 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
DNSMOS P.835: A Non-Intrusive Perceptual Objective Speech Quality Metric to Evaluate Noise Suppressors
Oct 08, 2021
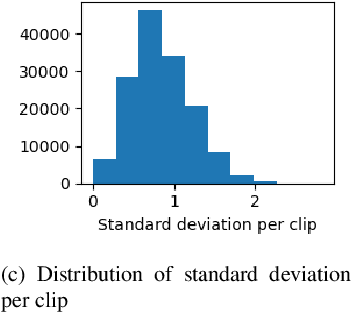
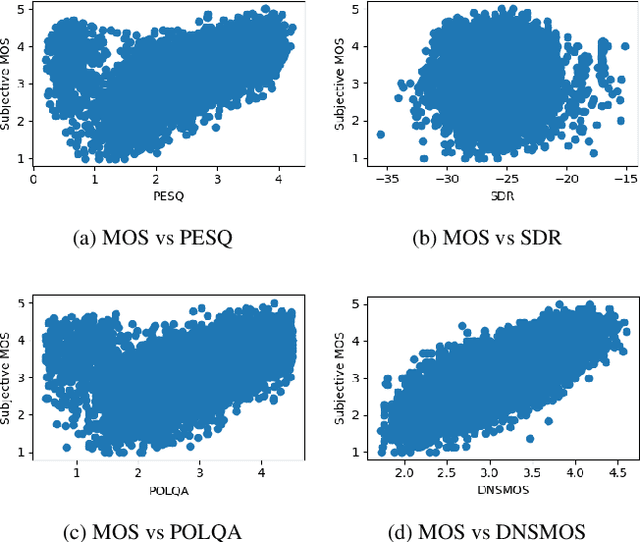
Human subjective evaluation is the gold standard to evaluate speech quality optimized for human perception. Perceptual objective metrics serve as a proxy for subjective scores. We have recently developed a non-intrusive speech quality metric called Deep Noise Suppression Mean Opinion Score (DNSMOS) using the scores from ITU-T Rec. P.808 subjective evaluation. The P.808 scores reflect the overall quality of the audio clip. ITU-T Rec. P.835 subjective evaluation framework gives the standalone quality scores of speech and background noise in addition to the overall quality. In this work, we train an objective metric based on P.835 human ratings that outputs 3 scores: i) speech quality (SIG), ii) background noise quality (BAK), and iii) the overall quality (OVRL) of the audio. The developed metric is highly correlated with human ratings, with a Pearson's Correlation Coefficient (PCC)=0.94 for SIG and PCC=0.98 for BAK and OVRL. This is the first non-intrusive P.835 predictor we are aware of. DNSMOS P.835 is made publicly available as an Azure service.
Dictionary-Based Fusion of Contact and Acoustic Microphones for Wind Noise Reduction
May 18, 2022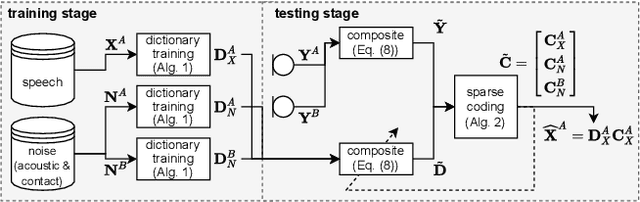
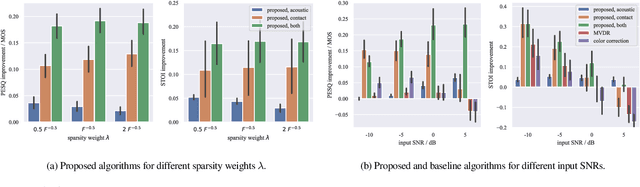
In mobile speech communication applications, wind noise can lead to a severe reduction of speech quality and intelligibility. Since the performance of speech enhancement algorithms using acoustic microphones tends to substantially degrade in extremely challenging scenarios, auxiliary sensors such as contact microphones can be used. Although contact microphones offer a much lower recorded wind noise level, they come at the cost of speech distortion and additional noise components. Aiming at exploiting the advantages of acoustic and contact microphones for wind noise reduction, in this paper we propose to extend conventional single-microphone dictionary-based speech enhancement approaches by simultaneously modeling the acoustic and contact microphone signals. We propose to train a single speech dictionary and two noise dictionaries and use a relative transfer function to model the relationship between the speech components at the microphones. Simulation results show that the proposed approach yields improvements in both speech quality and intelligibility compared to several baseline approaches, most notably approaches using only the contact microphones or only the acoustic microphone.
SpeechNet: A Universal Modularized Model for Speech Processing Tasks
May 07, 2021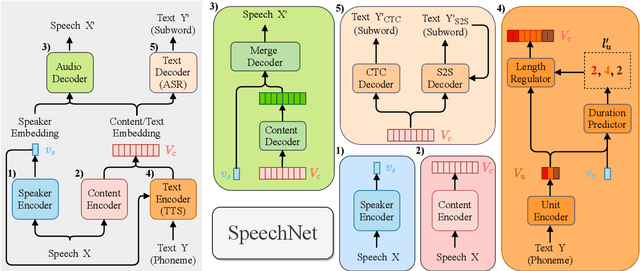
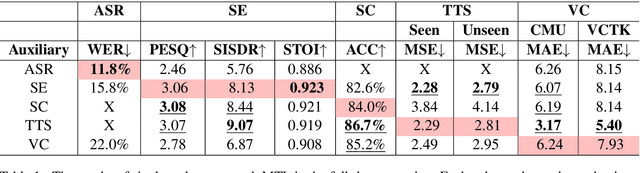
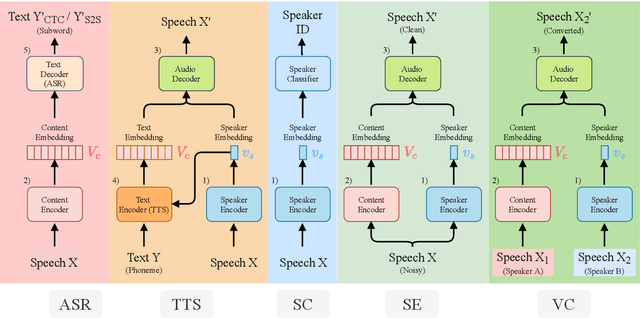
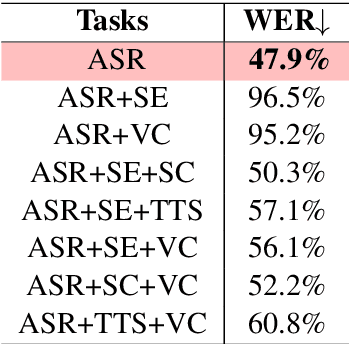
There is a wide variety of speech processing tasks. For different tasks, model networks are usually designed and tuned separately. This paper proposes a universal modularized model, SpeechNet, which contains the five basic modules for speech processing. The concatenation of modules solves a variety of speech processing tasks. We select five important and common tasks in the experiments that use all of these five modules altogether. Specifically, in each trial, we jointly train a subset of all speech tasks under multi-task setting, with all modules shared. Then we can observe whether one task can benefit another during training. SpeechNet is modularized and flexible for incorporating more modules, tasks, or training approaches in the future. We will release the code and experimental settings to facilitate the research of modularized universal models or multi-task learning of speech processing tasks.
Neural Network-augmented Kalman Filtering for Robust Online Speech Dereverberation in Noisy Reverberant Environments
Apr 06, 2022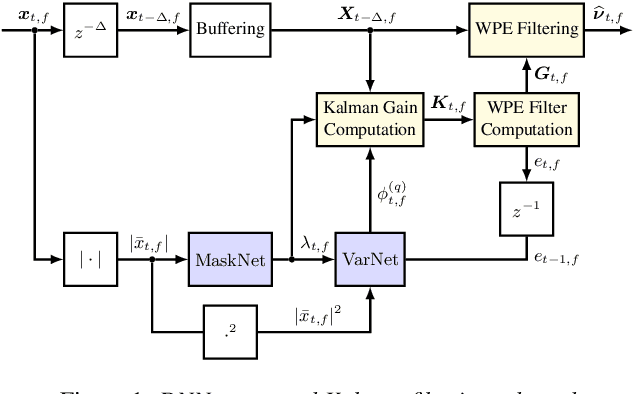
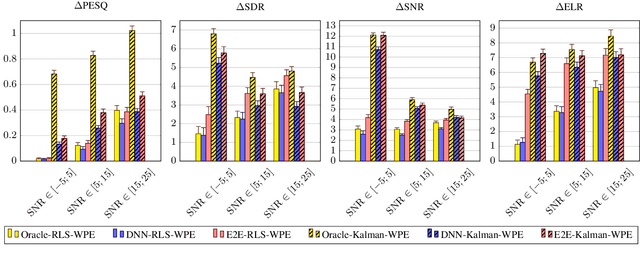
In this paper, a neural network-augmented algorithm for noise-robust online dereverberation with a Kalman filtering variant of the weighted prediction error (WPE) method is proposed. The filter stochastic variations are predicted by a deep neural network (DNN) trained end-to-end using the filter residual error and signal characteristics. The presented framework allows for robust dereverberation on a single-channel noisy reverberant dataset similar to WHAMR!. The Kalman filtering WPE introduces distortions in the enhanced signal when predicting the filter variations from the residual error only, if the target speech power spectral density is not perfectly known and the observation is noisy. The proposed approach avoids these distortions by correcting the filter variations estimation in a data-driven way, increasing the robustness of the method to noisy scenarios. Furthermore, it yields a strong dereverberation and denoising performance compared to a DNN-supported recursive least squares variant of WPE, especially for highly noisy inputs.
SoundChoice: Grapheme-to-Phoneme Models with Semantic Disambiguation
Jul 27, 2022
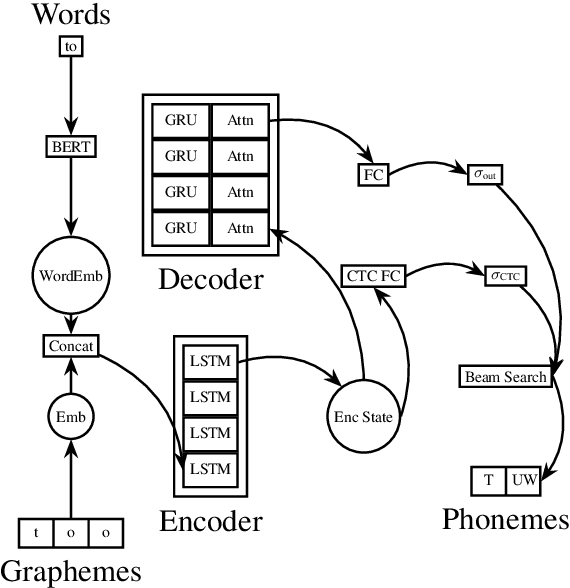

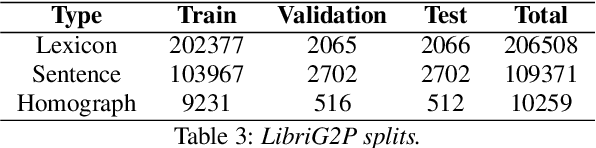
End-to-end speech synthesis models directly convert the input characters into an audio representation (e.g., spectrograms). Despite their impressive performance, such models have difficulty disambiguating the pronunciations of identically spelled words. To mitigate this issue, a separate Grapheme-to-Phoneme (G2P) model can be employed to convert the characters into phonemes before synthesizing the audio. This paper proposes SoundChoice, a novel G2P architecture that processes entire sentences rather than operating at the word level. The proposed architecture takes advantage of a weighted homograph loss (that improves disambiguation), exploits curriculum learning (that gradually switches from word-level to sentence-level G2P), and integrates word embeddings from BERT (for further performance improvement). Moreover, the model inherits the best practices in speech recognition, including multi-task learning with Connectionist Temporal Classification (CTC) and beam search with an embedded language model. As a result, SoundChoice achieves a Phoneme Error Rate (PER) of 2.65% on whole-sentence transcription using data from LibriSpeech and Wikipedia. Index Terms grapheme-to-phoneme, speech synthesis, text-tospeech, phonetics, pronunciation, disambiguation.
Should We Always Separate?: Switching Between Enhanced and Observed Signals for Overlapping Speech Recognition
Jun 02, 2021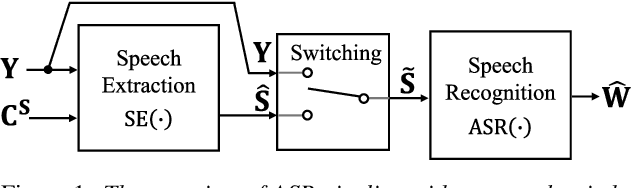
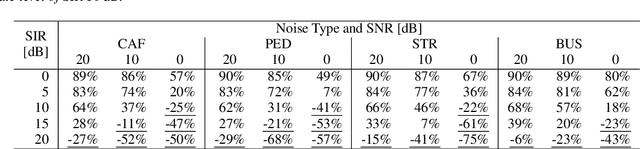
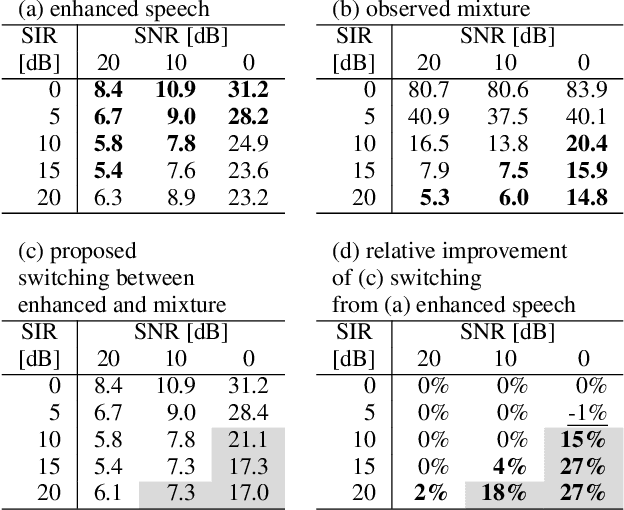
Although recent advances in deep learning technology improved automatic speech recognition (ASR), it remains difficult to recognize speech when it overlaps other people's voices. Speech separation or extraction is often used as a front-end to ASR to handle such overlapping speech. However, deep neural network-based speech enhancement can generate `processing artifacts' as a side effect of the enhancement, which degrades ASR performance. For example, it is well known that single-channel noise reduction for non-speech noise (non-overlapping speech) often does not improve ASR. Likewise, the processing artifacts may also be detrimental to ASR in some conditions when processing overlapping speech with a separation/extraction method, although it is usually believed that separation/extraction improves ASR. In order to answer the question `Do we always have to separate/extract speech from mixtures?', we analyze ASR performance on observed and enhanced speech at various noise and interference conditions, and show that speech enhancement degrades ASR under some conditions even for overlapping speech. Based on these findings, we propose a simple switching algorithm between observed and enhanced speech based on the estimated signal-to-interference ratio and signal-to-noise ratio. We demonstrated experimentally that such a simple switching mechanism can improve recognition performance when processing artifacts are detrimental to ASR.
Investigations on Speech Recognition Systems for Low-Resource Dialectal Arabic-English Code-Switching Speech
Aug 29, 2021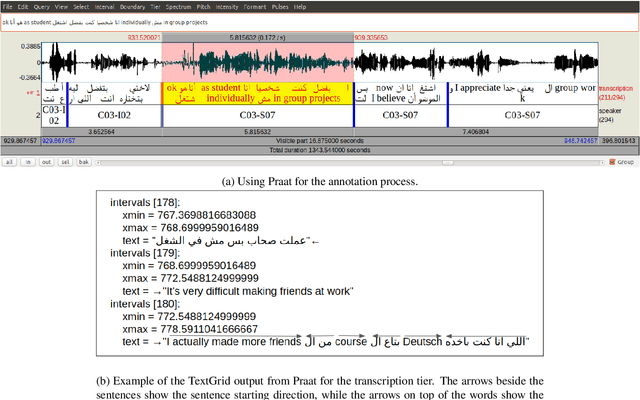
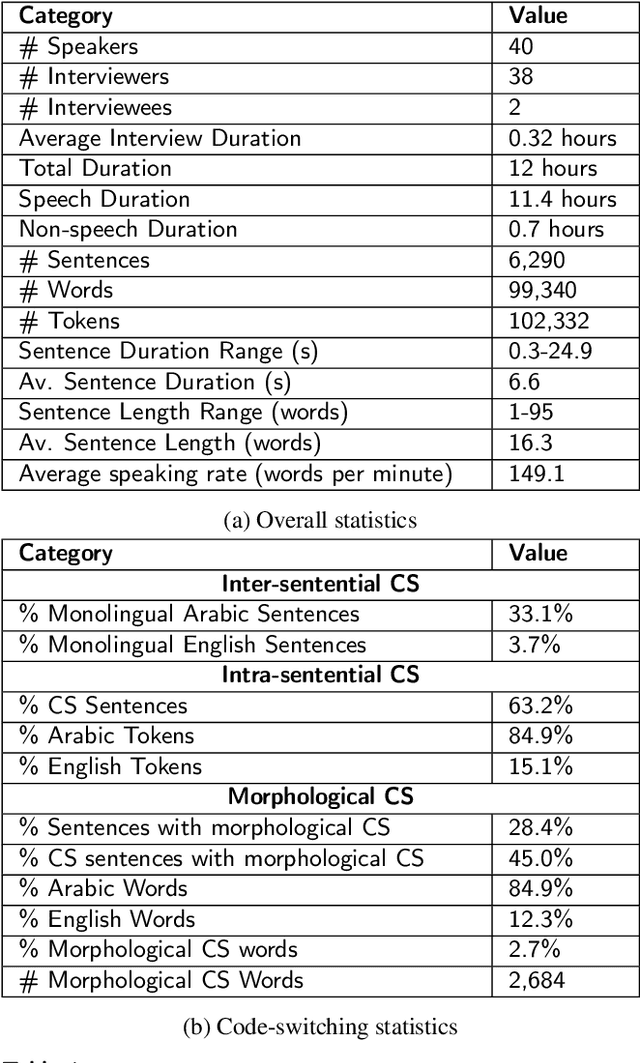
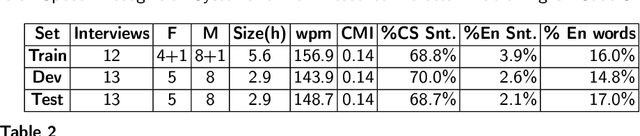
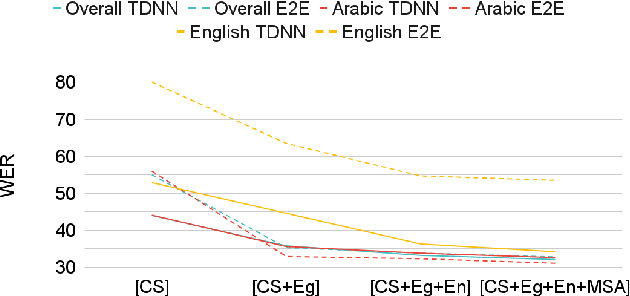
Code-switching (CS), defined as the mixing of languages in conversations, has become a worldwide phenomenon. The prevalence of CS has been recently met with a growing demand and interest to build CS ASR systems. In this paper, we present our work on code-switched Egyptian Arabic-English automatic speech recognition (ASR). We first contribute in filling the huge gap in resources by collecting, analyzing and publishing our spontaneous CS Egyptian Arabic-English speech corpus. We build our ASR systems using DNN-based hybrid and Transformer-based end-to-end models. In this paper, we present a thorough comparison between both approaches under the setting of a low-resource, orthographically unstandardized, and morphologically rich language pair. We show that while both systems give comparable overall recognition results, each system provides complementary sets of strength points. We show that recognition can be improved by combining the outputs of both systems. We propose several effective system combination approaches, where hypotheses of both systems are merged on sentence- and word-levels. Our approaches result in overall WER relative improvement of 4.7%, over a baseline performance of 32.1% WER. In the case of intra-sentential CS sentences, we achieve WER relative improvement of 4.8%. Our best performing system achieves 30.6% WER on ArzEn test set.
Utterance-level neural confidence measure for end-to-end children speech recognition
Sep 16, 2021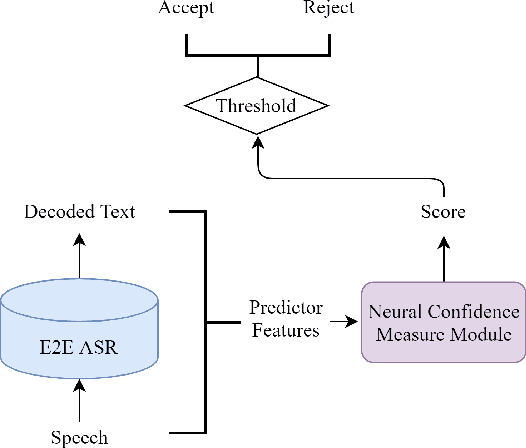
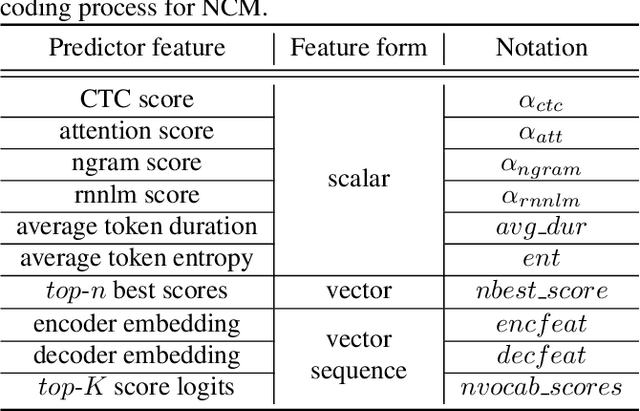
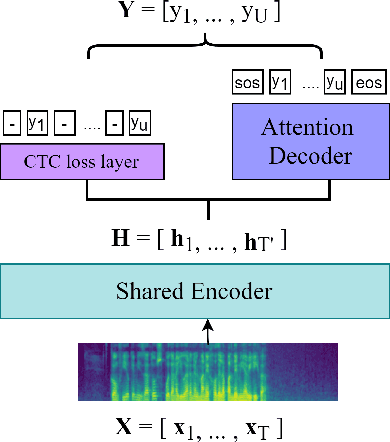
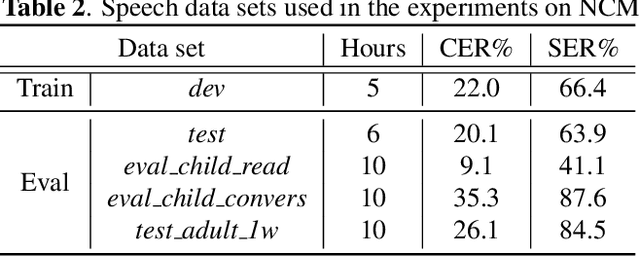
Confidence measure is a performance index of particular importance for automatic speech recognition (ASR) systems deployed in real-world scenarios. In the present study, utterance-level neural confidence measure (NCM) in end-to-end automatic speech recognition (E2E ASR) is investigated. The E2E system adopts the joint CTC-attention Transformer architecture. The prediction of NCM is formulated as a task of binary classification, i.e., accept/reject the input utterance, based on a set of predictor features acquired during the ASR decoding process. The investigation is focused on evaluating and comparing the efficacies of predictor features that are derived from different internal and external modules of the E2E system. Experiments are carried out on children speech, for which state-of-the-art ASR systems show less than satisfactory performance and robust confidence measure is particularly useful. It is noted that predictor features related to acoustic information of speech play a more important role in estimating confidence measure than those related to linguistic information. N-best score features show significantly better performance than single-best ones. It has also been shown that the metrics of EER and AUC are not appropriate to evaluate the NCM of a mismatched ASR with significant performance gap.
Hierarchical Diffusion Models for Singing Voice Neural Vocoder
Oct 18, 2022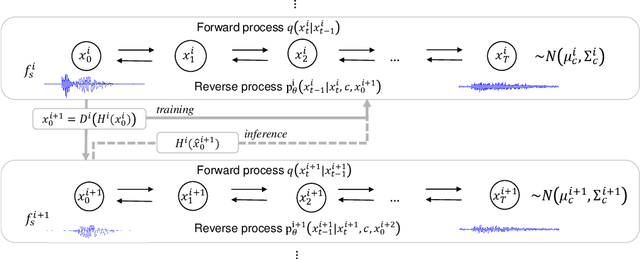
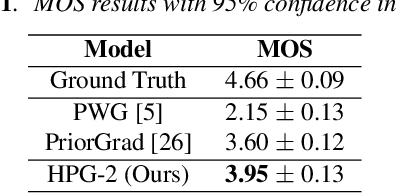
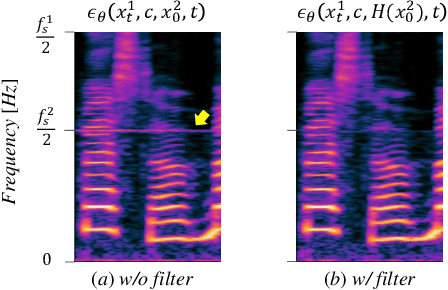
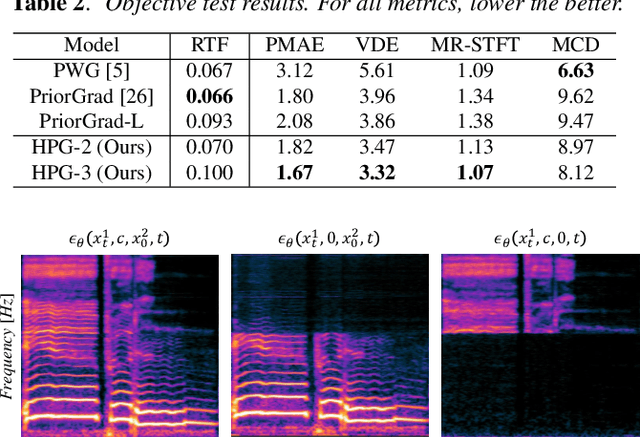
Recent progress in deep generative models has improved the quality of neural vocoders in speech domain. However, generating a high-quality singing voice remains challenging due to a wider variety of musical expressions in pitch, loudness, and pronunciations. In this work, we propose a hierarchical diffusion model for singing voice neural vocoders. The proposed method consists of multiple diffusion models operating in different sampling rates; the model at the lowest sampling rate focuses on generating accurate low-frequency components such as pitch, and other models progressively generate the waveform at higher sampling rates on the basis of the data at the lower sampling rate and acoustic features. Experimental results show that the proposed method produces high-quality singing voices for multiple singers, outperforming state-of-the-art neural vocoders with a similar range of computational costs.
Dual-Decoder Transformer For end-to-end Mandarin Chinese Speech Recognition with Pinyin and Character
Jan 26, 2022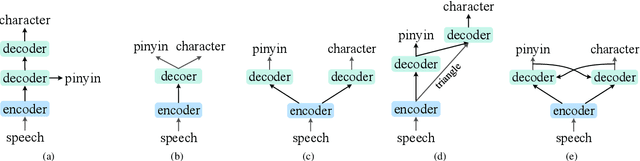
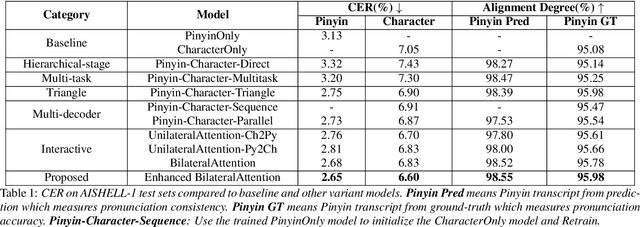
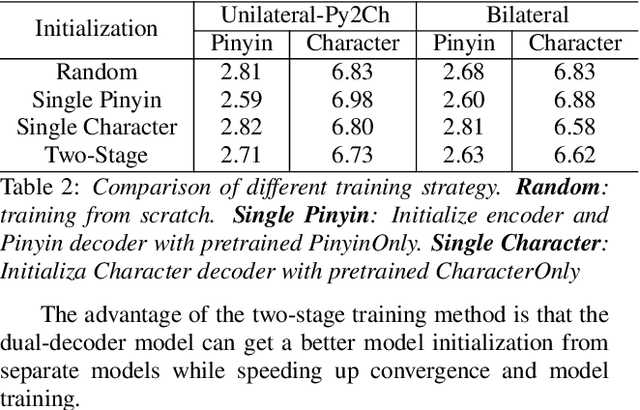
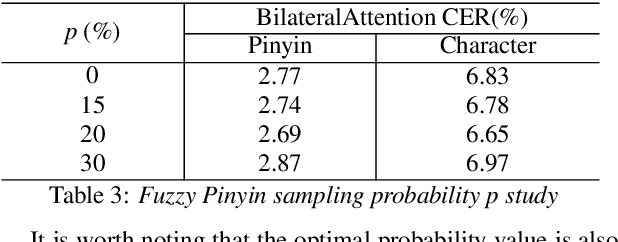
End-to-end automatic speech recognition (ASR) has achieved promising results. However, most existing end-to-end ASR methods neglect the use of specific language characteristics. For Mandarin Chinese ASR tasks, pinyin and character as writing and spelling systems respectively are mutual promotion in the Mandarin Chinese language. Based on the above intuition, we investigate types of related models that are suitable but not for joint pinyin-character ASR and propose a novel Mandarin Chinese ASR model with dual-decoder Transformer according to the characteristics of the pinyin transcripts and character transcripts. Specifically, the joint pinyin-character layer-wise linear interactive (LWLI) module and phonetic posteriorgrams adapter (PPGA) are proposed to achieve inter-layer multi-level interaction by adaptively fusing pinyin and character information. Furthermore, a two-stage training strategy is proposed to make training more stable and faster convergence. The results on the test sets of AISHELL-1 dataset show that the proposed Speech-Pinyin-Character-Interaction (SPCI) model without a language model achieves 9.85% character error rate (CER) on the test set, which is 17.71% relative reduction compared to baseline models based on Transformer.