 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Comparing Subjective Perceptions of Robot-to-Human Handover Trajectories
Nov 16, 2022


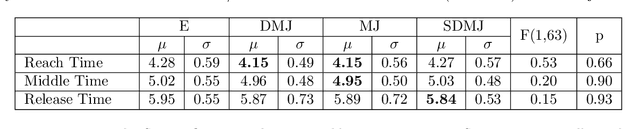

Robots must move legibly around people for safety reasons, especially for tasks where physical contact is possible. One such task is handovers, which requires implicit communication on where and when physical contact (object transfer) occurs. In this work, we study whether the trajectory model used by a robot during the reaching phase affects the subjective perceptions of receivers for robot-to-human handovers. We conducted a user study where 32 participants were handed over three objects with four trajectory models: three were versions of a minimum jerk trajectory, and one was an ellipse-fitting-based trajectory. The start position of the handover was fixed for all trajectories, and the end position was allowed to vary randomly around a fixed position by $\pm$3 cm in all axis. The user study found no significant differences among the handover trajectories in survey questions relating to safety, predictability, naturalness, and other subjective metrics. While these results seemingly reject the hypothesis that the trajectory affects human perceptions of a handover, it prompts future research to investigate the effect of other variables, such as robot speed, object transfer position, object orientation at the transfer point, and explicit communication signals such as gaze and speech.
An Attribute-Aligned Strategy for Learning Speech Representation
Jun 05, 2021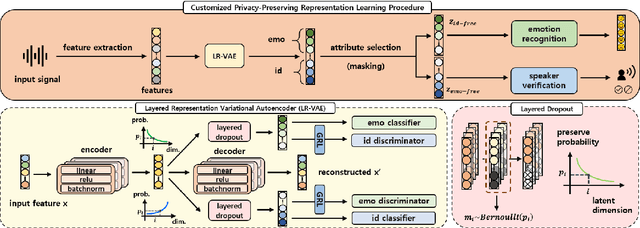
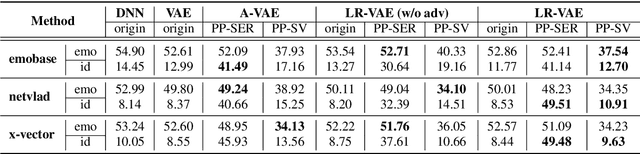
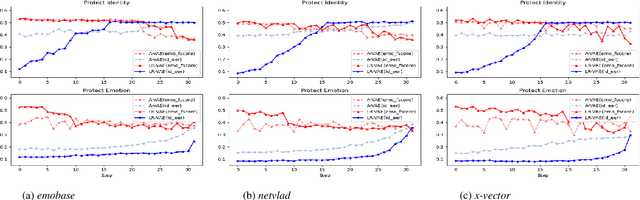
Advancement in speech technology has brought convenience to our life. However, the concern is on the rise as speech signal contains multiple personal attributes, which would lead to either sensitive information leakage or bias toward decision. In this work, we propose an attribute-aligned learning strategy to derive speech representation that can flexibly address these issues by attribute-selection mechanism. Specifically, we propose a layered-representation variational autoencoder (LR-VAE), which factorizes speech representation into attribute-sensitive nodes, to derive an identity-free representation for speech emotion recognition (SER), and an emotionless representation for speaker verification (SV). Our proposed method achieves competitive performances on identity-free SER and a better performance on emotionless SV, comparing to the current state-of-the-art method of using adversarial learning applied on a large emotion corpora, the MSP-Podcast. Also, our proposed learning strategy reduces the model and training process needed to achieve multiple privacy-preserving tasks.
A Streamwise GAN Vocoder for Wideband Speech Coding at Very Low Bit Rate
Aug 09, 2021
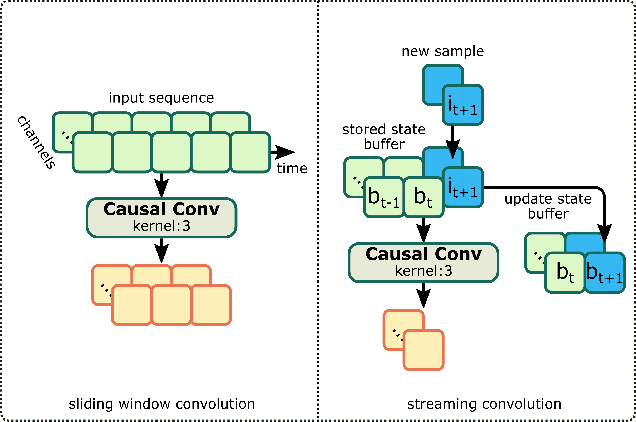
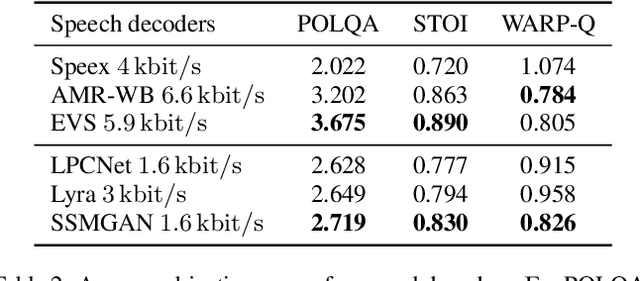
Recently, GAN vocoders have seen rapid progress in speech synthesis, starting to outperform autoregressive models in perceptual quality with much higher generation speed. However, autoregressive vocoders are still the common choice for neural generation of speech signals coded at very low bit rates. In this paper, we present a GAN vocoder which is able to generate wideband speech waveforms from parameters coded at 1.6 kbit/s. The proposed model is a modified version of the StyleMelGAN vocoder that can run in frame-by-frame manner, making it suitable for streaming applications. The experimental results show that the proposed model significantly outperforms prior autoregressive vocoders like LPCNet for very low bit rate speech coding, with computational complexity of about 5 GMACs, providing a new state of the art in this domain. Moreover, this streamwise adversarial vocoder delivers quality competitive to advanced speech codecs such as EVS at 5.9 kbit/s on clean speech, which motivates further usage of feed-forward fully-convolutional models for low bit rate speech coding.
T-Modules: Translation Modules for Zero-Shot Cross-Modal Machine Translation
May 24, 2022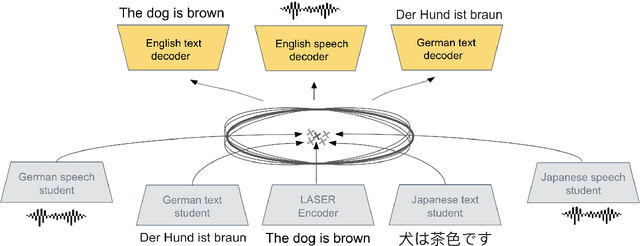

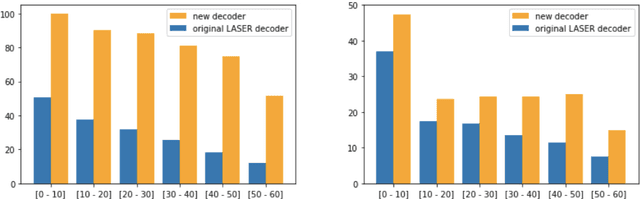
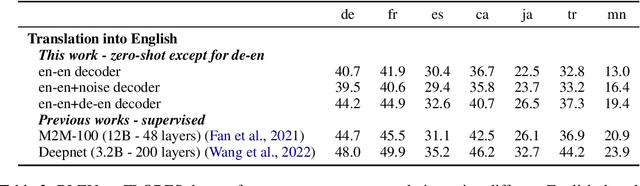
We present a new approach to perform zero-shot cross-modal transfer between speech and text for translation tasks. Multilingual speech and text are encoded in a joint fixed-size representation space. Then, we compare different approaches to decode these multimodal and multilingual fixed-size representations, enabling zero-shot translation between languages and modalities. All our models are trained without the need of cross-modal labeled translation data. Despite a fixed-size representation, we achieve very competitive results on several text and speech translation tasks. In particular, we significantly improve the state-of-the-art for zero-shot speech translation on Must-C. Incorporating a speech decoder in our framework, we introduce the first results for zero-shot direct speech-to-speech and text-to-speech translation.
Sampling Rate Offset Estimation and Compensation for Distributed Adaptive Node-Specific Signal Estimation in Wireless Acoustic Sensor Networks
Nov 04, 2022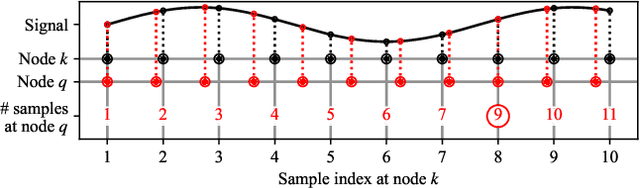
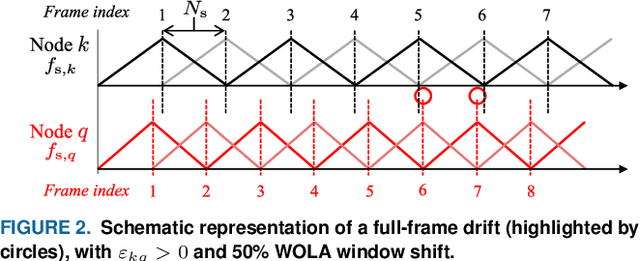
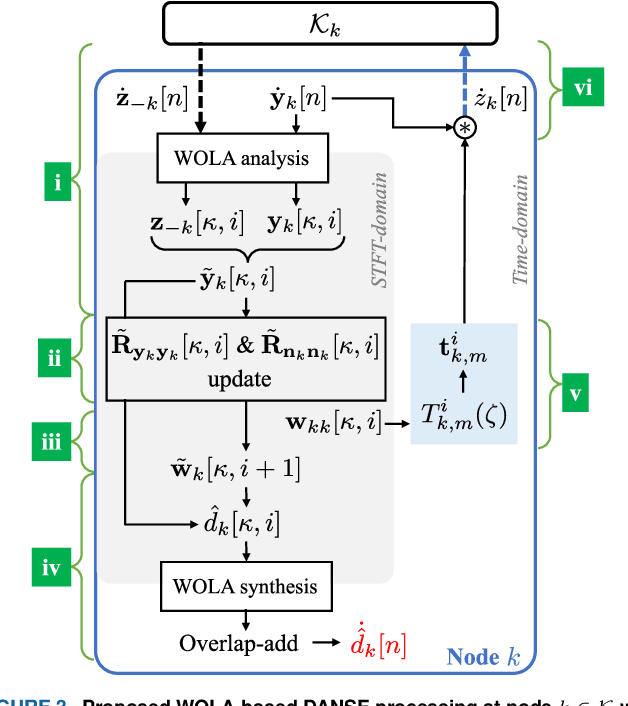
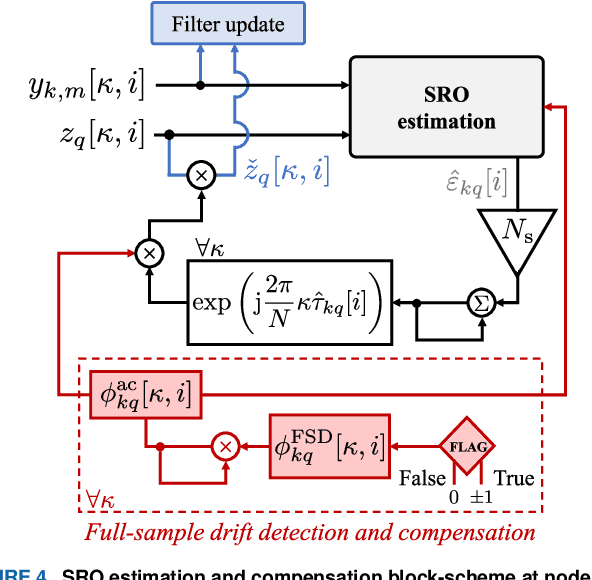
Sampling rate offsets (SROs) between devices in a heterogeneous wireless acoustic sensor network (WASN) can hinder the ability of distributed adaptive algorithms to perform as intended when they rely on coherent signal processing. In this paper, we present an SRO estimation and compensation method to allow the deployment of the distributed adaptive node-specific signal estimation (DANSE) algorithm in WASNs composed of asynchronous devices. The signals available at each node are first utilised in a coherence-drift-based method to blindly estimate SROs which are then compensated for via phase shifts in the frequency domain. A modification of the weighted overlap-add (WOLA) implementation of DANSE is introduced to account for SRO-induced full-sample drifts, permitting per-sample signal transmission via an approximation of the WOLA process as a time-domain convolution. The performance of the proposed algorithm is evaluated in the context of distributed noise reduction for the estimation of a target speech signal in an asynchronous WASN.
VSEGAN: Visual Speech Enhancement Generative Adversarial Network
Feb 04, 2021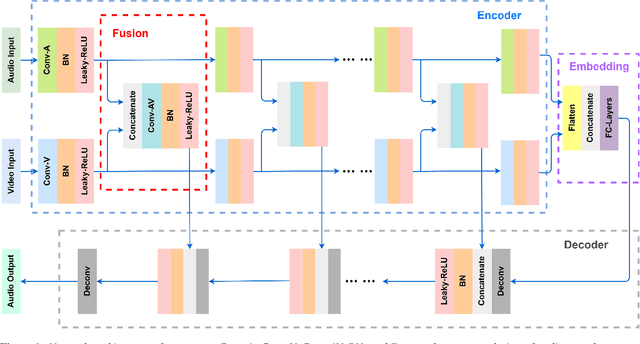

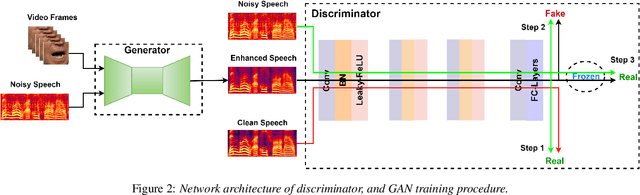
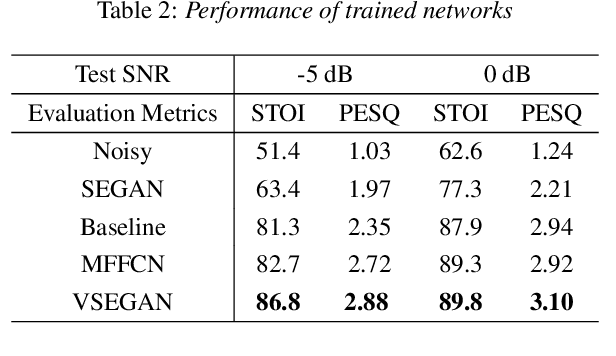
Speech enhancement is an essential task of improving speech quality in noise scenario. Several state-of-the-art approaches have introduced visual information for speech enhancement,since the visual aspect of speech is essentially unaffected by acoustic environment. This paper proposes a novel frameworkthat involves visual information for speech enhancement, by in-corporating a Generative Adversarial Network (GAN). In par-ticular, the proposed visual speech enhancement GAN consistof two networks trained in adversarial manner, i) a generator that adopts multi-layer feature fusion convolution network to enhance input noisy speech, and ii) a discriminator that attemptsto minimize the discrepancy between the distributions of the clean speech signal and enhanced speech signal. Experiment re-sults demonstrated superior performance of the proposed modelagainst several state-of-the-art
Investigation of Practical Aspects of Single Channel Speech Separation for ASR
Jul 05, 2021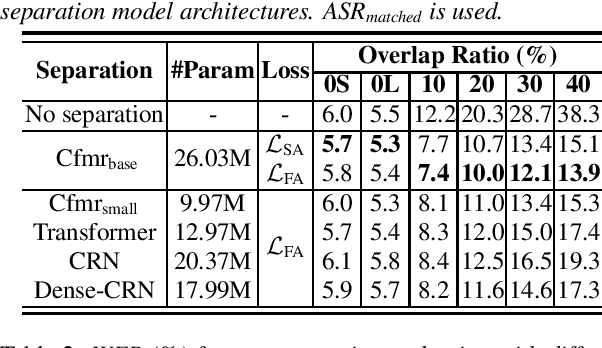
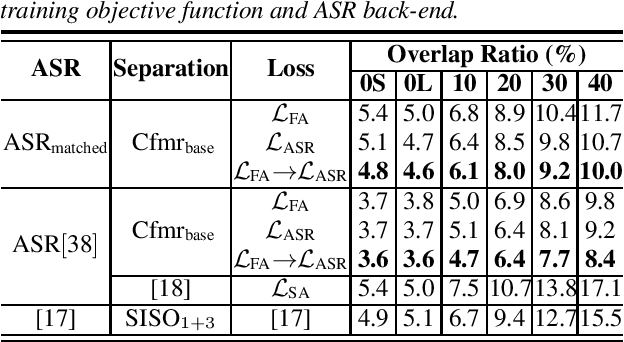
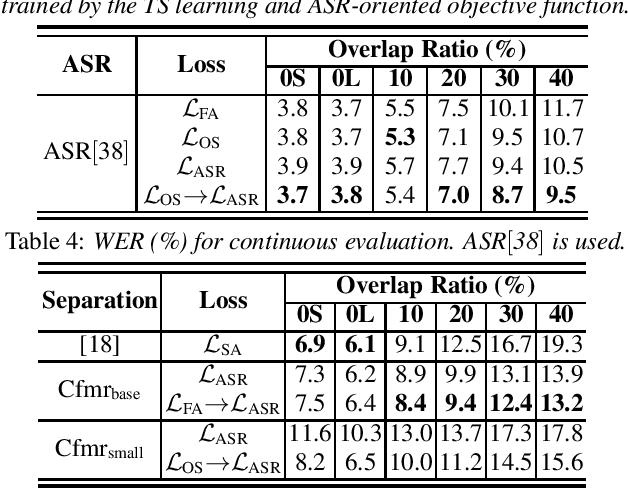
Speech separation has been successfully applied as a frontend processing module of conversation transcription systems thanks to its ability to handle overlapped speech and its flexibility to combine with downstream tasks such as automatic speech recognition (ASR). However, a speech separation model often introduces target speech distortion, resulting in a sub-optimum word error rate (WER). In this paper, we describe our efforts to improve the performance of a single channel speech separation system. Specifically, we investigate a two-stage training scheme that firstly applies a feature level optimization criterion for pretraining, followed by an ASR-oriented optimization criterion using an end-to-end (E2E) speech recognition model. Meanwhile, to keep the model light-weight, we introduce a modified teacher-student learning technique for model compression. By combining those approaches, we achieve a absolute average WER improvement of 2.70% and 0.77% using models with less than 10M parameters compared with the previous state-of-the-art results on the LibriCSS dataset for utterance-wise evaluation and continuous evaluation, respectively
A Scalable Model Specialization Framework for Training and Inference using Submodels and its Application to Speech Model Personalization
Mar 23, 2022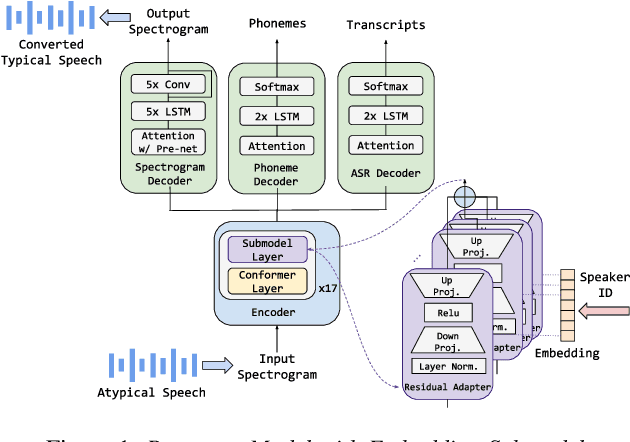
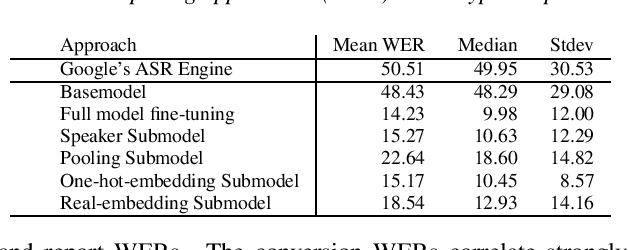
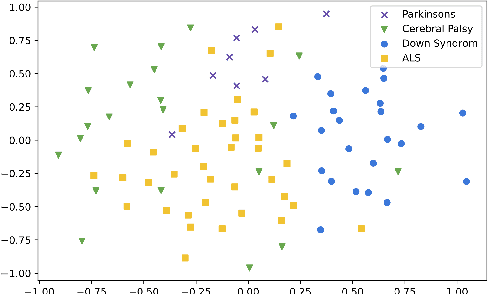
Model fine-tuning and adaptation have become a common approach for model specialization for downstream tasks or domains. Fine-tuning the entire model or a subset of the parameters using light-weight adaptation has shown considerable success across different specialization tasks. Fine-tuning a model for a large number of domains typically requires starting a new training job for every domain posing scaling limitations. Once these models are trained, deploying them also poses significant scalability challenges for inference for real-time applications. In this paper, building upon prior light-weight adaptation techniques, we propose a modular framework that enables us to substantially improve scalability for model training and inference. We introduce Submodels that can be quickly and dynamically loaded for on-the-fly inference. We also propose multiple approaches for training those Submodels in parallel using an embedding space in the same training job. We test our framework on an extreme use-case which is speech model personalization for atypical speech, requiring a Submodel for each user. We obtain 128x Submodel throughput with a fixed computation budget without a loss of accuracy. We also show that learning a speaker-embedding space can scale further and reduce the amount of personalization training data required per speaker.
CLSRIL-23: Cross Lingual Speech Representations for Indic Languages
Jul 15, 2021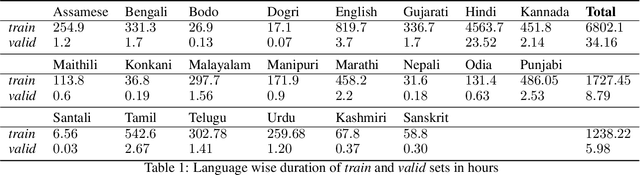
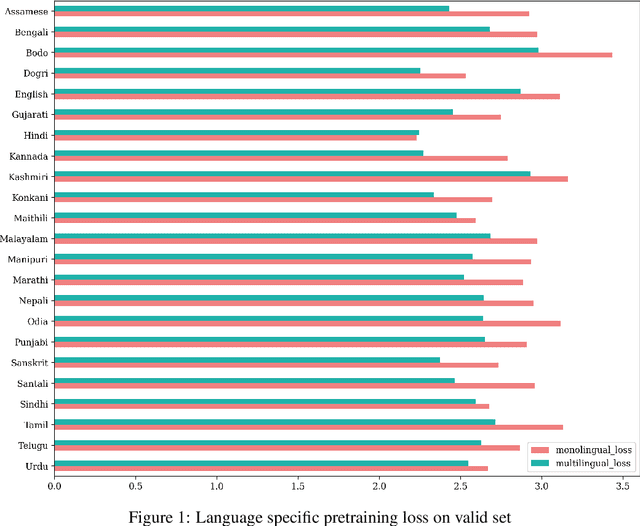
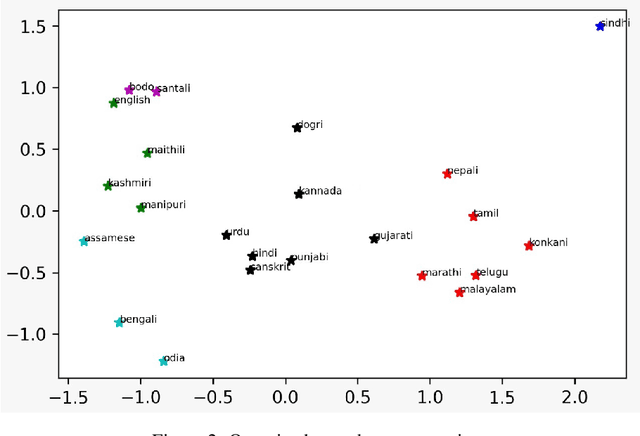

We present a CLSRIL-23, a self supervised learning based audio pre-trained model which learns cross lingual speech representations from raw audio across 23 Indic languages. It is built on top of wav2vec 2.0 which is solved by training a contrastive task over masked latent speech representations and jointly learns the quantization of latents shared across all languages. We compare the language wise loss during pretraining to compare effects of monolingual and multilingual pretraining. Performance on some downstream fine-tuning tasks for speech recognition is also compared and our experiments show that multilingual pretraining outperforms monolingual training, in terms of learning speech representations which encodes phonetic similarity of languages and also in terms of performance on down stream tasks. A decrease of 5% is observed in WER and 9.5% in CER when a multilingual pretrained model is used for finetuning in Hindi. All the code models are also open sourced. CLSRIL-23 is a model trained on $23$ languages and almost 10,000 hours of audio data to facilitate research in speech recognition for Indic languages. We hope that new state of the art systems will be created using the self supervised approach, especially for low resources Indic languages.
Speech BERT Embedding For Improving Prosody in Neural TTS
Jun 08, 2021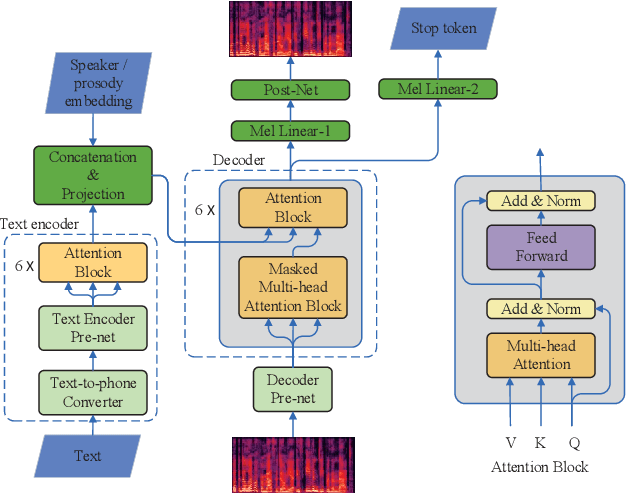
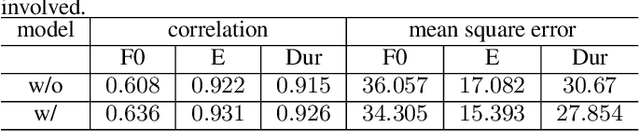
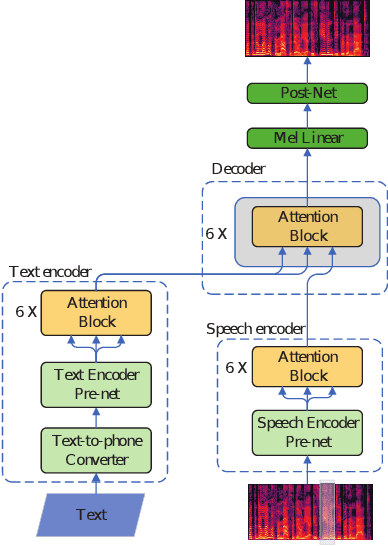
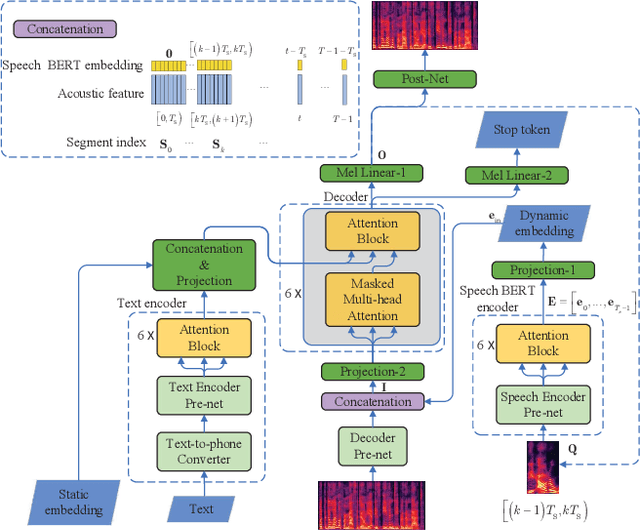
This paper presents a speech BERT model to extract embedded prosody information in speech segments for improving the prosody of synthesized speech in neural text-to-speech (TTS). As a pre-trained model, it can learn prosody attributes from a large amount of speech data, which can utilize more data than the original training data used by the target TTS. The embedding is extracted from the previous segment of a fixed length in the proposed BERT. The extracted embedding is then used together with the mel-spectrogram to predict the following segment in the TTS decoder. Experimental results obtained by the Transformer TTS show that the proposed BERT can extract fine-grained, segment-level prosody, which is complementary to utterance-level prosody to improve the final prosody of the TTS speech. The objective distortions measured on a single speaker TTS are reduced between the generated speech and original recordings. Subjective listening tests also show that the proposed approach is favorably preferred over the TTS without the BERT prosody embedding module, for both in-domain and out-of-domain applications. For Microsoft professional, single/multiple speakers and the LJ Speaker in the public database, subjective preference is similarly confirmed with the new BERT prosody embedding. TTS demo audio samples are in https://judy44chen.github.io/TTSSpeechBERT/.