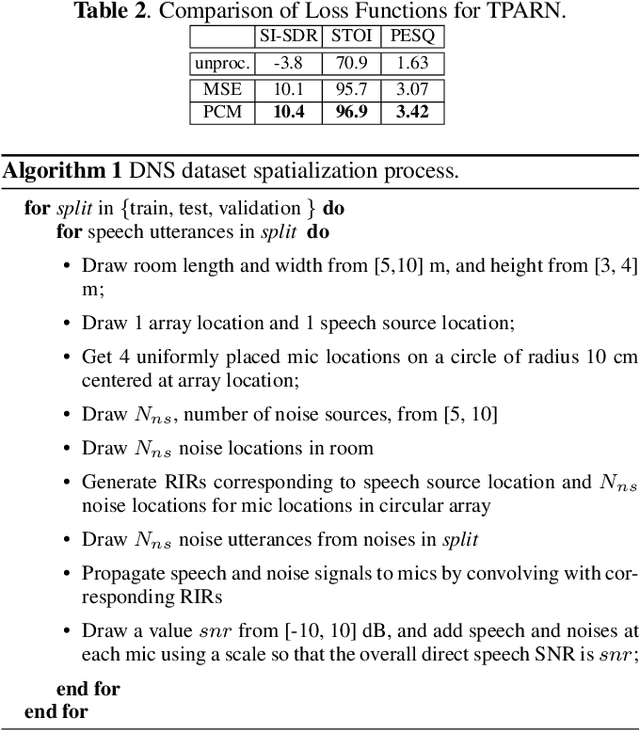
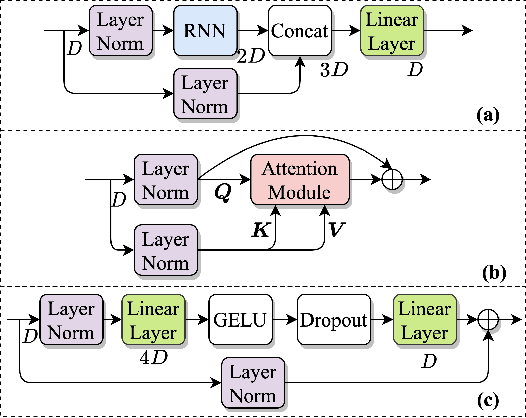
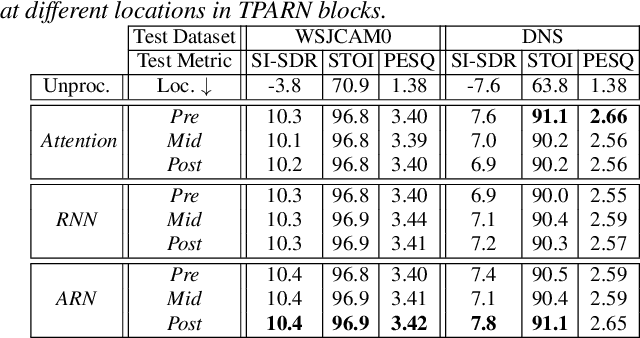
In this work, we propose a new model called triple-path attentive recurrent network (TPARN) for multichannel speech enhancement in the time domain. TPARN extends a single-channel dual-path network to a multichannel network by adding a third path along the spatial dimension. First, TPARN processes speech signals from all channels independently using a dual-path attentive recurrent network (ARN), which is a recurrent neural network (RNN) augmented with self-attention. Next, an ARN is introduced along the spatial dimension for spatial context aggregation. TPARN is designed as a multiple-input and multiple-output architecture to enhance all input channels simultaneously. Experimental results demonstrate the superiority of TPARN over existing state-of-the-art approaches.
A Study on Speech Enhancement Based on Diffusion Probabilistic Model
Jul 25, 2021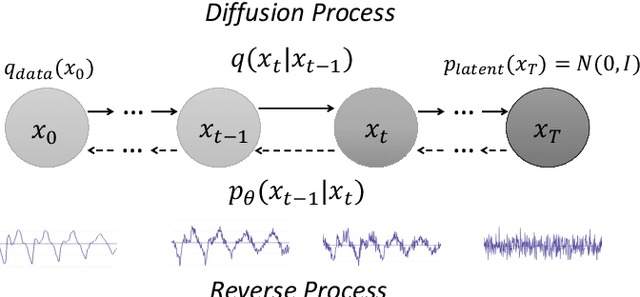
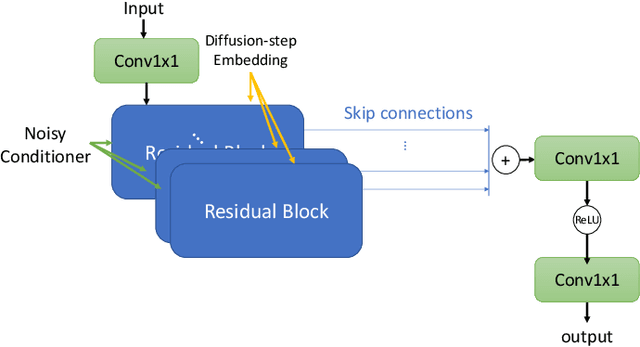
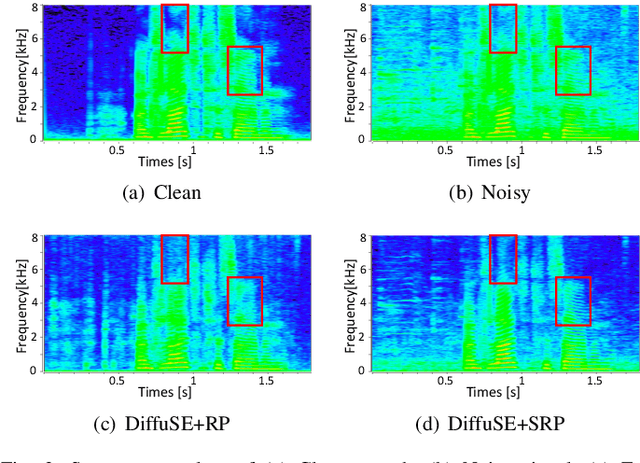
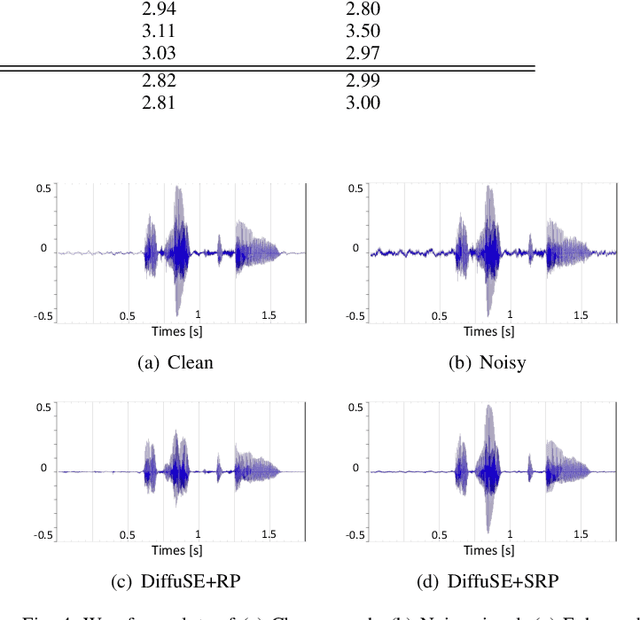
Diffusion probabilistic models have demonstrated an outstanding capability to model natural images and raw audio waveforms through a paired diffusion and reverse processes. The unique property of the reverse process (namely, eliminating non-target signals from the Gaussian noise and noisy signals) could be utilized to restore clean signals. Based on this property, we propose a diffusion probabilistic model-based speech enhancement (DiffuSE) model that aims to recover clean speech signals from noisy signals. The fundamental architecture of the proposed DiffuSE model is similar to that of DiffWave--a high-quality audio waveform generation model that has a relatively low computational cost and footprint. To attain better enhancement performance, we designed an advanced reverse process, termed the supportive reverse process, which adds noisy speech in each time-step to the predicted speech. The experimental results show that DiffuSE yields performance that is comparable to related audio generative models on the standardized Voice Bank corpus SE task. Moreover, relative to the generally suggested full sampling schedule, the proposed supportive reverse process especially improved the fast sampling, taking few steps to yield better enhancement results over the conventional full step inference process.
SEMOUR: A Scripted Emotional Speech Repository for Urdu
May 19, 2021
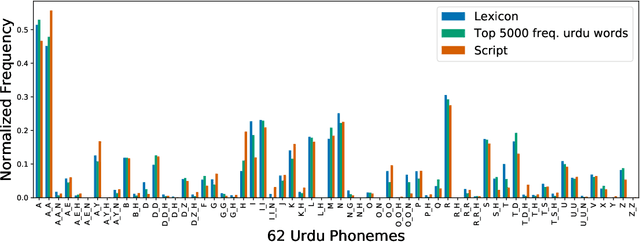
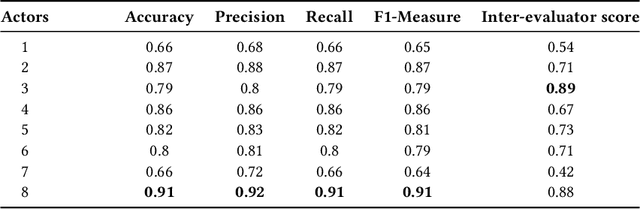
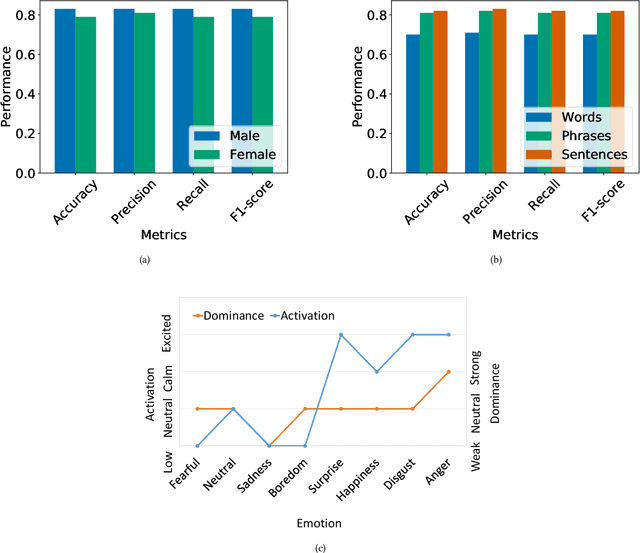
Designing reliable Speech Emotion Recognition systems is a complex task that inevitably requires sufficient data for training purposes. Such extensive datasets are currently available in only a few languages, including English, German, and Italian. In this paper, we present SEMOUR, the first scripted database of emotion-tagged speech in the Urdu language, to design an Urdu Speech Recognition System. Our gender-balanced dataset contains 15,040 unique instances recorded by eight professional actors eliciting a syntactically complex script. The dataset is phonetically balanced, and reliably exhibits a varied set of emotions as marked by the high agreement scores among human raters in experiments. We also provide various baseline speech emotion prediction scores on the database, which could be used for various applications like personalized robot assistants, diagnosis of psychological disorders, and getting feedback from a low-tech-enabled population, etc. On a random test sample, our model correctly predicts an emotion with a state-of-the-art 92% accuracy.
Leveraging Unimodal Self-Supervised Learning for Multimodal Audio-Visual Speech Recognition
Mar 26, 2022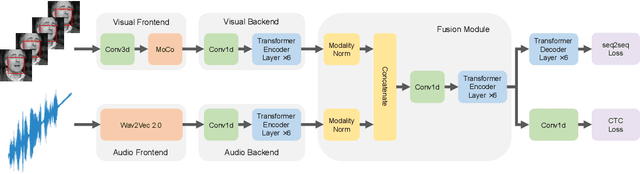
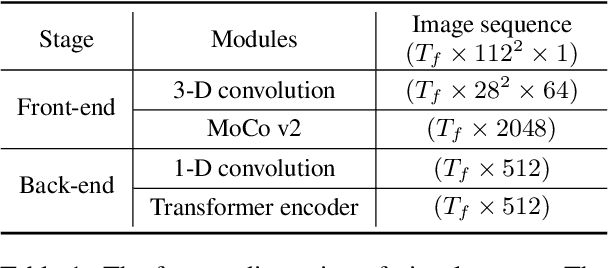


Training Transformer-based models demands a large amount of data, while obtaining aligned and labelled data in multimodality is rather cost-demanding, especially for audio-visual speech recognition (AVSR). Thus it makes a lot of sense to make use of unlabelled unimodal data. On the other side, although the effectiveness of large-scale self-supervised learning is well established in both audio and visual modalities, how to integrate those pre-trained models into a multimodal scenario remains underexplored. In this work, we successfully leverage unimodal self-supervised learning to promote the multimodal AVSR. In particular, audio and visual front-ends are trained on large-scale unimodal datasets, then we integrate components of both front-ends into a larger multimodal framework which learns to recognize parallel audio-visual data into characters through a combination of CTC and seq2seq decoding. We show that both components inherited from unimodal self-supervised learning cooperate well, resulting in that the multimodal framework yields competitive results through fine-tuning. Our model is experimentally validated on both word-level and sentence-level tasks. Especially, even without an external language model, our proposed model raises the state-of-the-art performances on the widely accepted Lip Reading Sentences 2 (LRS2) dataset by a large margin, with a relative improvement of 30%.
LAE: Language-Aware Encoder for Monolingual and Multilingual ASR
Jun 05, 2022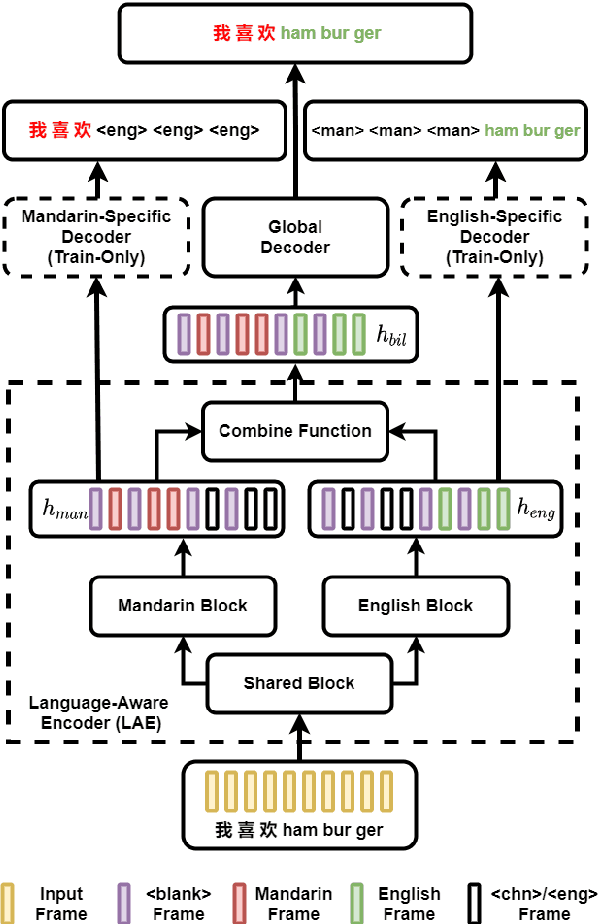
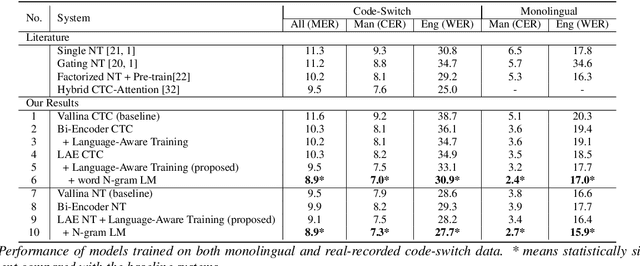
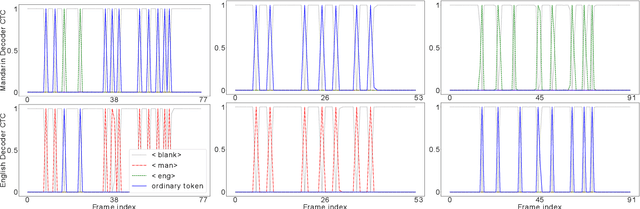
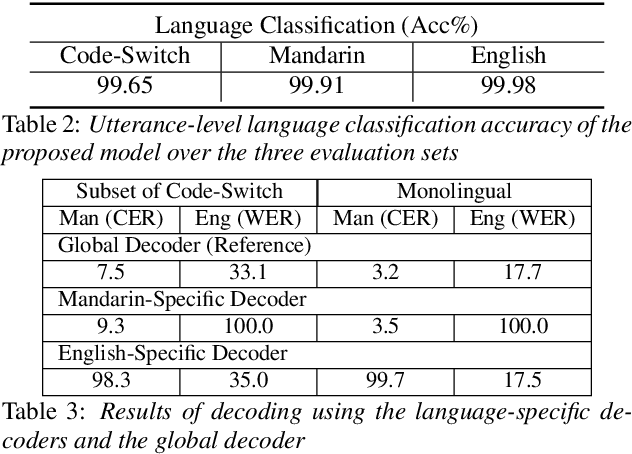
Despite the rapid progress in automatic speech recognition (ASR) research, recognizing multilingual speech using a unified ASR system remains highly challenging. Previous works on multilingual speech recognition mainly focus on two directions: recognizing multiple monolingual speech or recognizing code-switched speech that uses different languages interchangeably within a single utterance. However, a pragmatic multilingual recognizer is expected to be compatible with both directions. In this work, a novel language-aware encoder (LAE) architecture is proposed to handle both situations by disentangling language-specific information and generating frame-level language-aware representations during encoding. In the LAE, the primary encoding is implemented by the shared block while the language-specific blocks are used to extract specific representations for each language. To learn language-specific information discriminatively, a language-aware training method is proposed to optimize the language-specific blocks in LAE. Experiments conducted on Mandarin-English code-switched speech suggest that the proposed LAE is capable of discriminating different languages in frame-level and shows superior performance on both monolingual and multilingual ASR tasks. With either a real-recorded or simulated code-switched dataset, the proposed LAE achieves statistically significant improvements on both CTC and neural transducer systems. Code is released
Predicting speech intelligibility from EEG using a dilated convolutional network
May 19, 2021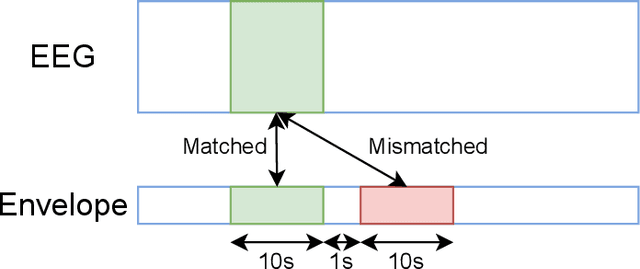
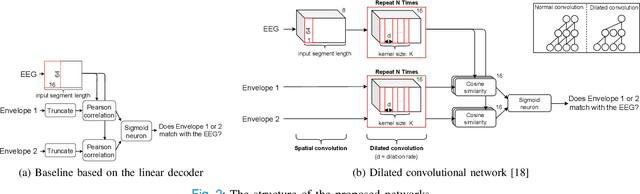
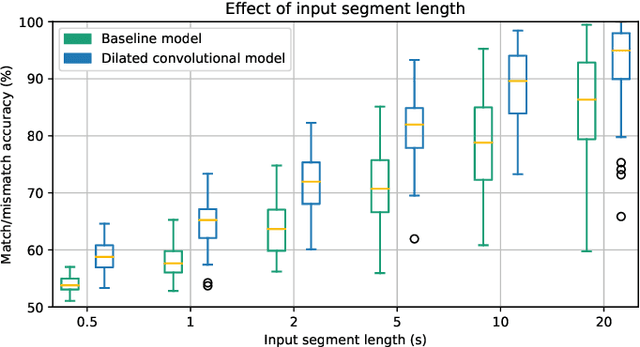
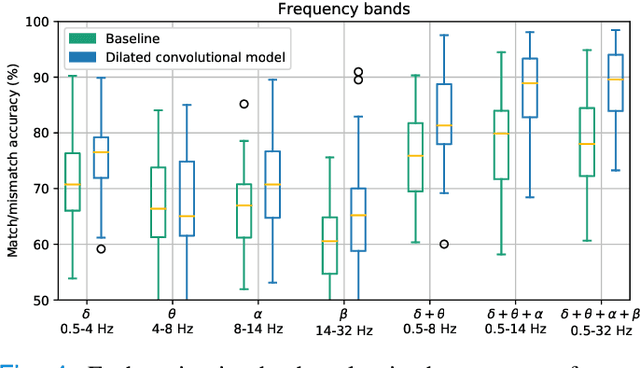
Objective: Currently, only behavioral speech understanding tests are available, which require active participation of the person. As this is infeasible for certain populations, an objective measure of speech intelligibility is required. Recently, brain imaging data has been used to establish a relationship between stimulus and brain response. Linear models have been successfully linked to speech intelligibility but require per-subject training. We present a deep-learning-based model incorporating dilated convolutions that can be used to predict speech intelligibility without subject-specific (re)training. Methods: We evaluated the performance of the model as a function of input segment length, EEG frequency band and receptive field size while comparing it to a baseline model. Next, we evaluated performance on held-out data and finetuning. Finally, we established a link between the accuracy of our model and the state-of-the-art behavioral MATRIX test. Results: The model significantly outperformed the baseline for every input segment length (p$\leq10^{-9}$), for all EEG frequency bands except the theta band (p$\leq0.001$) and for receptive field sizes larger than 125 ms (p$\leq0.05$). Additionally, finetuning significantly increased the accuracy (p$\leq0.05$) on a held-out dataset. Finally, a significant correlation (r=0.59, p=0.0154) was found between the speech reception threshold estimated using the behavioral MATRIX test and our objective method. Conclusion: Our proposed dilated convolutional model can be used as a proxy for speech intelligibility. Significance: Our method is the first to predict the speech reception threshold from EEG for unseen subjects, contributing to objective measures of speech intelligibility.