 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Adapting Speech Separation to Real-World Meetings Using Mixture Invariant Training
Oct 20, 2021
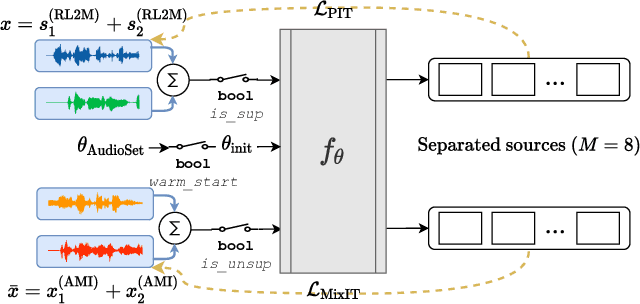
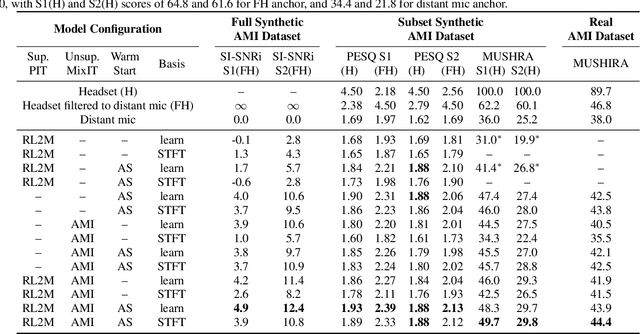
The recently-proposed mixture invariant training (MixIT) is an unsupervised method for training single-channel sound separation models in the sense that it does not require ground-truth isolated reference sources. In this paper, we investigate using MixIT to adapt a separation model on real far-field overlapping reverberant and noisy speech data from the AMI Corpus. The models are tested on real AMI recordings containing overlapping speech, and are evaluated subjectively by human listeners. To objectively evaluate our models, we also devise a synthetic AMI test set. For human evaluations on real recordings, we also propose a modification of the standard MUSHRA protocol to handle imperfect reference signals, which we call MUSHIRA. Holding network architectures constant, we find that a fine-tuned semi-supervised model yields the largest SI-SNR improvement, PESQ scores, and human listening ratings across synthetic and real datasets, outperforming unadapted generalist models trained on orders of magnitude more data. Our results show that unsupervised learning through MixIT enables model adaptation on real-world unlabeled spontaneous speech recordings.
Preserving background sound in noise-robust voice conversion via multi-task learning
Nov 06, 2022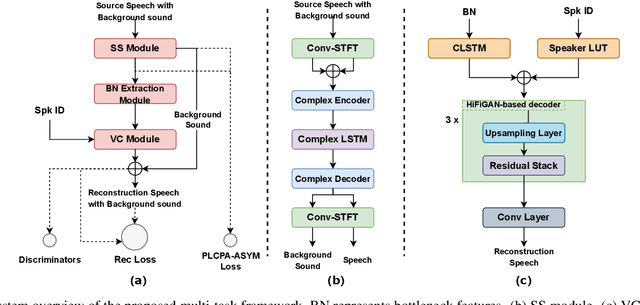
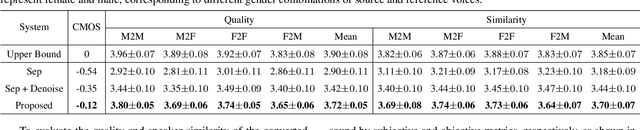
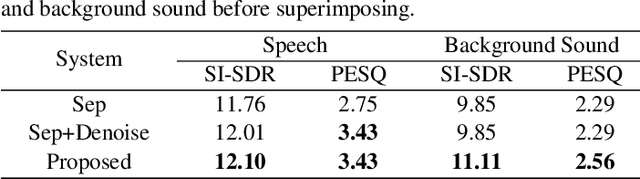
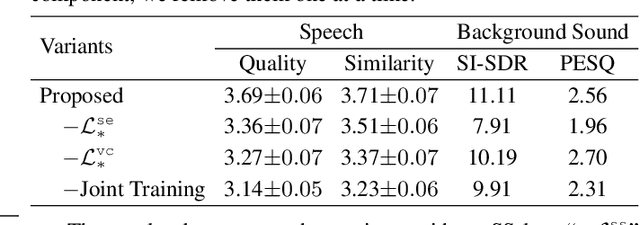
Background sound is an informative form of art that is helpful in providing a more immersive experience in real-application voice conversion (VC) scenarios. However, prior research about VC, mainly focusing on clean voices, pay rare attention to VC with background sound. The critical problem for preserving background sound in VC is inevitable speech distortion by the neural separation model and the cascade mismatch between the source separation model and the VC model. In this paper, we propose an end-to-end framework via multi-task learning which sequentially cascades a source separation (SS) module, a bottleneck feature extraction module and a VC module. Specifically, the source separation task explicitly considers critical phase information and confines the distortion caused by the imperfect separation process. The source separation task, the typical VC task and the unified task shares a uniform reconstruction loss constrained by joint training to reduce the mismatch between the SS and VC modules. Experimental results demonstrate that our proposed framework significantly outperforms the baseline systems while achieving comparable quality and speaker similarity to the VC models trained with clean data.
REAL-M: Towards Speech Separation on Real Mixtures
Oct 20, 2021
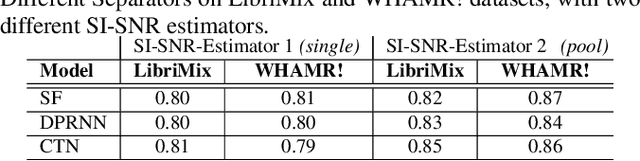
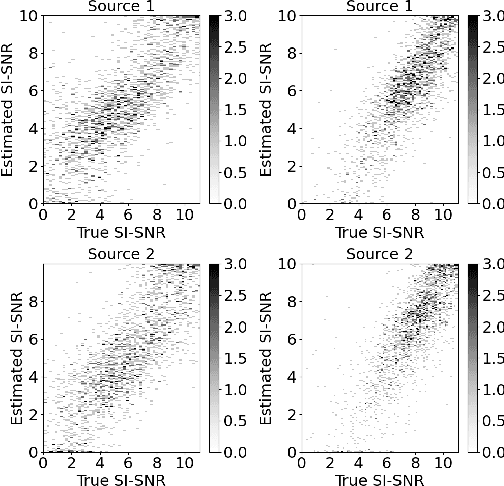
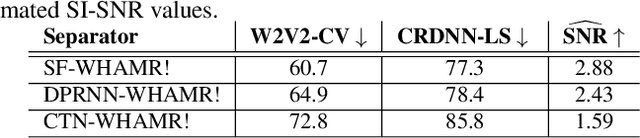
In recent years, deep learning based source separation has achieved impressive results. Most studies, however, still evaluate separation models on synthetic datasets, while the performance of state-of-the-art techniques on in-the-wild speech data remains an open question. This paper contributes to fill this gap in two ways. First, we release the REAL-M dataset, a crowd-sourced corpus of real-life mixtures. Secondly, we address the problem of performance evaluation of real-life mixtures, where the ground truth is not available. We bypass this issue by carefully designing a blind Scale-Invariant Signal-to-Noise Ratio (SI-SNR) neural estimator. Through a user study, we show that our estimator reliably evaluates the separation performance on real mixtures. The performance predictions of the SI-SNR estimator indeed correlate well with human opinions. Moreover, we observe that the performance trends predicted by our estimator on the REAL-M dataset closely follow those achieved on synthetic benchmarks when evaluating popular speech separation models.
End-to-End Voice Conversion with Information Perturbation
Jun 15, 2022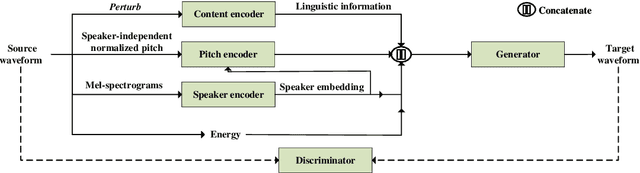
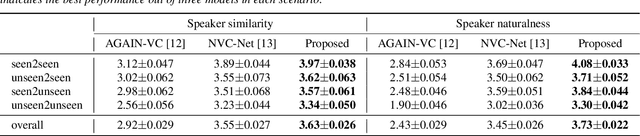
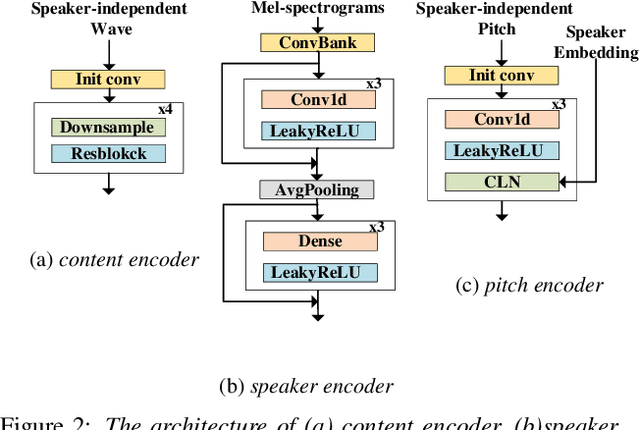
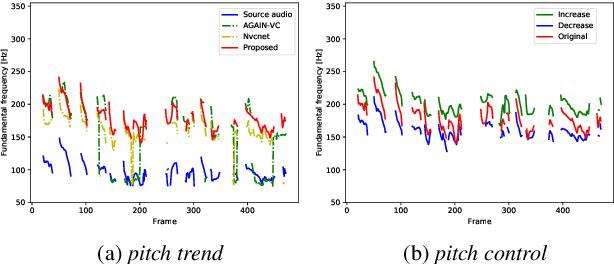
The ideal goal of voice conversion is to convert the source speaker's speech to sound naturally like the target speaker while maintaining the linguistic content and the prosody of the source speech. However, current approaches are insufficient to achieve comprehensive source prosody transfer and target speaker timbre preservation in the converted speech, and the quality of the converted speech is also unsatisfied due to the mismatch between the acoustic model and the vocoder. In this paper, we leverage the recent advances in information perturbation and propose a fully end-to-end approach to conduct high-quality voice conversion. We first adopt information perturbation to remove speaker-related information in the source speech to disentangle speaker timbre and linguistic content and thus the linguistic information is subsequently modeled by a content encoder. To better transfer the prosody of the source speech to the target, we particularly introduce a speaker-related pitch encoder which can maintain the general pitch pattern of the source speaker while flexibly modifying the pitch intensity of the generated speech. Finally, one-shot voice conversion is set up through continuous speaker space modeling. Experimental results indicate that the proposed end-to-end approach significantly outperforms the state-of-the-art models in terms of intelligibility, naturalness, and speaker similarity.
Expressive, Variable, and Controllable Duration Modelling in TTS
Jun 28, 2022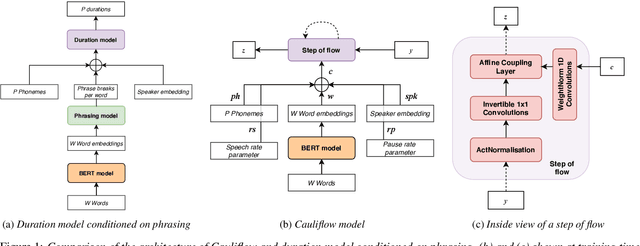
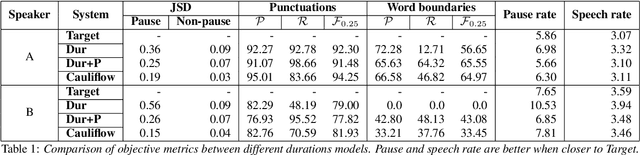
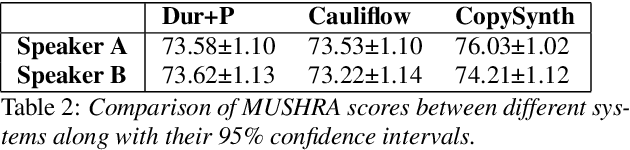
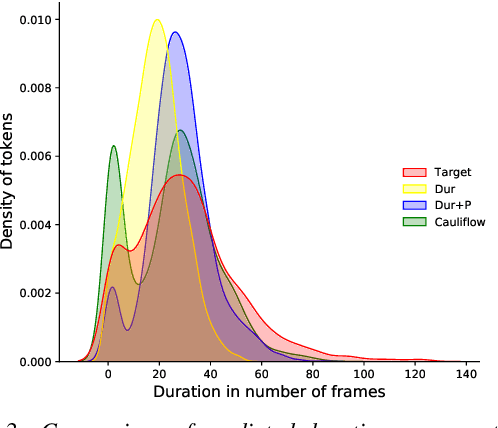
Duration modelling has become an important research problem once more with the rise of non-attention neural text-to-speech systems. The current approaches largely fall back to relying on previous statistical parametric speech synthesis technology for duration prediction, which poorly models the expressiveness and variability in speech. In this paper, we propose two alternate approaches to improve duration modelling. First, we propose a duration model conditioned on phrasing that improves the predicted durations and provides better modelling of pauses. We show that the duration model conditioned on phrasing improves the naturalness of speech over our baseline duration model. Second, we also propose a multi-speaker duration model called Cauliflow, that uses normalising flows to predict durations that better match the complex target duration distribution. Cauliflow performs on par with our other proposed duration model in terms of naturalness, whilst providing variable durations for the same prompt and variable levels of expressiveness. Lastly, we propose to condition Cauliflow on parameters that provide an intuitive control of the pacing and pausing in the synthesised speech in a novel way.
Modular Hybrid Autoregressive Transducer
Oct 31, 2022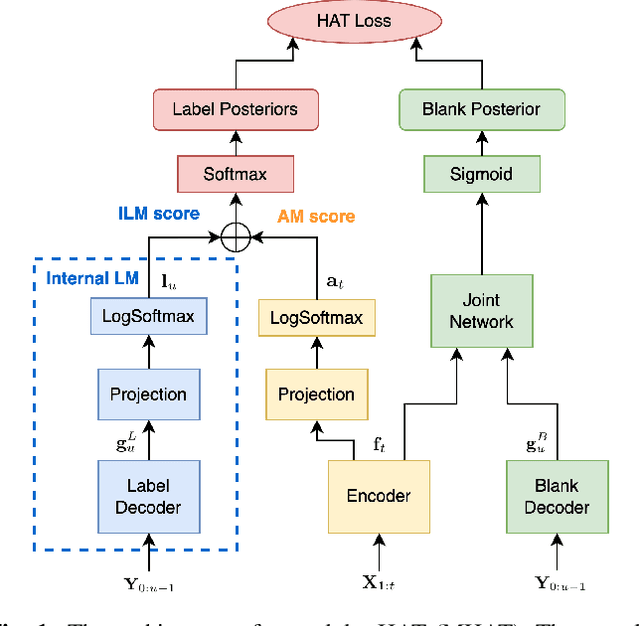
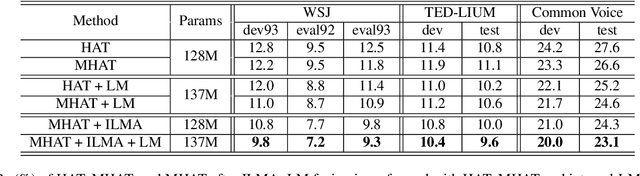
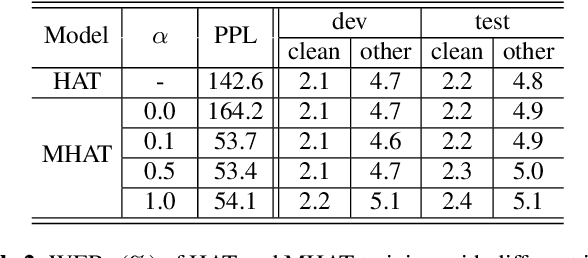
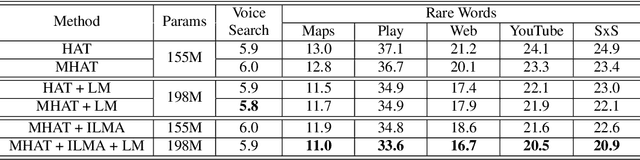
Text-only adaptation of a transducer model remains challenging for end-to-end speech recognition since the transducer has no clearly separated acoustic model (AM), language model (LM) or blank model. In this work, we propose a modular hybrid autoregressive transducer (MHAT) that has structurally separated label and blank decoders to predict label and blank distributions, respectively, along with a shared acoustic encoder. The encoder and label decoder outputs are directly projected to AM and internal LM scores and then added to compute label posteriors. We train MHAT with an internal LM loss and a HAT loss to ensure that its internal LM becomes a standalone neural LM that can be effectively adapted to text. Moreover, text adaptation of MHAT fosters a much better LM fusion than internal LM subtraction-based methods. On Google's large-scale production data, a multi-domain MHAT adapted with 100B sentences achieves relative WER reductions of up to 12.4% without LM fusion and 21.5% with LM fusion from 400K-hour trained HAT.
* 8 pages, 1 figure, SLT 2022
Improving Pseudo-label Training For End-to-end Speech Recognition Using Gradient Mask
Oct 08, 2021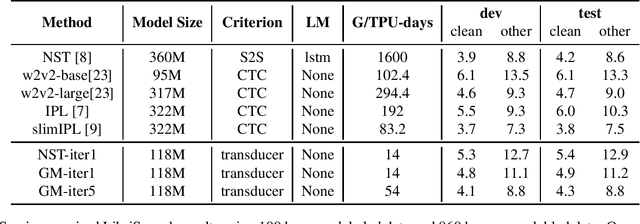
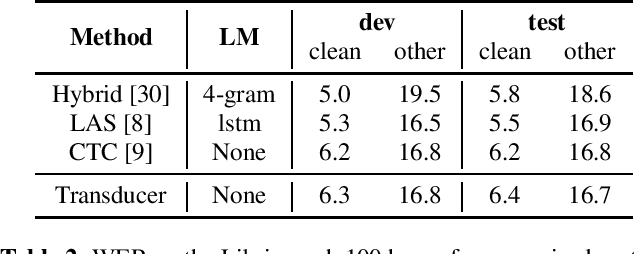
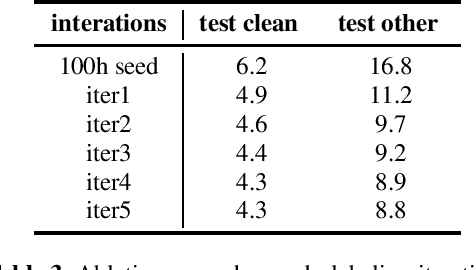
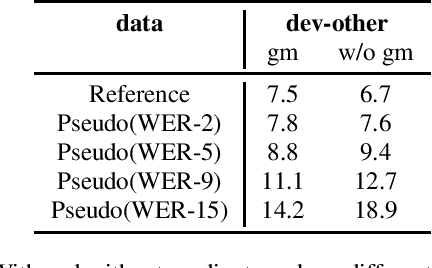
In the recent trend of semi-supervised speech recognition, both self-supervised representation learning and pseudo-labeling have shown promising results. In this paper, we propose a novel approach to combine their ideas for end-to-end speech recognition model. Without any extra loss function, we utilize the Gradient Mask to optimize the model when training on pseudo-label. This method forces the speech recognition model to predict from the masked input to learn strong acoustic representation and make training robust to label noise. In our semi-supervised experiments, the method can improve the model performance when training on pseudo-label and our method achieved competitive results comparing with other semi-supervised approaches on the Librispeech 100 hours experiments.
AVASpeech-SMAD: A Strongly Labelled Speech and Music Activity Detection Dataset with Label Co-Occurrence
Nov 02, 2021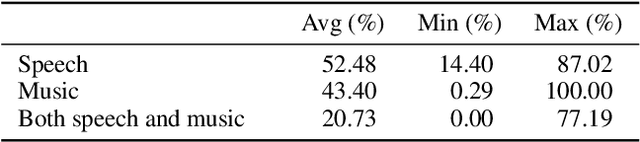
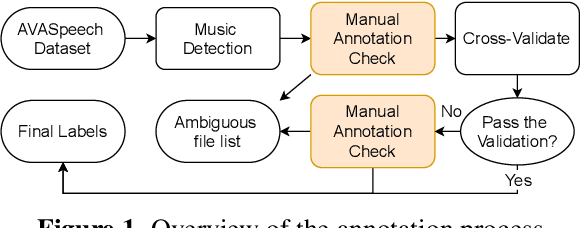

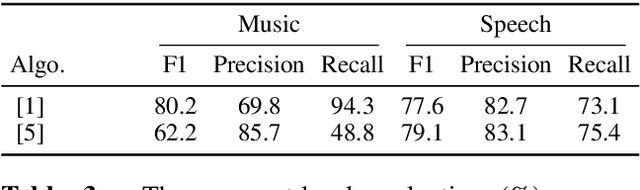
We propose a dataset, AVASpeech-SMAD, to assist speech and music activity detection research. With frame-level music labels, the proposed dataset extends the existing AVASpeech dataset, which originally consists of 45 hours of audio and speech activity labels. To the best of our knowledge, the proposed AVASpeech-SMAD is the first open-source dataset that features strong polyphonic labels for both music and speech. The dataset was manually annotated and verified via an iterative cross-checking process. A simple automatic examination was also implemented to further improve the quality of the labels. Evaluation results from two state-of-the-art SMAD systems are also provided as a benchmark for future reference.
Jointly Predicting Emotion, Age, and Country Using Pre-Trained Acoustic Embedding
Jul 21, 2022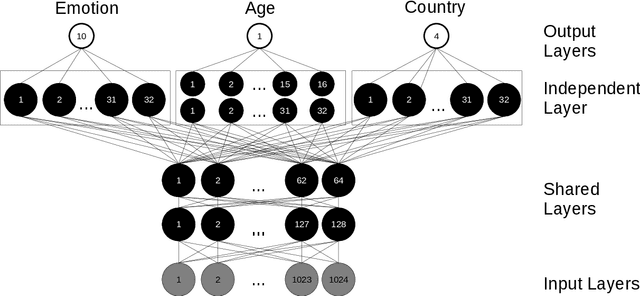
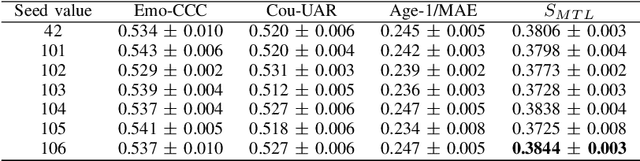

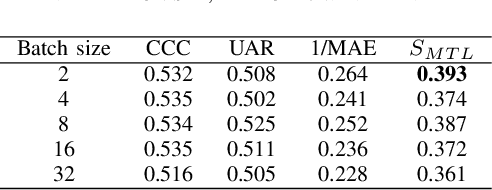
In this paper, we demonstrated the benefit of using pre-trained model to extract acoustic embedding to jointly predict (multitask learning) three tasks: emotion, age, and native country. The pre-trained model was trained with wav2vec 2.0 large robust model on the speech emotion corpus. The emotion and age tasks were regression problems, while country prediction was a classification task. A single harmonic mean from three metrics was used to evaluate the performance of multitask learning. The classifier was a linear network with two independent layers and shared layers, including the output layers. This study explores multitask learning on different acoustic features (including the acoustic embedding extracted from a model trained on an affective speech dataset), seed numbers, batch sizes, and normalizations for predicting paralinguistic information from speech.
Exploiting Pre-Trained ASR Models for Alzheimer's Disease Recognition Through Spontaneous Speech
Oct 04, 2021
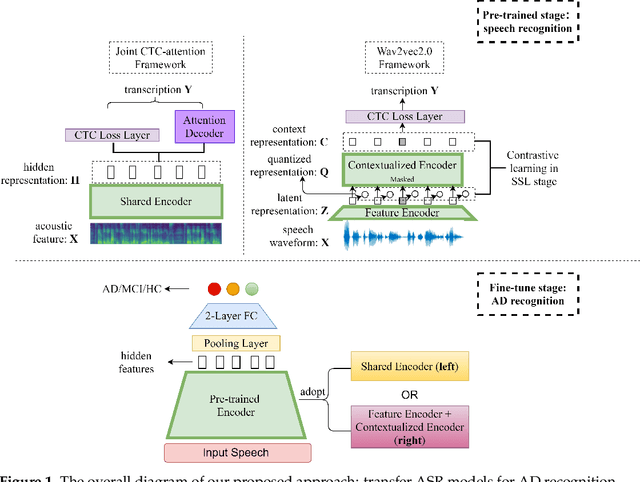
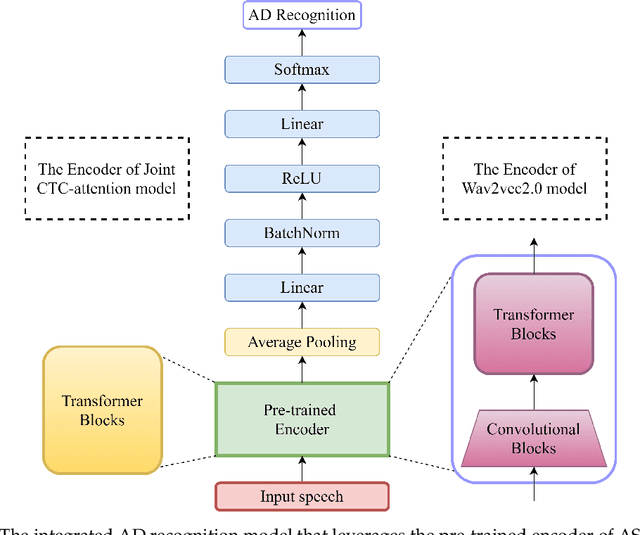
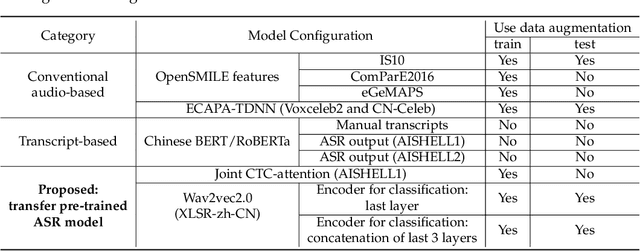
Alzheimer's disease (AD) is a progressive neurodegenerative disease and recently attracts extensive attention worldwide. Speech technology is considered a promising solution for the early diagnosis of AD and has been enthusiastically studied. Most recent works concentrate on the use of advanced BERT-like classifiers for AD detection. Input to these classifiers are speech transcripts produced by automatic speech recognition (ASR) models. The major challenge is that the quality of transcription could degrade significantly under complex acoustic conditions in the real world. The detection performance, in consequence, is largely limited. This paper tackles the problem via tailoring and adapting pre-trained neural-network based ASR model for the downstream AD recognition task. Only bottom layers of the ASR model are retained. A simple fully-connected neural network is added on top of the tailored ASR model for classification. The heavy BERT classifier is discarded. The resulting model is light-weight and can be fine-tuned in an end-to-end manner for AD recognition. Our proposed approach takes only raw speech as input, and no extra transcription process is required. The linguistic information of speech is implicitly encoded in the tailored ASR model and contributes to boosting the performance. Experiments show that our proposed approach outperforms the best manual transcript-based RoBERTa by an absolute margin of 4.6% in terms of accuracy. Our best-performing models achieve the accuracy of 83.2% and 78.0% in the long-audio and short-audio competition tracks of the 2021 NCMMSC Alzheimer's Disease Recognition Challenge, respectively.