 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Glow-WaveGAN: Learning Speech Representations from GAN-based Variational Auto-Encoder For High Fidelity Flow-based Speech Synthesis
Jun 21, 2021

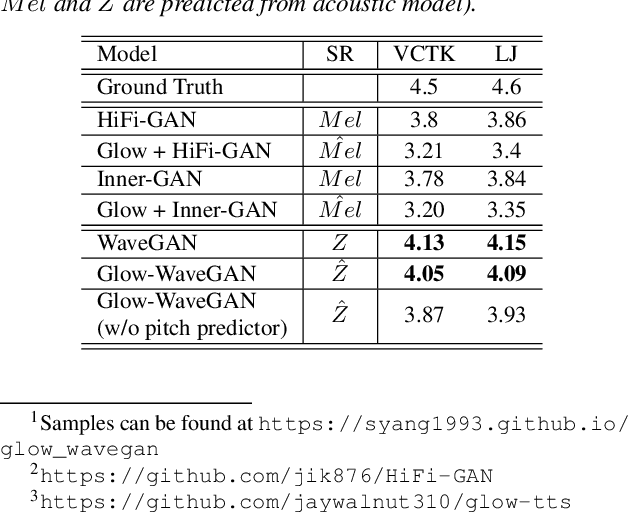
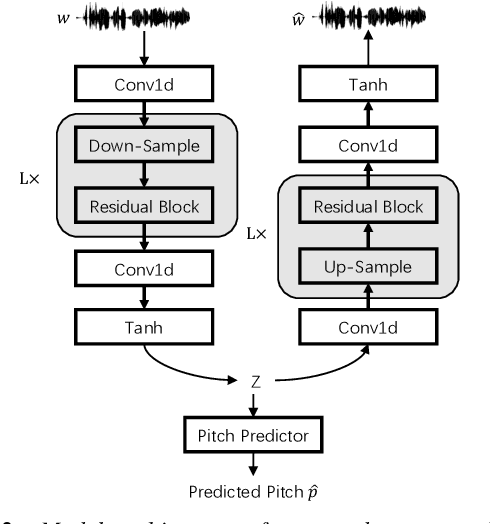
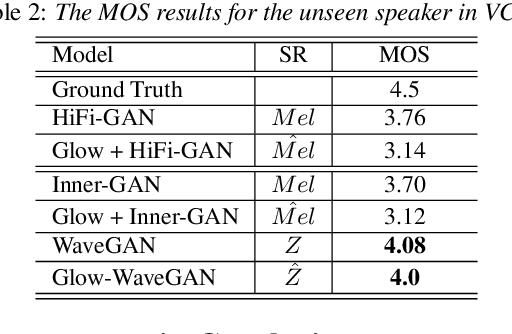
Current two-stage TTS framework typically integrates an acoustic model with a vocoder -- the acoustic model predicts a low resolution intermediate representation such as Mel-spectrum while the vocoder generates waveform from the intermediate representation. Although the intermediate representation is served as a bridge, there still exists critical mismatch between the acoustic model and the vocoder as they are commonly separately learned and work on different distributions of representation, leading to inevitable artifacts in the synthesized speech. In this work, different from using pre-designed intermediate representation in most previous studies, we propose to use VAE combining with GAN to learn a latent representation directly from speech and then utilize a flow-based acoustic model to model the distribution of the latent representation from text. In this way, the mismatch problem is migrated as the two stages work on the same distribution. Results demonstrate that the flow-based acoustic model can exactly model the distribution of our learned speech representation and the proposed TTS framework, namely Glow-WaveGAN, can produce high fidelity speech outperforming the state-of-the-art GAN-based model.
MeWEHV: Mel and Wave Embeddings for Human Voice Tasks
Sep 28, 2022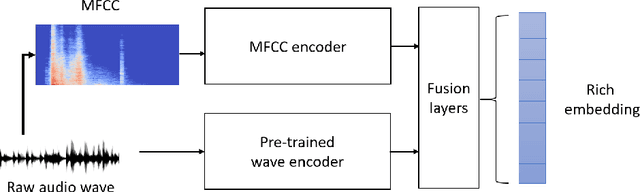
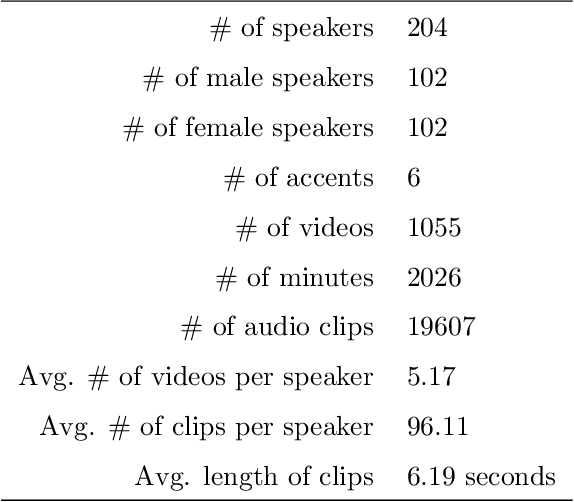
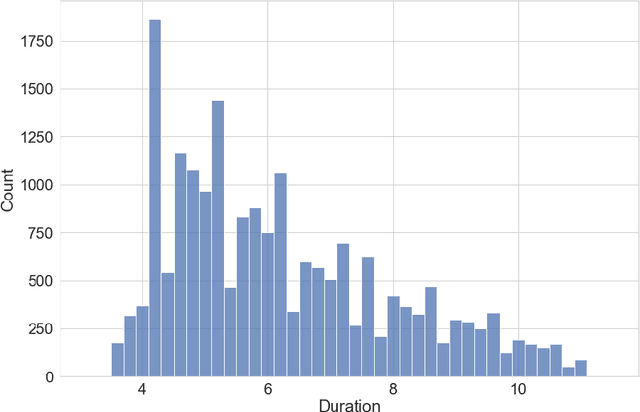
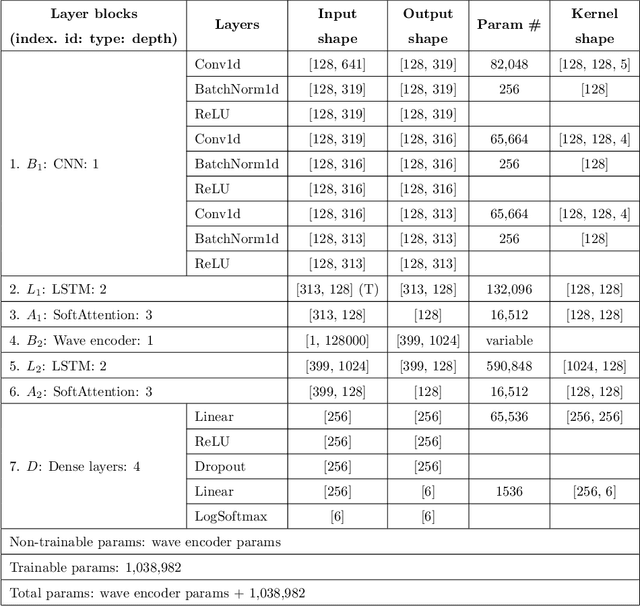
A recent trend in speech processing is the use of embeddings created through machine learning models trained on a specific task with large datasets. By leveraging the knowledge already acquired, these models can be reused in new tasks where the amount of available data is small. This paper proposes a pipeline to create a new model, called Mel and Wave Embeddings for Human Voice Tasks (MeWEHV), capable of generating robust embeddings for speech processing. MeWEHV combines the embeddings generated by a pre-trained raw audio waveform encoder model, and deep features extracted from Mel Frequency Cepstral Coefficients (MFCCs) using Convolutional Neural Networks (CNNs). We evaluate the performance of MeWEHV on three tasks: speaker, language, and accent identification. For the first one, we use the VoxCeleb1 dataset and present YouSpeakers204, a new and publicly available dataset for English speaker identification that contains 19607 audio clips from 204 persons speaking in six different accents, allowing other researchers to work with a very balanced dataset, and to create new models that are robust to multiple accents. For evaluating the language identification task, we use the VoxForge and Common Language datasets. Finally, for accent identification, we use the Latin American Spanish Corpora (LASC) and Common Voice datasets. Our approach allows a significant increase in the performance of state-of-the-art models on all the tested datasets, with a low additional computational cost.
DBT-Net: Dual-branch federative magnitude and phase estimation with attention-in-attention transformer for monaural speech enhancement
Feb 16, 2022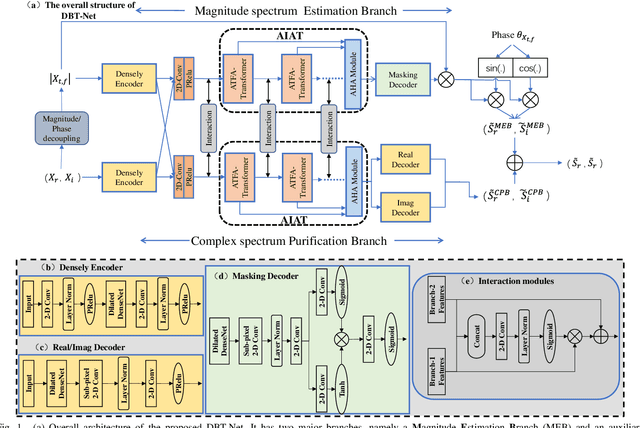
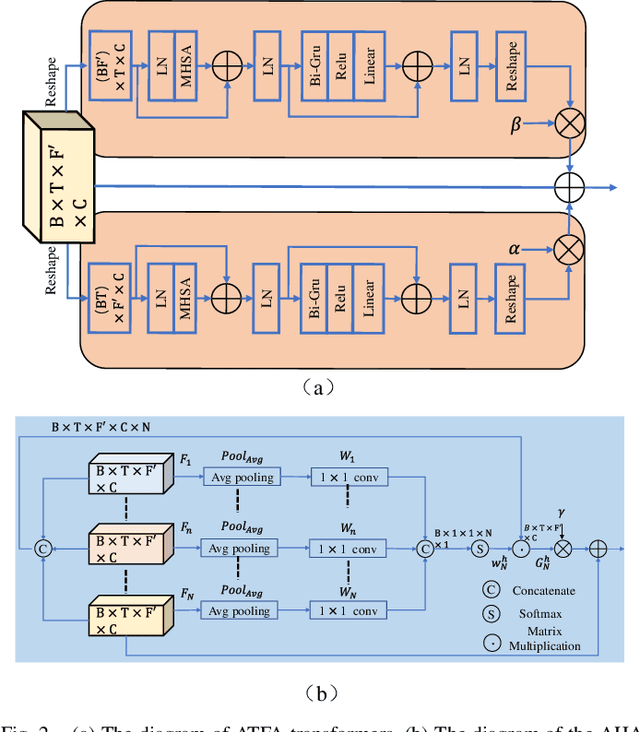
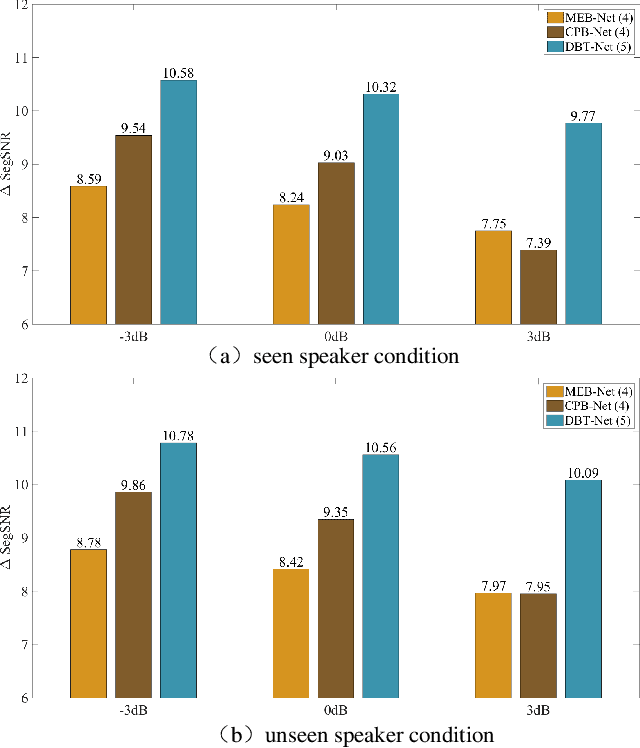
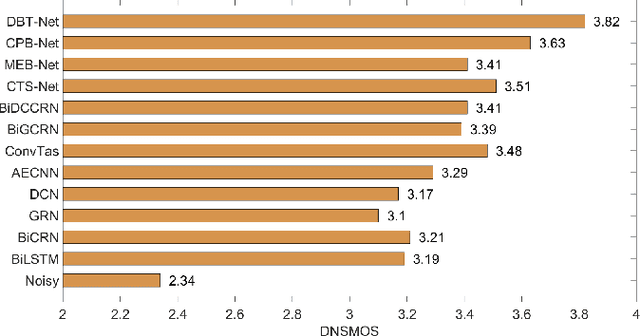
The decoupling-style concept begins to ignite in the speech enhancement area, which decouples the original complex spectrum estimation task into multiple easier sub-tasks (i.e., magnitude and phase), resulting in better performance and easier interpretability. In this paper, we propose a dual-branch federative magnitude and phase estimation framework, dubbed DBT-Net, for monaural speech enhancement, which aims at recovering the coarse- and fine-grained regions of the overall spectrum in parallel. From the complementary perspective, the magnitude estimation branch is designed to filter out dominant noise components in the magnitude domain, while the complex spectrum purification branch is elaborately designed to inpaint the missing spectral details and implicitly estimate the phase information in the complex domain. To facilitate the information flow between each branch, interaction modules are introduced to leverage features learned from one branch, so as to suppress the undesired parts and recover the missing components of the other branch. Instead of adopting the conventional RNNs and temporal convolutional networks for sequence modeling, we propose a novel attention-in-attention transformer-based network within each branch for better feature learning. More specially, it is composed of several adaptive spectro-temporal attention transformer-based modules and an adaptive hierarchical attention module, aiming to capture long-term time-frequency dependencies and further aggregate intermediate hierarchical contextual information. Comprehensive evaluations on the WSJ0-SI84 + DNS-Challenge and VoiceBank + DEMAND dataset demonstrate that the proposed approach consistently outperforms previous advanced systems and yields state-of-the-art performance in terms of speech quality and intelligibility.
Romanian Speech Recognition Experiments from the ROBIN Project
Nov 23, 2021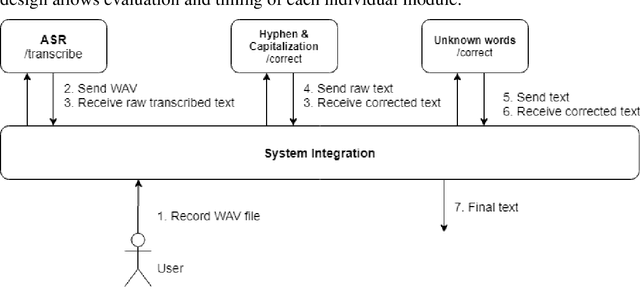
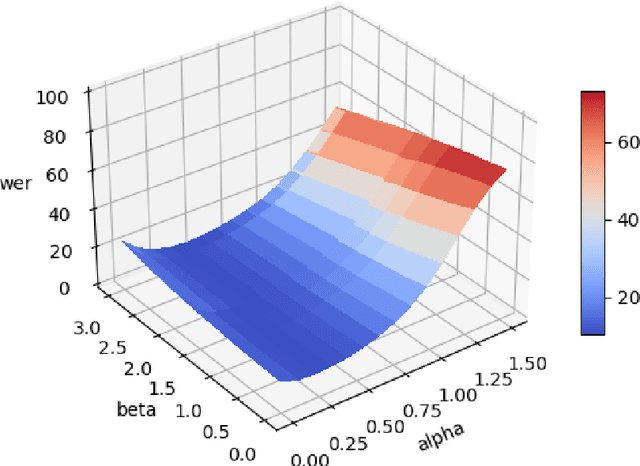
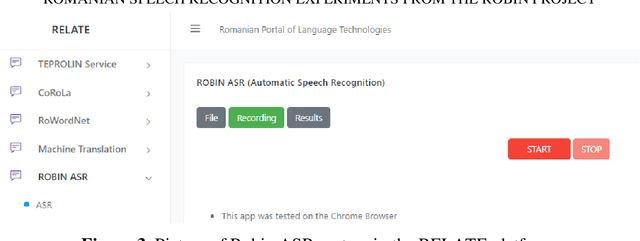
One of the fundamental functionalities for accepting a socially assistive robot is its communication capabilities with other agents in the environment. In the context of the ROBIN project, situational dialogue through voice interaction with a robot was investigated. This paper presents different speech recognition experiments with deep neural networks focusing on producing fast (under 100ms latency from the network itself), while still reliable models. Even though one of the key desired characteristics is low latency, the final deep neural network model achieves state of the art results for recognizing Romanian language, obtaining a 9.91% word error rate (WER), when combined with a language model, thus improving over the previous results while offering at the same time an improved runtime performance. Additionally, we explore two modules for correcting the ASR output (hyphen and capitalization restoration and unknown words correction), targeting the ROBIN project's goals (dialogue in closed micro-worlds). We design a modular architecture based on APIs allowing an integration engine (either in the robot or external) to chain together the available modules as needed. Finally, we test the proposed design by integrating it in the RELATE platform and making the ASR service available to web users by either uploading a file or recording new speech.
Analysis and Tuning of a Voice Assistant System for Dysfluent Speech
Jun 18, 2021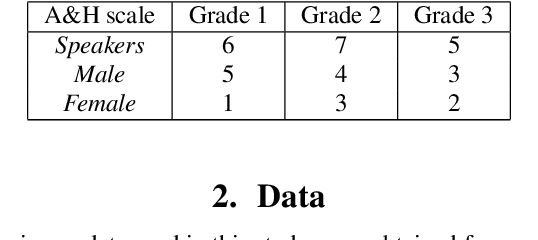
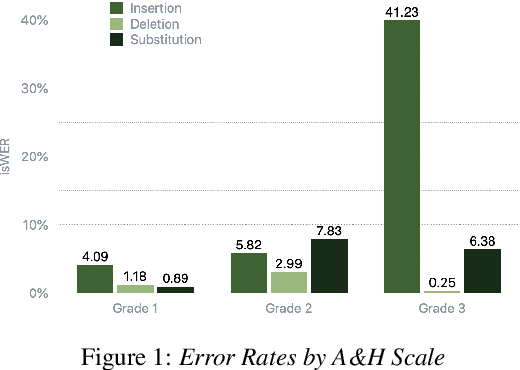
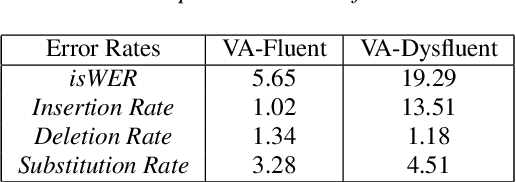
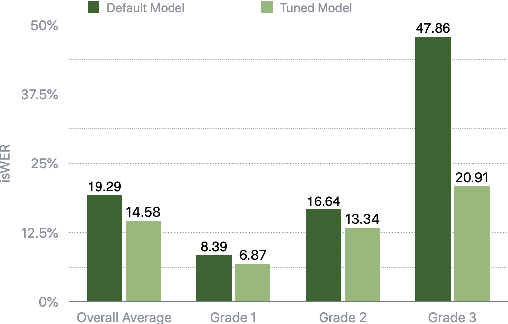
Dysfluencies and variations in speech pronunciation can severely degrade speech recognition performance, and for many individuals with moderate-to-severe speech disorders, voice operated systems do not work. Current speech recognition systems are trained primarily with data from fluent speakers and as a consequence do not generalize well to speech with dysfluencies such as sound or word repetitions, sound prolongations, or audible blocks. The focus of this work is on quantitative analysis of a consumer speech recognition system on individuals who stutter and production-oriented approaches for improving performance for common voice assistant tasks (i.e., "what is the weather?"). At baseline, this system introduces a significant number of insertion and substitution errors resulting in intended speech Word Error Rates (isWER) that are 13.64\% worse (absolute) for individuals with fluency disorders. We show that by simply tuning the decoding parameters in an existing hybrid speech recognition system one can improve isWER by 24\% (relative) for individuals with fluency disorders. Tuning these parameters translates to 3.6\% better domain recognition and 1.7\% better intent recognition relative to the default setup for the 18 study participants across all stuttering severities.
Deciphering Speech: a Zero-Resource Approach to Cross-Lingual Transfer in ASR
Nov 12, 2021



We present a method for cross-lingual training an ASR system using absolutely no transcribed training data from the target language, and with no phonetic knowledge of the language in question. Our approach uses a novel application of a decipherment algorithm, which operates given only unpaired speech and text data from the target language. We apply this decipherment to phone sequences generated by a universal phone recogniser trained on out-of-language speech corpora, which we follow with flat-start semi-supervised training to obtain an acoustic model for the new language. To the best of our knowledge, this is the first practical approach to zero-resource cross-lingual ASR which does not rely on any hand-crafted phonetic information. We carry out experiments on read speech from the GlobalPhone corpus, and show that it is possible to learn a decipherment model on just 20 minutes of data from the target language. When used to generate pseudo-labels for semi-supervised training, we obtain WERs that range from 25% to just 5% absolute worse than the equivalent fully supervised models trained on the same data.
Accented Speech Recognition Inspired by Human Perception
Apr 09, 2021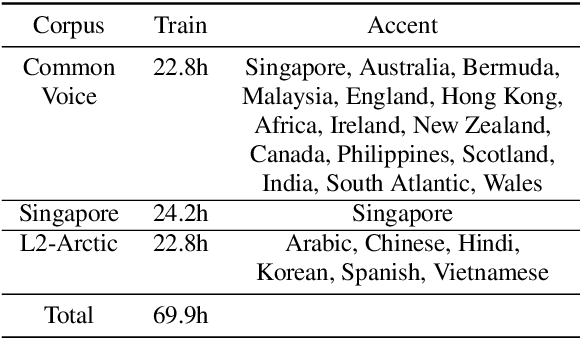
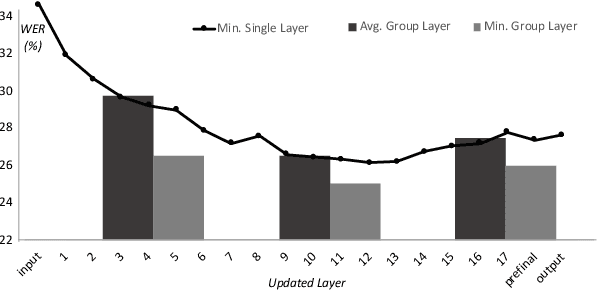
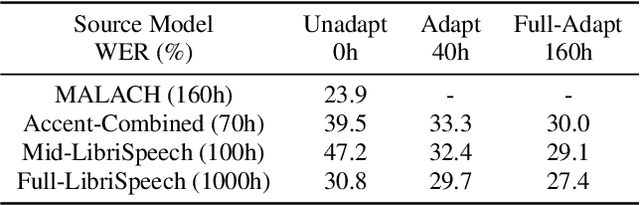
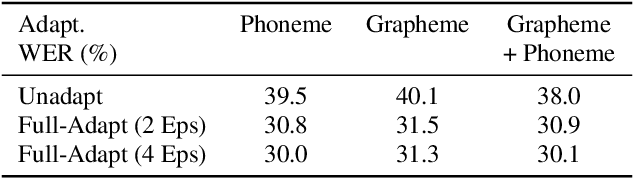
While improvements have been made in automatic speech recognition performance over the last several years, machines continue to have significantly lower performance on accented speech than humans. In addition, the most significant improvements on accented speech primarily arise by overwhelming the problem with hundreds or even thousands of hours of data. Humans typically require much less data to adapt to a new accent. This paper explores methods that are inspired by human perception to evaluate possible performance improvements for recognition of accented speech, with a specific focus on recognizing speech with a novel accent relative to that of the training data. Our experiments are run on small, accessible datasets that are available to the research community. We explore four methodologies: pre-exposure to multiple accents, grapheme and phoneme-based pronunciations, dropout (to improve generalization to a novel accent), and the identification of the layers in the neural network that can specifically be associated with accent modeling. Our results indicate that methods based on human perception are promising in reducing WER and understanding how accented speech is modeled in neural networks for novel accents.
Distilling a Pretrained Language Model to a Multilingual ASR Model
Jun 25, 2022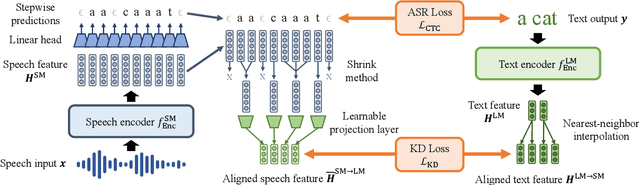
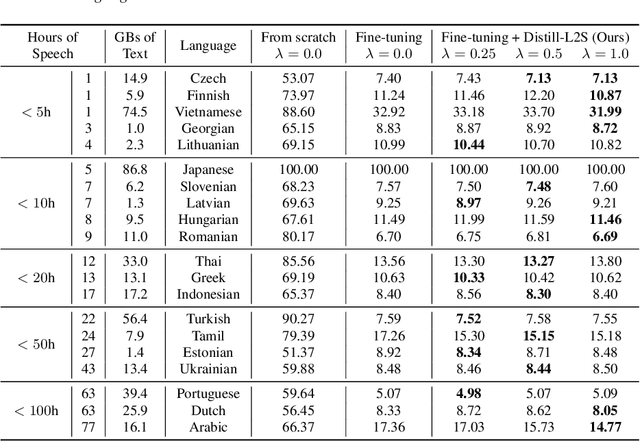
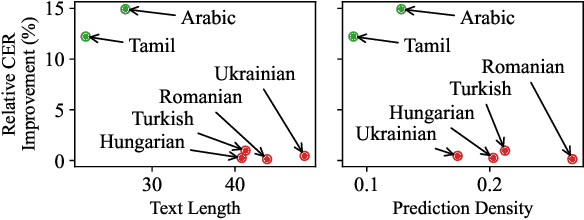
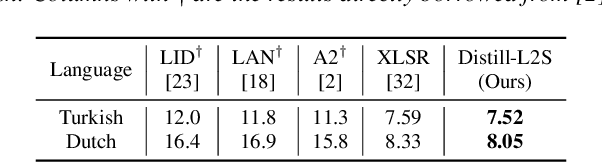
Multilingual speech data often suffer from long-tailed language distribution, resulting in performance degradation. However, multilingual text data is much easier to obtain, yielding a more useful general language model. Hence, we are motivated to distill the rich knowledge embedded inside a well-trained teacher text model to the student speech model. We propose a novel method called the Distilling a Language model to a Speech model (Distill-L2S), which aligns the latent representations of two different modalities. The subtle differences are handled by the shrinking mechanism, nearest-neighbor interpolation, and a learnable linear projection layer. We demonstrate the effectiveness of our distillation method by applying it to the multilingual automatic speech recognition (ASR) task. We distill the transformer-based cross-lingual language model (InfoXLM) while fine-tuning the large-scale multilingual ASR model (XLSR-wav2vec 2.0) for each language. We show the superiority of our method on 20 low-resource languages of the CommonVoice dataset with less than 100 hours of speech data.
An Investigation of Monotonic Transducers for Large-Scale Automatic Speech Recognition
Apr 19, 2022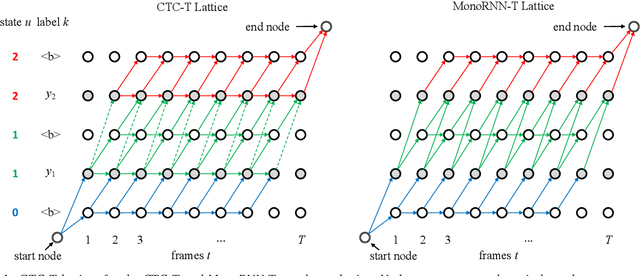
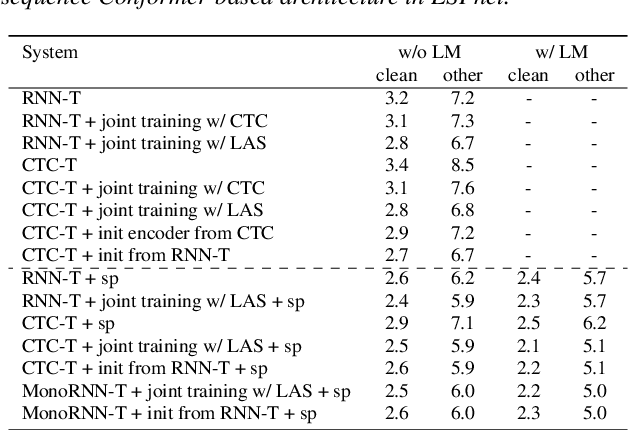
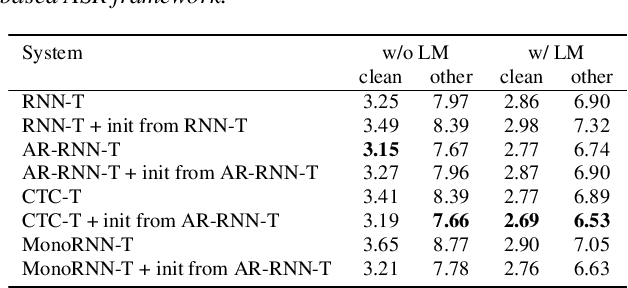
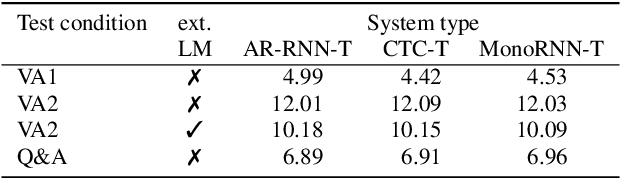
The two most popular loss functions for streaming end-to-end automatic speech recognition (ASR) are the RNN-Transducer (RNN-T) and the connectionist temporal classification (CTC) objectives. Both perform an alignment-free training by marginalizing over all possible alignments, but use different transition rules. Between these two loss types we can classify the monotonic RNN-T (MonoRNN-T) and the recently proposed CTC-like Transducer (CTC-T), which both can be realized using the graph temporal classification-transducer (GTC-T) loss function. Monotonic transducers have a few advantages. First, RNN-T can suffer from runaway hallucination, where a model keeps emitting non-blank symbols without advancing in time, often in an infinite loop. Secondly, monotonic transducers consume exactly one model score per time step and are therefore more compatible and unifiable with traditional FST-based hybrid ASR decoders. However, the MonoRNN-T so far has been found to have worse accuracy than RNN-T. It does not have to be that way, though: By regularizing the training - via joint LAS training or parameter initialization from RNN-T - both MonoRNN-T and CTC-T perform as well - or better - than RNN-T. This is demonstrated for LibriSpeech and for a large-scale in-house data set.
From Spelling to Grammar: A New Framework for Chinese Grammatical Error Correction
Nov 03, 2022
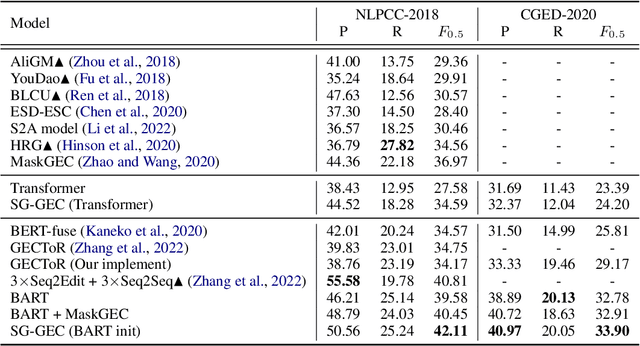
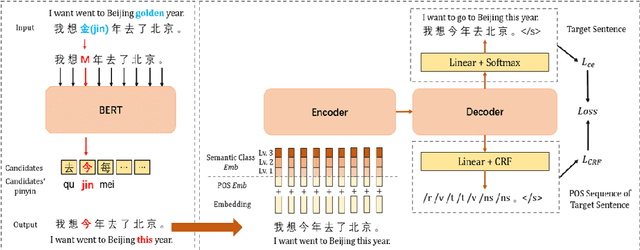
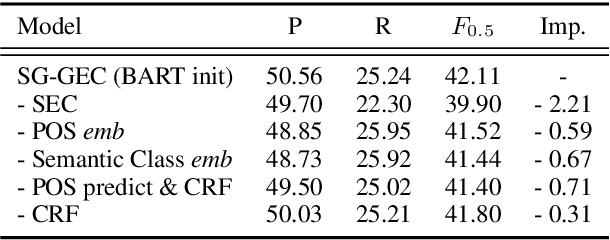
Chinese Grammatical Error Correction (CGEC) aims to generate a correct sentence from an erroneous sequence, where different kinds of errors are mixed. This paper divides the CGEC task into two steps, namely spelling error correction and grammatical error correction. Specifically, we propose a novel zero-shot approach for spelling error correction, which is simple but effective, obtaining a high precision to avoid error accumulation of the pipeline structure. To handle grammatical error correction, we design part-of-speech (POS) features and semantic class features to enhance the neural network model, and propose an auxiliary task to predict the POS sequence of the target sentence. Our proposed framework achieves a 42.11 F0.5 score on CGEC dataset without using any synthetic data or data augmentation methods, which outperforms the previous state-of-the-art by a wide margin of 1.30 points. Moreover, our model produces meaningful POS representations that capture different POS words and convey reasonable POS transition rules.