 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Jira: a Kurdish Speech Recognition System Designing and Building Speech Corpus and Pronunciation Lexicon
Feb 15, 2021
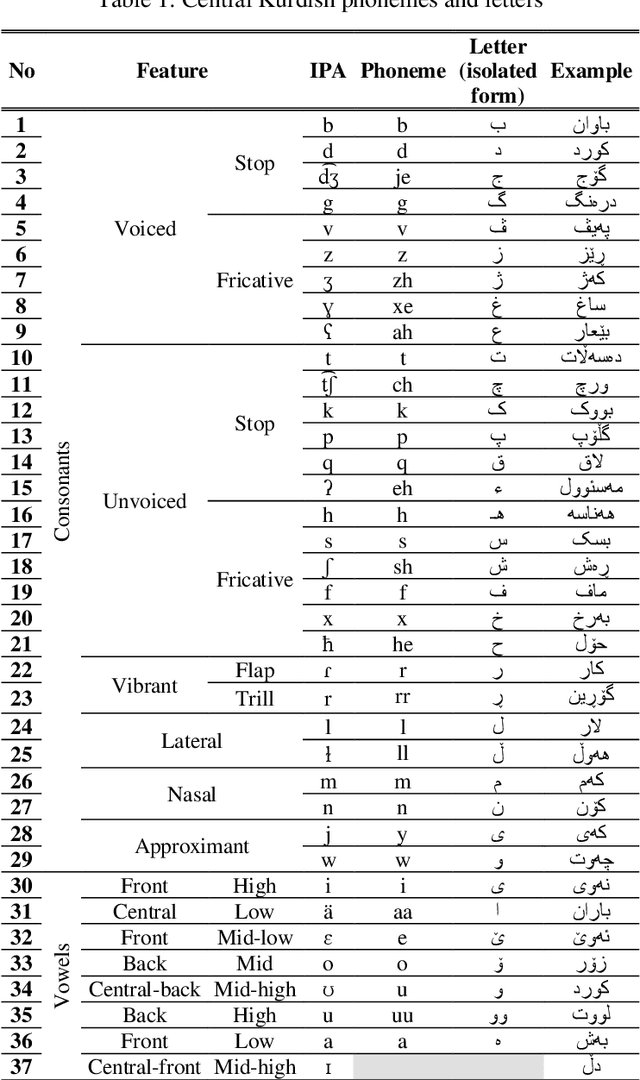
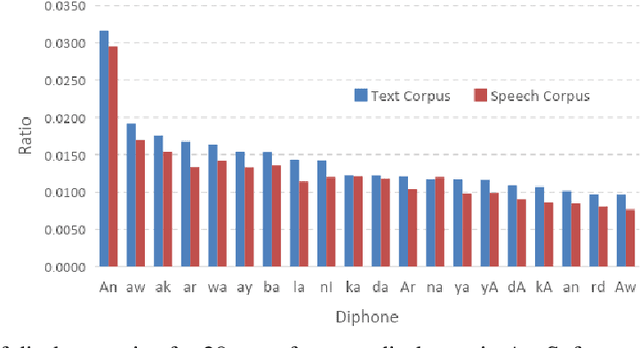

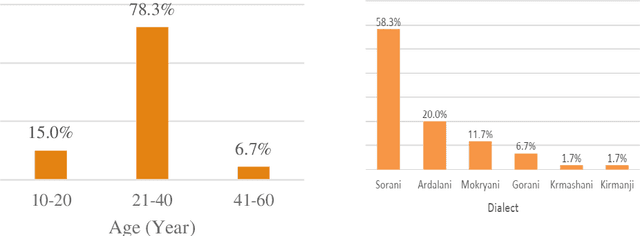
In this paper, we introduce the first large vocabulary speech recognition system (LVSR) for the Central Kurdish language, named Jira. The Kurdish language is an Indo-European language spoken by more than 30 million people in several countries, but due to the lack of speech and text resources, there is no speech recognition system for this language. To fill this gap, we introduce the first speech corpus and pronunciation lexicon for the Kurdish language. Regarding speech corpus, we designed a sentence collection in which the ratio of di-phones in the collection resembles the real data of the Central Kurdish language. The designed sentences are uttered by 576 speakers in a controlled environment with noise-free microphones (called AsoSoft Speech-Office) and in Telegram social network environment using mobile phones (denoted as AsoSoft Speech-Crowdsourcing), resulted in 43.68 hours of speech. Besides, a test set including 11 different document topics is designed and recorded in two corresponding speech conditions (i.e., Office and Crowdsourcing). Furthermore, a 60K pronunciation lexicon is prepared in this research in which we faced several challenges and proposed solutions for them. The Kurdish language has several dialects and sub-dialects that results in many lexical variations. Our methods for script standardization of lexical variations and automatic pronunciation of the lexicon tokens are presented in detail. To setup the recognition engine, we used the Kaldi toolkit. A statistical tri-gram language model that is extracted from the AsoSoft text corpus is used in the system. Several standard recipes including HMM-based models (i.e., mono, tri1, tr2, tri2, tri3), SGMM, and DNN methods are used to generate the acoustic model. These methods are trained with AsoSoft Speech-Office and AsoSoft Speech-Crowdsourcing and a combination of them. The best performance achieved by the SGMM acoustic model which results in 13.9% of the average word error rate (on different document topics) and 4.9% for the general topic.
Wav-BERT: Cooperative Acoustic and Linguistic Representation Learning for Low-Resource Speech Recognition
Oct 09, 2021
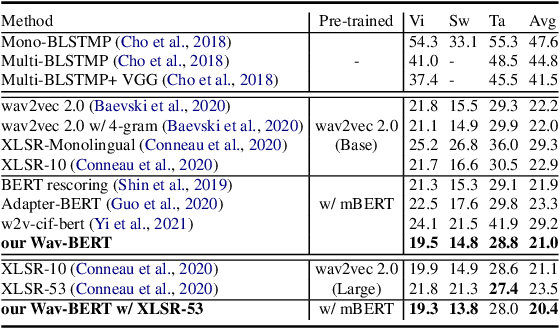
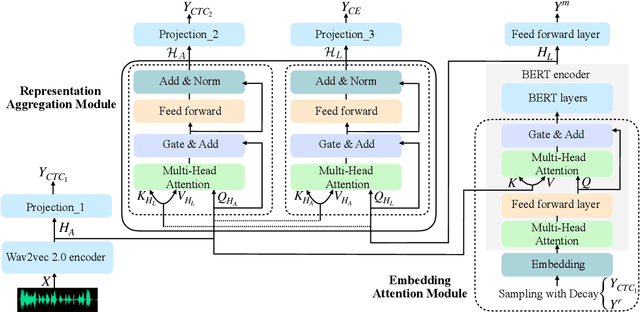
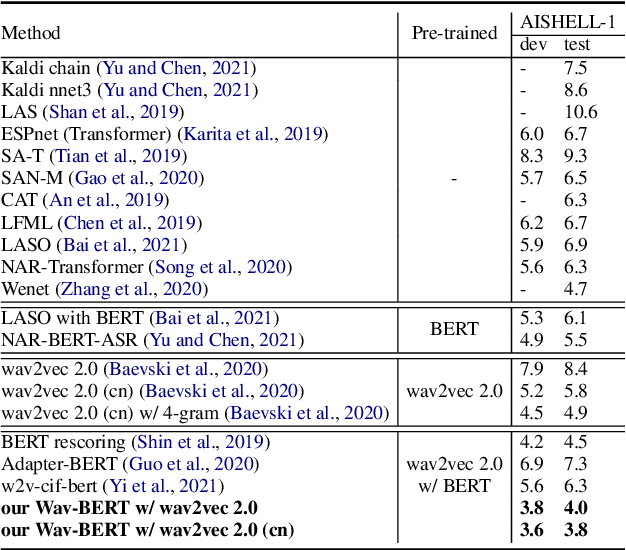
Unifying acoustic and linguistic representation learning has become increasingly crucial to transfer the knowledge learned on the abundance of high-resource language data for low-resource speech recognition. Existing approaches simply cascade pre-trained acoustic and language models to learn the transfer from speech to text. However, how to solve the representation discrepancy of speech and text is unexplored, which hinders the utilization of acoustic and linguistic information. Moreover, previous works simply replace the embedding layer of the pre-trained language model with the acoustic features, which may cause the catastrophic forgetting problem. In this work, we introduce Wav-BERT, a cooperative acoustic and linguistic representation learning method to fuse and utilize the contextual information of speech and text. Specifically, we unify a pre-trained acoustic model (wav2vec 2.0) and a language model (BERT) into an end-to-end trainable framework. A Representation Aggregation Module is designed to aggregate acoustic and linguistic representation, and an Embedding Attention Module is introduced to incorporate acoustic information into BERT, which can effectively facilitate the cooperation of two pre-trained models and thus boost the representation learning. Extensive experiments show that our Wav-BERT significantly outperforms the existing approaches and achieves state-of-the-art performance on low-resource speech recognition.
"Hello, It's Me": Deep Learning-based Speech Synthesis Attacks in the Real World
Sep 20, 2021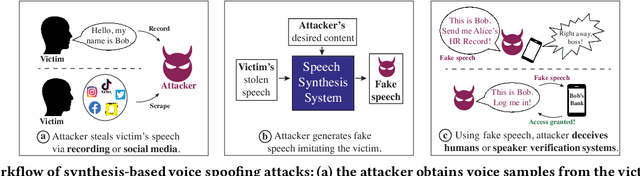
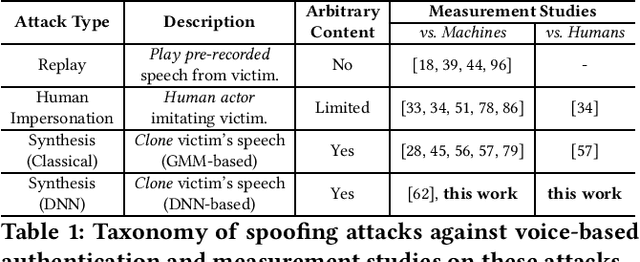

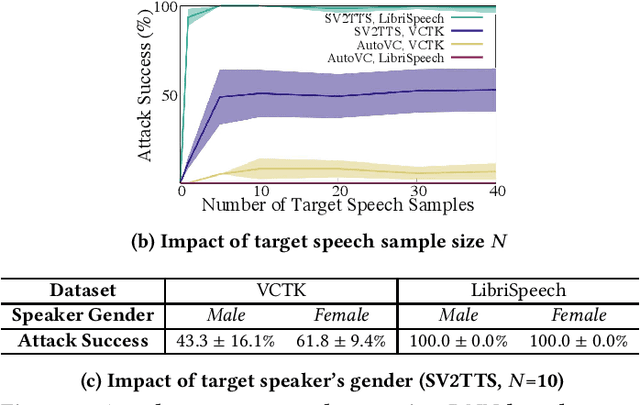
Advances in deep learning have introduced a new wave of voice synthesis tools, capable of producing audio that sounds as if spoken by a target speaker. If successful, such tools in the wrong hands will enable a range of powerful attacks against both humans and software systems (aka machines). This paper documents efforts and findings from a comprehensive experimental study on the impact of deep-learning based speech synthesis attacks on both human listeners and machines such as speaker recognition and voice-signin systems. We find that both humans and machines can be reliably fooled by synthetic speech and that existing defenses against synthesized speech fall short. These findings highlight the need to raise awareness and develop new protections against synthetic speech for both humans and machines.
Best of Both Worlds: Multi-task Audio-Visual Automatic Speech Recognition and Active Speaker Detection
May 10, 2022
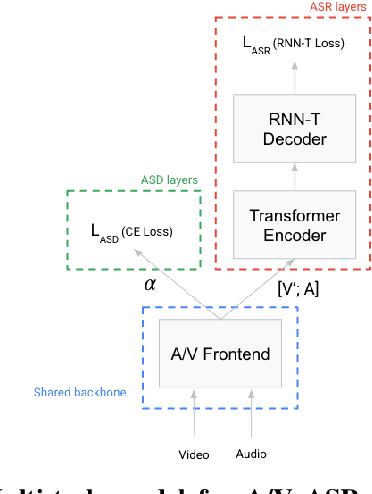
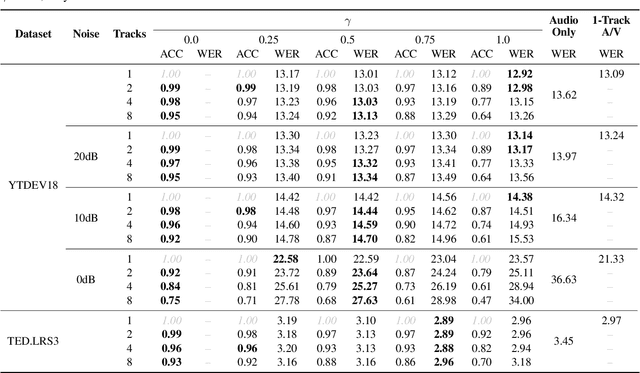
Under noisy conditions, automatic speech recognition (ASR) can greatly benefit from the addition of visual signals coming from a video of the speaker's face. However, when multiple candidate speakers are visible this traditionally requires solving a separate problem, namely active speaker detection (ASD), which entails selecting at each moment in time which of the visible faces corresponds to the audio. Recent work has shown that we can solve both problems simultaneously by employing an attention mechanism over the competing video tracks of the speakers' faces, at the cost of sacrificing some accuracy on active speaker detection. This work closes this gap in active speaker detection accuracy by presenting a single model that can be jointly trained with a multi-task loss. By combining the two tasks during training we reduce the ASD classification accuracy by approximately 25%, while simultaneously improving the ASR performance when compared to the multi-person baseline trained exclusively for ASR.
NORESQA -- A Framework for Speech Quality Assessment using Non-Matching References
Sep 16, 2021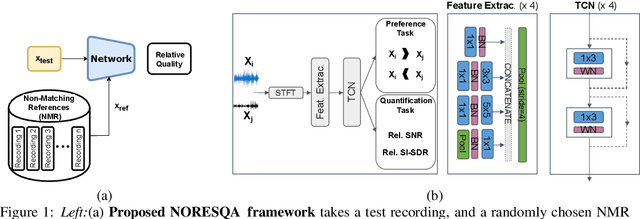
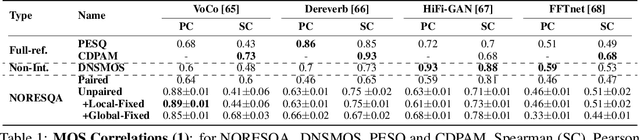
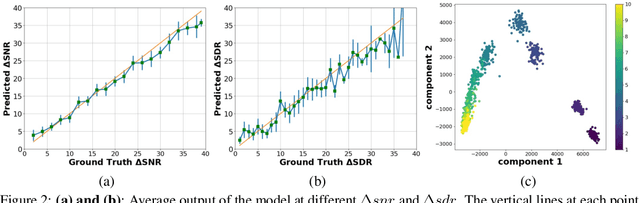
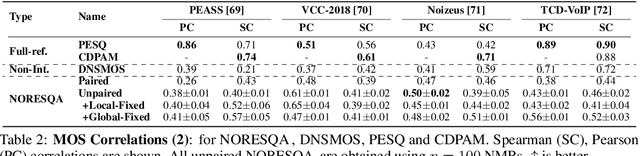
The perceptual task of speech quality assessment (SQA) is a challenging task for machines to do. Objective SQA methods that rely on the availability of the corresponding clean reference have been the primary go-to approaches for SQA. Clearly, these methods fail in real-world scenarios where the ground truth clean references are not available. In recent years, non-intrusive methods that train neural networks to predict ratings or scores have attracted much attention, but they suffer from several shortcomings such as lack of robustness, reliance on labeled data for training and so on. In this work, we propose a new direction for speech quality assessment. Inspired by human's innate ability to compare and assess the quality of speech signals even when they have non-matching contents, we propose a novel framework that predicts a subjective relative quality score for the given speech signal with respect to any provided reference without using any subjective data. We show that neural networks trained using our framework produce scores that correlate well with subjective mean opinion scores (MOS) and are also competitive to methods such as DNSMOS, which explicitly relies on MOS from humans for training networks. Moreover, our method also provides a natural way to embed quality-related information in neural networks, which we show is helpful for downstream tasks such as speech enhancement.
Signal inpainting from Fourier magnitudes
Oct 28, 2022
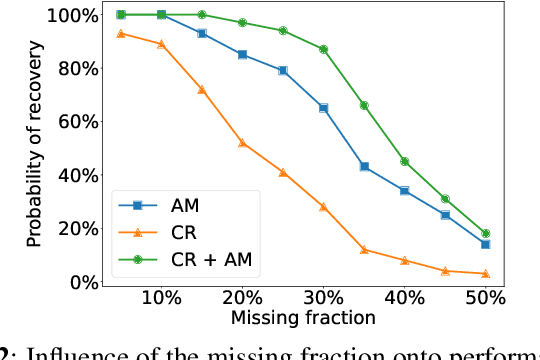
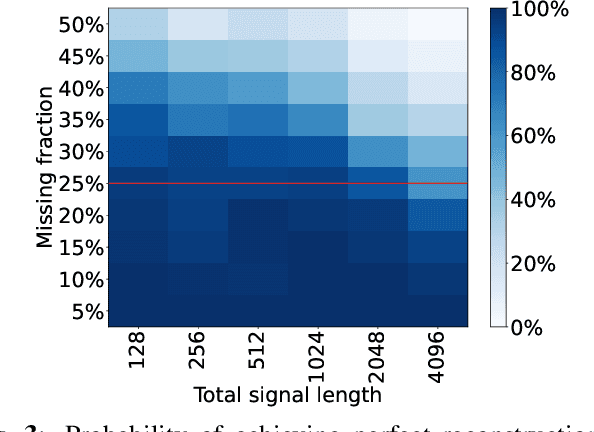
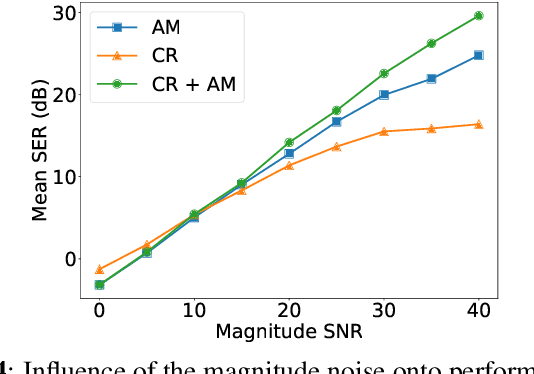
Signal inpainting is the task of restoring degraded or missing samples in a signal. In this paper we address signal inpainting when Fourier magnitudes are observed. We propose a mathematical formulation of the problem that highlights its connection with phase retrieval, and we introduce two methods for solving it. First, we derive an alternating minimization scheme, which shares similarities with the Gerchberg-Saxton algorithm, a classical phase retrieval method. Second, we propose a convex relaxation of the problem, which is inspired by recent approaches that reformulate phase retrieval into a semidefinite program. We assess the potential of these methods for the task of inpainting gaps in speech signals. Our methods exhibit both a high probability of recovering the original signals and robustness to magnitude noise.
Speech BERT Embedding For Improving Prosody in Neural TTS
Jun 15, 2021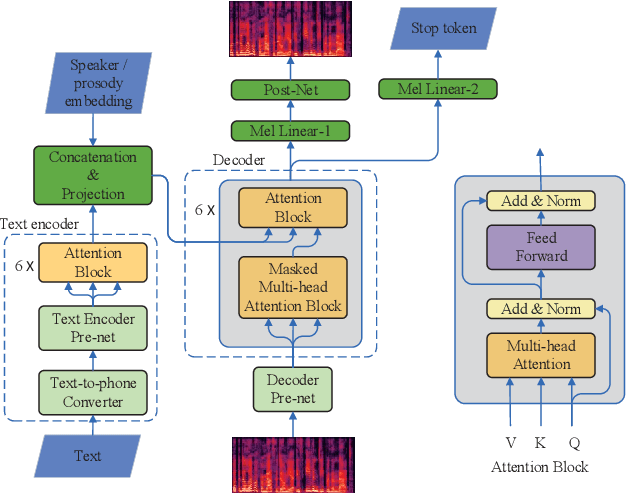
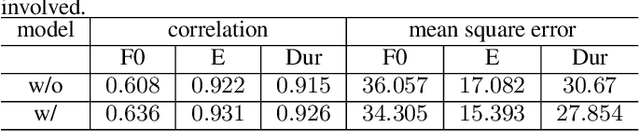
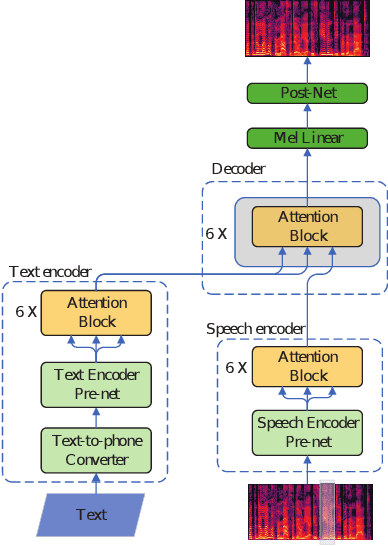
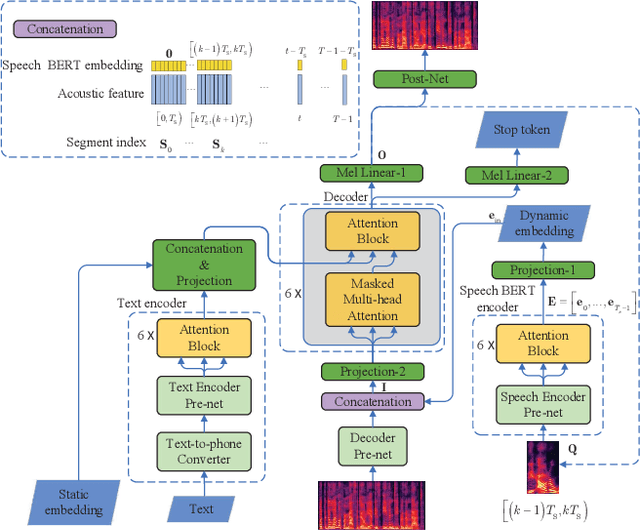
This paper presents a speech BERT model to extract embedded prosody information in speech segments for improving the prosody of synthesized speech in neural text-to-speech (TTS). As a pre-trained model, it can learn prosody attributes from a large amount of speech data, which can utilize more data than the original training data used by the target TTS. The embedding is extracted from the previous segment of a fixed length in the proposed BERT. The extracted embedding is then used together with the mel-spectrogram to predict the following segment in the TTS decoder. Experimental results obtained by the Transformer TTS show that the proposed BERT can extract fine-grained, segment-level prosody, which is complementary to utterance-level prosody to improve the final prosody of the TTS speech. The objective distortions measured on a single speaker TTS are reduced between the generated speech and original recordings. Subjective listening tests also show that the proposed approach is favorably preferred over the TTS without the BERT prosody embedding module, for both in-domain and out-of-domain applications. For Microsoft professional, single/multiple speakers and the LJ Speaker in the public database, subjective preference is similarly confirmed with the new BERT prosody embedding. TTS demo audio samples are in https://judy44chen.github.io/TTSSpeechBERT/.
Integrating Knowledge in End-to-End Automatic Speech Recognition for Mandarin-English Code-Switching
Dec 19, 2021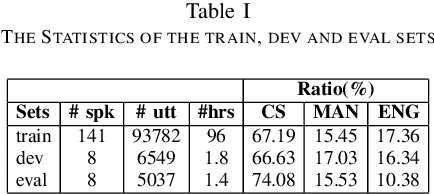
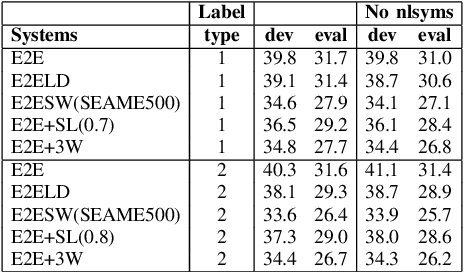

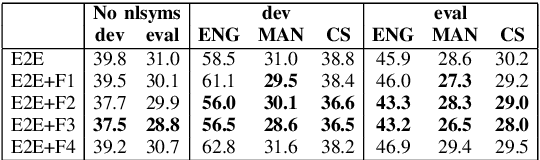
Code-Switching (CS) is a common linguistic phenomenon in multilingual communities that consists of switching between languages while speaking. This paper presents our investigations on end-to-end speech recognition for Mandarin-English CS speech. We analyse different CS specific issues such as the properties mismatches between languages in a CS language pair, the unpredictable nature of switching points, and the data scarcity problem. We exploit and improve the state-of-the-art end-to-end system by merging nonlinguistic symbols, by integrating language identification using hierarchical softmax, by modeling sub-word units, by artificially lowering the speaking rate, and by augmenting data using speed perturbed technique and several monolingual datasets to improve the final performance not only on CS speech but also on monolingual benchmarks in order to make the system more applicable on real life settings. Finally, we explore the effect of different language model integration methods on the performance of the proposed model. Our experimental results reveal that all the proposed techniques improve the recognition performance. The best combined system improves the baseline system by up to 35% relatively in terms of mixed error rate and delivers acceptable performance on monolingual benchmarks.
Don't Discard Fixed-Window Audio Segmentation in Speech-to-Text Translation
Oct 24, 2022
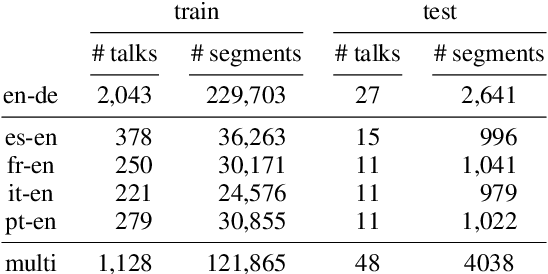
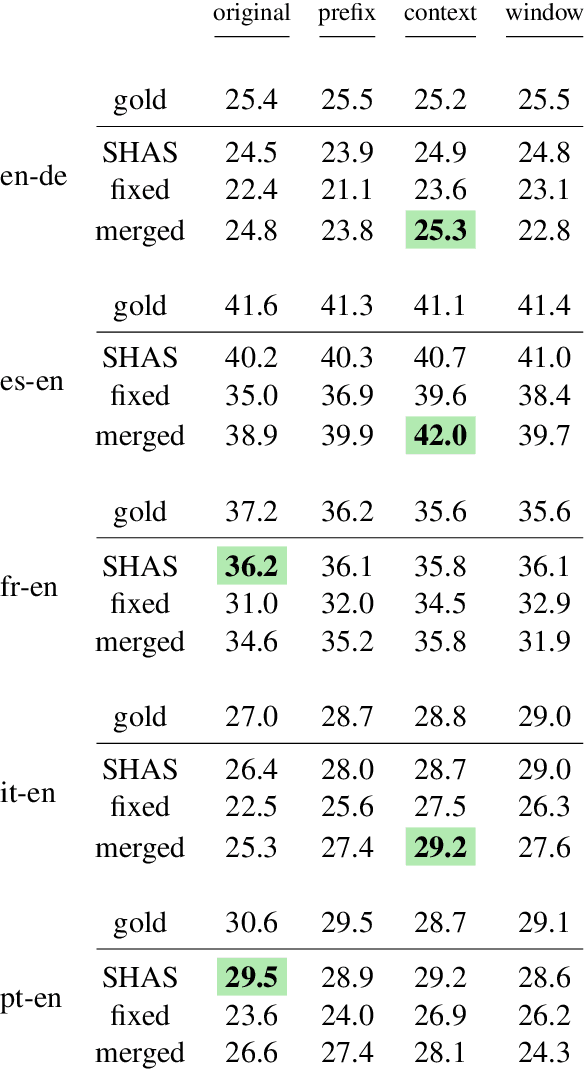
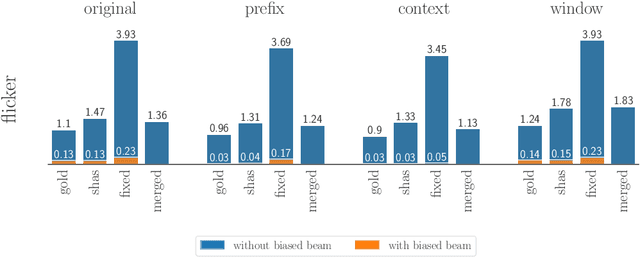
For real-life applications, it is crucial that end-to-end spoken language translation models perform well on continuous audio, without relying on human-supplied segmentation. For online spoken language translation, where models need to start translating before the full utterance is spoken, most previous work has ignored the segmentation problem. In this paper, we compare various methods for improving models' robustness towards segmentation errors and different segmentation strategies in both offline and online settings and report results on translation quality, flicker and delay. Our findings on five different language pairs show that a simple fixed-window audio segmentation can perform surprisingly well given the right conditions.
DelightfulTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2021
Oct 25, 2021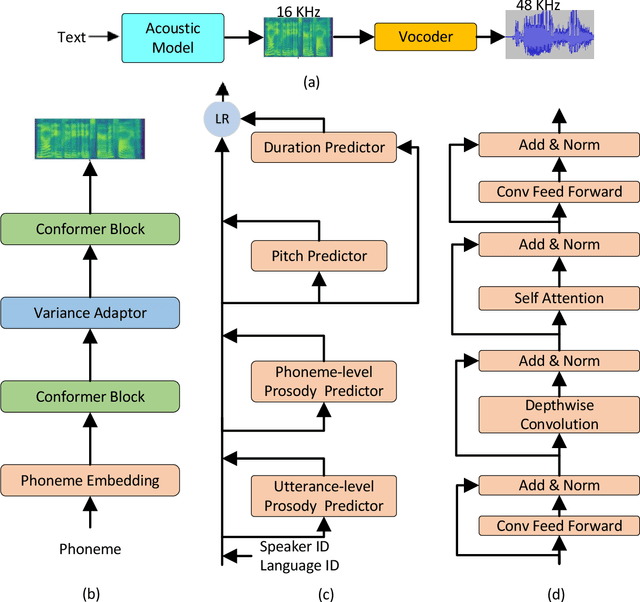
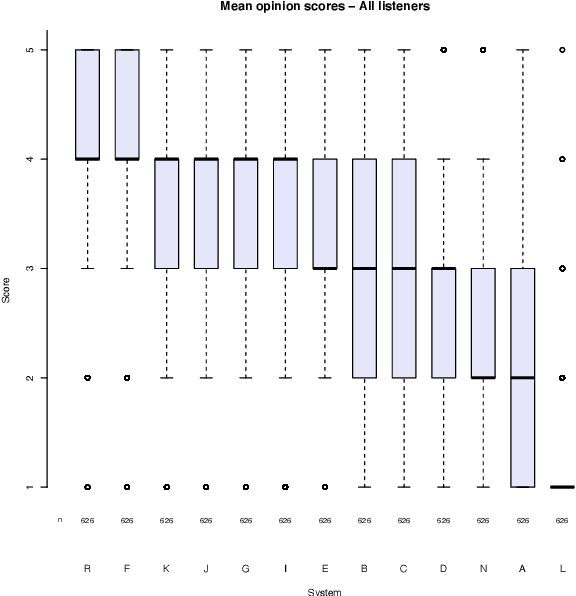
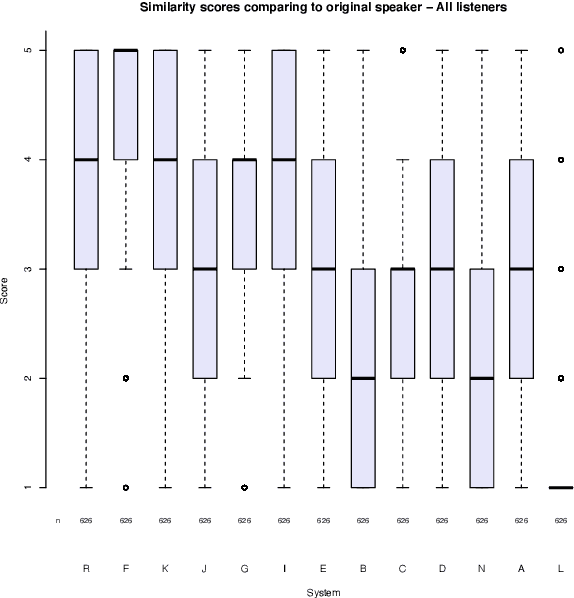
This paper describes the Microsoft end-to-end neural text to speech (TTS) system: DelightfulTTS for Blizzard Challenge 2021. The goal of this challenge is to synthesize natural and high-quality speech from text, and we approach this goal in two perspectives: The first is to directly model and generate waveform in 48 kHz sampling rate, which brings higher perception quality than previous systems with 16 kHz or 24 kHz sampling rate; The second is to model the variation information in speech through a systematic design, which improves the prosody and naturalness. Specifically, for 48 kHz modeling, we predict 16 kHz mel-spectrogram in acoustic model, and propose a vocoder called HiFiNet to directly generate 48 kHz waveform from predicted 16 kHz mel-spectrogram, which can better trade off training efficiency, modelling stability and voice quality. We model variation information systematically from both explicit (speaker ID, language ID, pitch and duration) and implicit (utterance-level and phoneme-level prosody) perspectives: 1) For speaker and language ID, we use lookup embedding in training and inference; 2) For pitch and duration, we extract the values from paired text-speech data in training and use two predictors to predict the values in inference; 3) For utterance-level and phoneme-level prosody, we use two reference encoders to extract the values in training, and use two separate predictors to predict the values in inference. Additionally, we introduce an improved Conformer block to better model the local and global dependency in acoustic model. For task SH1, DelightfulTTS achieves 4.17 mean score in MOS test and 4.35 in SMOS test, which indicates the effectiveness of our proposed system