 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Noisy-target Training: A Training Strategy for DNN-based Speech Enhancement without Clean Speech
Jan 21, 2021
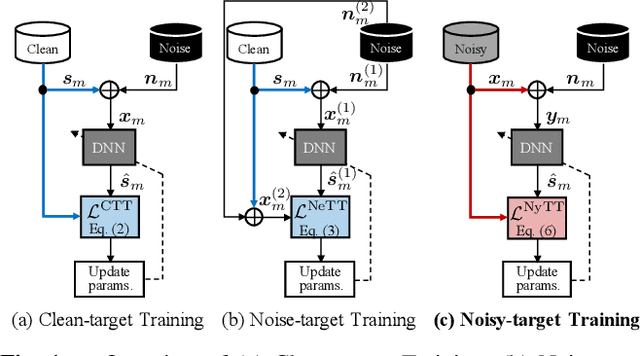

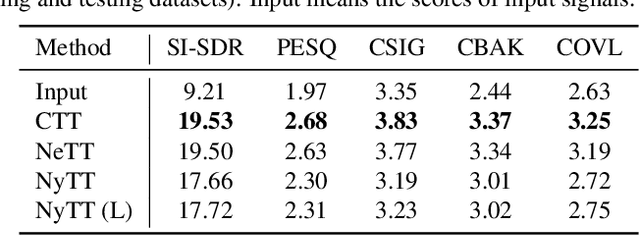
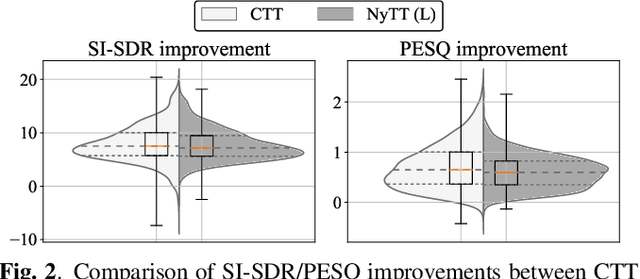
Deep neural network (DNN)-based speech enhancement ordinarily requires clean speech signals as the training target. However, collecting clean signals is very costly because they must be recorded in a studio. This requirement currently restricts the amount of training data for speech enhancement less than 1/1000 of that of speech recognition which does not need clean signals. Increasing the amount of training data is important for improving the performance, and hence the requirement of clean signals should be relaxed. In this paper, we propose a training strategy that does not require clean signals. The proposed method only utilizes noisy signals for training, which enables us to use a variety of speech signals in the wild. Our experimental results showed that the proposed method can achieve the performance similar to that of a DNN trained with clean signals.
Improving Transformer-based Conversational ASR by Inter-Sentential Attention Mechanism
Jul 02, 2022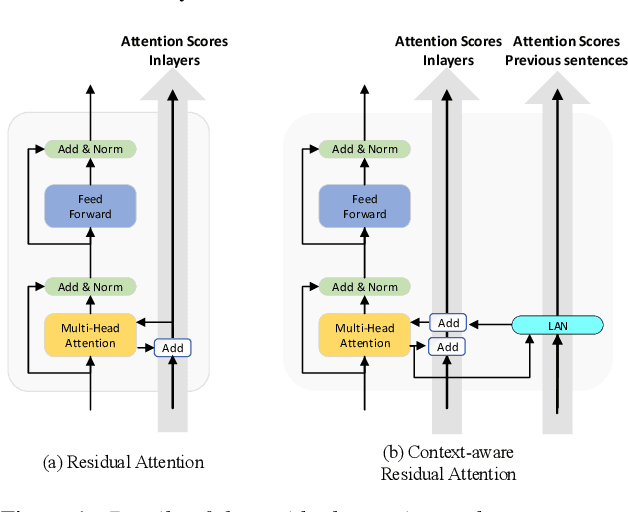
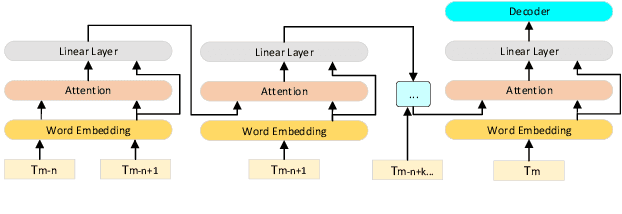

Transformer-based models have demonstrated their effectiveness in automatic speech recognition (ASR) tasks and even shown superior performance over the conventional hybrid framework. The main idea of Transformers is to capture the long-range global context within an utterance by self-attention layers. However, for scenarios like conversational speech, such utterance-level modeling will neglect contextual dependencies that span across utterances. In this paper, we propose to explicitly model the inter-sentential information in a Transformer based end-to-end architecture for conversational speech recognition. Specifically, for the encoder network, we capture the contexts of previous speech and incorporate such historic information into current input by a context-aware residual attention mechanism. For the decoder, the prediction of current utterance is also conditioned on the historic linguistic information through a conditional decoder framework. We show the effectiveness of our proposed method on several open-source dialogue corpora and the proposed method consistently improved the performance from the utterance-level Transformer-based ASR models.
UWSpeech: Speech to Speech Translation for Unwritten Languages
Jun 14, 2020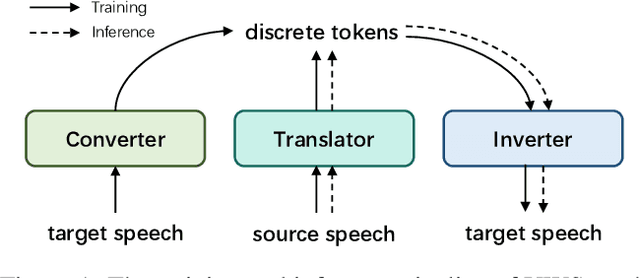
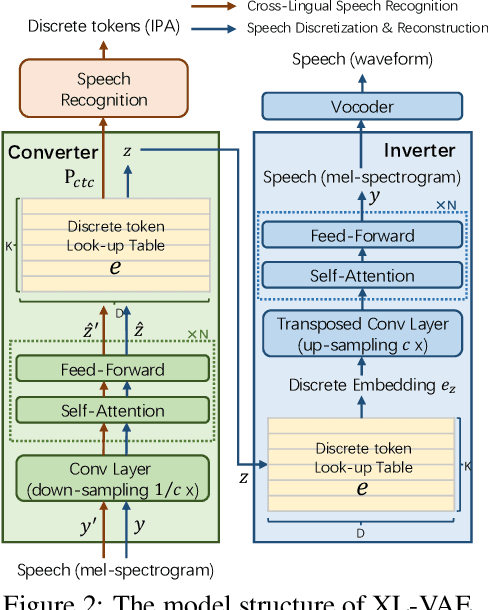


Existing speech to speech translation systems heavily rely on the text of target language: they usually translate source language either to target text and then synthesize target speech from text, or directly to target speech with target text for auxiliary training. However, those methods cannot be applied to unwritten target languages, which have no written text or phoneme available. In this paper, we develop a translation system for unwritten languages, named as UWSpeech, which converts target unwritten speech into discrete tokens with a converter, and then translates source-language speech into target discrete tokens with a translator, and finally synthesizes target speech from target discrete tokens with an inverter. We propose a method called XL-VAE, which enhances vector quantized variational autoencoder (VQ-VAE) with cross-lingual (XL) speech recognition, to train the converter and inverter of UWSpeech jointly. Experiments on Fisher Spanish-English conversation translation dataset show that UWSpeech outperforms direct translation and VQ-VAE baseline by about 16 and 10 BLEU points respectively, which demonstrate the advantages and potentials of UWSpeech.
AECMOS: A speech quality assessment metric for echo impairment
Oct 08, 2021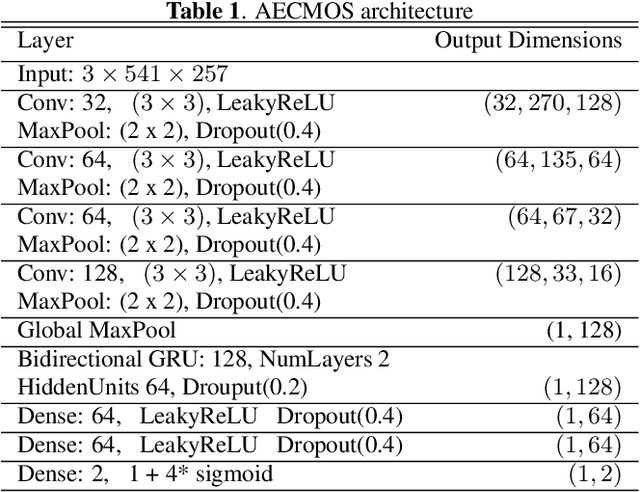
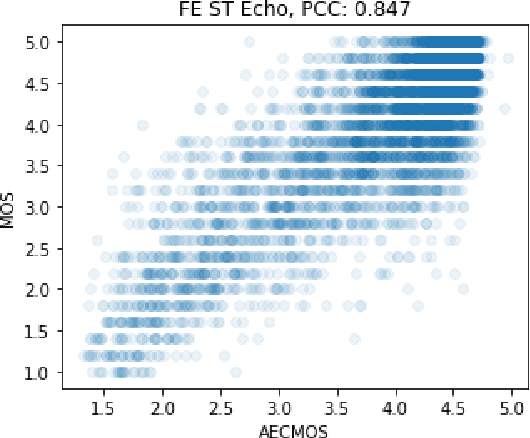
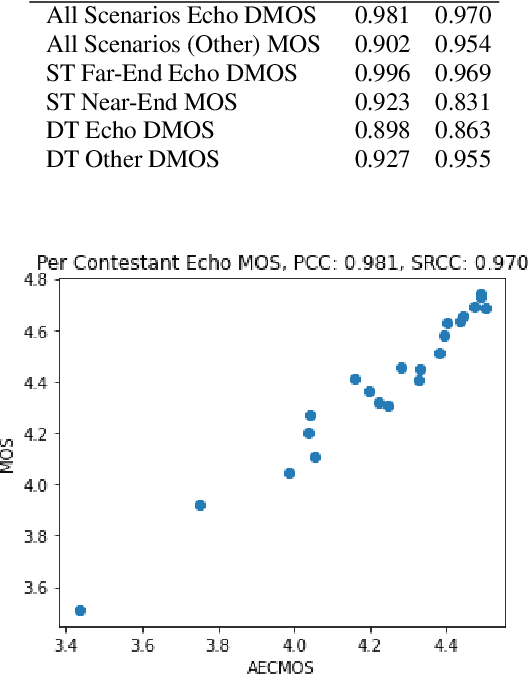
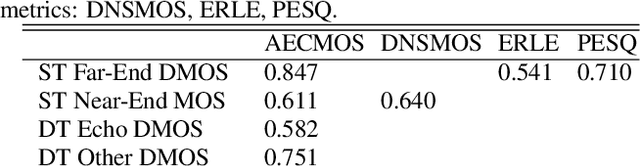
Traditionally, the quality of acoustic echo cancellers is evaluated using intrusive speech quality assessment measures such as ERLE \cite{g168} and PESQ \cite{p862}, or by carrying out subjective laboratory tests. Unfortunately, the former are not well correlated with human subjective measures, while the latter are time and resource consuming to carry out. We provide a new tool for speech quality assessment for echo impairment which can be used to evaluate the performance of acoustic echo cancellers. More precisely, we develop a neural network model to evaluate call quality degradations in two separate categories: echo and degradations from other sources. We show that our model is accurate as measured by correlation with human subjective quality ratings. Our tool can be used effectively to stack rank echo cancellation models. AECMOS is being made publicly available as an Azure service.
BirdSoundsDenoising: Deep Visual Audio Denoising for Bird Sounds
Oct 18, 2022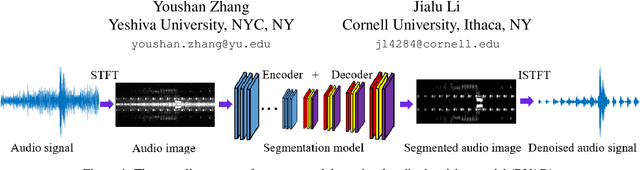

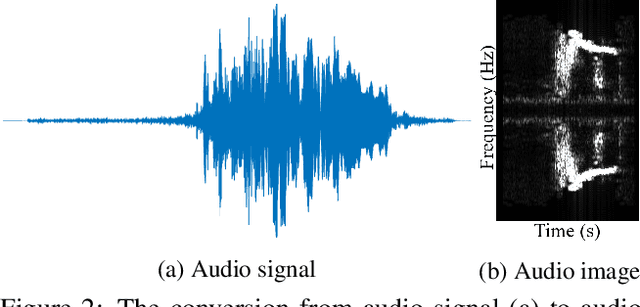
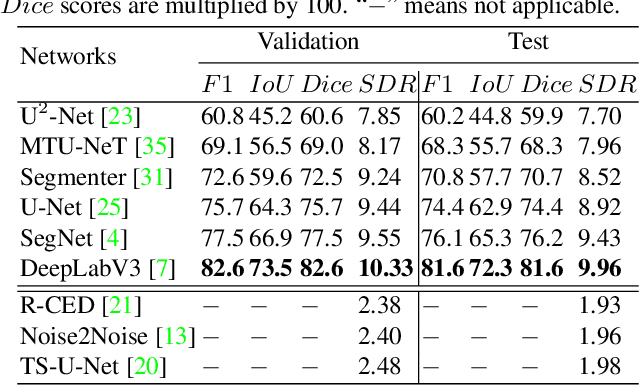
Audio denoising has been explored for decades using both traditional and deep learning-based methods. However, these methods are still limited to either manually added artificial noise or lower denoised audio quality. To overcome these challenges, we collect a large-scale natural noise bird sound dataset. We are the first to transfer the audio denoising problem into an image segmentation problem and propose a deep visual audio denoising (DVAD) model. With a total of 14,120 audio images, we develop an audio ImageMask tool and propose to use a few-shot generalization strategy to label these images. Extensive experimental results demonstrate that the proposed model achieves state-of-the-art performance. We also show that our method can be easily generalized to speech denoising, audio separation, audio enhancement, and noise estimation.
Is Attention always needed? A Case Study on Language Identification from Speech
Oct 05, 2021
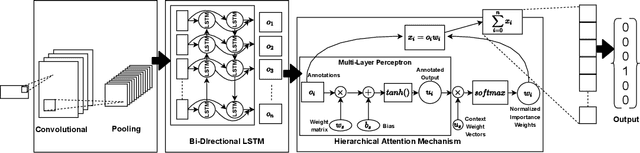
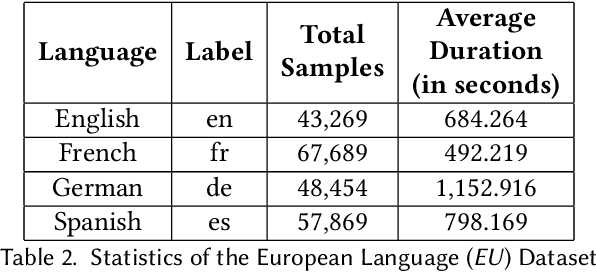
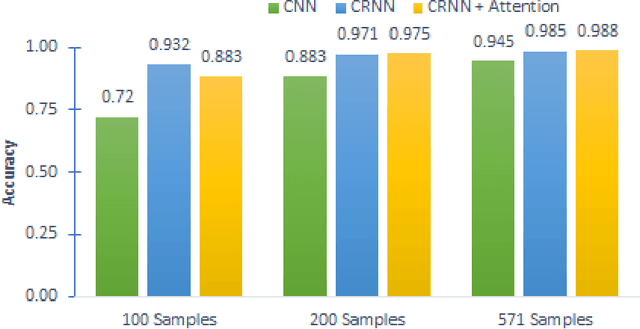
Language Identification (LID), a recommended initial step to Automatic Speech Recognition (ASR), is used to detect a spoken language from audio specimens. In state-of-the-art systems capable of multilingual speech processing, however, users have to explicitly set one or more languages before using them. LID, therefore, plays a very important role in situations where ASR based systems cannot parse the uttered language in multilingual contexts causing failure in speech recognition. We propose an attention based convolutional recurrent neural network (CRNN with Attention) that works on Mel-frequency Cepstral Coefficient (MFCC) features of audio specimens. Additionally, we reproduce some state-of-the-art approaches, namely Convolutional Neural Network (CNN) and Convolutional Recurrent Neural Network (CRNN), and compare them to our proposed method. We performed extensive evaluation on thirteen different Indian languages and our model achieves classification accuracy over 98%. Our LID model is robust to noise and provides 91.2% accuracy in a noisy scenario. The proposed model is easily extensible to new languages.
Simultaneous Speech-to-Speech Translation System with Neural Incremental ASR, MT, and TTS
Nov 11, 2020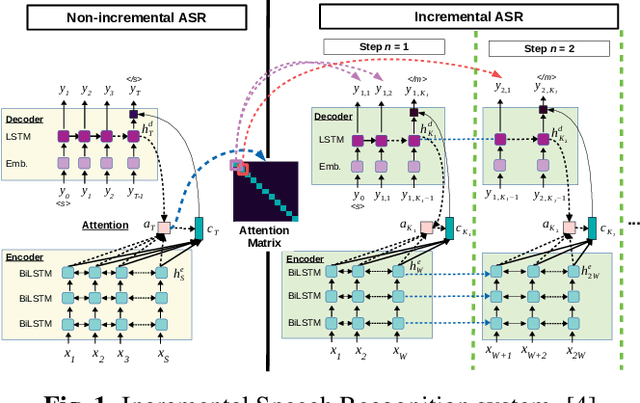
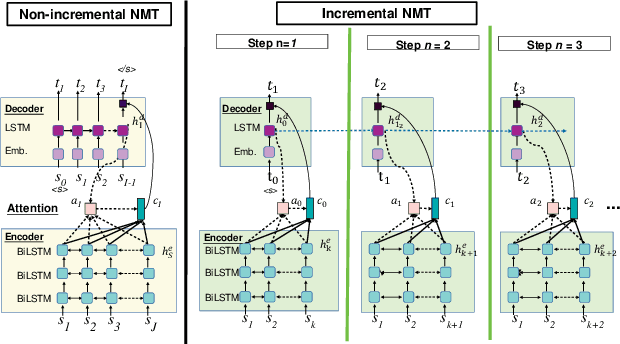
This paper presents a newly developed, simultaneous neural speech-to-speech translation system and its evaluation. The system consists of three fully-incremental neural processing modules for automatic speech recognition (ASR), machine translation (MT), and text-to-speech synthesis (TTS). We investigated its overall latency in the system's Ear-Voice Span and speaking latency along with module-level performance.
Enhancing audio quality for expressive Neural Text-to-Speech
Aug 13, 2021
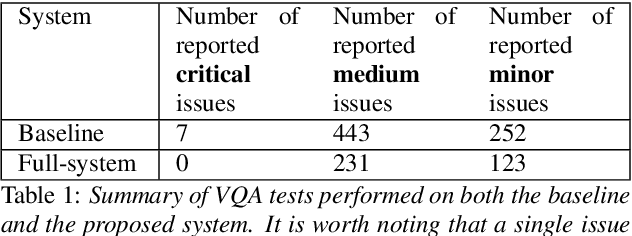
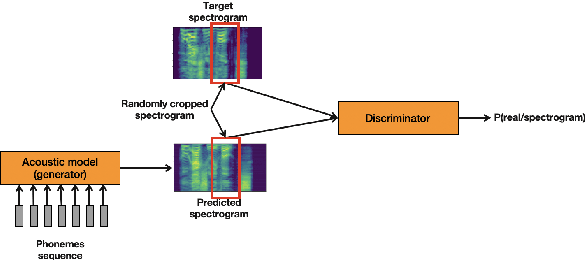
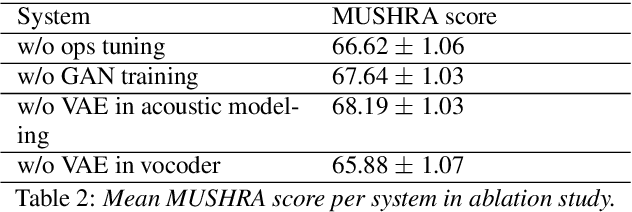
Artificial speech synthesis has made a great leap in terms of naturalness as recent Text-to-Speech (TTS) systems are capable of producing speech with similar quality to human recordings. However, not all speaking styles are easy to model: highly expressive voices are still challenging even to recent TTS architectures since there seems to be a trade-off between expressiveness in a generated audio and its signal quality. In this paper, we present a set of techniques that can be leveraged to enhance the signal quality of a highly-expressive voice without the use of additional data. The proposed techniques include: tuning the autoregressive loop's granularity during training; using Generative Adversarial Networks in acoustic modelling; and the use of Variational Auto-Encoders in both the acoustic model and the neural vocoder. We show that, when combined, these techniques greatly closed the gap in perceived naturalness between the baseline system and recordings by 39% in terms of MUSHRA scores for an expressive celebrity voice.
Black-box Adversarial Attacks on Commercial Speech Platforms with Minimal Information
Oct 19, 2021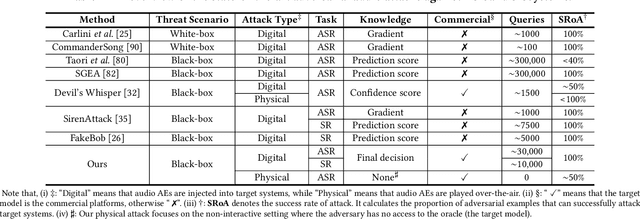

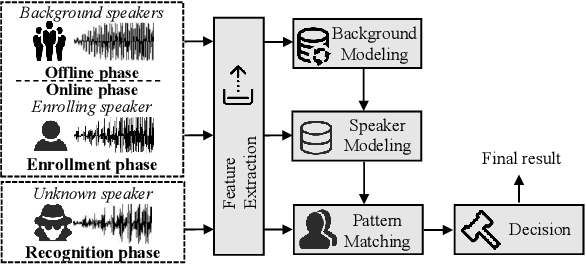
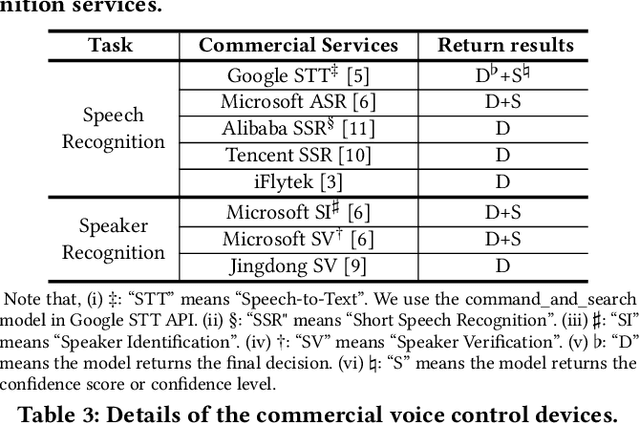
Adversarial attacks against commercial black-box speech platforms, including cloud speech APIs and voice control devices, have received little attention until recent years. The current "black-box" attacks all heavily rely on the knowledge of prediction/confidence scores to craft effective adversarial examples, which can be intuitively defended by service providers without returning these messages. In this paper, we propose two novel adversarial attacks in more practical and rigorous scenarios. For commercial cloud speech APIs, we propose Occam, a decision-only black-box adversarial attack, where only final decisions are available to the adversary. In Occam, we formulate the decision-only AE generation as a discontinuous large-scale global optimization problem, and solve it by adaptively decomposing this complicated problem into a set of sub-problems and cooperatively optimizing each one. Our Occam is a one-size-fits-all approach, which achieves 100% success rates of attacks with an average SNR of 14.23dB, on a wide range of popular speech and speaker recognition APIs, including Google, Alibaba, Microsoft, Tencent, iFlytek, and Jingdong, outperforming the state-of-the-art black-box attacks. For commercial voice control devices, we propose NI-Occam, the first non-interactive physical adversarial attack, where the adversary does not need to query the oracle and has no access to its internal information and training data. We combine adversarial attacks with model inversion attacks, and thus generate the physically-effective audio AEs with high transferability without any interaction with target devices. Our experimental results show that NI-Occam can successfully fool Apple Siri, Microsoft Cortana, Google Assistant, iFlytek and Amazon Echo with an average SRoA of 52% and SNR of 9.65dB, shedding light on non-interactive physical attacks against voice control devices.
AdaSpeech 2: Adaptive Text to Speech with Untranscribed Data
Apr 20, 2021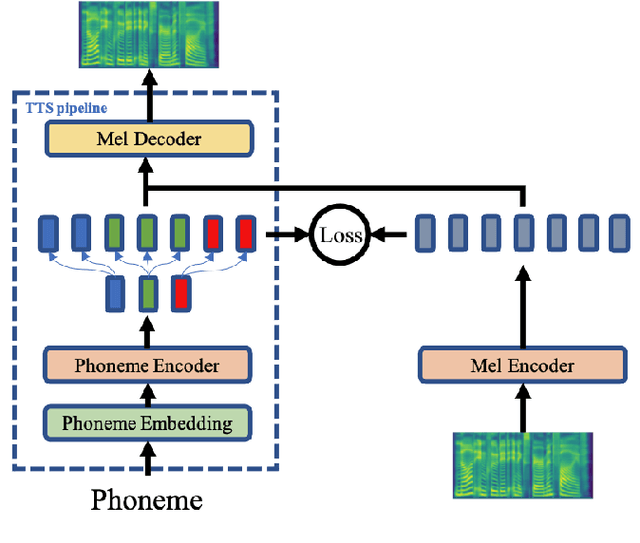
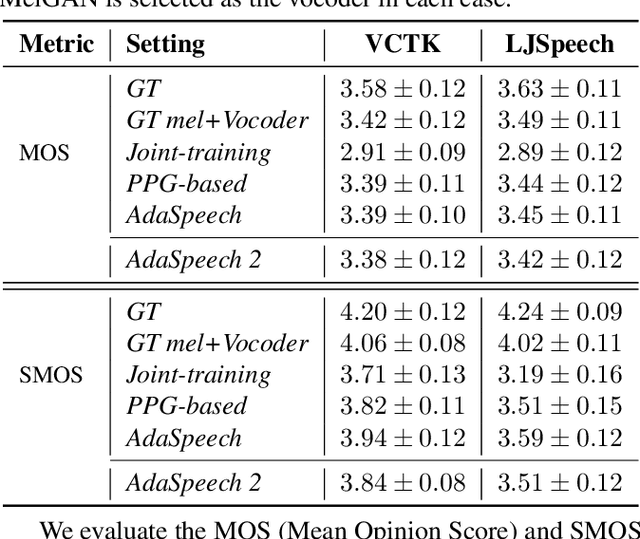
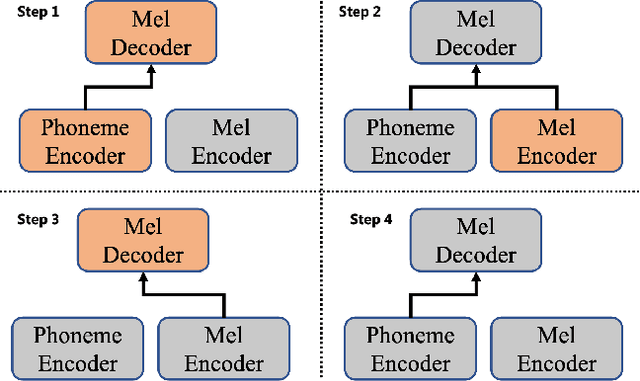

Text to speech (TTS) is widely used to synthesize personal voice for a target speaker, where a well-trained source TTS model is fine-tuned with few paired adaptation data (speech and its transcripts) on this target speaker. However, in many scenarios, only untranscribed speech data is available for adaptation, which brings challenges to the previous TTS adaptation pipelines (e.g., AdaSpeech). In this paper, we develop AdaSpeech 2, an adaptive TTS system that only leverages untranscribed speech data for adaptation. Specifically, we introduce a mel-spectrogram encoder to a well-trained TTS model to conduct speech reconstruction, and at the same time constrain the output sequence of the mel-spectrogram encoder to be close to that of the original phoneme encoder. In adaptation, we use untranscribed speech data for speech reconstruction and only fine-tune the TTS decoder. AdaSpeech 2 has two advantages: 1) Pluggable: our system can be easily applied to existing trained TTS models without re-training. 2) Effective: our system achieves on-par voice quality with the transcribed TTS adaptation (e.g., AdaSpeech) with the same amount of untranscribed data, and achieves better voice quality than previous untranscribed adaptation methods. Synthesized speech samples can be found at https://speechresearch.github.io/adaspeech2/.