 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Expressive, Variable, and Controllable Duration Modelling in TTS
Jun 28, 2022
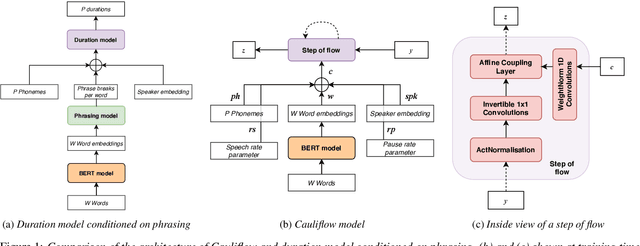
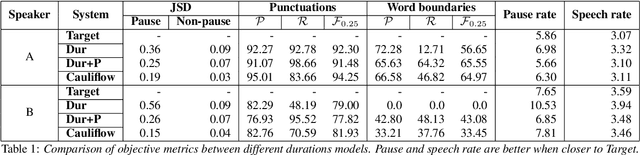
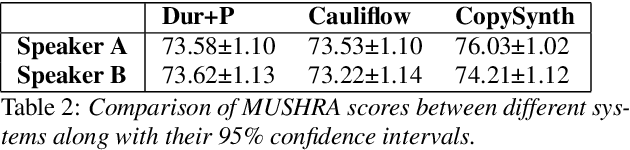
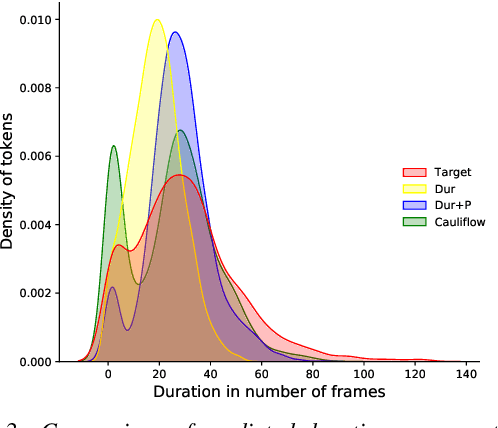
Duration modelling has become an important research problem once more with the rise of non-attention neural text-to-speech systems. The current approaches largely fall back to relying on previous statistical parametric speech synthesis technology for duration prediction, which poorly models the expressiveness and variability in speech. In this paper, we propose two alternate approaches to improve duration modelling. First, we propose a duration model conditioned on phrasing that improves the predicted durations and provides better modelling of pauses. We show that the duration model conditioned on phrasing improves the naturalness of speech over our baseline duration model. Second, we also propose a multi-speaker duration model called Cauliflow, that uses normalising flows to predict durations that better match the complex target duration distribution. Cauliflow performs on par with our other proposed duration model in terms of naturalness, whilst providing variable durations for the same prompt and variable levels of expressiveness. Lastly, we propose to condition Cauliflow on parameters that provide an intuitive control of the pacing and pausing in the synthesised speech in a novel way.
Speech enhancement with weakly labelled data from AudioSet
Feb 19, 2021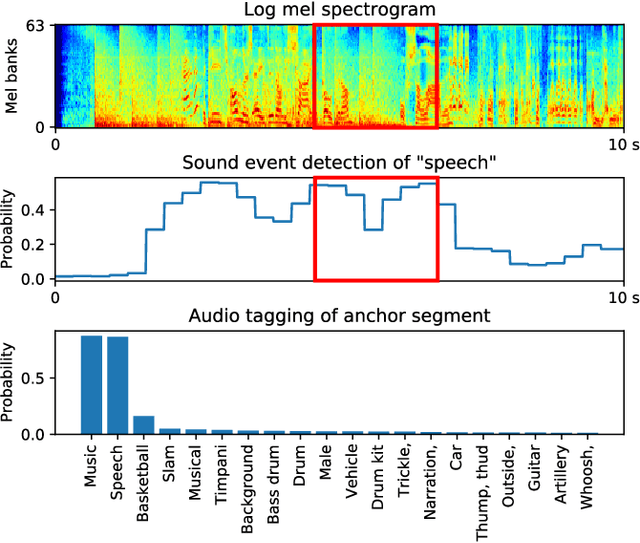
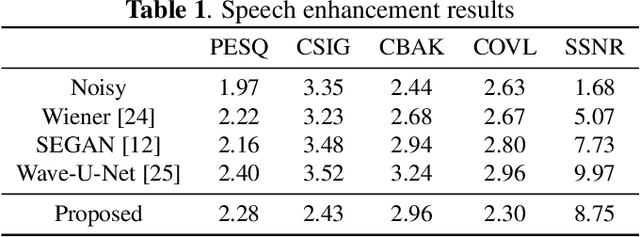
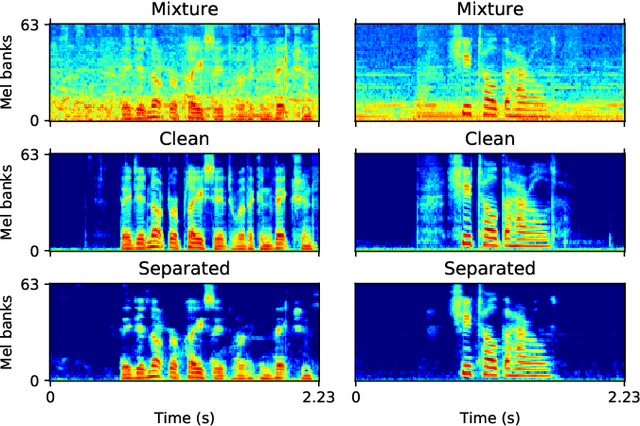
Speech enhancement is a task to improve the intelligibility and perceptual quality of degraded speech signal. Recently, neural networks based methods have been applied to speech enhancement. However, many neural network based methods require noisy and clean speech pairs for training. We propose a speech enhancement framework that can be trained with large-scale weakly labelled AudioSet dataset. Weakly labelled data only contain audio tags of audio clips, but not the onset or offset times of speech. We first apply pretrained audio neural networks (PANNs) to detect anchor segments that contain speech or sound events in audio clips. Then, we randomly mix two detected anchor segments containing speech and sound events as a mixture, and build a conditional source separation network using PANNs predictions as soft conditions for speech enhancement. In inference, we input a noisy speech signal with the one-hot encoding of "Speech" as a condition to the trained system to predict enhanced speech. Our system achieves a PESQ of 2.28 and an SSNR of 8.75 dB on the VoiceBank-DEMAND dataset, outperforming the previous SEGAN system of 2.16 and 7.73 dB respectively.
More Speaking or More Speakers?
Nov 02, 2022
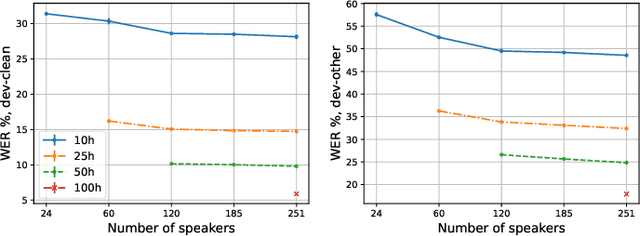
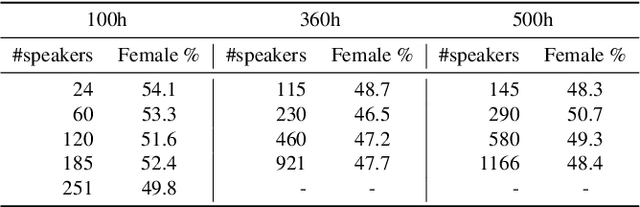
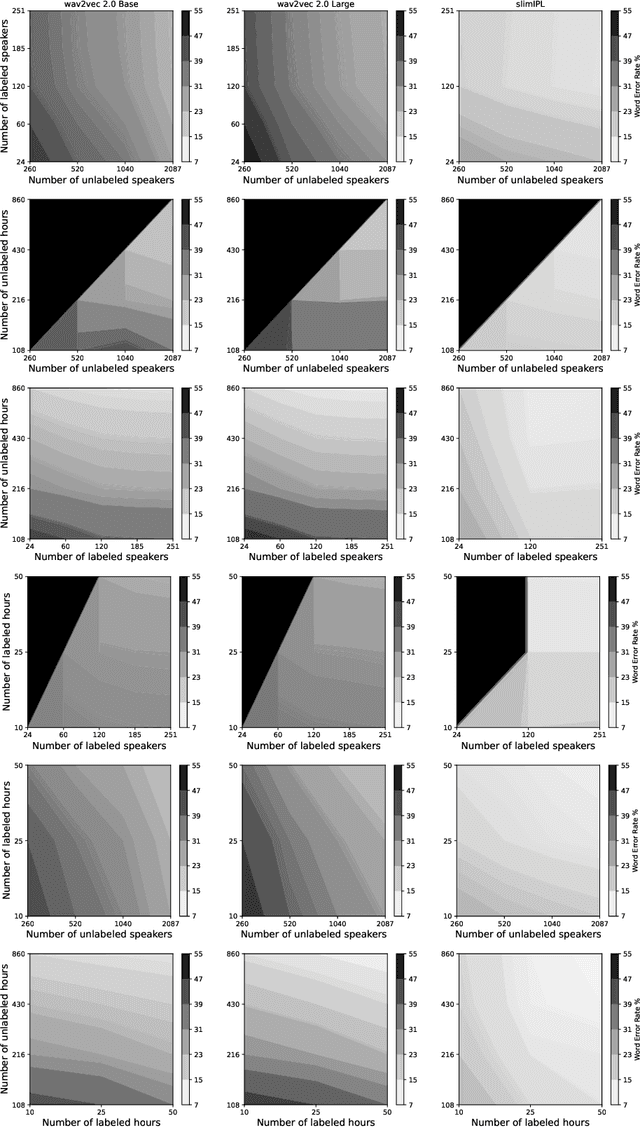
Self-training (ST) and self-supervised learning (SSL) methods have demonstrated strong improvements in automatic speech recognition (ASR). In spite of these advances, to the best of our knowledge, there is no analysis of how the composition of the labelled and unlabelled datasets used in these methods affects the results. In this work we aim to analyse the effect of numbers of speakers in the training data on a recent SSL algorithm (wav2vec 2.0), and a recent ST algorithm (slimIPL). We perform a systematic analysis on both labeled and unlabeled data by varying the number of speakers while keeping the number of hours fixed and vice versa. Our findings suggest that SSL requires a large amount of unlabeled data to produce high accuracy results, while ST requires a sufficient number of speakers in the labelled data, especially in the low-regime setting. In this manner these two approaches improve supervised learning in different regimes of dataset composition.
Yunshan Cup 2020: Overview of the Part-of-Speech Tagging Task for Low-resourced Languages
Apr 06, 2022
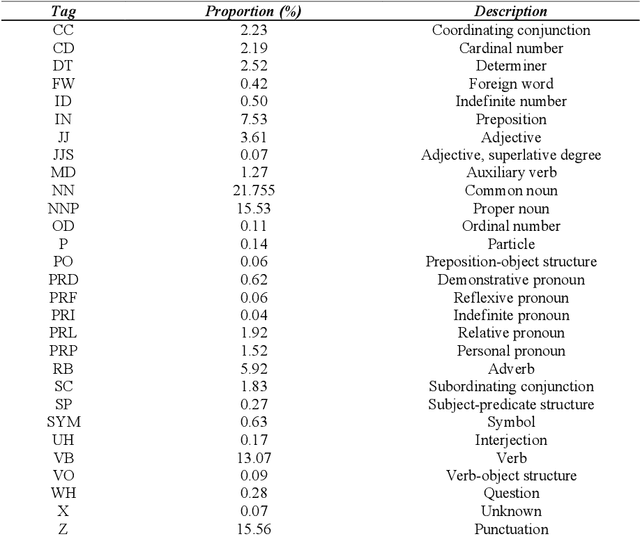
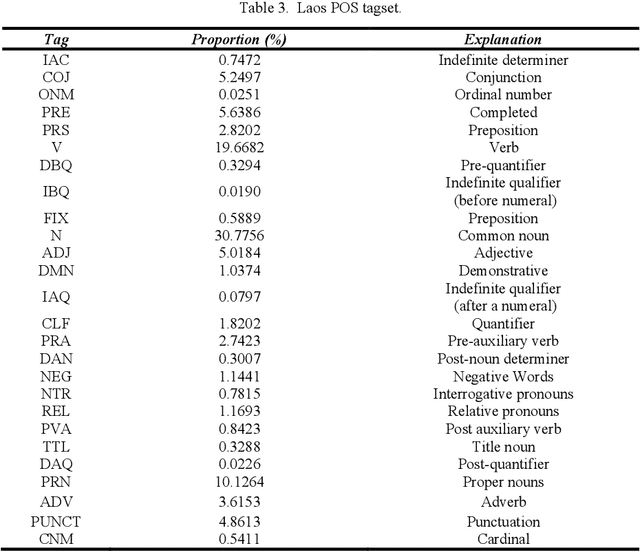
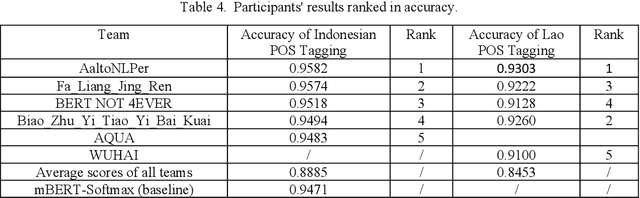
The Yunshan Cup 2020 track focused on creating a framework for evaluating different methods of part-of-speech (POS). There were two tasks for this track: (1) POS tagging for the Indonesian language, and (2) POS tagging for the Lao tagging. The Indonesian dataset is comprised of 10000 sentences from Indonesian news within 29 tags. And the Lao dataset consists of 8000 sentences within 27 tags. 25 teams registered for the task. The methods of participants ranged from feature-based to neural networks using either classical machine learning techniques or ensemble methods. The best performing results achieve an accuracy of 95.82% for Indonesian and 93.03%, showing that neural sequence labeling models significantly outperform classic feature-based methods and rule-based methods.
Overview of the HASOC Subtrack at FIRE 2022: Offensive Language Identification in Marathi
Nov 18, 2022
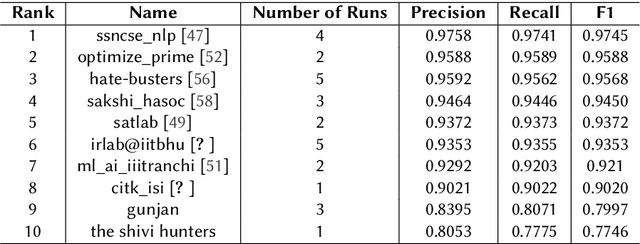


The widespread of offensive content online has become a reason for great concern in recent years, motivating researchers to develop robust systems capable of identifying such content automatically. With the goal of carrying out a fair evaluation of these systems, several international competitions have been organized, providing the community with important benchmark data and evaluation methods for various languages. Organized since 2019, the HASOC (Hate Speech and Offensive Content Identification) shared task is one of these initiatives. In its fourth iteration, HASOC 2022 included three subtracks for English, Hindi, and Marathi. In this paper, we report the results of the HASOC 2022 Marathi subtrack which provided participants with a dataset containing data from Twitter manually annotated using the popular OLID taxonomy. The Marathi track featured three additional subtracks, each corresponding to one level of the taxonomy: Task A - offensive content identification (offensive vs. non-offensive); Task B - categorization of offensive types (targeted vs. untargeted), and Task C - offensive target identification (individual vs. group vs. others). Overall, 59 runs were submitted by 10 teams. The best systems obtained an F1 of 0.9745 for Subtrack 3A, an F1 of 0.9207 for Subtrack 3B, and F1 of 0.9607 for Subtrack 3C. The best performing algorithms were a mixture of traditional and deep learning approaches.
Neural Predictor for Black-Box Adversarial Attacks on Speech Recognition
Mar 18, 2022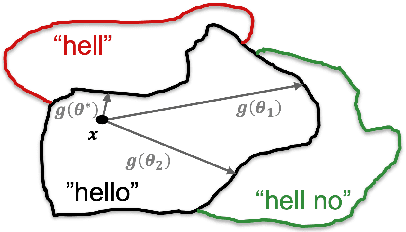

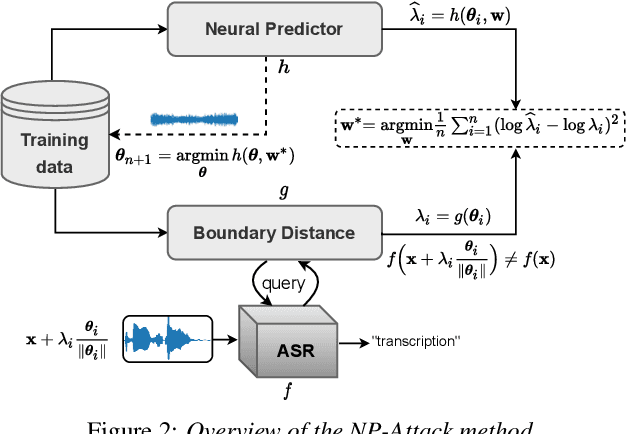
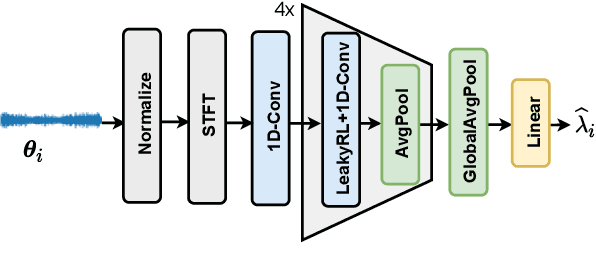
Recent works have revealed the vulnerability of automatic speech recognition (ASR) models to adversarial examples (AEs), i.e., small perturbations that cause an error in the transcription of the audio signal. Studying audio adversarial attacks is therefore the first step towards robust ASR. Despite the significant progress made in attacking audio examples, the black-box attack remains challenging because only the hard-label information of transcriptions is provided. Due to this limited information, existing black-box methods often require an excessive number of queries to attack a single audio example. In this paper, we introduce NP-Attack, a neural predictor-based method, which progressively evolves the search towards a small adversarial perturbation. Given a perturbation direction, our neural predictor directly estimates the smallest perturbation that causes a mistranscription. In particular, it enables NP-Attack to accurately learn promising perturbation directions via gradient-based optimization. Experimental results show that NP-Attack achieves competitive results with other state-of-the-art black-box adversarial attacks while requiring a significantly smaller number of queries. The code of NP-Attack is available online.
Protecting gender and identity with disentangled speech representations
Apr 22, 2021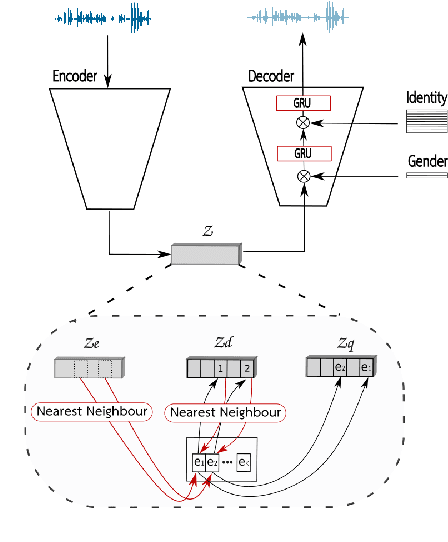
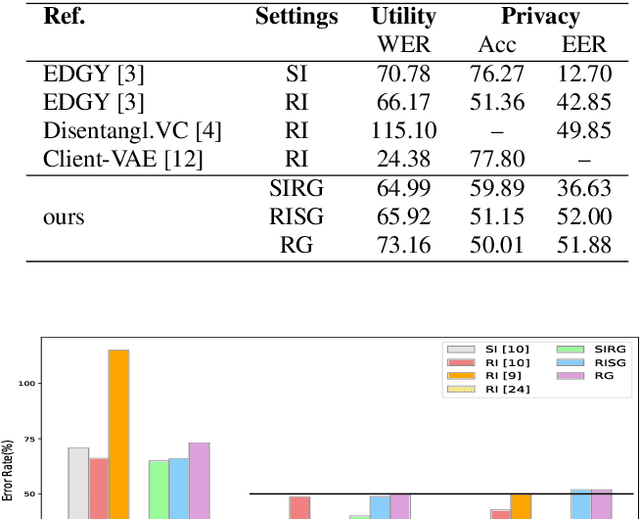
Besides its linguistic content, our speech is rich in biometric information that can be inferred by classifiers. Learning privacy-preserving representations for speech signals enables downstream tasks without sharing unnecessary, private information about an individual. In this paper, we show that protecting gender information in speech is more effective than modelling speaker-identity information only when generating a non-sensitive representation of speech. Our method relies on reconstructing speech by decoding linguistic content along with gender information using a variational autoencoder. Specifically, we exploit disentangled representation learning to encode information about different attributes into separate subspaces that can be factorised independently. We present a novel way to encode gender information and disentangle two sensitive biometric identifiers, namely gender and identity, in a privacy-protecting setting. Experiments on the LibriSpeech dataset show that gender recognition and speaker verification can be reduced to a random guess, protecting against classification-based attacks, while maintaining the utility of the signal for speech recognition.
Parkinsonian Chinese Speech Analysis towards Automatic Classification of Parkinson's Disease
May 31, 2021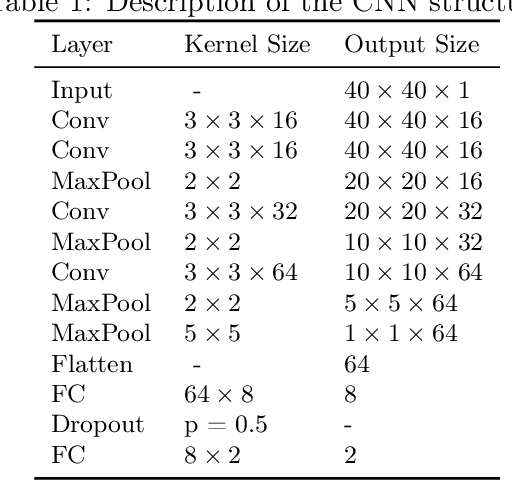
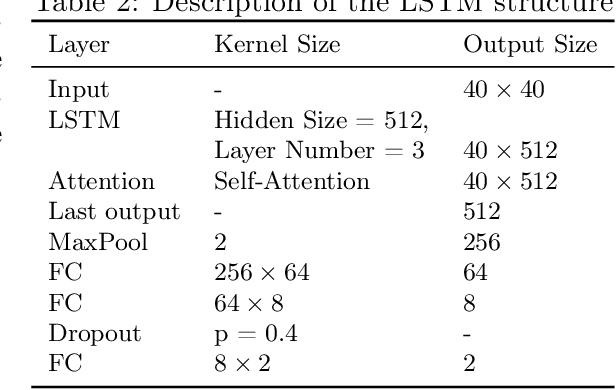

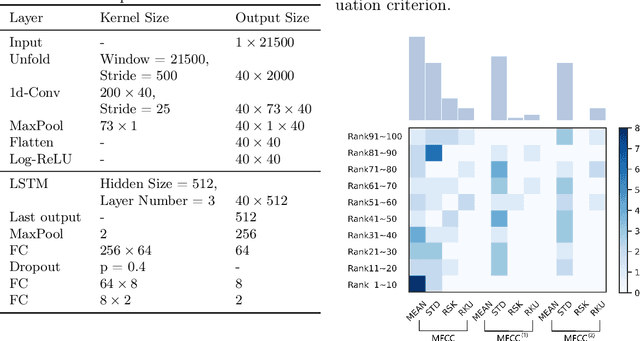
Speech disorders often occur at the early stage of Parkinson's disease (PD). The speech impairments could be indicators of the disorder for early diagnosis, while motor symptoms are not obvious. In this study, we constructed a new speech corpus of Mandarin Chinese and addressed classification of patients with PD. We implemented classical machine learning methods with ranking algorithms for feature selection, convolutional and recurrent deep networks, and an end to end system. Our classification accuracy significantly surpassed state-of-the-art studies. The result suggests that free talk has stronger classification power than standard speech tasks, which could help the design of future speech tasks for efficient early diagnosis of the disease. Based on existing classification methods and our natural speech study, the automatic detection of PD from daily conversation could be accessible to the majority of the clinical population.
Wav-BERT: Cooperative Acoustic and Linguistic Representation Learning for Low-Resource Speech Recognition
Sep 19, 2021
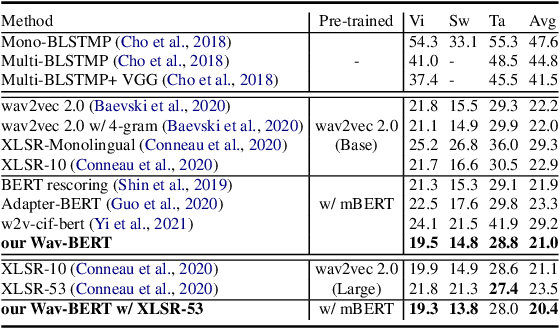
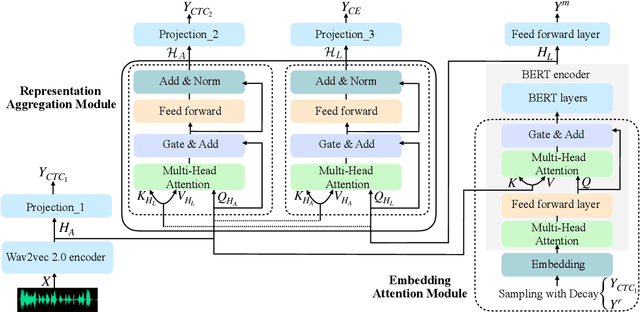
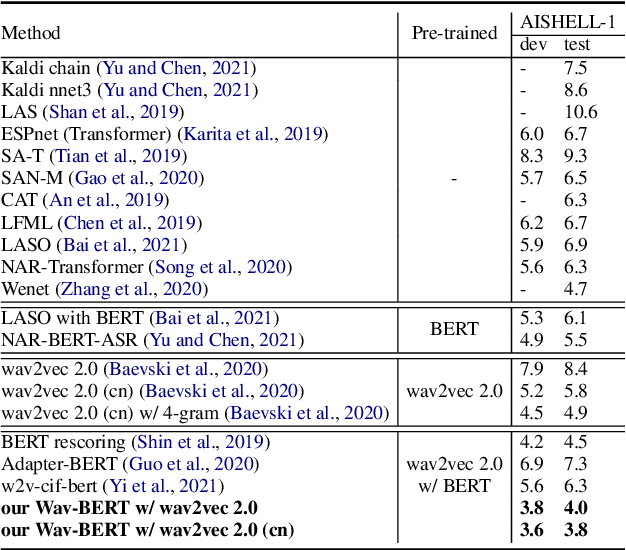
Unifying acoustic and linguistic representation learning has become increasingly crucial to transfer the knowledge learned on the abundance of high-resource language data for low-resource speech recognition. Existing approaches simply cascade pre-trained acoustic and language models to learn the transfer from speech to text. However, how to solve the representation discrepancy of speech and text is unexplored, which hinders the utilization of acoustic and linguistic information. Moreover, previous works simply replace the embedding layer of the pre-trained language model with the acoustic features, which may cause the catastrophic forgetting problem. In this work, we introduce Wav-BERT, a cooperative acoustic and linguistic representation learning method to fuse and utilize the contextual information of speech and text. Specifically, we unify a pre-trained acoustic model (wav2vec 2.0) and a language model (BERT) into an end-to-end trainable framework. A Representation Aggregation Module is designed to aggregate acoustic and linguistic representation, and an Embedding Attention Module is introduced to incorporate acoustic information into BERT, which can effectively facilitate the cooperation of two pre-trained models and thus boost the representation learning. Extensive experiments show that our Wav-BERT significantly outperforms the existing approaches and achieves state-of-the-art performance on low-resource speech recognition.
Jointly Predicting Emotion, Age, and Country Using Pre-Trained Acoustic Embedding
Jul 21, 2022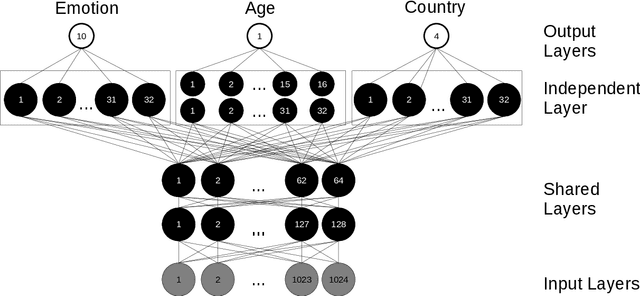
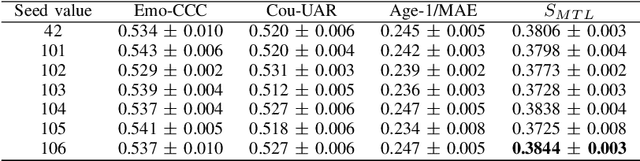

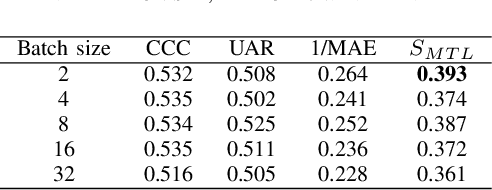
In this paper, we demonstrated the benefit of using pre-trained model to extract acoustic embedding to jointly predict (multitask learning) three tasks: emotion, age, and native country. The pre-trained model was trained with wav2vec 2.0 large robust model on the speech emotion corpus. The emotion and age tasks were regression problems, while country prediction was a classification task. A single harmonic mean from three metrics was used to evaluate the performance of multitask learning. The classifier was a linear network with two independent layers and shared layers, including the output layers. This study explores multitask learning on different acoustic features (including the acoustic embedding extracted from a model trained on an affective speech dataset), seed numbers, batch sizes, and normalizations for predicting paralinguistic information from speech.