 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Audio-driven Neural Gesture Reenactment with Video Motion Graphs
Jul 23, 2022
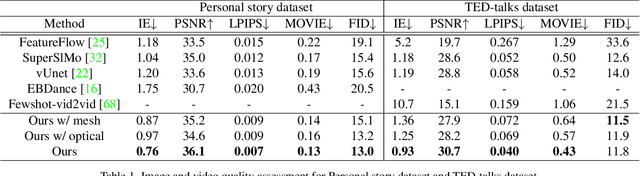
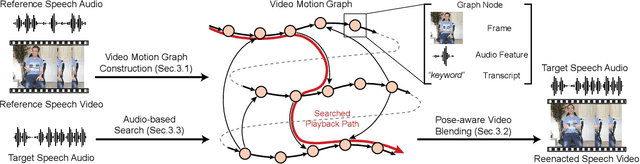
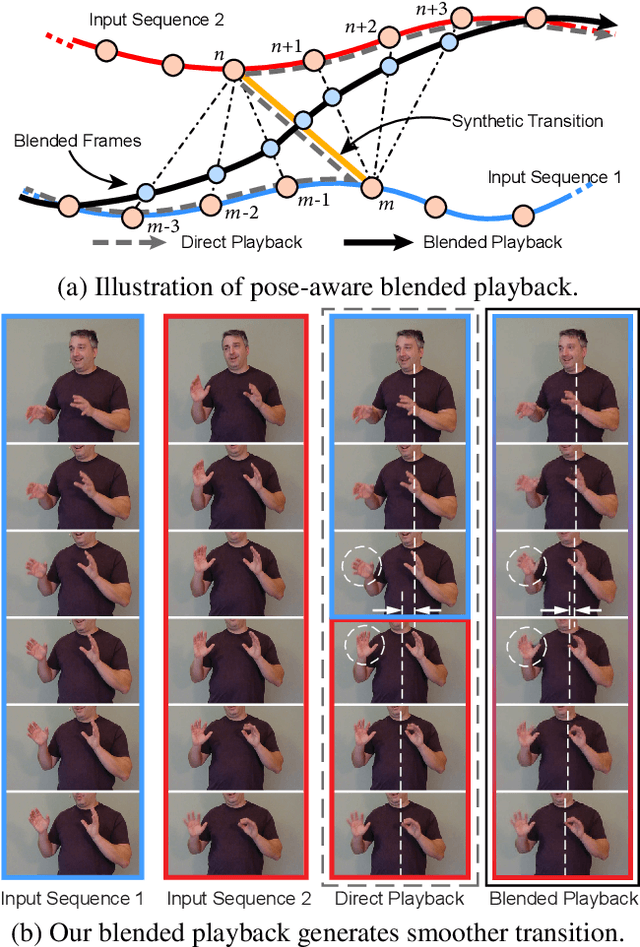
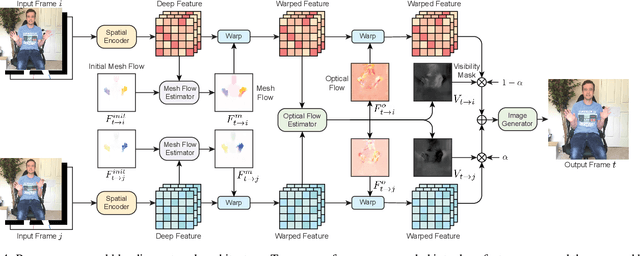
Human speech is often accompanied by body gestures including arm and hand gestures. We present a method that reenacts a high-quality video with gestures matching a target speech audio. The key idea of our method is to split and re-assemble clips from a reference video through a novel video motion graph encoding valid transitions between clips. To seamlessly connect different clips in the reenactment, we propose a pose-aware video blending network which synthesizes video frames around the stitched frames between two clips. Moreover, we developed an audio-based gesture searching algorithm to find the optimal order of the reenacted frames. Our system generates reenactments that are consistent with both the audio rhythms and the speech content. We evaluate our synthesized video quality quantitatively, qualitatively, and with user studies, demonstrating that our method produces videos of much higher quality and consistency with the target audio compared to previous work and baselines.
Topic Model Robustness to Automatic Speech Recognition Errors in Podcast Transcripts
Sep 25, 2021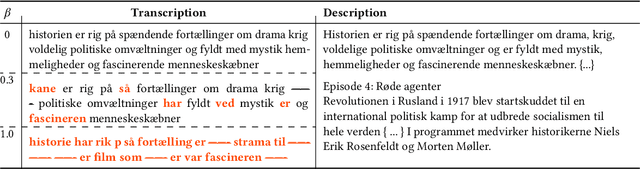
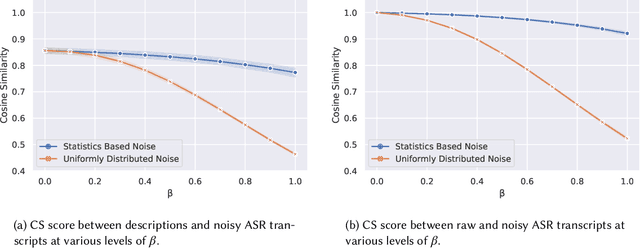

For a multilingual podcast streaming service, it is critical to be able to deliver relevant content to all users independent of language. Podcast content relevance is conventionally determined using various metadata sources. However, with the increasing quality of speech recognition in many languages, utilizing automatic transcriptions to provide better content recommendations becomes possible. In this work, we explore the robustness of a Latent Dirichlet Allocation topic model when applied to transcripts created by an automatic speech recognition engine. Specifically, we explore how increasing transcription noise influences topics obtained from transcriptions in Danish; a low resource language. First, we observe a baseline of cosine similarity scores between topic embeddings from automatic transcriptions and the descriptions of the podcasts written by the podcast creators. We then observe how the cosine similarities decrease as transcription noise increases and conclude that even when automatic speech recognition transcripts are erroneous, it is still possible to obtain high-quality topic embeddings from the transcriptions.
From Nano to Macro: Overview of the IEEE Bio Image and Signal Processing Technical Committee
Oct 31, 2022

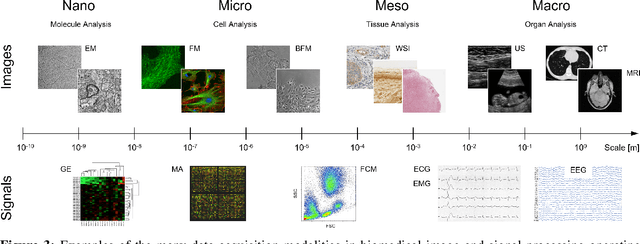
The Bio Image and Signal Processing (BISP) Technical Committee (TC) of the IEEE Signal Processing Society (SPS) promotes activities within the broad technical field of biomedical image and signal processing. Areas of interest include medical and biological imaging, digital pathology, molecular imaging, microscopy, and associated computational imaging, image analysis, and image-guided treatment, alongside physiological signal processing, computational biology, and bioinformatics. BISP has 40 members and covers a wide range of EDICS, including CIS-MI: Medical Imaging, BIO-MIA: Medical Image Analysis, BIO-BI: Biological Imaging, BIO: Biomedical Signal Processing, BIO-BCI: Brain/Human-Computer Interfaces, and BIO-INFR: Bioinformatics. BISP plays a central role in the organization of the IEEE International Symposium on Biomedical Imaging (ISBI) and contributes to the technical sessions at the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), and the IEEE International Conference on Image Processing (ICIP). In this paper, we provide a brief history of the TC, review the technological and methodological contributions its community delivered, and highlight promising new directions we anticipate.
Fast and parallel decoding for transducer
Oct 31, 2022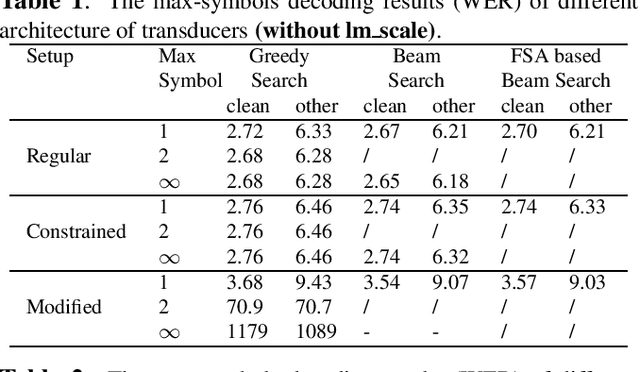
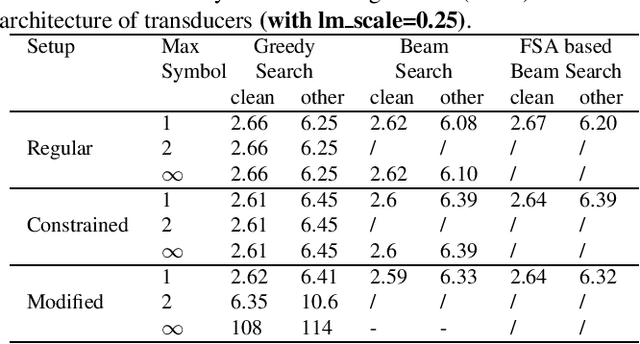
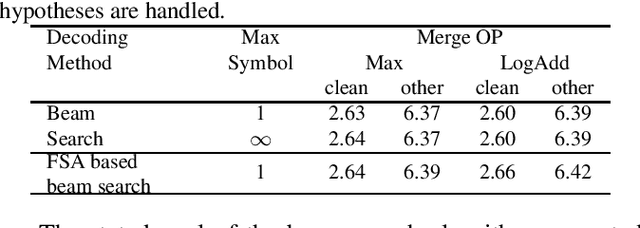
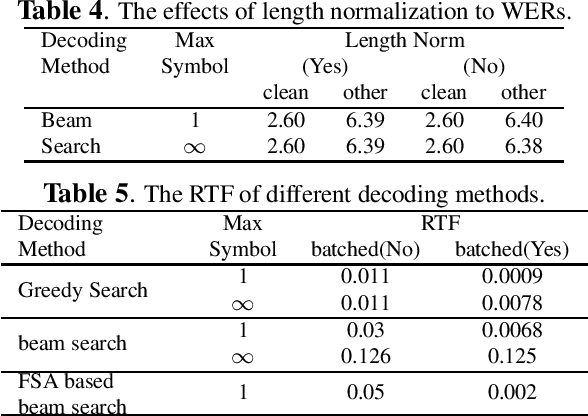
The transducer architecture is becoming increasingly popular in the field of speech recognition, because it is naturally streaming as well as high in accuracy. One of the drawbacks of transducer is that it is difficult to decode in a fast and parallel way due to an unconstrained number of symbols that can be emitted per time step. In this work, we introduce a constrained version of transducer loss to learn strictly monotonic alignments between the sequences; we also improve the standard greedy search and beam search algorithms by limiting the number of symbols that can be emitted per time step in transducer decoding, making it more efficient to decode in parallel with batches. Furthermore, we propose an finite state automaton-based (FSA) parallel beam search algorithm that can run with graphs on GPU efficiently. The experiment results show that we achieve slight word error rate (WER) improvement as well as significant speedup in decoding. Our work is open-sourced and publicly available\footnote{https://github.com/k2-fsa/icefall}.
Magnitude or Phase? A Two Stage Algorithm for Dereverberation
Oct 31, 2022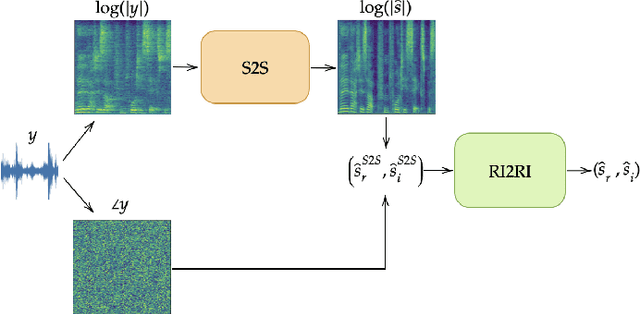
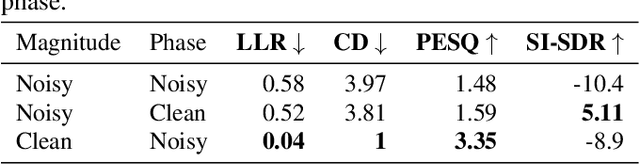
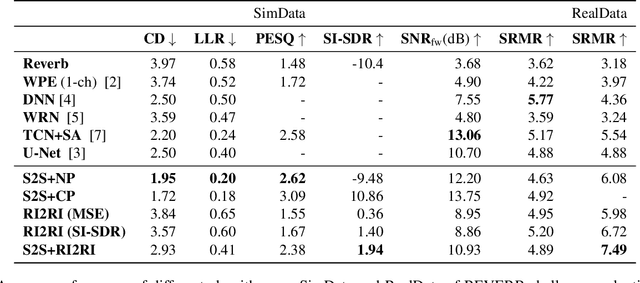
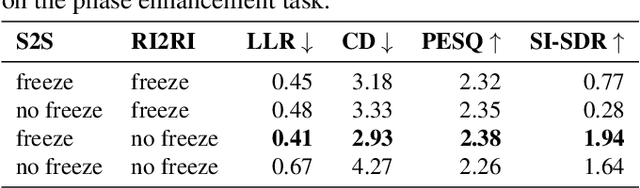
In this work we present a new single-microphone speech dereverberation algorithm. First, a performance analysis is presented to interpret that algorithms focused on improving solely magnitude or phase are not good enough. Furthermore, we demonstrate that few objective measurements have high correlation with the clean magnitude while others with the clean phase. Consequently ,we propose a new architecture which consists of two sub-models, each of which is responsible for a different task. The first model estimates the clean magnitude given the noisy input. The enhanced magnitude together with the noisy-input phase are then used as inputs to the second model to estimate the real and imaginary portions of the dereverberated signal. A training scheme including pre-training and fine-tuning is presented in the paper. We evaluate our proposed approach using data from the REVERB challenge and compare our results to other methods. We demonstrate consistent improvements in all measures, which can be attributed to the improved estimates of both the magnitude and the phase.
UTTS: Unsupervised TTS with Conditional Disentangled Sequential Variational Auto-encoder
Jun 07, 2022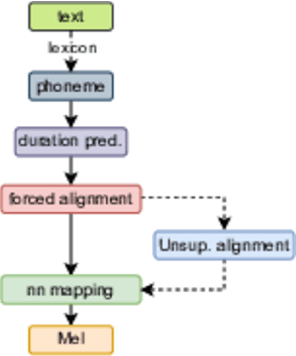

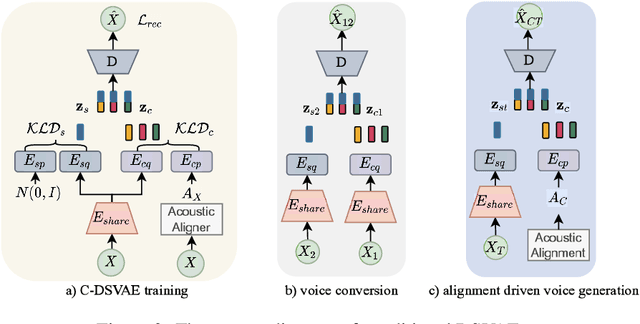
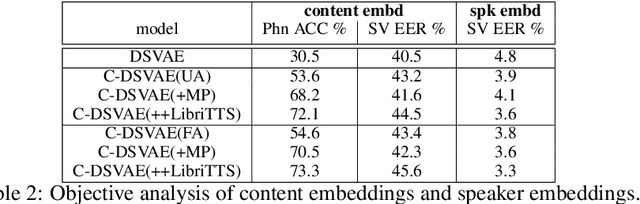
In this paper, we propose a novel unsupervised text-to-speech (UTTS) framework which does not require text-audio pairs for the TTS acoustic modeling (AM). UTTS is a multi-speaker speech synthesizer developed from the perspective of disentangled speech representation learning. The framework offers a flexible choice of a speaker's duration model, timbre feature (identity) and content for TTS inference. We leverage recent advancements in self-supervised speech representation learning as well as speech synthesis front-end techniques for the system development. Specifically, we utilize a lexicon to map input text to the phoneme sequence, which is expanded to the frame-level forced alignment (FA) with a speaker-dependent duration model. Then, we develop an alignment mapping module that converts the FA to the unsupervised alignment (UA). Finally, a Conditional Disentangled Sequential Variational Auto-encoder (C-DSVAE), serving as the self-supervised TTS AM, takes the predicted UA and a target speaker embedding to generate the mel spectrogram, which is ultimately converted to waveform with a neural vocoder. We show how our method enables speech synthesis without using a paired TTS corpus. Experiments demonstrate that UTTS can synthesize speech of high naturalness and intelligibility measured by human and objective evaluations.
Learning to Enhance or Not: Neural Network-Based Switching of Enhanced and Observed Signals for Overlapping Speech Recognition
Jan 11, 2022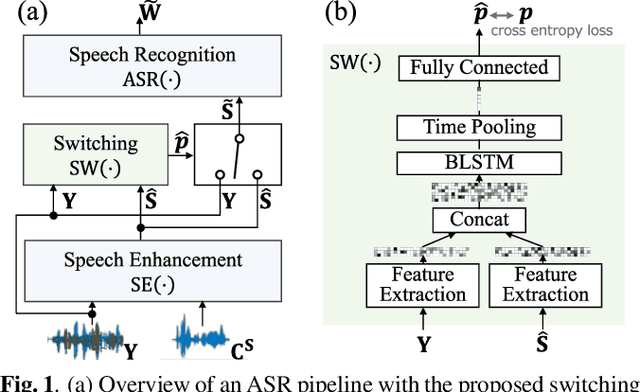
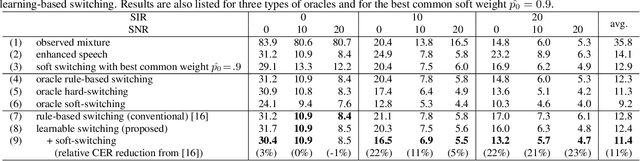
The combination of a deep neural network (DNN) -based speech enhancement (SE) front-end and an automatic speech recognition (ASR) back-end is a widely used approach to implement overlapping speech recognition. However, the SE front-end generates processing artifacts that can degrade the ASR performance. We previously found that such performance degradation can occur even under fully overlapping conditions, depending on the signal-to-interference ratio (SIR) and signal-to-noise ratio (SNR). To mitigate the degradation, we introduced a rule-based method to switch the ASR input between the enhanced and observed signals, which showed promising results. However, the rule's optimality was unclear because it was heuristically designed and based only on SIR and SNR values. In this work, we propose a DNN-based switching method that directly estimates whether ASR will perform better on the enhanced or observed signals. We also introduce soft-switching that computes a weighted sum of the enhanced and observed signals for ASR input, with weights given by the switching model's output posteriors. The proposed learning-based switching showed performance comparable to that of rule-based oracle switching. The soft-switching further improved the ASR performance and achieved a relative character error rate reduction of up to 23 % as compared with the conventional method.
Hierarchical Diffusion Models for Singing Voice Neural Vocoder
Oct 18, 2022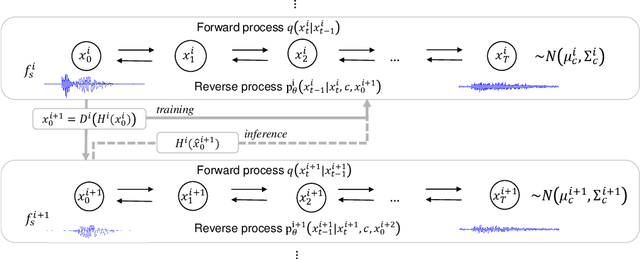
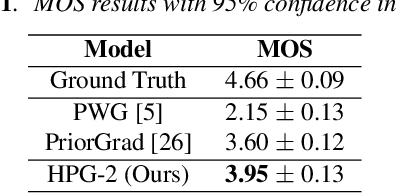
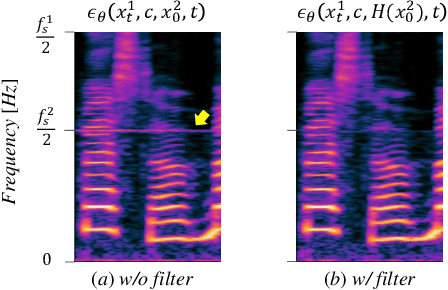
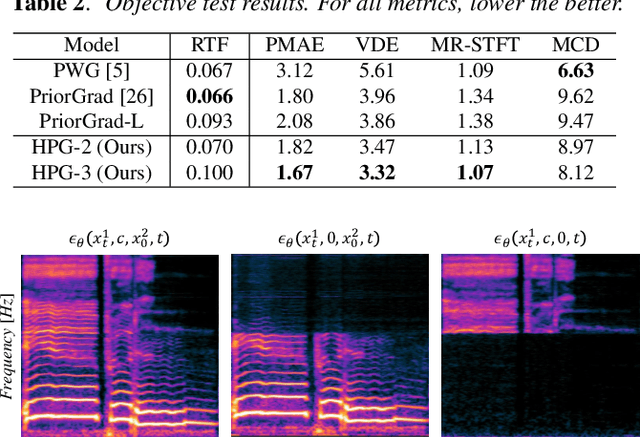
Recent progress in deep generative models has improved the quality of neural vocoders in speech domain. However, generating a high-quality singing voice remains challenging due to a wider variety of musical expressions in pitch, loudness, and pronunciations. In this work, we propose a hierarchical diffusion model for singing voice neural vocoders. The proposed method consists of multiple diffusion models operating in different sampling rates; the model at the lowest sampling rate focuses on generating accurate low-frequency components such as pitch, and other models progressively generate the waveform at higher sampling rates on the basis of the data at the lower sampling rate and acoustic features. Experimental results show that the proposed method produces high-quality singing voices for multiple singers, outperforming state-of-the-art neural vocoders with a similar range of computational costs.
Leveraging Acoustic Contextual Representation by Audio-textual Cross-modal Learning for Conversational ASR
Jul 03, 2022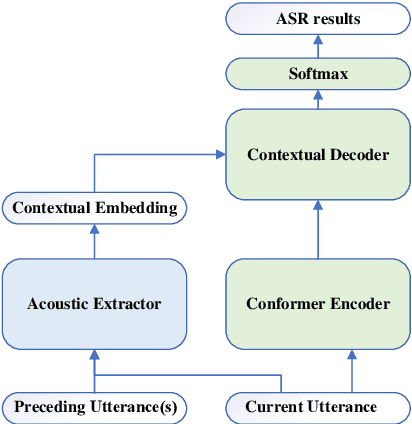
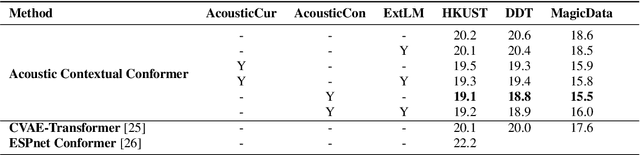
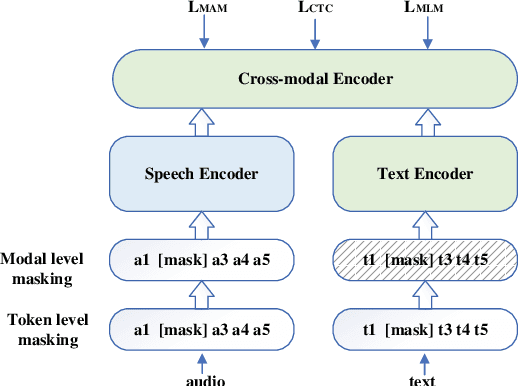

Leveraging context information is an intuitive idea to improve performance on conversational automatic speech recognition(ASR). Previous works usually adopt recognized hypotheses of historical utterances as preceding context, which may bias the current recognized hypothesis due to the inevitable historicalrecognition errors. To avoid this problem, we propose an audio-textual cross-modal representation extractor to learn contextual representations directly from preceding speech. Specifically, it consists of two modal-related encoders, extracting high-level latent features from speech and the corresponding text, and a cross-modal encoder, which aims to learn the correlation between speech and text. We randomly mask some input tokens and input sequences of each modality. Then a token-missing or modal-missing prediction with a modal-level CTC loss on the cross-modal encoder is performed. Thus, the model captures not only the bi-directional context dependencies in a specific modality but also relationships between different modalities. Then, during the training of the conversational ASR system, the extractor will be frozen to extract the textual representation of preceding speech, while such representation is used as context fed to the ASR decoder through attention mechanism. The effectiveness of the proposed approach is validated on several Mandarin conversation corpora and the highest character error rate (CER) reduction up to 16% is achieved on the MagicData dataset.
Separating Content from Speaker Identity in Speech for the Assessment of Cognitive Impairments
Mar 21, 2022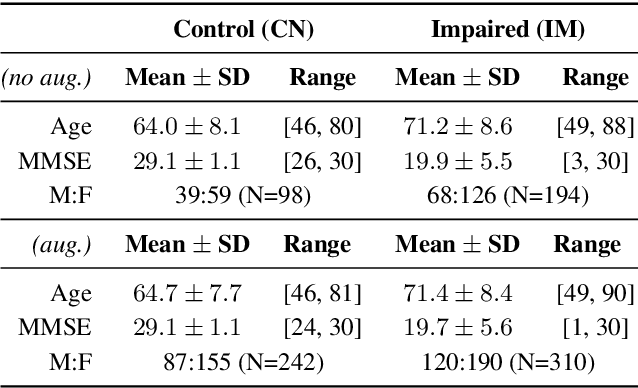
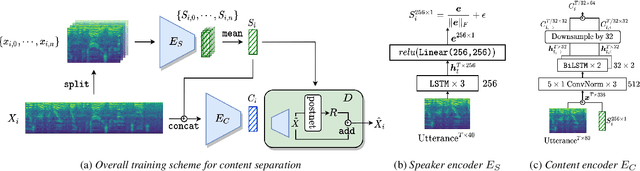
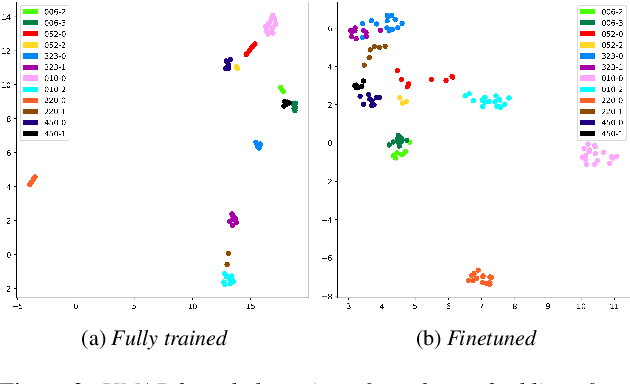
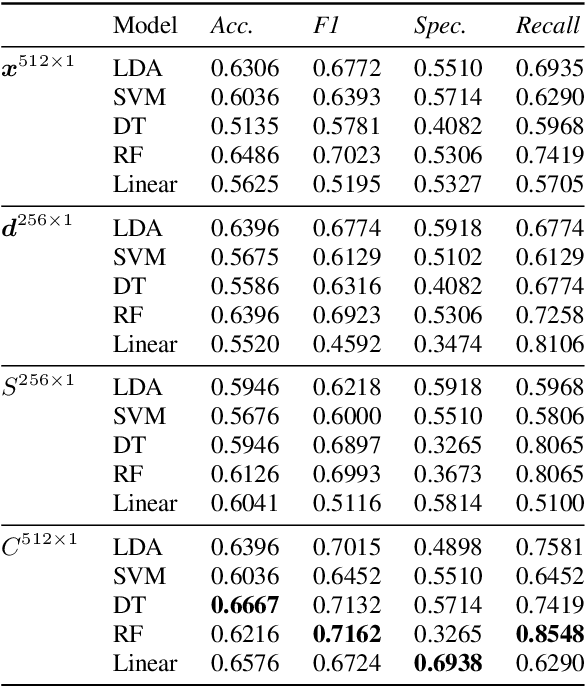
Deep speaker embeddings have been shown effective for assessing cognitive impairments aside from their original purpose of speaker verification. However, the research found that speaker embeddings encode speaker identity and an array of information, including speaker demographics, such as sex and age, and speech contents to an extent, which are known confounders in the assessment of cognitive impairments. In this paper, we hypothesize that content information separated from speaker identity using a framework for voice conversion is more effective for assessing cognitive impairments and train simple classifiers for the comparative analysis on the DementiaBank Pitt Corpus. Our results show that while content embeddings have an advantage over speaker embeddings for the defined problem, further experiments show their effectiveness depends on information encoded in speaker embeddings due to the inherent design of the architecture used for extracting contents.