 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
RescoreBERT: Discriminative Speech Recognition Rescoring with BERT
Feb 07, 2022
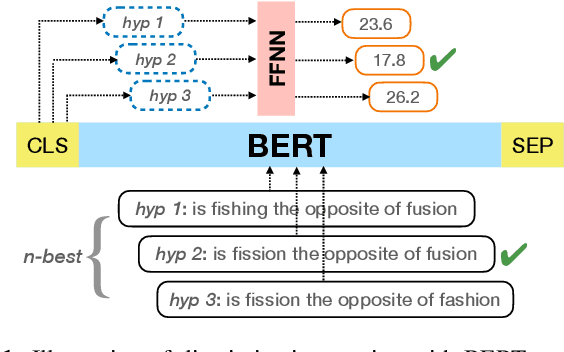
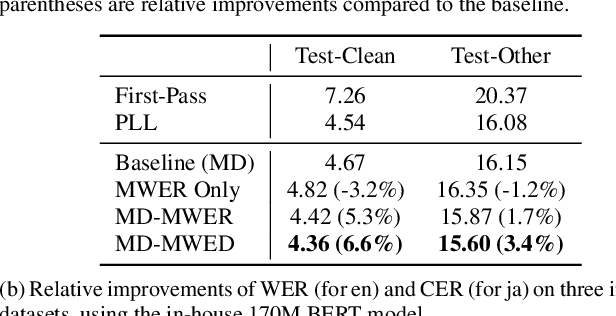

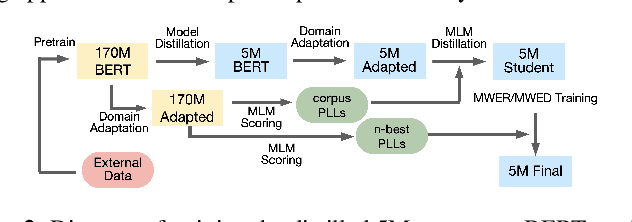
Second-pass rescoring is an important component in automatic speech recognition (ASR) systems that is used to improve the outputs from a first-pass decoder by implementing a lattice rescoring or $n$-best re-ranking. While pretraining with a masked language model (MLM) objective has received great success in various natural language understanding (NLU) tasks, it has not gained traction as a rescoring model for ASR. Specifically, training a bidirectional model like BERT on a discriminative objective such as minimum WER (MWER) has not been explored. Here we show how to train a BERT-based rescoring model with MWER loss, to incorporate the improvements of a discriminative loss into fine-tuning of deep bidirectional pretrained models for ASR. Specifically, we propose a fusion strategy that incorporates the MLM into the discriminative training process to effectively distill knowledge from a pretrained model. We further propose an alternative discriminative loss. We name this approach RescoreBERT. On the LibriSpeech corpus, it reduces WER by 6.6%/3.4% relative on clean/other test sets over a BERT baseline without discriminative objective. We also evaluate our method on an internal dataset from a conversational agent and find that it reduces both latency and WER (by 3 to 8% relative) over an LSTM rescoring model.
Neural Network-augmented Kalman Filtering for Robust Online Speech Dereverberation in Noisy Reverberant Environments
Apr 06, 2022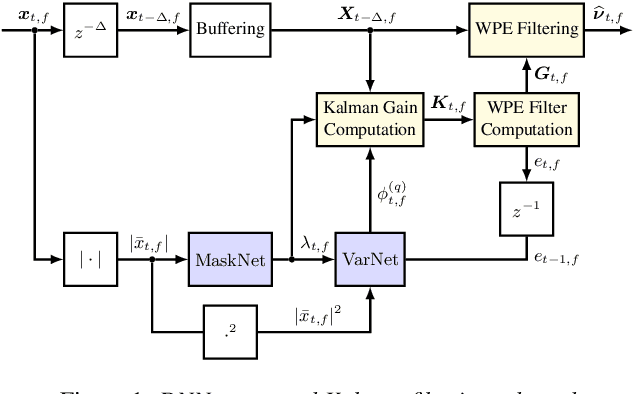
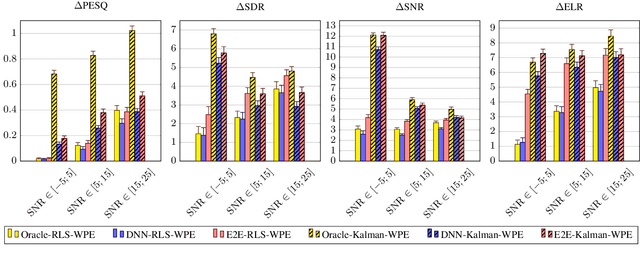
In this paper, a neural network-augmented algorithm for noise-robust online dereverberation with a Kalman filtering variant of the weighted prediction error (WPE) method is proposed. The filter stochastic variations are predicted by a deep neural network (DNN) trained end-to-end using the filter residual error and signal characteristics. The presented framework allows for robust dereverberation on a single-channel noisy reverberant dataset similar to WHAMR!. The Kalman filtering WPE introduces distortions in the enhanced signal when predicting the filter variations from the residual error only, if the target speech power spectral density is not perfectly known and the observation is noisy. The proposed approach avoids these distortions by correcting the filter variations estimation in a data-driven way, increasing the robustness of the method to noisy scenarios. Furthermore, it yields a strong dereverberation and denoising performance compared to a DNN-supported recursive least squares variant of WPE, especially for highly noisy inputs.
Quantifying Bias in Automatic Speech Recognition
Apr 01, 2021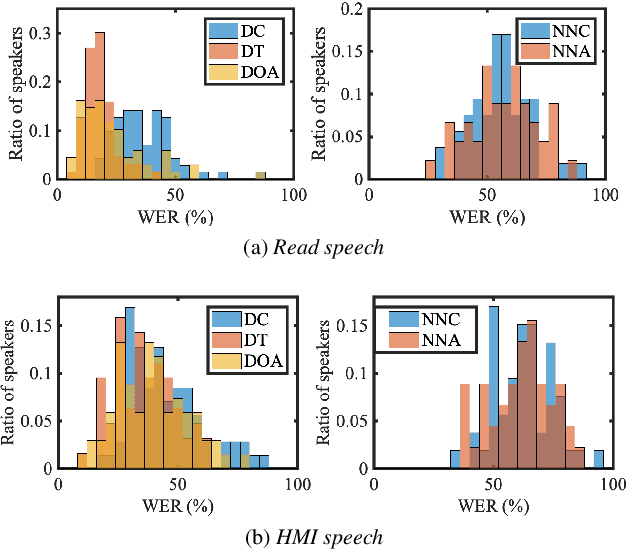
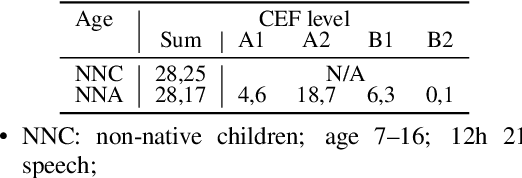
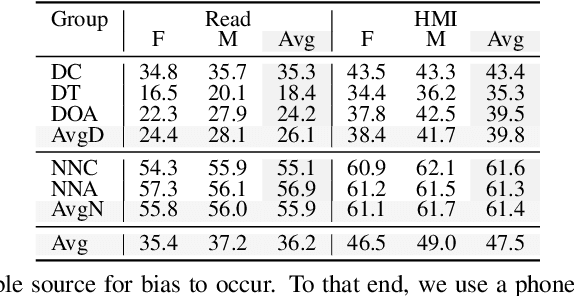
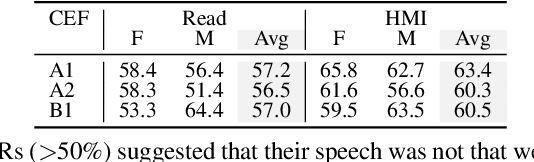
Automatic speech recognition (ASR) systems promise to deliver objective interpretation of human speech. Practice and recent evidence suggests that the state-of-the-art (SotA) ASRs struggle with the large variation in speech due to e.g., gender, age, speech impairment, race, and accents. Many factors can cause the bias of an ASR system. Our overarching goal is to uncover bias in ASR systems to work towards proactive bias mitigation in ASR. This paper is a first step towards this goal and systematically quantifies the bias of a Dutch SotA ASR system against gender, age, regional accents and non-native accents. Word error rates are compared, and an in-depth phoneme-level error analysis is conducted to understand where bias is occurring. We primarily focus on bias due to articulation differences in the dataset. Based on our findings, we suggest bias mitigation strategies for ASR development.
Token-level Sequence Labeling for Spoken Language Understanding using Compositional End-to-End Models
Oct 27, 2022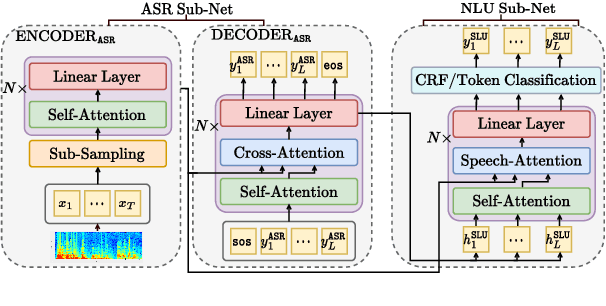
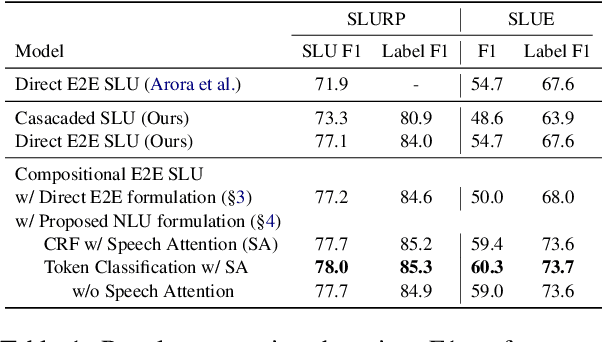
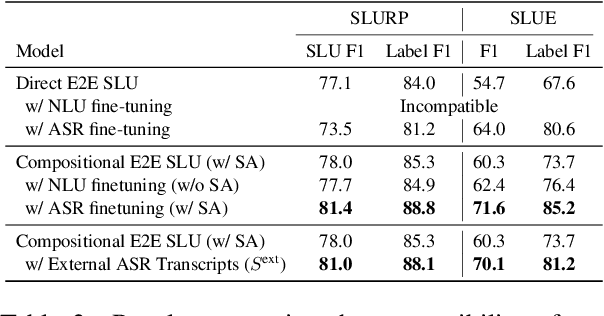

End-to-end spoken language understanding (SLU) systems are gaining popularity over cascaded approaches due to their simplicity and ability to avoid error propagation. However, these systems model sequence labeling as a sequence prediction task causing a divergence from its well-established token-level tagging formulation. We build compositional end-to-end SLU systems that explicitly separate the added complexity of recognizing spoken mentions in SLU from the NLU task of sequence labeling. By relying on intermediate decoders trained for ASR, our end-to-end systems transform the input modality from speech to token-level representations that can be used in the traditional sequence labeling framework. This composition of ASR and NLU formulations in our end-to-end SLU system offers direct compatibility with pre-trained ASR and NLU systems, allows performance monitoring of individual components and enables the use of globally normalized losses like CRF, making them attractive in practical scenarios. Our models outperform both cascaded and direct end-to-end models on a labeling task of named entity recognition across SLU benchmarks.
Searching for Discriminative Words in Multidimensional Continuous Feature Space
Nov 26, 2022
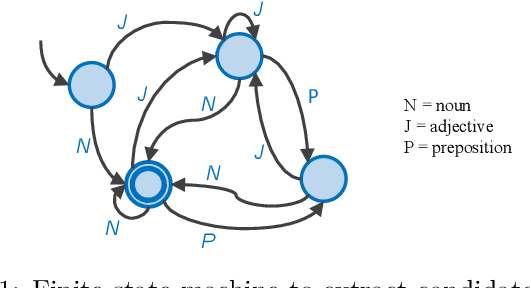
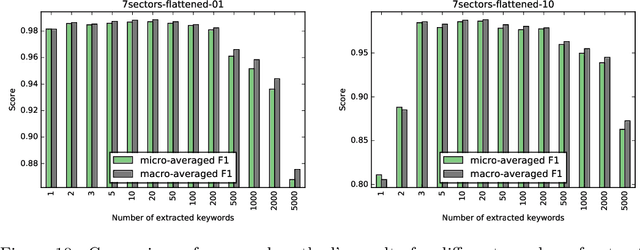
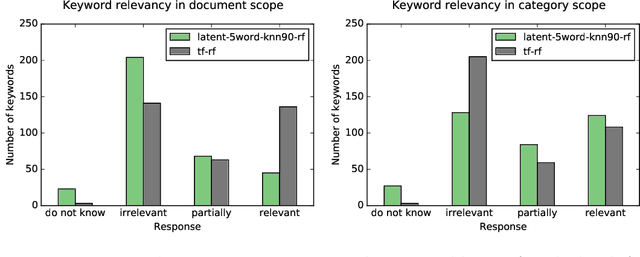
Word feature vectors have been proven to improve many NLP tasks. With recent advances in unsupervised learning of these feature vectors, it became possible to train it with much more data, which also resulted in better quality of learned features. Since it learns joint probability of latent features of words, it has the advantage that we can train it without any prior knowledge about the goal task we want to solve. We aim to evaluate the universal applicability property of feature vectors, which has been already proven to hold for many standard NLP tasks like part-of-speech tagging or syntactic parsing. In our case, we want to understand the topical focus of text documents and design an efficient representation suitable for discriminating different topics. The discriminativeness can be evaluated adequately on text categorisation task. We propose a novel method to extract discriminative keywords from documents. We utilise word feature vectors to understand the relations between words better and also understand the latent topics which are discussed in the text and not mentioned directly but inferred logically. We also present a simple way to calculate document feature vectors out of extracted discriminative words. We evaluate our method on the four most popular datasets for text categorisation. We show how different discriminative metrics influence the overall results. We demonstrate the effectiveness of our approach by achieving state-of-the-art results on text categorisation task using just a small number of extracted keywords. We prove that word feature vectors can substantially improve the topical inference of documents' meaning. We conclude that distributed representation of words can be used to build higher levels of abstraction as we demonstrate and build feature vectors of documents.
Noisy-target Training: A Training Strategy for DNN-based Speech Enhancement without Clean Speech
Jan 21, 2021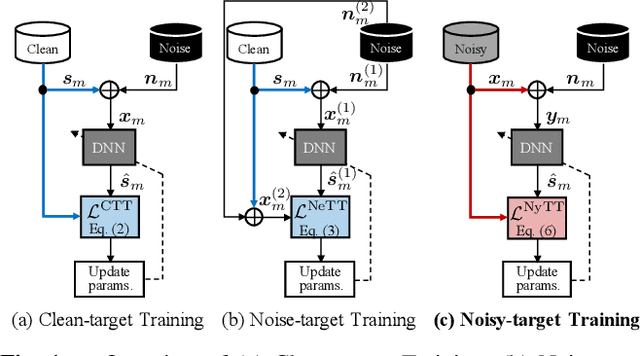

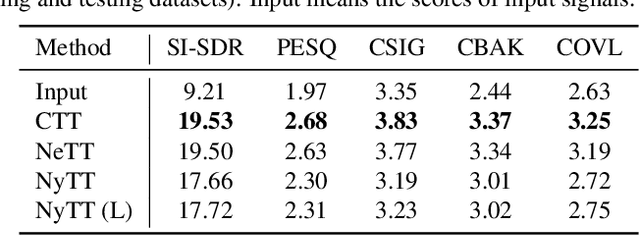
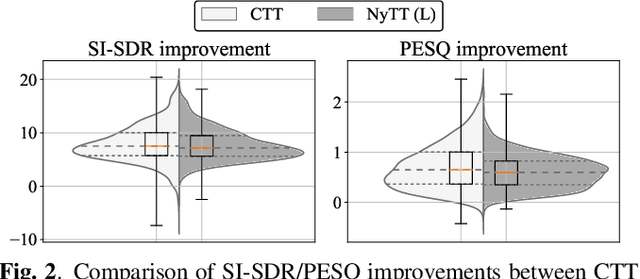
Deep neural network (DNN)-based speech enhancement ordinarily requires clean speech signals as the training target. However, collecting clean signals is very costly because they must be recorded in a studio. This requirement currently restricts the amount of training data for speech enhancement less than 1/1000 of that of speech recognition which does not need clean signals. Increasing the amount of training data is important for improving the performance, and hence the requirement of clean signals should be relaxed. In this paper, we propose a training strategy that does not require clean signals. The proposed method only utilizes noisy signals for training, which enables us to use a variety of speech signals in the wild. Our experimental results showed that the proposed method can achieve the performance similar to that of a DNN trained with clean signals.
AdaSpeech 2: Adaptive Text to Speech with Untranscribed Data
Apr 20, 2021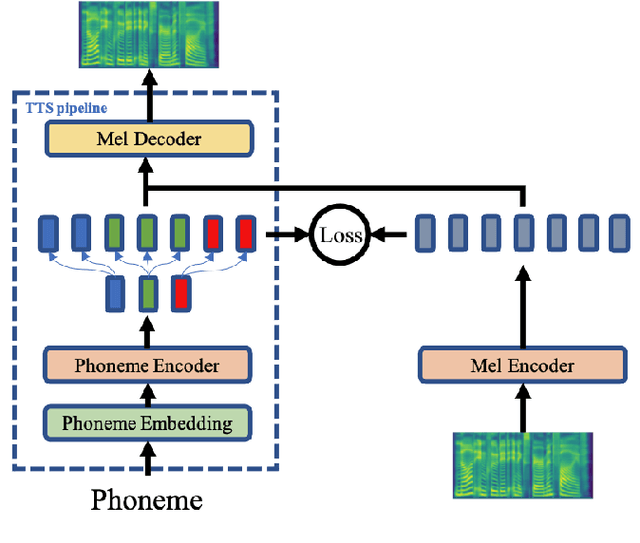
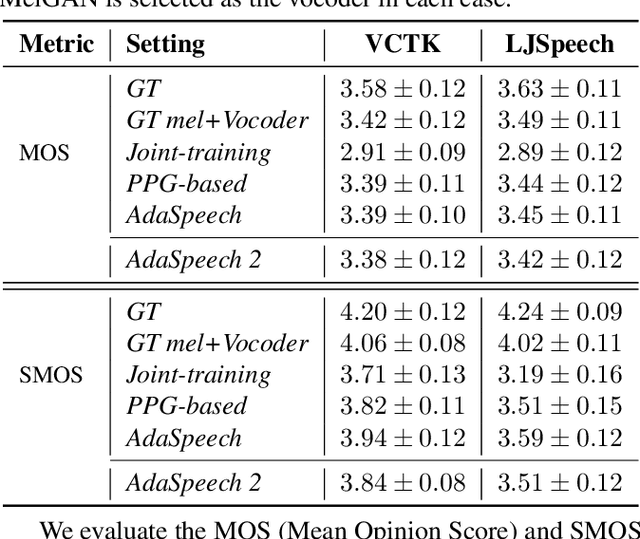
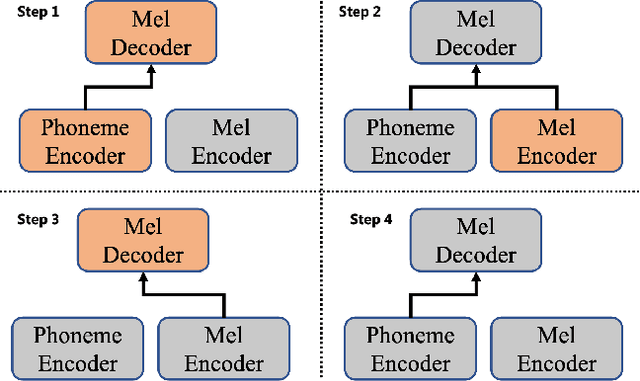

Text to speech (TTS) is widely used to synthesize personal voice for a target speaker, where a well-trained source TTS model is fine-tuned with few paired adaptation data (speech and its transcripts) on this target speaker. However, in many scenarios, only untranscribed speech data is available for adaptation, which brings challenges to the previous TTS adaptation pipelines (e.g., AdaSpeech). In this paper, we develop AdaSpeech 2, an adaptive TTS system that only leverages untranscribed speech data for adaptation. Specifically, we introduce a mel-spectrogram encoder to a well-trained TTS model to conduct speech reconstruction, and at the same time constrain the output sequence of the mel-spectrogram encoder to be close to that of the original phoneme encoder. In adaptation, we use untranscribed speech data for speech reconstruction and only fine-tune the TTS decoder. AdaSpeech 2 has two advantages: 1) Pluggable: our system can be easily applied to existing trained TTS models without re-training. 2) Effective: our system achieves on-par voice quality with the transcribed TTS adaptation (e.g., AdaSpeech) with the same amount of untranscribed data, and achieves better voice quality than previous untranscribed adaptation methods. Synthesized speech samples can be found at https://speechresearch.github.io/adaspeech2/.
Exploring Wav2vec 2.0 fine-tuning for improved speech emotion recognition
Oct 28, 2021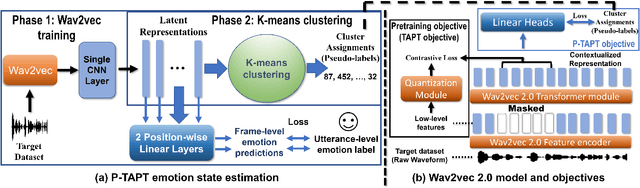
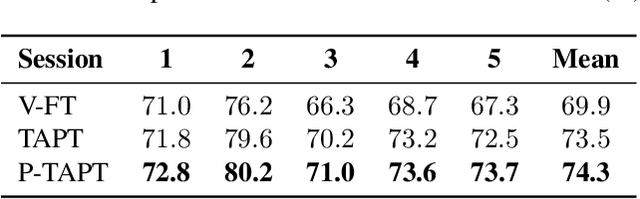
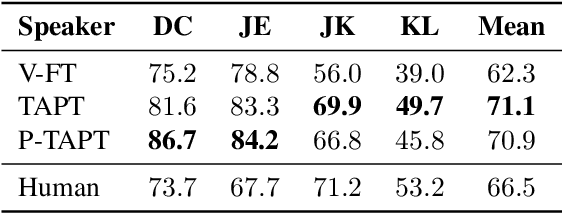

While wav2vec 2.0 has been proposed for speech recognition (ASR), it can also be used for speech emotion recognition (SER); its performance can be significantly improved using different fine-tuning strategies. Two baseline methods, vanilla fine-tuning (V-FT) and task adaptive pretraining (TAPT) are first presented. We show that V-FT is able to outperform state-of-the-art models on the IEMOCAP dataset. TAPT, an existing NLP fine-tuning strategy, further improves the performance on SER. We also introduce a novel fine-tuning method termed P-TAPT, which modifies the TAPT objective to learn contextualized emotion representations. Experiments show that P-TAPT performs better than TAPT especially under low-resource settings. Compared to prior works in this literature, our top-line system achieved a 7.4% absolute improvement on unweighted accuracy (UA) over the state-of-the-art performance on IEMOCAP. Our code is publicly available.
EML Online Speech Activity Detection for the Fearless Steps Challenge Phase-III
Jun 21, 2021

Speech Activity Detection (SAD), locating speech segments within an audio recording, is a main part of most speech technology applications. Robust SAD is usually more difficult in noisy conditions with varying signal-to-noise ratios (SNR). The Fearless Steps challenge has recently provided such data from the NASA Apollo-11 mission for different speech processing tasks including SAD. Most audio recordings are degraded by different kinds and levels of noise varying within and between channels. This paper describes the EML online algorithm for the most recent phase of this challenge. The proposed algorithm can be trained both in a supervised and unsupervised manner and assigns speech and non-speech labels at runtime approximately every 0.1 sec. The experimental results show a competitive accuracy on both development and evaluation datasets with a real-time factor of about 0.002 using a single CPU machine.
TransPOS: Transformers for Consolidating Different POS Tagset Datasets
Sep 24, 2022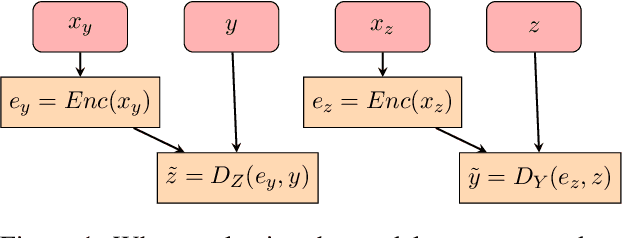
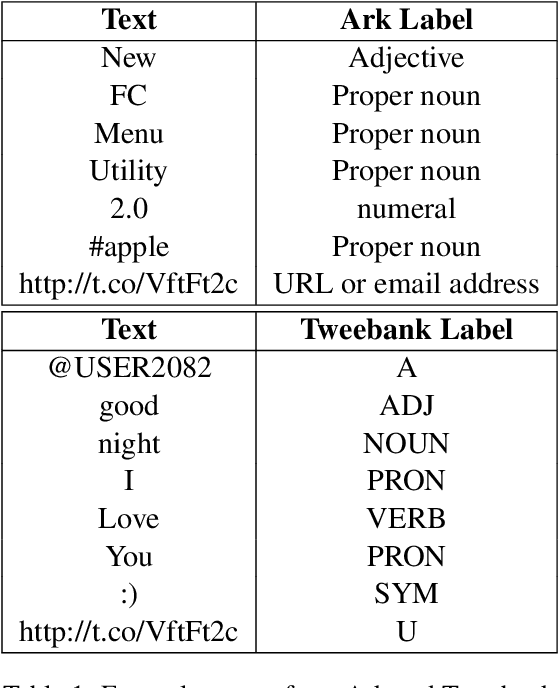
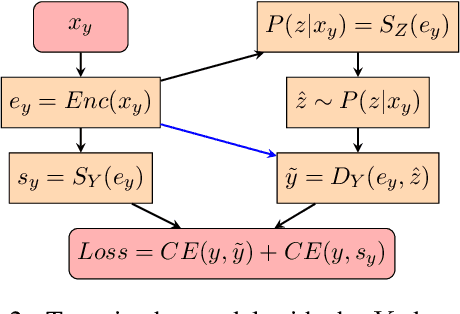
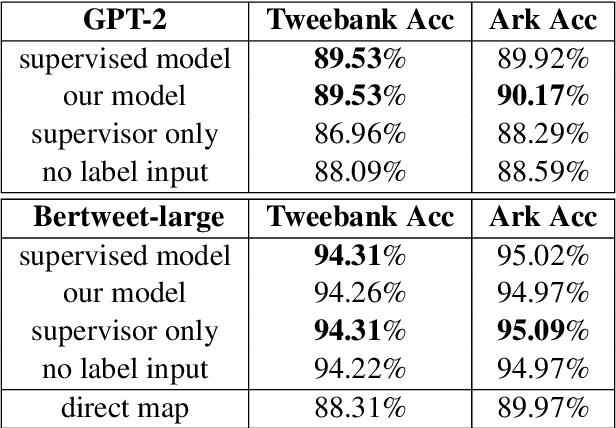
In hope of expanding training data, researchers often want to merge two or more datasets that are created using different labeling schemes. This paper considers two datasets that label part-of-speech (POS) tags under different tagging schemes and leverage the supervised labels of one dataset to help generate labels for the other dataset. This paper further discusses the theoretical difficulties of this approach and proposes a novel supervised architecture employing Transformers to tackle the problem of consolidating two completely disjoint datasets. The results diverge from initial expectations and discourage exploration into the use of disjoint labels to consolidate datasets with different labels.