 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Deep Learning For Prominence Detection In Children's Read Speech
Oct 27, 2021

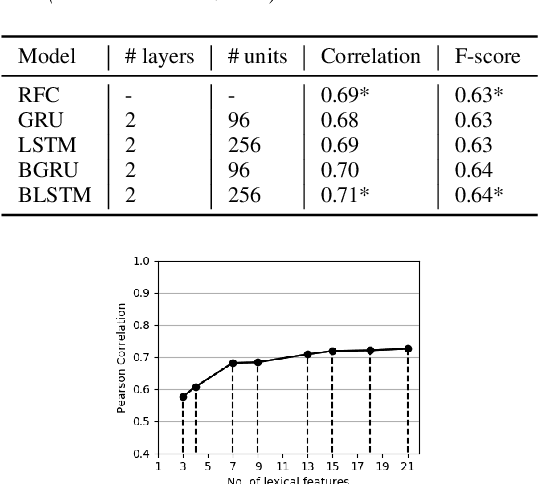
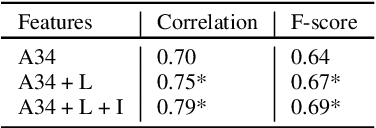
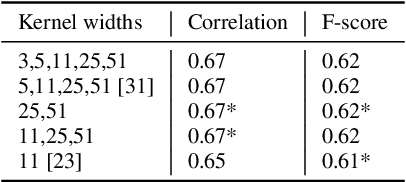
The detection of perceived prominence in speech has attracted approaches ranging from the design of linguistic knowledge-based acoustic features to the automatic feature learning from suprasegmental attributes such as pitch and intensity contours. We present here, in contrast, a system that operates directly on segmented speech waveforms to learn features relevant to prominent word detection for children's oral fluency assessment. The chosen CRNN (convolutional recurrent neural network) framework, incorporating both word-level features and sequence information, is found to benefit from the perceptually motivated SincNet filters as the first convolutional layer. We further explore the benefits of the linguistic association between the prosodic events of phrase boundary and prominence with different multi-task architectures. Matching the previously reported performance on the same dataset of a random forest ensemble predictor trained on carefully chosen hand-crafted acoustic features, we evaluate further the possibly complementary information from hand-crafted acoustic and pre-trained lexical features.
A Closer Look at Audio-Visual Multi-Person Speech Recognition and Active Speaker Selection
May 11, 2022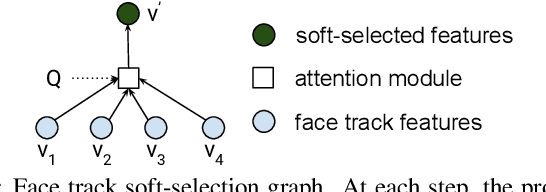
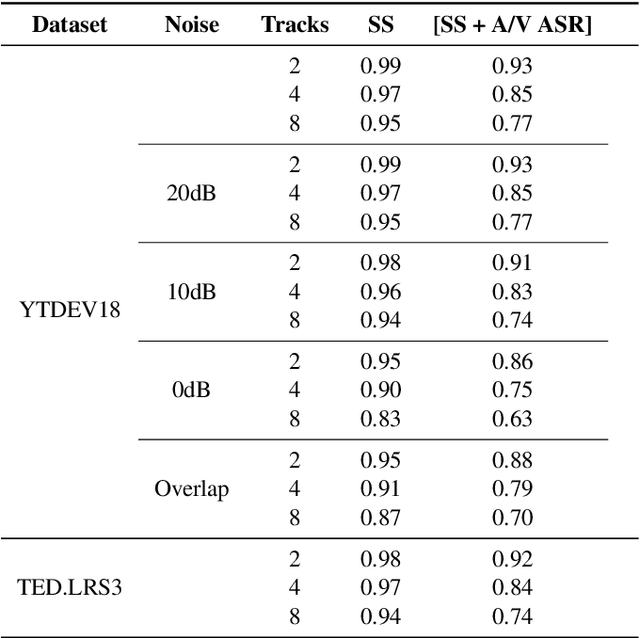
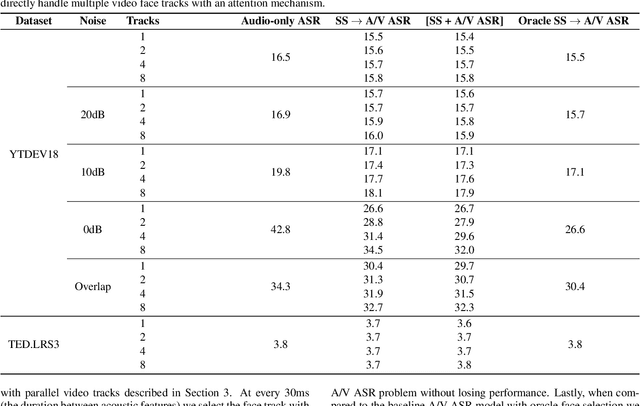
Audio-visual automatic speech recognition is a promising approach to robust ASR under noisy conditions. However, up until recently it had been traditionally studied in isolation assuming the video of a single speaking face matches the audio, and selecting the active speaker at inference time when multiple people are on screen was put aside as a separate problem. As an alternative, recent work has proposed to address the two problems simultaneously with an attention mechanism, baking the speaker selection problem directly into a fully differentiable model. One interesting finding was that the attention indirectly learns the association between the audio and the speaking face even though this correspondence is never explicitly provided at training time. In the present work we further investigate this connection and examine the interplay between the two problems. With experiments involving over 50 thousand hours of public YouTube videos as training data, we first evaluate the accuracy of the attention layer on an active speaker selection task. Secondly, we show under closer scrutiny that an end-to-end model performs at least as well as a considerably larger two-step system that utilizes a hard decision boundary under various noise conditions and number of parallel face tracks.
Topic Model Robustness to Automatic Speech Recognition Errors in Podcast Transcripts
Sep 25, 2021
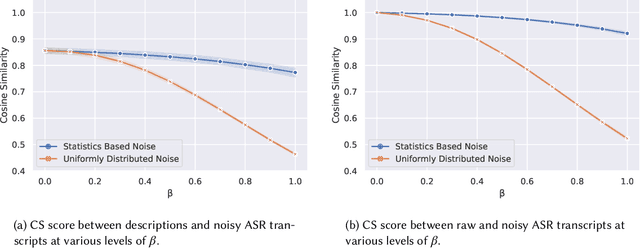

For a multilingual podcast streaming service, it is critical to be able to deliver relevant content to all users independent of language. Podcast content relevance is conventionally determined using various metadata sources. However, with the increasing quality of speech recognition in many languages, utilizing automatic transcriptions to provide better content recommendations becomes possible. In this work, we explore the robustness of a Latent Dirichlet Allocation topic model when applied to transcripts created by an automatic speech recognition engine. Specifically, we explore how increasing transcription noise influences topics obtained from transcriptions in Danish; a low resource language. First, we observe a baseline of cosine similarity scores between topic embeddings from automatic transcriptions and the descriptions of the podcasts written by the podcast creators. We then observe how the cosine similarities decrease as transcription noise increases and conclude that even when automatic speech recognition transcripts are erroneous, it is still possible to obtain high-quality topic embeddings from the transcriptions.
Proficiency assessment of L2 spoken English using wav2vec 2.0
Oct 24, 2022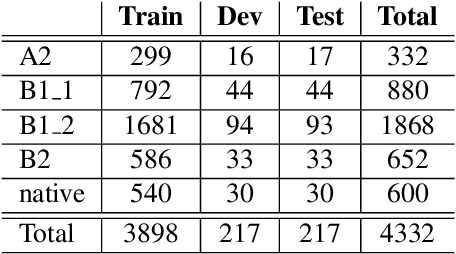
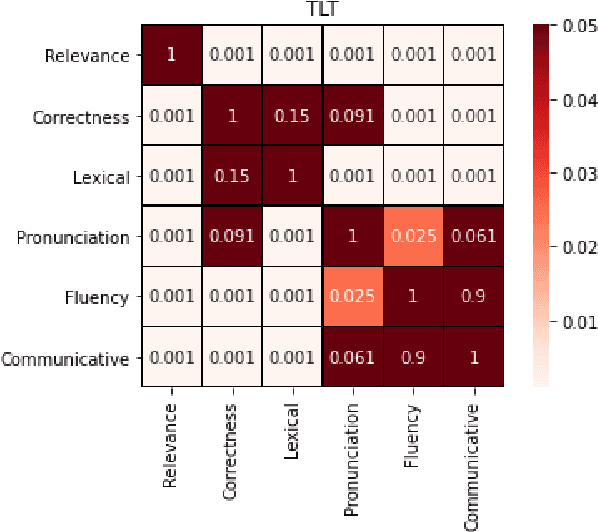
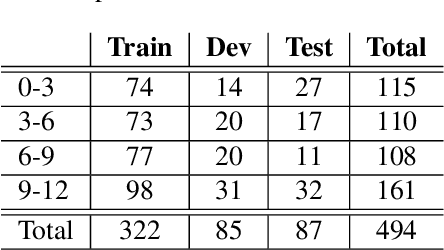
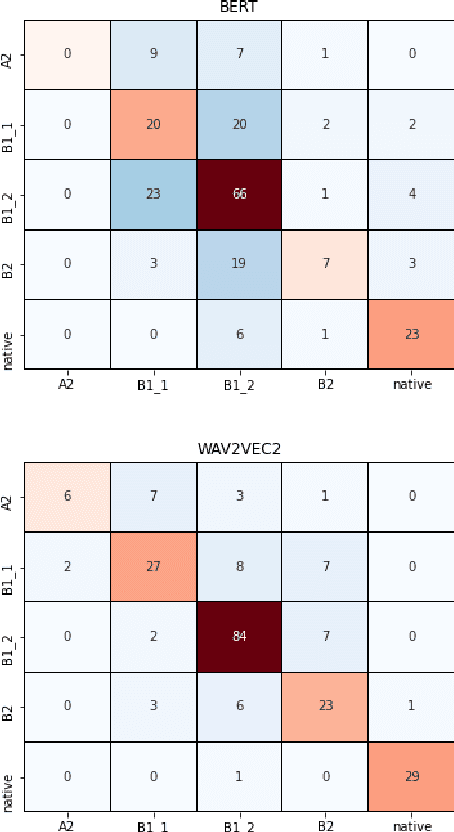
The increasing demand for learning English as a second language has led to a growing interest in methods for automatically assessing spoken language proficiency. Most approaches use hand-crafted features, but their efficacy relies on their particular underlying assumptions and they risk discarding potentially salient information about proficiency. Other approaches rely on transcriptions produced by ASR systems which may not provide a faithful rendition of a learner's utterance in specific scenarios (e.g., non-native children's spontaneous speech). Furthermore, transcriptions do not yield any information about relevant aspects such as intonation, rhythm or prosody. In this paper, we investigate the use of wav2vec 2.0 for assessing overall and individual aspects of proficiency on two small datasets, one of which is publicly available. We find that this approach significantly outperforms the BERT-based baseline system trained on ASR and manual transcriptions used for comparison.
PADA: Pruning Assisted Domain Adaptation for Self-Supervised Speech Representations
Mar 31, 2022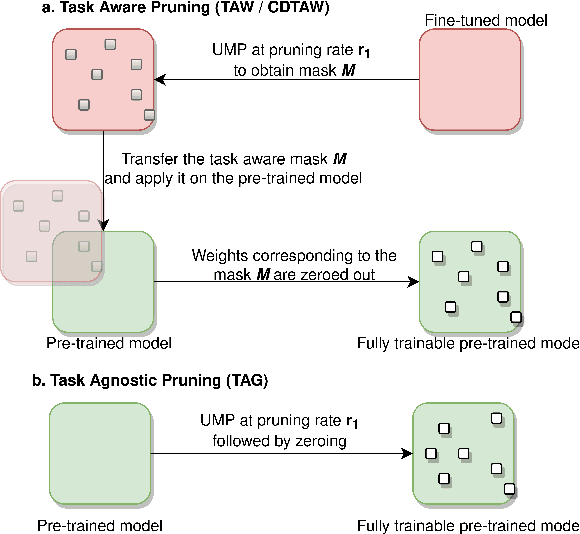
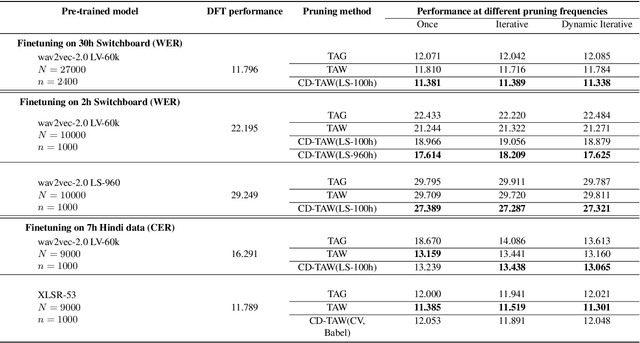
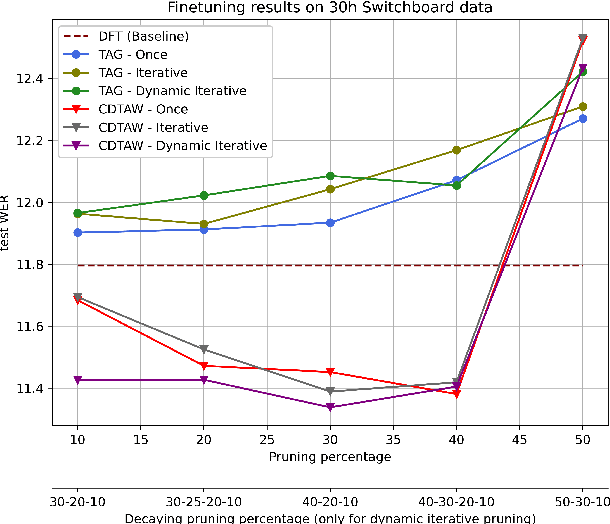
While self-supervised speech representation learning (SSL) models serve a variety of downstream tasks, these models have been observed to overfit to the domain from which the unlabelled data originates. To alleviate this issue, we propose PADA (Pruning Assisted Domain Adaptation) and zero out redundant weights from models pre-trained on large amounts of out-of-domain (OOD) data. Intuitively, this helps to make space for the target-domain ASR finetuning. The redundant weights can be identified through various pruning strategies which have been discussed in detail as a part of this work. Specifically, we investigate the effect of the recently discovered Task-Agnostic and Task-Aware pruning on PADA and propose a new pruning paradigm based on the latter, which we call Cross-Domain Task-Aware Pruning (CD-TAW). CD-TAW obtains the initial pruning mask from a well fine-tuned OOD model, which makes it starkly different from the rest of the pruning strategies discussed in the paper. Our proposed CD-TAW methodology achieves up to 20.6% relative WER improvement over our baseline when fine-tuned on a 2-hour subset of Switchboard data without language model (LM) decoding. Furthermore, we conduct a detailed analysis to highlight the key design choices of our proposed method.
Silent Speech Interfaces for Speech Restoration: A Review
Sep 04, 2020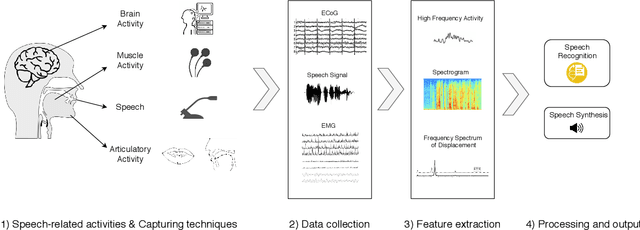

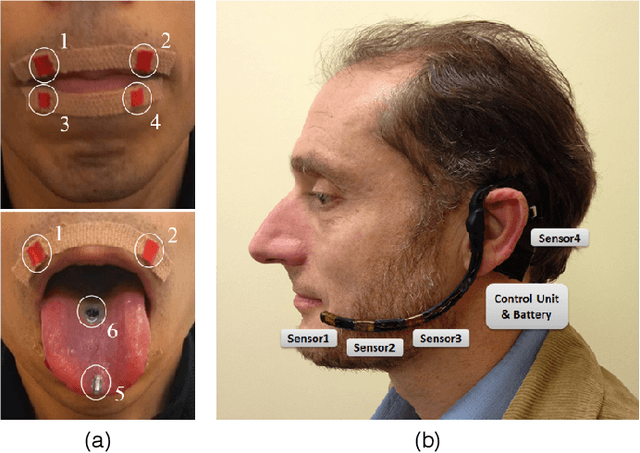

This review summarises the status of silent speech interface (SSI) research. SSIs rely on non-acoustic biosignals generated by the human body during speech production to enable communication whenever normal verbal communication is not possible or not desirable. In this review, we focus on the first case and present latest SSI research aimed at providing new alternative and augmentative communication methods for persons with severe speech disorders. SSIs can employ a variety of biosignals to enable silent communication, such as electrophysiological recordings of neural activity, electromyographic (EMG) recordings of vocal tract movements or the direct tracking of articulator movements using imaging techniques. Depending on the disorder, some sensing techniques may be better suited than others to capture speech-related information. For instance, EMG and imaging techniques are well suited for laryngectomised patients, whose vocal tract remains almost intact but are unable to speak after the removal of the vocal folds, but fail for severely paralysed individuals. From the biosignals, SSIs decode the intended message, using automatic speech recognition or speech synthesis algorithms. Despite considerable advances in recent years, most present-day SSIs have only been validated in laboratory settings for healthy users. Thus, as discussed in this paper, a number of challenges remain to be addressed in future research before SSIs can be promoted to real-world applications. If these issues can be addressed successfully, future SSIs will improve the lives of persons with severe speech impairments by restoring their communication capabilities.
Low-resource Accent Classification in Geographically-proximate Settings: A Forensic and Sociophonetics Perspective
Jun 29, 2022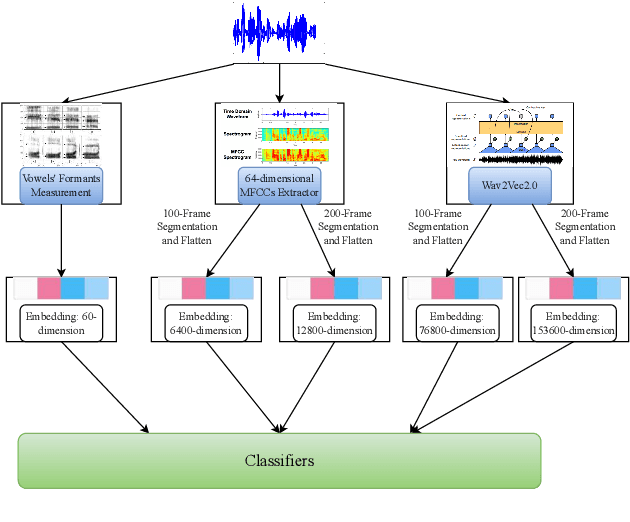
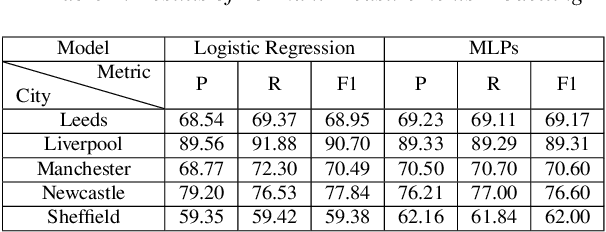

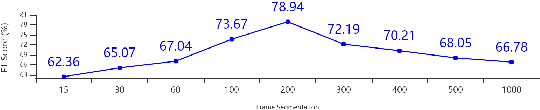
Accented speech recognition and accent classification are relatively under-explored research areas in speech technology. Recently, deep learning-based methods and Transformer-based pretrained models have achieved superb performances in both areas. However, most accent classification tasks focused on classifying different kinds of English accents and little attention was paid to geographically-proximate accent classification, especially under a low-resource setting where forensic speech science tasks usually encounter. In this paper, we explored three main accent modelling methods combined with two different classifiers based on 105 speaker recordings retrieved from five urban varieties in Northern England. Although speech representations generated from pretrained models generally have better performances in downstream classification, traditional methods like Mel Frequency Cepstral Coefficients (MFCCs) and formant measurements are equipped with specific strengths. These results suggest that in forensic phonetics scenario where data are relatively scarce, a simple modelling method and classifier could be competitive with state-of-the-art pretrained speech models as feature extractors, which could enhance a sooner estimation for the accent information in practices. Besides, our findings also cross-validated a new methodology in quantifying sociophonetic changes.
MetricNet: Towards Improved Modeling For Non-Intrusive Speech Quality Assessment
Apr 02, 2021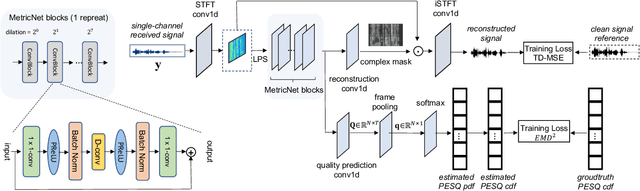
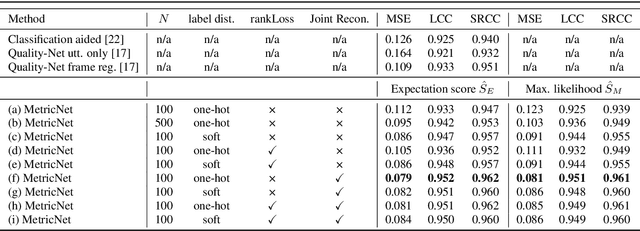
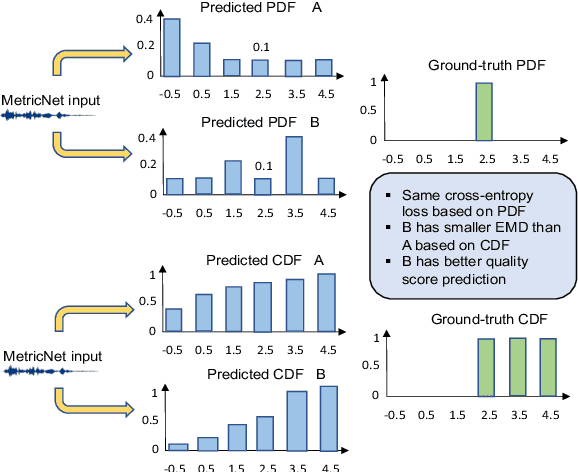
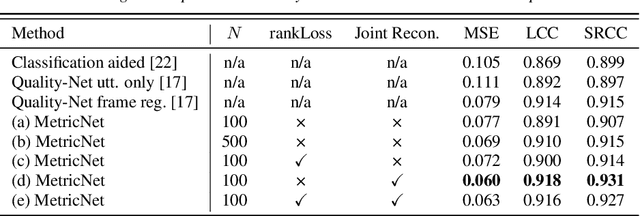
The objective speech quality assessment is usually conducted by comparing received speech signal with its clean reference, while human beings are capable of evaluating the speech quality without any reference, such as in the mean opinion score (MOS) tests. Non-intrusive speech quality assessment has attracted much attention recently due to the lack of access to clean reference signals for objective evaluations in real scenarios. In this paper, we propose a novel non-intrusive speech quality measurement model, MetricNet, which leverages label distribution learning and joint speech reconstruction learning to achieve significantly improved performance compared to the existing non-intrusive speech quality measurement models. We demonstrate that the proposed approach yields promisingly high correlation to the intrusive objective evaluation of speech quality on clean, noisy and processed speech data.
Towards Multi-Scale Style Control for Expressive Speech Synthesis
Apr 08, 2021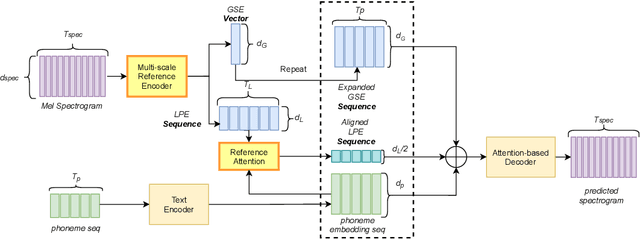
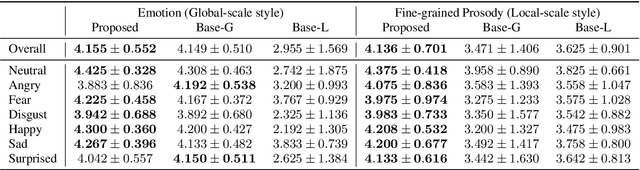
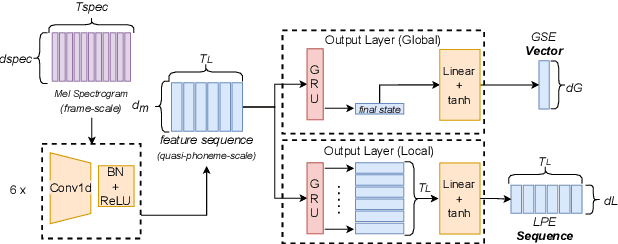
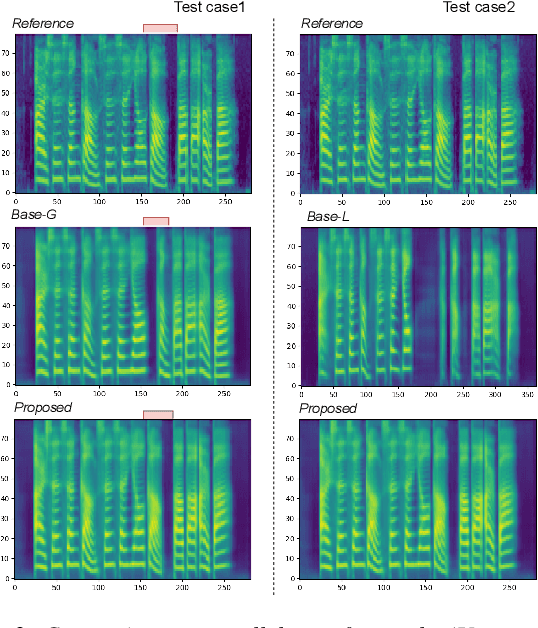
This paper introduces a multi-scale speech style modeling method for end-to-end expressive speech synthesis. The proposed method employs a multi-scale reference encoder to extract both the global-scale utterance-level and the local-scale quasi-phoneme-level style features of the target speech, which are then fed into the speech synthesis model as an extension to the input phoneme sequence. During training time, the multi-scale style model could be jointly trained with the speech synthesis model in an end-to-end fashion. By applying the proposed method to style transfer task, experimental results indicate that the controllability of the multi-scale speech style model and the expressiveness of the synthesized speech are greatly improved. Moreover, by assigning different reference speeches to extraction of style on each scale, the flexibility of the proposed method is further revealed.
Unsupervised Boundary-Aware Language Model Pretraining for Chinese Sequence Labeling
Oct 27, 2022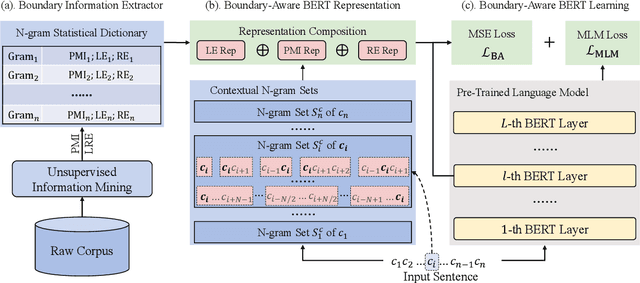
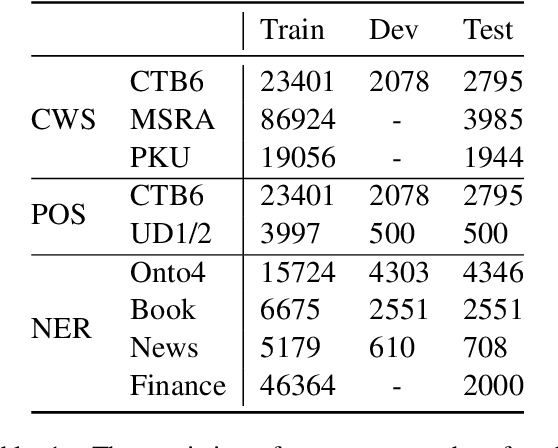
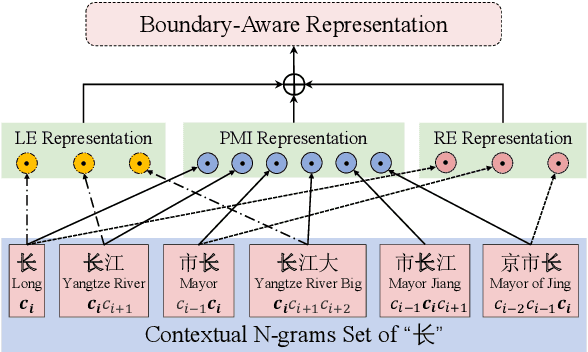
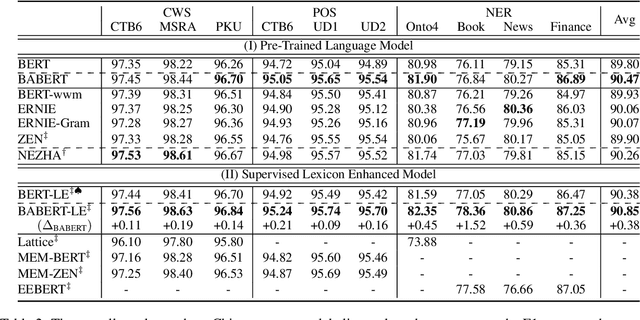
Boundary information is critical for various Chinese language processing tasks, such as word segmentation, part-of-speech tagging, and named entity recognition. Previous studies usually resorted to the use of a high-quality external lexicon, where lexicon items can offer explicit boundary information. However, to ensure the quality of the lexicon, great human effort is always necessary, which has been generally ignored. In this work, we suggest unsupervised statistical boundary information instead, and propose an architecture to encode the information directly into pre-trained language models, resulting in Boundary-Aware BERT (BABERT). We apply BABERT for feature induction of Chinese sequence labeling tasks. Experimental results on ten benchmarks of Chinese sequence labeling demonstrate that BABERT can provide consistent improvements on all datasets. In addition, our method can complement previous supervised lexicon exploration, where further improvements can be achieved when integrated with external lexicon information.