 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
FST: the FAIR Speech Translation System for the IWSLT21 Multilingual Shared Task
Jul 14, 2021
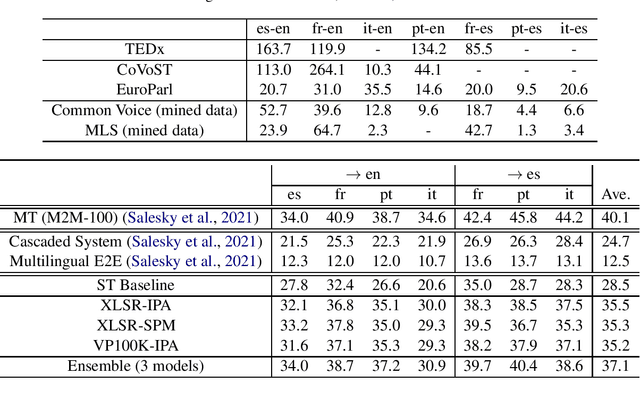
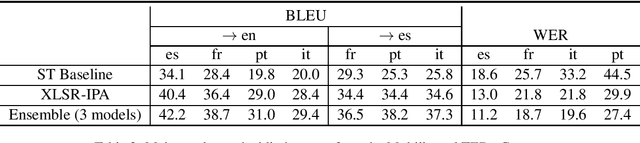
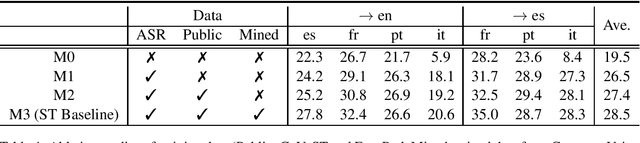
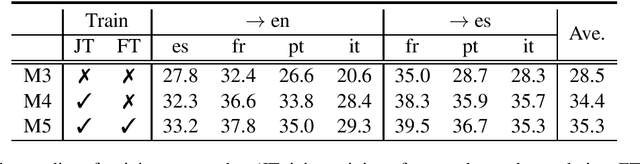
In this paper, we describe our end-to-end multilingual speech translation system submitted to the IWSLT 2021 evaluation campaign on the Multilingual Speech Translation shared task. Our system is built by leveraging transfer learning across modalities, tasks and languages. First, we leverage general-purpose multilingual modules pretrained with large amounts of unlabelled and labelled data. We further enable knowledge transfer from the text task to the speech task by training two tasks jointly. Finally, our multilingual model is finetuned on speech translation task-specific data to achieve the best translation results. Experimental results show our system outperforms the reported systems, including both end-to-end and cascaded based approaches, by a large margin. In some translation directions, our speech translation results evaluated on the public Multilingual TEDx test set are even comparable with the ones from a strong text-to-text translation system, which uses the oracle speech transcripts as input.
Improving Transformer-based Conversational ASR by Inter-Sentential Attention Mechanism
Jul 02, 2022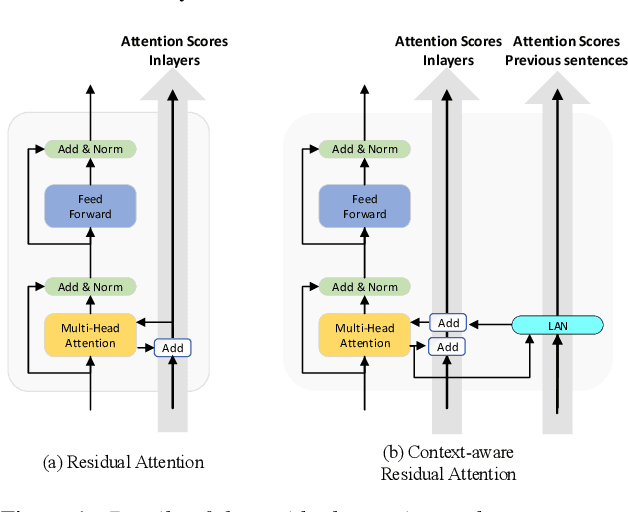
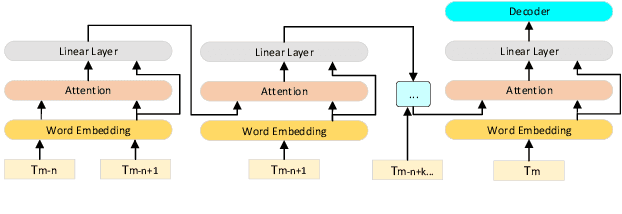

Transformer-based models have demonstrated their effectiveness in automatic speech recognition (ASR) tasks and even shown superior performance over the conventional hybrid framework. The main idea of Transformers is to capture the long-range global context within an utterance by self-attention layers. However, for scenarios like conversational speech, such utterance-level modeling will neglect contextual dependencies that span across utterances. In this paper, we propose to explicitly model the inter-sentential information in a Transformer based end-to-end architecture for conversational speech recognition. Specifically, for the encoder network, we capture the contexts of previous speech and incorporate such historic information into current input by a context-aware residual attention mechanism. For the decoder, the prediction of current utterance is also conditioned on the historic linguistic information through a conditional decoder framework. We show the effectiveness of our proposed method on several open-source dialogue corpora and the proposed method consistently improved the performance from the utterance-level Transformer-based ASR models.
Multi-modality Associative Bridging through Memory: Speech Sound Recollected from Face Video
Apr 04, 2022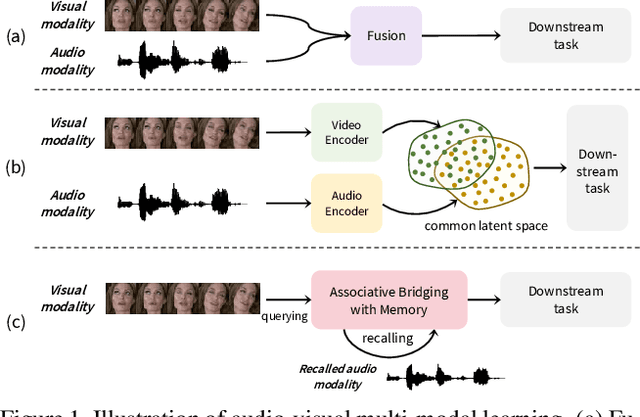
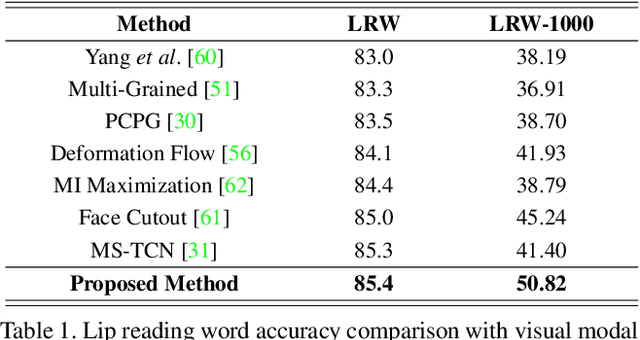
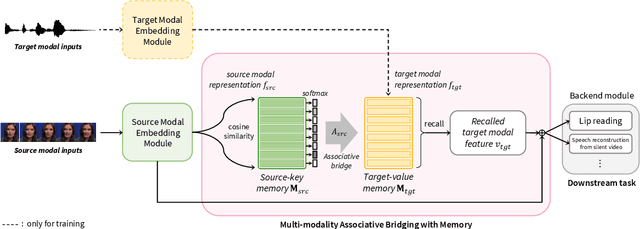
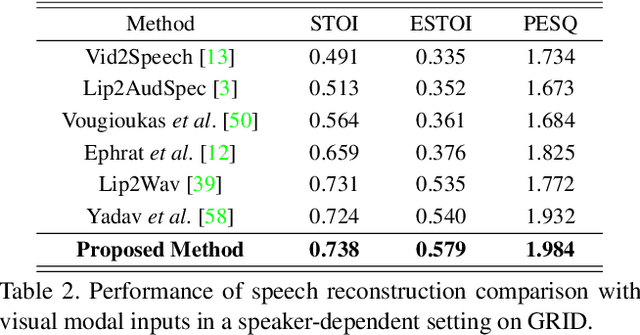
In this paper, we introduce a novel audio-visual multi-modal bridging framework that can utilize both audio and visual information, even with uni-modal inputs. We exploit a memory network that stores source (i.e., visual) and target (i.e., audio) modal representations, where source modal representation is what we are given, and target modal representations are what we want to obtain from the memory network. We then construct an associative bridge between source and target memories that considers the interrelationship between the two memories. By learning the interrelationship through the associative bridge, the proposed bridging framework is able to obtain the target modal representations inside the memory network, even with the source modal input only, and it provides rich information for its downstream tasks. We apply the proposed framework to two tasks: lip reading and speech reconstruction from silent video. Through the proposed associative bridge and modality-specific memories, each task knowledge is enriched with the recalled audio context, achieving state-of-the-art performance. We also verify that the associative bridge properly relates the source and target memories.
Deliberation Networks and How to Train Them
Nov 06, 2022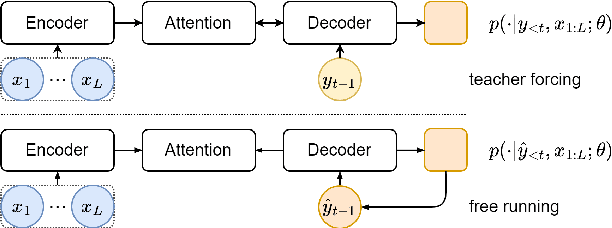
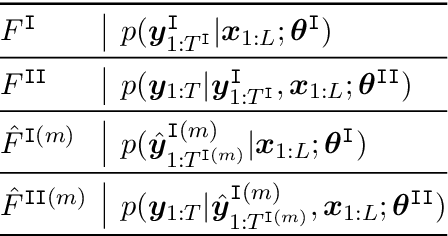
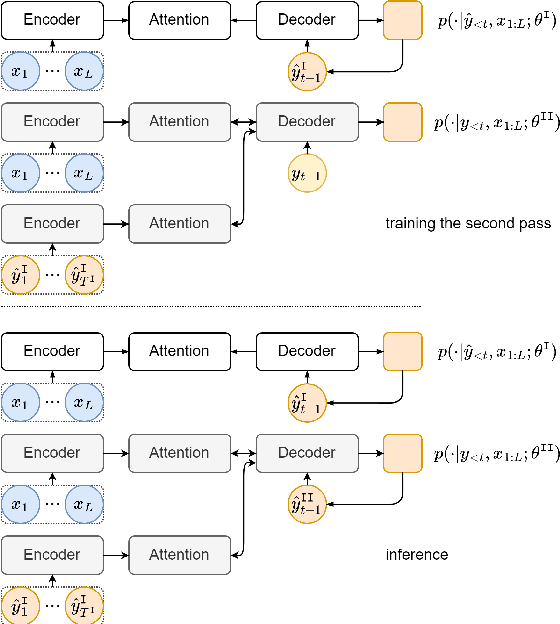
Deliberation networks are a family of sequence-to-sequence models, which have achieved state-of-the-art performance in a wide range of tasks such as machine translation and speech synthesis. A deliberation network consists of multiple standard sequence-to-sequence models, each one conditioned on the initial input and the output of the previous model. During training, there are several key questions: whether to apply Monte Carlo approximation to the gradients or the loss, whether to train the standard models jointly or separately, whether to run an intermediate model in teacher forcing or free running mode, whether to apply task-specific techniques. Previous work on deliberation networks typically explores one or two training options for a specific task. This work introduces a unifying framework, covering various training options, and addresses the above questions. In general, it is simpler to approximate the gradients. When parallel training is essential, separate training should be adopted. Regardless of the task, the intermediate model should be in free running mode. For tasks where the output is continuous, a guided attention loss can be used to prevent degradation into a standard model.
CycleGAN-based Non-parallel Speech Enhancement with an Adaptive Attention-in-attention Mechanism
Jul 28, 2021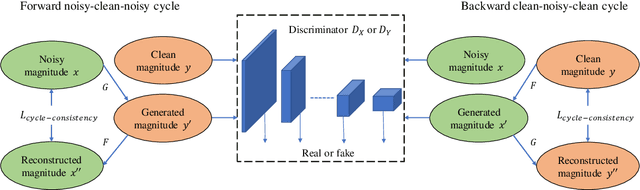
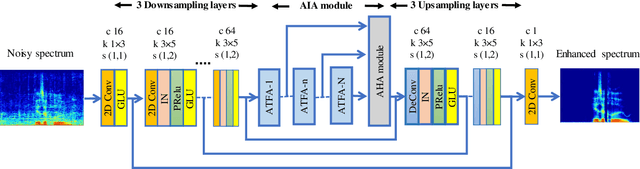
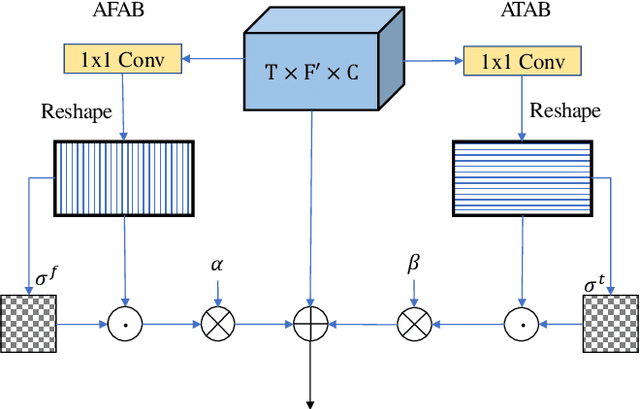
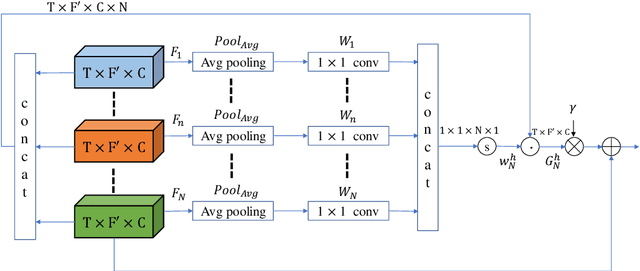
Non-parallel training is a difficult but essential task for DNN-based speech enhancement methods, for the lack of adequate noisy and paired clean speech corpus in many real scenarios. In this paper, we propose a novel adaptive attention-in-attention CycleGAN (AIA-CycleGAN) for non-parallel speech enhancement. In previous CycleGAN-based non-parallel speech enhancement methods, the limited mapping ability of the generator may cause performance degradation and insufficient feature learning. To alleviate this degradation, we propose an integration of adaptive time-frequency attention (ATFA) and adaptive hierarchical attention (AHA) to form an attention-in-attention (AIA) module for more flexible feature learning during the mapping procedure. More specifically, ATFA can capture the long-range temporal-spectral contextual information for more effective feature representations, while AHA can flexibly aggregate different intermediate feature maps by weights depending on the global context. Numerous experimental results demonstrate that the proposed approach achieves consistently more superior performance over previous GAN-based and CycleGAN-based methods in non-parallel training. Moreover, experiments in parallel training verify that the proposed AIA-CycleGAN also outperforms most advanced GAN-based speech enhancement approaches, especially in maintaining speech integrity and reducing speech distortion.
WeNet 2.0: More Productive End-to-End Speech Recognition Toolkit
Mar 29, 2022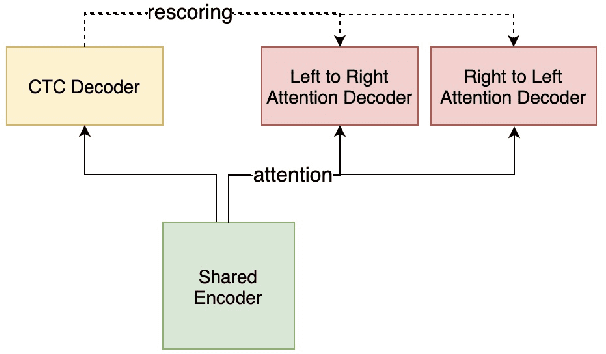


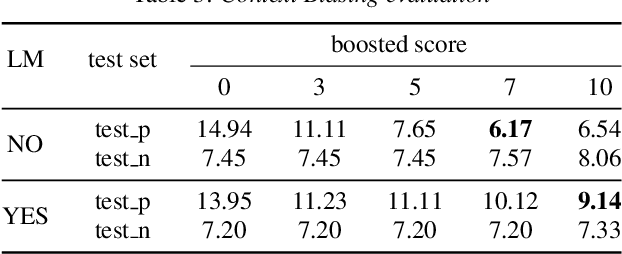
Recently, we made available WeNet, a production-oriented end-to-end speech recognition toolkit, which introduces a unified two-pass (U2) framework and a built-in runtime to address the streaming and non-streaming decoding modes in a single model. To further improve ASR performance and facilitate various production requirements, in this paper, we present WeNet 2.0 with four important updates. (1) We propose U2++, a unified two-pass framework with bidirectional attention decoders, which includes the future contextual information by a right-to-left attention decoder to improve the representative ability of the shared encoder and the performance during the rescoring stage. (2) We introduce an n-gram based language model and a WFST-based decoder into WeNet 2.0, promoting the use of rich text data in production scenarios. (3) We design a unified contextual biasing framework, which leverages user-specific context (e.g., contact lists) to provide rapid adaptation ability for production and improves ASR accuracy in both with-LM and without-LM scenarios. (4) We design a unified IO to support large-scale data for effective model training. In summary, the brand-new WeNet 2.0 achieves up to 10\% relative recognition performance improvement over the original WeNet on various corpora and makes available several important production-oriented features.
From Nano to Macro: Overview of the IEEE Bio Image and Signal Processing Technical Committee
Oct 31, 2022

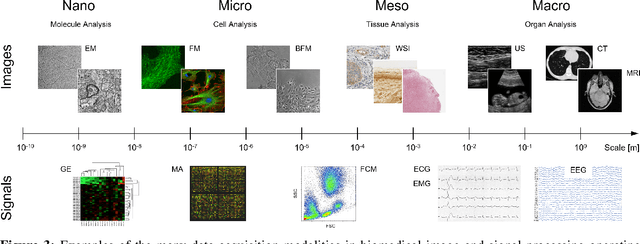
The Bio Image and Signal Processing (BISP) Technical Committee (TC) of the IEEE Signal Processing Society (SPS) promotes activities within the broad technical field of biomedical image and signal processing. Areas of interest include medical and biological imaging, digital pathology, molecular imaging, microscopy, and associated computational imaging, image analysis, and image-guided treatment, alongside physiological signal processing, computational biology, and bioinformatics. BISP has 40 members and covers a wide range of EDICS, including CIS-MI: Medical Imaging, BIO-MIA: Medical Image Analysis, BIO-BI: Biological Imaging, BIO: Biomedical Signal Processing, BIO-BCI: Brain/Human-Computer Interfaces, and BIO-INFR: Bioinformatics. BISP plays a central role in the organization of the IEEE International Symposium on Biomedical Imaging (ISBI) and contributes to the technical sessions at the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), and the IEEE International Conference on Image Processing (ICIP). In this paper, we provide a brief history of the TC, review the technological and methodological contributions its community delivered, and highlight promising new directions we anticipate.
Fast and parallel decoding for transducer
Oct 31, 2022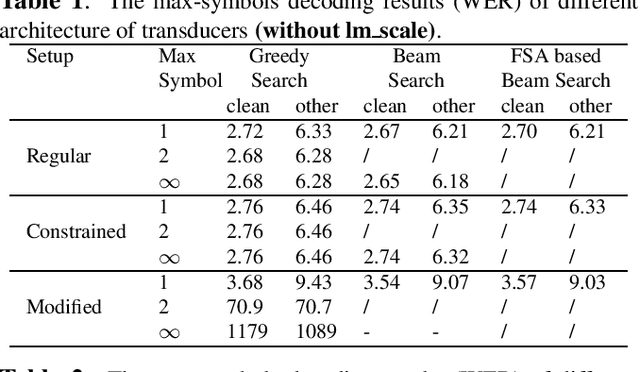
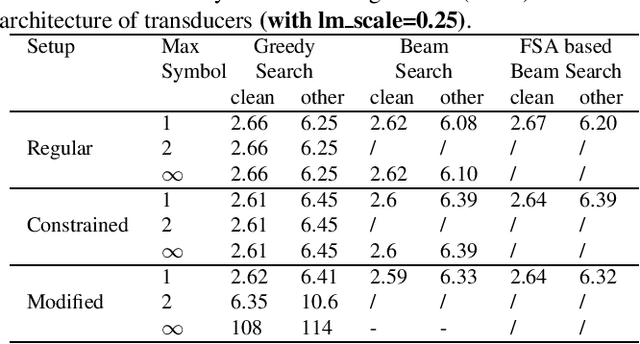
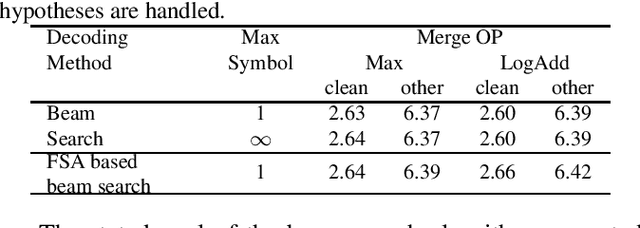
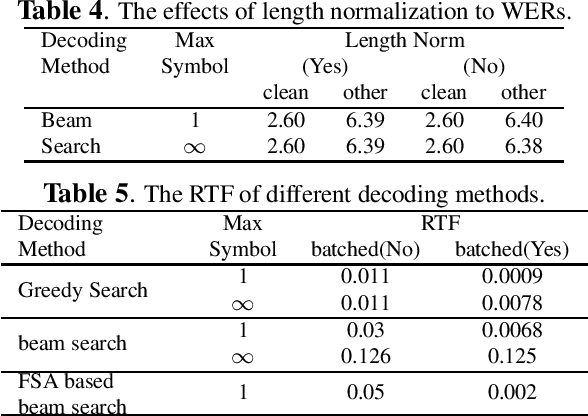
The transducer architecture is becoming increasingly popular in the field of speech recognition, because it is naturally streaming as well as high in accuracy. One of the drawbacks of transducer is that it is difficult to decode in a fast and parallel way due to an unconstrained number of symbols that can be emitted per time step. In this work, we introduce a constrained version of transducer loss to learn strictly monotonic alignments between the sequences; we also improve the standard greedy search and beam search algorithms by limiting the number of symbols that can be emitted per time step in transducer decoding, making it more efficient to decode in parallel with batches. Furthermore, we propose an finite state automaton-based (FSA) parallel beam search algorithm that can run with graphs on GPU efficiently. The experiment results show that we achieve slight word error rate (WER) improvement as well as significant speedup in decoding. Our work is open-sourced and publicly available\footnote{https://github.com/k2-fsa/icefall}.
Magnitude or Phase? A Two Stage Algorithm for Dereverberation
Oct 31, 2022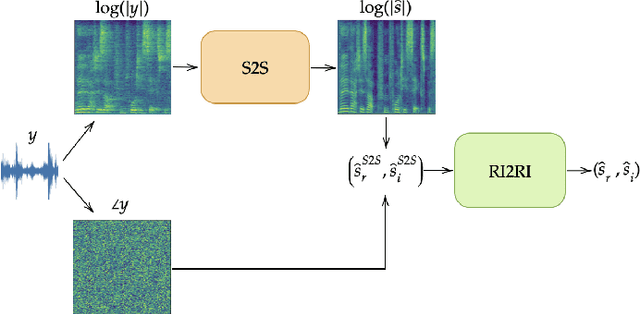
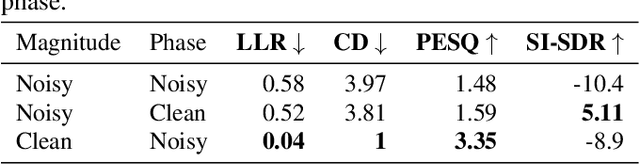
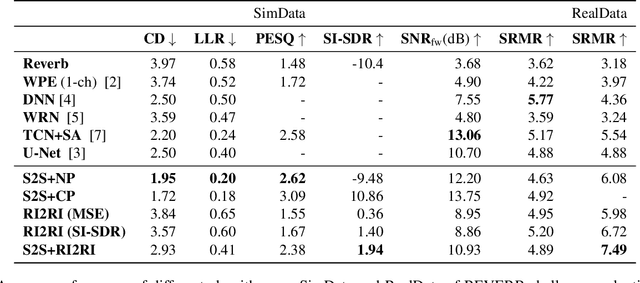
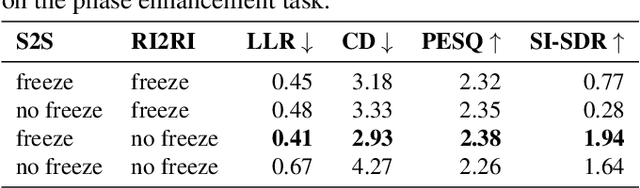
In this work we present a new single-microphone speech dereverberation algorithm. First, a performance analysis is presented to interpret that algorithms focused on improving solely magnitude or phase are not good enough. Furthermore, we demonstrate that few objective measurements have high correlation with the clean magnitude while others with the clean phase. Consequently ,we propose a new architecture which consists of two sub-models, each of which is responsible for a different task. The first model estimates the clean magnitude given the noisy input. The enhanced magnitude together with the noisy-input phase are then used as inputs to the second model to estimate the real and imaginary portions of the dereverberated signal. A training scheme including pre-training and fine-tuning is presented in the paper. We evaluate our proposed approach using data from the REVERB challenge and compare our results to other methods. We demonstrate consistent improvements in all measures, which can be attributed to the improved estimates of both the magnitude and the phase.
Deep Learning For Prominence Detection In Children's Read Speech
Oct 27, 2021
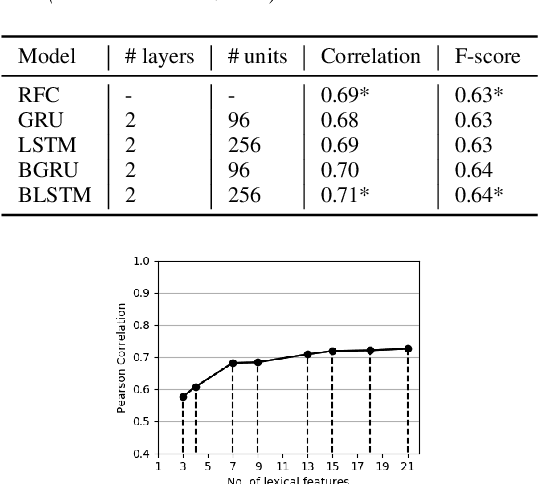
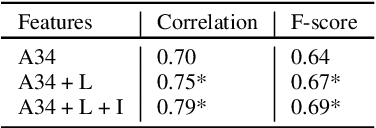
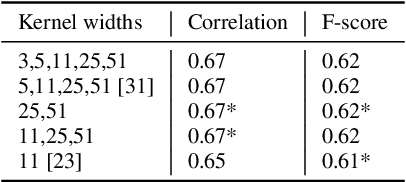
The detection of perceived prominence in speech has attracted approaches ranging from the design of linguistic knowledge-based acoustic features to the automatic feature learning from suprasegmental attributes such as pitch and intensity contours. We present here, in contrast, a system that operates directly on segmented speech waveforms to learn features relevant to prominent word detection for children's oral fluency assessment. The chosen CRNN (convolutional recurrent neural network) framework, incorporating both word-level features and sequence information, is found to benefit from the perceptually motivated SincNet filters as the first convolutional layer. We further explore the benefits of the linguistic association between the prosodic events of phrase boundary and prominence with different multi-task architectures. Matching the previously reported performance on the same dataset of a random forest ensemble predictor trained on carefully chosen hand-crafted acoustic features, we evaluate further the possibly complementary information from hand-crafted acoustic and pre-trained lexical features.