 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Unsupervised Word Segmentation from Discrete Speech Units in Low-Resource Settings
Jun 08, 2021
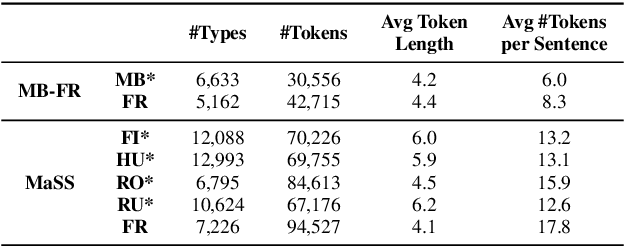
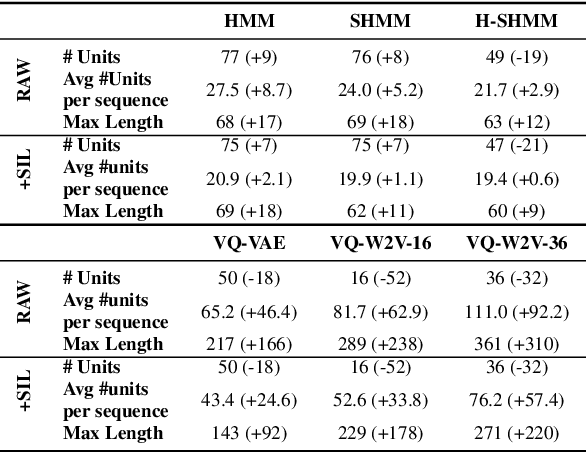
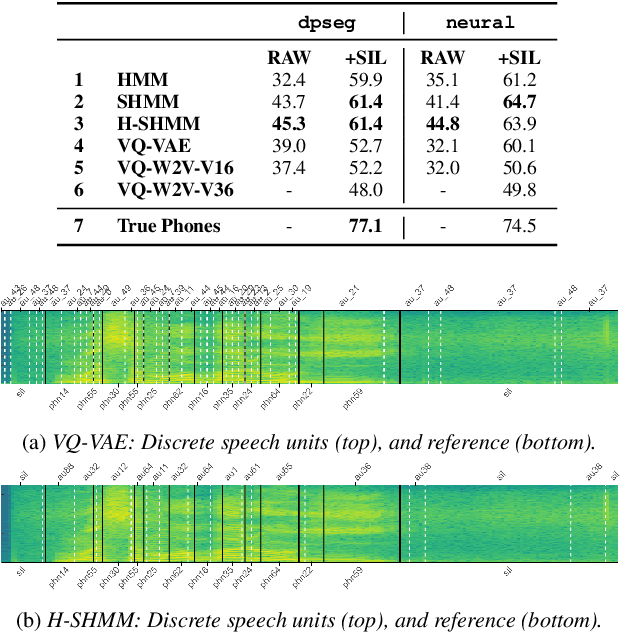
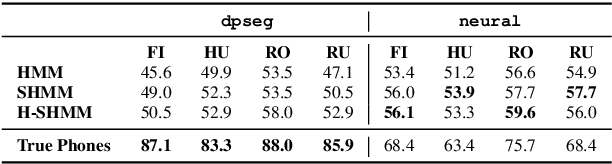
When documenting oral-languages, Unsupervised Word Segmentation (UWS) from speech is a useful, yet challenging, task. It can be performed from phonetic transcriptions, or in the absence of these, from the output of unsupervised speech discretization models. These discretization models are trained using raw speech only, producing discrete speech units which can be applied for downstream (text-based) tasks. In this paper we compare five of these models: three Bayesian and two neural approaches, with regards to the exploitability of the produced units for UWS. Two UWS models are experimented with and we report results for Finnish, Hungarian, Mboshi, Romanian and Russian in a low-resource setting (using only 5k sentences). Our results suggest that neural models for speech discretization are difficult to exploit in our setting, and that it might be necessary to adapt them to limit sequence length. We obtain our best UWS results by using the SHMM and H-SHMM Bayesian models, which produce high quality, yet compressed, discrete representations of the input speech signal.
Deep Learning Based Assessment of Synthetic Speech Naturalness
Apr 23, 2021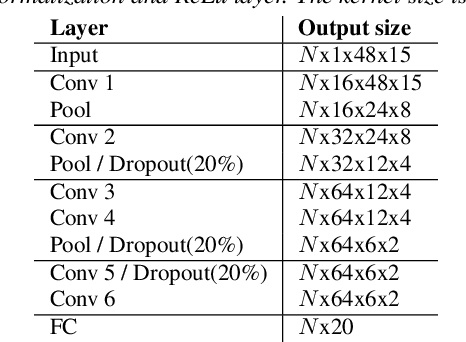
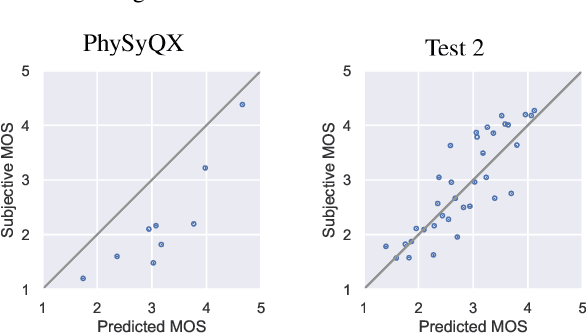
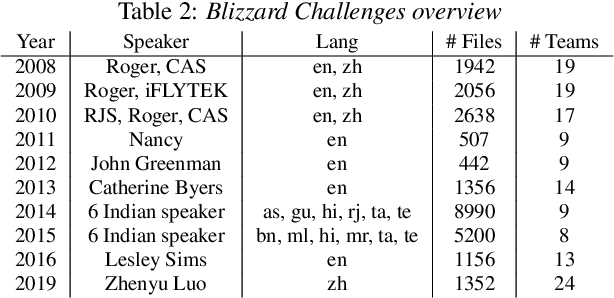
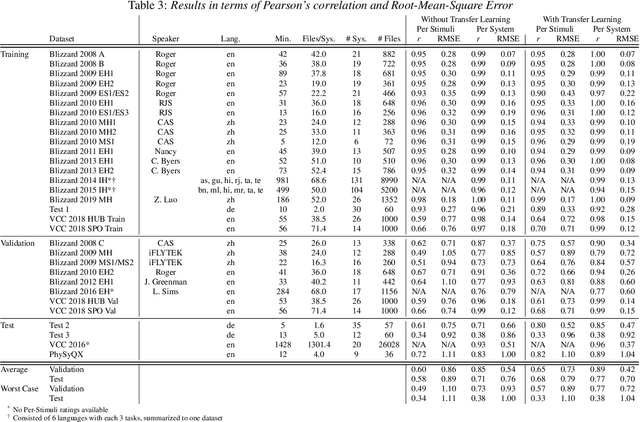
In this paper, we present a new objective prediction model for synthetic speech naturalness. It can be used to evaluate Text-To-Speech or Voice Conversion systems and works language independently. The model is trained end-to-end and based on a CNN-LSTM network that previously showed to give good results for speech quality estimation. We trained and tested the model on 16 different datasets, such as from the Blizzard Challenge and the Voice Conversion Challenge. Further, we show that the reliability of deep learning-based naturalness prediction can be improved by transfer learning from speech quality prediction models that are trained on objective POLQA scores. The proposed model is made publicly available and can, for example, be used to evaluate different TTS system configurations.
GANSpeech: Adversarial Training for High-Fidelity Multi-Speaker Speech Synthesis
Jun 29, 2021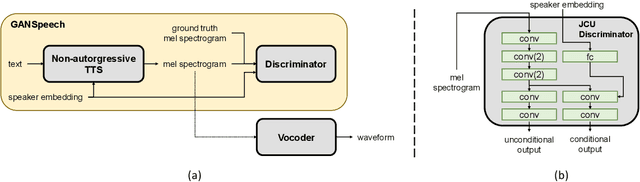


Recent advances in neural multi-speaker text-to-speech (TTS) models have enabled the generation of reasonably good speech quality with a single model and made it possible to synthesize the speech of a speaker with limited training data. Fine-tuning to the target speaker data with the multi-speaker model can achieve better quality, however, there still exists a gap compared to the real speech sample and the model depends on the speaker. In this work, we propose GANSpeech, which is a high-fidelity multi-speaker TTS model that adopts the adversarial training method to a non-autoregressive multi-speaker TTS model. In addition, we propose simple but efficient automatic scaling methods for feature matching loss used in adversarial training. In the subjective listening tests, GANSpeech significantly outperformed the baseline multi-speaker FastSpeech and FastSpeech2 models, and showed a better MOS score than the speaker-specific fine-tuned FastSpeech2.
Egocentric Audio-Visual Noise Suppression
Nov 07, 2022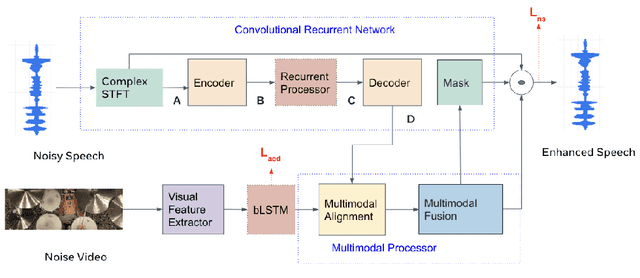
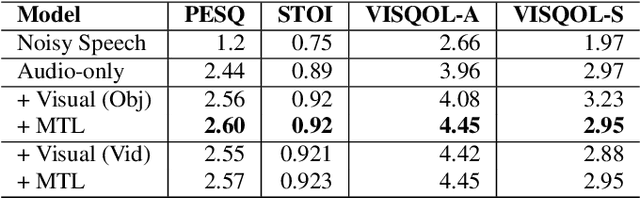
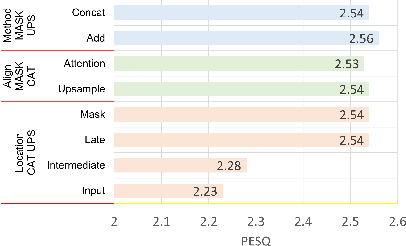

This paper studies audio-visual suppression for egocentric videos -- where the speaker is not captured in the video. Instead, potential noise sources are visible on screen with the camera emulating the off-screen speaker's view of the outside world. This setting is different from prior work in audio-visual speech enhancement that relies on lip and facial visuals. In this paper, we first demonstrate that egocentric visual information is helpful for noise suppression. We compare object recognition and action classification based visual feature extractors, and investigate methods to align audio and visual representations. Then, we examine different fusion strategies for the aligned features, and locations within the noise suppression model to incorporate visual information. Experiments demonstrate that visual features are most helpful when used to generate additive correction masks. Finally, in order to ensure that the visual features are discriminative with respect to different noise types, we introduce a multi-task learning framework that jointly optimizes audio-visual noise suppression and video based acoustic event detection. This proposed multi-task framework outperforms the audio only baseline on all metrics, including a 0.16 PESQ improvement. Extensive ablations reveal the improved performance of the proposed model with multiple active distractors, over all noise types and across different SNRs.
Generalized Product-of-Experts for Learning Multimodal Representations in Noisy Environments
Nov 07, 2022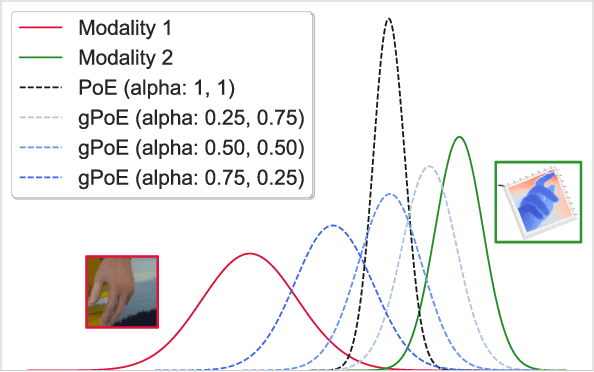
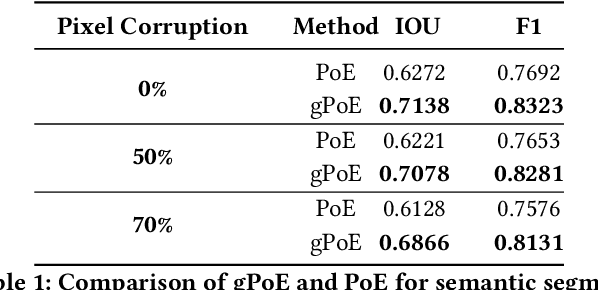
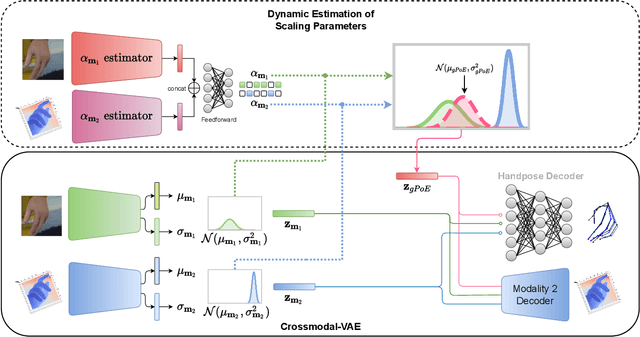
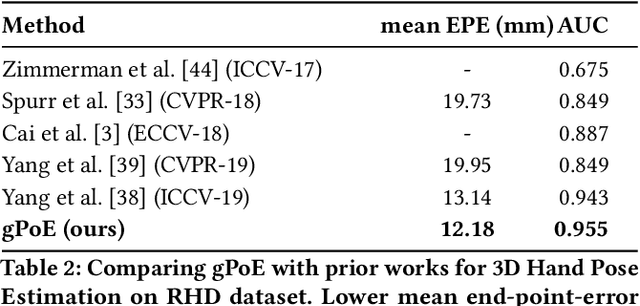
A real-world application or setting involves interaction between different modalities (e.g., video, speech, text). In order to process the multimodal information automatically and use it for an end application, Multimodal Representation Learning (MRL) has emerged as an active area of research in recent times. MRL involves learning reliable and robust representations of information from heterogeneous sources and fusing them. However, in practice, the data acquired from different sources are typically noisy. In some extreme cases, a noise of large magnitude can completely alter the semantics of the data leading to inconsistencies in the parallel multimodal data. In this paper, we propose a novel method for multimodal representation learning in a noisy environment via the generalized product of experts technique. In the proposed method, we train a separate network for each modality to assess the credibility of information coming from that modality, and subsequently, the contribution from each modality is dynamically varied while estimating the joint distribution. We evaluate our method on two challenging benchmarks from two diverse domains: multimodal 3D hand-pose estimation and multimodal surgical video segmentation. We attain state-of-the-art performance on both benchmarks. Our extensive quantitative and qualitative evaluations show the advantages of our method compared to previous approaches.
Speech Resynthesis from Discrete Disentangled Self-Supervised Representations
Apr 02, 2021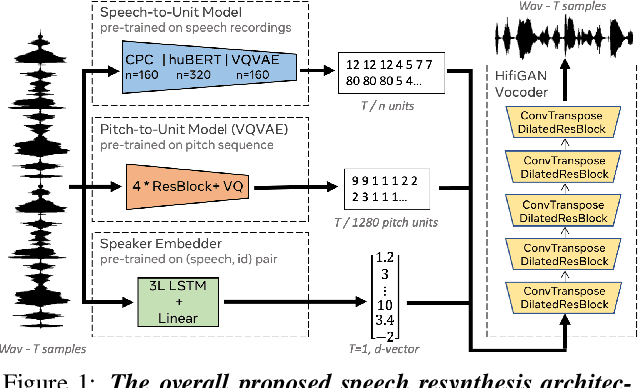
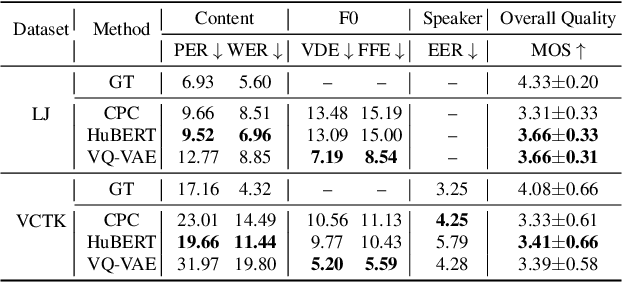
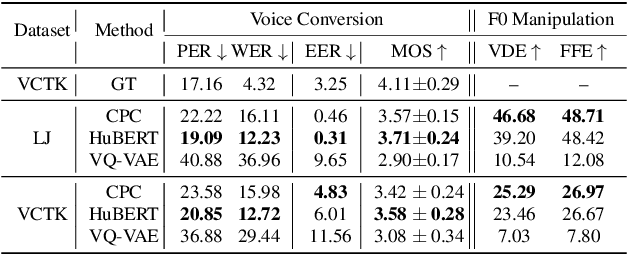
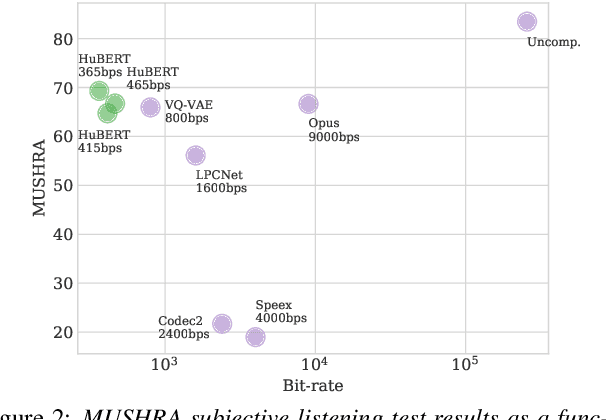
We propose using self-supervised discrete representations for the task of speech resynthesis. To generate disentangled representation, we separately extract low-bitrate representations for speech content, prosodic information, and speaker identity. This allows to synthesize speech in a controllable manner. We analyze various state-of-the-art, self-supervised representation learning methods and shed light on the advantages of each method while considering reconstruction quality and disentanglement properties. Specifically, we evaluate the F0 reconstruction, speaker identification performance (for both resynthesis and voice conversion), recordings' intelligibility, and overall quality using subjective human evaluation. Lastly, we demonstrate how these representations can be used for an ultra-lightweight speech codec. Using the obtained representations, we can get to a rate of 365 bits per second while providing better speech quality than the baseline methods. Audio samples can be found under https://resynthesis-ssl.github.io/.
SEMOUR: A Scripted Emotional Speech Repository for Urdu
May 19, 2021
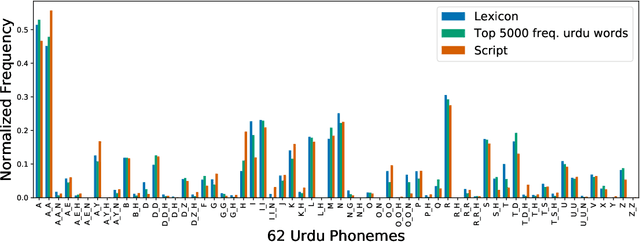
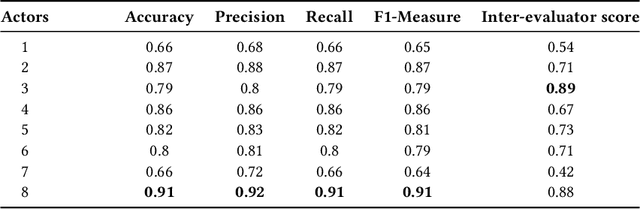
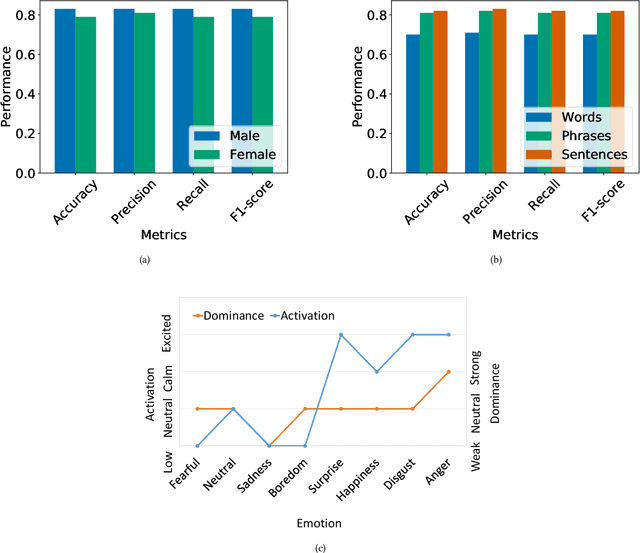
Designing reliable Speech Emotion Recognition systems is a complex task that inevitably requires sufficient data for training purposes. Such extensive datasets are currently available in only a few languages, including English, German, and Italian. In this paper, we present SEMOUR, the first scripted database of emotion-tagged speech in the Urdu language, to design an Urdu Speech Recognition System. Our gender-balanced dataset contains 15,040 unique instances recorded by eight professional actors eliciting a syntactically complex script. The dataset is phonetically balanced, and reliably exhibits a varied set of emotions as marked by the high agreement scores among human raters in experiments. We also provide various baseline speech emotion prediction scores on the database, which could be used for various applications like personalized robot assistants, diagnosis of psychological disorders, and getting feedback from a low-tech-enabled population, etc. On a random test sample, our model correctly predicts an emotion with a state-of-the-art 92% accuracy.
TransPOS: Transformers for Consolidating Different POS Tagset Datasets
Sep 24, 2022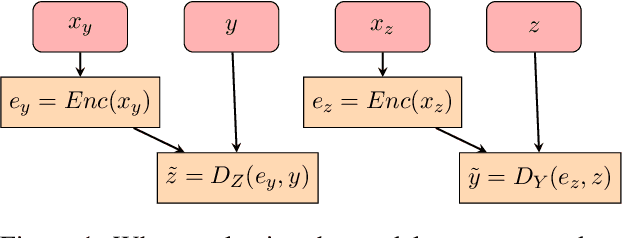
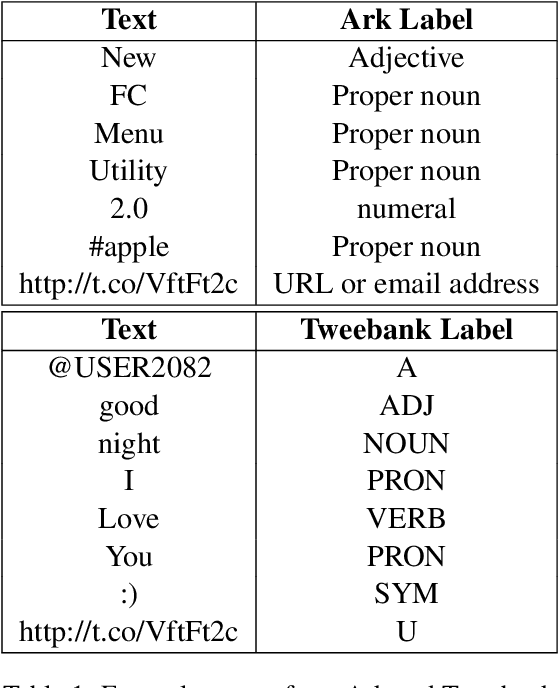
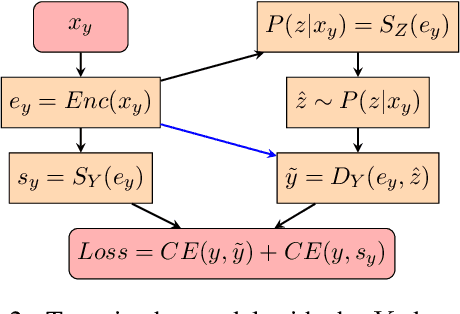
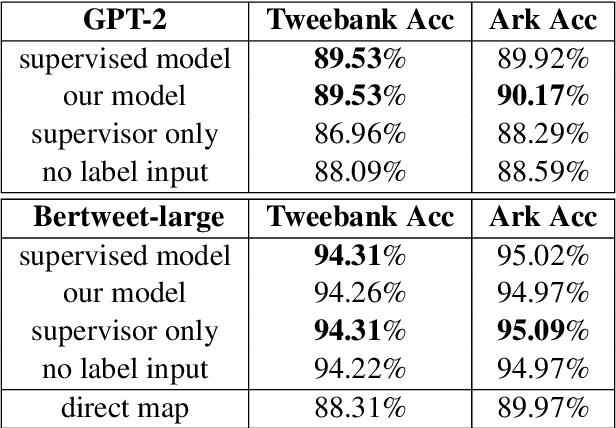
In hope of expanding training data, researchers often want to merge two or more datasets that are created using different labeling schemes. This paper considers two datasets that label part-of-speech (POS) tags under different tagging schemes and leverage the supervised labels of one dataset to help generate labels for the other dataset. This paper further discusses the theoretical difficulties of this approach and proposes a novel supervised architecture employing Transformers to tackle the problem of consolidating two completely disjoint datasets. The results diverge from initial expectations and discourage exploration into the use of disjoint labels to consolidate datasets with different labels.
A Review on Part-of-Speech Technologies
Oct 11, 2021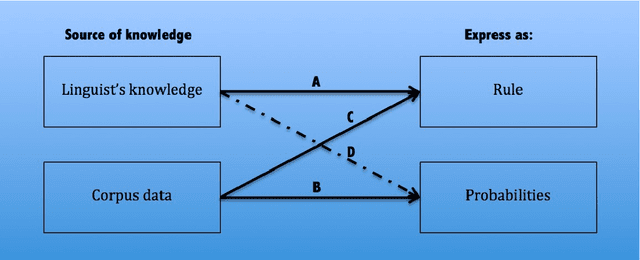
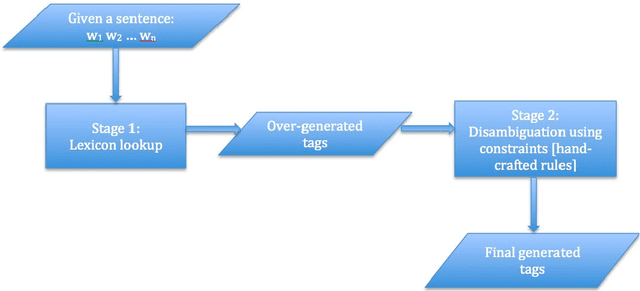
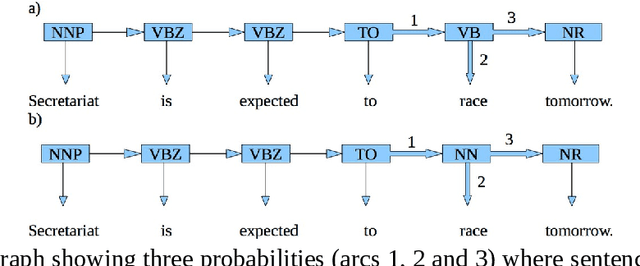
Developing an automatic part-of-speech (POS) tagging for any new language is considered a necessary step for further computational linguistics methodology beyond tagging, like chunking and parsing, to be fully applied to the language. Many POS disambiguation technologies have been developed for this type of research and there are factors that influence the choice of choosing one. This could be either corpus-based or non-corpus-based. In this paper, we present a review of POS tagging technologies.
Predicting speech intelligibility from EEG using a dilated convolutional network
May 19, 2021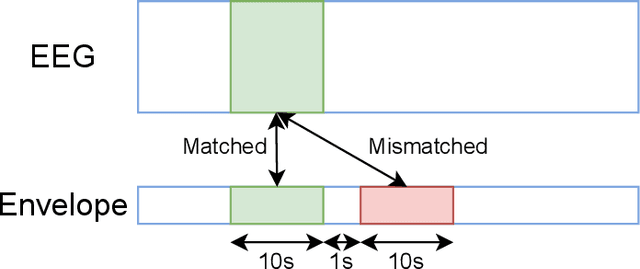
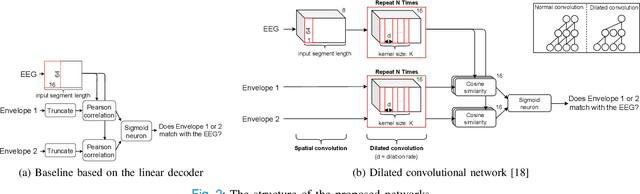
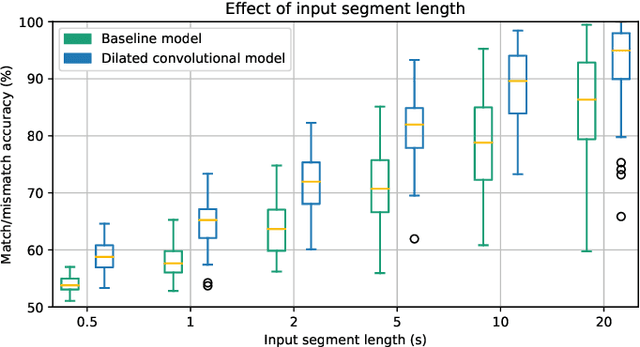
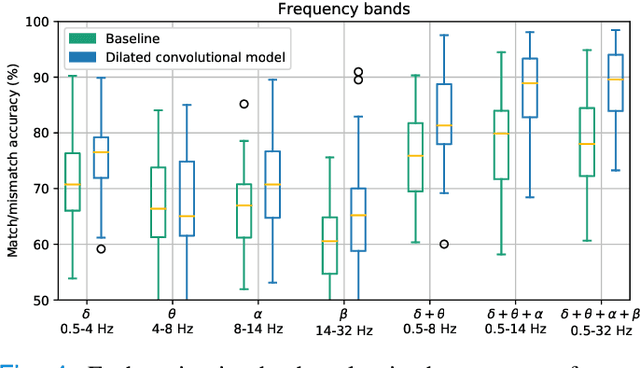
Objective: Currently, only behavioral speech understanding tests are available, which require active participation of the person. As this is infeasible for certain populations, an objective measure of speech intelligibility is required. Recently, brain imaging data has been used to establish a relationship between stimulus and brain response. Linear models have been successfully linked to speech intelligibility but require per-subject training. We present a deep-learning-based model incorporating dilated convolutions that can be used to predict speech intelligibility without subject-specific (re)training. Methods: We evaluated the performance of the model as a function of input segment length, EEG frequency band and receptive field size while comparing it to a baseline model. Next, we evaluated performance on held-out data and finetuning. Finally, we established a link between the accuracy of our model and the state-of-the-art behavioral MATRIX test. Results: The model significantly outperformed the baseline for every input segment length (p$\leq10^{-9}$), for all EEG frequency bands except the theta band (p$\leq0.001$) and for receptive field sizes larger than 125 ms (p$\leq0.05$). Additionally, finetuning significantly increased the accuracy (p$\leq0.05$) on a held-out dataset. Finally, a significant correlation (r=0.59, p=0.0154) was found between the speech reception threshold estimated using the behavioral MATRIX test and our objective method. Conclusion: Our proposed dilated convolutional model can be used as a proxy for speech intelligibility. Significance: Our method is the first to predict the speech reception threshold from EEG for unseen subjects, contributing to objective measures of speech intelligibility.