 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Taylor, Can You Hear Me Now? A Taylor-Unfolding Framework for Monaural Speech Enhancement
Apr 30, 2022
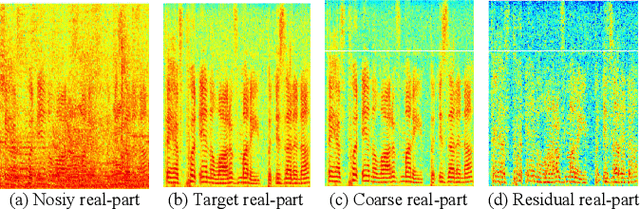
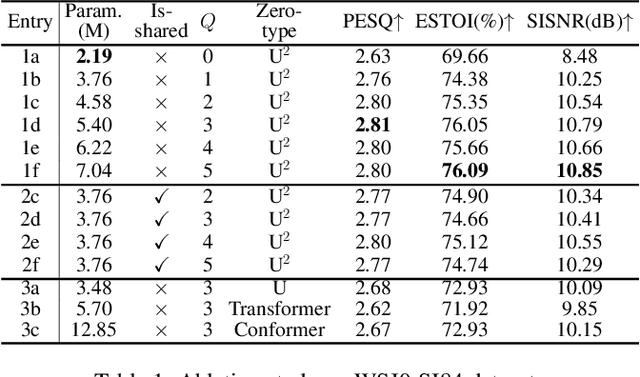
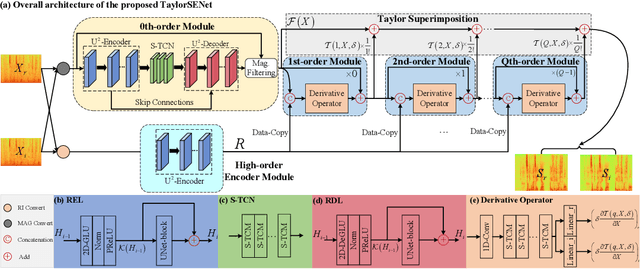
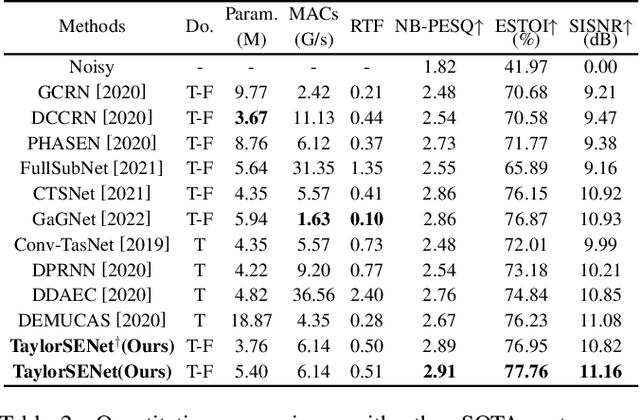
While the deep learning techniques promote the rapid development of the speech enhancement (SE) community, most schemes only pursue the performance in a black-box manner and lack adequate model interpretability. Inspired by Taylor's approximation theory, we propose an interpretable decoupling-style SE framework, which disentangles the complex spectrum recovery into two separate optimization problems \emph{i.e.}, magnitude and complex residual estimation. Specifically, serving as the 0th-order term in Taylor's series, a filter network is delicately devised to suppress the noise component only in the magnitude domain and obtain a coarse spectrum. To refine the phase distribution, we estimate the sparse complex residual, which is defined as the difference between target and coarse spectra, and measures the phase gap. In this study, we formulate the residual component as the combination of various high-order Taylor terms and propose a lightweight trainable module to replace the complicated derivative operator between adjacent terms. Finally, following Taylor's formula, we can reconstruct the target spectrum by the superimposition between 0th-order and high-order terms. Experimental results on two benchmark datasets show that our framework achieves state-of-the-art performance over previous competing baselines in various evaluation metrics. The source code is available at github.com/Andong-Lispeech/TaylorSENet.
Egocentric Audio-Visual Noise Suppression
Nov 07, 2022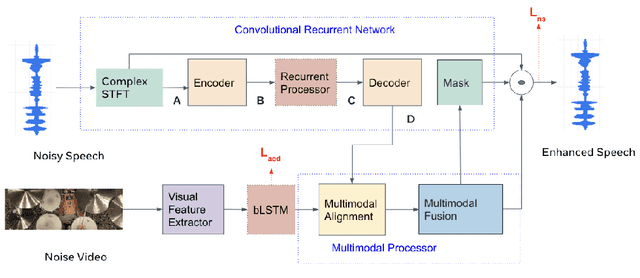
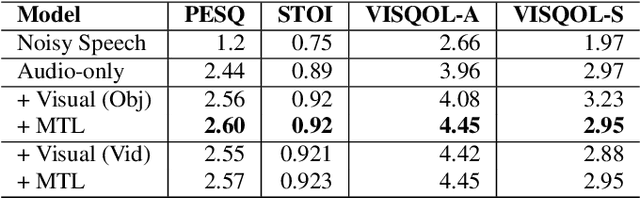
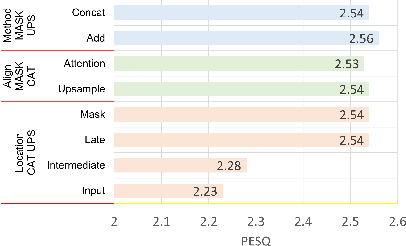

This paper studies audio-visual suppression for egocentric videos -- where the speaker is not captured in the video. Instead, potential noise sources are visible on screen with the camera emulating the off-screen speaker's view of the outside world. This setting is different from prior work in audio-visual speech enhancement that relies on lip and facial visuals. In this paper, we first demonstrate that egocentric visual information is helpful for noise suppression. We compare object recognition and action classification based visual feature extractors, and investigate methods to align audio and visual representations. Then, we examine different fusion strategies for the aligned features, and locations within the noise suppression model to incorporate visual information. Experiments demonstrate that visual features are most helpful when used to generate additive correction masks. Finally, in order to ensure that the visual features are discriminative with respect to different noise types, we introduce a multi-task learning framework that jointly optimizes audio-visual noise suppression and video based acoustic event detection. This proposed multi-task framework outperforms the audio only baseline on all metrics, including a 0.16 PESQ improvement. Extensive ablations reveal the improved performance of the proposed model with multiple active distractors, over all noise types and across different SNRs.
Generalized Product-of-Experts for Learning Multimodal Representations in Noisy Environments
Nov 07, 2022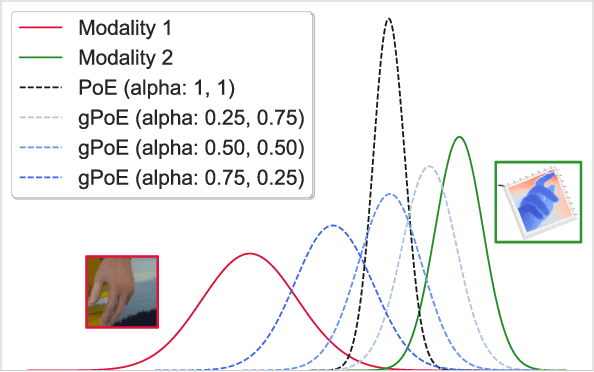
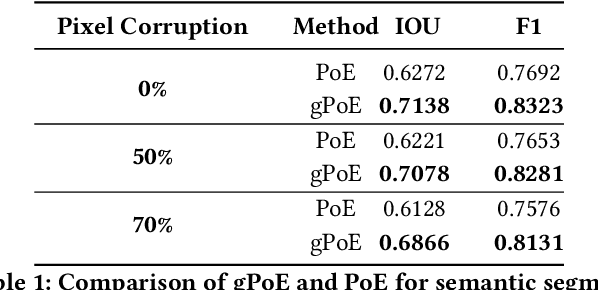
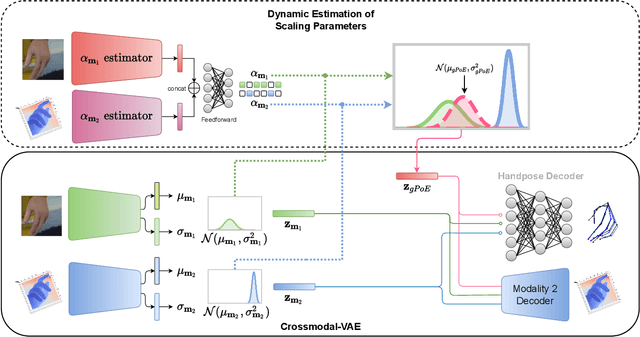
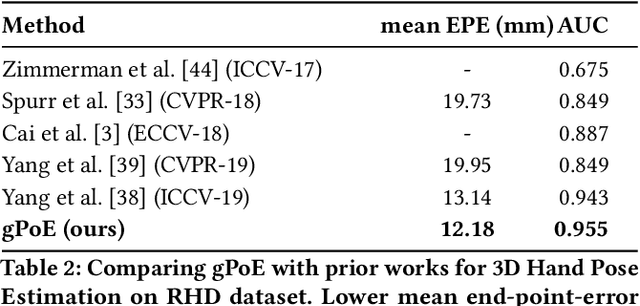
A real-world application or setting involves interaction between different modalities (e.g., video, speech, text). In order to process the multimodal information automatically and use it for an end application, Multimodal Representation Learning (MRL) has emerged as an active area of research in recent times. MRL involves learning reliable and robust representations of information from heterogeneous sources and fusing them. However, in practice, the data acquired from different sources are typically noisy. In some extreme cases, a noise of large magnitude can completely alter the semantics of the data leading to inconsistencies in the parallel multimodal data. In this paper, we propose a novel method for multimodal representation learning in a noisy environment via the generalized product of experts technique. In the proposed method, we train a separate network for each modality to assess the credibility of information coming from that modality, and subsequently, the contribution from each modality is dynamically varied while estimating the joint distribution. We evaluate our method on two challenging benchmarks from two diverse domains: multimodal 3D hand-pose estimation and multimodal surgical video segmentation. We attain state-of-the-art performance on both benchmarks. Our extensive quantitative and qualitative evaluations show the advantages of our method compared to previous approaches.
Facetron: Multi-speaker Face-to-Speech Model based on Cross-modal Latent Representations
Jul 26, 2021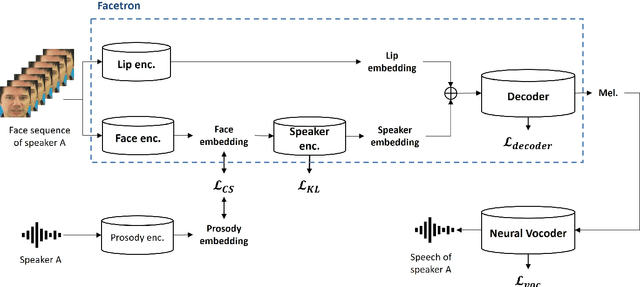
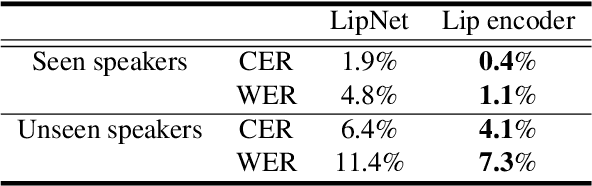
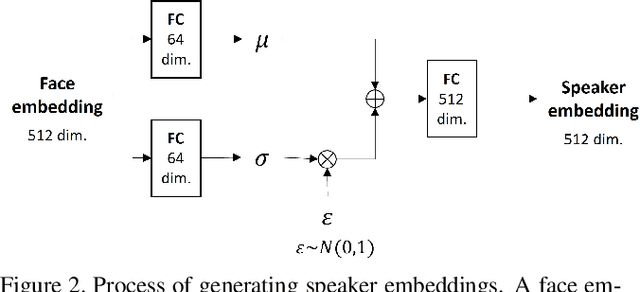
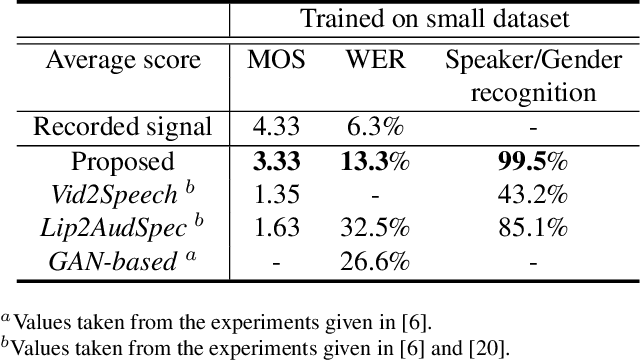
In this paper, we propose an effective method to synthesize speaker-specific speech waveforms by conditioning on videos of an individual's face. Using a generative adversarial network (GAN) with linguistic and speaker characteristic features as auxiliary conditions, our method directly converts face images into speech waveforms under an end-to-end training framework. The linguistic features are extracted from lip movements using a lip-reading model, and the speaker characteristic features are predicted from face images using cross-modal learning with a pre-trained acoustic model. Since these two features are uncorrelated and controlled independently, we can flexibly synthesize speech waveforms whose speaker characteristics vary depending on the input face images. Therefore, our method can be regarded as a multi-speaker face-to-speech waveform model. We show the superiority of our proposed model over conventional methods in terms of both objective and subjective evaluation results. Specifically, we evaluate the performances of the linguistic feature and the speaker characteristic generation modules by measuring the accuracy of automatic speech recognition and automatic speaker/gender recognition tasks, respectively. We also evaluate the naturalness of the synthesized speech waveforms using a mean opinion score (MOS) test.
K-Wav2vec 2.0: Automatic Speech Recognition based on Joint Decoding of Graphemes and Syllables
Oct 11, 2021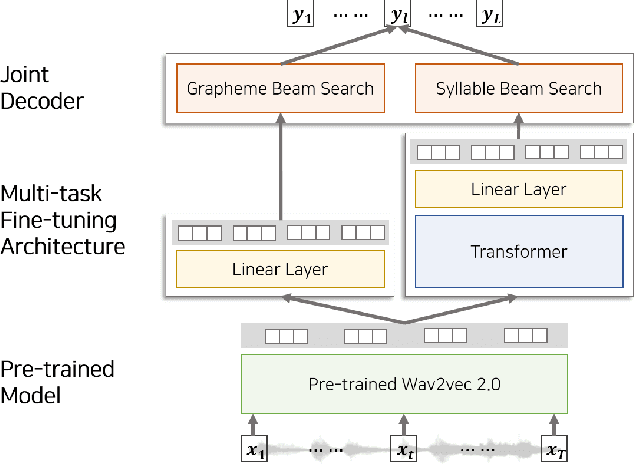
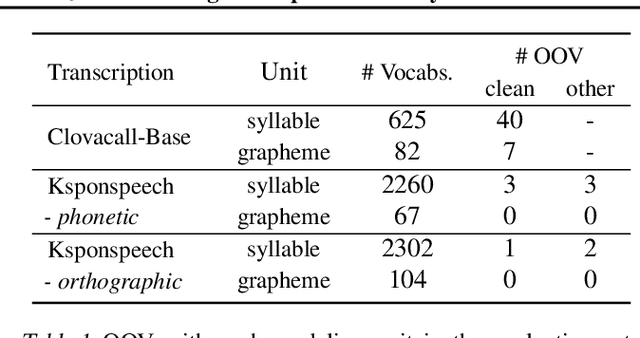
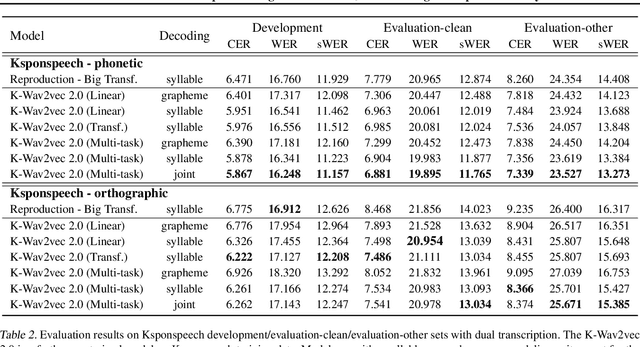
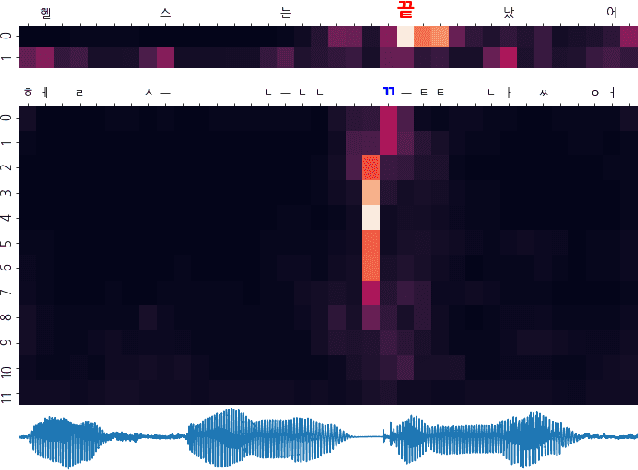
Wav2vec 2.0 is an end-to-end framework of self-supervised learning for speech representation that is successful in automatic speech recognition (ASR), but most of the work on the topic has been developed with a single language: English. Therefore, it is unclear whether the self-supervised framework is effective in recognizing other languages with different writing systems, such as Korean which uses the Hangul having a unique writing system. In this paper, we present K-Wav2Vec 2.0, which is a modified version of Wav2vec 2.0 designed for Korean automatic speech recognition by exploring and optimizing various factors of the original Wav2vec 2.0. In fine-tuning, we propose a multi-task hierarchical architecture to reflect the Korean writing structure. Moreover, a joint decoder is applied to alleviate the problem of words existing outside of the vocabulary. In pre-training, we attempted the cross-lingual transfer of the pre-trained model by further pre-training the English Wav2vec 2.0 on a Korean dataset, considering limited resources. Our experimental results demonstrate that the proposed method yields the best performance on both Korean ASR datasets: Ksponspeech (a large-scale Korean speech corpus) and Clovacall (a call-based dialog corpus). Further pre-training is also effective in language adaptation, leading to large improvements without additional data.
Complex-valued Spatial Autoencoders for Multichannel Speech Enhancement
Aug 06, 2021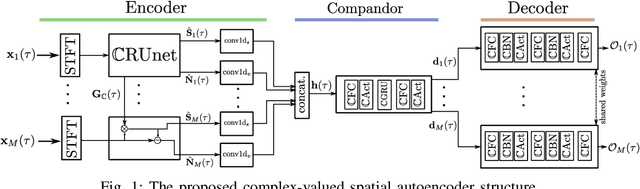
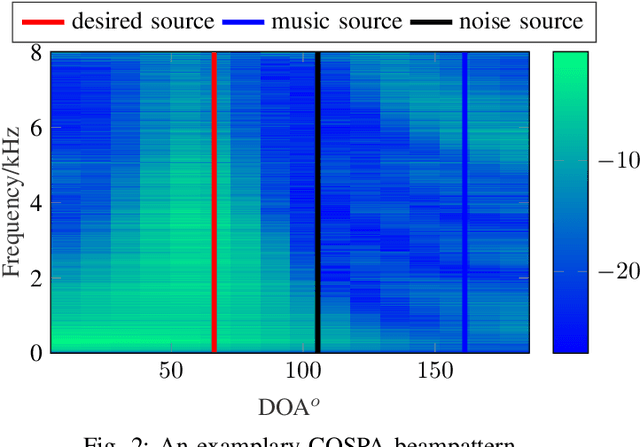
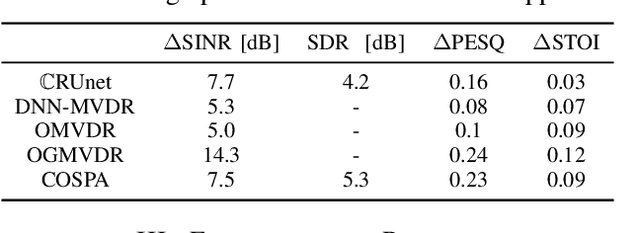
In this contribution, we present a novel online approach to multichannel speech enhancement. The proposed method estimates the enhanced signal through a filter-and-sum framework. More specifically, complex-valued masks are estimated by a deep complex-valued neural network, termed the complex-valued spatial autoencoder. The proposed network is capable of exploiting as well as manipulating both the phase and the amplitude of the microphone signals. As shown by the experimental results, the proposed approach is able to exploit both spatial and spectral characteristics of the desired source signal resulting in a physically plausible spatial selectivity and superior speech quality compared to other baseline methods.
TransPOS: Transformers for Consolidating Different POS Tagset Datasets
Sep 24, 2022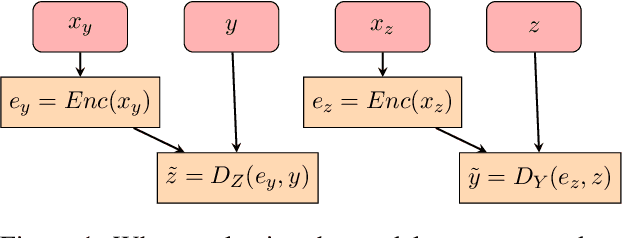
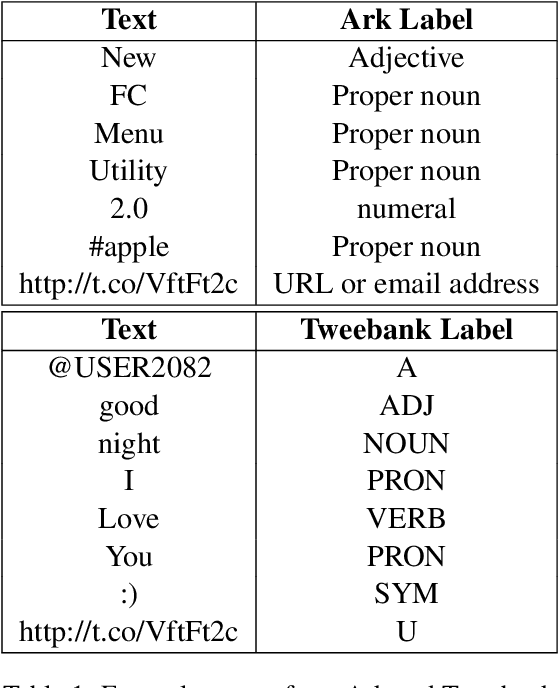
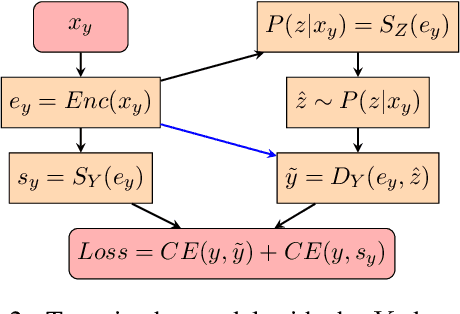
In hope of expanding training data, researchers often want to merge two or more datasets that are created using different labeling schemes. This paper considers two datasets that label part-of-speech (POS) tags under different tagging schemes and leverage the supervised labels of one dataset to help generate labels for the other dataset. This paper further discusses the theoretical difficulties of this approach and proposes a novel supervised architecture employing Transformers to tackle the problem of consolidating two completely disjoint datasets. The results diverge from initial expectations and discourage exploration into the use of disjoint labels to consolidate datasets with different labels.
Token-level Sequence Labeling for Spoken Language Understanding using Compositional End-to-End Models
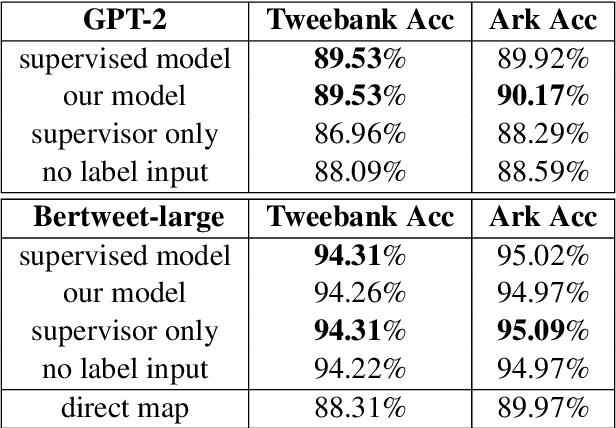
Oct 27, 2022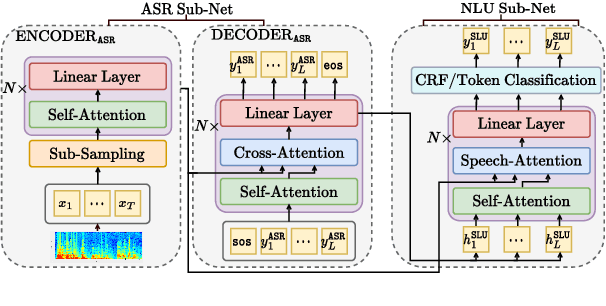
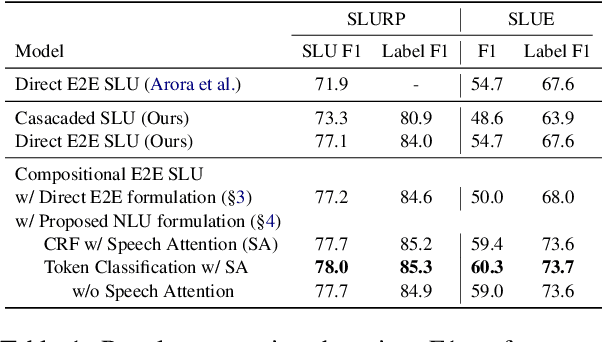
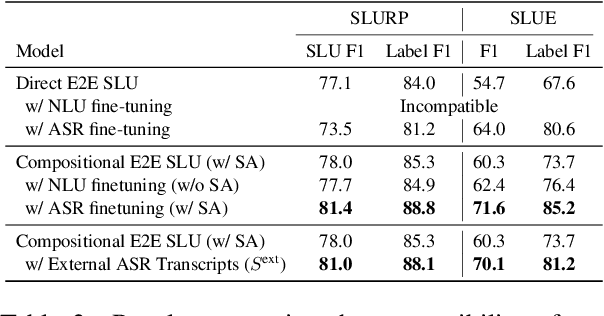

End-to-end spoken language understanding (SLU) systems are gaining popularity over cascaded approaches due to their simplicity and ability to avoid error propagation. However, these systems model sequence labeling as a sequence prediction task causing a divergence from its well-established token-level tagging formulation. We build compositional end-to-end SLU systems that explicitly separate the added complexity of recognizing spoken mentions in SLU from the NLU task of sequence labeling. By relying on intermediate decoders trained for ASR, our end-to-end systems transform the input modality from speech to token-level representations that can be used in the traditional sequence labeling framework. This composition of ASR and NLU formulations in our end-to-end SLU system offers direct compatibility with pre-trained ASR and NLU systems, allows performance monitoring of individual components and enables the use of globally normalized losses like CRF, making them attractive in practical scenarios. Our models outperform both cascaded and direct end-to-end models on a labeling task of named entity recognition across SLU benchmarks.
Expressive Text-to-Speech using Style Tag
Apr 01, 2021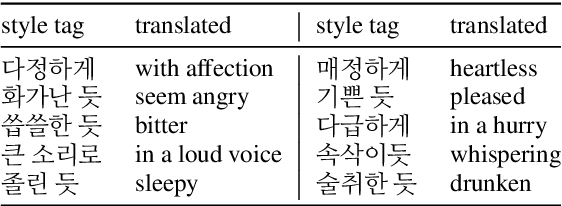
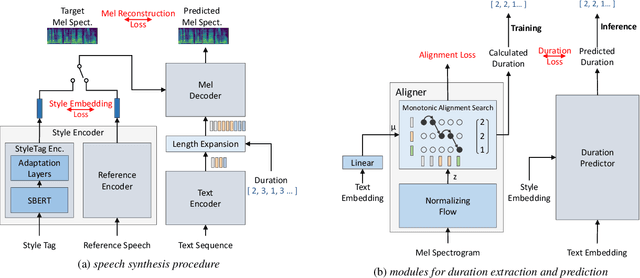
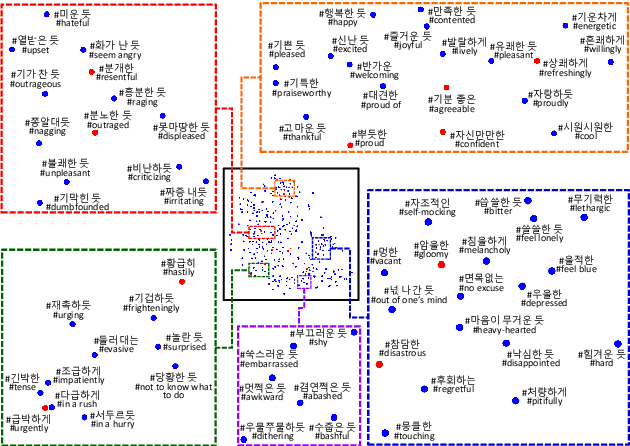
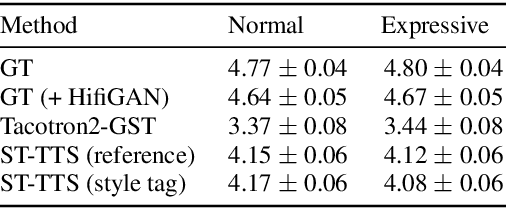
As recent text-to-speech (TTS) systems have been rapidly improved in speech quality and generation speed, many researchers now focus on a more challenging issue: expressive TTS. To control speaking styles, existing expressive TTS models use categorical style index or reference speech as style input. In this work, we propose StyleTagging-TTS (ST-TTS), a novel expressive TTS model that utilizes a style tag written in natural language. Using a style-tagged TTS dataset and a pre-trained language model, we modeled the relationship between linguistic embedding and speaking style domain, which enables our model to work even with style tags unseen during training. As style tag is written in natural language, it can control speaking style in a more intuitive, interpretable, and scalable way compared with style index or reference speech. In addition, in terms of model architecture, we propose an efficient non-autoregressive (NAR) TTS architecture with single-stage training. The experimental result shows that ST-TTS outperforms the existing expressive TTS model, Tacotron2-GST in speech quality and expressiveness.
Speech SIMCLR: Combining Contrastive and Reconstruction Objective for Self-supervised Speech Representation Learning
Oct 27, 2020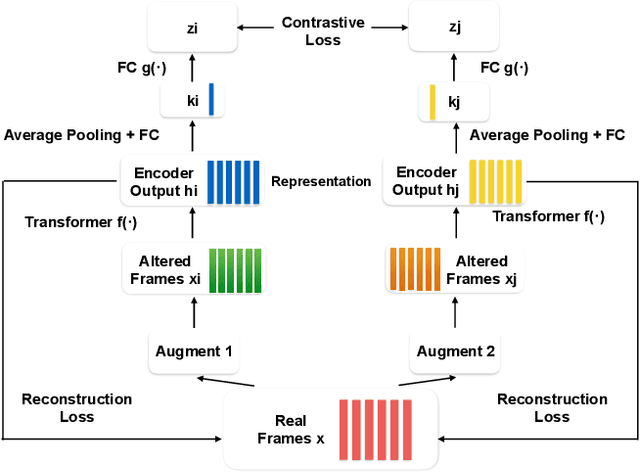

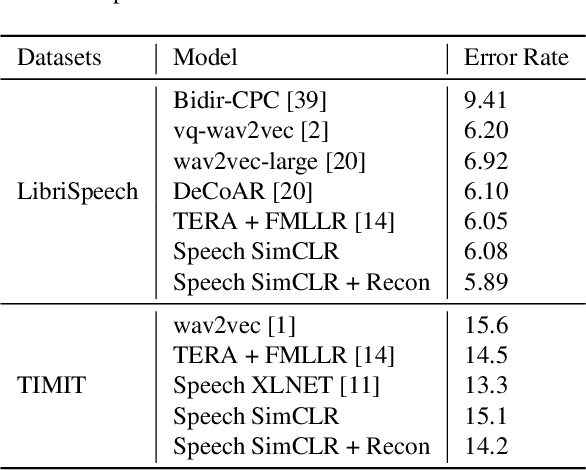

Self-supervised visual pretraining has shown significant progress recently. Among those methods, SimCLR greatly advanced the state of the art in self-supervised and semi-supervised learning on ImageNet. The input feature representations for speech and visual tasks are both continuous, so it is natural to consider applying similar objective on speech representation learning. In this paper, we propose Speech SimCLR, a new self-supervised objective for speech representation learning. During training, Speech SimCLR applies augmentation on raw speech and its spectrogram. Its objective is the combination of contrastive loss that maximizes agreement between differently augmented samples in the latent space and reconstruction loss of input representation. The proposed method achieved competitive results on speech emotion recognition and speech recognition. When used as feature extractor, our best model achieved 5.89% word error rate on LibriSpeech test-clean set using LibriSpeech 960 hours as pretraining data and LibriSpeech train-clean-100 set as fine-tuning data, which is the lowest error rate obtained in this setup to the best of our knowledge.