 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Noisy Speech Based Temporal Decomposition to Improve Fundamental Frequency Estimation
Dec 18, 2021
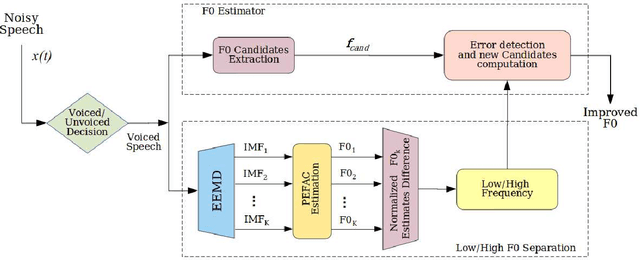
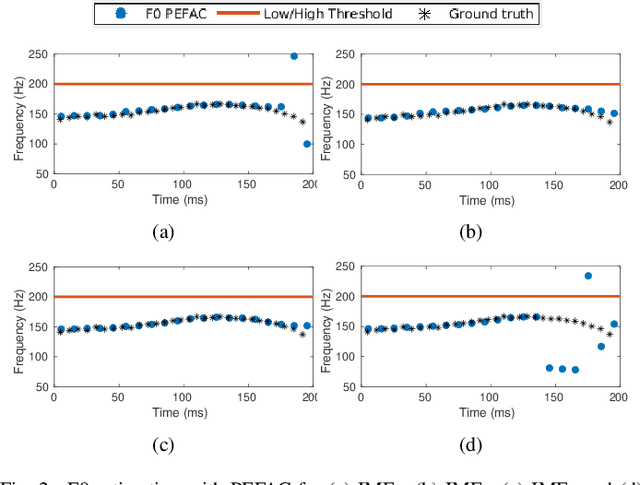
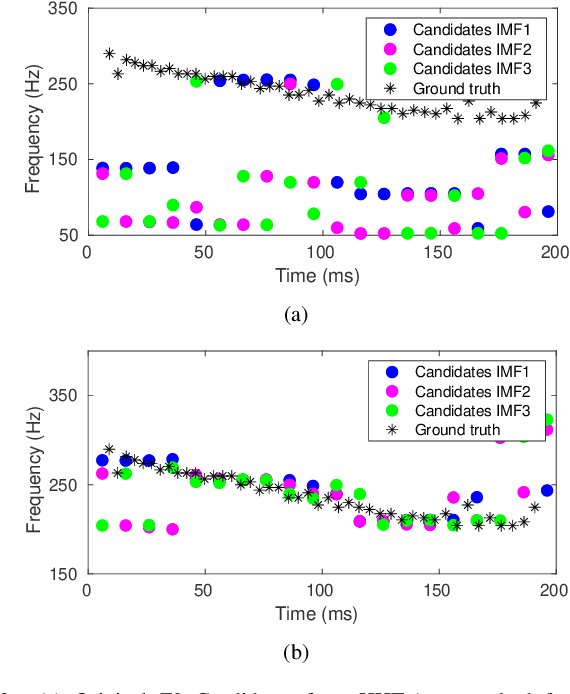
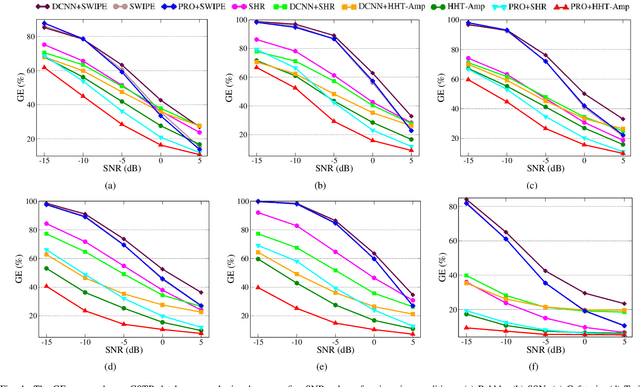
This paper introduces a novel method to separate noisy speech into low or high frequency frames, in order to improve fundamental frequency (F0) estimation accuracy. In this proposal, the target signal is analyzed by means of the ensemble empirical mode decomposition. Next, the pitch information is extracted from the first decomposition modes. This feature indicates the frequency region where the F0 of speech should be located, thus separating the frames into low-frequency (LF) or high-frequency (HF). The separation is applied to correct candidates extracted from a conventional fundamental frequency detection method, and hence improving the accuracy of F0 estimate. The proposed method is evaluated in experiments with CSTR and TIMIT databases, considering six acoustic noises under various signal-to-noise ratios. A pitch enhancement algorithm is adopted as baseline in the evaluation analysis considering three conventional estimators. Results show that the proposed method outperforms the competing strategies, in terms of low/high frequency separation accuracy. Moreover, the performance metrics of the F0 estimation techniques show that the novel solution is able to better improve F0 detection accuracy when compared to competitive approaches under different noisy conditions.
REAL-M: Towards Speech Separation on Real Mixtures
Oct 20, 2021
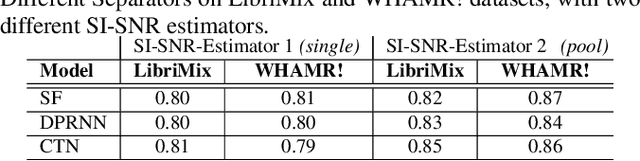
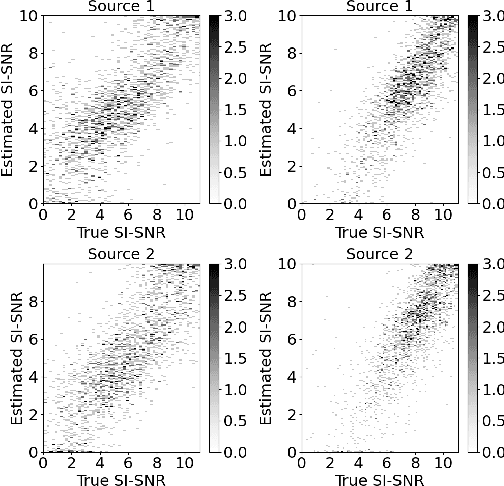
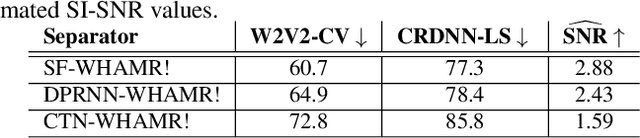
In recent years, deep learning based source separation has achieved impressive results. Most studies, however, still evaluate separation models on synthetic datasets, while the performance of state-of-the-art techniques on in-the-wild speech data remains an open question. This paper contributes to fill this gap in two ways. First, we release the REAL-M dataset, a crowd-sourced corpus of real-life mixtures. Secondly, we address the problem of performance evaluation of real-life mixtures, where the ground truth is not available. We bypass this issue by carefully designing a blind Scale-Invariant Signal-to-Noise Ratio (SI-SNR) neural estimator. Through a user study, we show that our estimator reliably evaluates the separation performance on real mixtures. The performance predictions of the SI-SNR estimator indeed correlate well with human opinions. Moreover, we observe that the performance trends predicted by our estimator on the REAL-M dataset closely follow those achieved on synthetic benchmarks when evaluating popular speech separation models.
To Dereverb Or Not to Dereverb? Perceptual Studies On Real-Time Dereverberation Targets
Jun 16, 2022



In real life, room effect, also known as room reverberation, and the present background noise degrade the quality of speech. Recently, deep learning-based speech enhancement approaches have shown a lot of promise and surpassed traditional denoising and dereverberation methods. It is also well established that these state-of-the-art denoising algorithms significantly improve the quality of speech as perceived by human listeners. But the role of dereverberation on subjective (perceived) speech quality, and whether the additional artifacts introduced by dereverberation cause more harm than good are still unclear. In this paper, we attempt to answer these questions by evaluating a state of the art speech enhancement system in a comprehensive subjective evaluation study for different choices of dereverberation targets.
Unsupervised Domain Adaptation for Hate Speech Detection Using a Data Augmentation Approach
Jul 31, 2021
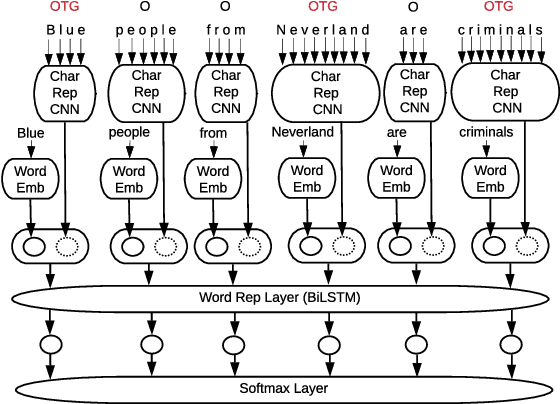
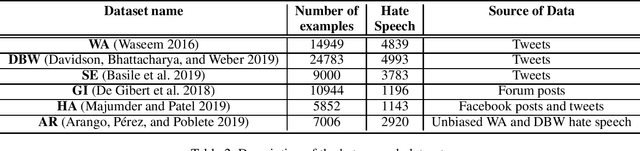

Online harassment in the form of hate speech has been on the rise in recent years. Addressing the issue requires a combination of content moderation by people, aided by automatic detection methods. As content moderation is itself harmful to the people doing it, we desire to reduce the burden by improving the automatic detection of hate speech. Hate speech presents a challenge as it is directed at different target groups using a completely different vocabulary. Further the authors of the hate speech are incentivized to disguise their behavior to avoid being removed from a platform. This makes it difficult to develop a comprehensive data set for training and evaluating hate speech detection models because the examples that represent one hate speech domain do not typically represent others, even within the same language or culture. We propose an unsupervised domain adaptation approach to augment labeled data for hate speech detection. We evaluate the approach with three different models (character CNNs, BiLSTMs and BERT) on three different collections. We show our approach improves Area under the Precision/Recall curve by as much as 42% and recall by as much as 278%, with no loss (and in some cases a significant gain) in precision.
Sampling Rate Offset Estimation and Compensation for Distributed Adaptive Node-Specific Signal Estimation in Wireless Acoustic Sensor Networks
Nov 04, 2022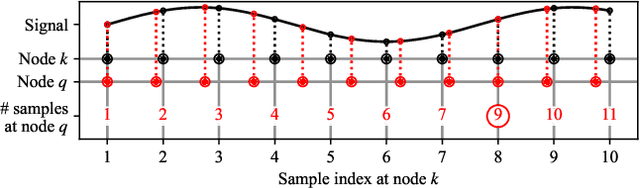
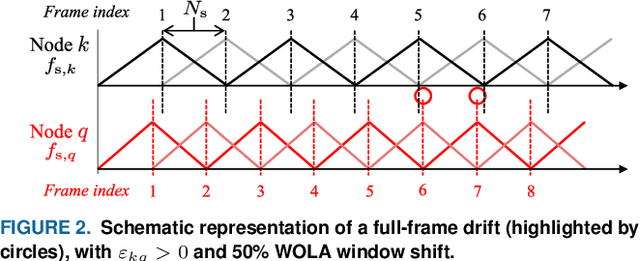
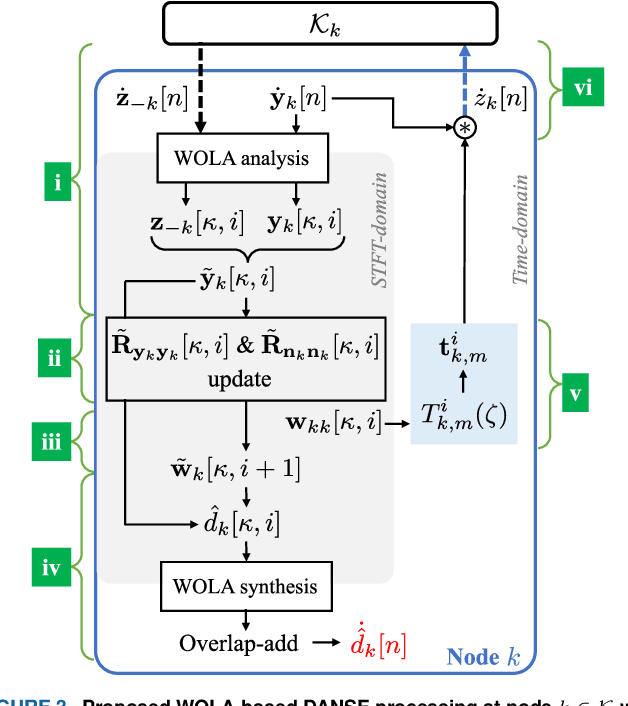
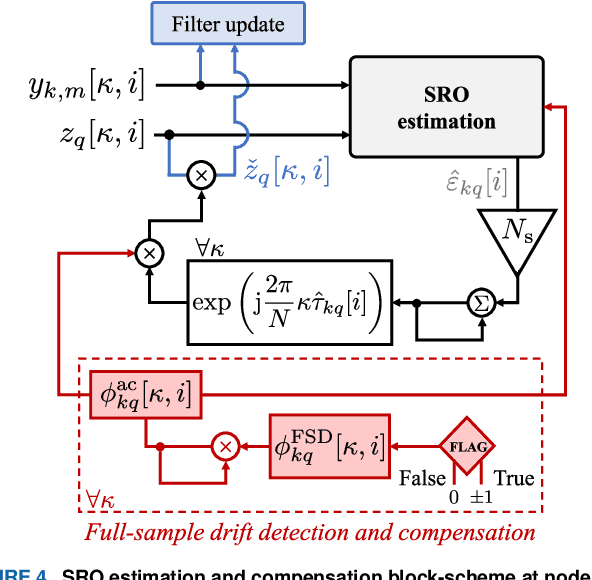
Sampling rate offsets (SROs) between devices in a heterogeneous wireless acoustic sensor network (WASN) can hinder the ability of distributed adaptive algorithms to perform as intended when they rely on coherent signal processing. In this paper, we present an SRO estimation and compensation method to allow the deployment of the distributed adaptive node-specific signal estimation (DANSE) algorithm in WASNs composed of asynchronous devices. The signals available at each node are first utilised in a coherence-drift-based method to blindly estimate SROs which are then compensated for via phase shifts in the frequency domain. A modification of the weighted overlap-add (WOLA) implementation of DANSE is introduced to account for SRO-induced full-sample drifts, permitting per-sample signal transmission via an approximation of the WOLA process as a time-domain convolution. The performance of the proposed algorithm is evaluated in the context of distributed noise reduction for the estimation of a target speech signal in an asynchronous WASN.
Improving Pseudo-label Training For End-to-end Speech Recognition Using Gradient Mask
Oct 08, 2021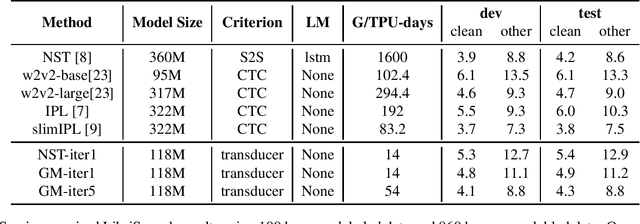
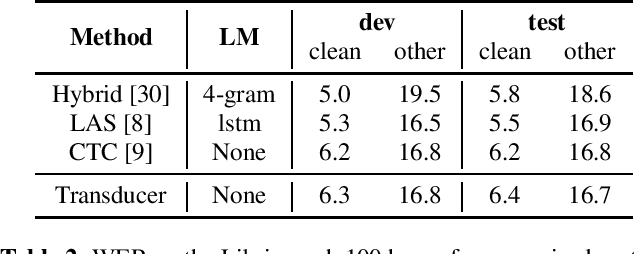
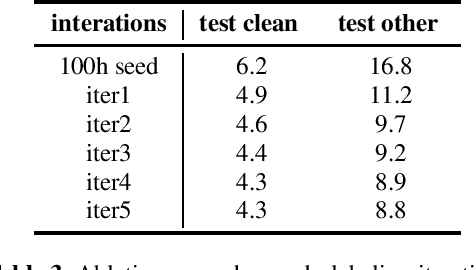
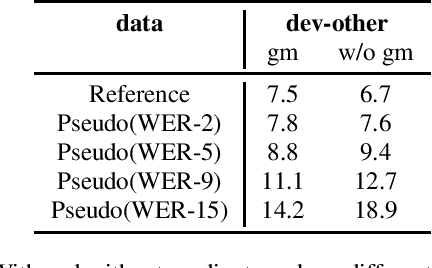
In the recent trend of semi-supervised speech recognition, both self-supervised representation learning and pseudo-labeling have shown promising results. In this paper, we propose a novel approach to combine their ideas for end-to-end speech recognition model. Without any extra loss function, we utilize the Gradient Mask to optimize the model when training on pseudo-label. This method forces the speech recognition model to predict from the masked input to learn strong acoustic representation and make training robust to label noise. In our semi-supervised experiments, the method can improve the model performance when training on pseudo-label and our method achieved competitive results comparing with other semi-supervised approaches on the Librispeech 100 hours experiments.
Glow-WaveGAN: Learning Speech Representations from GAN-based Variational Auto-Encoder For High Fidelity Flow-based Speech Synthesis
Jun 22, 2021
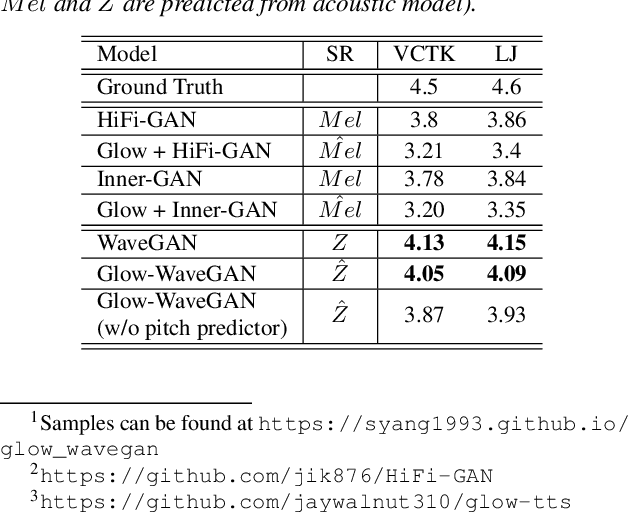
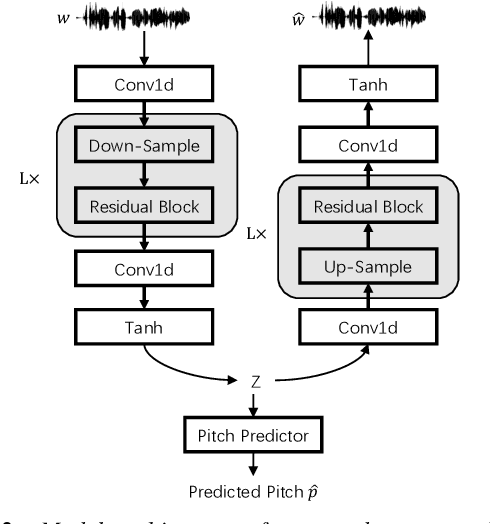
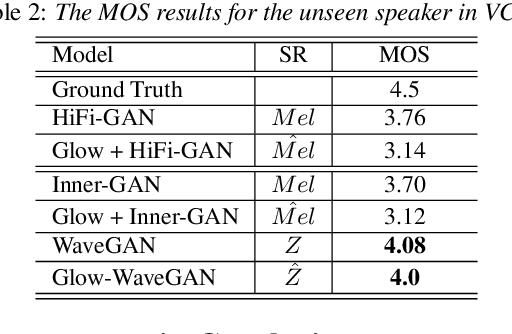
Current two-stage TTS framework typically integrates an acoustic model with a vocoder -- the acoustic model predicts a low resolution intermediate representation such as Mel-spectrum while the vocoder generates waveform from the intermediate representation. Although the intermediate representation is served as a bridge, there still exists critical mismatch between the acoustic model and the vocoder as they are commonly separately learned and work on different distributions of representation, leading to inevitable artifacts in the synthesized speech. In this work, different from using pre-designed intermediate representation in most previous studies, we propose to use VAE combining with GAN to learn a latent representation directly from speech and then utilize a flow-based acoustic model to model the distribution of the latent representation from text. In this way, the mismatch problem is migrated as the two stages work on the same distribution. Results demonstrate that the flow-based acoustic model can exactly model the distribution of our learned speech representation and the proposed TTS framework, namely Glow-WaveGAN, can produce high fidelity speech outperforming the state-of-the-art GAN-based model.
Exploiting Pre-Trained ASR Models for Alzheimer's Disease Recognition Through Spontaneous Speech
Oct 04, 2021
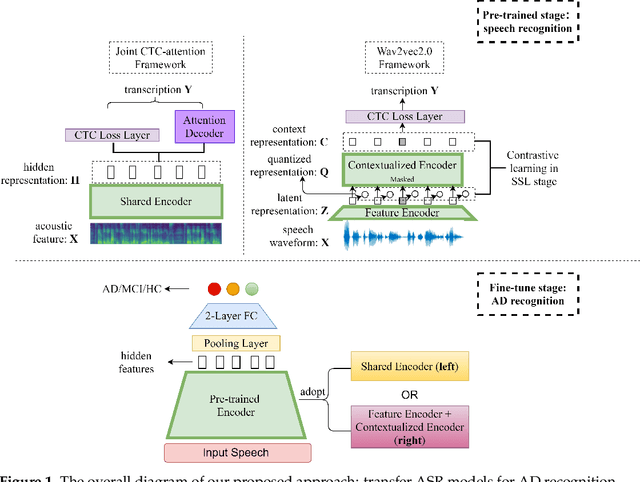
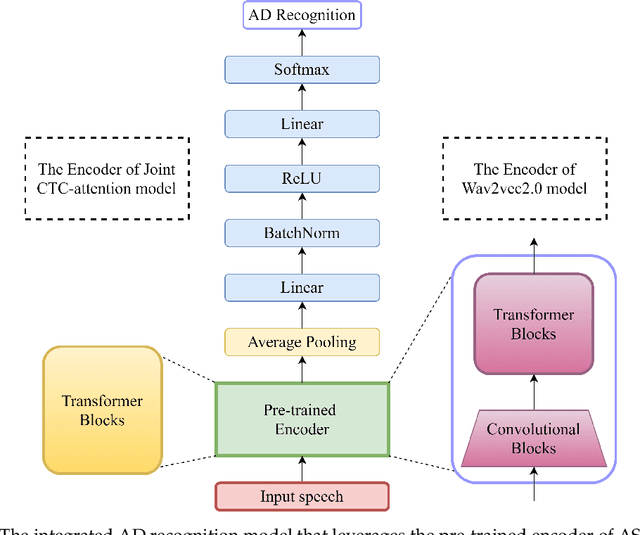
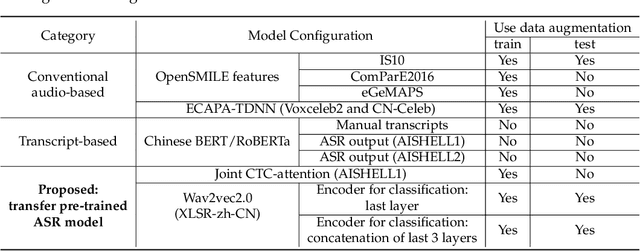
Alzheimer's disease (AD) is a progressive neurodegenerative disease and recently attracts extensive attention worldwide. Speech technology is considered a promising solution for the early diagnosis of AD and has been enthusiastically studied. Most recent works concentrate on the use of advanced BERT-like classifiers for AD detection. Input to these classifiers are speech transcripts produced by automatic speech recognition (ASR) models. The major challenge is that the quality of transcription could degrade significantly under complex acoustic conditions in the real world. The detection performance, in consequence, is largely limited. This paper tackles the problem via tailoring and adapting pre-trained neural-network based ASR model for the downstream AD recognition task. Only bottom layers of the ASR model are retained. A simple fully-connected neural network is added on top of the tailored ASR model for classification. The heavy BERT classifier is discarded. The resulting model is light-weight and can be fine-tuned in an end-to-end manner for AD recognition. Our proposed approach takes only raw speech as input, and no extra transcription process is required. The linguistic information of speech is implicitly encoded in the tailored ASR model and contributes to boosting the performance. Experiments show that our proposed approach outperforms the best manual transcript-based RoBERTa by an absolute margin of 4.6% in terms of accuracy. Our best-performing models achieve the accuracy of 83.2% and 78.0% in the long-audio and short-audio competition tracks of the 2021 NCMMSC Alzheimer's Disease Recognition Challenge, respectively.
AVASpeech-SMAD: A Strongly Labelled Speech and Music Activity Detection Dataset with Label Co-Occurrence
Nov 02, 2021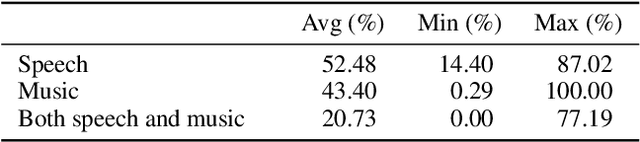

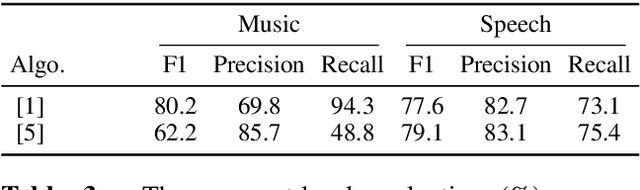
We propose a dataset, AVASpeech-SMAD, to assist speech and music activity detection research. With frame-level music labels, the proposed dataset extends the existing AVASpeech dataset, which originally consists of 45 hours of audio and speech activity labels. To the best of our knowledge, the proposed AVASpeech-SMAD is the first open-source dataset that features strong polyphonic labels for both music and speech. The dataset was manually annotated and verified via an iterative cross-checking process. A simple automatic examination was also implemented to further improve the quality of the labels. Evaluation results from two state-of-the-art SMAD systems are also provided as a benchmark for future reference.
"Notic My Speech" -- Blending Speech Patterns With Multimedia
Jun 12, 2020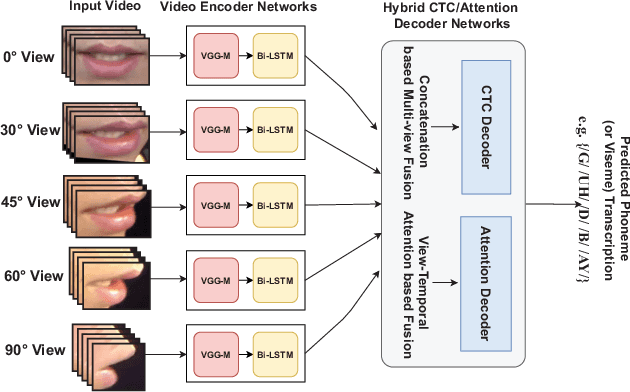
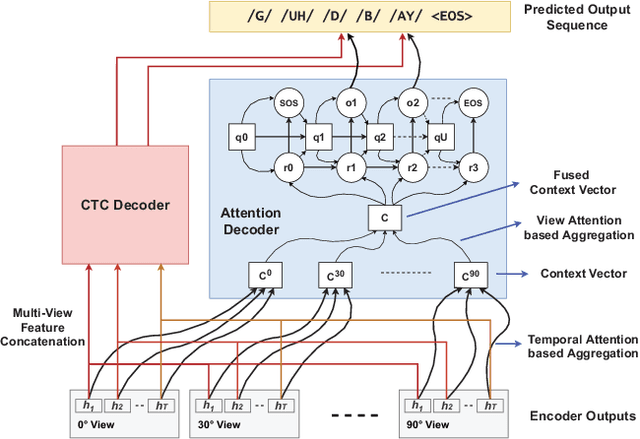
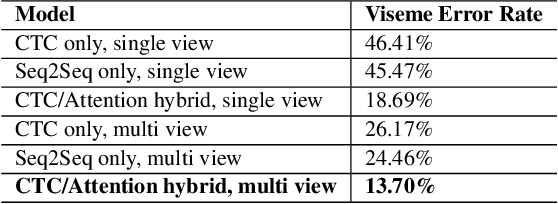
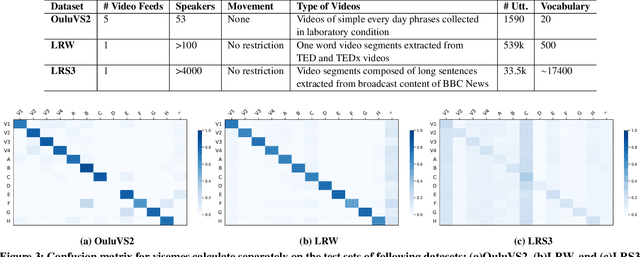
Speech as a natural signal is composed of three parts - visemes (visual part of speech), phonemes (spoken part of speech), and language (the imposed structure). However, video as a medium for the delivery of speech and a multimedia construct has mostly ignored the cognitive aspects of speech delivery. For example, video applications like transcoding and compression have till now ignored the fact how speech is delivered and heard. To close the gap between speech understanding and multimedia video applications, in this paper, we show the initial experiments by modelling the perception on visual speech and showing its use case on video compression. On the other hand, in the visual speech recognition domain, existing studies have mostly modeled it as a classification problem, while ignoring the correlations between views, phonemes, visemes, and speech perception. This results in solutions which are further away from how human perception works. To bridge this gap, we propose a view-temporal attention mechanism to model both the view dependence and the visemic importance in speech recognition and understanding. We conduct experiments on three public visual speech recognition datasets. The experimental results show that our proposed method outperformed the existing work by 4.99% in terms of the viseme error rate. Moreover, we show that there is a strong correlation between our model's understanding of multi-view speech and the human perception. This characteristic benefits downstream applications such as video compression and streaming where a significant number of less important frames can be compressed or eliminated while being able to maximally preserve human speech understanding with good user experience.